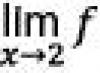PUNË LABORATORIKE Nr.4
Llogaritja e koeficientit të korrelacionit të mostrës dhe ndërtimi i linjës së regresionit empirik dhe teorik
Qëllimi i punës : njohja me korrelacionin linear; zhvillimi i aftësisë për llogaritjen dhe kampionimin e koeficientit të korrelacionit dhe përpilimin e ekuacioneve të linjave të regresionit teorik.
Përmbajtja e veprës
:
bazuar në të dhënat eksperimentale, llogaritni koeficientin e korrelacionit të mostrës, ndërtoni një interval besimi për të me besueshmëri, jepni një përshkrim semantik të rezultatit të marrë, ndërtoni linja regresioni empirik dhe teorik.  në
në  sipas metodës parafjalore të mësipërme.
sipas metodës parafjalore të mësipërme.
Metoda e korrelacionit
Duke përdorur metodën e korrelacionit në statistikat matematikore, përcaktohet marrëdhënia midis dukurive. E veçanta e studimit të kësaj marrëdhënieje është se është e pamundur të izolohet ndikimi i faktorëve të jashtëm. Prandaj, metoda e korrelacionit përdoret për të përcaktuar, në rastin e një ndërveprimi kompleks të ndikimeve të jashtme të faktorëve, cila do të ishte marrëdhënia midis karakteristikave nëse faktorët e jashtëm nuk do të ndryshonin, d.m.th., kushtet e eksperimentit do të ishin të përshtatshme .
Teoria e korrelacionit shqyrton dy probleme:
1) përcaktimi i parametrit të korrelacionit ndërmjet karakteristikave të ekzaminuara;
2) përcaktimi i afërsisë së kësaj lidhjeje. Mbi natyrën e marrëdhënies ndërmjet karakteristikave  Dhe
Dhe  mund të gjykohet nga vendndodhja e pikave në sistemin koordinativ (fusha e korrelacionit). Nëse këto pika ndodhen pranë një vije të drejtë, atëherë supozohet se midis mesatares së kushtëzuar
mund të gjykohet nga vendndodhja e pikave në sistemin koordinativ (fusha e korrelacionit). Nëse këto pika ndodhen pranë një vije të drejtë, atëherë supozohet se midis mesatares së kushtëzuar  Dhe
Dhe  ka një marrëdhënie lineare. Ekuacioni
ka një marrëdhënie lineare. Ekuacioni 
 në
në  .
.
Ekuacioni  quhet ekuacioni i vijës së regresionit
quhet ekuacioni i vijës së regresionit  në
në  . Nëse të dyja linjat e regresionit janë të drejta, atëherë ekziston një korrelacion linear.
. Nëse të dyja linjat e regresionit janë të drejta, atëherë ekziston një korrelacion linear.
Ekuacionet e vijës së regresionit
 Dhe
Dhe  janë përpiluar në bazë të të dhënave të mostrës të dhëna në tabelën e korrelacionit.
janë përpiluar në bazë të të dhënave të mostrës të dhëna në tabelën e korrelacionit.
 - vlerat mesatare të karakteristikave përkatëse;
- vlerat mesatare të karakteristikave përkatëse;
 - koeficientët e regresionit
- koeficientët e regresionit  në
në  Dhe
Dhe  në
në  - llogaritur duke përdorur formula
- llogaritur duke përdorur formula


Ku  - vlera mesatare e produktit
- vlera mesatare e produktit  në
në  ;
;
 Dhe
Dhe  - variancat e tipareve
- variancat e tipareve  Dhe
Dhe  .
.
Në korrelacionin linear, afërsia e marrëdhënies midis karakteristikave karakterizohet nga koeficienti i korrelacionit të mostrës.  , i cili merr vlera që variojnë nga "-1" në "+1".
, i cili merr vlera që variojnë nga "-1" në "+1".
Nëse vlera e koeficientit të korrelacionit është negative, atëherë kjo tregon një marrëdhënie lineare të anasjelltë midis karakteristikave që studiohen; nëse është pozitive - për një lidhje drejtvizore. Nëse koeficienti i korrelacionit është 0, atëherë nuk ka lidhje lineare midis karakteristikave.
Koeficienti i korrelacionit të mostrës llogaritet duke përdorur formulën:
r në  (1)
(1)
Ku  - vlera mesatare e produkteve
- vlera mesatare e produkteve  në
në 
 Dhe
Dhe  - vlerat mesatare të karakteristikave përkatëse;
- vlerat mesatare të karakteristikave përkatëse;
 Dhe
Dhe  - devijimet standarde të gjetura për karakteristikën
- devijimet standarde të gjetura për karakteristikën  dhe për shenjën
dhe për shenjën  .
.
METODA E KRYERJES SË PUNËS
Janë dhënë të dhëna statistikore për temperaturën e vajit lubrifikues të boshtit të pasmë të makinës.  në varësi të temperaturës së ambientit
në varësi të temperaturës së ambientit  .
.
|
| |||||||||||||||||
|
| |||||||||||||||||
|
| |||||||||||||||||
|
| |||||||||||||||||
|
| |||||||||||||||||
|
|






