The main generalizing indicators of variation in statistics are dispersions and standard deviations.
Dispersion this arithmetic mean squared deviations of each characteristic value from the overall average. The variance is usually called the mean square of deviations and is denoted by 2. Depending on the source data, the variance can be calculated using the simple or weighted arithmetic mean:
unweighted (simple) variance;
 variance weighted.
variance weighted.
Standard deviation this is a generalizing characteristic of absolute sizes variations signs in the aggregate. It is expressed in the same units of measurement as the attribute (in meters, tons, percentage, hectares, etc.).
The standard deviation is the square root of the variance and is denoted by :
 standard deviation unweighted;
standard deviation unweighted;
 weighted standard deviation.
weighted standard deviation.
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the better the arithmetic mean reflects the entire represented population.
The calculation of the standard deviation is preceded by the calculation of the variance.
The procedure for calculating the weighted variance is as follows:
1) determine the weighted arithmetic mean:
2) calculate the deviations of the options from the average:
3) square the deviation of each option from the average:
4) multiply the squares of deviations by weights (frequencies):
5) summarize the resulting products:
![]()
6) the resulting amount is divided by the sum of the weights:

Example 2.1

Let's calculate the weighted arithmetic mean:

The values of deviations from the mean and their squares are presented in the table. Let's define the variance:

The standard deviation will be equal to:

If the source data is presented in the form of interval distribution series , then you first need to determine the discrete value of the attribute, and then apply the described method.
Example 2.2
Let us show the calculation of variance for an interval series using data on the distribution of the sown area of a collective farm according to wheat yield.

The arithmetic mean is:

Let's calculate the variance:

6.3. Calculation of variance using a formula based on individual data
Calculation technique variances complex, and with large values of options and frequencies it can be cumbersome. Calculations can be simplified using the properties of dispersion.
The dispersion has the following properties.
1. Reducing or increasing the weights (frequencies) of a varying characteristic by a certain number of times does not change the dispersion.
2. Decrease or increase each value of a characteristic by the same constant amount A does not change the dispersion.
3. Decrease or increase each attribute value by a certain number of times k respectively reduces or increases the variance in k 2 times and standard deviation in k once.
4. The dispersion of a characteristic relative to an arbitrary value is always greater than the dispersion relative to the arithmetic mean per square of the difference between the average and arbitrary values:
![]()
If A 0, then we arrive at the following equality:
i.e., the variance of the characteristic is equal to the difference between the mean square of the characteristic values and the square of the mean.
Each property can be used independently or in combination with others when calculating variance.
The procedure for calculating variance is simple:
1) determine arithmetic mean :
2) square the arithmetic mean:

3) square the deviation of each variant of the series:
X i 2 .
4) find the sum of squares of the options:
5) divide the sum of the squares of the options by their number, i.e. determine the average square:
6) determine the difference between the mean square of the characteristic and the square of the mean:
Example 3.1 The following data is available on worker productivity:

