Функция распределения в этом случае согласно (5.7), примет вид:
где: m – математическое ожидание, s– среднеквадратическое отклонение.
Нормальное распределение называют еще гауссовским по имени немецкого математика Гаусса . Тот факт, что случайная величина имеет нормальное распределение с параметрами: m,, обозначают так: N (m,s), где: m =a =M ;
Достаточно часто в формулах математическое ожидание обозначают через а . Если случайная величина распределена по закону N(0,1), то она называется нормированной или стандартизированной нормальной величиной. Функция распределения для нее имеет вид:
|
|
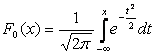 .
.График плотности нормального распределения, который называют нормальной кривой или кривой Гаусса, изображен на рис.5.4.

Рис. 5.4. Плотность нормального распределения
Определение числовых характеристик случайной величины по её плотности рассматривается на примере.
Пример 6 .
Непрерывная случайная величина задана плотностью распределения:![]() .
.
Определить вид распределения, найти математическое ожидание M(X) и дисперсию D(X).
Сравнивая заданную плотность распределения с (5.16) можно сделать вывод, что задан нормальный закон распределения с m =4. Следовательно, математическое ожидание M(X)=4, дисперсия D(X)=9.
Среднее квадратическое отклонение s=3.
Функция Лапласа, имеющая вид:
|
|
 ,
,связана с функцией нормального распределения (5.17), cоотношением:
F 0 (x) = Ф(х) + 0,5.
Функции Лапласа нечётная.
Ф(-x )=-Ф(x ).
Значения функции Лапласа Ф(х) табулированы и берутся из таблицы по значению х (см. Приложение 1).
Нормальное распределение непрерывной случайной величины играет важную роль в теории вероятностей и при описании реальности, имеет очень широкое распространение в случайных явлениях природы. На практике очень часто встречаются случайные величины, образующиеся именно в результате суммирования многих случайных слагаемых. В частности, анализ ошибок измерения показывает, что они являются суммой разного рода ошибок. Практика показывает, что распределение вероятностей ошибок измерения близко к нормальному закону.
С помощью функции Лапласа можно решать задачи вычисления вероятности попадания в заданный интервал и заданного отклонения нормальной случайной величины.
В чем состоит идея вероятностных рассуждений?Первый, самый естественный шаг вероятностных рассуждений заключается в следующем: если вы имеете некоторую переменную, принимающую значения случайным образом, то вам хотелось бы знать, с какими вероятностями эта переменная принимает определенные значения. Совокупность этих вероятностей как раз и задает распределение вероятностей. Например, имея игральную кость, можно a priori считать, что с равными вероятностями 1/6 она упадет на любую грань. И это происходит при условии, что кость симметричная. Если кость несимметричная, то можно определить большие вероятности для тех граней, которые выпадают чаще, а меньшие вероятности - для тех граней, которые выпадают реже, исходя из опытных данных. Если какая-то грань вообще не выпадает, то ей можно присвоить вероятность 0. Это и есть простейший вероятностный закон, с помощью которого можно описать результаты бросания кости. Конечно, это чрезвычайно простой пример, но аналогичные задачи возникают, например, при актуарных расчетах, когда на основе реальных данных рассчитывается реальный риск при выдаче страхового полиса.
В этой главе мы рассмотрим вероятностные законы, наиболее часто возникающие на практике.
Графики этих распределений можно легко построить в STATISTICA.
Нормальное распределение
Нормальное распределение вероятностей особенно часто используется в статистике. Нормальное распределение дает хорошую модель для реальных явлений, в которых:
1) имеется сильная тенденция данных группироваться вокруг центра;
2) положительные и отрицательные отклонения от центра равновероятны;
3) частота отклонений быстро падает, когда отклонения от центра становятся большими.
Механизм, лежащий в основе нормального распределения, объясняемый с помощью так называемой центральной предельной теоремы, можно образно описать следующим образом. Представьте, что у вас имеются частицы цветочной пыльцы, которые вы случайным образом бросили в стакан воды. Рассматривая отдельную частицу под микроскопом, вы увидите удивительное явление - частица движется. Конечно, это происходит, потому что перемещаются молекулы воды и передают свое движение частицам взвешенной пыльцы.
Но как именно происходит движение? Вот более интересный вопрос. А это движение очень причудливо!
Имеется бесконечное число независимых воздействий на отдельную частицу пыльцы в виде ударов молекул воды, которые заставляют частицу двигаться по весьма странной траектории. Под микроскопом это движение напоминает многократно и хаотично изломанную линию. Эти изломы невозможно предсказать, в них нет никакой закономерности, что как раз и соответствует хаотическим ударам молекул о частицу. Взвешенная частица, испытав удар молекулы воды в случайный момент времени, меняет направление своего движения, далее некоторое время движется по инерции, затем вновь попадает под удар следующей молекулы и так далее. Возникает удивительный бильярд в стакане воды!
Поскольку движение молекул имеет случайное направление и скорость, то величина и направление изломов траектории также совершенно случайны и непредсказуемы. Это удивительное явление, называемое броуновским движением, открытое в XIX веке, заставляет нас задуматься о многом.
Если ввести подходящую систему и отмечать координаты частицы через некоторые моменты времени, то как раз и получим нормальный закон. Более точно, смещения частицы пыльцы, возникающие из-за ударов молекул, будут подчиняться нормальному закону.
Впервые закон движения такой частицы, называемого броуновским, на физическом уровне строгости описал А. Эйнштейн. Затем более простой и интуитивно ясный подход развил Ленжеван.
Математики в XX веке посвятили этой теории лучшие страницы, а первый шаг был сделан 300 лет назад, когда был открыт простейший вариант центральной предельной теоремы.
В теории вероятности центральная предельная теорема, первоначально известная в формулировке Муавра и Лапласа еще в XVII веке как развитие знаменитого закона больших чисел Я. Бернулли (1654-1705) (см. Я. Бернулли (1713), Ars Conjectandi), в настоящее время чрезвычайно развилась и достигла своих высот. в современном принципе инвариантности, в создании которого существенную роль сыграла русская математическая школа. Именно в этом принципе находит свое строгое математическое объяснение движение броуновской частицы.
Идея состоит в том, что при суммировании большого числа независимых величин (ударов молекул о частицы пыльцы) в определенных разумных условиях получаются именно нормально распределенные величины. И это происходит независимо, то есть инвариантно, от распределения исходных величин. Иными словами, если на некоторую переменную воздействует множество факторов, эти воздействия независимы, относительно малы и слагаются друг с другом, то получаемая в итоге величина имеет нормальное распределение.
Например, практически бесконечное количество факторов определяет вес человека (тысячи генов, предрасположенность, болезни и т. д.). Таким образом, можно ожидать нормальное распределение веса в популяции всех людей.
Если вы финансист и занимаетесь игрой на бирже, то, конечно, вам известны случаи, когда курсы акций ведут себя подобно броуновским частицам, испытывая хаотические удары многих факторов.

