Ministerstvo školstva a vedy Ruskej federácie
Federálna agentúra pre vzdelávanie mesta Irkutsk
Bajkal Štátna univerzita ekonomika a právo
Katedra informatiky a kybernetiky
Chi-kvadrát rozdelenie a jeho aplikácia
Kolmyková Anna Andrejevna
študent 2. ročníka
skupina IS-09-1
Na spracovanie získaných údajov používame chí-kvadrát test.
Za týmto účelom zostavíme distribučnú tabuľku empirické frekvencie, t.j. frekvencie, ktoré pozorujeme:
Teoreticky očakávame, že frekvencie budú rozdelené rovnomerne, t.j. frekvencia bude rozdelená medzi chlapcov a dievčatá. Zostavme si tabuľku teoretických frekvencií. Ak to chcete urobiť, vynásobte súčet riadkov súčtom stĺpcov a výsledné číslo vydeľte celková suma(s).
Výsledná tabuľka pre výpočty bude vyzerať takto:
χ2 \u003d ∑ (E – T)² / T
n = (R - 1), kde R je počet riadkov v tabuľke.
V našom prípade chí-kvadrát = 4,21; n = 2.
Podľa tabuľky kritických hodnôt kritéria zistíme: pre n = 2 a úroveň chyby 0,05 kritická hodnota x2 = 5,99.
Výsledná hodnota je menšia ako kritická hodnota, čo znamená, že je akceptovaná nulová hypotéza.
Záver: učitelia nepripisujú dôležitosť pohlaviu dieťaťa pri písaní jeho charakteristík.
Aplikácia
Kritické distribučné body χ2
stôl 1

Záver
Študenti takmer všetkých odborov študujú na konci kurzu vyššia matematikačasti „teória pravdepodobnosti a matematická štatistika“, v skutočnosti sa oboznamujú len s niektorými základnými pojmami a výsledkami, ktoré zjavne nestačia na praktická práca. S niektorými matematickými metódami výskumu sa študenti stretávajú v špeciálnych kurzoch (napríklad „Prognózovanie a plánovanie realizovateľnosti“, „Technická a ekonomická analýza“, „Kontrola kvality produktov“, „Marketing“, „Kontroling“, „ Matematické metódy Prognostika, "štatistika" atď. - v prípade študentov ekonomických odborov je však prezentácia vo väčšine prípadov veľmi skrátená a predpisujúca, v dôsledku čoho odborníci na aplikovanú štatistiku nemajú dostatok vedomostí.
Preto veľký význam má kurz „Aplikovaná štatistika“ v technické univerzity, a v ekonomické univerzity- kurz „Ekonometria“, keďže ekonometria je, ako viete, Štatistická analýza konkrétne ekonomické údaje.
Teória pravdepodobnosti a matematická štatistika poskytujú základné poznatky pre aplikovanú štatistiku a ekonometriu.
Sú potrebné pre špecialistov na praktickú prácu.
Uvažoval som o nepretržitom pravdepodobnostný model a pokúsil sa ukázať jeho využitie na príkladoch.
Bibliografia
1. Orlov A.I. Aplikovaná štatistika. M.: Vydavateľstvo "Skúška", 2004.
2. Gmurman V.E. Teória pravdepodobnosti a matematická štatistika. M.: absolventská škola, 1999. - 479 s.
3. Ayvozyan S.A. Teória pravdepodobnosti a aplikovanej štatistiky, v.1. M.: Jednota, 2001. - 656. roky.
4. Khamitov G.P., Vederniková T.I. Pravdepodobnosti a štatistiky. Irkutsk: BSUEP, 2006 - 272 s.
5. Ezhova L.N. Ekonometria. Irkutsk: BSUEP, 2002. - 314s.
6. Mosteller F. Päťdesiat zábavných pravdepodobnostných problémov s riešeniami. M. : Nauka, 1975. - 111s.
7. Mosteller F. Pravdepodobnosť. M. : Mir, 1969. - 428. roky.
8. Yaglom A.M. Pravdepodobnosť a informácie. M. : Nauka, 1973. - 511s.
9. Chistyakov V.P. Kurz pravdepodobnosti. M.: Nauka, 1982. - 256 s.
10. Kremer N.Sh. Teória pravdepodobnosti a matematická štatistika. M.: UNITI, 2000. - 543 s.
11. Matematická encyklopédia, v.1. M.: Sovietska encyklopédia, 1976. - 655. roky.
12. http://psystat.at.ua/ - Štatistika v psychológii a pedagogike. Článok Chí-kvadrát test.