Let's make the following calculations:
![]()
Steps
Calculating sample variance
-
Record the sample values. In most cases, statisticians only have access to samples of specific populations. For example, as a rule, statisticians do not analyze the cost of maintaining the totality of all cars in Russia - they analyze a random sample of several thousand cars. Such a sample will help determine the average cost of a car, but, most likely, the resulting value will be far from the real one.
- For example, let's analyze the number of buns sold in a cafe over 6 days, taken in random order. The sample looks like this: 17, 15, 23, 7, 9, 13. This is a sample, not a population, because we do not have data on buns sold for each day the cafe is open.
- If you are given a population rather than a sample of values, continue to the next section.
-
Write down a formula to calculate sample variance. Dispersion is a measure of the spread of values of a certain quantity. The closer the variance value is to zero, the closer the values are grouped together. When working with a sample of values, use the following formula to calculate variance:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– this is dispersion. Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in the sample.
- x i (\displaystyle x_(i)) you need to subtract x̅, square it, and then add the results.
- x̅ – sample mean (sample mean).
- n – number of values in the sample.
-
Calculate the sample mean. It is denoted as x̅. The sample mean is calculated as a simple arithmetic mean: add up all the values in the sample, and then divide the result by the number of values in the sample.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
Now divide the result by the number of values in the sample (in our example there are 6): 84 ÷ 6 = 14.
Sample mean x̅ = 14. - The sample mean is the central value around which the values in the sample are distributed. If the values in the sample cluster around the sample mean, then the variance is small; otherwise the variance is large.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Subtract the sample mean from each value in the sample. Now calculate the difference x i (\displaystyle x_(i))- x̅, where x i (\displaystyle x_(i))– each value in the sample. Each result obtained indicates the degree of deviation of a particular value from the sample mean, that is, how far this value is from the sample mean.
- In our example:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - The correctness of the results obtained is easy to check, since their sum should be equal to zero. This is related to the definition of the average, since negative values (distances from the average to smaller values) are completely offset by positive values (distances from the average to larger values).
- In our example:
-
As noted above, the sum of the differences x i (\displaystyle x_(i))- x̅ must be equal to zero. This means that the average variance is always zero, which does not give any idea about the spread of values of a certain quantity. To solve this problem, square each difference x i (\displaystyle x_(i))- x̅. This will result in you only getting positive numbers, which will never add up to 0.
- In our example:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - You found the square of the difference - x̅) 2 (\displaystyle ^(2)) for each value in the sample.
- In our example:
-
Calculate the sum of the squares of the differences. That is, find that part of the formula that is written like this: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Here the sign Σ means the sum of squared differences for each value x i (\displaystyle x_(i)) in the sample. You have already found the squared differences (x i (\displaystyle (x_(i))- x̅) 2 (\displaystyle ^(2)) for each value x i (\displaystyle x_(i)) in the sample; now just add these squares.
- In our example: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Divide the result by n - 1, where n is the number of values in the sample. Some time ago, to calculate sample variance, statisticians simply divided the result by n; in this case you will get the mean of the squared variance, which is ideal for describing the variance of a given sample. But remember that any sample is only a small part of the population of values. If you take another sample and perform the same calculations, you will get a different result. As it turns out, dividing by n - 1 (rather than just n) gives a more accurate estimate of the population variance, which is what you're interested in. Division by n – 1 has become common, so it is included in the formula for calculating sample variance.
- In our example, the sample includes 6 values, that is, n = 6.
Sample variance = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- In our example, the sample includes 6 values, that is, n = 6.
-
The difference between variance and standard deviation. Note that the formula contains an exponent, so the dispersion is measured in square units of the value being analyzed. Sometimes such a magnitude is quite difficult to operate; in such cases, use the standard deviation, which is equal to the square root of the variance. That is why the sample variance is denoted as s 2 (\displaystyle s^(2)), and the standard deviation of the sample is as s (\displaystyle s).
- In our example, the standard deviation of the sample is: s = √33.2 = 5.76.
Calculating Population Variance
-
Analyze some set of values. The set includes all values of the quantity under consideration. For example, if you are studying the age of residents of the Leningrad region, then the totality includes the age of all residents of this region. When working with a population, it is recommended to create a table and enter the population values into it. Consider the following example:
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
-
Write down a formula to calculate the population variance. Since the population includes all values of a certain quantity, the formula below allows you to obtain the exact value of the population variance. To distinguish population variance from sample variance (which is only an estimate), statisticians use various variables:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))– population dispersion (read as “sigma squared”). Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in its entirety.