Формально плотность нормального распределения записывается так:

где а и õ 2 - параметры закона, интерпретируемые соответственно как среднее значение и дисперсия данной случайной величины (ввиду особой роли нормального распределения мы будем использовать специальную символику для обозначения его функции плотности и функции распределения). Визуально график нормальной плотности - это знаменитая колоколообразная кривая.
Соответствующая функция распределения нормальной случайной величины (а,õ 2) обозначается Ф(x; a,õ 2) и задается соотношением:

Нормальный закон с параметрами а = 0 и õ 2 = 1 называется стандартным.
Обратная функция стандартного нормального распределения, примененная к величине
z, 0 Воспользуйтесь вероятностным калькулятором STATISTICA, чтобы по х вычислить z и наоборот. Основные характеристики нормального закона: Среднее, мода, медиана: Е=x mod =x med =a; Дисперсия: D=õ 2 ; Ассиметрия: Эксцесс: Из формул видно, что нормальное распределение описывается двумя параметрами: а - mean - среднее; õ - stantard deviation - стандартное отклонение, читается: «сигма». Иногда стандартное отклонение называют среднеквадратическим отклонением
, но это уже устаревшая терминология. Приведем некоторые полезные факты относительно нормального распределения. Среднее значение определяет меру расположения плотности. Плотность нормального распределения симметрична относительно среднего. Среднее нормального распределения совпадает с медианой и модой (см. графики). Плотность нормального распределения с дисперсией 1 и средним 1 Плотность нормального распределения со средним 0 и дисперсией 0,01 Плотность нормального распределения со средним 0 и дисперсией 4 При увеличении дисперсии плотность нормального распределения расплывается или растекается вдоль оси ОХ, при уменьшении дисперсии она, наоборот, сжимается, концентрируясь вокруг одной точки - точки максимального значения, совпадающей со средним значением. В предельном случае нулевой дисперсии случайная величина вырождается и принимает единственное значение, равное среднему. Полезно знать правила 2- и 3-сигма, или 2- и 3-стандартных отклонений, которые связаны с нормальным распределением и используются в разнообразных приложениях. Смысл этих правил очень простой. Если от точки среднего или, что то же самое, от точки максимума плотности нормального распределения отложить вправо и влево соответственно два и три стандартных отклонения (2- и 3-сигма), то площадь под графиком нормальной плотности, подсчитанная по этому промежутку, будет соответственно равна 95,45% и 99,73% всей площади под графиком (проверьте на вероятностном калькуляторе STATISTICA!). Другими словами, это можно выразить следующим образом: 95,45% и 99,73% всех независимых наблюдений из нормальной совокупности, например размеров детали или цены акций, лежит в зоне 2- и 3-стандартных отклонений от среднего значения. Равномерное распределение
Равномерное распределение полезно при описании переменных, у которых каждое значение равновероятно, иными словами, значения переменной равномерно распределены в некоторой области. Ниже приведены формулы плотности и функции распределения равномерной случайной величины, принимающей значения на отрезке [а,
b]. Из этих формул легко понять, что вероятность того, что равномерная случайная величина примет значения из множества
[с, d]
[а, b], равна (d - c)/(b - a).
Положим а=0,b=1. Ниже показан график равномерной плотности вероятности, сосредоточенной на отрезке .
Числовые характеристики равномерного закона: Экспоненциальное распределение
Имеют место события, которые на обыденном языке можно назвать редкими. Если Т - время между наступлениями редких событий, происходящих в среднем с интенсивностью X, то величина Это распределение обладает очень интересным свойством отсутствия последействия, или, как еще говорят, марковским свойством, в честь знаменитого русского математика Маркова А. А., которое можно объяснить следующим образом. Если распределение между моментами наступления некоторых событий является показательным, то распределение, отсчитанное от любого момента
t до следующего события, также имеет показательное распределение (с тем же самым параметром).
Иными словами, для потока редких событий время ожидания следующего посетителя всегда распределено показательно независимо от того, сколько времени вы его уже ждали. Показательное распределение связано с пуассоновским распределением: в единичном интервале времени количество событий, интервалы между которыми независимы и показательно распределены, имеет распределение Пуассона. Если интервалы между посещениями сайта имеют экспоненциальное распределение, то количество посещений, например в течение часа, распределено по закону Пуассона. Показательное распределение представляет собой частный случай распределения Вейбулла. Если время не непрерывно, а дискретно, то аналогом показательного распределения является геометрическое распределение. Плотность экспоненциального распределения описывается формулой: Это распределение имеет только один параметр, который и определяет его характеристики. График плотности показательного распределения имеет вид: Основные числовые характеристики экспоненциального распределения: Распределение Эрланга
Это непрерывное распределение сосредоточено на (0,1) и имеет плотность: Математическое ожидание и дисперсия равны соответственно Распределение Эрланга названо в честь А. Эрланга (A. Erlang), впервые применившего его в задачах теории массового обслуживания и телефонии. Распределение Эрланга с параметрами µ и n является распределением суммы п независимых, одинаково распределенных случайных величин, каждая из которых имеет показательное распределение с параметром
nµ При n = 1 распределение Эрланга совпадает с показательным или экспоненциальным распределением.
Распределение Лапласа
Функция плотности распределения Лапласа, или, как его еще называют, двойного экспоненциального, используется, например, для описания распределения ошибок в моделях регрессии. Взглянув на график этого распределения, вы увидите, что оно состоит из двух экспоненциальных распределений, симметричных относительно оси OY. Если параметр положения равен 0, то функция плотности распределения Лапласа имеет вид: Основные числовые характеристики этого закона распределения в предположении, что параметр положения нулевой, выглядят следующим образом: В общем случае плотность распределения Лапласа имеет вид: а - среднее распределения; b - параметр масштаба; е - число Эйлера (2,71...). Гамма-распределение
Плотность экспоненциального распределения имеет моду в точке 0, и это иногда неудобно для практических применений. Во многих примерах заранее известно, что мода рассматриваемой случайной переменной не равна 0, например, интервалы между приходами покупателей в магазин электронной торговли или заходами на сайт имеют ярко выраженную моду. Для моделирования таких событий используется гамма-распределение. Плотность гамма-распределения имеет вид: где Г - Г-функция Эйлера, а > 0 - параметр «формы» и b >
0 - параметр масштаба. В частном случае имеем распределение Эрланга и экспоненциальное распределение. Основные характеристики гамма-распределения: Ниже приведены два графика плотности гамма-распределения с параметром масштаба, равным 1, и параметрами формы, равными 3 и 5. Полезное свойство гамма-распределения: сумма любого числа независимых гамма-распределенных случайных величин (с одинаковым параметром масштаба
b) (a l ,b) + (a 2 ,b) + --- +(a n ,b)
также подчиняется гамма-распределению, но с параметрами а 1 +
а 2 + + а n и b.
Логнормальное распределение
Случайная величина h называется логарифмически нормальной, или логнормальной, если ее натуральный логарифм
(lnh) подчинен нормальному закону распределения. Логнормальное распределение используется, например, при моделировании таких переменных, как доходы, возраст новобрачных или допустимое отклонение от стандарта вредных веществ в продуктах питания. Итак, если величина x имеет нормальное распределение, то величина
у = е x имеет Логнормальное распределение.
Если вы подставите нормальную величину в степень экспоненты, то легко поймете, что логнормальная величина получается в результате многократных умножений независимых величин, так же как нормальная случайная величина есть результат многократного суммирования. Плотность логнормального распределения имеет вид: Основные характеристики логарифмически нормального распределения: Хи-квадрат-распределение
Сумма квадратов т независимых нормальных величин со средним 0 и дисперсией 1 имеет
хи-квадрат-распределение с т степенями свободы. Это распределение наиболее часто используется при анализе данных. Формально плотность ям-квадрат -распределения с т степенями свободы имеет вид: При отрицательных х плотность обращается в 0.
Основные числовые характеристики хи -квадрат-распределения: График плотности приводится на рисунке ниже: Биномиальное распределение