Zvážte rozdelenie chí-kvadrát. Pomocou funkcie MS EXCELCHI2.DIST() zostrojíme grafy distribučnej funkcie a hustoty pravdepodobnosti, vysvetlíme aplikáciu tohto rozdelenia pre účely matematickej štatistiky.
Chi-kvadrát rozdelenie (X 2, XI2, AngličtinaChi- štvorecdistribúcia) aplikovaný v rôzne metódy matematická štatistika:
- pri stavbe;
- v ;
- at (sú empirické údaje v súlade s naším predpokladom teoretická funkcia distribúcia alebo nie vhodnosť)
- at (používa sa na určenie vzťahu medzi dvoma kategorickými premennými, eng. Chí-kvadrát test asociácie).
Definícia: Ak x 1 , x 2 , …, x n sú nezávislé náhodné premenné rozdelené na N(0;1), potom rozdelenie náhodnej premennej Y=x 1 2 + x 2 2 +…+ x n 2 má distribúcia X 2 s n stupňami voľnosti.
Distribúcia X 2 závisí od jedného parametra tzv stupeň voľnosti (df, stupňazslobody). Napríklad pri stavbe počet stupňov voľnosti sa rovná df=n-1, kde n je veľkosť vzorky.
Hustota distribúcie X 2
vyjadrené vzorcom:
Grafy funkcií
Distribúcia X 2 má asymetrický tvar, rovný n, rovný 2n.
AT príklad súboru na liste Graf daný grafy hustoty distribúcie pravdepodobnosti a integrálna distribučná funkcia.

Užitočný majetok chi2 distribúcie
Nech x 1 , x 2 , …, x n sú nezávislé náhodné premenné rozložené cez normálny zákon
s rovnakými parametrami μ a σ, a X porov je aritmetický priemer tieto hodnoty x.
Potom náhodná hodnota r rovný

Má X 2 -distribúcia s n-1 stupňami voľnosti. Pomocou definície možno vyššie uvedený výraz prepísať takto:
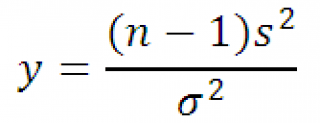
v dôsledku toho distribúcia vzoriekštatistiky y, s vzorkovanie od normálne rozdelenie , Má X 2 -distribúcia s n-1 stupňami voľnosti.
Túto nehnuteľnosť budeme potrebovať na . Pretože disperzia môže len byť kladné číslo, a X 2 -distribúcia používané na jej vyhodnotenie r d.b. >0, ako je uvedené v definícii.
HI2 distribúcia v MS EXCEL
V MS EXCEL, počnúc verziou 2010, pre X 2 -distribúcie existuje špeciálna funkcia XI2.DIST() , anglický názov– CHISQ.DIST(), ktorá vám umožňuje vypočítať hustota pravdepodobnosti(pozri vzorec vyššie) a (pravdepodobnosť, že náhodná premenná X má XI2-distribúcia, nadobúda hodnotu menšiu alebo rovnú x, P(X<= x}).
Poznámka: Pretože chi2 distribúcia je špeciálny prípad, potom vzorec =GAMMA.DIST(x,n/2;2;PRAVDA) pre kladné celé číslo n vráti rovnaký výsledok ako vzorec =XI2.DIST(x; n; TRUE) alebo =1-XI2.DIST.X(x;n) . A vzorec =GAMMA.DIST(x,n/2;2;FALSE) vráti rovnaký výsledok ako vzorec =XI2.DIST(x; n; FALSE), t.j. hustota pravdepodobnosti distribúcie XI2.
Vráti funkciu CH2.DIST.RT(). distribučná funkcia, presnejšie pravostranná pravdepodobnosť, t.j. P(X > x). Je zrejmé, že rovnosť
=CHI2.DIST.X(x;n)+ CHI2.DIST(x;n;TRUE)=1
pretože prvý člen počíta pravdepodobnosť P(X > x) a druhý P(X<= x}.
Pred MS EXCEL 2010 mal EXCEL len funkciu HI2DIST(), ktorá umožňuje vypočítať pravdepodobnosť pravej ruky, t.j. P(X > x). Možnosti nových funkcií MS EXCEL 2010 CHI2.DIST() a CHI2.DIST.RT() prekrývajú možnosti tejto funkcie. Funkcia HI2DIST() bola v MS EXCEL 2010 ponechaná kvôli kompatibilite.