1. LLOGARITJA E KOEFICIENTIT TË KORELACIONIT TË MOSTRAVE
Ne do t'i përmbledhim këto kushte në një tabelë korrelacioni
Tabela 1.
|
n y(frekuenca e karakteristikës y) |
||||||||
|
n x (frekuenca e karakteristikës x) |
Le të gjejmë karakteristikat numerike të mostrës
1.1. Le të gjejmë vlerat mesatare të karakteristikave X dhe Y


 ,
,

1.2. Le të gjejmë variancat e mostrës

1513-1281,64=231,36

1.3. Shembull i devijimit standard
 ,
,
 ,
,

1.4. Modeli i momentit të korrelacionit
1/50(40 + 120+720+480+200+800+900+4200+1120+2160+4500+5280+4400+1320+1560) – 497,62=
1/50(27800) – 497,62 = 556 – 497,62 = 58,38

1.5. Koeficienti i korrelacionit të mostrës

 0,77
0,77
2. Le të kontrollojmë rëndësinë e koeficientit të korrelacionit për ta bërë këtë, le të kontrollojmë statistikat:
 =
= ≈ 8,3
≈ 8,3
Ne do të gjejmë  nga tabela e shpërndarjes së studentëve (Shtojca) sipas nivelit të rëndësisë që përdoret më shpesh në teknologji
nga tabela e shpërndarjes së studentëve (Shtojca) sipas nivelit të rëndësisë që përdoret më shpesh në teknologji  DheY– numri i shkallëve të lirisë K= n – 2 = 50 – 2 = 48,
DheY– numri i shkallëve të lirisë K= n – 2 = 50 – 2 = 48,
 2,02
2,02
Sepse  = 8.3 > 2.02, atëherë koeficienti i korrelacionit të gjetur ndryshon ndjeshëm nga zero. Kjo do të thotë se variablat X dhe Y janë të lidhura me një marrëdhënie regresioni linear të formës
= 8.3 > 2.02, atëherë koeficienti i korrelacionit të gjetur ndryshon ndjeshëm nga zero. Kjo do të thotë se variablat X dhe Y janë të lidhura me një marrëdhënie regresioni linear të formës 
Kështu, koeficienti i korrelacionit tregon marrëdhënien e ngushtë lineare që ekziston midis temperaturës së vajit lubrifikues të boshtit të pasmë dhe temperaturës së ajrit të ambientit.
3. Hartimi i ekuacioneve empirike të regresionit linearYnëXDheXnëY.
3.1. Ekuacioni empirik i regresionit linear i Y në X.
 ,
,


3.2. Ekuacioni empirik i regresionit linear i X nëY.
 ,
,

 =35,8+2,34 (y-13,9)
=35,8+2,34 (y-13,9)

4. NDËRTIMI I NJË LINJE REGRESIONI EMPIRIKEYAKTIVX.
Për të ndërtuar një linjë regresioni empirik, le të hartojmë Tabelën 2.
Tabela 2
|
|

 - mesatare e kushtëzuar e vlerave karakteristike
- mesatare e kushtëzuar e vlerave karakteristike  me kusht që
me kusht që  merr një vlerë të caktuar, d.m.th.
merr një vlerë të caktuar, d.m.th. 
 ;
;

 ;
;

 ;
;


Marrja e çifteve të numrave  për koordinatat e pikave, ndërto ato në një sistem koordinativ dhe lidh me segmente të drejtëza. Vija e thyer që rezulton do të jetë linja e regresionit empirik.
për koordinatat e pikave, ndërto ato në një sistem koordinativ dhe lidh me segmente të drejtëza. Vija e thyer që rezulton do të jetë linja e regresionit empirik.
Ekuacioni i regresionit teorik drejtvizor të Y në X është:
 ;
;
 , Ku
, Ku  - mostra mesatare e atributit
- mostra mesatare e atributit  ;
;
 - mostra mesatare e atributit
- mostra mesatare e atributit  .
.
 ;
;
 ;
; ;
;
 ;
; .
.
Ekuacioni i regresionit të drejtpërdrejtë të Y në X do të shkruhet si më poshtë:
 ose në fund
ose në fund 

Le të ndërtojmë të dy linjat e regresionit (Fig. 1)