Биномиальное распределение является наиболее важным дискретным распределением, которое сосредоточено всего лишь в нескольких точках. Этим точкам биномиальное распределение приписывает положительные вероятности. Таким образом, биномиальное распределение отличается от непрерывных распределений (нормального, хи-квадрат и др.), которые приписывают нулевые вероятности отдельно выбранным точкам и называются непрерывными. Лучше понять биномиальное распределение можно, рассмотрев следующую игру. Представьте, что вы бросаете монету. Пусть вероятность выпадения герба
есть р, а вероятность выпадения решки есть
q = 1 - р (мы рассматриваем самый общий случай, когда монета несимметрична, имеет, например, смещенный центр тяжести-в монете сделана дырка).
Выпадение герба считается успехом, а выпадение решки - неудачей. Тогда число выпавших гербов (или решек) имеет биномиальное распределение. Отметим, что рассмотрение несимметричных монет или неправильных игральных костей имеет практический интерес. Как отметил Дж. Нейман в своей изящной книге «Вводный курс теории вероятностей и математической статистики», люди давно догадались, что частота выпадений очков на игральной кости зависит от свойств самой этой кости и может быть искусственно изменена. Археологи обнаружили в гробнице фараона две пары костей: «честные» - с равными вероятностями выпадения всех граней, и фальшивые - с умышленным смещением центра тяжести, что увеличивало вероятность выпадения шестерок. Параметрами биномиального распределения являются вероятность успеха
р (q = 1 - р) и число испытаний п.
Биномиальное распределение полезно для описания распределения биномиальных событий, таких, например, как количество мужчин и женщин в случайно выбранных компаниях. Особую важность имеет применение биномиального распределения в игровых задачах. Точная формула для вероятности т успехов в n
испытаниях записывается так:
p-вероятность успеха q равно 1-p, q>=0, p+q==1 n- число испытаний, m =0,1...m Основные характеристики биноминального распределения: График этого распределения при различном числе испытаний п и вероятностях успеха р имеет вид: Биномиальное распределение связано с нормальным распределением и распределением Пуассона (см. ниже); при определенных значениях параметров при большом числе испытаний оно превращается в эти распределения. Это легко продемонстрировать с помощью STATISTICA. Например, рассматривая график биномиального распределения с параметрами р=0,7,n = 100 (см. рисунок), мы использовали STATISTICA BASIC, - вы можете заметить, что график очень похож на плотность нормального распределения (так оно и есть на самом деле!).
График биномиального распределения с параметрами р=0,05,
n= 100 очень похож на график пуассоновского распределения.
Как уже было сказано, биномиальное распределение возникло из наблюдений за простейшей азартной игрой - бросание правильной монеты. Во многих ситуациях эта модель служит хорошим первым приближением для более сложных игр и случайных процессов, возникающих при игре на бирже. Замечательно, что существенные черты многих сложных процессов можно понять, исходя из простой биномиальной модели. Например, рассмотрим следующую ситуацию. Отметим выпадение герба как 1, а выпадение решки - минус 1 и будем суммировать выигрыши и проигрыши в последовательные моменты времени. На графиках показаны типичные траектории такой игры при 1 000 бросков, при 5 000 бросков и при 10 000 бросков. Обратите внимание, какие длинные отрезки времени траектория находится выше или ниже нуля, иными словами, время, в течение которого один из игроков находится в выигрыше в абсолютно справедливой игре, очень продолжительно, а переходы от выигрыша к проигрышу относительно редки, и это с трудом укладывается в неподготовленном сознании, для которого выражение «абсолютно справедливая игра» звучит как магическое заклинание. Итак, хотя игра и справедлива по условиям, поведение типичной траектории вовсе не справедливо и не демонстрирует равновесия! Конечно, эмпирически этот факт известен всем игрокам, с ним связана стратегия, когда игроку не дают уйти с выигрышем, а заставляют играть дальше. Рассмотрим количество бросков, в течение которых один игрок находится в выигрыше (траектория выше 0), а второй - в проигрыше (траектория ниже 0). На первый взгляд кажется, что количество таких бросков примерно одинаково. Однако (см. захватывающую книгу: Феллер В. «Введение в теорию вероятностей и ее приложения». Москва: Мир, 1984, с.106) при 10 000 бросках идеальной монеты (то есть для испытаний Бернулли
с р = q = 0,5, n=10
000) вероятность того, что одна из сторон будет лидировать на протяжении более 9 930 испытаний, а вторая - менее 70, превосходит 0,1.
Удивительно, что в игре, состоящей из 10 000 бросаний правильной монеты, вероятность того, что лидерство поменяется не более 8 раз, превышает 0,14, а вероятность более 78 изменений лидерства приблизительно равна 0,12. Итак, мы имеем парадоксальную ситуацию: в симметричном блуждании Бернулли «волны» на графике между последовательными возвращениями в нуль (см. графики) могут быть поразительно длинными. С этим связано и другое обстоятельство, а именно то, что для
Т n /n (доли времени, когда график находится выше оси абсцисс) наименее вероятными оказываются значения, близкие к 1/2.
Математиками был открыт так называемый закон арксинуса, согласно которому при каждом 0 < а <1 вероятность неравенства
, где Т n - число шагов, в течение которых первый игрок находится в выигрыше, стремится к Распределение арксинуса
Это непрерывное распределение сосредоточено на интервале (0, 1) и имеет плотность: Распределение арксинуса связано со случайным блужданием. Это распределение доли времени, в течение которого первый игрок находится в выигрыше при бросании симметричной монеты, то есть монеты, которая с равными вероятностями
S падает на герб и решку. По-другому такую игру можно рассматривать как случайное блуждание частицы, которая, стартуя из нуля, с равными вероятностями делает единичные скачки вправо или влево. Так как скачки частицы - выпадения герба или решки - равновероятны, то такое блуждание часто называется симметричным. Если бы вероятности были разными, то мы имели бы несимметричное блуждание.
График плотности распределения арксинуса приведен на следующем рисунке: Самое интересное - это качественная интерпретация графика, из которой можно сделать удивительные выводы о сериях выигрышей и проигрышей в справедливой игре. Взглянув на график, вы можете заметить, что минимум плотности находится в точке
1/2.« Ну и что?!» - спросите вы. Но если вы задумаетесь над этим наблюдением, то вашему удивлению не будет границ! Оказывается, определенная как справедливая, игра в действительности вовсе не такая справедливая, как может показаться на первый взгляд.
Траектории симметричного случайного, в которых частица равное время проводит как на положительной, так и на отрицательной полуоси, то есть правее или левее нуля, являются как раз наименее вероятными. Переходя на язык игроков, можно сказать, что при бросании симметричной монеты игры, в которых игроки находятся равное время в выигрыше и проигрыше, наименее вероятны. Напротив, игры, в которых один игрок значительно чаще находится в выигрыше, а другой соответственно в проигрыше, являются наиболее вероятными. Удивительный парадокс! Чтобы рассчитать вероятность того, что доля времени т, в течение которой первый игрок находится в выигрыше, лежит в пределах от t1 до
t2, нужно из значения функции распределения
F(t2) вычесть значение функции распределения
F(t1).
Формально получаем: P{t1 Опираясь на этот факт, можно вычислить с помощью STATISTICА, что при 10 000 шагов частица остается на положительной стороне более чем 9930 моментов времени с вероятностью 0,1, то есть, грубо говоря, подобное положение будет наблюдаться не реже чем в одном случае из десяти (хотя, на первый взгляд, оно кажется абсурдным; см. замечательную по ясности заметку Ю. В. Прохорова «Блуждание Бернулли» в энциклопедии «Вероятность и математическая статистика», с. 42-43, М.: Большая Российская Энциклопедия, 1999). Отрицательное биномиальное распределение
Это дискретное распределение, приписывающее целым точкам
k = 0,1,2,... вероятности:
p k =P{X=k}=C k r+k-1 p r (l-p) k ",
где 0<р<1,r>0.
Отрицательное биномиальное распределение встречается во многих приложениях. При целом r > 0 отрицательное биномиальное распределение интерпретируется как распределение времени ожидания r-го «успеха» в схеме испытаний Бернулли с вероятностью «успеха»
р, например, количество бросков, которые нужно сделать до второго выпадения герба, в этом случае оно иногда называется распределением Паскаля и является дискретным аналогом гамма-распределения.
При r = 1 отрицательное биномиальное распределение совпадает с геометрическим распределением.
Если Y - случайная величина, имеющая распределение Пуассона со случайным параметром
, который, в свою очередь, имеет гамма-распределение с плотностью То Убудет иметь отрицательно биномиальное распределение с параметрами; Распределение Пуассона