CHI2.DIST() je jediná funkcia, ktorá vracia hustota pravdepodobnosti rozdelenia chi2(tretí argument musí byť NEPRAVDA). Zvyšné funkcie sa vrátia integrálna funkcia distribúcia, t.j. pravdepodobnosť, že náhodná premenná nadobudne hodnotu zo zadaného rozsahu: P(X<= x}.
Vyššie uvedené funkcie MS EXCEL sú uvedené v.
Príklady
Nájdite pravdepodobnosť, že náhodná premenná X nadobudne hodnotu menšiu alebo rovnú zadanej X: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; TRUE)
=1-CHI2.DIST.RP(x; n)
=1-CHI2DIST(x; n)
Funkcia XI2.DIST.X() vráti pravdepodobnosť P(X > x), takzvanú pravostrannú pravdepodobnosť, aby sme našli P(X<= x}, необходимо вычесть ее результат от 1.
Nájdite pravdepodobnosť, že náhodná premenná X nadobudne väčšiu hodnotu ako je daná X: P(X > x). To možno vykonať niekoľkými funkciami:
1-CHI2.DIST(x; n; TRUE)
=XI2.DIST.RP(x; n)
=CHI2DIST(x, n)
Funkcia inverzného rozdelenia chi2
Na výpočet sa používa inverzná funkcia alfa- t.j. na výpočet hodnôt X pre danú pravdepodobnosť alfa, a X musí spĺňať výraz P(X<= x}=alfa.
Na výpočet sa používa funkcia CH2.INV(). intervaly spoľahlivosti rozptylu normálneho rozdelenia.
Funkcia XI2.INV.RT() slúži na výpočet , t.j. ak je ako argument funkcie zadaná hladina významnosti, napríklad 0,05, potom funkcia vráti takú hodnotu náhodnej premennej x, pre ktorú P(X>x)=0,05. Pre porovnanie: funkcia XI2.INV() vráti takú hodnotu náhodnej premennej x, pre ktorú P(X<=x}=0,05.
V MS EXCEL 2007 a starších bola namiesto XI2.OBR.RT() použitá funkcia XI2OBR().
Vyššie uvedené funkcie je možné zamieňať, napr nasledujúce vzorce vrátia rovnaký výsledok:
=CHI.OBR(alfa,n)
=XI2.INV.RT(1-alfa;n)
\u003d XI2OBR (1-alfa; n)
Niektoré príklady výpočtov sú uvedené v vzorový súbor na hárku Funkcie.
MS EXCEL funguje pomocou distribúcie chi2
Nižšie je uvedená korešpondencia medzi ruskými a anglickými názvami funkcií:
HI2.DIST.PH() - angl. názov CHISQ.DIST.RT, t.j. CHI-Squared DISTribution Right Tail, pravostranná Chi-square(d) distribúcia
XI2.OBR () - anglicky. názov CHISQ.INV, t.j. CHI-štvorcová distribúcia INverzná
HI2.PH.OBR() - angličtina. názov CHISQ.INV.RT, t.j. CHI-Squared distribúcia INverse Right Tail
HI2DIST() - angl. názov CHIDIST, funkcia ekvivalentná CHISQ.DIST.RT
HI2OBR() - angl. názov CHIINV, t.j. CHI-štvorcová distribúcia INverzná
Odhad distribučných parametrov
Pretože zvyčajne chi2 distribúcia používa sa na účely matematickej štatistiky (výpočet intervaly spoľahlivosti, testovanie hypotéz a pod.) a takmer nikdy pri konštrukcii modelov reálnych hodnôt, potom pre toto rozdelenie sa tu diskusia o odhade parametrov rozdelenia neuskutočňuje.
Aproximácia rozdelenia XI2 normálnym rozdelením
S počtom stupňov voľnosti n>30 rozdelenie X 2 dobre aproximované normálne rozdelenie spol priemerμ=n a disperzia σ= 2*n (pozri vzorový list súboru Aproximácia).
1. Porovnateľné ukazovatele by sa mali merať v nominálna stupnica(napríklad pohlavie pacienta - muž alebo žena) alebo v radový(napríklad stupeň arteriálnej hypertenzie s hodnotami od 0 do 3).
2. Táto metóda umožňuje analýzu nielen tabuliek so štyrmi poliami, keď faktor aj výsledok sú binárne premenné, to znamená, že majú iba dve možné hodnoty (napríklad muž alebo žena, prítomnosť alebo neprítomnosť istá choroba v histórii...). Pearsonov chí-kvadrát test možno použiť aj v prípade analýzy tabuliek s viacerými poľami, keď faktor a (alebo) výsledok nadobúdajú tri alebo viac hodnôt.
