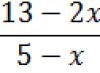Analisis regresi dan korelasi adalah metode penelitian statistik. Ini adalah cara paling umum untuk menunjukkan ketergantungan suatu parameter pada satu atau lebih variabel independen.
Di bawah ini, dengan menggunakan contoh-contoh praktis yang spesifik, kami akan mempertimbangkan dua analisis yang sangat populer di kalangan ekonom. Kami juga akan memberikan contoh memperoleh hasil dengan menggabungkannya.
Analisis Regresi di Excel
Menunjukkan pengaruh beberapa nilai (independen, independen) terhadap variabel dependen. Misalnya, jumlah penduduk yang aktif secara ekonomi bergantung pada jumlah perusahaan, upah, dan parameter lainnya. Atau: bagaimana investasi asing, harga energi, dll mempengaruhi tingkat PDB.
Hasil analisis memungkinkan Anda untuk mengidentifikasi prioritas. Dan berdasarkan faktor-faktor utama tersebut, memprediksi, merencanakan pengembangan kawasan prioritas, dan mengambil keputusan pengelolaan.
Regresi terjadi:
- linier (y = a + bx);
- parabola (y = a + bx + cx 2);
- eksponensial (y = a * exp(bx));
- pangkat (y = a*x^b);
- hiperbolik (y = b/x + a);
- logaritma (y = b * 1n(x) + a);
- eksponensial (y = a * b^x).
Mari kita lihat contoh pembuatan model regresi di Excel dan menginterpretasikan hasilnya. Mari kita ambil jenis regresi linier.
Tugas. Di 6 perusahaan, rata-rata gaji bulanan dan jumlah karyawan yang berhenti dianalisis. Perlu diketahui ketergantungan jumlah pegawai yang berhenti terhadap gaji rata-rata.
Model regresi linier terlihat seperti ini:
Y = a 0 + a 1 x 1 +…+a k x k.
Dimana a adalah koefisien regresi, x adalah variabel yang mempengaruhi, k adalah banyaknya faktor.
Dalam contoh kita, Y adalah indikator berhentinya karyawan. Faktor yang mempengaruhi adalah upah (x).
Excel memiliki fungsi bawaan yang bisa membantu Anda menghitung parameter model regresi linier. Namun add-on “Paket Analisis” akan melakukan ini lebih cepat.
Kami mengaktifkan alat analisis yang kuat:


Setelah diaktifkan, add-on akan tersedia di tab Data.

Sekarang mari kita lakukan analisis regresi itu sendiri.


Pertama-tama, kita memperhatikan R-kuadrat dan koefisiennya.
R-squared adalah koefisien determinasi. Dalam contoh kita – 0,755, atau 75,5%. Artinya parameter model yang dihitung menjelaskan 75,5% hubungan antar parameter yang diteliti. Semakin tinggi koefisien determinasi maka semakin baik model tersebut. Bagus - di atas 0,8. Buruk – kurang dari 0,5 (analisis seperti itu hampir tidak dapat dianggap masuk akal). Dalam contoh kita – “tidak buruk”.
Koefisien 64,1428 menunjukkan berapa Y jika seluruh variabel dalam model yang dipertimbangkan sama dengan 0. Artinya, nilai parameter yang dianalisis juga dipengaruhi oleh faktor lain yang tidak dijelaskan dalam model.
Koefisien -0,16285 menunjukkan bobot variabel X terhadap Y. Artinya, rata-rata gaji bulanan dalam model ini mempengaruhi jumlah orang yang berhenti merokok dengan bobot -0,16285 (tingkat pengaruhnya kecil). Tanda “-” menunjukkan dampak negatif: semakin tinggi gaji, semakin sedikit orang yang berhenti. Itu adil.
Analisis Korelasi di Excel
Analisis korelasi membantu mengetahui apakah terdapat hubungan antar indikator dalam satu atau dua sampel. Misalnya antara waktu pengoperasian suatu mesin dengan biaya perbaikan, harga peralatan dan lama pengoperasian, tinggi dan berat badan anak, dll.
Jika terdapat hubungan, maka apakah peningkatan pada satu parameter menyebabkan peningkatan (korelasi positif) atau penurunan (negatif) pada parameter lainnya. Analisis korelasi membantu analis menentukan apakah nilai suatu indikator dapat digunakan untuk memprediksi kemungkinan nilai indikator lainnya.
Koefisien korelasi dilambangkan dengan r. Bervariasi dari +1 hingga -1. Klasifikasi korelasi untuk berbagai wilayah akan berbeda. Ketika koefisiennya 0, tidak ada hubungan linier antar sampel.
Mari kita lihat cara mencari koefisien korelasi menggunakan Excel.
Untuk mencari koefisien berpasangan digunakan fungsi CORREL.
Tujuan: Mengetahui apakah ada hubungan antara waktu pengoperasian mesin bubut dengan biaya pemeliharaannya.