Распределение Пуассона иногда называют распределением редких событий. Примерами переменных, распределенных по закону Пуассона, могут служить: число несчастных случаев, число дефектов в производственном процессе и т. д. Распределение Пуассона определяется формулой: Основные характеристики пуассоновской случайной величины: Распределение Пуассона связано с показательным распределением и с распределением Бернулли. Если число событий имеет распределение Пуассона, то интервалы между событиями имеют экспоненциальное или показательное распределение. График распределения Пуассона: Сравните график пуассоновского распределения с параметром 5 с графиком распределения Бернулли при
p=q=0,5,n=100.
Вы увидите, что графики очень похожи. В общем случае имеется следующая закономерность (см. например, превосходную книгу: Ширяев А. Н. «Вероятность». Москва: Наука, с. 76): если в испытаниях Бернулли
n принимает большие значения, а вероятность успеха/? относительно мала, так что среднее число успехов (произведение и нар) и не мало и не велико, то распределение Бернулли с параметрами
n, р можно заменить распределением Пуассона с параметром
= np.
Распределение Пуассона широко используется на практике, например, в картах контроля качества как распределение редких событий. В качестве другого примера рассмотрим следующую задачу, связанную с телефонными линиями и взятую из практики (см.: Феллер В. Введение в теорию вероятностей и ее приложения. Москва: Мир, 1984, с. 205, а также Molina E. С. (1935) Probability in engineering, Electrical engineering, 54, p. 423-427; Bell Telephone System Technical Publications Monograph B-854). Эту задачу легко перевести на современный язык, например на язык мобильной связи, что и предлагается сделать заинтересованным читателям. Задача формулируется следующим образом. Пусть имеется две телефонные станции - А и В. Телефонная станция А должна обеспечить связь 2 000 абонентов со станцией В. Качество связи должно быть таким, чтобы только 1 вызов из 100 ждал, когда освободится линия. Спрашивается: сколько нужно провести телефонных линий, чтобы обеспечить заданное качество связи? Очевидно, что глупо создавать 2 000 линий, так как длительное время многие из них будут свободными. Из интуитивных соображений ясно, что, по-видимому, имеется какое-то оптимальное число линий N. Как рассчитать это количество? Начнем с реалистической модели, которая описывает интенсивность обращения абонента к сети, при этом заметим, что точность модели, конечно, можно проверить, используя стандартные статистические критерии. Итак, предположим, что каждый абонент использует линию в среднем 2 минуты в час и подключения абонентов независимы (однако, как справедливо замечает Феллер, последнее имеет место, если не происходит некоторых событий, затрагивающих всех абонентов, например, войны или урагана). Тогда мы имеем 2000 испытаний Бернулли (бросков монеты) или подключений к сети с вероятностью успеха
p=2/60=1/30.
Нужно найти такое N, когда вероятность того, что к сети одновременно подключается больше N пользователей, не превосходит 0,01. Эти расчеты легко можно решить в системе STATISTICA. Решение задачи на STATISTICA.
Шаг 1.
Откройте модульОсновные статистики
. Создайте файл binoml.sta, содержащий 110 наблюдений. Назовите первую переменную
БИНОМ
, вторую переменную - ПУАССОН
. Шаг 2.
БИНОМ
, откройте окно
Переменная 1
(см. рис.). Введите в окно формулу, как показано на рисунке. Нажмите кнопку
ОК
. Шаг 3.
Дважды щелкнув мышью на заголовке ПУАССОН
, откройте окно
Переменная 2
(см. рис.) Введите в окно формулу, как показано на рисунке. Обратите внимание, что мы вычисляем параметр
распределения Пуассона по формуле =n×p.
Поэтому = 2000 × 1/30. Нажмите кнопку ОК
.
STATISTICA рассчитает вероятности и запишет их в созданный файл. Шаг 4.
Прокрутите построенную таблицу до наблюдений с номером 86. Вы увидите, что вероятность того, что в течение часа из 2000 пользователей сети одновременно работают 86 или более, равна 0,01347, если используется биномиальное распределение. Вероятность того, что в течение часа из 2000 пользователей сети одновременно работают 86 или более человек, равна 0,01293, если используется пуассоновское приближение для биномиального распределения. Так как нам нужна вероятность не более 0,01, то 87 линий будет достаточно, чтобы обеспечить нужное качество связи. Близкие результаты можно получить, если использовать нормальное приближение для биномиального распределения (проверьте это!). Заметим, что В. Феллер не имел в своем распоряжении систему STATISTICA и использовал таблицы для биномиального и нормального распределения. С помощью таких же рассуждений можно решить следующую задачу, обсуждаемую В. Феллером. Требуется проверить, больше или меньше линий потребуется для надежного обслуживания пользователей при разбиении их на 2 группы по 1000 человек в каждой. Оказывается, при разбиении пользователей на группы потребуется дополнительно 10 линий, чтобы достичь качества того же уровня. Можно также учесть изменение интенсивности подключения к сети в течение дня. Геометрическое распределение
Если проводятся независимые испытания Бернулли и подсчитывается количество испытаний до наступления следующего «успеха», то это число имеет геометрическое распределение. Таким образом, если вы бросаете монету, то число подбрасываний, которое вам нужно сделать до выпадения очередного герба, подчиняется геометрическому закону. Геометрическое распределение определяется формулой: F(x) = p(1-p) x-1
р - вероятность успеха, х = 1, 2,3... Название распределения связано с геометрической прогрессией. Итак, геометрическое распределение задает вероятность того, что успех наступил на определенном шаге. Геометрическое распределение представляет собой дискретный аналог показательного распределения. Если время изменяется квантами, то вероятность успеха в каждый момент времени описывается геометрическим законом. Если время непрерывно, то вероятность описывается показательным или экспоненциальным законом. Гипергеометрическое распределение
Это дискретное распределение вероятностей случайной величины X, принимающей целочисленные значения т = 0, 1,2,...,n с вероятностями: где N, М и n - целые неотрицательные числа и М <
N, n < N. Гипергеометрическое распределение обычно связано с выбором без возвращения и определяет, например, вероятность найти ровно т черных шаров в случайной выборке объема
n из генеральной совокупности, содержащей N шаров, среди
которых М черных и N - М белых (см., например, энциклопедию «Вероятность и математическая
статистика», М.: Большая Российская Энциклопедия, с. 144). Математическое ожидание гипергеометрического распределения не зависит от N и
совпадает с математическим ожиданием µ=np соответствующего биномиального распределения. Дисперсия гипергеометрического распределения
Это распределение чрезвычайно часто возникает в задачах, связанных с контролем качества. Полиномиальное распределение
Полиномиальное, или мультиномиальное, распределение естественно обобщает распределение. Если биномиальное распределение возникает при бросании монеты с двумя исходами (решетка или герб), то полиномиальное распределение возникает, когда бросается игральная кость и имеется больше двух возможных исходов. Формально - это совместное распределение вероятностей случайных величин
X 1 ,...,X k , принимающих целые неотрицательные значения
n 1 ,...,n k , удовлетворяющие условию n 1 + ... +
n k = n, c вероятностями: Название «полиномиальное распределение» объясняется тем, что мультиномиальные вероятности возникают при разложении полинома
(р 1 + ... + p k) n
Бета-распределение
Бета-распределение имеет плотность вида: Стандартное бета-распределение сосредоточено на отрезке от 0 до 1. Применяя линейные преобразования, бета-величину можно преобразовать так, что она будет принимать значения на любом интервале. Основные числовые характеристики величины, имеющей бета-распределение: Распределение экстремальных значений
Распределение экстремальных значений (тип I) имеет плотность вида: Это распределение иногда также называют распределением крайних значений. Распределение экстремальных значении используется при моделировании экстремальных событий, например, уровней наводнений, скоростей вихрей, максимума индексов рынков ценных бумаг за данный год и т. д. Это распределение используется в теории надежности, например, для описания времени отказа электрических схем, а также в в актуарных расчетах. Распределения Релея
Распределение Релея имеет плотность вида: где b - параметр масштаба. Распределение Релея сосредоточено в интервале от 0 до бесконечности. Вместо значения
0 STATISTICA позволяет ввести другое значение порогового параметра, которое будет вычтено из исходных данных перед подгонкой распределения Релея. Следовательно, значение порогового параметра должно быть меньше всех наблюдаемых значений. Если две переменные у 1 и у 2 являются независимыми друг от друга и нормально распределены с одинаковой дисперсией, то переменная
Распределение Релея используется, например, в теории стрельбы. Распределение Вейбулла
Распределение Вейбулла названо в честь шведского исследователя Валодди Вейбулла (Waloddi Weibull), применявшего это распределение для описания времен отказов разного типа в теории надежности. Формально плотность распределения Вейбулла записывается в виде: Иногда плотность распределения Вейбулла записывается также в виде: B - параметр масштаба;
С - параметр формы;
Е - константа Эйлера (2,718...).
