Dalam catatan ini, distribusi χ 2 digunakan untuk menguji konsistensi suatu kumpulan data dengan distribusi probabilitas tetap. Kriteria persetujuan sering kali HAI Anda yang termasuk dalam kategori tertentu dibandingkan dengan frekuensi yang secara teoritis diharapkan jika data benar-benar memiliki distribusi yang ditentukan.
Pengujian menggunakan kriteria goodness-of-fit χ 2 dilakukan dalam beberapa tahap. Pertama, distribusi probabilitas tertentu ditentukan dan dibandingkan dengan data asli. Kedua, hipotesis diajukan tentang parameter distribusi probabilitas yang dipilih (misalnya, ekspektasi matematisnya) atau penilaiannya dilakukan. Ketiga, berdasarkan distribusi teoretis, ditentukan probabilitas teoretis yang sesuai dengan setiap kategori. Terakhir, statistik uji χ2 digunakan untuk memeriksa konsistensi data dan distribusi:
Di mana f 0- frekuensi yang diamati, fe- frekuensi teoretis atau yang diharapkan, k- jumlah kategori yang tersisa setelah penggabungan, R- jumlah parameter yang akan diestimasi.
Unduh catatan dalam atau format, contoh dalam format
Menggunakan uji kesesuaian χ2 untuk distribusi Poisson

Untuk menghitung menggunakan rumus ini di Excel, akan lebih mudah menggunakan fungsi =SUMPRODUK() (Gbr. 1).
Untuk memperkirakan parameternya λ Anda dapat menggunakan perkiraan tersebut . Frekuensi teoritis X keberhasilan (X = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 dan lebih banyak lagi) sesuai dengan parameter λ = 2.9 dapat ditentukan dengan menggunakan fungsi =POISSON.DIST(X;;FALSE). Mengalikan probabilitas Poisson dengan ukuran sampel N, kita mendapatkan frekuensi teoritis fe(Gbr. 2).

Beras. 2. Tingkat kedatangan aktual dan teoritis per menit
Sebagai berikut dari Gambar. 2, frekuensi teoritis sembilan kedatangan atau lebih tidak melebihi 1,0. Untuk memastikan bahwa setiap kategori berisi frekuensi 1,0 atau lebih besar, kategori “9 atau lebih” harus digabungkan dengan kategori “8”. Artinya, tersisa sembilan kategori (0, 1, 2, 3, 4, 5, 6, 7, 8 dan lebih banyak lagi). Karena ekspektasi matematis distribusi Poisson ditentukan berdasarkan data sampel, maka jumlah derajat kebebasannya sama dengan k – p – 1 = 9 – 1 – 1 = 7. Dengan menggunakan tingkat signifikansi 0,05, kita cari nilai kritis statistik χ 2 yang mempunyai 7 derajat kebebasan menurut rumus =CHI2.OBR(1-0.05;7) = 14.067. Aturan pengambilan keputusan dirumuskan sebagai berikut: hipotesis jam 0 ditolak jika χ 2 > 14,067, sebaliknya hipotesisnya jam 0 tidak menyimpang.
Untuk menghitung χ 2 kita menggunakan rumus (1) (Gbr. 3).

Beras. 3. Perhitungan kriteria χ 2 -goodness-of-fit untuk distribusi Poisson
Karena χ 2 = 2,277< 14,067, следует, что гипотезу jam 0 tidak dapat ditolak. Dengan kata lain, kami tidak mempunyai alasan untuk menyatakan bahwa kedatangan nasabah di bank tidak mengikuti distribusi Poisson.
Penerapan uji χ 2 -goodness-of-fit untuk distribusi normal
Dalam catatan sebelumnya, ketika menguji hipotesis tentang variabel numerik, kami berasumsi bahwa populasi yang diteliti berdistribusi normal. Untuk memeriksa asumsi ini, Anda dapat menggunakan alat grafis, misalnya plot kotak atau grafik distribusi normal (untuk lebih jelasnya lihat). Untuk ukuran sampel yang besar, uji kesesuaian χ 2 untuk distribusi normal dapat digunakan untuk menguji asumsi ini.
Mari kita perhatikan, sebagai contoh, data pengembalian 5 tahun dari 158 dana investasi (Gbr. 4). Misalkan Anda ingin yakin apakah datanya terdistribusi normal. Hipotesis nol dan alternatif dirumuskan sebagai berikut: jam 0: Hasil 5 tahun mengikuti distribusi normal, jam 1: Imbal hasil 5 tahun tidak mengikuti distribusi normal. Distribusi normal memiliki dua parameter - ekspektasi matematis μ dan deviasi standar σ, yang dapat diperkirakan berdasarkan data sampel. Dalam hal ini = 10,149 dan S = 4,773.

Beras. 4. Susunan terurut yang berisi data pengembalian tahunan rata-rata lima tahun sebesar 158 dana
Data return dana dapat dikelompokkan, misalnya ke dalam kelas (interval) dengan lebar 5% (Gambar 5).