3. Zhodné skupiny by mali byť nezávislé, t.j. test chí-kvadrát by sa nemal používať pri porovnávaní pozorovaní pred a po. McNemarov test(pri porovnaní dvoch súvisiacich populácií) alebo vypočítané Q-test Cochran(v prípade porovnávania troch a viacerých skupín).
4. Pri analýze štvorpolových tabuliek očakávané hodnoty v každej z buniek musí byť aspoň 10. V prípade, že aspoň v jednej bunke očakávaný jav nadobudne hodnotu od 5 do 9, musí sa vypočítať chí-kvadrát test s Yatesovou korekciou. Ak je aspoň v jednej bunke očakávaný jav menší ako 5, potom by sa mala použiť analýza Fisherov presný test.
5. V prípade analýzy tabuliek s viacerými poľami by predpokladaný počet pozorovaní nemal nadobudnúť hodnoty menšie ako 5 vo viac ako 20 % buniek.
Na výpočet chí-kvadrát testu musíte:
1. Vypočítajte očakávaný počet pozorovaní pre každú z buniek kontingenčnej tabuľky (v závislosti od platnosti nulovej hypotézy o neprítomnosti vzťahu) vynásobením súčtu riadkov a stĺpcov a následným vydelením výsledného produktu celkovým počtom pozorovaní. Všeobecný pohľad na tabuľku očakávaných hodnôt je uvedený nižšie:
| Exodus je (1) | Žiadny odchod (0) | Celkom | |
| Existuje rizikový faktor (1) | (A+B)*(A+C) / (A+B+C+D) | (A+B)*(B+D)/ (A+B+C+D) | A+B |
| Žiadny rizikový faktor (0) | (C+D)*(A+C)/ (A+B+C+D) | (C+D)*(B+D)/ (A+B+C+D) | C+D |
| Celkom | A+C | B+D | A+B+C+D |
2. Nájdeme hodnotu kritéria χ 2 podľa nasledujúceho vzorca:
kde i– číslo riadku (od 1 do r), j– číslo stĺpca (od 1 do c), O ij je skutočný počet pozorovaní v bunke ij, E ij je očakávaný počet pozorovaní v bunke ij.
V prípade, že počet očakávaných javov je menší ako 10 aspoň v jednej bunke, pri analýze štvorpolových tabuliek sa chí-kvadrát test s Yatesovou korekciou. Táto korekcia znižuje pravdepodobnosť chyby typu I, t. j. zisťuje rozdiely tam, kde žiadne nie sú. Yatesova korekcia spočíva v odčítaní 0,5 od absolútnej hodnoty rozdielu medzi skutočným a očakávaným počtom pozorovaní v každej bunke, čo vedie k zníženiu hodnoty chí-kvadrát testu.
Vzorec na výpočet kritéria χ 2 s Yatesovou korekciou je nasledujúci:

3. Určte počet stupňov voľnosti podľa vzorca: f = (r - 1) × (c - 1). V súlade s tým je pre tabuľku so štyrmi poliami s 2 riadkami (r = 2) a 2 stĺpcami (c = 2) počet stupňov voľnosti f 2x2 = (2 - 1)*(2 - 1) = 1.
4. Hodnotu kritéria χ 2 porovnávame s kritickou hodnotou s počtom stupňov voľnosti f (podľa tabuľky).
Tento algoritmus je použiteľný pre štvorpolové aj viacpolové tabuľky.
Ako interpretovať hodnotu Pearsonovho chí-kvadrát testu?
V prípade, že získaná hodnota kritéria χ 2 je väčšia ako kritická, usúdime, že existuje štatistický vzťah medzi študovaným rizikovým faktorom a výsledkom na príslušnej hladine významnosti.
Príklad výpočtu Pearsonovho chí-kvadrát testu
Stanovme štatistickú významnosť vplyvu faktora fajčenia na výskyt arteriálnej hypertenzie podľa tabuľky vyššie:
1. Vypočítajte očakávané hodnoty pre každú bunku:
2. Nájdite hodnotu Pearsonovho chí-kvadrát testu:
χ 2 \u003d (40-33,6) 2 / 33,6 + (30-36,4) 2 / 36,4 + (32-38,4) 2 / 38,4 + (48-41,6) 2 / 41,6 \u003d 4,396.