Параметр положения. Обычно распределение Вейбулла сосредоточено на полуоси от 0 до бесконечности. Если вместо границы 0 ввести параметр а, что часто бывает необходимо на практике, то возникает так называемое трехпараметрическое распределение Вейбулла. Распределение Вейбулла интенсивно используется в теории надежности и страховании. Как описывалось выше, экспоненциальное распределение часто используется как модель, оценивающая время наработки до отказа в предположении, что вероятность отказа объекта постоянна. Если вероятность отказа меняется с течением времени, применяется распределение Вейбулла. При с =1 или, в другой параметризации, при
распределение Вейбулла, как легко видеть из формул, переходит в экспоненциальное распределение, а при
- в распределение Релея.
Разработаны специальные методы оценки параметров распределения Вейбулла (см. например, книгу: Lawless (1982) Statistical models and methods for lifetime data, Belmont, CA: Lifetime Learning, где описаны методы оценивания, а также проблемы, возникающие при оценке параметра положения для трехпараметрического распределения Вейбулла). Часто при проведении анализа надежности необходимо рассматривать вероятность отказа в течение малого интервала времени после момента времени t
при условии, что до момента t
отказа не произошло.
Такая функция называется функцией риска, или функцией интенсивности отказов, и формально определяется следующим образом: H(t) - функция интенсивности отказов или функция риска в момент времени
t;
f(t) - плотность распределения времен отказов;
F(t) - функция распределения времен отказов (интеграл от плотности по интервалу ).
В общем виде функция интенсивности отказов записывается так: При функция риска равна константе, что соответствует нормальной эксплуатации прибора (см. формулы). При функция риска убывает, что соответствует приработке прибора. При функция риска убывает, что соответствует старению прибора. Типичные функции риска показаны на графике. Ниже показаны графики плотности распределения Вейбулла с различными параметрами. Нужно обратить внимание на три области значений параметра а: В первой области функция риска убывает (период настройки), во второй области функция риска равна константе, в третьей области функция риска возрастает. Вы легко поймете сказанное на примере покупки нового автомобиля: вначале идет период адаптации машины, затем длительный период нормальной эксплуатации, далее детали автомобиля изнашиваются и функция риска выхода его из строя резко возрастает. Важно, что все периоды эксплуатации можно описать одним и тем же семейством распределения. В этом и состоит идея распределения Вейбулла. Приведем основные числовые характеристики распределения Вейбулла. Распределение Парето
В различных задачах прикладной статистики довольно часто встречаются так называемые усеченные распределения. Например, это распределение используется в страховании или в налогообложении, когда интерес представляют доходы, которые превосходят некоторую величину
c 0
Основные числовые характеристики распределения Парето: Логистическое распределение
Логистическое распределение имеет функцию плотности: А - параметр положения;
B - параметр масштаба;
Е - число Эйлера (2,71...).
Хотеллинга Т 2 -распределение
Это непрерывное распределение, сосредоточенное на интервале (0, Г), имеет плотность: где параметры n и k, n >_k >_1, называются степенями свободы.
При k = 1 Хотеллинга Р-распределение сводится к распределению Стьюдента, а при любом
k >1 может рассматриваться как обобщение распределения Стьюдента на многомерный случай.
Распределение Хотеллинга строится исходя из нормального распределения. Пусть k-мерный случайный вектор Y имеет нормальное распределение с нулевым вектором средних и ковариационной матрицей
. Рассмотрим величину где случайные векторы Z i независимы между собой и
Y и распределены так же, как Y. Тогда случайная величина Т 2 =Y T S -1 Y имеет
T 2 -распределение Хотеллинга с n степенями свободы (Y - вектор-столбец, Т - оператор транспонирования). где случайная величина t n имеет распределение Стьюдента с
n степенями свободы (см. «Вероятность и математическая статистика», Энциклопедия, с. 792).
Если Y имеет нормальное распределение с ненулевым средним, то соответствующее распределение называется
нецентральным
Хотеллинга T 2 -распределением с
n степенями свободы и параметром нецентральности
v.
Хотеллинга T 2 -распределение используют в математической статистике в той же ситуации, что и ^-распределение Стьюдента, но только в многомерном случае. Если результаты наблюдений
X 1 ,..., Х n представляют собой независимые, нормально распределенные случайные векторы с вектором средних
µ и невырожденной ковариационной матрицей , то статистика имеет Хотеллинга T 2 -распределение с n
- 1 степенями свободы. Этот факт положен в основу критерия Хотеллинга.
В STATISTICA критерий Хотеллинга доступен, например, в модуле Основные статистики и таблицы (см. приведенное ниже диалоговое окно). Распределение Максвелла
Распределение Максвелла возникло в физике при описании распределения скоростей молекул идеального газа. Это непрерывное распределение сосредоточено на (0,
) и имеет плотность: Функция распределения имеет вид: где Ф(x) - функция стандартного нормального распределения. Распределение Максвелла имеет положительный коэффициент асимметрии и единственную моду в точке (то есть распределение унимодально). Распределение Максвелла имеет конечные моменты любого порядка; математическое ожидание и дисперсия равны соответственно
и Распределение Максвелла естественным образом связано с нормальным распределением. Если Х 1 , Х 2 , Х 3 - независимые случайные величины, имеющие нормальное распределение с параметрами 0 и
õ 2 , то случайная величина
Распределение Коши
У этого удивительного распределения иногда не существует среднего значения, т. к. плотность его очень медленно стремится к нулю при увеличении
x по абсолютной величине. Такие распределения называют распределениями с тяжелыми хвостами. Если вам нужно придумать распределение, не имеющее среднего, то сразу называйте распределение Коши. Распределение Коши унимодально и симметрично относительно моды, которая одновременно является и медианой, и имеет функцию плотности вида: где с > 0 - параметр масштаба и
а - параметр центра, определяющий одновременно значения моды и медианы.
Интеграл от плотности, то есть функция распределения задается соотношением: Распределение Стьюдента
Английский статистик В. Госсет, известный под псевдонимом «Стьюдент» и начавший свою карьеру со статистического исследования качества английского пива, получил в 1908 г. следующий результат. Пусть
x 0 , x 1 ,.., х m - независимые, (0,
s 2) - нормально распределенные случайные величины:
Это распределение, известное теперь как распределение Стьюдента (кратко обозначается как
t(m) -распределения, где т, число степеней свободы), лежит в основе знаменитого t-критерия, предназначенного для сравнения средних двух совокупностей.
Функция плотности f t (x) не зависит от дисперсии
õ 2 случайных величин и, кроме того, является унимодальной и симметричной относительно точки
х = 0.
Основные числовые характеристики распределения Стьюдента: t-распределение важно в тех случаях, когда рассматриваются оценки среднего и неизвестна дисперсия выборки. В этом случае используют выборочную дисперсию и t-распределение. При больших степенях свободы (больших 30) t-распределение практически совпадает со стандартным нормальным распределением. График функции плотности t-распределения деформируется при возрастании числа степеней свободы следующим образом: пик увеличивается, хвосты более круто идут к 0, и кажется, будто графики функции плотности t-распределения сжимается с боков. F-распределение
Рассмотрим m 1 + m 2 независимых и (0,
s 2) нормально распределенных величин
Очевидно, та же самая случайная величина может быть определена и как отношение двух независимых и соответствующим образом нормированных
хи-квадрат-распределенных величин и , то есть Знаменитый английский статистик Р. Фишер в 1924 году показал, что плотность вероятности случайной величины
F(m 1 , m 2) задается функцией: где Г (у) - значение гамма-функции Эйлера в. точке
у, а сам закон называется
F-pacпределением с числами степеней свободы числителя и знаменателя, равными соответственно т,1л т7
Основные числовые характеристики F-распределения: F-распределение возникает в дискриминантом, регрессионном и дисперсионном анализе, а также в других видах многомерного анализа данных. Определение.
Нормальным
называется
распределение вероятностей непрерывной
случайной величины, которое описывается
плотностью вероятности Нормальный
закон распределения также называется
законом
Гаусса
. Нормальный
закон распределения занимает центральное
место в теории вероятностей. Это
обусловлено тем, что этот закон проявляется
во всех случаях, когда случайная величина
является результатом действия большого
числа различных факторов. К нормальному
закону приближаются все остальные
законы распределения. Можно
легко показать, что параметры
Найдём
функцию распределения F
(x
)
. График
плотности нормального распределения
называется нормальной
кривой
или
кривой Гаусса
. Нормальная