Tempatkan kursor di sel mana pun dan tekan tombol fx.
- Pada kategori “Statistik”, pilih fungsi CORREL.
- Argumen “Array 1” - rentang nilai pertama – waktu pengoperasian mesin: A2:A14.
- Argumen “Array 2” - rentang nilai kedua – biaya perbaikan: B2:B14. Klik Oke.

Untuk menentukan jenis koneksi, Anda perlu melihat angka absolut koefisiennya (setiap bidang kegiatan memiliki skalanya sendiri).
Untuk analisis korelasi beberapa parameter (lebih dari 2), akan lebih mudah menggunakan “Analisis Data” (add-on “Paket Analisis”). Anda perlu memilih korelasi dari daftar dan menentukan array. Semua.
Koefisien yang dihasilkan akan ditampilkan dalam matriks korelasi. Seperti ini:

Analisis korelasi dan regresi
Dalam praktiknya, kedua teknik ini sering digunakan bersamaan.
Contoh:



Sekarang data analisis regresi sudah terlihat.
Selama belajar, siswa sangat sering menjumpai berbagai macam persamaan. Salah satunya - persamaan regresi - dibahas dalam artikel ini. Persamaan jenis ini digunakan secara khusus untuk menggambarkan ciri-ciri hubungan antar parameter matematika. Jenis persamaan ini digunakan dalam statistik dan ekonometrika.
Definisi regresi
Dalam matematika, regresi berarti besaran tertentu yang menggambarkan ketergantungan nilai rata-rata suatu kumpulan data terhadap nilai besaran lain. Persamaan regresi menunjukkan, sebagai fungsi dari suatu karakteristik tertentu, nilai rata-rata dari karakteristik lainnya. Fungsi regresi berbentuk persamaan sederhana y = x, dimana y berperan sebagai variabel terikat, dan x sebagai variabel bebas (faktor fitur). Faktanya, regresi dinyatakan sebagai y = f (x).
Apa saja jenis hubungan antar variabel?
Secara umum, ada dua jenis hubungan yang berlawanan: korelasi dan regresi.
Yang pertama ditandai dengan kesetaraan variabel bersyarat. Dalam hal ini, tidak diketahui secara pasti variabel mana yang bergantung pada variabel lainnya.
Jika tidak ada persamaan antara variabel-variabel dan syarat-syarat yang menyatakan variabel mana yang bersifat penjelas dan mana yang terikat, maka kita dapat berbicara tentang adanya hubungan tipe kedua. Untuk membangun persamaan regresi linier, perlu diketahui jenis hubungan apa yang diamati.
Jenis regresi
Saat ini, ada 7 jenis regresi yang berbeda: hiperbolik, linier, berganda, nonlinier, berpasangan, invers, linier logaritmik.

Hiperbolik, linier dan logaritma
Persamaan regresi linier digunakan dalam statistik untuk menjelaskan dengan jelas parameter persamaan. Sepertinya y = c+t*x+E. Persamaan hiperbolik berbentuk hiperbola beraturan y = c + m / x + E. Persamaan linier logaritma menyatakan hubungan menggunakan fungsi logaritma: In y = In c + m * In x + In E.
Berganda dan nonlinier
Dua jenis regresi yang lebih kompleks adalah regresi berganda dan nonlinier. Persamaan regresi berganda dinyatakan dengan fungsi y = f(x 1, x 2 ... x c) + E. Dalam situasi ini, y berperan sebagai variabel terikat, dan x berperan sebagai variabel penjelas. Variabel E bersifat stokastik; variabel ini mencakup pengaruh faktor-faktor lain dalam persamaan. Persamaan regresi nonlinier agak kontroversial. Di satu sisi, relatif terhadap indikator-indikator yang diperhitungkan tidak linier, namun di sisi lain dalam peran indikator penilaian bersifat linier.

Jenis regresi terbalik dan berpasangan
Invers adalah jenis fungsi yang perlu diubah ke bentuk linier. Pada sebagian besar program aplikasi tradisional, fungsi ini berbentuk fungsi y = 1/c + m*x+E. Persamaan regresi berpasangan menunjukkan hubungan antar data sebagai fungsi dari y = f (x) + E. Sama seperti persamaan lainnya, y bergantung pada x, dan E merupakan parameter stokastik.