3. Počet stupňov voľnosti f = (2-1)*(2-1) = 1. Nájdite kritickú hodnotu Pearsonovho chí-kvadrát testu z tabuľky, ktorá na hladine významnosti p=0,05 resp. počet stupňov voľnosti 1, je 3,841.
4. Získanú hodnotu chí-kvadrát testu porovnávame s kritickou: 4,396 > 3,841, preto je závislosť výskytu artériovej hypertenzie od prítomnosti fajčenia štatisticky významná. Hladina významnosti tohto vzťahu zodpovedá p<0.05.
| Počet stupňov voľnosti, f | x2 pri p=0,05 | x2 pri p=0,01 |
| 3.841 | 6.635 | |
| 5.991 | 9.21 | |
| 7.815 | 11.345 | |
| 9.488 | 13.277 | |
| 11.07 | 15.086 | |
| 12.592 | 16.812 | |
| 14.067 | 18.475 | |
| 15.507 | 20.09 | |
| 16.919 | 21.666 | |
| 18.307 | 23.209 | |
| 19.675 | 24.725 | |
| 21.026 | 26.217 | |
| 22.362 | 27.688 | |
| 23.685 | 29.141 | |
| 24.996 | 30.578 | |
| 26.296 | ||
| 27.587 | 33.409 | |
| 28.869 | 34.805 | |
| 30.144 | 36.191 | |
| 31.41 | 37.566 |
V prípade, že získaná hodnota kritéria χ 2 je väčšia ako kritická, usúdime, že existuje štatistický vzťah medzi študovaným rizikovým faktorom a výsledkom na príslušnej hladine významnosti.
Príklad výpočtu Pearsonovho chí-kvadrát testu
Stanovme štatistickú významnosť vplyvu faktora fajčenia na výskyt arteriálnej hypertenzie podľa tabuľky vyššie:
1. Vypočítajte očakávané hodnoty pre každú bunku:
2. Nájdite hodnotu Pearsonovho chí-kvadrát testu:
χ 2 \u003d (40-33,6) 2 / 33,6 + (30-36,4) 2 / 36,4 + (32-38,4) 2 / 38,4 + (48-41,6) 2 / 41,6 \u003d 4,396.
3. Počet stupňov voľnosti f = (2-1)*(2-1) = 1. Nájdite kritickú hodnotu Pearsonovho chí-kvadrát testu z tabuľky, ktorá na hladine významnosti p=0,05 resp. počet stupňov voľnosti 1, je 3,841.
4. Získanú hodnotu chí-kvadrát testu porovnávame s kritickou: 4,396 > 3,841, preto je závislosť výskytu artériovej hypertenzie od prítomnosti fajčenia štatisticky významná. Hladina významnosti tohto vzťahu zodpovedá p<0.05.
Podľa vzorca sa vypočíta aj Pearsonov chí-kvadrát test
Ale pre stôl 2x2 poskytuje Yatesovo opravený test presnejšie výsledky.

Ak  potom H(0) prijatý,
potom H(0) prijatý,
Kedy ![]() prijatý H(1)
prijatý H(1)
Keď je počet pozorovaní malý a v bunkách tabuľky sa vyskytuje frekvencia menšia ako 5, test chí-kvadrát nie je použiteľný a používa sa na testovanie hypotéz. Fisherov presný test . Postup výpočtu tohto kritéria je dosť namáhavý av tomto prípade je lepšie použiť počítačové programy na štatistickú analýzu.
Podľa kontingenčnej tabuľky môžete vypočítať mieru vzťahu medzi dvoma kvalitatívnymi znakmi - je to Yule asociačný koeficient Q (analóg korelačného koeficientu)

Q leží v rozmedzí od 0 do 1. Koeficient blízky jednote naznačuje silný vzťah medzi znakmi. Ak sa rovná nule, neexistuje spojenie .
Podobne sa používa koeficient phi-square (φ 2).
ŠTANDARDNÁ ÚLOHA
Tabuľka popisuje súvislosť medzi mierami mutácií v kŕmených a nekŕmených skupinách Drosophila.
Krížová tabuľková analýza
Na analýzu kontingenčnej tabuľky sa predkladá H 0 - hypotéza, to znamená absencia vplyvu študovaného znaku na výsledok štúdie. Na tento účel sa vypočíta očakávaná frekvencia a zostaví sa tabuľka očakávaní.