Oriz. 1. Linjat e regresionit empirik dhe teorik
në  ;
; 
5. Ne do të bëjmë një interpretim kuptimplotë të rezultateve të analizës.
Ekziston një lidhje e ngushtë lineare e drejtpërdrejtë midis temperaturës së vajit lubrifikues të boshtit të pasmë të një automjeti dhe temperaturës së ajrit të ambientit ( r V=0.77). Kjo mund të thuhet me një probabilitet prej 0.95.
Ekuacioni  karakterizon sesi, mesatarisht, temperatura e vajit lubrifikues të boshtit të pasmë të një makine varet nga temperatura e ambientit.
karakterizon sesi, mesatarisht, temperatura e vajit lubrifikues të boshtit të pasmë të një makine varet nga temperatura e ambientit.
Koeficienti i regresionit linear (  ) sugjeron që nëse temperatura e ambientit rritet mesatarisht me 1 gradë, atëherë temperatura e vajit lubrifikues të boshtit të pasmë të makinës do të rritet mesatarisht me 0,25 gradë.
) sugjeron që nëse temperatura e ambientit rritet mesatarisht me 1 gradë, atëherë temperatura e vajit lubrifikues të boshtit të pasmë të makinës do të rritet mesatarisht me 0,25 gradë.
Ekuacioni  karakterizon se si temperatura e vajit lubrifikues të boshtit të pasmë të një automjeti varet nga temperatura e ambientit. Nëse temperatura e vajit lubrifikues të boshtit të pasmë të një makine duhet të rritet mesatarisht me 1 gradë, atëherë temperatura e ajrit të ambientit duhet të rritet mesatarisht me 2.34 gradë (
karakterizon se si temperatura e vajit lubrifikues të boshtit të pasmë të një automjeti varet nga temperatura e ambientit. Nëse temperatura e vajit lubrifikues të boshtit të pasmë të një makine duhet të rritet mesatarisht me 1 gradë, atëherë temperatura e ajrit të ambientit duhet të rritet mesatarisht me 2.34 gradë (  )
)
OPSIONET PËR DETYRA INDIVIDUALE
1. Shpërndarja e X - kostoja e aseteve fikse të prodhimit (milion rubla) dhe Y - prodhimi mesatar mujor për punëtor
2. Shpërndarja e 200 shtyllave cilindrike të llambave sipas gjatësisë X (në cm) dhe sipas peshës Y (në kg) jepet në tabelën e mëposhtme:
3. Shpërndarja e 100 firmave me anë të prodhimit X (në njësi monetare) dhe sipas prodhimit ditor Y (në tonë) jepet në tabelën e mëposhtme:
Me një numër të madh provash, e njëjta vlerë X mund të shfaqet nx herë, e njëjta vlerë Y mund të ndodhë ny herë dhe e njëjta çift numrash (x; y) mund të ndodhë nxy herë,
dhe zakonisht madhësia e kampionit.
Prandaj, të dhënat e vëzhgimit janë të grupuara, d.m.th., llogariten nx, ny, nxy. Të gjitha të dhënat e grupuara regjistrohen në formën e një tabele, e cila quhet tabelë korrelacioni.
Nëse të dy linjat e regresionit të Y në X dhe X në Y janë të drejta, atëherë korrelacioni është linear.
Ekuacioni i mostrës së vijës së regresionit të drejtë Y në X ka formën:

Parametrat pyx dhe B, të cilët përcaktohen me metodën e katrorëve më të vegjël, kanë formën:
ku yx është mesatarja e kushtëzuar; XВ dhe Ув janë mesataret e mostrës së karakteristikave X dhe Y; -x dhe -y janë devijime standarde të mostrës; gV është koeficienti i korrelacionit të mostrës.
Ekuacioni i mostrës së regresionit të drejtëz të X në Y ka formën:

Supozojmë se të dhënat vëzhguese për karakteristikat X dhe Y jepen në formën e një tabele korrelacioni me opsione të barabarta.
Pastaj kalojmë te opsionet e kushtëzuara:

ku C1 është varianti i tiparit X që ka frekuencën më të lartë; C 2 - variant i tiparit Y, i cili ka frekuencën më të lartë; h1 - hap (ndryshimi midis dy opsioneve ngjitur X); h2 - hap (ndryshimi midis dy opsioneve ngjitur Y).
Pastaj koeficienti i korrelacionit të mostrës

Sasitë u, v, su, sv mund të gjenden me metodën e produktit, ose drejtpërdrejt duke përdorur formulat
Duke ditur këto sasi, ne do të gjejmë parametrat e përfshirë në ekuacionet e regresionit duke përdorur formulat
PUNA TIPIKE KONTROLLI SIPAS SEKSIONIT 6. 12.1. Ngjarje të rastësishme
12.1. Ngjarje të rastësishme
12.1.1. Kutia përmban 6 palë doreza identike të zeza dhe 4 palë doreza identike bezhë. Gjeni probabilitetin që dy doreza të nxjerra rastësisht të formojnë një palë.
Merrni parasysh ngjarjen A - dy doreza të tërhequra rastësisht formojnë një palë; dhe hipotezat: B1 - janë nxjerrë një palë doreza të zeza, B2 - janë nxjerrë një palë doreza bezhë, B3 - dorezat e nxjerra nuk formojnë një palë.
Probabiliteti i hipotezës B1 nga teorema e shumëzimit është i barabartë me produktin e probabiliteteve që doreza e parë të jetë e zezë dhe dorashka e dytë të jetë e zezë, d.m.th.
Në mënyrë të ngjashme, probabiliteti i hipotezës Bi është:
Meqenëse hipotezat B1, B2 dhe B3 përbëjnë një grup të plotë ngjarjesh, probabiliteti i hipotezës B3 është i barabartë me:
Sipas formulës së probabilitetit total, kemi:
ku Pb (A) është probabiliteti që një çift të formohet nga dy doreza të zeza dhe Pb1 (A) = 1; pB1 (A) është probabiliteti që dy doreza bezhë të formojnë një palë dhe Pb2 (A) = 1; dhe, së fundi, РВз(A) - probabiliteti që një palë të formohet nga doreza me ngjyra të ndryshme dhe

