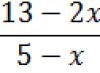Énoncé du problème
Soit la fonction donnée f(x) Rn
Requis f(x) X = Rn

Stratégie de recherche
xk
} , k = 0,1,...,
tel que ![]() , k = 0,1,...
. Points de séquence ( xk
) sont calculés selon la règle
, k = 0,1,...
. Points de séquence ( xk
) sont calculés selon la règle
où est le point x0 défini par l'utilisateur ; taille de pas merci déterminé pour chaque valeur k de l'état
Le problème (3) peut être résolu en utilisant la condition minimale nécessaire suivie de la vérification de la condition minimale suffisante. Ce chemin peut être utilisé soit pour une fonction assez simple à minimiser, soit pour une approximation préliminaire d'une fonction assez complexe ![]() polynôme P(tk)
(généralement du deuxième ou du troisième degré), puis la condition est remplacée par la condition, et la condition par la condition
polynôme P(tk)
(généralement du deuxième ou du troisième degré), puis la condition est remplacée par la condition, et la condition par la condition 
Séquençage (xk)
se termine au point xk
, pour quoi , où ε
- un petit nombre positif donné, ou k ≥M
, Où M
- le nombre limite d'itérations, soit avec deux exécutions simultanées de deux inégalités ![]() ,
, ![]() Où ε 2
- petit nombre positif. La question est de savoir si un point peut xk
être considéré comme l'approximation trouvée du point minimum local souhaité x*
, est résolu grâce à des recherches supplémentaires.
Où ε 2
- petit nombre positif. La question est de savoir si un point peut xk
être considéré comme l'approximation trouvée du point minimum local souhaité x*
, est résolu grâce à des recherches supplémentaires.
Interprétation géométrique de la méthode pour n=2 sur la fig. 4.

Méthode de descente de coordonnées
Énoncé du problème
Soit la fonction donnée f(x) , délimité en dessous sur l'ensemble Rn et ayant des dérivées partielles continues en tous ses points.
f(x) sur l'ensemble des solutions réalisables X = Rn , c'est-à-dire trouver un point tel que

Stratégie de recherche
La stratégie pour résoudre le problème consiste à construire une séquence de points ( xk
} , k = 0,1,...,
tel que ![]() , k = 0,1,...
. Points de séquence ( xk
) sont calculés sur des cycles conformément à la règle
, k = 0,1,...
. Points de séquence ( xk
) sont calculés sur des cycles conformément à la règle
 (4)
(4)
Où j - numéro du cycle de calcul ; j = 0,1,2,...; k - numéro d'itération à l'intérieur de la boucle, k = 0,1,... ,n - 1; e k +1 , k = 0,l,...,n - 1 -vecteur unitaire, (k+1) -ème projection dont est égale à 1 ; point x00 défini par l'utilisateur, taille de pas merci est sélectionné à partir de la condition
 ou
ou  .
.
Si la condition sélectionnée à l'heure actuelle merci
n'est pas remplie, l'étape est divisée par deux et la période  est calculé à nouveau. Il est facile de voir que pour un j fixe, en une itération de nombre k
une seule projection du point change xjk
, ayant un numéro k+1
, et pendant tout le cycle avec numéro j
, c'est-à-dire à partir de k = 0
et se terminant k = n-1
, toutes les n projections du point changent j0
. Après ce point xjn
le numéro est attribué xj + 1,0
, et il est pris comme point de départ pour les calculs dans j+1
faire du vélo. Le calcul se termine au point xjk
lorsqu'au moins un des trois critères de fin de comptage est rempli :
est calculé à nouveau. Il est facile de voir que pour un j fixe, en une itération de nombre k
une seule projection du point change xjk
, ayant un numéro k+1
, et pendant tout le cycle avec numéro j
, c'est-à-dire à partir de k = 0
et se terminant k = n-1
, toutes les n projections du point changent j0
. Après ce point xjn
le numéro est attribué xj + 1,0
, et il est pris comme point de départ pour les calculs dans j+1
faire du vélo. Le calcul se termine au point xjk
lorsqu'au moins un des trois critères de fin de comptage est rempli : ![]() , ou , ou double exécution des inégalités.
, ou , ou double exécution des inégalités.
Les points obtenus à la suite de calculs peuvent être écrits comme éléments d'une séquence (xl), Où l=n*j+k - numéro de série du point,
L'interprétation géométrique de la méthode pour n = 2 est présentée sur la Fig. 5.

4. Méthode Frank-Wolfe .
Supposons que nous devions trouver la valeur maximale d'une fonction concave

Sous conditions

Un trait caractéristique de ce problème est que son système de contraintes ne contient que des inégalités linéaires. Cette fonctionnalité constitue la base du remplacement de la fonction objectif non linéaire par une fonction linéaire à proximité du point étudié, grâce à quoi la solution du problème d'origine est réduite à la solution séquentielle de problèmes de programmation linéaire.
Le processus de recherche d'une solution au problème commence par l'identification d'un point appartenant à la région des solutions réalisables au problème.
270
datchas Que ce soit le point X(k)
alors à ce stade le gradient de la fonction (57) est calculé
Et construisons une fonction linéaire