Konsep korelasi
Ini merupakan indikator yang menunjukkan adanya hubungan antara dua fenomena atau proses. Kekuatan hubungan dinyatakan sebagai koefisien korelasi. Nilainya berfluktuasi dalam interval [-1;+1]. Indikator negatif menunjukkan adanya umpan balik, indikator positif menunjukkan adanya umpan balik langsung. Jika koefisien bernilai 0, maka tidak ada hubungan. Semakin dekat nilainya dengan 1, semakin kuat hubungan antar parameter; semakin mendekati 0, semakin lemah.
Metode
Metode parametrik korelasi dapat menilai kekuatan hubungan. Mereka digunakan berdasarkan estimasi distribusi untuk mempelajari parameter yang mematuhi hukum distribusi normal.
Parameter persamaan regresi linier diperlukan untuk mengidentifikasi jenis ketergantungan, fungsi persamaan regresi dan mengevaluasi indikator rumus hubungan yang dipilih. Bidang korelasi digunakan sebagai metode identifikasi koneksi. Untuk melakukan ini, semua data yang ada harus digambarkan secara grafis. Semua data yang diketahui harus diplot dalam sistem koordinat dua dimensi persegi panjang. Ini adalah bagaimana bidang korelasi terbentuk. Nilai faktor pendeskripsi ditandai sepanjang sumbu absis, sedangkan nilai faktor terikat ditandai sepanjang sumbu ordinat. Jika terdapat hubungan fungsional antar parameter, maka parameter tersebut disusun dalam bentuk garis.
Jika koefisien korelasi data tersebut kurang dari 30%, kita dapat berbicara tentang hampir tidak adanya koneksi sama sekali. Jika antara 30% dan 70%, maka ini menunjukkan adanya hubungan sedang-dekat. Indikator 100% adalah bukti koneksi fungsional.
Persamaan regresi nonlinier, seperti halnya persamaan linier, harus dilengkapi dengan indeks korelasi (R).
Korelasi untuk Regresi Berganda
Koefisien determinasi merupakan indikator kuadrat korelasi berganda. Ia berbicara tentang hubungan erat antara kumpulan indikator yang disajikan dengan karakteristik yang diteliti. Ini juga dapat berbicara tentang sifat pengaruh parameter terhadap hasil. Persamaan regresi berganda diestimasi menggunakan indikator ini.
Untuk menghitung indikator korelasi berganda, perlu dihitung indeksnya.

Metode kuadrat terkecil
Metode ini merupakan salah satu cara untuk memperkirakan faktor regresi. Esensinya adalah meminimalkan jumlah simpangan kuadrat yang diperoleh dari ketergantungan faktor pada fungsi.
Persamaan regresi linier berpasangan dapat diestimasi dengan menggunakan metode seperti itu. Jenis persamaan ini digunakan ketika hubungan linier berpasangan terdeteksi antar indikator.
Parameter Persamaan
Setiap parameter fungsi regresi linier memiliki arti tertentu. Persamaan regresi linier berpasangan berisi dua parameter: c dan m. Parameter m menunjukkan perubahan rata-rata pada indikator akhir fungsi y, asalkan variabel x berkurang (meningkat) sebesar satu satuan konvensional. Jika variabel x sama dengan nol, maka fungsinya sama dengan parameter c. Jika variabel x tidak nol, maka faktor c tidak mempunyai arti ekonomis. Satu-satunya pengaruh terhadap fungsi tersebut adalah tanda di depan faktor c. Jika ada yang minus maka bisa dikatakan perubahan hasilnya lambat dibandingkan faktornya. Jika ada nilai tambah, maka ini menunjukkan percepatan perubahan hasil.

Setiap parameter yang mengubah nilai persamaan regresi dapat dinyatakan melalui persamaan. Misalnya faktor c berbentuk c = y - mx.
Data yang dikelompokkan
Ada kondisi tugas di mana semua informasi dikelompokkan berdasarkan atribut x, tetapi untuk kelompok tertentu nilai rata-rata yang sesuai dari indikator dependen ditunjukkan. Dalam hal ini, nilai rata-rata mencirikan bagaimana indikator yang bergantung pada x berubah. Dengan demikian, informasi yang dikelompokkan membantu menemukan persamaan regresi. Ini digunakan sebagai analisis hubungan. Namun, metode ini mempunyai kelemahan. Sayangnya, indikator rata-rata sering kali dipengaruhi oleh fluktuasi eksternal. Fluktuasi ini tidak mencerminkan pola hubungan; mereka hanya menutupi “kegaduhan” yang ada. Rata-rata menunjukkan pola hubungan yang jauh lebih buruk daripada persamaan regresi linier. Namun, mereka dapat digunakan sebagai dasar untuk menemukan persamaan. Dengan mengalikan jumlah populasi individu dengan rata-rata yang bersangkutan, kita dapat memperoleh jumlah y dalam kelompok tersebut. Selanjutnya, Anda perlu menjumlahkan semua jumlah yang diterima dan menemukan indikator akhir y. Sedikit lebih sulit melakukan perhitungan dengan indikator penjumlahan xy. Jika intervalnya kecil, kita dapat mengambil kondisional indikator x untuk semua unit (dalam grup) menjadi sama. Anda harus mengalikannya dengan jumlah y untuk mengetahui jumlah hasil kali x dan y. Selanjutnya, semua jumlah dijumlahkan dan diperoleh jumlah total xy.
Persamaan regresi berpasangan berganda: menilai pentingnya suatu hubungan
Seperti yang telah dibahas sebelumnya, regresi berganda memiliki fungsi berbentuk y = f (x 1,x 2,…,x m)+E. Paling sering, persamaan seperti itu digunakan untuk menyelesaikan masalah penawaran dan permintaan suatu produk, pendapatan bunga atas pembelian kembali saham, dan untuk mempelajari penyebab dan jenis fungsi biaya produksi. Persamaan ini juga digunakan secara aktif dalam berbagai studi dan penghitungan makroekonomi, namun pada tingkat mikroekonomi, persamaan ini lebih jarang digunakan.
Tugas utama regresi berganda adalah membangun model data yang berisi sejumlah besar informasi untuk menentukan lebih lanjut apa pengaruh masing-masing faktor secara individu dan totalitas terhadap indikator yang perlu dimodelkan dan koefisiennya. Persamaan regresi dapat mempunyai nilai yang sangat beragam. Dalam hal ini, untuk menilai hubungan, biasanya digunakan dua jenis fungsi: linier dan nonlinier.