Kështu, probabiliteti që dy doreza të nxjerra rastësisht të formojnë një palë është e barabartë me
12.1.2. Urna përmban 3 topa të bardhë dhe 5 topa të zinj. Tërhiqen 3 topa në mënyrë të rastësishme, një nga një dhe pas çdo nxjerrjeje ato kthehen në urnë. Gjeni probabilitetin që midis topave të tërhequr të ketë:
a) saktësisht dy topa të bardhë, b) të paktën dy topa të bardhë.
Zgjidhje. Ne kemi një skemë me kthim, pra çdo herë përbërja e topave nuk ndryshon:
a) kur tërhiqen tre topa, dy prej tyre duhet të jenë të bardhë dhe një i zi. Në këtë rast, e zeza mund të jetë ose e para, ose e dyta ose e treta. Duke zbatuar teoremat e mbledhjes dhe shumëzimit të probabiliteteve së bashku, kemi:

b) nxjerrja e të paktën dy topa të bardhë do të thotë se duhet të ketë ose dy ose tre topa të bardhë:

12.1.3. Urna përmban 6 topa të bardhë dhe 5 të zinj. Tre topa tërhiqen në mënyrë të rastësishme me radhë pa i kthyer ato në urnë. Gjeni probabilitetin që topi i tretë me radhë të jetë i bardhë.
Zgjidhje. Nëse topi i tretë duhet të jetë i bardhë, atëherë dy topat e parë mund të jenë të bardhë, ose të bardhë dhe të zi, ose bardh e zi, ose të zi, d.m.th. ekzistojnë katër grupe të jo-
ngjarje të përbashkëta. Duke zbatuar teoremën e shumëzimit të probabilitetit për to, marrim:
P = P1 (5 . P2 (5 . P3 (5 + (P1 (5 . P2ch. P3 (5 + P14 . P2 (5 . P3 (5) + P1ch. P2ch. P3 (5 =
A A 4 A A 5 A A 5 A A 6=540 = A
F. 10. 9 + I. 10. 9 + I. 10. 9 + I. 10. 9 = 990 = IT
Çfarë është regresioni?
Konsideroni dy ndryshore të vazhdueshme x=(x 1, x 2, .., x n), y=(y 1, y 2, ..., y n).
Le t'i vendosim pikat në një komplot shpërndarjeje dydimensionale dhe të themi se kemi lidhje lineare, nëse të dhënat përafrohen me një vijë të drejtë.
Nëse besojmë se y varet nga x, dhe ndryshimet në y shkaktohen pikërisht nga ndryshimet në x, mund të përcaktojmë vijën e regresionit (regresion y në x), i cili përshkruan më së miri marrëdhënien lineare midis këtyre dy variablave.
Përdorimi statistikor i fjalës regresion vjen nga fenomeni i njohur si regresion në mesatare, që i atribuohet Sir Francis Galton (1889).
Ai tregoi se megjithëse baballarët e gjatë priren të kenë djem të gjatë, gjatësia mesatare e djemve është më e shkurtër se ajo e baballarëve të tyre të gjatë. Gjatësia mesatare e djemve "regresoi" dhe "u zhvendos prapa" drejt gjatësisë mesatare të të gjithë baballarëve në popullatë. Kështu, mesatarisht, baballarët e gjatë kanë djem më të shkurtër (por ende mjaft të gjatë), dhe baballarët e shkurtër kanë djem më të gjatë (por ende mjaft të shkurtër).
Linja e regresionit
Një ekuacion matematik që vlerëson një vijë të thjeshtë regresioni linear (në çift):
x quhet ndryshore e pavarur ose parashikues.
Y- variabli i varur ose variabli i përgjigjes. Kjo është vlera që ne presim y(mesatarisht) nëse e dimë vlerën x, d.m.th. kjo është "vlera e parashikuar" y»
- a- anëtar (kryqëzimi) i lirë i vijës së vlerësimit; ky është kuptimi Y, Kur x=0(Fig.1).
- b- pjerrësia ose pjerrësia e vijës së vlerësuar; paraqet shumën me të cilën Y rritet mesatarisht nëse rritemi x për një njësi.
- a Dhe b quhen koeficientë regresioni të vijës së vlerësuar, megjithëse ky term shpesh përdoret vetëm për b.
Regresioni linear në çift mund të zgjerohet për të përfshirë më shumë se një ndryshore të pavarur; në këtë rast njihet si regresioni i shumëfishtë.
Fig.1. Vija e regresionit linear që tregon ndërprerjen a dhe pjerrësinë b (shuma Y rritet kur x rritet me një njësi)
Metoda e katrorëve më të vegjël
Ne kryejmë analizën e regresionit duke përdorur një mostër vëzhgimesh ku a Dhe b- vlerësimet e mostrave të parametrave të vërtetë (të përgjithshëm), α dhe β, të cilët përcaktojnë vijën e regresionit linear në popullatë (popullata e përgjithshme).
Metoda më e thjeshtë për përcaktimin e koeficientëve a Dhe bështë Metoda e katrorëve më të vegjël(MNC).
Përshtatja vlerësohet duke parë mbetjet (distanca vertikale e secilës pikë nga vija, p.sh. mbetje = vëzhguar y- parashikoi y, Oriz. 2).
Linja e përshtatjes më të mirë zgjidhet në mënyrë që shuma e katrorëve të mbetjeve të jetë minimale.