Trouvez ensuite la valeur maximale de cette fonction sous les restrictions (58) et (59). Laissez la solution à ce problème être déterminée par le point Z(k)
. Ensuite, les coordonnées du point sont considérées comme une nouvelle solution réalisable au problème d'origine. X(k+1)
:
Où λk - un certain nombre appelé pas de calcul et compris entre zéro et un (0<λk < 1). Это число λk pris arbitrairement ou déterminé
de sorte que la valeur de la fonction au point X (k +1) f(X (k +1)) , selon λk , était le maximum. Pour ce faire, vous devez trouver une solution à l’équation et choisir sa plus petite racine. Si sa valeur est supérieure à un, alors nous devrions mettre λk=1 . Après avoir déterminé le nombre λk trouver les coordonnées d'un point X(k+1) calculer la valeur de la fonction objectif et déterminer la nécessité de se déplacer vers un nouveau point X(k+2) . S'il y a un tel besoin, calculez au point X(k+1) gradient de la fonction objectif, accédez au problème de programmation linéaire correspondant et trouvez sa solution. Déterminez les coordonnées du point et X(k+2) et étudier la nécessité de calculs supplémentaires. Après un nombre fini d’étapes, une solution au problème initial est obtenue avec la précision requise.
Ainsi, le processus de recherche d'une solution au problème (57) - (59) à l'aide de la méthode Frank-Wolfe comprend les étapes suivantes:
1. Déterminez la solution réalisable initiale au problème.
2. Trouvez le gradient de la fonction (57) au point d'une solution admissible.
3. Construisez la fonction (60) et trouvez sa valeur maximale dans les conditions (58) et (59).
4. Déterminez l'étape de calcul.
5. À l'aide des formules (61), les composantes d'une nouvelle solution réalisable sont trouvées.
6. Vérifiez la nécessité de passer à la prochaine solution réalisable. Si nécessaire, passez à l'étape 2, sinon une solution acceptable au problème initial est trouvée.
Méthode de fonctions de pénalité.
Considérons le problème de la détermination de la valeur maximale de la fonction concave
f (x 1, x 2, .... x n) dans des conditions g je (x 1, x 2, .... x n) ≤ b je (i=l, m) , xj ≥ 0 (j=1, n) , Où g je (x 1, x 2, .... x n) - les fonctions convexes.
Au lieu de résoudre ce problème directement, trouvez la valeur maximale de la fonction F(x 1, x 2, ...., x n)= f(x 1, x 2, ...., x n) +H(x 1, x 2, ...., xn) qui est la somme de la fonction objectif du problème et d'une fonction
H(x 1, x 2, ...., xn), défini par un système de restrictions et appelé fonction de pénalité. La fonction de pénalité peut être construite de différentes manières. Cependant, le plus souvent, cela ressemble à
UN un je > 0
- quelques nombres constants représentant des coefficients de pondération.
À l’aide de la fonction de pénalité, ils se déplacent séquentiellement d’un point à un autre jusqu’à obtenir une solution acceptable. Dans ce cas, les coordonnées du point suivant sont trouvées à l'aide de la formule
De la dernière relation, il s'ensuit que si le point précédent se situe dans la région des solutions réalisables au problème d'origine, alors le deuxième terme entre crochets est égal à zéro et la transition vers le point suivant n'est déterminée que par la pente de l'objectif. fonction. Si le point spécifié n'appartient pas à la région des solutions admissibles, alors grâce à ce terme dans les itérations suivantes, un retour à la région des solutions admissibles est obtenu
décisions. En même temps, moins un je
, plus une solution acceptable est trouvée rapidement, mais la précision de sa détermination diminue. Par conséquent, le processus itératif démarre généralement à des valeurs relativement faibles. un je
et, en continuant, ces valeurs augmentent progressivement.
Ainsi, le processus de recherche d'une solution à un problème de programmation convexe à l'aide de la méthode de la fonction de pénalité comprend les étapes suivantes :
1. Déterminez la solution réalisable initiale.
2. Sélectionnez l'étape de calcul.
3. Trouver, pour toutes les variables, les dérivées partielles de la fonction objectif et des fonctions qui déterminent l'éventail de solutions réalisables au problème.
4. À l'aide de la formule (72), les coordonnées du point qui détermine une nouvelle solution possible au problème sont trouvées.
5. Vérifiez si les coordonnées du point trouvé satisfont au système de contraintes du problème. Si ce n’est pas le cas, passez à l’étape suivante. Si les coordonnées du point trouvé déterminent une solution admissible au problème, alors la nécessité de passer à la solution admissible suivante est étudiée. Si nécessaire, passez à l'étape 2, sinon une solution acceptable au problème initial a été trouvée.
6. Définissez les valeurs des coefficients de pondération et passez à l'étape 4.
Méthode Arrow-Hurwitz.
Lors de la recherche de solutions aux problèmes de programmation non linéaire à l'aide de la méthode de la fonction de pénalité, nous avons choisi les valeurs un je , arbitrairement, ce qui a conduit à des fluctuations importantes de la distance entre les points déterminés et la région des solutions réalisables. Cet inconvénient est éliminé lors de la résolution du problème par la méthode Arrow-Hurwitz, selon laquelle à l'étape suivante les nombres un je (k) calculé par la formule
Comme valeurs initiales un je (0) prenez des nombres arbitraires non négatifs.
EXEMPLE DE SOLUTION
Exemple 1.
Trouver le minimum local d'une fonction
Définir un point xk
1. Posons .
2. Mettons k = 0 .
3 0 . Calculons
4 0 . Calculons ![]() . Passons à l'étape 5.
. Passons à l'étape 5.
5 0 . Vérifions l'état ![]() . Passons à l'étape 6.
. Passons à l'étape 6.
6 0 . Mettons t0 = 0,5 .
7 0 . Calculons
8 0 . Comparons ![]() . Nous avons
. Nous avons ![]() . Conclusion : condition pour k = 0
n'est pas exécuté. Mettons t0 = 0,25
, passez à la répétition des étapes 7 et 8.
. Conclusion : condition pour k = 0
n'est pas exécuté. Mettons t0 = 0,25
, passez à la répétition des étapes 7 et 8.
7 01. Calculons.
8 01. Comparons f (x 1) et f (x 0) . Conclusion: f (x 1)< f (x 0) . Passons à l'étape 9.
9 0 . Calculons
Conclusion : nous croyons k =1 et passez à l'étape 3.
3 1. Calculons
4 1. Calculons ![]() . Passons à l'étape 5.
. Passons à l'étape 5.
5 1. Vérifions l'état k ≥ M : k = 1< 10 = M . Passons à l'étape 6.
6 1. Mettons t 1 = 0,25.
7 1. Calculons
![]()
8 1. Comparons f (x 2) avec f (x 1) . Conclusion: f (x 2)< f (х 1). Passons à l'étape 9.
9 1. Calculons
Conclusion : nous croyons k = 2 et passez à l'étape 3.
3 2. Calculons
4 2 . Calculons. Passons à l'étape 5.
5 2. Vérifions l'état k ≥M : k = 2< 10 = М , passez à l'étape 6.
6 2. Mettons t 2 =0,25 .
7 2. Calculons
![]()
8 2. Comparons f (x 3) Et f (x 2) . Conclusion: f (x 3)< f (х 2) .Passez à l'étape 9.
9 2. Calculons ![]()
Conclusion : nous croyons k = 3 et passez à l'étape 3.
3 3 . Calculons
4 3 . Calculons. Passons à l'étape 5.
5 3. Vérifions l'état k ≥M : k = 3<10 = М , passez à l'étape 6.
6 3. Mettons t 3 = 0,25.
7 3. Calculons
![]()
8 3. Comparons f (x 4) Et f (x 3) : f (x 4)< f (х 3) .
9 3. Calculons ![]()
Les conditions sont remplies lorsque k = 2,3 . Calcul
fini. Point trouvé
Sur la fig. Les 3 points résultants sont reliés par une ligne pointillée.