- Σ – sum sign. That is, from each value x i (\displaystyle x_(i)) you need to subtract μ, square it, and then add the results.
- μ – population mean.
- n – number of values in the population.
-
Calculate the population mean. When working with a population, its mean is denoted as μ (mu). The population mean is calculated as a simple arithmetic mean: add up all the values in the population, and then divide the result by the number of values in the population.
- Keep in mind that averages are not always calculated as the arithmetic mean.
- In our example, the population mean: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Subtract the population mean from each value in the population. The closer the difference value is to zero, the closer the specific value is to the population mean. Find the difference between each value in the population and its mean, and you will get a first idea of the distribution of values.
- In our example:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- In our example:
-
Square each result obtained. The difference values will be both positive and negative; If these values are plotted on a number line, they will lie to the right and left of the population mean. This is not good for calculating variance because positive and negative numbers cancel each other out. So square each difference to get exclusively positive numbers.
- In our example:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) for each population value (from i = 1 to i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Where x n (\displaystyle x_(n))– the last value in the population. - To calculate the average value of the results obtained, you need to find their sum and divide it by n:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Now let's write down the above explanation using variables: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n and get a formula for calculating the population variance.
- In our example:
If the population is divided into groups according to the characteristic being studied, then the following types of variance can be calculated for this population: total, group (within-group), average of group (average of within-group), intergroup.
Initially, it calculates the coefficient of determination, which shows what part of the total variation of the trait being studied is intergroup variation, i.e. due to the grouping characteristic:
The empirical correlation relationship characterizes the closeness of the connection between grouping (factorial) and performance characteristics.
The empirical correlation ratio can take values from 0 to 1.
To assess the closeness of the connection based on the empirical correlation ratio, you can use the Chaddock relations:
Example 4. The following data is available on the performance of work by design and survey organizations of various forms of ownership:
Define:
1) total variance;
2) group variances;
3) the average of the group variances;
4) intergroup variance;
5) total variance based on the rule for adding variances;
6) coefficient of determination and empirical correlation ratio.
Draw conclusions.
Solution:
1. Let us determine the average volume of work performed by enterprises of two forms of ownership:
Let's calculate the total variance:
![]()
2. Determine group averages:
![]() million rubles;
million rubles;
![]() million rubles
million rubles
Group variances:
![]() ;
;
3. Calculate the average of the group variances:
4. Let’s determine the intergroup variance:
5. Calculate the total variance based on the rule for adding variances:
6. Let's determine the coefficient of determination:
![]() .
.
Thus, the volume of work performed by design and survey organizations depends by 22% on the form of ownership of the enterprises.
The empirical correlation ratio is calculated using the formula
![]() .
.
The value of the calculated indicator indicates that the dependence of the volume of work on the form of ownership of the enterprise is small.
Example 5. As a result of a survey of the technological discipline of production areas, the following data were obtained:
Determine the coefficient of determination
Expectation and variance are the most commonly used numerical characteristics of a random variable. They characterize the most important features of the distribution: its position and degree of scattering. In many practical problems, a complete, exhaustive characteristic of a random variable - the distribution law - either cannot be obtained at all, or is not needed at all. In these cases, one is limited to an approximate description of a random variable using numerical characteristics.
The expected value is often called simply the average value of a random variable. Dispersion of a random variable is a characteristic of dispersion, the spread of a random variable around its mathematical expectation.
Expectation of a discrete random variable
Let us approach the concept of mathematical expectation, first based on the mechanical interpretation of the distribution of a discrete random variable. Let the unit mass be distributed between the points of the x-axis x1 , x 2 , ..., x n, and each material point has a corresponding mass of p1 , p 2 , ..., p n. It is required to select one point on the abscissa axis, characterizing the position of the entire system of material points, taking into account their masses. It is natural to take the center of mass of the system of material points as such a point. This is the weighted average of the random variable X, to which the abscissa of each point xi enters with a “weight” equal to the corresponding probability. The average value of the random variable obtained in this way X is called its mathematical expectation.
The mathematical expectation of a discrete random variable is the sum of the products of all its possible values and the probabilities of these values:

Example 1. A win-win lottery has been organized. There are 1000 winnings, of which 400 are 10 rubles. 300 - 20 rubles each. 200 - 100 rubles each. and 100 - 200 rubles each. What is the average winnings for someone who buys one ticket?
Solution. We will find the average winnings if we divide the total amount of winnings, which is 10*400 + 20*300 + 100*200 + 200*100 = 50,000 rubles, by 1000 (total amount of winnings). Then we get 50000/1000 = 50 rubles. But the expression for calculating the average winnings can be presented in the following form:
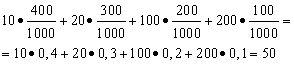
On the other hand, under these conditions, the winning size is a random variable, which can take values of 10, 20, 100 and 200 rubles. with probabilities equal to 0.4, respectively; 0.3; 0.2; 0.1. Therefore, the expected average win is equal to the sum of the products of the size of the wins and the probability of receiving them.
Example 2. The publisher decided to publish a new book. He plans to sell the book for 280 rubles, of which he himself will receive 200, 50 to the bookstore and 30 to the author. The table provides information about the costs of publishing a book and the probability of selling a certain number of copies of the book.
Find the publisher's expected profit.
Solution. The random variable “profit” is equal to the difference between the income from sales and the cost of costs. For example, if 500 copies of a book are sold, then the income from the sale is 200 * 500 = 100,000, and the cost of publication is 225,000 rubles. Thus, the publisher faces a loss of 125,000 rubles. The following table summarizes the expected values of the random variable - profit:
| Number | Profit xi | Probability pi | xi p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Total: | 1,00 | 25000 |
Thus, we obtain the mathematical expectation of the publisher’s profit:
![]() .
.
Example 3. Probability of hitting with one shot p= 0.2. Determine the consumption of projectiles that provide a mathematical expectation of the number of hits equal to 5.
Solution. From the same mathematical expectation formula that we have used so far, we express x- shell consumption:
![]() .
.
Example 4. Determine the mathematical expectation of a random variable x number of hits with three shots, if the probability of a hit with each shot p = 0,4 .
Hint: find the probability of random variable values by Bernoulli's formula .
Properties of mathematical expectation
Let's consider the properties of mathematical expectation.
Property 1. The mathematical expectation of a constant value is equal to this constant:
Property 2. The constant factor can be taken out of the mathematical expectation sign:
![]()
Property 3. The mathematical expectation of the sum (difference) of random variables is equal to the sum (difference) of their mathematical expectations:
Property 4. The mathematical expectation of a product of random variables is equal to the product of their mathematical expectations:
Property 5. If all values of a random variable X decrease (increase) by the same number WITH, then its mathematical expectation will decrease (increase) by the same number:
![]()
When you can’t limit yourself only to mathematical expectation
In most cases, only the mathematical expectation cannot sufficiently characterize a random variable.
Let the random variables X And Y are given by the following distribution laws:
| Meaning X | Probability |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Meaning Y | Probability |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
The mathematical expectations of these quantities are the same - equal to zero:
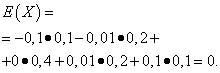
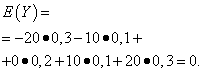
However, their distribution patterns are different. Random variable X can only take values that differ little from the mathematical expectation, and the random variable Y can take values that deviate significantly from the mathematical expectation. A similar example: the average wage does not make it possible to judge the share of high- and low-paid workers. In other words, one cannot judge from the mathematical expectation what deviations from it, at least on average, are possible. To do this, you need to find the variance of the random variable.
Variance of a discrete random variable
Variance discrete random variable X is called the mathematical expectation of the square of its deviation from the mathematical expectation:
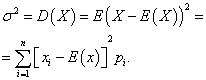
The standard deviation of a random variable X the arithmetic value of the square root of its variance is called:
![]() .
.
Example 5. Calculate variances and standard deviations of random variables X And Y, the distribution laws of which are given in the tables above.
Solution. Mathematical expectations of random variables X And Y, as found above, are equal to zero. According to the dispersion formula at E(X)=E(y)=0 we get:
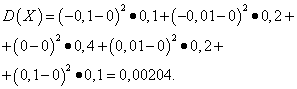
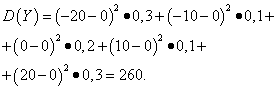
Then the standard deviations of random variables X And Y make up
![]() .
.
Thus, with the same mathematical expectations, the variance of the random variable X very small, but a random variable Y- significant. This is a consequence of differences in their distribution.
Example 6. The investor has 4 alternative investment projects. The table summarizes the expected profit in these projects with the corresponding probability.
| Project 1 | Project 2 | Project 3 | Project 4 |
| 500, P=1 | 1000, P=0,5 | 500, P=0,5 | 500, P=0,5 |