Fungsi linier digambarkan dalam bentuk hubungan berikut: y = a 0 + a 1 x 1 + a 2 x 2,+ ... + a m x m. Dalam hal ini, a2, am dianggap sebagai koefisien regresi “murni”. Mereka diperlukan untuk mengkarakterisasi perubahan rata-rata parameter y dengan perubahan (penurunan atau peningkatan) di setiap parameter x yang sesuai sebanyak satu unit, tergantung pada nilai stabil dari indikator lainnya.
Persamaan nonlinier, misalnya, berbentuk fungsi pangkat y=ax 1 b1 x 2 b2 ...x m bm. Dalam hal ini, indikator b 1, b 2 ..... b m disebut koefisien elastisitas, indikator tersebut menunjukkan bagaimana hasilnya akan berubah (berapa%) dengan peningkatan (penurunan) indikator yang sesuai x sebesar 1% dan dengan indikator stabil dari faktor-faktor lain.
Faktor-faktor apa saja yang perlu dipertimbangkan saat membuat regresi berganda
Untuk membangun regresi berganda dengan benar, perlu diketahui faktor-faktor mana yang harus mendapat perhatian khusus.
Penting untuk memahami sifat hubungan antara faktor-faktor ekonomi dan apa yang dimodelkan. Faktor-faktor yang perlu dimasukkan harus memenuhi kriteria berikut:
- Harus tunduk pada pengukuran kuantitatif. Untuk menggunakan faktor yang menggambarkan kualitas suatu objek, bagaimanapun juga, faktor tersebut harus diberikan bentuk kuantitatif.
- Seharusnya tidak ada interkorelasi faktor, atau hubungan fungsional. Tindakan seperti itu paling sering menimbulkan konsekuensi yang tidak dapat diubah - sistem persamaan biasa menjadi tidak bersyarat, dan ini menyebabkan perkiraannya tidak dapat diandalkan dan tidak jelas.
- Dalam kasus indikator korelasi yang sangat besar, tidak ada cara untuk mengetahui pengaruh faktor-faktor yang terisolasi terhadap hasil akhir indikator, oleh karena itu, koefisien menjadi tidak dapat diinterpretasikan.
Metode konstruksi
Ada banyak sekali metode dan metode yang menjelaskan bagaimana Anda dapat memilih faktor untuk suatu persamaan. Namun, semua metode ini didasarkan pada pemilihan koefisien dengan menggunakan indikator korelasi. Diantaranya adalah:
- Metode eliminasi.
- Metode peralihan.
- Analisis regresi bertahap.
Metode pertama melibatkan menyaring semua koefisien dari total set. Metode kedua melibatkan pengenalan banyak faktor tambahan. Nah, yang ketiga adalah penghapusan faktor-faktor yang sebelumnya digunakan untuk persamaan tersebut. Masing-masing metode ini memiliki hak untuk hidup. Mereka memiliki pro dan kontra, namun mereka semua dapat menyelesaikan masalah menghilangkan indikator yang tidak perlu dengan cara mereka sendiri. Biasanya, hasil yang diperoleh dari masing-masing metode cukup mirip.
Metode analisis multivariat
Metode penentuan faktor tersebut didasarkan pada pertimbangan kombinasi individu dari karakteristik yang saling terkait. Ini termasuk analisis diskriminan, pengenalan bentuk, analisis komponen utama, dan analisis cluster. Selain itu juga terdapat analisis faktor, namun muncul karena berkembangnya metode komponen. Semuanya berlaku dalam keadaan tertentu, tergantung pada kondisi dan faktor tertentu.
Setelah analisis korelasi mengungkapkan adanya hubungan statistik antar variabel dan menilai tingkat kedekatannya, kita biasanya beralih ke deskripsi matematis dari jenis ketergantungan tertentu menggunakan analisis regresi. Untuk tujuan ini, kelas fungsi dipilih yang menghubungkan indikator resultan y dan argumen x 1, x 2, ..., x k, argumen paling informatif dipilih, perkiraan nilai parameter yang tidak diketahui persamaan komunikasi dihitung, dan sifat-sifat persamaan yang dihasilkan dianalisis.
Fungsi f(x 1, x 2,..., xk) yang menggambarkan ketergantungan nilai rata-rata karakteristik resultan y pada nilai argumen tertentu disebut fungsi regresi (persamaan). Istilah "regresi" (Latin -regression - kemunduran, kembali ke sesuatu) diperkenalkan oleh psikolog dan antropolog Inggris F. Galton dan dikaitkan secara eksklusif dengan spesifik dari salah satu contoh spesifik pertama di mana konsep ini digunakan. Jadi, dalam mengolah data statistik sehubungan dengan analisis hereditas tinggi badan, F. Galton menemukan bahwa jika ayah menyimpang dari rata-rata tinggi badan semua ayah sebesar x inci, maka anak laki-lakinya menyimpang dari rata-rata tinggi badan semua anak laki-lakinya kurang dari x. inci. Tren yang teridentifikasi disebut “regresi terhadap nilai tengah”. Sejak itu, istilah “regresi” telah banyak digunakan dalam literatur statistik, meskipun dalam banyak kasus istilah ini tidak secara akurat menggambarkan konsep ketergantungan statistik.
Untuk menggambarkan persamaan regresi secara akurat, perlu diketahui hukum distribusi indikator efektif y. Dalam praktik statistik, seseorang biasanya harus membatasi diri pada pencarian perkiraan yang sesuai untuk fungsi regresi sebenarnya yang tidak diketahui, karena peneliti tidak memiliki pengetahuan pasti tentang hukum distribusi probabilitas bersyarat dari indikator resultan y yang dianalisis untuk nilai tertentu dari argumen x.
Mari kita perhatikan hubungan antara f(x) = M(y1x) yang sebenarnya, model regresi? dan estimasi regresi y. Misalkan indikator efektif y dihubungkan dengan argumen x melalui relasi:
dimana adalah variabel acak yang mempunyai hukum distribusi normal, dan Me = 0 dan D e = y 2. Fungsi regresi sebenarnya dalam hal ini berbentuk: f (x) = M(y/x) = 2x 1.5.
Mari kita asumsikan bahwa kita tidak mengetahui bentuk pasti dari persamaan regresi yang sebenarnya, namun kita mempunyai sembilan pengamatan terhadap variabel acak dua dimensi yang dihubungkan dengan relasi yi = 2x1.5 + e, dan disajikan pada Gambar. 1
Gambar 1 - Posisi relatif kebenaran f(x) dan teoritis? model regresi
