Index (Индексы)
Типы индексов:
Индексы в виде B-дерева (B-tree)
– самые распространенные и используются по умолчанию
Кластерные индексы в виде B-дерева
– определяются специально для кластера
Индексы хэш-кластера
– определяются специально для хэш-кластера
Глобальные и локальные индексы
– относятся к секционированным таблицам и индексам
Индексы с инвертированным ключом
– полезны в среде Oracle Real Application Cluster
Битовые индексы
– компактные, подходят для столбцов с небольшим набором значений
Индексы на базе функций
– содержат заранее вычисленные значения функции/выражения
Индексы домена
– зависят от приложения или картриджа
B*Tree
Структура индекса выглядит так:
Блоки самого нижнего уровня в индексе, которые называют листовыми вершинами (leaf blocks ), содержат все проиндексированные ключи и идентификаторы строк (rowid на схеме), ссылающиеся на соответствующие строки. Промежуточные блоки над листовыми вершинами называют блоками ветвления (branch blocks ). Они используются для переходов по структуре. Самый верхний блок называется корневым (root block ), он относится к группе branch blocks.
Индексы состоят из одного или более уровней branch blocks и одного уровня leaf blocks.
Index height
- высота индекса, кол-во уровней индекса
blevel
- высота кол-ва уровней branch blocks
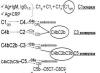
Пример
Создадим новую пустую таблицу и создадим индекс по ней. Индекс будет состоять из одного пустого блока (он будет одновременно и root и leaf блоком). Index height = 1, blevel = 0.
Добавим строки в таблицу. По мере того как новые строки будут вставлять в таблицу, новые индексные записи будут добавляться в блок индекса, до тех пор пока блок не заполнится.
Далее Oracle выделяет два новых индексных блока и переносит все записи из начального блока (root block) в эти два новых блока, и добавляет в root block указатели(RBA - Relative Block Address) на эти два новых блока (которые теперь являются листовыми) и наименьшее проиндексированное значение из каждого из этих двух листовых блоков. RBA1 - min(value) leaf_blk_1, RBA2 - min(value) leaf_blk_2. Таким образом Oracle с этой информацией из root блока может искать нужное значение в листовых блоках.
Теперь Index height = 2, blevel = 1.

Продолжаем вставлять строки в таблицу. Два leaf блока заполняются индексами, и когда они заполнятся, Oracle добавит ещё один листовой блок, содержимое старого заполненного блока, куда должен был бы попасть новый индекс распределяется между старым и новым листовыми блоками. Указатель на новый листовой блок помещается в root блок. Каждый раз когда листовой блок заполняется и разделяется на новый, в root записывается указатель, таким образом со временем заполнится и root блок.
Когда root блок полностью заполнится указателями, произойдёт его разделение на два branch блока, над которыми будет root блок с указателями на эти два блока. Теперь Index height = 3, blevel = 2. Как на картинке ниже:

По мере заполнения разделяются(split) листовые блоки, затем branch блоки и root блок. И так далее.
Интересно отметить, что листовые блоки фактически образут двухсвязный список.
Как только найдено "начало" среди листовых вершин, т.е. первое значение, очень легко просматривать значения по порядку (это называют также просмотром диапазона по индексу, index range scan
). Проходить по структуре индекса больше не нужно; мы просто переходим по листовым вершинам.
Одно из свойств В*-дерева состоит в том, что все листовые блоки должны быть на одном уровне, если точнее, разница по высоте между ветвями дерева не может быть больше 1.
Уровень листовых блоков называют также высотой дерева
.
Все вершины выше листовых могут указывать только на содержащие более детальную информацию вершины следующего уровня, а листовые вершины указывают на конкретные идентификаторы строк или диапазоны идентификаторов строк. Большинство индексов на основе В*-дерева будут иметь высоту 2 или 3 , даже для миллионов записей. Это означает, что для поиска ключа в индексе потребуется 2 или 3 чтения, что неплохо.
Еще одно свойство - автоматическая балансировка листовых вершин : они почти всегда располагаются на одном уровне. Есть причины, по которым индекс может оказаться не идеально сбалансированным при изменении и удалении записей. Сервер Oracle будет пытаться заполнять блоки индекса не более чем на три четверти, но и это свойство может временно нарушаться при выполнении операторов DELETE и UPDATE.
Создать индекс
create index t_idx on t(owner,object_type,object_name);
Когда следует использовать B*Tree индексы:
- Как средство доступа к строкам в таблице.
Индекс читается, чтобы добраться до строки в таблице. Так имеет смысл обращаться к очень небольшой части строк таблицы.
