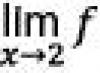7.1. Analisis Regresi Linier terdiri dari pemasangan grafik ke sekumpulan observasi menggunakan metode kuadrat terkecil. Analisis regresi memungkinkan kita membangun hubungan fungsional antara beberapa variabel acak Y dan ada pula yang mempengaruhi Y nilai-nilai X. Ketergantungan ini disebut persamaan regresi. Ada yang sederhana ( y=m*x+b) dan jamak ( y=m 1 *x 1 +m 2 *x 2 +... + m k *x k +b) regresi tipe linier dan nonlinier.
Untuk menilai derajat hubungan antar besaran digunakan Koefisien korelasi berganda Pearson R(rasio korelasi), yang dapat mengambil nilai dari 0 hingga 1. R=0 jika tidak ada hubungan antar besaran, dan R=1 jika ada hubungan fungsional antar besaran. Dalam kebanyakan kasus, R mengambil nilai antara dari 0 hingga 1. Nilai R 2 ditelepon koefisien determinasi.
Tugas membangun ketergantungan regresi adalah mencari vektor koefisien M model regresi linier berganda, dimana koefisiennya R mengambil nilai maksimum.
Untuk menilai signifikansi R berlaku uji F Fisher, dihitung dengan rumus:
Di mana N– jumlah percobaan; k– jumlah koefisien model. Jika F melebihi beberapa nilai kritis untuk data N Dan k dan probabilitas kepercayaan yang diterima, maka nilainya R dianggap signifikan.
7.2. Alat Regresi dari Paket analisis memungkinkan Anda menghitung data berikut:
· koefisien fungsi regresi linier– metode kuadrat terkecil; jenis fungsi regresi ditentukan oleh struktur sumber data;
· koefisien determinasi dan besaran-besaran yang berkaitan(meja Statistik regresi);
· tabel varians dan statistik kriteria untuk menguji signifikansi regresi(meja Analisis varians);
· standar deviasi dan karakteristik statistik lainnya untuk setiap koefisien regresi, memungkinkan Anda memeriksa signifikansi koefisien ini dan membangun interval kepercayaan untuk koefisien tersebut;
· nilai fungsi regresi dan residu– perbedaan antara nilai awal variabel Y dan nilai fungsi regresi yang dihitung (tabel Penarikan saldo);
· probabilitas yang sesuai dengan nilai variabel Y yang diurutkan dalam urutan menaik(meja Keluaran probabilitas).
7.3. Hubungi alat seleksi melalui Data > Analisis Data > Regresi.

7.4. Di lapangan Interval masukan Y masukkan alamat rentang yang berisi nilai variabel terikat Y. Rentang harus terdiri dari satu kolom.
Di lapangan Interval masukan X masukkan alamat rentang yang berisi nilai variabel X. Rentang harus terdiri dari satu atau lebih kolom, tetapi tidak lebih dari 16 kolom. Jika ditentukan di kolom Interval masukan Y Dan Interval masukan X rentang menyertakan tajuk kolom, maka Anda perlu mencentang kotak opsi Tag– header ini akan digunakan dalam tabel keluaran yang dihasilkan oleh alat ini Regresi.
Kotak centang opsi Konstan - nol harus ditetapkan jika persamaan regresi memiliki konstanta B dipaksa sama dengan nol.
Pilihan Tingkat keandalan diatur ketika diperlukan untuk membuat interval kepercayaan untuk koefisien regresi dengan tingkat kepercayaan selain 0,95, yang digunakan secara default. Setelah mencentang kotak opsi Tingkat keandalan Bidang masukan tersedia di mana nilai tingkat kepercayaan baru dimasukkan.
Di daerah Sisa Ada empat opsi: Sisa, Saldo terstandar, Bagan keseimbangan Dan Jadwal seleksi. Jika setidaknya salah satunya terinstal, tabel akan muncul di hasil output Penarikan saldo, yang akan menampilkan nilai fungsi regresi dan residu – selisih antara nilai awal variabel Y dan nilai perhitungan fungsi regresi. Di daerah Kemungkinan normal Ada satu pilihan – ; instalasinya menghasilkan tabel di hasil keluaran Keluaran probabilitas dan mengarah pada konstruksi grafik yang sesuai.
7.5. Atur parameter sesuai gambar. Pastikan nilai Y adalah variabel pertama (termasuk sel dengan nama), dan nilai X adalah dua variabel lainnya (termasuk sel dengan nama). Klik OKE.


7.6. Di meja Statistik regresi Data berikut disediakan.
jamak R– akar koefisien determinasi R 2 diberikan pada baris berikutnya. Nama lain dari indikator ini adalah indeks korelasi, atau koefisien korelasi berganda.
R-persegi– koefisien determinasi R 2 ; dihitung sebagai rasio jumlah regresi kuadrat(sel C12) ke jumlah total kuadrat(sel C14).
R-kuadrat yang dinormalisasi dihitung dengan rumus
dimana n adalah banyaknya nilai variabel Y, k adalah banyaknya kolom pada interval masukan variabel X.
Kesalahan standar– akar varians sisa (sel D13).
Pengamatan– banyaknya nilai variabel Y.
7.7. DI DALAM Tabel dispersi di kolom SS jumlah kuadrat diberikan di kolom df– jumlah derajat kebebasan. di kolom MS– dispersi. Sejalan Regresi di kolom F Nilai statistik kriteria dihitung untuk menguji signifikansi regresi. Nilai ini dihitung sebagai rasio varian regresi terhadap varian sisa (sel D12 dan D13). Di kolom Signifikansi F probabilitas nilai statistik kriteria yang diperoleh dihitung. Jika probabilitas ini lebih kecil dari, misalnya, 0,05 (tingkat signifikansi tertentu), maka hipotesis tentang tidak signifikannya regresi (yaitu hipotesis bahwa semua koefisien fungsi regresi sama dengan nol) ditolak dan regresi tersebut dibatalkan. dianggap signifikan. Dalam contoh ini, regresinya tidak signifikan.
7.8. Pada tabel berikut, di kolom Kemungkinan, nilai perhitungan koefisien fungsi regresi ditulis, sedangkan di garis Persimpangan Y nilai istilah bebas ditulis B. Di kolom Kesalahan standar Deviasi standar dari koefisien dihitung.
Di kolom t-statistik Rasio nilai koefisien terhadap standar deviasinya dicatat. Ini adalah nilai statistik kriteria untuk menguji hipotesis tentang signifikansi koefisien regresi.
Di kolom Nilai-P tingkat signifikansi yang sesuai dengan nilai statistik kriteria dihitung. Jika tingkat signifikansi yang dihitung lebih kecil dari tingkat signifikansi yang ditentukan (misalnya 0,05). maka hipotesis bahwa koefisien berbeda signifikan dari nol diterima; jika tidak, hipotesis bahwa koefisien berbeda tidak signifikan dari nol diterima. Dalam contoh ini, hanya koefisiennya saja B berbeda nyata dari nol, selebihnya tidak signifikan.
Di kolom 95% terbawah Dan 95% teratas diberikan batas interval kepercayaan dengan tingkat kepercayaan 0,95. Batas-batas ini dihitung menggunakan rumus
Lebih rendah 95% = Koefisien - Kesalahan Standar * t α;
95% Atas = Koefisien + Kesalahan Standar * t α.
Di Sini t α– jumlah pesanan α
Distribusi Student t dengan derajat kebebasan (n-k-1). Dalam hal ini α
= 0,95. Batas interval kepercayaan dalam kolom dihitung dengan cara yang sama 90,0% terbawah Dan 90,0% teratas.
7.9. Perhatikan tabelnya Penarikan saldo dari hasil keluarannya. Tabel ini muncul di hasil keluaran hanya jika setidaknya satu opsi di area tersebut ditetapkan Sisa kotak dialog Regresi.