кривая обладает следующими свойствами: 1)
Функция определена на всей числовой
оси. 2)
При всех х
функция распределения принимает только
положительные значения. 3)
Ось ОХ является горизонтальной асимптотой
графика плотности вероятности, т.к. при
неограниченном возрастании по абсолютной
величине аргумента х
,
значение функции стремится к нулю. 4)
Найдём
экстремум функции. Т.к.
при y
’
> 0
при x
<
m
и y
’
< 0
при x
>
m
, то в точке х
= т
функция
имеет максимум, равный
5)
Функция является симметричной относительно
прямой х = а
,
т.к. разность (х
– а
) входит
в функцию плотности распределения в
квадрате. 6)
Для нахождения точек перегиба графика
найдем вторую производную функции
плотности. При
x
=
m
+
и x
=
m
-
вторая производная равна нулю, а при
переходе через эти точки меняет знак,
т.е. в этих точках функция имеет перегиб. В
этих точках значение функции равно
Построим
график функции плотности распределения
(рис. 5). Построены
графики при т
=0 и трёх возможных значениях
среднеквадратичного отклонения
= 1,
= 2 и
= 7. Как видно, при увеличении значения
среднего квадратичного отклонения
график становится более пологим, а
максимальное значение уменьшается. Если
а
> 0, то график сместится в положительном
направлении, если а
< 0 – в отрицательном. При
а
= 0 и
= 1 кривая называется нормированной
.
Уравнение нормированной кривой: Функция Лапласа
Найдём
вероятность попадания случайной
величины, распределенной по нормальному
закону, в заданный интервал. Обозначим
Т.к.
интеграл
которая
называется функцией
Лапласа
или
интегралом
вероятностей
. Значения
этой функции при различных значениях
х
посчитаны и приводятся в специальных
таблицах. На
рис. 6 показан график функции Лапласа. Функция
Лапласа обладает следующими свойствами: 1) Ф(0)
= 0; 2) Ф(-х)
= - Ф(х);
3) Ф(
)
= 1. Функцию
Лапласа также называют функцией
ошибок
и
обозначают erf
x
. Е На
рис. 7 показан график нормированной
функции Лапласа. Правило
трёх сигм
При рассмотрении
нормального закона распределения
выделяется важный частный случай,
известный как правило
трёх сигм
. Запишем
вероятность того, что отклонение
нормально распределенной случайной
величины от математического ожидания
меньше заданной величины : Если
принять
= 3,
то получаем с использованием таблиц
значений функции Лапласа: Т.е.
вероятность того, что случайная величина
отклонится от своего математического
ожидание на величину, большую чем
утроенное среднее квадратичное
отклонение, практически равна нулю. Это
правило называется правилом
трёх сигм
. Не
практике считается, что если для
какой-либо случайной величины выполняется
правило трёх сигм, то эта случайная
величина имеет нормальное распределение. Заключение
по лекции:
В лекции мы
рассмотрели законы распределения
непрерывных величин В ходе подготовки
к последующей лекции и практическим
занятиям вы должны самостоятельно при
углубленном изучении рекомендованной
литературы и решения предложенных задач
дополнить свои конспекты лекций. Если
исследователь использовав методы,
изложенные в предыдущем параграфе,
убедился, что гипотеза нормальности
распределения не может быть принята,
то вполне может быть, что с помощью
существующих методов удастся так
преобразовать исходные данные, что их
распределение будет подчиняться
нормальному закону распределения. Для
пояснения идеи преобразований рассмотрим
качественный пример. Пусть кривая
распределения f(x) имеет вид, представленный
на рис. 3.7, т.е. имеется очень крутая левая
ветвь и пологая правая. Такое распределение
отличается от нормального. Для
выполнения операций преобразования
каждое наблюдение трансформируется с
помощью логарифмического преобразования
При этом левая ветвь кривой распределения
сильно растягивается и распределение
принимает приближенно нормальный вид.
Если при преобразовании получаются
значения, расположенные между 0 и 1, то
все наблюдаемые значения для удобства
расчетов и во избежание получения
отрицательных параметров необходимо
умножить на 10 в соответствующей степени,
чтобы все вновь полученные, преобразованные
значения были больше единицы, т.е.
необходимо выполнить преобразования Рис. 3
.7.
Преобразование функции f(x)
к нормальному распределению
Асимметричное
распределение с одной вершиной приводится
к нормальному преобразованием
а)
обратная величина
б)
обратное значение квадратных корней
Преобразование
"обратная величина" является
наиболее "сильным". Среднее положение
между логарифмическим преобразованием
и "обратной величиной" занимает
преобразование "обратное значение
квадратных корней". Для
нормализации смещенного вправо
распределения служат, например, степенные
преобразования
а
ограничено? Рассмотрим в дальнейшем
методологию решения этой На
практике сама необходимость измерений
большинства величин вызывается тем,
что они не остаются постоянными, а
изменяются в функции от изменения других
величин. В этом случае целью проведения
эксперимента является установление
вида функциональной зависимости
Определение
связи включает в себя указание вида
модели и определения ее параметров. В
теории экспериментов независимые
параметры X
=(x 1 , ..., x n)
принято называтьфакторами
, а
зависимые переменные y –откликами
.
Координатное пространство с координатами
x 1 , x 2 , ..., x i , ..., x n называетсяфакторным пространством
.
Эксперимент по определению вида функции где
x – скаляр, называется однофакторным
.
Эксперимент по определению функции
вида где
X
=(x 1 , x 2 , ..., x i , ..., x k)
– вектор, – многофакторным. Геометрическое
представление функции отклика в факторном
пространстве является поверхностью
отклика
. При однофакторном эксперименте
k=1 поверхность отклика представляет
собой линию на плоскости, при двухфакторном
k=2 – поверхность в трехмерном пространстве. Связи
в общем случае являются достаточно
многообразными и сложными. Обычно
выделяют следующие виды связей. Функциональные
связи
(или зависимости). Это такие
связи, когда при изменении величиныX
другая величинаY
изменяется так,
что каждому значению x i соответствует
совершенно определенное (однозначное)
значение y i (рис.4.1а). Таким образом,
если выбрать все условия эксперимента
абсолютно одинаковыми, то повторяя
испытания получим одну и ту же зависимость,
т.е. кривые идеально совпадут для всех
испытаний. К
сожалению, таких условий в реальности
не встречается. На практике не удается
поддерживать постоянство условий
(например, колебания физико-химических
свойств шихты при моделировании процессов
тепломассопереноса в металлургических
печах). При этом влияние каждого случайного
фактора в отдельности может быть мало,
однако в совокупности они существенно
могут повлиять на результаты эксперимента.
В этом случае говорят о стохастической
(вероятностной) связи между переменными. Рис.4.1.
Виды
связей: а – функциональная связь, все
точки лежат на линии; б – связь достаточно
тесная, точки группируются возле линии
регрессии, но не все они лежат на ней; в
– связь слабая
Стохастичность
связи
состоит в том, что одна
случайная переменнаяY
реагирует
на изменение другойX
изменением
своего закона распределения (см. рис.
4.1б). Таким образом, зависимая переменная
принимает не одно конкретное значение,
а некоторое из множества значений.
Повторяя испытания мы будем получать
другие значения функции отклика и одному
и тому же значению x в различных реализациях
будут соответствовать различные значения
y в интервале . Искомая
зависимость На
рис.4.1б эта кривая зависимости, проходящая
по центру полосы экспериментальных
точек (математическому ожиданию), которые
могут и не лежать на искомой кривой
При
анализе стохастических связей можно
выделить следующие основные типы
зависимостей между переменными. 1.
Зависимости между одной случайной
переменной X
от другой случайной
переменнойY
и их условными средними
значениями называютсякорреляционными
.
Условное среднее 2.
Зависимость случайной переменной Y
от неслучайной переменнойX
или
зависимость математического ожидания
M y случайной величиныY
от
детерминированного значенияX
называетсярегрессионной
. Приведенная
зависимость характеризует влияние
изменений величиныX
на среднее
значение величиныY
. Стохастические
зависимости характеризуются формой,
теснотой связи и численными значениями
коэффициентов уравнения регрессии.
Форма
связи
устанавливает вид функциональной
зависимости где
b 0 , ..., b j , ..., b k –
коэффициенты уравнения. Для пояснения
существа используемых методов ограничимся
сначала случаем, когда x скаляр. В общем
случае виды функциональных зависимостей
в технике достаточно многообразны:
показательные Заметим,
что задача выбора вида функциональной
зависимости – задача неформализуемая,
т.к. одна и та же кривая на данном участке
примерно с одинаковой точностью может
быть описана самыми различными
аналитическими выражениями. Отсюда
следует важный практический вывод. Даже
в наш век ПЭВМ принятие решения о выборе
той или иной математической модели
остается за исследователем.
Только
экспериментатор знает, для чего будет
в дальнейшем использоваться эта модель,
на основе каких понятий будут
интерпретироваться ее параметры. Крайне
желательно при обработке результатов
эксперимента вид функции
Рис.4.2.
Корреляционное поле