II. Analyse des points x4 .
Fonction ![]() est deux fois différentiable, nous vérifierons donc les conditions suffisantes pour le minimum au point x4
. Pour ce faire, analysons la matrice hessienne.
est deux fois différentiable, nous vérifierons donc les conditions suffisantes pour le minimum au point x4
. Pour ce faire, analysons la matrice hessienne.
La matrice est constante et définie positive (c'est-à-dire . H > 0
) puisque ses deux mineurs angulaires sont positifs. Par conséquent, le point ![]() est l'approximation trouvée du point minimum local, et la valeur
est l'approximation trouvée du point minimum local, et la valeur ![]() est l'approximation trouvée de la valeur f(x*) =0
. Notez que la condition H > 0
, il existe en même temps une condition de stricte convexité de la fonction
est l'approximation trouvée de la valeur f(x*) =0
. Notez que la condition H > 0
, il existe en même temps une condition de stricte convexité de la fonction ![]() . Par conséquent, on trouve des approximations du point minimum global f(x)
et sa valeur minimale à R2
. ■
. Par conséquent, on trouve des approximations du point minimum global f(x)
et sa valeur minimale à R2
. ■
Exemple 2
Trouver le minimum local d'une fonction
I. Définition d'un point xk, dans lequel au moins un des critères pour effectuer les calculs est rempli.
1. Posons .
Trouvons le gradient de la fonction en un point arbitraire
2. Mettons k = 0 .
3 0 . Calculons
4 0 . Calculons ![]() . Passons à l'étape 5.
. Passons à l'étape 5.
5 0 . Vérifions l'état ![]() . Passons à l'étape 6.
. Passons à l'étape 6.
6° Le point suivant est trouvé par la formule
Remplaçons les expressions obtenues pour les coordonnées dans
Trouvons le minimum de la fonction f(t0) Par t 0 en utilisant les conditions nécessaires pour un extremum inconditionnel :
![]()
D'ici t0 =0,24
. Parce que  , la valeur de pas trouvée fournit le minimum de la fonction f(t0)
Par t 0
.
, la valeur de pas trouvée fournit le minimum de la fonction f(t0)
Par t 0
.

Définissons ![]()
7 0 . Nous trouverons
8°. Calculons
![]()
![]()
Conclusion : nous croyons k = 1 et passez à l'étape 3.
3 1. Calculons
4 1. Calculons ![]()
5 1. Vérifions l'état k ≥ 1 : k = 1< 10 = М.
6 1. Définissons
7 1. Nous trouverons ![]() :
:
8 1. Calculons
Nous croyons k = 2 et passez à l'étape 3.
3 2. Calculons
4 2 . Calculons
5 2. Vérifions l'état k ≥ M : k = 2< 10 = M .
6 2. Définissons
7 2. Nous trouverons ![]()
8 2. Calculons
Nous croyons k =3 et passez à l'étape 3.
3 3 . Calculons
4 3 . Calculons.
Le calcul est terminé. Point trouvé
II. Analyse des points x3 .
Dans l'exemple 1.1 (Chapitre 2 §1) il a été montré que la fonction f(x) est strictement convexe et, par conséquent, aux points 3 est l'approximation trouvée du point minimum global X* .
Exemple 3.
Trouver le minimum local d'une fonction
![]()
I. Définition d'un point xjk , dans lequel au moins un des critères pour effectuer les calculs est rempli.
1. Posons
Trouvons le gradient de la fonction en un point arbitraire ![]()
2. Posons j = 0.
3 0 . Vérifions si la condition est remplie
4 0 . Mettons k = 0.
5 0 . Vérifions si la condition est remplie
6 0 . Calculons
7 0 . Vérifions l'état ![]()
8 0 . Mettons
9 0 . Calculons ![]() , Où
, Où
10 0 . Vérifions l'état
Conclusion : on suppose et on passe à l'étape 9.
9 01. Calculons x01 par étapes
10 01. Vérifions l'état ![]()
11 0 . Vérifions les conditions
Nous croyons k =1 et passez à l'étape 5.
5 1. Vérifions l'état
6 1. Calculons
7 1. Vérifions l'état
8 1. Mettons
9 1. Calculons
10 1. Vérifions l'état ![]() :
:
11 1. Vérifions les conditions
Nous croyons k = 2 , passez à l'étape 5.
5 2. Vérifions l'état. C'est parti, passez à l'étape 3.
3 1. Vérifions l'état
4 1. Mettons k = 0.
5 2. Vérifions l'état
6 2. Calculons
7 2. Vérifions l'état
8 2. Mettons
9 2. Calculons
10 2. Vérifions l'état ![]()
11 2. Vérifions les conditions
Nous croyons k =1 et passez à l'étape 5.
5 3. Vérifions l'état
6 3. Calculons
7 3. Vérifions les conditions
8 3. Mettons
9 3. Calculons
10 3. Vérifions l'état ![]()
11 3. Vérifions les conditions
Mettons k = 2 et passez à l'étape 5.
5 4 . Vérifions l'état ![]()
Nous croyons j = 2, x 20 = x 12 et passez à l'étape 3.
3 2. Vérifions l'état
4 2 . Mettons k =0 .
5 4 . Vérifions l'état
6 4. Calculons
7 4. Vérifions l'état
8 4 . Mettons
9 4. Calculons
10 4. Vérifions la condition et passons à l'étape 11.
11 4. Vérifions les conditions
Les conditions sont remplies en deux cycles consécutifs avec des chiffres j=2 Et j -1= 1 . Le calcul est terminé, le point a été trouvé
Sur la fig. Les 6 points résultants sont reliés par une ligne pointillée.
Dans la méthode de descente de coordonnées, nous descendons le long d'une ligne brisée constituée de segments droits parallèles aux axes de coordonnées.
II. Analyse du point x21.
Dans l'exemple 1.1, il a été montré que la fonction f(x)
est strictement convexe, a un minimum unique et donc un point ![]() est l'approximation trouvée du point minimum global.
est l'approximation trouvée du point minimum global.

Dans toutes les méthodes de gradient évoquées ci-dessus, la séquence de points (xk) converge vers le point stationnaire de la fonction f(x) avec des propositions assez générales concernant les propriétés de cette fonction. En particulier, le théorème est vrai :
Théorème. Si la fonction f(x) est bornée en dessous, son gradient satisfait la condition de Lipschitz () et le choix de valeur tn produit par l'une des méthodes décrites ci-dessus, alors quel que soit le point de départ x0 :
![]() à .
à .
Dans la mise en œuvre pratique du programme
![]() k =1, 2, … n.
k =1, 2, … n.
les itérations s'arrêtent si pour tout je, je = 1, 2, ..., n , des conditions comme
 ,
,
où est un certain nombre caractérisant l'exactitude de la recherche du minimum.
Dans les conditions du théorème, la méthode du gradient assure la convergence dans la fonction ou vers la borne inférieure exacte (si la fonction f(x) n'a pas de minimum ; riz. 7), ou à la valeur de la fonction en un point stationnaire, qui est la limite de la séquence (xk). Il n'est pas difficile de trouver des exemples lorsqu'une selle est réalisée à ce stade, et pas un minimum. En pratique, les méthodes de descente de gradient contournent en toute confiance les points selle et trouvent les minima de la fonction objectif (dans le cas général, locaux).