Oriz. 2. Vija e regresionit linear me mbetjet e paraqitura (vija vertikale me pika) për secilën pikë.
Supozimet e regresionit linear
Pra, për secilën vlerë të vëzhguar, mbetja është e barabartë me diferencën dhe vlera e parashikuar përkatëse mund të jetë pozitive ose negative.
Ju mund të përdorni mbetjet për të testuar supozimet e mëposhtme pas regresionit linear:
- Mbetjet zakonisht shpërndahen me një mesatare prej zero;
Nëse supozimet e linearitetit, normalitetit dhe/ose variancës konstante janë të dyshimta, ne mund të transformojmë ose dhe të llogarisim një vijë të re regresioni për të cilën këto supozime plotësohen (për shembull, të përdorim një transformim logaritmik, etj.).
Vlerat anormale (të jashtme) dhe pikat e ndikimit
Një vëzhgim "ndikues", nëse hiqet, ndryshon një ose më shumë vlerësime të parametrave të modelit (dmth. pjerrësia ose ndërprerja).
Një vëzhgim i jashtëm (një vëzhgim që nuk është në përputhje me shumicën e vlerave në një grup të dhënash) mund të jetë një vëzhgim "ndikues" dhe mund të zbulohet lehtësisht vizualisht duke inspektuar një grafik shpërhapjeje me dy variacione ose grafik të mbetur.
Si për pikat e jashtme, ashtu edhe për vëzhgimet (pikat) "ndikues", përdoren modele, si me përfshirjen e tyre ashtu edhe pa ato, dhe vëmendje i kushtohet ndryshimeve në vlerësime (koeficientët e regresionit).
Kur kryeni një analizë, nuk duhet të hiqni automatikisht pikat e jashtme ose pikat e ndikimit, pasi thjesht injorimi i tyre mund të ndikojë në rezultatet e marra. Gjithmonë studioni arsyet e këtyre të dhënave dhe analizoni ato.
Hipoteza e regresionit linear
Kur ndërtohet regresioni linear, testohet hipoteza zero se pjerrësia e përgjithshme e vijës së regresionit β është e barabartë me zero.
Nëse pjerrësia e vijës është zero, nuk ka lidhje lineare midis dhe: ndryshimi nuk ndikon
Për të testuar hipotezën zero se pjerrësia e vërtetë është zero, mund të përdorni algoritmin e mëposhtëm:
Llogaritni statistikën e testit të barabartë me raportin , i cili i nënshtrohet një shpërndarjeje me shkallë lirie, ku gabimi standard i koeficientit