- Как средство ответа на запрос.
Индекс содержит достаточно информации, чтобы дать полный ответ на запрос — к таблице вообще не придется обращаться. Индекс будет использоваться как уменьшенная версия таблицы.
Bitmap
Индексы на основе битовых карт — это структуры, в которых хранятся указатели на множество строк, соответствующих одному значению ключа индекса
, тогда как в структуре В*-дерева количество ключей индекса обычно примерно соответствует количеству строк. В индексе на основе битовых карт записей очень мало, и каждая из них указывает на множество строк. В индексе на основе В*-дерева обычно имеется однозначное соответствие — запись индекса ссылается на одну строку.
Когда следует использовать Bitmap индексы:
Для данных с небольшим количеством уникальных значений. Это данные, для которых при делении количества уникальных значений в строках на общее количество строк получается небольшое число (близкое к нулю).
Создать bitmap индекс
create bitmap index empno_bmx on t(empno);
Function Based
Индексы по функциям позволяют индексировать вычисляемые столбцы и эффективно
использовать их в запросах.
Индексы можно создавать не только по системным оракловым ф-циям, но и по своим написанным ф-циям
Создать индекс по ф-ции
create index emp_upper_idx on emp (upper(ename));
Application domain indexes(прикладные индексы)
Прикладные индексы позволяют создавать новые, еще не существующие в базе данных, типы индексов.
Например , если создается приложение, анализирующее хранящиеся в базе данных изображения и выдающее информацию об этих изображениях - скажем, используемые цвета — можно создать специальный индекс по изображениям. При добавлении изображений в базу данных будет вызываться код для извлечения информации о цветах, которая будет сохраняться отдельно (там, где сочтет нужным разработчик). При выполнении запросов, требующих вернуть "изображения в синих тонах", сервер Oracle при необходимости потребует от прикладного индекса вернуть ответ.
Избирательность индекса
Избирательность представляет собой отношение количества выбранных строк к общему количеству строк. Если это отношение мало, значит, индекс обладает высокой избирательностью. Он позволяет отбросить большую часть строк и значительно уменьшает размер результирующего набора. Подобный индекс является эффективным. Индекс, не обладающий избирательностью, не является эффективным.
Наилучшей избирательностью обладает уникальный индекс. При использовании уникального индекса возвращается только одна строка, что делает этот индекс наиболее эффективным для применения в запросах, которые должны возвращать только одну строку. Например, индексирование по столбцу, содержащему уникальный код, позволяет быстро найти требуемую строку.
В Oracle имеется несколько типов индексов:
· древовидные индексы (В-деревья).
· хешированные индексы (hash ).
· индексы на основе битовых карт или битовые индексы (bitmap ).
В-деревья были реализованы в Oracle практически с самого начала ее существования, затем появились хешированные индексы появились, а затем - битовые карты.
Понимание того, когда и где следует использовать конкретные типы индексов, очень важно для эффективного их применения. В-деревья используются наиболее часто, в то время как хешированные и битовые индексы лишь при наличии некоторых условий могут обеспечить существенные преимущества в выполнении определенных запросов.
Оператор создания индекса использует следующий синтаксис:
СREATE INDEX имя_индекса
ON имя_таблицы (имя_столбца, [¼])
Для удаления индекса используется команда
DROP INDEX <ИМЯ> (удалить)
Можно перестроить существующий индекс без его удаления и повторного создания при помощи команды:
ALTER INDEX<ИМЯ> REBUILD (перестроить индекс)
ALTER INDEX<ИМЯ> UNUSABLE (отключить индекс на время,
чтобы снова включить обратно при помощи REBUILD)
B-деревья
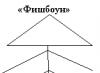
Видимо, наиболее популярным подходом к организации индексов в базах данных является использование техники B-деревьев. B-дерево содержит по одному индексному элементу для каждой строки таблицы, в которой имеется непустое (NOT NULL) индексное значение. С точки зрения внешнего логического представления B-дерево - это сбалансированное сильно ветвистое дерево во внешней памяти (рис.5.3).
Рис. 5.3 - Древовидный индекс по текстовому столбцу
С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). Внутренние и листовые страницы обычно имеют разную структуру.
В типовом случае структура внутренней страницы выглядит следующим образом:
При этом выдерживаются следующие свойства:
ключ(1) <= ключ(2) <= ... <= ключ(n);
в странице дерева Nm находятся ключи k со значениями ключ(m) <= k <= ключ(m+1).