CONCLUSION
Des exemples de méthodes d'optimisation de gradient sans contrainte ont été discutés ci-dessus. À la suite des travaux effectués, les conclusions suivantes peuvent être tirées :
1. Les problèmes plus ou moins complexes de recherche d'un extremum en présence de restrictions nécessitent des approches et des méthodes particulières.
2. De nombreux algorithmes pour résoudre des problèmes contraints incluent la minimisation sans contrainte comme étape.
3. Les différentes méthodes de descente diffèrent les unes des autres par la manière dont elles sélectionnent la direction de descente et la longueur de la marche dans cette direction.
4. Il n'existe pas encore de théorie qui prendrait en compte les caractéristiques des fonctions qui décrivent la formulation du problème. La préférence doit être donnée aux méthodes plus faciles à gérer dans le processus de résolution d'un problème.
Les vrais problèmes d’optimisation appliquée sont très complexes. Les méthodes d'optimisation modernes ne permettent pas toujours de résoudre des problèmes réels sans aide humaine.
RÉFÉRENCES
1. Kosoroukov O.A. Recherche opérationnelle : un manuel. 2003
2. Pantleev A.V. Méthodes d'optimisation en exemples et problèmes : manuel. Avantage. 2005
3. Chichkine E.V. Recherche opérationnelle : manuel. 2006
4. Akulich I.L. Programmation mathématique en exemples et problèmes. 1986
5. Ventzel E.S. Recherche opérationnelle. 1980
6. Ventzel E.S., Ovcharov L.A. Théorie des probabilités et ses applications techniques. 1988
©2015-2019site
Tous les droits appartiennent à leurs auteurs. Ce site ne revendique pas la paternité, mais propose une utilisation gratuite.
Date de création de la page : 2017-07-02
Annotation: Cette conférence couvre largement des méthodes d'optimisation multiparamétriques telles que la méthode de descente la plus raide et la méthode Davidon – Fletcher – Powell. De plus, une analyse comparative des méthodes ci-dessus est réalisée afin de déterminer la plus efficace, leurs avantages et inconvénients sont identifiés ; et considère également des problèmes d'optimisation multidimensionnels, tels que la méthode des ravins et la méthode multiextrémale.
1. Méthode de descente la plus raide
L'essence de cette méthode est qu'en utilisant la méthode mentionnée précédemment méthode de descente de coordonnées une recherche est effectuée à partir d'un point donné dans une direction parallèle à l'un des axes jusqu'au point minimum dans cette direction. La recherche s'effectue alors dans une direction parallèle à l'autre axe, et ainsi de suite. Les directions sont bien entendu fixes. Il semble raisonnable d'essayer de modifier cette méthode pour qu'à chaque étape la recherche du point minimum s'effectue dans la « meilleure » direction. On ne sait pas quelle direction est la « meilleure », mais on sait que direction du dégradé est la direction de l'augmentation la plus rapide de la fonction. Par conséquent, la direction opposée est la direction de la diminution la plus rapide de la fonction. Cette propriété peut être justifiée comme suit.
Supposons que nous nous déplacions du point x au point suivant x + hd, où d est une certaine direction et h est un pas d'une certaine longueur. Par conséquent, le mouvement s'effectue du point (x 1, x 2, ..., x n) au point (x 1 + zx 1, x 2 + zx 2, ..., x n + zx n), Où
Le changement des valeurs de fonction est déterminé par les relations
| (1.3) |
Jusqu'au premier ordre zx i , les dérivées partielles étant calculées au point x . Comment choisir les directions d i qui satisfont à l'équation (1.2) afin d'obtenir la plus grande valeur de changement dans la fonction df ? C’est là que se pose un problème de maximisation avec une contrainte. Appliquons la méthode des multiplicateurs de Lagrange, à l'aide de laquelle on détermine la fonction
La valeur df satisfaisant la contrainte (1.2) atteint son maximum lorsque la fonction
Atteint le maximum. Son dérivé
Ainsi,
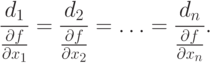 |
(1.6) |
Alors di ~ df/dx i et la direction d est parallèle à la direction V/(x) au point x.
Ainsi, plus forte augmentation locale la fonction pour un petit pas donné h se produit lorsque d est la direction de Vf(x) ou g(x) . Par conséquent, la direction de la descente la plus raide est la direction
Sous une forme plus simple, l’équation (1.3) peut s’écrire comme suit :
Où est l'angle entre les vecteurs Vf(x) et dx. Pour une valeur donnée de dx, on minimise df en choisissant que la direction de dx coïncide avec la direction de -Vf(x) .
Commentaire. Direction du dégradé perpendiculaire à n’importe quel point d’une ligne de niveau constant, puisque le long de cette ligne la fonction est constante. Ainsi, si (d 1, d 2, ..., d n) est un petit pas le long de la ligne de niveau, alors
Et donc
 |
(1.8) |
Le gradient de la fonction différentiable f(x) au point X appelé n vecteur dimensionnel f(x) , dont les composantes sont des dérivées partielles de la fonction f(x), calculé au point X, c'est-à-dire
f"(x ) = (df(x)/dh 1 , …, df(x)/dx n) T .
Ce vecteur est perpendiculaire au plan passant par le point X, et tangent à la surface plane de la fonction f(x), passant par un point X.En chaque point d’une telle surface la fonction f(x) prend la même valeur. En assimilant la fonction à différentes valeurs constantes C 0 , C 1 , ..., on obtient une série de surfaces caractérisant sa topologie (Fig. 2.8).
Riz. 2.8. PenteLe vecteur gradient est dirigé vers l'augmentation la plus rapide de la fonction en un point donné. Vecteur opposé au dégradé (-f'(x)) , appelé anti-dégradé et est orienté vers la diminution la plus rapide de la fonction. Au point minimum, le gradient de la fonction est nul. Les méthodes du premier ordre, également appelées méthodes de gradient et de minimisation, sont basées sur les propriétés des gradients. L'utilisation de ces méthodes dans le cas général permet de déterminer le point minimum local d'une fonction.
Évidemment, s'il n'y a pas d'informations supplémentaires, alors dès le point de départ X il est raisonnable d'aller au point X, se trouvant dans la direction de l'antigradient - la diminution la plus rapide de la fonction. Choisir comme direction de descente[k r ] anti-dégradé - f'(x ) [k] X[k au point
], on obtient un processus itératif de la forme X[ 1] = k+[k]-x f'(x ) , a k f"(x > 0; k=0, 1, 2, ...
et k
Sous forme de coordonnées, ce processus s'écrit comme suit : k+1]=x je [[k] - x jef(x f'(x ) un k
/x je n; k= 0, 1, 2,...
je = 1, ..., k+[k Comme critère d'arrêt du processus itératif, soit la réalisation de la condition de petit incrément de l'argument || +l][k] || <= e , либо выполнение условия малости градиента
|| -x[k f'(x ) || <= g ,
+l]
Ici, e et g reçoivent de petites quantités. a k f"(x.
Un critère combiné est également possible, consistant en la réalisation simultanée des conditions spécifiées. Les méthodes de dégradé diffèrent les unes des autres dans la manière dont elles choisissent la taille du pas a k f"(x Dans la méthode à pas constant, une certaine valeur de pas constant est sélectionnée pour toutes les itérations. Un tout petit pas
garantira que la fonction diminue, c'est-à-dire que l'inégalité k+1]) = f(x f(x[ [k] – f'(x )) < f(x f'(x ) .
Cependant, cela peut conduire à devoir effectuer un nombre inacceptable d’itérations pour atteindre le point minimum. En revanche, un pas trop grand peut provoquer une augmentation inattendue de la fonction ou conduire à des oscillations autour du point minimum (cyclage). En raison de la difficulté d'obtenir les informations nécessaires pour sélectionner la taille du pas, les méthodes à pas constants sont rarement utilisées dans la pratique.
Ceux à gradient sont plus économiques en termes de nombre d'itérations et de fiabilité méthodes à pas variables, lorsque, en fonction des résultats des calculs, la taille du pas change d'une manière ou d'une autre. Considérons les variantes de telles méthodes utilisées dans la pratique.
Lorsque vous utilisez la méthode de descente la plus raide à chaque itération, la taille du pas a k f"(x est sélectionné à partir de la condition minimale de la fonction f(x) dans le sens de la descente, c'est-à-dire
f(x[k]–ak f’(x[k]))
= f(x f'(x – unf"(x[k]))
.
Cette condition signifie que le mouvement le long de l'antigradient se produit aussi longtemps que la valeur de la fonction f(x) diminue. D'un point de vue mathématique, à chaque itération il faut résoudre le problème de minimisation unidimensionnelle selon UN fonctions
j (un) = f(x[k]-af"(x[k]))
.
L'algorithme de la méthode de descente la plus raide est le suivant.
1. Définissez les coordonnées du point de départ X.
2. Au point X[k], k = 0, 1, 2, ... calcule la valeur du dégradé -x[k]) .
3. La taille du pas est déterminée un k, par minimisation unidimensionnelle sur UN fonctions j (un) = f(x[k]-af"(x[k])).
4. Les coordonnées du point sont déterminées X[X[ 1]:
x je [ X[ 1]= xi[k]– a k f'i (x[k]), je = 1,..., p.
5. Les conditions d'arrêt du processus de stération sont vérifiées. S'ils sont remplis, les calculs s'arrêtent. Sinon, passez à l'étape 1.
Dans la méthode considérée, la direction du mouvement à partir du point X[k] touche la ligne de niveau au point k+[X[ 1] (Fig. 2.9). La trajectoire de descente est en zigzag, avec des liens en zigzag adjacents orthogonaux les uns aux autres. En effet, une étape un k est choisi en minimisant par UN fonctions ? (un) = f(x f'(x -af"(x[k])) . Condition nécessaire pour le minimum d'une fonction j d(a)/da = 0.
Après avoir calculé la dérivée d'une fonction complexe, on obtient la condition d'orthogonalité des vecteurs de directions de descente en points voisins : DJ[X[ 1]-x[k]) = 0.