Beras. 5. Distribusi frekuensi rata-rata imbal hasil tahunan lima tahun sebanyak 158 dana
Karena distribusi normal bersifat kontinu, maka perlu ditentukan luas bangun-bangun yang dibatasi oleh kurva distribusi normal dan batas-batas setiap interval. Selain itu, karena distribusi normal secara teoritis berkisar antara –∞ hingga +∞, maka perlu memperhitungkan luas bangun yang berada di luar batas kelas. Jadi, luas area di bawah kurva normal di sebelah kiri titik –10 sama dengan luas gambar yang terletak di bawah kurva normal terstandar di sebelah kiri nilai Z sama dengan
Z = (–10 – 10,149) / 4,773 = –4,22
Luas bangun yang terletak di bawah kurva normal terstandar di sebelah kiri nilai Z = –4,22 ditentukan dengan rumus =NORM.DIST(-10;10.149;4.773;TRUE) dan kira-kira sama dengan 0,00001. Untuk menghitung luas bangun yang terletak di bawah kurva normal antara titik –10 dan –5, pertama-tama Anda perlu menghitung luas bangun yang terletak di sebelah kiri titik –5: =NORM.DIST( -5,10.149,4.773,BENAR) = 0,00075 . Jadi luas bangun yang terletak di bawah kurva normal antara titik –10 dan –5 adalah 0,00075 – 0,00001 = 0,00074. Demikian pula, Anda dapat menghitung luas bangun yang dibatasi oleh batas masing-masing kelas (Gbr. 6).

Beras. 6. Area dan frekuensi yang diharapkan untuk setiap kelas pengembalian 5 tahun
Terlihat frekuensi teoritis pada empat kelas ekstrim (dua minimum dan dua maksimum) kurang dari 1, maka kita akan menggabungkan kelas-kelas tersebut seperti terlihat pada Gambar 7.

Beras. 7. Perhitungan terkait penggunaan uji goodness-of-fit χ 2 untuk distribusi normal
Kami menggunakan uji χ 2 untuk kesesuaian antara data dan distribusi normal menggunakan rumus (1). Dalam contoh kita, setelah penggabungan, tersisa enam kelas. Karena nilai yang diharapkan dan deviasi standar diperkirakan dari data sampel, maka jumlah derajat kebebasannya adalah k – P – 1 = 6 – 2 – 1 = 3. Dengan menggunakan tingkat signifikansi 0,05, diperoleh nilai kritis statistik χ 2 yang mempunyai tiga derajat kebebasan = CI2.OBR(1-0.05;F3) = 7.815. Perhitungan yang terkait dengan penggunaan kriteria goodness-of-fit χ 2 ditunjukkan pada Gambar. 7.
Terlihat bahwa χ 2 -statistik = 3,964< χ U 2 7,815, следовательно гипотезу jam 0 tidak dapat ditolak. Dengan kata lain, kami tidak memiliki alasan untuk percaya bahwa pengembalian 5 tahun dari dana investasi dengan pertumbuhan tinggi tidak terdistribusi secara normal.
Beberapa postingan terbaru mengeksplorasi pendekatan berbeda untuk menganalisis data kategorikal. Metode untuk menguji hipotesis tentang data kategorikal yang diperoleh dari analisis dua atau lebih sampel independen dijelaskan. Selain uji chi-kuadrat, prosedur nonparametrik juga dipertimbangkan. Tes peringkat Wilcoxon dijelaskan, yang digunakan dalam situasi di mana kondisi penerapan tidak terpenuhi T-kriteria pengujian hipotesis persamaan ekspektasi matematis dua kelompok independen, serta uji Kruskal-Wallis, yang merupakan alternatif analisis varians satu faktor (Gbr. 8).