T имеет экспоненциальное распределение с параметром
(лямбда). Экспоненциальное распределение часто используется для описания интервалов между последовательными случайными событиями, например, интервалов между заходами на непопулярный сайт, так как эти посещения являются редкими событиями.![]()




![]()





























![]()

![]()
![]()







![]() не превосходит дисперсии биномиального распределения
npq. При моменты любого порядка гипергеометрического распределения стремятся к соответствующим значениям моментов биномиального распределения.
не превосходит дисперсии биномиального распределения
npq. При моменты любого порядка гипергеометрического распределения стремятся к соответствующим значениям моментов биномиального распределения.




![]() будет иметь распределение Релея.
будет иметь распределение Релея.


![]()




















![]() имеет распределение Максвелла. Таким образом, распределение Максвелла можно рассматривать как распределение длины случайного вектора, координаты которого в декартовой системе координат в трехмерном пространстве независимы и нормально распределены со средним 0 и дисперсией
õ 2 .
имеет распределение Максвелла. Таким образом, распределение Максвелла можно рассматривать как распределение длины случайного вектора, координаты которого в декартовой системе координат в трехмерном пространстве независимы и нормально распределены со средним 0 и дисперсией
õ 2 .
![]()




![]() и положим
и положим





 и
и ,
входящие в плотность распределения
являются соответственно математическим
ожиданием и среднеквадратическим
отклонением случайной величиныХ
.
,
входящие в плотность распределения
являются соответственно математическим
ожиданием и среднеквадратическим
отклонением случайной величиныХ
.![]()


 .
.
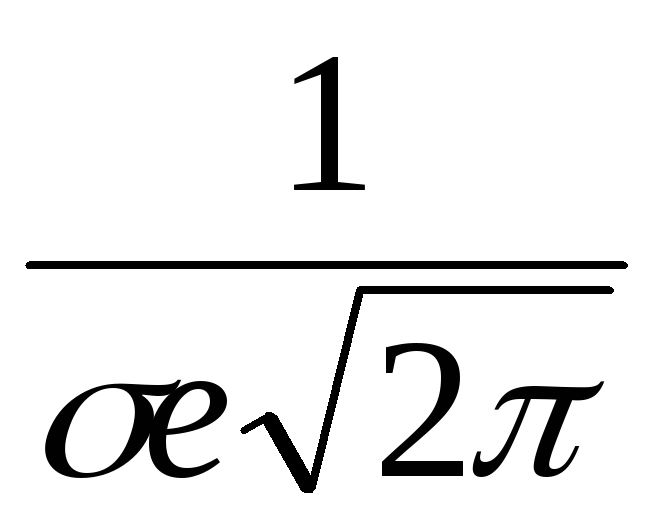 .
.



 не выражается через элементарные
функции, то вводится в рассмотрение
функция
не выражается через элементарные
функции, то вводится в рассмотрение
функция
![]() ,
,
![]() щё
используетсянормированная
функция
Лапласа, которая связана с функцией
Лапласа соотношением:
щё
используетсянормированная
функция
Лапласа, которая связана с функцией
Лапласа соотношением:



 В отдельных случаях можно применять и
другие преобразования:
В отдельных случаях можно применять и
другие преобразования:

 При этом для a принимают значения: а=1,5
при умеренном и а=2 при сильно выраженном
правом смещении. Рекомендуем читателю
придумать такие преобразования, которые
удовлетворяли бы исследователя в том
или ином случае.
При этом для a принимают значения: а=1,5
при умеренном и а=2 при сильно выраженном
правом смещении. Рекомендуем читателю
придумать такие преобразования, которые
удовлетворяли бы исследователя в том
или ином случае.4. Анализ результатов пассивного эксперимента. Эмпирические зависимости
4.1. Характеристика видов связей между рядами наблюдений
 =f(X
).
Для этого должны одновременно определяться
как значенияX
, так и соответствующие
им значения
=f(X
).
Для этого должны одновременно определяться
как значенияX
, так и соответствующие
им значения ,
а задачей эксперимента является
установление математической модели
исследуемой зависимости. Фактически
речь идет об установлениисвязи
между двумя рядами наблюдений (измерений).
,
а задачей эксперимента является
установление математической модели
исследуемой зависимости. Фактически
речь идет об установлениисвязи
между двумя рядами наблюдений (измерений). (4.1)
(4.1) =f(X
), (4.1а)
=f(X
), (4.1а)
 может быть найдена лишь в результате
совместной обработки полученных значений
x и y.
может быть найдена лишь в результате
совместной обработки полученных значений
x и y. ,
а занимают некоторую полосу вокруг нее.
Эти отклонения вызваны погрешностями
измерений, неполнотой модели и учитываемых
факторов, случайным характером самих
исследуемых процессов и другими
причинами.
,
а занимают некоторую полосу вокруг нее.
Эти отклонения вызваны погрешностями
измерений, неполнотой модели и учитываемых
факторов, случайным характером самих
исследуемых процессов и другими
причинами. i – это среднее арифметическое для
реализации случайной величиныY
при
условии, что случайная величинаX
принимает значение
i – это среднее арифметическое для
реализации случайной величиныY
при
условии, что случайная величинаX
принимает значение i .
i . =f(X
)
и характеризуетсяуравнением регрессии
.
Если уравнение связи линейное, то имеем
линейную многомерную регрессию, в этом
случае зависимостиY
отX
описываются уравнением прямой линии в
k-мерном пространстве
=f(X
)
и характеризуетсяуравнением регрессии
.
Если уравнение связи линейное, то имеем
линейную многомерную регрессию, в этом
случае зависимостиY
отX
описываются уравнением прямой линии в
k-мерном пространстве (4.2)
(4.2) ,
логарифмические
,
логарифмические и т.д.
и т.д. =f(X)
выбирать исходя их условия соответствия
физической природе изучаемых явлений
или имеющимся представлениям об
особенностях поведения исследуемой
величины. К сожалению, такая возможность
не всегда имеется, так как эксперименты
чаще всего проводятся для исследования
недостаточно или неполно изученных
явлений.
=f(X)
выбирать исходя их условия соответствия
физической природе изучаемых явлений
или имеющимся представлениям об
особенностях поведения исследуемой
величины. К сожалению, такая возможность
не всегда имеется, так как эксперименты
чаще всего проводятся для исследования
недостаточно или неполно изученных
явлений.