Riz. 2.9. M Interprétation géométrique de la méthode de descente la plus raide Les méthodes de gradient convergent vers un minimum à un rythme élevé (taux de progression géométrique) pour les fonctions convexes lisses. De telles fonctions ont le plus grand et le moins

m valeurs propres de la matrice des dérivées secondes (matrice de Hesse) diffèrent peu les uns des autres, c'est-à-dire la matrice N(x) =1, …, n bien conditionné. Rappelons que les valeurs propres l i,

Cependant, en pratique, en règle générale, les fonctions minimisées ont des matrices de dérivées secondes mal conditionnées (t/m<< 1). Les valeurs de ces fonctions dans certaines directions changent beaucoup plus rapidement (parfois de plusieurs ordres de grandeur) que dans d'autres directions. Leurs surfaces planes dans le cas le plus simple sont fortement allongées (Fig. 2.10), et dans les cas plus complexes, elles se plient et ressemblent à des ravins. Les fonctions avec de telles propriétés sont appelées ravine. La direction de l'antigradient de ces fonctions (voir Fig. 2.10) s'écarte considérablement de la direction vers le point minimum, ce qui entraîne un ralentissement de la vitesse de convergence.

Le taux de convergence des méthodes de gradient dépend également de manière significative de la précision des calculs de gradient. La perte de précision, qui se produit généralement à proximité des points minimaux ou dans une situation de ravin, peut généralement perturber la convergence du processus de descente de gradient. X Pour les raisons ci-dessus, les méthodes de gradient sont souvent utilisées en combinaison avec d'autres méthodes plus efficaces au stade initial de la résolution d'un problème. Dans ce cas, le point
est loin du point minimum, et des pas en direction de l'antigradient permettent d'obtenir une diminution significative de la fonction.
Les méthodes de gradient discutées ci-dessus ne trouvent le point minimum d'une fonction dans le cas général que dans un nombre infini d'itérations. La méthode du gradient conjugué génère des directions de recherche plus cohérentes avec la géométrie de la fonction minimisée. Cela augmente considérablement la vitesse de leur convergence et permet, par exemple, de minimiser la fonction quadratique
f(x) = (x, Hx) + (b, x) + une avec une matrice définie positive symétrique N en un nombre fini d'étapes p,
égal au nombre de variables de fonction. n Toute fonction lisse située à proximité du point minimum peut être bien approchée par une fonction quadratique, c'est pourquoi les méthodes de gradient conjugué sont utilisées avec succès pour minimiser les fonctions non quadratiques. Dans ce cas, ils cessent d’être finis et deviennent itératifs. X Par définition, deux vecteur dimensionnel Et à appelé conjugué par rapport à la matrice conjugué H (ou, -conjugué), si le produit scalaire(x Eh bien) = 0. Ici N- matrice de taille définie positive symétrique n
X p.[k]) L’un des problèmes les plus importants des méthodes de gradient conjugué est celui de la construction efficace de directions. La méthode Fletcher-Reeves résout ce problème en transformant l'antigradient à chaque étape -f(x[k], conjugué-conjuguer avec les directions trouvées précédemment Choisir comme direction de descente, Choisir comme direction de descente, ..., Choisir comme direction de descente[k-1].
Considérons d'abord cette méthode en relation avec le problème de la minimisation d'une fonction quadratique. Choisir comme direction de descente[k Instructions
] est calculé à l'aide des formules : k] = --x[k]) p[ -f(x[k+bk-1 k>= 1;
-l], p = -’(ou) .
f k valeurs b -f(x[k], Choisir comme direction de descente[k-1 sont choisis pour que les directions conjugué-1] étaient :
(-f(x[k], -conjuguer[HP 1])= 0.
k-
![]() ,
,
En conséquence, pour la fonction quadratique
le processus itératif de minimisation a la forme k f'(x x[[k]=x[k],
Où Choisir comme direction de descente[k] - +ak kp HP direction de descente vers m pas; et k- taille du pas. Par UN Cette dernière est choisie parmi la condition minimale de la fonction
garantira que la fonction diminue, c'est-à-dire que l'inégalité k] + f(x)[k]) = f(x[k] + dans la direction du mouvement, c'est-à-dire suite à la résolution du problème de minimisation unidimensionnelle : [k]) .
un kr
![]()
ar
Pour une fonction quadratique X L'algorithme de la méthode du gradient conjugué de Fletcher-Reeves est le suivant. -f(x = --x) .
1. Au point HP calculé UN 2. Activé . m pas, en utilisant les formules ci-dessus, le pas est déterminé X[X[ 1].
k f(x[k+1]) et période -x[k+1]) .
3. Les valeurs sont calculées -x) Et X[k 4. Si = 0, alors pointez+1] est le point minimum de la fonction -f(x[k f(x).
Sinon, une nouvelle direction est déterminée N-+l] de la relation et le passage à l'itération suivante est effectué. Cette procédure trouvera le minimum d'une fonction quadratique en pas plus de mesures. Lors de la minimisation de fonctions non quadratiques, la méthode Fletcher-Reeves devient itérative à partir de finie. Dans ce cas, après X(p+ X[N- 1) la ème itération de la procédure 1 à 4 est répétée cycliquement avec remplacement
le processus itératif de minimisation a la forme k f'(x sur[k]=x[k],
] est calculé à l'aide des formules : k] +1] , et les calculs se terminent à , où est un nombre donné. Dans ce cas, la modification suivante de la méthode est utilisée :[k])+ =x HP 1 -f(x[k+bk-1 k>= 1;
= -f'(x k+);
garantira que la fonction diminue, c'est-à-dire que l'inégalité k] + b[k]) = f(x[k] p = -f'([k];
 .
.
un kp +ap Ici +ap je - de nombreux index := (0, n, 2 N- p, salaire, ...)
, c'est-à-dire que la méthode est mise à jour tous les X mesures. Choisir comme direction de descente = La signification géométrique de la méthode du gradient conjugué est la suivante (Fig. 2.11). A partir d'un point de départ donné la descente s'effectue dans le sens X-f"(x ). Au point X le vecteur gradient est déterminé Choisir comme direction de descente, f"(x ] anti-dégradé -) ). Depuis Choisir comme direction de descente est le point minimum de la fonction dans la direction Choisir comme direction de descente , conjugué Que Choisir comme direction de descente orthogonal au vecteur Choisir comme direction de descente. On trouve alors le vecteur