Листовая страница обычно содержит значение индекса и идентификаторы строк (ROWID) и имеет следующую структуру:
Листовая страница обладает следующими свойствами:
· ключ(1) < ключ(2) < ... < ключ(t);
· сп(r) - упорядоченный список идентификаторов кортежей (tid), включающих значение ключ(r);
· листовые страницы связаны одно- или двунаправленным списком.
Поиск в B-дереве - это прохождение от корня к листу в соответствии с заданным значением ключа. Заметим, что поскольку деревья сильно ветвистые и сбалансированные, то для выполнения поиска по любому значению ключа потребуется одно и то же (и обычно небольшое) число обменов с внешней памятью. Более точно, в сбалансированном дереве, где длины всех путей от корня к листу одни и те же, если во внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной log n (m). Если n достаточно велико (обычный случай), то глубина дерева невелика, и производится быстрый поиск.
Основной "изюминкой" B-деревьев является автоматическое поддержание свойства сбалансированности. Рассмотрим, как это делается при выполнении операций занесения и удаления записей.
При занесение новой записи выполняется:
· Поиск листовой страницы. Фактически, производится обычный поиск по ключу. Если в B-дереве не содержится ключ с заданным значением, то будет получен номер страницы, в которой ему надлежит содержаться, и соответствующие координаты внутри страницы.
· Помещение записи на место. Естественно, что вся работа производится в буферах оперативной памяти. Листовая страница, в которую требуется занести запись, считывается в буфер, и в нем выполняется операция вставки. Размер буфера должен превышать размер страницы внешней памяти.
· Если после выполнения вставки новой записи размер используемой части буфера не превосходит размера страницы, то на этом выполнение операции занесения записи заканчивается. Буфер может быть немедленно вытолкнут во внешнюю память, или временно сохранен в оперативной памяти в зависимости от политики управления буферами.
· Если же возникло переполнение буфера (т.е. размер его используемой части превосходит размер страницы), то выполняется расщепление страницы. Для этого запрашивается новая страница внешней памяти, используемая часть буфера разбивается, грубо говоря, пополам (так, чтобы вторая половина также начиналась с ключа), и вторая половина записывается во вновь выделенную страницу, а в старой странице модифицируется значение размера свободной памяти. Естественно, модифицируются ссылки по списку листовых страниц.
· Чтобы обеспечить доступ от корня дерева к заново заведенной странице, необходимо соответствующим образом модифицировать внутреннюю страницу, являющуюся предком ранее существовавшей листовой страницы, т.е. вставить в нее соответствующее значение ключа и ссылку на новую страницу. При выполнении этого действия может снова произойти переполнение теперь уже внутренней страницы, и она будет расщеплена на две. В результате потребуется вставить значение ключа и ссылку на новую страницу во внутреннюю страницу-предка выше по иерархии и т.д.
· Предельным случаем является переполнение корневой страницы B-дерева. В этом случае она тоже расщепляется на две, и заводится новая корневая страница дерева, т.е. его глубина увеличивается на единицу.
При удалении записи выполняются следующие действия:
· Поиск записи по ключу. Если запись не найдена, то удалять ничего не нужно.
· Реальное удаление записи в буфере, в который прочитана соответствующая листовая страница.
· Если после выполнения этой подоперации размер занятой в буфере области оказывается таковым, что его сумма с размером занятой области в листовых страницах, являющихся левым или правым братом данной страницы, больше, чем размер страницы, операция завершается.
· Иначе производится слияние с правым или левым братом, т.е. в буфере производится новый образ страницы, содержащей общую информацию из данной страницы и ее левого или правого брата. Ставшая ненужной листовая страница заносится в список свободных страниц. Соответствующим образом корректируется список листовых страниц.
· Чтобы устранить возможность доступа от корня к освобожденной странице, нужно удалить соответствующее значение ключа и ссылку на освобожденную страницу из внутренней страницы - ее предка. При этом может возникнуть потребность в слиянии этой страницы с ее левым или правыми братьями и т.д.
· Предельным случаем является полное опустошение корневой страницы дерева, которое возможно после слияния последних двух потомков корня. В этом случае корневая страница освобождается, а глубина дерева уменьшается на единицу.
Как видно, при выполнении операций вставки и удаления свойство сбалансированности B-дерева сохраняется, а внешняя память расходуется достаточно экономно.