Lokasi titik pada Gambar. 1 memungkinkan kita membatasi diri pada kelas ketergantungan linier dalam bentuk? = dalam 0 + dalam 1 x. Dengan menggunakan metode kuadrat terkecil, kita mencari estimasi persamaan regresi y = b 0 + b 1 x. Sebagai perbandingan, pada Gambar. 1 menunjukkan grafik fungsi regresi sebenarnya y = 2x 1,5, fungsi regresi aproksimasi teoritis? = dalam 0 + dalam 1 x .
Karena kita melakukan kesalahan dalam memilih kelas fungsi regresi, dan hal ini cukup umum terjadi dalam praktik penelitian statistik, kesimpulan dan perkiraan statistik kita akan menjadi salah. Dan tidak peduli seberapa banyak kita meningkatkan jumlah observasi, estimasi sampel kita y tidak akan mendekati fungsi regresi sebenarnya f(x). Jika kita telah memilih kelas fungsi regresi dengan benar, maka ketidakakuratan dalam mendeskripsikan f(x) menggunakan? hanya dapat dijelaskan dengan keterbatasan sampel.
Untuk memulihkan yang terbaik, dari data statistik asli, nilai kondisional dari indikator efektif y(x) dan fungsi regresi yang tidak diketahui f(x) = M(y/x), kriteria kecukupan (fungsi kerugian) berikut ini adalah yang paling sering digunakan.
Metode kuadrat terkecil. Menurutnya, kuadrat deviasi nilai observasi dari indikator efektif y, (i = 1,2,..., n) dari nilai model,? = f(x i), dimana x i adalah nilai vektor argumen pada observasi ke-i: ?(y i - f(x i) 2 > min. Regresi yang dihasilkan disebut mean square.
Metode modul terkecil. Menurutnya, jumlah deviasi absolut dari nilai yang diamati dari indikator efektif dari nilai modular diminimalkan. Dan kita mengerti,? = f(x i), berarti regresi median absolut? |kamu saya - f(x saya)| > menit.
Analisis regresi adalah metode analisis statistik ketergantungan variabel acak y pada variabel x j = (j = 1,2,...,k), yang dalam analisis regresi dianggap sebagai variabel non-acak, terlepas dari hukum distribusi sebenarnya dari xj.
Biasanya diasumsikan bahwa variabel acak y mempunyai hukum distribusi normal dengan ekspektasi bersyarat y, yang merupakan fungsi dari argumen x/ (/ = 1, 2,..., k) dan varians konstan y 2 tidak bergantung pada argumen.
Secara umum model analisis regresi linier mempunyai bentuk:
Y = Y k j=0 V J ts J(X 1 , X 2 . . .. ,X k)+E
dimana q j adalah suatu fungsi dari variabelnya - x 1, x 2. . .. ,x k, E adalah variabel acak dengan ekspektasi matematis dan varians y 2 nol.
Dalam analisis regresi, jenis persamaan regresi dipilih berdasarkan sifat fisik dari fenomena yang diteliti dan hasil observasi.
Estimasi parameter persamaan regresi yang tidak diketahui biasanya diperoleh dengan menggunakan metode kuadrat terkecil. Di bawah ini kami akan membahas masalah ini secara lebih rinci.
Persamaan regresi linier bivariat. Mari kita asumsikan, berdasarkan analisis fenomena yang diteliti, bahwa pada “rata-rata” y adalah fungsi linier dari x, yaitu terdapat persamaan regresi
y=M(y/x)=dalam 0 + dalam 1 x)
dimana M(y1x) adalah ekspektasi matematis bersyarat dari variabel acak y untuk x tertentu; pada 0 dan pada 1 - parameter populasi umum yang tidak diketahui, yang harus diperkirakan berdasarkan hasil pengamatan sampel.
Misalkan untuk mengestimasi parameter pada 0 dan 1, diambil sampel berukuran n dari populasi dua dimensi (x, y), dimana (x, y,) adalah hasil observasi ke-i (i = 1 , 2,..., n) . Dalam hal ini model analisis regresi berbentuk:
y j = dalam 0 + dalam 1 x+e j .
dimana e j adalah variabel acak bebas berdistribusi normal dengan ekspektasi dan varian matematis nol y 2, yaitu M e j. = 0;
D e j .= y 2 untuk semua i = 1, 2,..., n.
Menurut metode kuadrat terkecil, sebagai perkiraan parameter yang tidak diketahui pada 0 dan 1, seseorang harus mengambil nilai karakteristik sampel b 0 dan b 1 yang meminimalkan jumlah simpangan kuadrat dari nilai-nilai yang dihasilkan. karakteristik i dari ekspektasi matematis bersyarat? Saya
Kami akan mempertimbangkan metodologi untuk menentukan pengaruh karakteristik pemasaran terhadap laba suatu perusahaan dengan menggunakan contoh tujuh belas perusahaan tipikal dengan ukuran rata-rata dan indikator kegiatan ekonomi.
Saat memecahkan masalah, karakteristik berikut diperhitungkan, yang diidentifikasi sebagai yang paling signifikan (penting) sebagai hasil survei kuesioner:
* aktivitas inovatif perusahaan;
* merencanakan jangkauan produk yang dihasilkan;
* pembentukan kebijakan penetapan harga;
* hubungan masyarakat;
* sistem penjualan;
* sistem insentif karyawan.
Berdasarkan sistem perbandingan faktor, matriks kedekatan persegi dibangun, di mana nilai prioritas relatif dihitung untuk setiap faktor: aktivitas inovatif perusahaan, perencanaan rangkaian produk, pembentukan kebijakan harga, periklanan , hubungan masyarakat, sistem penjualan, sistem insentif karyawan.
Perkiraan prioritas untuk faktor “hubungan dengan masyarakat” diperoleh dari hasil survei terhadap para pakar perusahaan. Notasi berikut diterima: > (lebih baik), > (lebih baik atau sama), = (sama),< (хуже или одинаково), <
Selanjutnya, masalah penilaian komprehensif terhadap tingkat pemasaran suatu perusahaan diselesaikan. Saat menghitung indikator, signifikansi (bobot) dari karakteristik parsial yang dipertimbangkan ditentukan dan masalah konvolusi linier dari indikator parsial diselesaikan. Pemrosesan data dilakukan dengan menggunakan program yang dikembangkan khusus.
Selanjutnya, penilaian komprehensif terhadap tingkat pemasaran suatu perusahaan dihitung - koefisien pemasaran, yang dimasukkan dalam Tabel 1. Selain itu, tabel tersebut mencakup indikator-indikator yang mencirikan perusahaan secara keseluruhan. Data dalam tabel akan digunakan untuk melakukan analisis regresi. Atribut yang dihasilkan adalah keuntungan. Selain koefisien pemasaran, indikator-indikator berikut digunakan sebagai indikator faktor: volume output kotor, biaya aset tetap, jumlah karyawan, dan koefisien spesialisasi.
Tabel 1 - Data awal untuk analisis regresi