Čakací stôl
| skupiny | Chilo kultúry | Celkom | ||||
| Dal mutácie | Nezmutoval | |||||
| Skutočná frekvencia | Očakávaná frekvencia | Skutočná frekvencia | Očakávaná frekvencia | |||
| S vrchným obväzom | ||||||
| Bez vrchného obväzu | ||||||
| Celkom | ||||||
Metóda #1
Určite frekvenciu čakania:
2756 - X ![]() ;
;
2. 3561 – 3124
Ak je počet pozorovaní v skupinách malý, pri použití X 2 je to v prípade porovnávania skutočných a očakávaných frekvencií s diskrétnymi rozdeleniami spojené s určitou nepresnosťou.Na zníženie nepresnosti sa používa Yatesova korekcia.
Chí-kvadrát Pearson je najjednoduchší test pre význam asociácie medzi dvoma kategorizovanými premennými. Pearsonovo kritérium je založené na skutočnosti, že v tabuľke dvoch vstupov očakávané frekvencie podľa hypotézy „medzi premennými neexistuje vzťah“ možno vypočítať priamo. Predstavte si, že 20 mužov a 20 žien sa opýta na výber sódy (zn A alebo značka B). Ak neexistuje vzťah medzi preferenciou a pohlavím, potom prirodzene očakávať rovnaký výber značky A a značky B pre každé pohlavie.
Význam štatistiky chí-kvadrát a jeho úroveň významnosti závisí od celkového počtu pozorovaní a počtu buniek v tabuľke. V súlade so zásadami uvedenými v časti , relatívne malé odchýlky pozorovaných frekvencií od očakávaných sa ukážu ako významné, ak je počet pozorovaní veľký.
Existuje len jedno významné obmedzenie použitia kritéria chí-kvadrát(okrem zrejmého predpokladu náhodného výberu pozorovaní), ktorým je, že očakávané frekvencie by nemali byť veľmi malé. Je to kvôli kritériu chí-kvadrát podľa prírody kontroly pravdepodobnosti v každej bunke; a ak sa očakávané frekvencie buniek stanú malými, napr. menej ako 5, potom tieto pravdepodobnosti nemožno odhadnúť s dostatočnou presnosťou pomocou dostupných frekvencií. Pre ďalšiu diskusiu pozri Everitt (1977), Hays (1988) alebo Kendall a Stuart (1979).
Chí-kvadrát test (metóda maximálnej pravdepodobnosti).maximálna pravdepodobnosť chí-kvadrát je navrhnutý tak, aby testoval rovnakú hypotézu o vzťahoch v krížových tabuľkách ako test chí-kvadrát Pearson. Jeho výpočet je však založený na metóde maximálnej pravdepodobnosti. V praxi MP štatistiky chí-kvadrát veľmi blízko k obvyklej Pearsonovej štatistike chí-kvadrát. Viac o týchto štatistikách pozri Bishop, Fienberg a Holland (1975) alebo Fienberg (1977). V kapitole Log lineárna analýza o týchto štatistikách sa diskutuje podrobnejšie.
Yeatsova korekcia. Približná štatistika chí-kvadrát pre tabuľky 2x2 s malým počtom pozorovaní v bunkách možno zlepšiť znížením absolútnej hodnoty rozdielov medzi očakávanou a pozorovanou frekvenciou o 0,5 pred kvadratizáciou (tzv. Yatesova korekcia). Yatesova korekcia, vďaka ktorej je odhad miernejší, sa zvyčajne používa, keď tabuľky obsahujú len malé frekvencie, napríklad keď niektoré očakávané frekvencie klesnú pod 10 (pre ďalšiu diskusiu pozri Conover, 1974; Everitt, 1977; Hays, 1988 Kendall a Stuart, 1979 a Mantel, 1974).
Fisherov presný test. Toto kritérium platí len pre stoly 2x2. Kritérium je založené na nasledujúcom odôvodnení. Vzhľadom na hraničné frekvencie v tabuľke predpokladajme, že obe tabuľkové premenné sú nezávislé. Položme si otázku: aká je pravdepodobnosť získania frekvencií pozorovaných v tabuľke na základe daných okrajových? Ukazuje sa, že táto pravdepodobnosť je vypočítaná presne tak spočítaním všetkých tabuliek, ktoré sa dajú postaviť na základe okrajových. Takto sa vypočíta Fisherovo kritérium presné pravdepodobnosť výskytu pozorovaných frekvencií pri nulovej hypotéze (nedostatok asociácie medzi tabuľkovými premennými). Tabuľka výsledkov zobrazuje jednostranné aj obojstranné úrovne.