Проблемой является то, что при выполнении операций модификации слишком часто могут возникать расщепления и слияния. Чтобы добиться эффективного использования внешней памяти с минимизацией числа расщеплений и слияний, применяются более сложные приемы, в том числе:
· упреждающие расщепления, т.е. расщепления страницы не при ее переполнении, а несколько раньше, когда степень заполненности страницы достигает некоторого уровня;
· переливания, т.е. поддержание равновесного заполнения соседних страниц;
· слияния 3-в-2, т.е. порождение двух листовых страниц на основе содержимого трех соседних.
Следует заметить, что при организации мультидоступа к B-деревьям, характерного при их использовании в СУБД, приходится решать ряд нетривиальных проблем. Конечно, грубые решения очевидны, например монопольный захват B-дерева на все выполнение операции модификации. Но существуют и более тонкие решения.
Сбалансированное дерево автоматически не уравновешивает распределение ключей в пределах дерева так, чтобы половина ключей находилась бы на одной стороне В-дерева, а другая половина - на другой. Очевидно, что нет необходимости перестраивать дерево всякий раз, когда добавляются или удаляются ключи. Однако если ключи добавляются или удаляются только на одной стороне дерева, то распределение индексных ключей может стать неравномерным, с изрядным числом разреженных и даже опустошенных блоков по одну сторону дерева. В этом случае индекс рекомендуется перестроить.
На В-деревьях для извлечения данных по запросу может использоваться механизм быстрого полного просмотра (fast full scan ). Этот механизм дает существенные преимущества, если все запрошенные из конкретной таблицы данные могут быть получены только из индекса. При быстром полном просмотре эффективный многоблочный ввод/вывод, обычно применяемый для полных просмотров таблиц, используется для прочтения всех листовых блоков В-дерева. Поскольку число листовых блоков индекса, скорее всего, намного меньше, чем блоков данных в таблице, для выполнения запроса требуется просмотреть меньшее число блоков. Поэтому просмотр индекса совершится значительно быстрее, чем полный просмотр таблицы, хотя иногда неравномерное распределение ключей снижает эффективность быстрого полного просмотра, поскольку требуется просмотреть большее число листовых блоков (содержащих малое или вообще нулевое число элементов). При этом следует учитывать наличие или отсутствие в таблице пустых значений, которые, как было сказано выше, в индекс не заносятся.
В-деревья можно использовать для поиска данных, как по условиям равенства, так и по условиям неравенства. Это единственный тип индексов, который можно использовать для предикатов неравенства: LIKE, BETWEEN, “>”, “>=”, “<”, “<=”. Исключение представляет случай использования предиката LIKE при сравнении с шаблоном вида ‘%выражение’ или ‘_выражение ’. В-деревья хранят только непустые значения ключей, так что можно построить разреженное В-дерево.
Индексы Oracle обеспечивают быстрый доступ к строкам таблиц, сохраняя отсортированные значения указанных столбцов и используя эти отсортированные значения для быстрого нахождения ассоциированных строк таблицы. Индексы позволяют находить строку с определенным значением столбца, просматривая при этом лишь небольшую часть общего объема строк таблицы. Таким образом правильное использование индексов сокращает до минимума количество дорогостоящих операций ввода-вывода.
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса – ускорение запросов – довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблиц, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже.
Вообще говоря, если таблицы в основном используются для чтения (выборки) информации, как в хранилищах данных, то лучше иметь много индексов. Если база данных относится к типу OLTP, с большим количеством вставок, обновлений и удалений, то лучше обойтись меньшим числом индексов.
Если только вам не нужно обращаться к большинству сток таблицы, индексированные запросы обеспечивают более быстрое получение результатов, чем запросы, не использующие индексы. Не существует ограничений на количество индексов, которые могут относиться к одной таблице Oracle, но, как упоминалось ранее, от их количества зависит производительность. Индекс полностью прозрачен для пользователя – т.е. оператор SQL пользователя не должен изменяться в результате создания индексов. Однако разработчикам приложений для построения эффективных запросов следует хорошо представлять себе, что такое индексы и как они работают.
Индексы могут относиться к нескольким типам, наиболее важные из которых перечислены ниже:
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце – обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы – это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы – это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы – индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных, следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индекс имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4-5% данных таблицы. Альтернативной использования индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного колюча Oracle автоматически создаст индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, стоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец в котором количество строк с одинаковым значением минимально.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса: например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Схемы индексации Oracle
Oracle предлагает несколько схем индексации, соответствующих требованиям различных типов приложений. На фазе проектирования после тщательного анализа конкретных требований приложения, необходимо выбрать правильный тип индекса.
(B*tree)
В реализации индексов на основе B-деревьев используется концепция сбалансированного (на что указывает буква ‘B’ (balanced)) дерева поиска в качестве основы структуры индекса. В Oracle имеется собственный вариант B-дерева. Это обычные индексы, создаваемые по умолчанию, когда вы применяете оператора CREATE INDEX.