Di kolom Pengamatan nomor seri nilai variabel diberikan Y.
Di kolom Prediksi Y nilai fungsi regresi y i = f(x i) dihitung untuk nilai variabel tersebut X, yang sesuai dengan nomor seri Saya
di kolom Pengamatan.
Di kolom Sisa mengandung selisih (residu) ε i =Y-y i, dan kolom Saldo standar– residu yang dinormalisasi, yang dihitung sebagai rasio ε i / s ε. dimana s ε adalah simpangan baku dari residu. Kuadrat nilai s ε dihitung menggunakan rumus
![]()
dimana adalah rata-rata dari residu. Nilainya dapat dihitung sebagai rasio dua nilai dari tabel dispersi: jumlah sisa kuadrat (sel C13) dan derajat kebebasan dari baris tersebut Total(sel B14).
7.10. Berdasarkan nilai tabel Penarikan saldo dua jenis grafik dibangun: grafik sisa Dan jadwal seleksi(jika opsi yang sesuai ditetapkan di area tersebut Sisa kotak dialog Regresi). Mereka dibangun untuk setiap komponen variabel X terpisah.
Pada grafik keseimbangan saldo ditampilkan, mis. perbedaan antara nilai aslinya Y dan dihitung dari fungsi regresi untuk setiap nilai komponen variabel X.

Pada jadwal seleksi menampilkan nilai Y asli dan nilai fungsi regresi yang dihitung untuk setiap nilai komponen variabel X.

7.11. Tabel hasil keluaran yang terakhir adalah tabel Keluaran probabilitas. Tampaknya jika di kotak dialog Regresi opsi diinstal Plot probabilitas normal.
Nilai kolom Persentil dihitung sebagai berikut. Langkah dihitung jam = (1/n)*100%, nilai pertama adalah jam/2, yang terakhir adalah sama 100 jam/2. Mulai dari nilai kedua, setiap nilai berikutnya sama dengan nilai sebelumnya, yang ditambahkan satu langkah H.
Di kolom Y nilai variabel diberikan Y, diurutkan dalam urutan menaik. Berdasarkan data pada tabel ini, yang disebut grafik distribusi normal. Ini memungkinkan Anda menilai secara visual tingkat linearitas hubungan antar variabel X Dan Y.
8. D analisis varians
8.1. Paket analisis memungkinkan untuk tiga jenis analisis varians. Pemilihan instrumen tertentu ditentukan oleh jumlah faktor dan jumlah sampel dalam kumpulan data yang diteliti.
digunakan untuk menguji hipotesis bahwa rata-rata dua atau lebih sampel yang dimiliki oleh populasi yang sama adalah serupa.
ANOVA dua arah dengan pengulangan adalah versi analisis univariat yang lebih kompleks yang mencakup lebih dari satu sampel untuk setiap kelompok data.
ANOVA dua arah tanpa pengulangan adalah analisis varians dua arah yang tidak mencakup lebih dari satu sampel per kelompok. Digunakan untuk menguji hipotesis bahwa mean dari dua sampel atau lebih adalah sama (sampel tersebut berasal dari populasi yang sama).
8.2. ANOVA satu arah
8.2.1. Mari siapkan data untuk dianalisis. Buat lembar baru dan salin kolom ke dalamnya A, B, C, D. Hapus dua baris pertama. Data yang telah disiapkan dapat digunakan untuk melakukan Analisis varians satu arah.