etc. N- p, salaire, ...)
Riz. 2.11 Trajectoire de descente dans la méthode du gradient conjugué Les méthodes de direction conjuguée sont parmi les plus efficaces pour résoudre les problèmes de minimisation. Il convient cependant de noter qu’ils sont sensibles aux erreurs qui surviennent lors du processus de comptage. Avec un grand nombre de variables, l'erreur peut tellement augmenter que le processus devra être répété même pour une fonction quadratique, c'est-à-dire le processus correspondant ne rentre pas toujours dans Objet de la prestation . Calculateur en ligne utilisé pour trouver(voir exemple). La solution est rédigée au format Word.Règles de saisie d'une fonction
DANS méthode de descente la plus raide un vecteur dont la direction est opposée à la direction du vecteur gradient de la fonction ▽f(x) est sélectionné comme direction de recherche. De l'analyse mathématique, on sait que le vecteur grad f(x)=▽f(x) caractérise la direction de l'augmentation la plus rapide de la fonction (voir gradient de la fonction). Par conséquent, le vecteur - grad f (X) = -▽f(X) est appelé anti-dégradé et c'est la direction de sa diminution la plus rapide. La relation de récurrence avec laquelle la méthode de descente la plus raide est mise en œuvre a la forme X k +1 =X k - λ k ▽f(x k), k = 0,1,...,
où λ k >0 est la taille du pas. En fonction du choix de la taille du pas, vous pouvez obtenir différentes options pour la méthode du dégradé. Si pendant le processus d'optimisation la taille du pas λ est fixe, alors la méthode est appelée méthode du gradient avec un pas discret. Le processus d'optimisation dans les premières itérations peut être considérablement accéléré si λ k est sélectionné à partir de la condition λ k = min f(X k + λS k) .
Pour déterminer λ k, n'importe quelle méthode d'optimisation unidimensionnelle est utilisée. Dans ce cas, la méthode est appelée méthode de descente la plus raide. En règle générale, dans le cas général, une étape ne suffit pas pour atteindre le minimum de la fonction ; le processus est répété jusqu'à ce que les calculs ultérieurs améliorent le résultat.
Si l'espace est très allongé dans certaines variables, alors un « ravin » se forme. La recherche peut ralentir et zigzaguer au fond du « ravin ». Parfois, une solution ne peut être obtenue dans un délai acceptable.
Un autre inconvénient de la méthode peut être le critère d'arrêt ||▽f(X k)||<ε k , так как этому условию удовлетворяет и седловая точка, а не только оптимум.
Exemple. À partir du point x k =(-2, 3), déterminez le point x k +1 en utilisant la méthode de descente la plus raide pour minimiser la fonction.
Comme direction de recherche, sélectionnez le vecteur de dégradé au point actuel 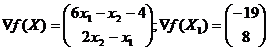
Vérifions le critère d'arrêt. Nous avons ![]()
Calculons la valeur de la fonction au point initial f(X 1) = 35. Faisons
avancer dans la direction antigradiente
Calculons la valeur de la fonction à un nouveau point
f(X 2) = 3(-2 + 19λ 1) 2 + (3-8λ 1) 2 - (-2 + 19λ 1)(3-8λ 1) - 4(-2 + 19λ 1)
Trouvons un pas tel que la fonction objectif atteigne un minimum dans cette direction. De la condition nécessaire à l'existence d'un extremum de la fonction
f'(X 2) = 6(-2 + 19λ 1) 19 + 2(3-8λ 1)(-8) – (73 - 304 λ 1) – 4*19
ou f'(X 2) = 2598 λ 1 – 425 = 0.
On obtient le pas λ 1 = 0,164
Terminer cette étape mènera au point ![]()
dans lequel la valeur du gradient ![]() , valeur de la fonction f(X 2) = 0,23. La précision n'est pas atteinte, à partir du moment où l'on fait un pas dans la direction de l'antigradient.
, valeur de la fonction f(X 2) = 0,23. La précision n'est pas atteinte, à partir du moment où l'on fait un pas dans la direction de l'antigradient.
f(X 2) = 3(1,116 – 1,008λ 1) 2 + (1,688-2,26λ 1) 2 - (1,116 – 1,008λ 1)(1,688-2,26λ 1) - 4(1,116 – 1,008λ 1)
f'(X 2) = 11,76 – 6,12λ 1 = 0
On obtient λ 1 = 0,52 ![]()
Figure 3. Interprétation géométrique de la méthode de descente la plus raide. A chaque étape, on choisit pour que l'itération suivante soit le point minimum de la fonction sur le rayon L.
Cette version de la méthode du gradient est basée sur le choix de l'étape à partir des considérations suivantes. A partir du point on se déplacera dans la direction de l'antigradient jusqu'à atteindre le minimum de la fonction f dans cette direction, c'est à dire sur le rayon :
Autrement dit, il est choisi pour que l'itération suivante soit le point minimum de la fonction f sur le rayon L (voir Fig. 3). Cette version de la méthode du gradient est appelée méthode de descente la plus raide. Notez au passage que dans cette méthode, les directions des marches adjacentes sont orthogonales.
La méthode de descente la plus raide nécessite de résoudre un problème d’optimisation unidimensionnel à chaque étape. La pratique montre que cette méthode nécessite souvent moins d'opérations que la méthode du gradient à pas constant.
Dans la situation générale, cependant, le taux de convergence théorique de la méthode de la descente la plus raide n'est pas supérieur au taux de convergence de la méthode du gradient avec un pas constant (optimal).
Exemples numériques
Méthode de descente de gradient à pas constant
Pour étudier la convergence de la méthode de descente de gradient à pas constant, la fonction a été choisie :
Des résultats obtenus, nous pouvons conclure que si l’écart est trop grand, la méthode diverge ; si l’écart est trop petit, elle converge lentement et la précision est moins bonne. Il faut choisir le pas le plus grand parmi ceux vers lesquels la méthode converge.
Méthode de dégradé avec division par étapes
Pour étudier la convergence de la méthode de descente de gradient avec division par échelons (2), la fonction a été choisie :