McNemarov chí-kvadrát. Toto kritérium platí, keď frekvencie v tabuľke 2x2 predstavujú závislý vzorky. Napríklad pozorovania tých istých jedincov pred a po experimente. Môžete spočítať najmä počet študentov, ktorí majú najnižšie skóre z matematiky na začiatku a na konci semestra, alebo preferenciu tých istých respondentov pred a po inzeráte. Vypočítajú sa dve hodnoty chí-kvadrát: A/D a B/C. A/D chí-kvadrát testuje hypotézu, že frekvencie v bunkách A a D(vľavo hore, vpravo dole) sú rovnaké. B/C chí-kvadrát testuje hypotézu o rovnosti frekvencií v bunkách B a C(vpravo hore, vľavo dole).
Koeficient Phi.phi-štvorec je miera asociácie medzi dvoma premennými v tabuľke 2x2. Jeho hodnoty sa líšia od 0 (žiadna závislosť medzi premennými; chí-kvadrát = 0.0 ) predtým 1 (absolútny vzťah medzi dvoma faktormi v tabuľke). Podrobnosti pozri Castellan a Siegel (1988, s. 232).
Tetrachorická korelácia. Táto štatistika sa počíta (a aplikuje) len pre krížové tabuľky 2x2. Ak tabuľku 2x2 možno považovať za výsledok (umelého) rozdelenia hodnôt dvoch spojitých premenných do dvoch tried, potom koeficient tetrachorickej korelácie umožňuje odhadnúť vzťah medzi týmito dvoma premennými.
Koeficient konjugácie. Koeficient kontingencie je štatisticky založený chí-kvadrát miera vzťahu znakov v kontingenčnej tabuľke (navrhnutá Pearsonom). Výhoda tohto koeficientu oproti bežnej štatistike chí-kvadrát v tom, že sa ľahšie interpretuje, pretože jeho rozsah je v rozmedzí od 0 predtým 1 (kde 0 zodpovedá prípadu nezávislosti znakov v tabuľke a zvýšenie koeficientu ukazuje zvýšenie miery spojenia). Nevýhodou kontingenčného koeficientu je, že jeho maximálna hodnota „závisí“ od veľkosti tabuľky. Tento faktor môže dosiahnuť 1 iba vtedy, ak je počet tried neobmedzený (pozri Siegel, 1956, s. 201).
Interpretácia komunikačných opatrení. Hlavnou nevýhodou asociačných opatrení (diskutovaných vyššie) je obtiažnosť ich interpretácie bežnými termínmi pravdepodobnosti alebo „vysvetleným zlomkom rozptylu“, ako v prípade korelačného koeficientu. r Pearson (pozri Korelácie). Preto neexistuje žiadna všeobecne akceptovaná miera alebo koeficient asociácie.
Štatistiky založené na poradí. V mnohých problémoch, ktoré vznikajú v praxi, máme merania len v radový mierka (viď Základné pojmy štatistiky). Platí to najmä pre merania v oblasti psychológie, sociológie a iných disciplín súvisiacich so štúdiom človeka. Povedzme, že ste urobili rozhovor so skupinou respondentov, aby ste zistili ich postoje k určitým športom. Merania reprezentujete na stupnici s nasledujúcimi pozíciami: (1) vždy, (2) zvyčajne, (3) niekedy a (4) nikdy. Očividne odpoveď niekedy záujem prejaví menší záujem respondenta ako odpoveď zvyčajne zaujíma atď. Tak je možné zefektívniť (zoradiť) mieru záujmu respondentov. Toto je typický príklad radovej stupnice. Premenné merané na ordinálnej stupnici majú svoje vlastné typy korelácií, ktoré vám umožňujú vyhodnocovať závislosti.
R Spearman.štatistiky R Spearmana možno interpretovať rovnakým spôsobom ako Pearsonovu koreláciu ( r Pearson) z hľadiska podielu rozptylu vysvetleného (majte však na pamäti, že štatistika Spearmana sa počíta z poradí). Predpokladá sa, že premenné sú merané v min radový stupnica. Komplexnú diskusiu o Spearmanovej korelácii hodnosti, jej sile a účinnosti možno nájsť napríklad v Gibbonsovi (1985), Haysovi (1981), McNemarovi (1969), Siegelovi (1956), Siegelovi a Castellanovi (1988), Kendall (1948). ), Olds (1949) a Hotelling a Pabst (1936).