Индексы на основе B-деревьев структурированы в форме обратного дерева, где блоки верхнего уровня называются блоками ветвей (branch blocks), а блоки нижнего уровня – листовыми блоками (leaf blocks). В иерархии узлов все узлы кроме вершины, или корневого узла, имеют родительский узел и могут иметь ноль или более дочерних узлов. Если глубина древовидной структуры, т.е. количество уровней, одинакова от каждого листового блока до корневого узла, то такое дерево называется сбалансированным, или B-деревом.
B-деревья автоматически поддерживают необходимый уровень индекса по размеру таблицы. B-деревья также гарантируют, что индексные блоки всегда будут заполнены не меньше, чем наполовину, и менее, чем на 100%. B-деревья допускают операции выборки, вставки и удаления с очень небольшим количеством операций ввода-вывода на один оператор. Большинство B-деревьев имеет всего три и менее уровней. При использовании B-дерева нужно читать только блоки B-дерева, так что количество операций ввода-вывода будет ограничено числом уровней B-дерева (скажем, тремя) плюс две операции ввода-вывода на выполнение обновления или удаления (одна для чтения и одна для записи). Для выполнения поиска по B-дереву понадоисят всего три или менее обращений к диску.
Реализация B-дерева от Oracle – всегда сохраняет дерево сбалансированным. Листовые блоки содержат по два элемента: индексированные значения столбца и соответствующий идентификатор ROWID для строки, которая содержит это значение столбца. ROWID – уникальный указатель Oracle, идентифицирующий физическое местоположение строки и обеспечивающий самый быстрый способ доступа к строке в базе данных Oracle. Сканирование индекса быстро дает ROWID строки, и отсюда можно быстро получить к ней доступ непосредственно. Если запрос нуждается лишь в значении индексированного столбца, то конечно, последний шаг исключается, поскольку извлекать дополнительные данные, кроме прочитанных из индекса, не потребуется.
Оценка размера индекса
Для оценки размера нового индекса можно использовать пакет DBMS_SPACE. Процедуре CREATE_INDEX_COST этого пакета потребуется передать оператор DDL, создающий индекс, в качестве атрибута.
SET SERVEROUTPUT ON DECLARE l_index_ddl varchar2(1000); l_used_bytes NUMBER; l_allocated_bytes NUMBER; BEGIN DBMS_SPACE.create_index_cost (ddl => "create index repsons_idx on EMP(ENAME)", used_bytes => l_used_bytes, alloc_bytes => l_allocated_bytes); DBMS_OUTPUT.PUT_LINE ("RESULT:"); DBMS_OUTPUT.PUT_LINE ("used_bytes = " || l_used_bytes || " byte"); DBMS_OUTPUT.PUT_LINE ("alloc_bytes = " || l_allocated_bytes || " byte"); END; /
Обратите внимание на отличие между атрибутами, касающимися размера, в процедуре CREATE_INDEX_COST:
- Used_bytes показывает количество байт, которыми представлены данные индекса;
- Alloc_bytes показывает количество байт, которое займет индекс в табличном пространстве после его создания.
Создание индекса
Индекс создается с помощью оператора CREATE INDEX
CREATE INDEX employee_id ON employee(employee_id) TABLESPACE MY_INDEXES;
По умолчанию Oracle допускает дублирование значения в столбцах индекса, которые также называются ключевыми столбцами. Однако можно специфицировать уникальный индекс, что исключит дублирование значений столбца в нескольких строках.
Для создания уникального индекса служит оператор CREATE UNIQUE INDEX.
Специальные типы индексов
Нормальный или типовой индекс, который создается в базе данных, называется индексом кучи (heap index), или неупорядоченным индексом. Oracle также предоставляет несколько специальных типов индексов для специфических нужд.
Битовые индексы (bitmap indexes)
Битовые индексы используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью (число уникальных записей в таблице мало) при при большом размере таблицы. Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных.
Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев.
Для создания битового индекса используется оператор
CREATE BITMAP INDEX gender_dx ON employee(gender) TABLESPACE MY_INDEXES;
Иногда можно наблюдать значительное повышение производительности при замене обычных индексов B-дерева на битовые в некоторых очень крупных таблицах. Однако каждый элемент битового индекса открывает огромное количество строк в таблице, так что когда данные обновляются,вставляются или удаляются из таблицы, то необходимые обновления битового индекса очень велики., и сам индекс может существенно увеличиться в размере. Единственный способ обойти это увеличение размера индекса с последующим падением производительности заключается в регулярной его перестройке. Битовый индекс – не слишком разумная альтернатива для таблиц, подвергающихся большому количеству вставок, удалений и обновлений.