 ,
,
 - vlerësimi i dispersionit të mbetjeve.
- vlerësimi i dispersionit të mbetjeve.
Në mënyrë tipike, nëse arrihet niveli i rëndësisë, hipoteza zero refuzohet.
![]()
ku është pika e përqindjes së shpërndarjes me shkallë lirie, e cila jep probabilitetin e një testi të dyanshëm
Ky është intervali që përmban pjerrësinë e përgjithshme me një probabilitet prej 95%.
Për mostrat e mëdha, të themi, mund të përafrojmë një vlerë prej 1.96 (d.m.th., statistikat e testimit do të priren të shpërndahen normalisht)
Vlerësimi i cilësisë së regresionit linear: koeficienti i përcaktimit R 2
Për shkak të marrëdhënies lineare dhe ne presim që të ndryshojë si
, dhe e quajmë atë variacion që është për shkak ose shpjegohet me regresion. Variacioni i mbetur duhet të jetë sa më i vogël që të jetë e mundur.
Nëse kjo është e vërtetë, atëherë shumica e variacionit do të shpjegohet me regresion, dhe pikat do të qëndrojnë afër vijës së regresionit, d.m.th. rreshti i përshtatet mirë të dhënave.
Përqindja e variancës totale që shpjegohet me regresion quhet koeficienti i përcaktimit, zakonisht shprehet si përqindje dhe shënohet R 2(në regresionin linear të çiftuar kjo është sasia r 2, katrori i koeficientit të korrelacionit), ju lejon të vlerësoni subjektivisht cilësinë e ekuacionit të regresionit.
Diferenca paraqet përqindjen e variancës që nuk mund të shpjegohet me regresion.
Nuk ka asnjë test formal për të vlerësuar ne duhet të mbështetemi në gjykimin subjektiv për të përcaktuar mirësinë e përshtatjes së linjës së regresionit.
Zbatimi i një linje regresioni për parashikimin
Ju mund të përdorni një linjë regresioni për të parashikuar një vlerë nga një vlerë në skajin ekstrem të diapazonit të vëzhguar (kurrë mos e ekstrapoloni përtej këtyre kufijve).
Ne parashikojmë mesataren e vëzhguesve që kanë një vlerë të veçantë duke e futur atë vlerë në ekuacionin e vijës së regresionit.
Pra, nëse parashikojmë si Përdorni këtë vlerë të parashikuar dhe gabimin e tij standard për të vlerësuar një interval besimi për mesataren e vërtetë të popullsisë.
Përsëritja e kësaj procedure për vlera të ndryshme ju lejon të ndërtoni kufijtë e besimit për këtë linjë. Ky është brezi ose zona që përmban vijën e vërtetë, për shembull në nivelin 95% të besimit.
Plane të thjeshta regresioni
Modelet e thjeshta të regresionit përmbajnë një parashikues të vazhdueshëm. Nëse ka 3 vëzhgime me vlera parashikuese P, të tilla si 7, 4 dhe 9, dhe dizajni përfshin një efekt të rendit të parë P, atëherë matrica e projektimit X do të jetë

dhe ekuacioni i regresionit duke përdorur P për X1 është
Y = b0 + b1 P
Nëse një dizajn i thjeshtë regresioni përmban një efekt të rendit më të lartë në P, siç është një efekt kuadratik, atëherë vlerat në kolonën X1 në matricën e projektimit do të ngrihen në fuqinë e dytë:

dhe ekuacioni do të marrë formën
Y = b0 + b1 P2
Metodat e kodimit të kufizuara nga Sigma dhe të mbiparametizuara nuk zbatohen për dizajne të thjeshta regresioni dhe modele të tjera që përmbajnë vetëm parashikues të vazhdueshëm (sepse thjesht nuk ka parashikues kategorikë). Pavarësisht nga metoda e zgjedhur e kodimit, vlerat e ndryshoreve të vazhdueshme rriten në përputhje me rrethanat dhe përdoren si vlera për ndryshoret X. Në këtë rast, nuk kryhet rikodim. Përveç kësaj, kur përshkruani planet e regresionit, mund të mos merrni parasysh matricën e projektimit X dhe të punoni vetëm me ekuacionin e regresionit.
Shembull: Analiza e thjeshtë e regresionit
Ky shembull përdor të dhënat e paraqitura në tabelë:

Oriz. 3. Tabela e të dhënave fillestare.
Të dhënat e përpiluara nga një krahasim i regjistrimeve të 1960 dhe 1970 në 30 qarqe të zgjedhura rastësisht. Emrat e qarqeve paraqiten si emra vëzhgimi. Informacioni në lidhje me secilën variabël është paraqitur më poshtë:

Oriz. 4. Tabela e specifikimeve të variablave.
Problemi i kërkimit
Për këtë shembull, do të analizohet korrelacioni ndërmjet shkallës së varfërisë dhe shkallës që parashikon përqindjen e familjeve që janë nën kufirin e varfërisë. Prandaj, ne do ta trajtojmë variablin 3 (Pt_Poor) si variabël të varur.
Mund të parashtrojmë një hipotezë: ndryshimet në madhësinë e popullsisë dhe përqindja e familjeve që janë nën kufirin e varfërisë janë të lidhura. Duket e arsyeshme të pritet që varfëria të çojë në migrim jashtë, kështu që do të kishte një korrelacion negativ midis përqindjes së njerëzve nën kufirin e varfërisë dhe ndryshimit të popullsisë. Prandaj, ne do ta trajtojmë variablin 1 (Pop_Chng) si një ndryshore parashikuese.
Shiko rezultatet
Koeficientët e regresionit

Oriz. 5. Koeficientët e regresionit të Pt_Poor në Pop_Chng.
Në kryqëzimin e rreshtit Pop_Chng dhe kolonës Param.<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
koeficienti i pa standardizuar për regresionin e Pt_Poor në Pop_Chng është -0.40374. Kjo do të thotë se për çdo njësi ulje të popullsisë, ka një rritje të shkallës së varfërisë prej .40374. Kufijtë e sipërm dhe të poshtëm (të parazgjedhur) 95% të besimit për këtë koeficient të pa standardizuar nuk përfshijnë zero, kështu që koeficienti i regresionit është i rëndësishëm në nivelin p.
Koeficientët e korrelacionit mund të mbivlerësohen ose nënvlerësohen ndjeshëm nëse në të dhëna janë të pranishme vlera të mëdha të jashtme. Le të studiojmë shpërndarjen e ndryshores së varur Pt_Poor sipas rretheve. Për ta bërë këtë, le të ndërtojmë një histogram të ndryshores Pt_Poor.