La première approximation est le point (10,10).
Critère d'arrêt utilisé :
Les résultats de l'expérience sont présentés dans le tableau :
|
Signification paramètre |
Valeur du paramètre |
Valeur du paramètre |
Précision atteinte |
Nombre d'itérations |
A partir des résultats obtenus, nous pouvons conclure sur le choix optimal des paramètres : , bien que la méthode soit peu sensible au choix des paramètres.
Méthode de descente la plus raide
Pour étudier la convergence de la méthode de descente la plus raide, la fonction suivante a été choisie :
La première approximation est le point (10,10). Critère d'arrêt utilisé :
Pour résoudre les problèmes d’optimisation unidimensionnels, la méthode du nombre d’or a été utilisée.
La méthode a atteint une précision de 6e-8 en 9 itérations.
De cela, nous pouvons conclure que la méthode de descente la plus raide converge plus rapidement que la méthode de gradient à pas divisé et la méthode de descente à gradient à pas constant.
L’inconvénient de la méthode de descente la plus raide est qu’elle nécessite de résoudre un problème d’optimisation unidimensionnel.
Lors de la programmation des méthodes de descente de gradient, vous devez être prudent lors du choix des paramètres, à savoir
- · Méthode de descente de gradient avec un pas constant : le pas doit être choisi inférieur à 0,01, sinon la méthode diverge (la méthode peut diverger même avec un tel pas, selon la fonction étudiée).
- · La méthode du gradient avec division par échelons est peu sensible au choix des paramètres. Une des options de sélection des paramètres :
- · Méthode de descente la plus raide : la méthode du nombre d'or (le cas échéant) peut être utilisée comme méthode d'optimisation unidimensionnelle.
La méthode du gradient conjugué est une méthode itérative d'optimisation sans contrainte dans un espace multidimensionnel. Le principal avantage de la méthode est qu’elle résout un problème d’optimisation quadratique en un nombre fini d’étapes. Par conséquent, la méthode du gradient conjugué pour optimiser la fonctionnelle quadratique est d'abord décrite, des formules itératives sont dérivées et des estimations du taux de convergence sont données. Après cela, nous montrons comment la méthode adjointe est généralisée pour optimiser une fonctionnelle arbitraire, diverses variantes de la méthode sont considérées et la convergence est discutée.
Énoncé du problème d'optimisation
Soit un ensemble donné et une fonction objectif définie sur cet ensemble. Le problème d’optimisation consiste à trouver la borne supérieure ou inférieure exacte de la fonction objectif sur l’ensemble. L'ensemble des points auxquels la limite inférieure de la fonction objectif est atteinte est désigné.
Si, alors le problème d’optimisation est dit sans contrainte. Si, alors le problème d’optimisation est appelé contraint.
Méthode du gradient conjugué pour la fonctionnelle quadratique
Énoncé de la méthode
Considérez le problème d'optimisation suivant :
Voici une matrice symétrique de taille définie positive. Ce problème d'optimisation est appelé quadratique. Noter que. La condition pour un extremum d'une fonction est équivalente au système. La fonction atteint sa limite inférieure en un seul point défini par l'équation. Ainsi, ce problème d'optimisation se réduit à résoudre un système d'équations linéaires. L'idée de la méthode du gradient conjugué est la suivante : Soit la base de. Ensuite, pour n'importe quel point, le vecteur est développé dans la base. Ainsi, il peut être représenté sous la forme.
Chaque approximation ultérieure est calculée à l'aide de la formule :
Définition. Deux vecteurs et sont dits conjugués par rapport à la matrice symétrique B si
Décrivons la méthode de construction d'une base dans la méthode du gradient conjugué. Nous sélectionnons un vecteur arbitraire comme première approximation. A chaque itération les règles suivantes sont sélectionnées :
Les vecteurs de base sont calculés à l'aide des formules :
Les coefficients sont choisis pour que les vecteurs et soient conjugués par rapport à A.
Si l'on note , alors après plusieurs simplifications nous obtenons les formules finales utilisées lors de l'application pratique de la méthode du gradient conjugué :
Pour la méthode du gradient conjugué, le théorème suivant est valable : Théorème Let, où est une matrice de taille définie positive symétrique. Ensuite, la méthode du gradient conjugué converge en seulement quelques étapes et les relations suivantes sont vérifiées :
Convergence de la méthode
Si tous les calculs sont précis et que les données initiales sont exactes, alors la méthode converge vers la résolution du système en un maximum d'itérations, où est la dimension du système. Une analyse plus fine montre que le nombre d'itérations ne dépasse pas, où est le nombre de valeurs propres différentes de la matrice A. Pour estimer le taux de convergence, l'estimation suivante (assez grossière) est correcte :
Il permet d'estimer le taux de convergence si les estimations des valeurs propres maximales et minimales de la matrice sont connues. En pratique, le critère d'arrêt suivant est le plus souvent utilisé :
Complexité informatique
A chaque itération du procédé, des opérations sont effectuées. Ce nombre d'opérations est nécessaire pour calculer le produit - c'est la procédure la plus longue à chaque itération. D'autres calculs nécessitent des opérations O(n). La complexité de calcul totale de la méthode ne dépasse pas - puisque le nombre d'itérations n'est pas supérieur à n.
Exemple numérique