Индексы с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
SQL> CREATE INDEX reverse_idx ON employee(emp_id) REVERSE;
При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет создания индекса со сжатым ключом. Всякий раз, когда индексируемый ключ имеет повторяющийся компонент, или же создается уникальный многостолбцовый индекс, получается выигрыш от использования сжатия ключа. Вот пример:
SQL> CREATE INDEX emp_indx1 ON employees(ename) TABLESPACE MY_INDEXES COMPRESS 1;
Приведенный выше оператор сжимает все дублированные вхождения индексированного ключа в листовом блоке индекса (на уровне 1).
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы и сохраняют результат в индексе. Когда конструкция WHERE содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER
SQL> CREATE INDEX lastname _idx ON employees(LOWER(l_name));
Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции, поскольку база данных создаст его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Секционированные индексы
Секционированные индексы используются для индексации секционированных таблиц. Oracle предлагает два типа индексов для таких таблиц: локальные и глобальные.
Существенное различие между ними заключается в том, что локальные индексы основаны на разделах таблицы, по которой они созданы. Если таблица секционирована на 12 разделов по диапазонам дат, то индексы также будут распределены по тем же 12 разделам. Другими словами, между разделами индексов и разделами таблиц существует соответствие «один к одному». Такого соответствия нет между глобальными индексами и разделами таблицы, потому что глобальные индексы секционируются независимо от базовых таблиц.
В следующих разделах будут раскрыт важные различия между управлением глобального секционированными индексами и локально секционированными индексами.
Глобальные индексы
Глобальные индексы на секционированных таблицах могут быть как секционированными, так и несекционированными. Глобальные несекционированные индексы подобны обычным индексам Oracle для несекционированных таблиц. Для создания таких индексов применяется обычный синтаксис CREATE INDEX.
Ниже приведен пример глобального индекса на таблице ticket_sales:
SQL> CREATE INDEX tickersales_idx ON ticket_sales(month) GLOBAL PARTITION BY range(month) (PARTITION ticketsales1_idx VALUES LESS THAN (3) PARTITION ticketsales1_idx VALUES LESS THAN (6) PARTITION ticketsales2_idx VALUES LESS THAN (9) PARTITION ticketsales3_idx VALUES LESS THAN (MAXVALUE);
Обратите внимание, что управление глобально секционированными индексами требует серьезных усилий. Всякий раз, когда происходит какое-т о действие DDL над секционированной таблицей, ее глобальные индексы требуют перестройки. Действия DDL над лежащей в основе таблице помечают глобальные индексы как недействительные. По умолчанию любая операция обслуживания секционированной таблицы делает недействительными глобальные индексы.
Давайте в качестве примера воспользуемся таблицей ticket_sales, чтобы разобраться, почему это так. Предположим, что вы ежеквартально уничтожаете самый старый раздел, чтобы освободить место для нового раздела, в который поступят данные за новый квартал. Когда уничтожается раздел, относящийся к таблице ticket_sales, глобальные индексы могут стать недействительными, потому что часть данных, на которые они указывают, перестают существовать. Чтобы предотвратить такое объявление недействительным индекса из-за уничтожения раздела, необходимо использовать опцию UPDATE GLOBAL INDEXES вместе с оператором DROP PARTITION:
SQL> ALTER TABLE ticket_sales DROP PARTITION sales_quarter01 UPDATE GLOBAL INDEXES;
Если не включить оператор UPDATE GLOBAL INDEXES, то все глобальные индексы станут недействительными. Опцию UPDATE GLOBAL INDEXES можно также использовать при добавлении, объединении, обмене, слиянии, перемещении, разделении или усечении секционированных таблиц. Разумеется, с помощью ALTER INDEX..REBUILD можно перестраивать любой индекс, который становится недействительным, но эта опция также требует дополнительных затрат времени и обслуживания.