Oriz. 6. Histogrami i ndryshores Pt_Poor.
Siç mund ta shihni, shpërndarja e kësaj variabli ndryshon dukshëm nga shpërndarja normale. Megjithatë, edhe pse edhe dy qarqe (dy kolonat djathtas) kanë një përqindje më të lartë të familjeve që janë nën kufirin e varfërisë sesa pritej në një shpërndarje normale, ato duket se janë "brenda kufirit".

Oriz. 7. Histogrami i ndryshores Pt_Poor.
Ky gjykim është disi subjektiv. Rregulli i përgjithshëm është që të dhënat e jashtme duhet të merren parasysh nëse vëzhgimi (ose vëzhgimet) nuk bien brenda intervalit (mesatarja ± 3 herë devijimi standard). Në këtë rast, ia vlen të përsëritet analiza me dhe pa pika të jashtme për t'u siguruar që ato të mos kenë një efekt të madh në korrelacionin midis anëtarëve të popullsisë.
Scatterplot
Nëse një nga hipotezat është a priori për marrëdhënien midis variablave të dhënë, atëherë është e dobishme ta testoni atë në grafikun e scatterplot-it përkatës.

Oriz. 8. Diagrami i shpërndarjes.
Skaterploti tregon një korrelacion të qartë negativ (-.65) midis dy variablave. Ai gjithashtu tregon intervalin 95% të besimit për vijën e regresionit, d.m.th., ka një probabilitet 95% që vija e regresionit të shtrihet midis dy kthesave të ndërprera.
Kriteret e rëndësisë