Berdasarkan data tabel dan berdasarkan faktor-faktor dengan nilai koefisien korelasi paling signifikan, fungsi regresi ketergantungan keuntungan pada faktor-faktor dibangun.
Persamaan regresi dalam kasus kita akan berbentuk:
Pengaruh kuantitatif faktor-faktor yang dibahas di atas terhadap jumlah keuntungan ditunjukkan oleh koefisien persamaan regresi. Mereka menunjukkan berapa ribu rubel nilainya berubah ketika karakteristik faktor berubah sebesar satu unit. Sebagai berikut dari persamaan tersebut, peningkatan koefisien bauran pemasaran sebesar satu unit memberikan peningkatan laba sebesar 1.547,7 ribu rubel. Hal ini menunjukkan bahwa peningkatan kegiatan pemasaran mempunyai potensi yang sangat besar untuk meningkatkan kinerja ekonomi perusahaan.
Dalam mempelajari efektivitas pemasaran, faktor yang paling menarik dan terpenting adalah faktor X5 – koefisien pemasaran. Sesuai dengan teori statistik, keunggulan persamaan regresi berganda yang ada adalah kemampuannya untuk mengevaluasi pengaruh terisolasi dari setiap faktor, termasuk faktor pemasaran.
Hasil analisis regresi memiliki penerapan yang lebih luas dibandingkan untuk menghitung parameter persamaan. Kriteria untuk mengklasifikasikan perusahaan (Kef) sebagai perusahaan yang relatif lebih baik atau relatif lebih buruk didasarkan pada indikator relatif dari hasil:

di mana Y facti adalah nilai sebenarnya dari perusahaan ke-i, ribuan rubel;
Y dihitung - besarnya keuntungan perusahaan ke-i, diperoleh dengan perhitungan menggunakan persamaan regresi
Dalam kaitannya dengan masalah yang dipecahkan, nilai tersebut disebut “koefisien efisiensi”. Kegiatan suatu perusahaan dapat dianggap efektif jika nilai koefisiennya lebih besar dari satu. Artinya keuntungan sebenarnya lebih besar dari rata-rata keuntungan atas sampel.
Nilai keuntungan aktual dan perkiraan disajikan pada tabel. 2.
Tabel 2 - Analisis karakteristik yang dihasilkan dalam model regresi

Analisis tabel menunjukkan bahwa dalam kasus kami, kegiatan perusahaan 3, 5, 7, 9, 12, 14, 15, 17 untuk periode yang ditinjau dapat dianggap berhasil.
Analisis regresi adalah salah satu metode penelitian statistik yang paling populer. Dapat digunakan untuk mengetahui besarnya pengaruh variabel independen terhadap variabel dependen. Microsoft Excel memiliki alat yang dirancang untuk melakukan analisis jenis ini. Mari kita lihat apa itu dan bagaimana menggunakannya.
Namun, untuk menggunakan fungsi yang memungkinkan Anda melakukan analisis regresi, Anda harus mengaktifkan Paket Analisis terlebih dahulu. Hanya kemudian alat yang diperlukan untuk prosedur ini akan muncul di pita Excel.


Sekarang ketika kita pergi ke tab "Data", pada pita di kotak peralatan "Analisa" kita akan melihat tombol baru - "Analisis Data".

Jenis Analisis Regresi
Ada beberapa jenis regresi:
- parabola;
- tenang;
- logaritma;
- eksponensial;
- demonstratif;
- hiperbolis;
- regresi linier.
Kami akan membahas lebih detail tentang melakukan jenis analisis regresi terakhir di Excel nanti.
Regresi Linier di Excel
Di bawah ini, sebagai contoh, adalah tabel yang menunjukkan rata-rata suhu udara harian di luar dan jumlah pelanggan toko pada hari kerja yang bersangkutan. Mari kita cari tahu dengan menggunakan analisis regresi bagaimana kondisi cuaca berupa suhu udara dapat mempengaruhi kehadiran suatu perusahaan retail.
Persamaan regresi linier umum adalah sebagai berikut: Y = a0 + a1x1 +...+akhk. Dalam rumus ini Y berarti suatu variabel, pengaruh faktor-faktor yang ingin kita pelajari. Dalam kasus kami, ini adalah jumlah pembeli. Arti X adalah berbagai faktor yang mempengaruhi suatu variabel. Pilihan A adalah koefisien regresi. Artinya, merekalah yang menentukan signifikansi suatu faktor tertentu. Indeks k menunjukkan jumlah total faktor-faktor yang sama.


Analisis hasil analisis
Hasil analisis regresi ditampilkan dalam bentuk tabel di tempat yang ditentukan dalam pengaturan.