При небольшом количестве листовых блоков индекса, что приводит к высокой конкуренции Oracle рекомендует использовать глобальные индексы с хэш-секционированием. Синтаксис для создания хэш-секционированного глобального индекса подобен тому, что применяется для хэш-секционированной таблицы. Например, следующий оператор создает хэш-секционированный глобальный индекс:
SQL> CREATE INDEX hgidx ON tab (c1,c2,c3) GLOBAL PARITION BY HASH (c1,c2) (PARTITION p1 TABLESPACE tsb_1, PARTITION p2 TABLESPACE tsb_2, PARTITION p3 TABLESPACE tsb_3, PARTITION p4 TABLESPACE tsb_4,);
Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имею отношение «один к одному» с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же, как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов – Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
SQL> CREATE INDEX ticket_no_idx ON Ticket_sales(ticket_no) LOCAL TABLESPACE localidx_01;
Невидимые индексы
По умолчанию оптимизатор «видит» все индексы. Тем не менее, можно создать невидимый индекс, который оптимизатор не обнаруживает и не принимает во внимание при создании плана выполнения оператора. Невидимый индекс можно применять в качестве временного индекса для определенных операций или его тестирования перед тем, как сделать его «официальным». Вдобавок, иногда объявления индекса невидимым можно использовать в качестве альтернативы уничтожению индекса или объявлению его недоступным. Сделать индекс невидимым можно временно, чтобы протестировать эффект от его уничтожения.
База данных поддерживает невидимый индекс точно так же, как и нормальный (видимый) индекс. После объявления индекса невидимым, его и все прочие невидимые индексы можно сделать вновь видимым для оптимизатора, установив значение параметра optimizer_use_invisible_index равным TRUE на уровне сеанса или всей системы. Значением этого параметра по умолчанию является FALSE, а это означает, что оптимизатор по умолчанию не может использовать невидимые индексы.
Создание невидимого индекса.
Чтобы сделать индекс невидимым, к оператору CRETE INDEX нужно добавить конструкцию INVISIBLE.
С помощью команды ALTER INDEX можно превратить существующий индекс в невидимый.
ALTER INDEX test_idx INVISIBLE;
И обратная команда
ALTER INDEX test_idx VISIBLE;
Приведенный ниже запрос к представлению DBA_INDEXES показывает состояние видимости индекса:
Мониторинг использования индекса
Если вы сомневаетесь в использовании определенного индекса, можете попросить Oracle выполнить мониторинг его применения. Таким образом, если индекс окажется избыточным, его можно уничтожить и сэкономить место в хранилище, а также снизить накладные расходы на операции DML.
Опишем, что потребуется сделать для отслеживания индекса в базе данных. Предположим, что вы пытаетесь узнать, используется ли индекс p_key_sales в определенных запросах к таблице sales. Обеспечьте репрезентативный промежуток времени для оценки использования индекса. Для базы данных OLTP это промежуток может быть относительно коротким. Для хранилища данных может понадобится запустить тестовый мониторинг на несколько дней, чтобы точно проверить, как используется индекс.
Чтобы запустить мониторинг использования индекса, войдите в базу данный как владелец индекса p_keyPsales и запустите следующую команду:
SQL> ALTER INDEX p_key_sales MONITORING USAGE;
Теперь запустите какие-нибудь запросы к таблице sales. Завершите мониторинг, применив следующую команду:
SQL> ALTER INDEX p_key_sales NOMONITORING USAGE;
После этого можно запросить представление словаря данных V$OBJECT_USAGE для определения того, используется ли индекс p_key_sales.
Причина по которой нельзя узнать количество случаев использования индекса, связана с тем, что база данных выполняет мониторинг его использования только на фазе разбора (parsing); если бы разбор производился при каждом выполнении, пострадала бы производительность.
Обслуживание индексов
Данные индекса постоянно изменяются из-за DML-действий, связанных с его таблицей. Индексы часто становятся слишком большими, если происходит много удалений сток, потому что пространство, занятое удаленными значениями, автоматически повторно индексом не используется. За счет периодического применения команды REBUILD можно реорганизовать индексы и сделать их более компактными, а потому и более эффективными. Команда REBUILD также служит для изменения параметров хранения, которые устанавливаются во время начального создания индекса.
ALTER INDEX sales_idx REBUILD;
Перестройка индексов лучше уничтожения и воссоздания неудачного индекса, потому что при этой операции пользователи продолжают иметь доступ к индексу в процессе его перестройки. Однако индексы в процессе перестройки накладывают много ограничений на действия пользователя. Еще более эффективный способ перестройки индексов состоит в том, чтобы сделать это в оперативном (online) режиме, как показано в следующем примере. Во время оперативной перестройки индекса разрешено применение всех операций DML, но не операций DDL.
ALTER INDEX sales_idx REBUILD ONLINE;
Оперативную перестройку индекса можно ускорить за счет добавления к показанному выше оператору ALTER INDEX конструкции ONLINE NOLOGGING. После добавления этой конструкции база данных не будет генерировать данные повторного выполнения для операции перестройки индекса.