Oriz. 9. Tabela që përmban kriteret e rëndësisë.
Testi për koeficientin e regresionit Pop_Chng konfirmon se Pop_Chng është i lidhur fort me Pt_Poor, p.<.001 .
Fundi
Ky shembull tregoi se si të analizohet një dizajn i thjeshtë regresioni. U prezantuan edhe interpretimet e koeficientëve të regresionit të pa standardizuar dhe të standardizuar. Diskutohet rëndësia e studimit të shpërndarjes së përgjigjes së një variabli të varur dhe demonstrohet një teknikë për përcaktimin e drejtimit dhe forcës së marrëdhënies midis një parashikuesi dhe një ndryshoreje të varur.
Faqja e kopertinës së formularit metodologjik
Ministria e Arsimit dhe Shkencës e Republikës së Kazakistanit
«
Kryetari i UMC-së _______________ « ___"___________20__
MIRATUAR:
Shefi i OPiMOUP _________________ « ___"___________20__
Miratuar nga këshilli arsimor dhe metodologjik i universitetit
« ___»___________20 __ Protokolli nr.____
Kur studioni temën " Informacion nga teoria e probabilitetit dhe statistikat matematikore”, vëmendje e veçantë duhet t'i kushtohet metodave të paraqitjes dhe përpunimit të të dhënave statistikore. Karakteristikat teorike dhe selektive. Skema e përgjithshme për testimin e hipotezave. Gabimet e llojit 1 dhe 2. Vlerësimet e pikës dhe intervalit. Vetitë statistikore të vlerësimeve. Analiza e varësive të dy ndryshoreve të rastësishme.
Subjekti. Metoda e katrorëve më të vegjël.
h1, h2 - hapat, d.m.th. ndryshimi midis dy opsioneve fqinje.
Në këtë rast, koeficienti i korrelacionit të mostrës
 ,
,
Për më tepër, termi është i përshtatshëm për t'u llogaritur duke përdorur tabelën e llogaritjes 1.
Vlerat mund të gjenden duke përdorur formulat
Për tranzicionin e kundërt, përdoren shprehjet
Shembull Gjeni mostrën e ekuacionit të regresionit linear të Y në X bazuar në tabelën e korrelacionit.
Zgjidhje. Për të thjeshtuar llogaritjet, le të kalojmë në opsionet e kushtëzuara, të cilat llogariten duke përdorur formulat
, 
dhe krijoni një tabelë korrelacioni të transformuar me opsione të kushtëzuara
Pastaj do të përpilojmë një tabelë të re në të cilën do të fusim vlerat e llogaritura në këndin e sipërm të djathtë të qelizës së mbushur dhe në këndin e poshtëm të majtë, pas së cilës mbledhim vlerat e sipërme në rreshta për të marrë vlerat. Vj dhe vlerat më të ulëta në kolonat për Ui dhe llogaritni vlerat dhe .
vjVj |
||||||||
Dy ndryshore të rastësishme mund të lidhen ose nga një varësi funksionale, ose një varësi statistikore, ose të jenë të pavarura. Një varësi e rreptë funksionale realizohet rrallë, pasi të dyja ose njëra nga dy sasitë janë gjithashtu subjekt i ndikimit të faktorëve të rastësishëm. Për më tepër, midis këtyre faktorëve mund të ketë disa të përbashkëta për të dyja sasitë, d.m.th. duke prekur të dy variablat e rastësishëm. Në këto raste, lind një varësi statistikore.
Statistikoreështë një varësi në të cilën një ndryshim në njërën nga sasitë sjell një ndryshim në shpërndarjen e tjetrës. Në veçanti, një ndryshim në njërën nga sasitë shkakton një ndryshim në vlerën mesatare të tjetrës. Në këtë rast quhet varësia statistikore korrelacioni. Për shembull, lidhja midis sasisë së plehut dhe të korrave, midis fondeve të investuara dhe fitimit.
Mesatarja aritmetike e vlerave të vëzhguara të ndryshores së rastësishme Y që korrespondon me vlerën X=x quhet mesatare e kushtëzuar x dhe është një vlerësim pikësor i pritshmërisë matematikore . Mesatarja e kushtëzuar y përcaktohet në mënyrë të ngjashme.
Pritshmëria matematikore e kushtëzuar M(Y|x)është një funksion i x, prandaj vlerësimi i tij, d.m.th. mesatare e kushtëzuar x, gjithashtu një funksion i x:
x = f*(x).
Ky ekuacion quhet ekuacioni i regresionit të mostrës së Y në X. Funksioni f*(x) thirrur regresioni i mostrës, dhe grafiku i tij është kampion i linjës së regresionit të Y në X. Në mënyrë të ngjashme, barazimi.
Y = φ * (y),
funksionin φ * (y) dhe orari i saj quhet ekuacioni i regresionit të mostrës, regresioni i mostrës dhe linja e regresionit të mostrës X në Y.
Gjetja e parametrave të funksionit f*(x) Dhe φ * (y), nëse dihet lloji i tyre, vlerësimi i afërsisë së marrëdhënies midis madhësive X dhe Y është problem analiza e korrelacionit. Detyra e analizës së regresionit është të vlerësojë parametrat e funksionit të regresionit β i dhe variancës së mbetur σ ost 2 .
Varianca e mbetur është ajo pjesë e dispersionit Y që nuk mund të shpjegohet me veprimin e X. σ mbetja 2 mund të shërbejë për të vlerësuar saktësinë e përzgjedhjes së funksionit të regresionit dhe plotësinë e grupit të veçorive të përfshira në analizë. Lloji i varësisë g(x) zgjidhet në bazë të natyrës së fushës së korrelacionit dhe natyrës së procesit.
Vlerësimi i koeficientit të regresionit linear β është koeficienti i regresionit të mostrës së Y në X r yx. Vlerat e parametrave r yx dhe parametri b ekuacionet e regresionit të drejtë
Y = r yx x + b
zgjidhen në atë mënyrë që pikat (x 1 ,y 1), (x 2 ,y 2),…,(x n ,y n), të ndërtuara nga të dhënat e vëzhgimit, në rrafshin xOy të shtrihen sa më afër të jetë e mundur me të drejtën vija e regresionit. Kjo është ekuivalente me kërkesën që shuma e devijimeve në katror të funksionit Y(x i) nga y i të jetë minimale. Ky është thelbi i MNC-ve.
Ekuacioni i mostrës së një linje regresioni të drejtë të Y në X mund të shkruhet si më poshtë:
x -= r në s y /s x (x - ) ,
ku s x dhe s y janë devijimet standarde të mostrës së X dhe Y, dhe
r në =  –
–
koeficienti i korrelacionit të mostrës i llogaritur nga të dhënat e grupuara. Këtu n xy është frekuenca e çiftit të variantit (x,y). Në mënyrë të ngjashme, gjeni ekuacionin e mostrës së vijës së drejtë të regresionit X në Y:
Y – = r në s x / s y (y -)
Për të përcaktuar nëse modeli matematik i marrëdhënies midis Y dhe X i gjetur në kampion korrespondon me të dhënat statistikore, duhet vlerësuar rëndësia e koeficientëve të regresionit dhe rëndësia e ekuacionit të regresionit.
Testimi i rëndësisë së koeficientëve të regresionit nënkupton përcaktimin nëse madhësia e vlerësimit është e mjaftueshme për të mbështetur një përfundim të arsyeshëm se koeficienti i regresionit është i ndryshëm nga zero. Parashtrohet hipoteza H 0: koeficienti i regresionit është i barabartë me zero β =0. Hipoteza H0 testohet duke përdorur statistika të shpërndara sipas ligjit të Studentit
t = │b / s b │
Ku bështë vlerësimi i koeficientit të regresionit, dhe s b- një vlerësim i devijimit standard të tij, me fjalë të tjera, gabimi standard i vlerësimit. Nëse │t │≥ t cr (α, k), hipoteza zero se koeficienti i regresionit është i barabartë me zero refuzohet dhe koeficienti konsiderohet i rëndësishëm. Në │t │< t кр нет оснований отвергать нулевую гипотезу.