| 0, P=0,5 | 1000, P=0,25 | 10500, P=0,25 | |
| 0, P=0,25 | 9500, P=0,25 |
Find the mathematical expectation, variance and standard deviation for each alternative.
Solution. Let us show how these values are calculated for the 3rd alternative:
The table summarizes the found values for all alternatives.
All alternatives have the same mathematical expectations. This means that in the long run everyone has the same income. Standard deviation can be interpreted as a measure of risk - the higher it is, the greater the risk of the investment. An investor who does not want much risk will choose project 1 since it has the smallest standard deviation (0). If the investor prefers risk and high returns in a short period, then he will choose the project with the largest standard deviation - project 4.
Dispersion properties
Let us present the properties of dispersion.
Property 1. The variance of a constant value is zero:
Property 2. The constant factor can be taken out of the dispersion sign by squaring it:
![]() .
.
Property 3. The variance of a random variable is equal to the mathematical expectation of the square of this value, from which the square of the mathematical expectation of the value itself is subtracted:
![]() ,
,
Where ![]() .
.
Property 4. The variance of the sum (difference) of random variables is equal to the sum (difference) of their variances:
Example 7. It is known that a discrete random variable X takes only two values: −3 and 7. In addition, the mathematical expectation is known: E(X) = 4 . Find the variance of a discrete random variable.
Solution. Let us denote by p the probability with which a random variable takes a value x1 = −3 . Then the probability of the value x2 = 7 will be 1 − p. Let us derive the equation for the mathematical expectation:
E(X) = x 1 p + x 2 (1 − p) = −3p + 7(1 − p) = 4 ,
where we get the probabilities: p= 0.3 and 1 − p = 0,7 .
Law of distribution of a random variable:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
We calculate the variance of this random variable using the formula from property 3 of dispersion:
D(X) = 2,7 + 34,3 − 16 = 21 .
Find the mathematical expectation of a random variable yourself, and then look at the solution
Example 8. Discrete random variable X takes only two values. It accepts the greater of the values 3 with probability 0.4. In addition, the variance of the random variable is known D(X) = 6 . Find the mathematical expectation of a random variable.
Example 9. There are 6 white and 4 black balls in the urn. 3 balls are drawn from the urn. The number of white balls among the drawn balls is a discrete random variable X. Find the mathematical expectation and variance of this random variable.
Solution. Random variable X can take values 0, 1, 2, 3. The corresponding probabilities can be calculated from probability multiplication rule. Law of distribution of a random variable:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Hence the mathematical expectation of this random variable:
M(X) = 3/10 + 1 + 1/2 = 1,8 .
The variance of a given random variable is:
D(X) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Expectation and variance of a continuous random variable
For a continuous random variable, the mechanical interpretation of the mathematical expectation will retain the same meaning: the center of mass for a unit mass distributed continuously on the x-axis with density f(x). Unlike a discrete random variable, whose function argument xi changes abruptly; for a continuous random variable, the argument changes continuously. But the mathematical expectation of a continuous random variable is also related to its average value.
To find the mathematical expectation and variance of a continuous random variable, you need to find definite integrals . If the density function of a continuous random variable is given, then it directly enters into the integrand. If a probability distribution function is given, then by differentiating it, you need to find the density function.
The arithmetic average of all possible values of a continuous random variable is called its mathematical expectation, denoted by or .
For grouped data residual variance- average of intragroup variances:Where σ 2 j is the intragroup variance of the jth group.
For ungrouped data residual variance– measure of approximation accuracy, i.e. approximation of the regression line to the original data: 
where y(t) is the forecast using the trend equation; y t – initial dynamics series; n – number of points; p – number of regression equation coefficients (number of explanatory variables).
In this example it is called unbiased variance estimator.
Example No. 1. The distribution of workers of three enterprises of one association according to tariff categories is characterized by the following data:
| Worker's tariff category | Number of workers at the enterprise | ||
| enterprise 1 | enterprise 2 | enterprise 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Define:
1. variance for each enterprise (intra-group variances);
2. the average of the within-group variances;
3. intergroup dispersion;
4. total variance.
Solution.
Before starting to solve the problem, it is necessary to find out which feature is effective and which is factorial. In the example under consideration, the resultant attribute is “Tariff category”, and the factor attribute is “Number (name) of the enterprise”.
Then we have three groups (enterprises), for which it is necessary to calculate the group average and intragroup variances:

| Enterprise | Group average, | Within-group variance, |
| 1 | 4 | 1,8 |
The average of the within-group variances ( residual variance) will be calculated using the formula:

where you can calculate:
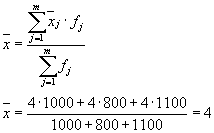
or:
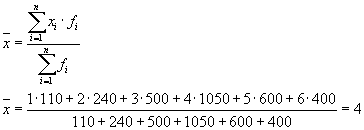
Then:
The total variance will be equal to: s 2 = 1.6 + 0 = 1.6.
The total variance can also be calculated using one of the following two formulas:
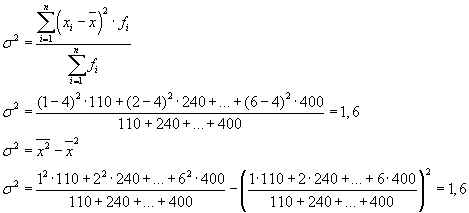
When solving practical problems, one often has to deal with a feature that takes only two alternative values. In this case, we are not talking about the weight of a particular value of a feature, but about its share in the totality. If the proportion of population units possessing the characteristic being studied is denoted by “ r", and those who do not have - through " q", then the variance can be calculated using the formula:
s 2 = p×q
Example No. 2. Based on the production data of six workers in a team, determine the intergroup variance and evaluate the impact of the work shift on their labor productivity if the total variance is 12.2.
| Team worker no. | Worker output, pcs. | |
| in the first shift | in the second shift | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Solution. Initial data
| X | f 1 | f 2 | f 3 | f 4 | f 5 | f 6 | Total |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Total | 31 | 33 | 37 | 37 | 40 | 38 |
Then we have 6 groups for which it is necessary to calculate the group mean and intragroup variances.
1. Find the average values of each group.
2. Find the mean square of each group.
Let's summarize the calculation results in a table:
| Group number | Group average | Within-group variance |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Within-group variance characterizes the change (variation) of the studied (resultative) characteristic within a group under the influence of all factors on it, except for the factor underlying the grouping:
We calculate the average of the intragroup variances using the formula:
4. Intergroup variance characterizes the change (variation) of the studied (resultative) characteristic under the influence of a factor (factorial characteristic) that forms the basis of the group.
We define intergroup variance as:
Where
Then
Total variance characterizes the change (variation) of the studied (resultative) characteristic under the influence of all factors (factorial characteristics) without exception. According to the conditions of the problem, it is equal to 12.2.
Empirical correlation relationship measures what part of the total variability of the resulting characteristic is caused by the factor being studied. This is the ratio of factor variance to total variance:
We define the empirical correlation relation:
Connections between characteristics can be weak and strong (close). Their criteria are assessed on the Chaddock scale:
0.1 0.3 0.5 0.7 0.9 In our example, the relationship between trait Y and factor X is weak
Determination coefficient.
Let's determine the coefficient of determination:
Thus, 0.67% of the variation is due to differences between traits, and 99.37% is due to other factors.
Conclusion: in this case, the output of workers does not depend on work on a specific shift, i.e. the influence of the work shift on their labor productivity is not significant and is due to other factors.
Example No. 3. Based on data on average wages and the squared deviations from its value for two groups of workers, find the total variance by applying the rule of adding variances:
Solution:Average of within-group variances
We define intergroup variance as:
The total variance will be: 480 + 13824 = 14304