Структура B-дерева имеет следующие преимущества:
B-дерево автоматически поддерживается в сбалансированном виде.
Все блоки-листья в дереве расположены на одном уровне, следовательно, поиск любой записи в индексе занимает примерно одно и то же время.
B-деревья обеспечивают хорошую производительность для широкого спектра запросов, включая поиск по конкретному значению и поиск в открытом и закрытом интервалах (благодаря ссылкам между блоками-листьями).
Модификация данных таблицы выполняется достаточно эффективно, т.к. в блоках индекса обычно есть свободное место для размещения новых значений, а полная перестройка дерева выполняется достаточно редко.
Производительность B-дерева одинаково хороша для маленьких и больших таблиц, и не меняется существенно при росте таблицы.

Использование индексов
Синтаксис команды create index следующий:
create index <имя_индекса>
on <имя_таблицы>(<поле1> [, <поле2>,...]) [<параметры>];
Имя индекса должно быть уникальным среди имён объектов БД. Если индекс составной, то входящие в него поля перечисляются через
запятую. Необязательные <параметры> зависят от используемой СУБД. Например, в Oracle с помощью следующей команды можно создать составной индекс для таблицы СОТРУДНИКИ (EMP) по полямФамилия (fam) иИмя (name):
create index ind_emp_name on emp(fam, name) TABLESPACE MY_INDEXES;
Индексы и таблицы желательно создавать в разных табличных пространствах.

Использование индексов
Выбор столбцов для индекса определяется следующими соображениями:
В первую очередь выбираются столбцы, которые часто встречаются в условиях поиска.
Стоит индексировать столбцы, которые используются для соединения таблиц или являются внешними ключами. В последнем случае наличие индекса позволяет обновлять строки подчинённой таблицы без блокировки основной таблицы, когда происходит интенсивное конкурентное обновление связанных между собою таблиц.
Нецелесообразно индексировать столбцы с низкой селективностью. Исключения для низкой селективности составляют случаи, при которых выборка чаще производится по редко встречающимся значениям.
Не индексируются столбцы, которые часто обновляются, т.к. команды обновления ведут к потере времени на обновление индекса.
Не индексируются столбцы, которые часто используются как аргументы выражений или функций: как правило, это не позволяет использовать индекс.

Использование индексов
В некоторых случаях использование составного индекса предпочтительнее, чем одиночного, а именно:
Если в запросах часто используются только столбцы, участвующие в индексе, система может вообще не обращаться к таблице для поиска данных.
Несколько столбцов с низкой селективностью в комбинации друг с другом могут дать гораздо более высокую селективность.
Обращение к составному индексу возможно только в том случае, если в условиях выбора участвуют столбцы, представляющие собой лидирующую часть составного индекса. Если индекс, например, включает поля (X, Y, Z), то обращение к индексу будет происходить в тех случаях, когда в условии запроса участвуют поля XYZ, XY или X, причём именно в таком порядке.

Использование индексов
Вопрос. Будет ли система пользоваться индексом при выполнении следующих запросов:
1) SELECT * FROM emp;
2) SELECT * FROM emp
WHERE name = "Даль";
3) SELECT * FROM emp
WHERE sex = "ж";
4) SELECT depno, count(*) FROM emp GROUP BY depno;
5) SELECT * FROM emp e, child c WHERE e.tabno=c.tabno;
Необходимое условие использования индекса: в запросе есть условие на значение индексируемого поля.
Достаточное условие использования индекса: запрос по индексу выполняется быстрее, чем без индекса (повышение эффективности).

Индекс имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4-5% данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного колюча Oracle автоматически создаст индекс по этому столбцу.
Индексируйте столбцы, участвующие в многотабличных операциях соединения.
Индексируйте столбцы, которые часто используются в конструкциях WHERE.

Использование индексов в Oracle
Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
Столбцы, стоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
Индексируйте таблицы в которых мало строк имеют одинаковые значения.
Сохраняйте количество индексов небольшим.
Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец в котором количество строк с одинаковым значением минимально.

Битовые индексы Oracle
Битовые индексы (BITMAP) используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью (число уникальных записей в таблице мало) при большом размере таблицы.
Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных. Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев.

Битовые индексы Oracle
Для создания битового индекса используется оператор^ CREATE BITMAP INDEX day_ind ON tab(day) TABLESPACE MY_INDEXES;

Индексы Oracle с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
CREATE INDEX reverse_idx ON employee(emp_id) REVERSE;
При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.