Salah satu indikator utamanya adalah R-persegi. Ini menunjukkan kualitas model. Dalam kasus kami, koefisien ini adalah 0,705 atau sekitar 70,5%. Ini adalah tingkat kualitas yang dapat diterima. Ketergantungan kurang dari 0,5 itu buruk.
Indikator penting lainnya terletak pada sel di perpotongan garis "persimpangan Y" dan kolom "Kemungkinan". Ini menunjukkan nilai Y yang akan dimiliki, dan dalam kasus kita, ini adalah jumlah pembeli, dengan semua faktor lainnya sama dengan nol. Dalam tabel ini, nilainya adalah 58,04.
Nilai pada perpotongan grafik "Variabel X1" Dan "Kemungkinan" menunjukkan tingkat ketergantungan Y pada X. Dalam kasus kami, ini adalah tingkat ketergantungan jumlah pelanggan toko terhadap suhu. Koefisien 1,31 dianggap sebagai indikator pengaruh yang cukup tinggi.
Seperti yang Anda lihat, menggunakan Microsoft Excel cukup mudah untuk membuat tabel analisis regresi. Tetapi hanya orang terlatih yang dapat bekerja dengan data keluaran dan memahami esensinya.
Dalam karyanya sejak tahun 1908. Dia menggambarkannya dengan menggunakan contoh pekerjaan seorang agen yang menjual real estat. Dalam catatannya, spesialis penjualan rumah melacak berbagai macam data masukan untuk setiap bangunan tertentu. Berdasarkan hasil lelang, ditentukan faktor mana yang paling besar pengaruhnya terhadap harga transaksi.
Analisis terhadap sejumlah besar transaksi membuahkan hasil yang menarik. Harga akhir dipengaruhi oleh banyak faktor, terkadang mengarah pada kesimpulan yang paradoks dan bahkan “pencilan” yang jelas ketika sebuah rumah dengan potensi awal yang tinggi dijual dengan harga yang lebih rendah.
Contoh kedua penerapan analisis tersebut adalah pekerjaan yang dipercayakan untuk menentukan remunerasi pegawai. Kompleksitas tugas ini terletak pada kenyataan bahwa tugas tersebut tidak memerlukan pembagian jumlah yang tetap kepada semua orang, tetapi kepatuhan yang ketat terhadap pekerjaan spesifik yang dilakukan. Munculnya banyak masalah dengan solusi praktis serupa memerlukan studi yang lebih rinci pada tingkat matematika.
Tempat penting dialokasikan pada bagian “analisis regresi”, yang menggabungkan metode praktis yang digunakan untuk mempelajari dependensi yang termasuk dalam konsep regresi. Hubungan ini diamati antara data yang diperoleh dari studi statistik.
Di antara banyak tugas yang harus diselesaikan, tujuan utamanya adalah tiga: penentuan persamaan regresi umum; membuat estimasi parameter yang tidak diketahui yang merupakan bagian dari persamaan regresi; pengujian hipotesis regresi statistik. Dalam mempelajari hubungan yang timbul antara sepasang besaran yang diperoleh dari hasil pengamatan percobaan dan merupakan suatu deret (himpunan) yang bertipe (x1, y1), ..., (xn, yn), mereka mengandalkan ketentuan teori regresi dan berasumsi bahwa untuk satu besaran Y terdapat distribusi probabilitas tertentu, sedangkan besaran X lainnya tetap.
Hasil Y bergantung pada nilai variabel X; ketergantungan ini dapat ditentukan oleh berbagai pola, sedangkan keakuratan hasil yang diperoleh dipengaruhi oleh sifat pengamatan dan tujuan analisis. Model eksperimental didasarkan pada asumsi-asumsi tertentu yang disederhanakan namun masuk akal. Syarat utamanya adalah parameter X merupakan besaran yang terkendali. Nilainya ditetapkan sebelum percobaan dimulai.
Jika sepasang variabel tak terkendali XY digunakan selama percobaan, maka analisis regresi dilakukan dengan cara yang sama, tetapi metode digunakan untuk menginterpretasikan hasil, di mana hubungan variabel acak yang diteliti dipelajari bukanlah topik yang abstrak. Mereka menemukan penerapannya dalam kehidupan di berbagai bidang aktivitas manusia.
Dalam literatur ilmiah, istilah analisis regresi linier banyak digunakan untuk mendefinisikan metode di atas. Untuk variabel X digunakan istilah regressor atau prediktor, dan variabel dependen Y disebut juga variabel kriteria. Terminologi ini hanya mencerminkan ketergantungan matematis dari variabel-variabel, tetapi tidak mencerminkan hubungan sebab-akibat.
Analisis regresi merupakan metode yang paling umum digunakan dalam mengolah hasil berbagai macam observasi. Ketergantungan fisik dan biologis dipelajari dengan menggunakan metode ini; diterapkan baik di bidang ekonomi maupun teknologi. Banyak bidang lain yang menggunakan model analisis regresi. Analisis varians dan analisis statistik multivariat erat kaitannya dengan metode penelitian ini.