 =f(X
)
от одного фактора при заранее неизвестном
виде функции отклика для приближенного
определения вида уравнения регрессии
полезно предварительно построить
эмпирическую линию регрессии (рис.4.2).
Для этого весь диапазон изменения x на
поле корреляции разбивают на равные
интервалыx. Все
точки, попавшие в данный интервалx j ,
относят к его середине
=f(X
)
от одного фактора при заранее неизвестном
виде функции отклика для приближенного
определения вида уравнения регрессии
полезно предварительно построить
эмпирическую линию регрессии (рис.4.2).
Для этого весь диапазон изменения x на
поле корреляции разбивают на равные
интервалыx. Все
точки, попавшие в данный интервалx j ,
относят к его середине .
Для этого подсчитывают частные средние
для каждого интервала
.
Для этого подсчитывают частные средние
для каждого интервала
 (4.3)
(4.3)
Здесь
n j – число точек в интервалеx j ,
причем ,
где k* – число интервалов разбиения, n –
объем выборки.
,
где k* – число интервалов разбиения, n –
объем выборки.
Затем
последовательно соединяют точки
 отрезками прямой. Полученная ломаная
называетсяэмпирической линией
регрессии
. По виду эмпирической линии
регрессии можно в первом приближении
подобрать вид уравнения регрессии
отрезками прямой. Полученная ломаная
называетсяэмпирической линией
регрессии
. По виду эмпирической линии
регрессии можно в первом приближении
подобрать вид уравнения регрессии =f(X
).
=f(X
).
Под теснотой связи понимается степень близости стохастической зависимости к функциональной, т.е. это показатель тесноты группирования экспериментальных данных относительно принятого уравнения модели (см. рис. 4.1б). В дальнейшем уточним это положение.
Законы распределений случайных величин.
Большинство СВ подчиняется определенному закону распределения, зная который можно предвидеть вероятности попадания исследуемой СВ в определенные интервалы. Это очень важно при анализе экономических показателей, т.к. в этом случае появляется возможность осуществлять продуманную политику с учетом возможности возникновения той или иной ситуации.
Законов распределений достаточно много. К числу наиболее активно использующихся в эконометрическом анализе относятся:
Нормальное распределение (распределение Гаусса);
Распределение χ 2 ;
Распределение Стьюдента;
Распределение Фишера.
Для удобства использования данных законов были разработаны таблицы критических точек, которые позволяют быстро и эффективно оценивать соответствующие вероятности.
Нормальное распределение (распределение Гаусса) является предельным случаем почти всех реальных распределений вероятности. Поэтому оно используется в очень большом числе реальных приложений теории вероятностей.
СВ Х имеет нормальное распределение, если ее плотность вероятности имеет вид:
 (14)
(14)
Это равносильно тому, что
 (15)
(15)
СВ, имеющая нормальное распределение, называется нормально распределенной или нормальной. Графики плотности вероятности и функции распределения нормальной СВ изображены на рис.1 и 2.

0 m – σ m m + σ x
Рис.1. График плотности вероятности нормального распределения СВ Х.

Рис.2. Функция распределения нормальной СВ.
Как видно из формул (1) и (2), нормальное распределение зависит от параметров m и σ
и полностью определяется ими. При этом m = M (X),
σ = σ (Х),
т.е. D (X) = σ 2 , π = 3,14159…, e = 2,71828….
Если СВ Х
имеет нормальное распределение с параметрами M (X) = m
и
σ (Х) = σ
, то символически это можно записать так:
Х ~ N (m, σ) или Х ~ N (m, σ 2).
Очень важным частным случаем нормального распределения является ситуация, когда m = 0 и σ = 1 . В этом случае говорят о стандартизированном (стандартном) нормальном распределении.
Стандартизированную нормальную СВ обозначают через U (U ~ N (0,1)), учитывая при этом, что
 ;
;  (16)
(16)
Для практических расчетов специально разработаны таблицы функций
f (u), F (u)
стандартизированного нормального распределения, но чаще используется так называемая таблица значений Лапласа Ф (
u).
Функция Лапласа имеет вид:
 (17)
(17)
Эту таблицу можно использовать для любой нормальной СВ
Х (Х ~ N (m, σ))
при расчете соответствующих вероятностей:
Заметим, что если Х ~ N (m, σ),
то  ~ N(0,1).
~ N(0,1).
Как видно из предыдущих рисунков, нормально распределенная СВ Х ведет себя достаточно предсказуемо. График ее плотности вероятности (рис.1) симметричен относительно прямой Х = m . Площадь фигуры под графиком плотности вероятности должна оставаться равной единице при любых значениях m и σ. Следовательно, чем меньше значение σ , тем более крутым является график.
Кроме того, справедливы следующие соотношения:
Р ( Х – M (Х) < σ) = 0,68; Р ( Х – M (Х) < 2σ) = 0,95;
Р ( Х – M (Х) < 3σ) = 0,9973 .
Другими словами, значения нормально распределенной СВ
Х (Х ~ N (m, σ))
на 99,73 % сосредоточены в области [ m – 3σ, m + 3σ ].
Важным является тот факт, что линейная комбинация произвольного количества нормальных СВ имеет нормальное распределение . При этом, если Х ~ N (m х, σ х) и Y ~ N (m y , σ y) – независимые СВ, то
Z = aX + bY ~ N (m z , σ) , (19)
где m z = a m х + b m y ; σ z 2 = a 2 σ x 2 + b 2 σ y 2 .
Многие экономические показатели имеют нормальный или близкий к нормальному закон распределения. Например, доход населения, прибыль фирм в отрасли, объем потребления и т.д. имеют близкое к нормальному распределение.
Нормальное распределение используется при проверке различных гипотез в статистике (о величине математического ожидания при известной дисперсии, о равенстве математических ожиданий и т.д.).
Часто при моделировании экономических процессов приходится рассматривать СВ, которые представляют собой алгебраическую комбинацию нескольких СВ. Существенную роль в этом играет ряд специально разработанных теоретических законов распределений. К ним относятся χ 2 – распределение, распределения Стьюдента и Фишера.
Распределение χ 2 (хи – квадрат)
Пусть Х i , i = 1, 2, …, n – независимые нормально распределенные СВ с математическими ожиданиями m i и средними квадратическими отклонениями σ i соответственно, т.е. Х i ~ N (m i , σ i).
Тогда СВ  , i = 1, 2, …, n
, являются независимыми СВ, имеющими стандартизированное нормальное распределение, U i ~ N (0,1).
, i = 1, 2, …, n
, являются независимыми СВ, имеющими стандартизированное нормальное распределение, U i ~ N (0,1).
СВ χ 2
имеет хи – квадрат распределение с n
степенями свободы (χ 2 ~ χ n 2), если  (20).
(20).
Отметим, что число степеней свободы (это число обозначается v ) исследуемой СВ определяется числом СВ, ее составляющих, уменьшенным на число линейных связей между ними.
Например, число степеней свободы СВ, являющейся композицией n случайных величин, которые в свою очередь связаны m линейными уравнениями, определяется числом v = m – n. Таким образом, U 2 ~ χ 1 2 .
Из определения (20) следует, что распределение χ 2 определяется одним параметром – числом степеней свободы v .
График плотности вероятности СВ, имеющий χ 2 – распределение, лежит только в первой четверти декартовой системы координат и имеет асимметричный вид с вытянутым правым «хвостом» (рис.3). Но с увеличением числа степеней свободы распределение χ 2 постепенно приближается к нормальному:

Рис. 3. График плотности вероятности СВ Х, имеюший χ 2 – распределение.
M (χ 2) = v = n – m,
D (χ 2) = 2 v = 2 (n – m).
Если Х и Y – две независимые χ 2 – распределенные СВ с числами степеней свободы n и k соответственно (Х ~ χ n 2 , Y ~ χ k 2), то их сумма (Х + Y) также является χ 2 – распределенной СВ с числом степеней свободы v = n + k.
Распределение χ 2 применяется для нахождения интервальных оценок и проверки статистических гипотез. При этом используется таблица критических точек χ 2 – распределения.