8.2.2. Hubungi alat seleksi melalui Data > Analisis Data > ANOVA satu arah. Isi sesuai gambar. Klik OKE.


8.2.3. Perhatikan tabelnya Hasil: Memeriksa– jumlah pengulangan, Jumlah– jumlah nilai indikator per baris, Penyebaran– varians parsial dari indikator.
8.2.4. Meja Analisis varians: kolom pertama Sumber Variasi berisi nama dispersi, SS– jumlah deviasi kuadrat, df– derajat kebebasan, MS– rata-rata persegi, Uji-F distribusi F sebenarnya. Nilai-P– probabilitas bahwa varians yang direproduksi oleh persamaan tersebut sama dengan varians dari residu. Ini menetapkan kemungkinan bahwa penentuan kuantitatif yang diperoleh dari hubungan antara faktor-faktor dan hasilnya dapat dianggap acak. F-kritis adalah nilai F teoritis, yang selanjutnya dibandingkan dengan nilai F sebenarnya.
8.2.5. Hipotesis nol tentang persamaan ekspektasi matematis semua sampel diterima jika terjadi ketidaksetaraan Uji-F < F-kritis. hipotesis ini harus ditolak. Dalam hal ini, nilai rata-rata sampel berbeda secara signifikan.
Analisis regresi adalah metode penelitian statistik yang memungkinkan Anda menunjukkan ketergantungan suatu parameter tertentu pada satu atau lebih variabel independen. Di era pra-komputer, penggunaannya cukup sulit, terutama jika menyangkut data dalam jumlah besar. Saat ini, setelah mempelajari cara membuat regresi di Excel, Anda dapat menyelesaikan masalah statistik yang kompleks hanya dalam beberapa menit. Di bawah ini adalah contoh spesifik dari bidang ekonomi.
Jenis Regresi
Konsep ini sendiri diperkenalkan ke dalam matematika pada tahun 1886. Regresi terjadi:
- linier;
- parabola;
- tenang;
- eksponensial;
- hiperbolis;
- demonstratif;
- logaritmik.
Contoh 1
Mari kita perhatikan masalah penentuan ketergantungan jumlah anggota tim yang berhenti terhadap gaji rata-rata di 6 perusahaan industri.
Tugas. Di enam perusahaan, rata-rata gaji bulanan dan jumlah karyawan yang berhenti secara sukarela dianalisis. Dalam bentuk tabel kita memiliki:
Jumlah orang yang berhenti | Gaji |
||
30.000 rubel |
|||
35.000 rubel |
|||
40.000 rubel |
|||
45.000 rubel |
|||
50.000 rubel |
|||
55.000 rubel |
|||
60.000 rubel |
Untuk tugas menentukan ketergantungan jumlah pekerja yang berhenti terhadap gaji rata-rata di 6 perusahaan, model regresi berbentuk persamaan Y = a 0 + a 1 x 1 +...+a k x k, dimana x i adalah variabel yang mempengaruhi, i adalah koefisien regresi, dan k adalah jumlah faktor.
Untuk permasalahan ini, Y merupakan indikator keluarnya karyawan dan faktor yang mempengaruhinya adalah gaji yang dilambangkan dengan X.
Menggunakan kemampuan prosesor spreadsheet Excel
Analisis regresi di Excel harus didahului dengan penerapan fungsi bawaan pada data tabular yang ada. Namun, untuk tujuan ini lebih baik menggunakan add-on “Paket Analisis” yang sangat berguna. Untuk mengaktifkannya, Anda perlu:
- dari tab “File”, buka bagian “Opsi”;
- di jendela yang terbuka, pilih baris “Add-on”;
- klik tombol “Go” yang terletak di bawah, di sebelah kanan baris “Manajemen”;
- centang kotak di sebelah nama "Paket Analisis" dan konfirmasikan tindakan Anda dengan mengklik "Oke".
Jika semuanya dilakukan dengan benar, tombol yang diperlukan akan muncul di sisi kanan tab “Data”, terletak di atas lembar kerja Excel.
di Excel
Sekarang kita memiliki semua alat virtual yang diperlukan untuk melakukan perhitungan ekonometrik, kita dapat mulai memecahkan masalah kita. Untuk melakukan ini:
- Klik tombol “Analisis Data”;
- di jendela yang terbuka, klik tombol “Regresi”;
- pada tab yang muncul, masukkan rentang nilai Y (jumlah karyawan yang berhenti) dan X (gajinya);
- Kami mengkonfirmasi tindakan kami dengan menekan tombol "Ok".
Hasilnya, program secara otomatis akan mengisi spreadsheet baru dengan data analisis regresi. Memperhatikan! Excel memungkinkan Anda mengatur secara manual lokasi yang Anda inginkan untuk tujuan ini. Misalnya, ini bisa berupa lembar yang sama tempat nilai Y dan X berada, atau bahkan buku kerja baru yang dirancang khusus untuk menyimpan data tersebut.
Analisis hasil regresi R-squared
Di Excel, data yang diperoleh selama pemrosesan data pada contoh yang dipertimbangkan berbentuk:
Pertama-tama, Anda harus memperhatikan nilai R-kuadrat. Ini mewakili koefisien determinasi. Dalam contoh ini, R-square = 0,755 (75,5%), yaitu parameter model yang dihitung menjelaskan hubungan antara parameter yang dipertimbangkan sebesar 75,5%. Semakin tinggi nilai koefisien determinasi, semakin cocok model yang dipilih untuk tugas tertentu. Dianggap tepat untuk menggambarkan keadaan sebenarnya bila nilai R-square di atas 0,8. Jika R-kuadrat<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Analisis Peluang
Angka 64.1428 menunjukkan berapa nilai Y jika semua variabel xi pada model yang kita pertimbangkan direset ke nol. Dengan kata lain dapat dikatakan bahwa nilai parameter yang dianalisis juga dipengaruhi oleh faktor-faktor lain yang tidak dijelaskan dalam model tertentu.
Koefisien selanjutnya -0,16285 yang terletak pada sel B18 menunjukkan bobot pengaruh variabel X terhadap Y. Artinya, rata-rata gaji bulanan pegawai dalam model yang dipertimbangkan mempengaruhi jumlah orang yang berhenti bekerja dengan bobot -0,16285, yaitu. tingkat pengaruhnya sangat kecil. Tanda “-” menunjukkan bahwa koefisiennya negatif. Hal ini jelas, karena semua orang tahu bahwa semakin tinggi gaji di suatu perusahaan, semakin sedikit orang yang menyatakan keinginannya untuk memutuskan kontrak kerja atau berhenti.