Appliquons la méthode du gradient conjugué pour résoudre un système où, en utilisant la méthode du gradient conjugué, la solution de ce système est obtenue en deux itérations. Les valeurs propres de la matrice sont 5, 5, -5 - parmi elles il y en a deux différentes, donc, selon l'estimation théorique, le nombre d'itérations ne pourrait pas dépasser deux
La méthode du gradient conjugué est l’une des méthodes les plus efficaces pour résoudre les SLAE avec une matrice définie positive. La méthode garantit la convergence en un nombre fini d’étapes et la précision requise peut être obtenue beaucoup plus tôt. Le principal problème est qu'en raison de l'accumulation d'erreurs, l'orthogonalité des vecteurs de base peut être violée, ce qui altère la convergence.
La méthode du gradient conjugué en général
Considérons maintenant une modification de la méthode du gradient conjugué pour le cas où la fonctionnelle minimisée n'est pas quadratique : Nous allons résoudre le problème :
Fonction différenciable en continu. Pour modifier la méthode du gradient conjugué afin de résoudre ce problème, il faut obtenir pour les formules qui n'incluent pas la matrice A :
peut être calculé à l’aide de l’une des trois formules suivantes :
1. - Méthode Fletcher-Reeves
- 2. - Méthode Polak-Ribière
Si la fonction est quadratique et strictement convexe, alors les trois formules donnent le même résultat. Si est une fonction arbitraire, alors chacune des formules correspond à sa propre modification de la méthode du gradient conjugué. La troisième formule est rarement utilisée car elle nécessite la fonction et le calcul de la Hesse de la fonction à chaque étape de la méthode.
Si la fonction n'est pas quadratique, la méthode du gradient conjugué peut ne pas converger en un nombre fini d'étapes. De plus, un calcul précis à chaque étape n’est possible que dans de rares cas. Par conséquent, l'accumulation d'erreurs conduit au fait que les vecteurs n'indiquent plus le sens de diminution de la fonction. Puis, à un moment donné, ils croient. L'ensemble de tous les nombres auxquels il est accepté sera désigné par . Les nombres sont appelés moments de mise à jour de méthode. En pratique, on choisit souvent où se situe la dimension de l'espace.
Convergence de la méthode
Pour la méthode de Fletcher-Reeves, il existe un théorème de convergence qui impose des conditions pas trop strictes sur la fonction à minimiser : Théorème. Soit les conditions suivantes remplies :
La variété est limitée
La dérivée satisfait la condition de Lipschitz avec une constante dans un certain voisinage
définit M : .
Pour la méthode Polak-Reiber, la convergence est prouvée sous l’hypothèse qu’elle est une fonction strictement convexe. Dans le cas général, il est impossible de prouver la convergence de la méthode Polak-Reiber. Au contraire, le théorème suivant est vrai : Théorème. Supposons que dans la méthode Polak-Reiber les valeurs à chaque étape soient calculées exactement. Ensuite, il y a une fonction, et une première supposition, telle que.
Cependant, en pratique, la méthode Polak-Reiber fonctionne mieux. Les critères d'arrêt les plus courants en pratique : La norme de gradient devient inférieure à un certain seuil La valeur de la fonction est restée quasiment inchangée pendant m itérations consécutives
Complexité informatique
A chaque itération des méthodes Polak-Reiber ou Fletcher-Reeves, la fonction et son gradient sont calculés une fois, et le problème d'optimisation unidimensionnelle est résolu. Ainsi, la complexité d’une étape de la méthode du gradient conjugué est du même ordre de grandeur que la complexité d’une étape de la méthode de la descente la plus raide. En pratique, la méthode du gradient conjugué montre la meilleure vitesse de convergence.
Nous rechercherons le minimum de la fonction en utilisant la méthode du gradient conjugué
Le minimum de cette fonction est 1 et est atteint au point (5, 4). En utilisant cette fonction comme exemple, comparons les méthodes Polak-Reiber et Fletcher-Reeves. Les itérations dans les deux méthodes s'arrêtent lorsque la norme au carré du gradient devient plus petite à l'étape en cours. La méthode du nombre d'or est utilisée pour la sélection
|
Méthode Fletcher-Reeves |
Méthode Polak-Reiber |
|||||
|
Nombre d'itérations |
Solution trouvée |
Valeur de la fonction |
Nombre d'itérations |
Solution trouvée |
Valeur de la fonction |
|
|
(5.01382198,3.9697932) |
(5.03942877,4.00003512) |
|||||
|
(5.01056482,3.99018026) |
(4.9915894,3.99999044) |
|||||
|
(4.9979991,4.00186173) |
(5.00336181,4.0000018) |
|||||
|
(4.99898277,4.00094645) |
(4.99846808,3.99999918) |
|||||
|
(4.99974658,4.0002358) |
(4.99955034,3.99999976) |
Deux versions de la méthode du gradient conjugué ont été implémentées : pour minimiser une fonctionnelle quadratique et pour minimiser une fonction arbitraire. Dans le premier cas, la méthode est implémentée par la fonction vectorielle
Les méthodes de descente de gradient sont des outils assez puissants pour résoudre les problèmes d’optimisation. Le principal inconvénient de ces méthodes est leur champ d’application limité. La méthode du gradient conjugué utilise uniquement des informations sur la partie linéaire de l'incrément en un point, comme dans les méthodes de descente de gradient. De plus, la méthode du gradient conjugué permet de résoudre des problèmes quadratiques en un nombre fini d'étapes. Sur de nombreux autres problèmes, la méthode du gradient conjugué surpasse également la méthode de la descente de gradient. La convergence de la méthode du gradient dépend de manière significative de la précision avec laquelle le problème d’optimisation unidimensionnelle est résolu. Les boucles de méthode possibles sont résolues à l’aide de mises à jour. Cependant, si une méthode atteint un minimum local d’une fonction, elle ne pourra probablement pas en échapper.