Tau Kendall.Štatistiky tau Kendall ekvivalent R Spearman za určitých základných predpokladov. Tiež ekvivalentné ich sile. Zvyčajne však hodnoty R Spearman a tau Kendall sú iné, pretože sa líšia ako vo vnútornej logike, tak aj v spôsobe výpočtu. V práci Siegel a Castellan (1988) autori vyjadrili vzťah medzi týmito dvoma štatistikami takto:
1 < = 3 * Тау Кендалла - 2 * R Спирмена < = 1
Ešte dôležitejšie sú štatistiky Kendall tau a Spearman R majú rôzne výklady: kým štatistika R Spearmana možno považovať za priamu analógiu štatistík r Pearson vypočítaný podľa hodností, štatistiky Kendall tau skôr na základe pravdepodobnosti. Presnejšie sa kontroluje, či je rozdiel medzi pravdepodobnosťou, že pozorované údaje sú v rovnakom poradí pre dve veličiny, a pravdepodobnosťou, že sú v inom poradí. Kendall (1948, 1975), Everitt (1977) a Siegel a Castellan (1988) veľmi podrobne rozoberajú tau Kendall. Zvyčajne sa počítajú dva varianty štatistiky tau Kendall: tau b a tau c. Tieto opatrenia sa líšia iba spôsobom, akým sa zaobchádza s prekrývajúcimi sa hodnosťami. Vo väčšine prípadov sú ich významy dosť podobné. Ak vzniknú rozdiely, potom sa javí ako najbezpečnejší spôsob, ako zvážiť menšiu z týchto dvoch hodnôt.
Sommerov koeficient d: d(X|Y), d(Y|X).Štatistiky d Sommer je nesymetrická miera vzťahu medzi dvoma premennými. Táto štatistika je blízko tau b(Pozri Siegel a Castellan, 1988, str. 303-310).
Gamma štatistiky. Ak je v údajoch veľa zodpovedajúcich hodnôt, štatistika gama výhodnejšie R Spearman resp tau Kendall. Pokiaľ ide o základné predpoklady, štatistiky gama zodpovedá štatistike R Spearman alebo Tau Kendall. Jeho interpretácia a výpočty sa viac podobajú Kendallovej štatistike tau ako Spearmanovej R štatistike. V skratke, gama je tiež pravdepodobnosť; presnejšie, rozdiel medzi pravdepodobnosťou, že sa poradie dvoch premenných zhoduje, mínus pravdepodobnosť, že sa nezhoduje, vydelený jednou mínus pravdepodobnosť zhody. Takže štatistika gama v podstate ekvivalentné tau Kendall, až na to, že náhody sa pri normalizácii vyslovene zohľadňujú. Podrobná diskusia o štatistikách gama možno nájsť v Goodman a Kruskal (1954, 1959, 1963, 1972), Siegel (1956) a Siegel a Castellan (1988).
Koeficienty neistoty. Tieto pomery merajú informačné spojenie medzi faktormi (riadky a stĺpce tabuľky). koncepcie informačná závislosť vychádza z informačno-teoretického prístupu k analýze frekvenčných tabuliek, na objasnenie tejto problematiky je možné odkázať na príslušné príručky (pozri Kullback, 1959; Ku a Kullback, 1968; Ku, Varner a Kullback, 1971; pozri tiež Bishop Fienberg a Holland, 1975, str. 344-348). Štatistiky S(Y, X) je symetrický a meria množstvo informácií v premennej Y relatívne k premennej X alebo v premennej X relatívne k premennej Y. Štatistiky S(X|Y) a S(Y|X) vyjadrovať smerový vzťah.
Viacrozmerné odpovede a dichotómie. Premenné ako mnohorozmerné odpovede a mnohorozmerné dichotómie vznikajú v situáciách, keď sa výskumník zaujíma nielen o „jednoduché“ frekvencie udalostí, ale aj o niektoré (často neštruktúrované) kvalitatívne vlastnosti týchto udalostí. Povahu viacrozmerných premenných (faktorov) najlepšie pochopíme na príkladoch.
- · Viacrozmerné odpovede
- · Viacrozmerné dichotómie
- Krížová tabuľka multivariačných odpovedí a dichotómií
- Párová krížová tabuľka premenných s viacrozmernými odpoveďami
- · Záverečný komentár
Viacrozmerné odpovede. Predstavte si, že ste v priebehu veľkého prieskumu trhu požiadali zákazníkov, aby vymenovali svoje 3 najlepšie nealkoholické nápoje. Typická otázka môže vyzerať takto.