Regresi berganda
Istilah ini mengacu pada persamaan hubungan dengan beberapa variabel bebas yang berbentuk:
y=f(x 1 +x 2 +…x m) + ε, dimana y adalah karakteristik resultan (variabel terikat), dan x 1, x 2,…x m adalah karakteristik faktor (variabel bebas).
Estimasi Parameter
Untuk regresi berganda (MR) dilakukan dengan menggunakan metode kuadrat terkecil (OLS). Untuk persamaan linier berbentuk Y = a + b 1 x 1 +…+b m x m + ε kita buat sistem persamaan normal (lihat di bawah)

Untuk memahami prinsip metode ini, pertimbangkan kasus dua faktor. Kemudian kita memiliki situasi yang dijelaskan oleh rumus

Dari sini kita mendapatkan:

di mana σ adalah varians dari atribut terkait yang tercermin dalam indeks.
OLS dapat diterapkan pada persamaan MR pada skala standar. Dalam hal ini kita mendapatkan persamaan:

di mana t y, t x 1, ... t xm adalah variabel terstandarisasi, yang nilai rata-ratanya sama dengan 0; β i adalah koefisien regresi standar, dan standar deviasinya adalah 1.
Harap dicatat bahwa semua β i dalam hal ini ditetapkan sebagai ternormalisasi dan terpusat, oleh karena itu perbandingannya satu sama lain dianggap benar dan dapat diterima. Selain itu, merupakan kebiasaan untuk menyaring faktor-faktor dengan membuang faktor-faktor yang memiliki nilai βi terendah.
Soal Menggunakan Persamaan Regresi Linier
Misalkan kita memiliki tabel dinamika harga untuk produk N tertentu selama 8 bulan terakhir. Penting untuk membuat keputusan tentang kelayakan membeli sejumlah batch dengan harga 1.850 rubel/t.
nomor bulan | nama bulan | harga produk N |
|
1750 rubel per ton |
|||
1755 rubel per ton |
|||
1767 rubel per ton |
|||
1760 rubel per ton |
|||
1770 rubel per ton |
|||
1790 rubel per ton |
|||
1810 rubel per ton |
|||
1840 rubel per ton |
|||
Untuk mengatasi masalah ini pada prosesor spreadsheet Excel, Anda perlu menggunakan alat “Analisis Data”, yang sudah diketahui dari contoh di atas. Selanjutnya, pilih bagian “Regresi” dan atur parameternya. Harus diingat bahwa pada kolom “Interval masukan Y” harus dimasukkan rentang nilai untuk variabel terikat (dalam hal ini, harga barang pada bulan-bulan tertentu dalam setahun), dan pada “Interval masukan X” - untuk variabel bebas (nomor bulan). Konfirmasikan tindakan dengan mengklik “Oke”. Pada lembar baru (jika diindikasikan demikian) kami memperoleh data untuk regresi.
Dengan menggunakannya, kita membuat persamaan linier dalam bentuk y=ax+b, dengan parameter a dan b adalah koefisien garis dengan nama nomor bulan dan koefisien serta garis “persimpangan Y” dari lembar dengan hasil analisis regresi. Dengan demikian, persamaan regresi linier (LR) untuk tugas 3 ditulis sebagai:
Harga produk N = 11.714* nomor bulan + 1727.54.
atau dalam notasi aljabar
kamu = 11,714 x + 1727,54
Analisis hasil
Untuk menentukan apakah persamaan regresi linier yang dihasilkan memadai, digunakan koefisien korelasi berganda (MCC) dan determinasi, serta uji Fisher dan uji t Student. Dalam spreadsheet Excel dengan hasil regresi, masing-masing disebut multiple R, R-squared, F-statistic dan t-statistic.
KMC R memungkinkan untuk menilai kedekatan hubungan probabilistik antara variabel independen dan dependen. Nilainya yang tinggi menunjukkan hubungan yang cukup kuat antara variabel “Jumlah bulan” dan “Harga produk N dalam rubel per 1 ton”. Namun sifat hubungan ini masih belum diketahui.
Kuadrat koefisien determinasi R2 (RI) merupakan ciri numerik dari proporsi sebaran total dan menunjukkan sebaran bagian mana dari data eksperimen, yaitu. nilai variabel terikat sesuai dengan persamaan regresi linier. Dalam soal yang sedang dipertimbangkan, nilai ini sama dengan 84,8%, yaitu data statistik dijelaskan dengan tingkat akurasi yang tinggi oleh SD yang dihasilkan.
Statistik F, juga disebut uji Fisher, digunakan untuk mengevaluasi signifikansi hubungan linier, menyangkal atau mengkonfirmasi hipotesis keberadaannya.
(Tes Siswa) membantu mengevaluasi signifikansi koefisien untuk suku bebas atau suku bebas dari suatu hubungan linier. Jika nilai uji-t > tcr, maka hipotesis tidak signifikannya suku bebas persamaan linear tersebut ditolak.
Dalam soal yang dipertimbangkan untuk suku bebas, dengan menggunakan alat Excel, diperoleh t = 169,20903, dan p = 2,89E-12, yaitu, kita memiliki probabilitas nol bahwa hipotesis yang benar tentang tidak pentingnya suku bebas akan ditolak. . Untuk koefisien yang tidak diketahui t=5,79405, dan p=0,001158. Dengan kata lain, kemungkinan ditolaknya hipotesis yang benar tentang tidak pentingnya koefisien untuk suatu hal yang tidak diketahui adalah 0,12%.
Dengan demikian, dapat dikatakan bahwa persamaan regresi linier yang dihasilkan sudah memadai.
Masalah kelayakan pembelian satu blok saham
Regresi berganda di Excel dilakukan menggunakan alat Analisis Data yang sama. Mari kita pertimbangkan masalah aplikasi tertentu.
Manajemen perusahaan NNN harus memutuskan kelayakan pembelian 20% saham MMM JSC. Harga paket (SP) adalah 70 juta dollar AS. Spesialis NNN telah mengumpulkan data tentang transaksi serupa. Diputuskan untuk mengevaluasi nilai kepemilikan saham berdasarkan parameter seperti itu, yang dinyatakan dalam jutaan dolar AS, seperti:
- hutang usaha (VK);
- volume omset tahunan (VO);
- piutang (VD);
- biaya aset tetap (COF).
Selain itu, digunakan parameter tunggakan upah perusahaan (V3 P) dalam ribuan dolar AS.
Solusi menggunakan prosesor spreadsheet Excel
Pertama-tama, Anda perlu membuat tabel data awal. Ini terlihat seperti ini:

- panggil jendela “Analisis Data”;
- pilih bagian “Regresi”;
- Pada kotak “Input interval Y”, masukkan rentang nilai variabel terikat dari kolom G;
- Klik ikon dengan panah merah di sebelah kanan jendela "Input interval X" dan sorot rentang semua nilai dari kolom B, C, D, F pada lembar.
Tandai item “Lembar kerja baru” dan klik “OK”.
Dapatkan analisis regresi untuk masalah tertentu.

Studi hasil dan kesimpulan
Kami “mengumpulkan” persamaan regresi dari data bulat yang disajikan di atas pada spreadsheet Excel:
SP = 0,103*SOF + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
Dalam bentuk matematika yang lebih familiar, dapat ditulis sebagai:
kamu = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Data MMM JSC disajikan pada tabel:
Menggantinya ke dalam persamaan regresi, kita mendapatkan angka 64,72 juta dolar AS. Artinya, saham MMM JSC tidak layak dibeli karena nilainya yang sebesar 70 juta dollar AS cukup melambung.
Seperti yang Anda lihat, penggunaan prosesor spreadsheet Excel dan persamaan regresi memungkinkan pengambilan keputusan yang tepat mengenai kelayakan transaksi yang sangat spesifik.
Sekarang Anda tahu apa itu regresi. Contoh Excel yang dibahas di atas akan membantu Anda memecahkan masalah praktis di bidang ekonometrika.
Konstruksi regresi linier, evaluasi parameternya dan signifikansinya dapat dilakukan lebih cepat bila menggunakan paket analisis Excel (Regresi). Mari kita perhatikan interpretasi hasil yang diperoleh dalam kasus umum ( k variabel penjelas) sesuai contoh 3.6.
Di meja statistik regresi nilai-nilai berikut diberikan:
Banyak R – koefisien korelasi berganda;
R- persegi– koefisien determinasi R 2 ;
Dinormalisasi R - persegi– disesuaikan R 2 disesuaikan dengan jumlah derajat kebebasan;
Kesalahan standar– kesalahan standar regresi S;
Pengamatan – sejumlah observasi N.
Di meja Analisis varians diberikan:
1. Kolom df - jumlah derajat kebebasan sama dengan
untuk string Regresi df = k;
untuk string Sisadf = N – k – 1;
untuk string Totaldf = N– 1.
2. Kolom SS – jumlah simpangan kuadrat sama dengan
untuk string Regresi ;
untuk string Sisa ;
untuk string Total .
3. Kolom MS varians ditentukan oleh rumus MS = SS/df:
untuk string Regresi– dispersi faktor;
untuk string Sisa– varians sisa.
4. Kolom F – nilai yang dihitung F-kriteria dihitung menggunakan rumus
F = MS(regresi)/ MS(sisa).
5. Kolom Makna F – nilai tingkat signifikansi sesuai dengan yang dihitung F-statistik .
Makna F= FDIST( F- statistik, df(regresi), df(sisa)).
Jika penting F < стандартного уровня значимости, то R 2 signifikan secara statistik.
| Kemungkinan | Kesalahan standar | t-statistik | Nilai-P | 95% terbawah | 95% teratas | |
| Y | 65,92 | 11,74 | 5,61 | 0,00080 | 38,16 | 93,68 |
| X | 0,107 | 0,014 | 7,32 | 0,00016 | 0,0728 | 0,142 |
Tabel ini menunjukkan:
1. Kemungkinan– nilai koefisien A, B.
2. Kesalahan standar– kesalahan standar koefisien regresi S a, Sb.
3. T- statistik– nilai yang dihitung T -kriteria dihitung dengan rumus:
t-statistik = Koefisien/Kesalahan standar.
4.R-nilai (signifikansi T) adalah nilai tingkat signifikansi yang sesuai dengan yang dihitung T- statistik.
R-nilai = PELAJAR(T-statistik, df(sisa)).
Jika R-arti< стандартного уровня значимости, то соответствующий коэффициент статистически значим.
5. 95% terbawah dan 95% teratas– batas bawah dan atas interval kepercayaan 95% untuk koefisien persamaan regresi linier teoritis.
| PENARIKAN SISANYA | ||
| Pengamatan | Diprediksi kamu | Residu e |
| 72,70 | -29,70 | |
| 82,91 | -20,91 | |
| 94,53 | -4,53 | |
| 105,72 | 5,27 | |
| 117,56 | 12,44 | |
| 129,70 | 19,29 | |
| 144,22 | 20,77 | |
| 166,49 | 24,50 | |
| 268,13 | -27,13 |
Di meja PENARIKAN SISANYA ditunjukkan:
di kolom Pengamatan– nomor observasi;
di kolom Dinubuatkan kamu – nilai yang dihitung dari variabel terikat;
di kolom Sisa e – perbedaan antara nilai variabel dependen yang diamati dan dihitung.
Contoh 3.6. Terdapat data (unit konvensional) mengenai biaya pangan kamu dan pendapatan per kapita X untuk sembilan kelompok keluarga:
| X | |||||||||
| kamu |
Dengan menggunakan hasil paket analisis Excel (Regresi), kita akan menganalisis ketergantungan biaya pangan terhadap pendapatan per kapita.
Hasil analisis regresi biasanya ditulis dalam bentuk:
![]()
di mana kesalahan standar koefisien regresi ditunjukkan dalam tanda kurung.
Koefisien regresi A = 65,92 dan b= 0,107. Arah komunikasi antar kamu Dan X menentukan tanda koefisien regresi B= 0,107, yaitu hubungannya langsung dan positif. Koefisien B= 0,107 menunjukkan bahwa dengan peningkatan pendapatan per kapita sebesar 1 konvensional. unit biaya pangan meningkat sebesar 0,107 unit konvensional. unit
Mari kita evaluasi signifikansi koefisien model yang dihasilkan. Signifikansi koefisien ( a, b) diperiksa oleh T-tes:
Nilai P ( A) = 0,00080 < 0,01 < 0,05
Nilai P ( B) = 0,00016 < 0,01 < 0,05,
oleh karena itu, koefisien ( a, b) signifikan pada tingkat signifikansi 1%, terlebih lagi signifikan pada tingkat signifikansi 5%. Dengan demikian, koefisien regresinya signifikan dan modelnya memadai untuk data asli.
Hasil estimasi regresi tidak hanya sesuai dengan nilai koefisien regresi yang diperoleh, tetapi juga dengan himpunan tertentu (interval kepercayaan). Dengan probabilitas 95%, interval kepercayaan untuk koefisiennya adalah (38,16 – 93,68) untuk A dan (0,0728 – 0,142) untuk B.
Kualitas model dinilai dengan koefisien determinasi R 2 .
Besarnya R 2 = 0,884 berarti faktor pendapatan per kapita dapat menjelaskan 88,4% variasi (scatter) pengeluaran makanan.
Makna R 2 diperiksa oleh F- tes: signifikansi F = 0,00016 < 0,01 < 0,05, следовательно, R 2 signifikan pada tingkat signifikansi 1%, terlebih lagi signifikan pada tingkat signifikansi 5%.
Dalam kasus regresi linier berpasangan, koefisien korelasi dapat didefinisikan sebagai ![]() . Nilai koefisien korelasi yang diperoleh menunjukkan bahwa hubungan antara biaya pangan dengan pendapatan per kapita sangat erat.
. Nilai koefisien korelasi yang diperoleh menunjukkan bahwa hubungan antara biaya pangan dengan pendapatan per kapita sangat erat.
Saat mempelajari fenomena kompleks, perlu memperhitungkan lebih dari dua faktor acak. Pemahaman yang benar tentang sifat hubungan antara faktor-faktor ini hanya dapat diperoleh jika semua faktor acak yang dipertimbangkan diperiksa sekaligus. Studi bersama terhadap tiga atau lebih faktor acak akan memungkinkan peneliti untuk menetapkan asumsi yang kurang lebih masuk akal tentang ketergantungan sebab akibat antara fenomena yang diteliti. Bentuk sederhana dari hubungan berganda adalah hubungan linier antara tiga sifat. Faktor acak dilambangkan sebagai X 1 , X 2 dan X 3. Koefisien korelasi berpasangan antara X 1 dan X 2 dilambangkan sebagai R 12, masing-masing antara X 1 dan X 3 - R 12, antara X 2 dan X 3 - R 23. Sebagai ukuran keeratan hubungan linier antara ketiga karakteristik tersebut digunakan koefisien korelasi berganda yang dilambangkan R 1 dan 23 , R 2 dan 13 , R 3 ּ 12 dan koefisien korelasi parsial, dilambangkan R 12.3 , R 13.2 , R 23.1 .
Koefisien korelasi berganda R 1,23 ketiga faktor merupakan indikator keeratan hubungan linier antara salah satu faktor (indeks sebelum titik) dengan kombinasi dua faktor lainnya (indeks setelah titik).
Nilai koefisien R selalu berkisar antara 0 hingga 1. Ketika R mendekati satu, derajat hubungan linier antara ketiga karakteristik tersebut meningkat.
Antara koefisien korelasi berganda, mis. R 2 ּ 13 , dan koefisien korelasi dua pasangan R 12 dan R 23 terdapat hubungan: masing-masing koefisien yang dipasangkan tidak boleh melebihi nilai absolutnya R 2 dan 13 .
Rumus untuk menghitung koefisien korelasi berganda dengan nilai koefisien korelasi berpasangan yang diketahui r 12, r 13 dan r 23 berbentuk:
Koefisien korelasi berganda kuadrat R 2 dipanggil koefisien determinasi berganda. Ini menunjukkan proporsi variasi variabel dependen akibat faktor-faktor yang diteliti.
Signifikansi korelasi ganda dinilai dengan F-kriteria:
![]()
N - ukuran sampel; k – sejumlah faktor. Dalam kasus kami k = 3.
hipotesis nol tentang persamaan koefisien korelasi berganda dalam populasi dengan nol ( ho:R=0) diterima jika F F<f t, dan ditolak jika
F f³ F T.
nilai teoretis F-kriteria ditentukan untuk ay 1 = k- 1 dan ay 2 = N - k derajat kebebasan dan tingkat signifikansi a yang diterima (Lampiran 1).
Contoh penghitungan koefisien korelasi berganda. Saat mempelajari hubungan antar faktor, diperoleh koefisien korelasi berpasangan ( N =15): R 12 ==0,6; g 13 = 0,3; R 23 = - 0,2.
Penting untuk mengetahui ketergantungan fitur tersebut X 2 dari tanda X 1 dan X 3, yaitu menghitung koefisien korelasi berganda:

Nilai tabel F-kriteria dengan n 1 = 2 dan n 2 = 15 – 3 = 12 derajat kebebasan dengan a = 0,05 F 0,05 = 3,89 dan pada a = 0,01 F 0,01 = 6,93.
Jadi, hubungan antar tanda R 2,13 = 0,74 signifikan pada
tingkat signifikansi 1%. F f > F 0,01 .
Dilihat dari koefisien determinasi berganda R 2 = (0,74) 2 = 0,55, variasi sifat X 2 sebesar 55% berhubungan dengan pengaruh faktor-faktor yang diteliti, dan 45% variasinya (1-R 2) tidak dapat dijelaskan oleh pengaruh variabel-variabel tersebut.
Korelasi linier parsial
Koefisien korelasi parsial adalah indikator yang mengukur derajat konjugasi dua karakteristik.
Statistik matematika memungkinkan Anda membangun korelasi antara dua karakteristik dengan nilai konstanta ketiga, tanpa melakukan eksperimen khusus, tetapi menggunakan koefisien korelasi berpasangan. R 12 , R 13 , R 23 .
Koefisien korelasi parsial dihitung dengan menggunakan rumus:

Angka-angka sebelum titik menunjukkan ciri-ciri hubungan mana yang sedang dipelajari, dan angka setelah titik menunjukkan pengaruh ciri mana yang dikecualikan (dihilangkan). Kriteria kesalahan dan signifikansi untuk korelasi parsial ditentukan dengan menggunakan rumus yang sama seperti untuk korelasi berpasangan:
 .
.
Nilai teoritis T- kriteria ditentukan untuk ay = N– 2 derajat kebebasan dan tingkat signifikansi a yang diterima (Lampiran 1).
Hipotesis nol bahwa koefisien korelasi parsial dalam populasi sama dengan nol ( H o: R= 0) diterima jika T F< T t, dan ditolak jika
T f³ T T.
Koefisien parsial dapat bernilai antara -1 dan +1. Pribadi koefisien determinasi ditemukan dengan mengkuadratkan koefisien korelasi parsial:
D 12.3 = R 2 12ּ3 ; D 13.2 = R 2 13ּ2 ; D 23ּ1 = R 2 23ּ1 .
Menentukan tingkat pengaruh parsial faktor-faktor individu pada suatu sifat efektif sambil mengecualikan (menghilangkan) hubungannya dengan sifat-sifat lain yang mendistorsi korelasi ini seringkali merupakan hal yang menarik. Kadang-kadang terjadi bahwa dengan nilai konstan dari karakteristik yang dihilangkan, tidak mungkin untuk melihat pengaruh statistiknya terhadap variabilitas karakteristik lainnya. Untuk memahami teknik menghitung koefisien korelasi parsial, perhatikan sebuah contoh. Ada tiga pilihan X, Y Dan Z. Untuk ukuran sampel N= 180 koefisien korelasi berpasangan ditentukan
rxy = 0,799; rxz = 0,57; r yz = 0,507.
Mari kita tentukan koefisien korelasi parsial:

Koefisien korelasi parsial antar parameter X Dan Y Z (R xyּz = 0,720) menunjukkan bahwa hanya sebagian kecil hubungan antara karakteristik tersebut dalam korelasi keseluruhan ( rxy= 0,799) disebabkan oleh pengaruh sifat ketiga ( Z). Kesimpulan serupa harus dibuat mengenai koefisien korelasi parsial antar parameter X dan parameter Z dengan nilai parameter konstan Y (R X zּу = 0,318 dan rxz= 0,57). Sebaliknya, koefisien korelasi parsial antar parameter Y Dan Z dengan nilai parameter konstan X r yz ּ X= 0,105 berbeda signifikan dengan koefisien korelasi keseluruhan ry z = 0,507. Dari sini jelas jika Anda memilih objek dengan nilai parameter yang sama X, lalu hubungan antar tanda Y Dan Z mereka akan memiliki hubungan yang sangat lemah, karena sebagian besar hubungan ini disebabkan oleh variasi dalam parameter X.
Dalam keadaan tertentu, koefisien korelasi parsial mungkin bertanda berlawanan dengan pasangan satu.
Misalnya saja ketika mempelajari hubungan antar karakteristik X, Y Dan Z- Koefisien korelasi berpasangan diperoleh (dengan N = 100): R xy = 0,6; R X z= 0,9;
r y z = 0,4.
Koefisien korelasi parsial tidak termasuk pengaruh karakteristik ketiga:

Contoh tersebut menunjukkan bahwa nilai koefisien pasangan dan koefisien korelasi parsial berbeda tandanya.
Metode korelasi parsial memungkinkan untuk menghitung koefisien korelasi parsial orde kedua. Koefisien ini menunjukkan hubungan antara sifat pertama dan kedua dengan nilai konstanta sifat ketiga dan keempat. Penentuan koefisien parsial orde kedua didasarkan pada koefisien parsial orde pertama dengan menggunakan rumus:

Di mana R 12 . 4 , R 13 dan 4, R 23 ּ4 - koefisien parsial, yang nilainya ditentukan oleh rumus koefisien parsial, menggunakan koefisien korelasi berpasangan R 12 , R 13 , R 14 , R 23 , R 24 , R 34 .
Koefisien korelasi berganda tiga variabel merupakan indikator keeratan hubungan linier antara salah satu sifat (huruf indeks sebelum tanda hubung) dengan gabungan dua sifat lainnya (huruf indeks setelah tanda hubung):
 ; (12.7)
; (12.7)
 (12.8)
(12.8)
Rumus ini memudahkan penghitungan koefisien korelasi berganda dengan nilai koefisien korelasi berpasangan yang diketahui r xy, r xz dan r yz.
Koefisien R tidak negatif dan selalu berkisar dari 0 hingga 1. Saat Anda mendekat R Pertama, derajat hubungan linier antara ketiga karakteristik tersebut meningkat. Antara koefisien korelasi berganda, mis. R y-xz, dan koefisien korelasi dua pasangan r yx Dan r yz terdapat hubungan sebagai berikut: masing-masing koefisien yang dipasangkan tidak boleh melebihi nilai absolutnya R y-xz.
Koefisien korelasi berganda kuadrat R 2 disebut koefisien determinasi berganda. Ini menunjukkan proporsi variasi variabel dependen di bawah pengaruh faktor-faktor yang diteliti.
Signifikansi korelasi ganda dinilai dengan
F–kriteria:
 , (12.9)
, (12.9)
N– ukuran sampel,
k– jumlah tanda; dalam kasus kami k = 3.
Nilai teoritis F– kriteria diambil dari tabel aplikasi untuk ν 1 = k–1 dan ν 2 = n–k derajat kebebasan dan tingkat signifikansi yang diterima. Hipotesis nol bahwa koefisien korelasi berganda dalam populasi sama dengan nol ( H0:R= 0) diterima jika F fakta.< F табл . dan ditolak jika F fakta. ≥ F tabel.
Akhir pekerjaan -
Topik ini termasuk dalam bagian:
Statistik matematika
Institusi pendidikan.. Universitas Negeri Gomel.. dinamai Francis Skaryna Yu M Zhuchenko..
Jika Anda memerlukan materi tambahan tentang topik ini, atau Anda tidak menemukan apa yang Anda cari, kami sarankan untuk menggunakan pencarian di database karya kami:
Apa yang akan kami lakukan dengan materi yang diterima:
Jika materi ini bermanfaat bagi Anda, Anda dapat menyimpannya ke halaman Anda di jejaring sosial:
| Menciak |
Semua topik di bagian ini:
tutorial
untuk mahasiswa yang belajar di spesialisasi 1-31 01 01 “Biologi” Gomel 2010
Mata pelajaran dan metode statistik matematika
Mata pelajaran statistika matematika adalah ilmu yang mempelajari sifat-sifat fenomena massa dalam biologi, ekonomi, teknologi dan bidang lainnya. Fenomena-fenomena tersebut biasanya disajikan secara kompleks karena adanya keragaman (variasi)
Konsep kejadian acak
Induksi statistik atau kesimpulan statistik, sebagai komponen utama metode mempelajari fenomena massa, memiliki ciri khas tersendiri. Kesimpulan statistik dibuat dengan numerik
Kemungkinan suatu kejadian acak
Karakteristik numerik dari suatu kejadian acak yang mempunyai sifat bahwa untuk serangkaian pengujian yang cukup besar, frekuensi kejadian hanya berbeda sedikit dari karakteristik ini disebut
Menghitung Probabilitas
Seringkali ada kebutuhan untuk menambah dan mengalikan probabilitas secara bersamaan. Misalnya, Anda perlu menentukan peluang mendapatkan 5 poin ketika melempar 2 dadu secara bersamaan. Kemungkinan besar jumlah yang dibutuhkan
Konsep variabel acak
Setelah mendefinisikan konsep probabilitas dan memperjelas sifat-sifat utamanya, mari kita beralih ke salah satu konsep terpenting teori probabilitas - konsep variabel acak.
Mari kita asumsikan hal itu sebagai hasilnya
Variabel acak diskrit
Variabel acak bersifat diskrit jika himpunan nilai yang mungkin terbatas, atau setidaknya dapat dihitung. Misalkan variabel acak X dapat mengambil nilai x1
Variabel acak kontinu
Berbeda dengan variabel acak diskrit yang dibahas pada subbab sebelumnya, himpunan nilai yang mungkin dari suatu variabel acak kontinu tidak hanya tidak berhingga, tetapi juga tidak tunduk pada
Ekspektasi dan varians
Seringkali ada kebutuhan untuk mengkarakterisasi distribusi variabel acak menggunakan satu atau dua indikator numerik yang mengungkapkan sifat paling penting dari distribusi ini. Untuk itu
Momen
Apa yang disebut momen distribusi variabel acak sangat penting dalam statistik matematika. Dalam ekspektasi matematis, nilai besar dari variabel acak tidak cukup diperhitungkan.
Distribusi binomial dan pengukuran probabilitas
Dalam topik ini kita akan membahas jenis utama distribusi variabel acak diskrit. Misalkan peluang terjadinya suatu kejadian acak A selama satu kali percobaan adalah sama dengan
Distribusinya berbentuk persegi panjang (seragam).
Distribusi persegi panjang (seragam) merupakan jenis distribusi kontinu yang paling sederhana. Jika suatu variabel acak X dapat mengambil nilai real apa pun pada interval (a,b), dimana a dan b adalah real
Distribusi normal memainkan peran mendasar dalam statistik matematika. Hal ini sedikit pun bukan suatu kebetulan: dalam realitas obyektif, berbagai tanda sangat sering dijumpai
Distribusi lognormal
Variabel acak Y berdistribusi lognormal dengan parameter μ dan σ jika variabel acak X = lnY berdistribusi normal dengan parameter μ dan & yang sama
Nilai rata-rata
Dari semua properti kelompok, tingkat rata-rata, yang diukur dengan nilai rata-rata suatu atribut, memiliki signifikansi teoretis dan praktis terbesar.
Nilai rata-rata suatu fitur adalah konsep yang sangat mendalam,
Sifat umum rata-rata
Untuk penggunaan nilai rata-rata yang benar, perlu diketahui sifat-sifat indikator ini: lokasi median, keabstrakan, dan kesatuan tindakan total.
Menurut nilai numeriknya
Rata-rata aritmatika
Rata-rata aritmatika, yang mempunyai sifat-sifat umum nilai rata-rata, mempunyai ciri-ciri tersendiri, yang dapat dinyatakan dengan rumus berikut:
Peringkat rata-rata (rata-rata non-parametrik)
Peringkat rata-rata ditentukan untuk karakteristik yang belum ditemukan metode pengukuran kuantitatifnya. Menurut tingkat manifestasi tanda-tanda tersebut, objek dapat diberi peringkat, yaitu
Rata-rata aritmatika tertimbang
Biasanya, untuk menghitung rata-rata aritmatika, semua nilai atribut dijumlahkan dan jumlah yang dihasilkan dibagi dengan jumlah opsi. Dalam hal ini, setiap nilai yang termasuk dalam penjumlahan akan menambahnya secara penuh
Berarti persegi
Root mean square dihitung menggunakan rumus: , (6.5) Sama dengan akar kuadrat dari jumlah tersebut
median
Median adalah nilai karakteristik yang membagi seluruh kelompok menjadi dua bagian yang sama besar: satu bagian mempunyai nilai karakteristik lebih kecil dari median, dan bagian lainnya mempunyai nilai lebih besar.
Misalnya, jika Anda punya
Rata-rata geometris
Untuk mendapatkan mean geometrik suatu grup dengan n data, Anda perlu mengalikan semua opsi dan mengekstrak akar ke-n dari hasil perkalian:
Arti harmonik
Rata-rata harmonik dihitung menggunakan rumus. (6.14) Untuk lima pilihan: 1, 4, 5, 5 Rabu
Deviasi standar adalah nilai bernama yang dinyatakan dalam satuan pengukuran yang sama dengan mean aritmatika.
Oleh karena itu, untuk membandingkan karakteristik berbeda yang dinyatakan dalam satuan berbeda dari
Batasan dan ruang lingkup
Untuk penilaian tingkat keanekaragaman yang cepat dan perkiraan, indikator paling sederhana sering digunakan: lim = (min ¸ max) – batas, yaitu nilai karakteristik terkecil dan terbesar, p =
Deviasi yang dinormalisasi
Biasanya, derajat perkembangan suatu sifat ditentukan dengan mengukurnya dan dinyatakan dengan bilangan tertentu: berat 3 kg, panjang 15 cm, 20 kait pada sayap lebah, 4% lemak dalam susu, 15 kg dari guntingan
Rata-rata dan sigma dari total kelompok
Terkadang perlu untuk menentukan mean dan sigma untuk ringkasan distribusi yang terdiri dari beberapa distribusi. Dalam hal ini, bukan distribusinya yang diketahui, melainkan hanya rata-rata dan sigmanya saja.
Kemiringan (skewness) dan kecuraman (kurtosis) kurva distribusi
Untuk sampel besar (n > 100), dua statistik lagi dihitung.
Kemiringan kurva disebut asimetri:
Seri variasi
Dengan bertambahnya jumlah kelompok yang diteliti, pola keberagaman yang tersembunyi dalam kelompok-kelompok kecil karena bentuk manifestasinya yang acak menjadi semakin nyata.
Kurva histogram dan variasi
Histogram adalah rangkaian variasi yang disajikan dalam bentuk diagram di mana nilai frekuensi yang berbeda diwakili oleh ketinggian batang yang berbeda. Histogram sebaran data ditunjukkan pada hal
Keandalan perbedaan distribusi
Hipotesis statistik adalah asumsi spesifik tentang distribusi probabilitas yang mendasari sampel data yang diamati.
Pengujian hipotesis statistik adalah proses penerimaan
Kriteria skewness dan kurtosis
Beberapa ciri tumbuhan, hewan dan mikroorganisme, bila benda-benda digabungkan ke dalam kelompok-kelompok, memberikan distribusi yang sangat berbeda dari biasanya.
Jika ada
Populasi dan sampel
Pendugaan parameter umum dengan menggunakan indikator sampel mempunyai ciri khas tersendiri.
Suatu bagian tidak pernah dapat sepenuhnya mencirikan keseluruhan, oleh karena itu merupakan ciri-ciri masyarakat umum
Batasan kepercayaan
Penting untuk menentukan besarnya kesalahan keterwakilan untuk menggunakan indikator sampel dan juga untuk menemukan kemungkinan nilai parameter umum. Proses ini disebut o
Prosedur penilaian umum
Tiga besaran yang diperlukan untuk menilai parameter umum adalah indikator sampel (), kriteria reliabilitas
Estimasi mean aritmatika
Pendugaan nilai rata-rata bertujuan untuk menetapkan nilai rata-rata umum untuk kategori objek yang diteliti. Kesalahan keterwakilan yang diperlukan untuk tujuan ini ditentukan dengan rumus:
Estimasi perbedaan rata-rata
Beberapa penelitian mengambil perbedaan dua pengukuran sebagai data primer. Hal ini mungkin terjadi ketika setiap individu dalam sampel dipelajari di dua negara bagian - baik pada usia yang berbeda, atau
Estimasi perbedaan rata-rata yang tidak dapat diandalkan dan dapat diandalkan
Hasil studi sampel yang tidak dapat diperoleh perkiraan pasti mengenai parameter umum (baik lebih besar dari nol, atau kurang dari, atau sama dengan nol) disebut tidak dapat diandalkan.
Estimasi perbedaan antara rata-rata umum
Dalam penelitian biologi, perbedaan antara dua kuantitas sangatlah penting. Berdasarkan perbedaan, perbandingan dibuat antara populasi, ras, ras, varietas, galur, famili, kelompok eksperimen dan kontrol yang berbeda (metode gr
Kriteria reliabilitas perbedaan
Mengingat pentingnya memperoleh perbedaan yang dapat diandalkan bagi para peneliti, maka terdapat kebutuhan untuk menguasai metode yang memungkinkan untuk menentukan apakah hasil yang diperoleh dapat diandalkan atau tidak.
Keterwakilan dalam kajian karakteristik kualitatif
Ciri-ciri kualitatif biasanya tidak dapat mempunyai gradasi manifestasi: ada atau tidak ada pada setiap individu, misalnya jenis kelamin, keserbagunaan, ada tidaknya ciri-ciri tertentu, kelainan bentuk.
Keandalan selisih saham
Keandalan perbedaan proporsi sampel ditentukan dengan cara yang sama seperti perbedaan rata-rata: (10.34)
Koefisien korelasi
Banyak penelitian memerlukan pemeriksaan berbagai sifat dalam keterkaitannya. Jika Anda melakukan penelitian seperti itu terhadap dua karakteristik, Anda akan melihat bahwa tidak ada variabilitas pada satu karakteristik
Kesalahan koefisien korelasi
Keandalan koefisien korelasi sampel
Kriteria koefisien korelasi sampel ditentukan dengan rumus: (11.9) dimana:
Batas kepercayaan koefisien korelasi
Batas kepercayaan nilai umum koefisien korelasi dicari secara umum dengan menggunakan rumus:
Keandalan perbedaan antara dua koefisien korelasi
Keandalan selisih koefisien korelasi ditentukan dengan cara yang sama seperti reliabilitas selisih rata-rata, menurut rumus biasa
Persamaan Regresi Lurus
Korelasi garis lurus berbeda karena dengan bentuk hubungan ini, setiap perubahan identik pada karakteristik pertama berhubungan dengan perubahan rata-rata yang pasti dan juga identik pada karakteristik lainnya.
Kesalahan dalam elemen persamaan regresi linier
Dalam persamaan regresi linier sederhana: y = a + bx, muncul tiga kesalahan keterwakilan.
1 Kesalahan koefisien regresi:
Koefisien korelasi parsial
Koefisien korelasi parsial adalah indikator yang mengukur derajat konjugasi dua karakteristik dengan nilai konstanta ketiga.
Statistik matematika memungkinkan kita membangun korelasi
Persamaan regresi linier berganda
Persamaan matematis hubungan garis lurus antara tiga variabel disebut persamaan bidang regresi linier berganda. Ini memiliki bentuk umum sebagai berikut:
Hubungan korelasi
Jika hubungan antar fenomena yang diteliti menyimpang secara signifikan dari hubungan linier, yang mudah ditentukan dari grafik, maka koefisien korelasi tidak cocok sebagai ukuran hubungan. Dia bisa menunjukkan ketidakhadirannya
Sifat-sifat hubungan korelasi
Rasio korelasi mengukur derajat korelasi dalam bentuk apapun.
Selain itu, hubungan korelasi memiliki sejumlah sifat lain yang sangat menarik dalam statistik
Kesalahan keterwakilan hubungan korelasi
Rumus pasti untuk kesalahan keterwakilan suatu hubungan korelasi belum dikembangkan. Biasanya rumus yang diberikan dalam buku teks memiliki kekurangan yang tidak selalu bisa diabaikan. Rumus ini tidak mengajarkan
Kriteria Linearitas Korelasi
Untuk menentukan derajat pendekatan ketergantungan lengkung ke bujursangkar digunakan kriteria F yang dihitung dengan rumus:
Pengaruh statistik merupakan cerminan dari keragaman atribut yang dihasilkan dari keragaman faktor (gradasinya) yang disusun dalam penelitian.
Untuk menilai pengaruh faktor neo
Pengaruh faktorial
Pengaruh faktorial adalah pengaruh statistik sederhana atau gabungan dari faktor-faktor yang diteliti.
Dalam kompleks faktor tunggal, pengaruh sederhana dari satu faktor dipelajari pada organisasi tertentu
Kompleks dispersi satu faktor
Analisis dispersi dikembangkan dan diperkenalkan ke dalam praktik penelitian pertanian dan biologi oleh ilmuwan Inggris R. A. Fisher, yang menemukan hukum distribusi rasio mean kuadrat.
Kompleks dispersi multifaktor
Pemahaman yang jelas tentang model matematis analisis varians memudahkan pemahaman tentang operasi komputasi yang diperlukan, terutama saat memproses data dari eksperimen multivariat yang lebih banyak
Transformasi
Penggunaan analisis varians yang benar untuk mengolah bahan eksperimen mengandaikan homogenitas varians antar varian (sampel), berdistribusi normal atau mendekati normal dalam
Indikator kekuatan pengaruh
Menentukan kekuatan pengaruh berdasarkan hasil diperlukan dalam biologi, pertanian, kedokteran untuk memilih cara pengaruh yang paling efektif, untuk dosis agen fisik dan kimia - seni.
Kesalahan keterwakilan merupakan indikator utama kekuatan pengaruh
Rumus kesalahan yang tepat untuk indikator utama kekuatan pengaruh belum ditemukan.
Dalam kompleks satu faktor, kesalahan keterwakilan ditentukan hanya untuk satu indikator faktorial
Batasi nilai indikator pengaruh
Indikator utama kekuatan pengaruh sama dengan bagian satu istilah dari jumlah total istilah. Selain itu, indikator ini sama dengan kuadrat rasio korelasi. Karena dua alasan ini, indikator daya
Keandalan pengaruh
Indikator utama kekuatan pengaruh yang diperoleh dalam suatu studi sampel mencirikan, pertama-tama, tingkat pengaruh yang benar-benar terwujud dalam kelompok objek yang diteliti.
Analisis Diskriminan
Analisis diskriminan merupakan salah satu metode analisis statistik multivariat. Tujuan analisis diskriminan adalah, berdasarkan pengukuran berbagai karakteristik (fitur, pasangan)
Analisis diskriminan “berhasil” jika sejumlah asumsi terpenuhi.
Asumsi bahwa besaran yang dapat diamati—karakteristik suatu benda yang dapat diukur—memiliki distribusi normal. Ini
Algoritma Analisis Diskriminan
Penyelesaian masalah diskriminasi (analisis diskriminan) terdiri dari pembagian seluruh ruang sampel (himpunan realisasi semua variabel acak multidimensi yang dipertimbangkan) menjadi sejumlah tertentu
Analisis klaster
Analisis cluster menggabungkan berbagai prosedur yang digunakan untuk melakukan klasifikasi. Sebagai hasil dari penerapan prosedur ini, kumpulan objek awal dibagi menjadi beberapa cluster atau kelompok
Metode analisis klaster
Dalam praktiknya, metode pengelompokan aglomeratif biasanya diterapkan.
Biasanya, sebelum klasifikasi dimulai, data distandarisasi (rata-ratanya dikurangi dan dibagi dengan akar kuadrat