Beras. 8. Diagram blok metode pengujian hipotesis tentang data kategorikal
Bahan yang digunakan adalah dari buku Levin et al.Statistik untuk Manajer. – M.: Williams, 2004. – hal. 763–769
Distribusi. Distribusi Pearson Kepadatan probabilitas ... Wikipedia
distribusi chi-kuadrat- distribusi chi kuadrat - Topik perlindungan informasi EN distribusi chi kuadrat ... Panduan Penerjemah Teknis
distribusi chi-kuadrat- Distribusi probabilitas suatu variabel acak kontinu dengan nilai dari 0 sampai, yang kepadatannya diberikan oleh rumus, dimana 0 untuk parameter =1,2,...; – fungsi gamma. Contoh. 1) Jumlah kuadrat acak acak ternormalisasi independen... ... Kamus Statistik Sosiologis
DISTRIBUSI CHI-SQUARE (chi2)- Distribusi variabel acak chi2. Jika sampel acak ukuran 1 diambil dari distribusi normal dengan mean (dan varians q2, maka chi2 = (X1 u)2/q2, dimana X adalah nilai sampel. Jika ukuran sampel adalah dinaikkan secara acak menjadi N, maka chi2 = … …
Kepadatan probabilitas... Wikipedia
- (Distribusi Snedecor) Kepadatan probabilitas ... Wikipedia
Distribusi Fisher Kepadatan probabilitas Fungsi distribusi Parameter bilangan dengan ... Wikipedia
Salah satu konsep dasar teori probabilitas dan statistik matematika. Dengan pendekatan modern, seperti matematika model fenomena acak yang sedang dipelajari, diambil ruang probabilitas yang sesuai (W, S, P), di mana W adalah himpunan dasar... Ensiklopedia Matematika
Distribusi gamma Kepadatan probabilitas Fungsi distribusi Parameter ... Wikipedia
DISTRIBUSI F- Distribusi probabilitas teoretis dari variabel acak F. Jika sampel acak berukuran N diambil secara independen dari populasi normal, masing-masing menghasilkan distribusi chi-kuadrat dengan derajat kebebasan = N. Rasio dua ... ... Kamus Penjelasan Psikologi
Buku
- Teori probabilitas dan statistik matematika dalam soal: Lebih dari 360 soal dan latihan, Borzykh D.. Manual yang diusulkan berisi soal-soal dengan berbagai tingkat kompleksitas. Namun, penekanan utamanya adalah pada tugas-tugas dengan kompleksitas sedang. Hal ini sengaja dilakukan untuk mendorong siswa...
- Teori probabilitas dan statistik matematika dalam masalah. Lebih dari 360 tugas dan latihan, Borzykh D.A.. Manual yang diusulkan berisi tugas-tugas dengan berbagai tingkat kompleksitas. Namun, penekanan utamanya adalah pada tugas-tugas dengan kompleksitas sedang. Hal ini sengaja dilakukan untuk mendorong siswa...
Jika nilai kriteria χ 2 yang diperoleh lebih besar dari nilai kritis, kami menyimpulkan bahwa terdapat hubungan statistik antara faktor risiko yang diteliti dan hasil pada tingkat signifikansi yang sesuai.
Contoh penghitungan uji chi-kuadrat Pearson
Mari kita tentukan signifikansi statistik pengaruh faktor merokok terhadap kejadian hipertensi arteri menggunakan tabel yang dibahas di atas:
1. Hitung nilai yang diharapkan untuk setiap sel:
2. Tentukan nilai uji chi-kuadrat Pearson:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. Banyaknya derajat kebebasan f = (2-1)*(2-1) = 1. Dengan menggunakan tabel tersebut, kita mencari nilai kritis uji chi-kuadrat Pearson, yang pada taraf signifikansi p=0,05 dan jumlah derajat kebebasan 1 adalah 3,841.
4. Kami membandingkan nilai uji chi-square yang diperoleh dengan nilai kritis: 4,396 > 3,841, oleh karena itu, ketergantungan kejadian hipertensi arteri pada adanya merokok signifikan secara statistik. Tingkat signifikansi hubungan ini sesuai dengan hal<0.05.
Selain itu, uji chi-kuadrat Pearson dihitung menggunakan rumus
Namun untuk tabel 2x2, hasil yang lebih akurat diperoleh dengan kriteria koreksi Yates

Jika  Itu tidak(0) diterima,
Itu tidak(0) diterima,
Jika ![]() diterima H(1)
diterima H(1)
Jika jumlah observasi sedikit dan sel tabel berisi frekuensi kurang dari 5, uji chi-kuadrat tidak dapat diterapkan dan digunakan untuk menguji hipotesis. Tes eksak Fisher . Prosedur untuk menghitung kriteria ini cukup memakan waktu, dan dalam hal ini lebih baik menggunakan program analisis statistik komputer.
Dengan menggunakan tabel kontingensi, Anda dapat menghitung ukuran hubungan antara dua karakteristik kualitatif - ini adalah koefisien asosiasi Yule Q (analog dengan koefisien korelasi)

Q terletak pada rentang 0 sampai 1. Koefisien yang mendekati satu menunjukkan adanya hubungan yang kuat antar karakteristik. Jika sama dengan nol maka tidak ada koneksi .
Koefisien phi-kuadrat (φ 2) digunakan dengan cara yang sama
TUGAS PATOKAN
Tabel tersebut menggambarkan hubungan frekuensi mutasi pada kelompok Drosophila dengan dan tanpa pemberian pakan
Analisis tabel kontingensi
Untuk menganalisis tabel kontingensi diajukan hipotesis H 0, yaitu tidak adanya pengaruh karakteristik yang diteliti terhadap hasil penelitian. Untuk itu, frekuensi yang diharapkan dihitung dan tabel ekspektasi dibuat.
Meja tunggu
| kelompok | Tanaman cabai | Total | ||||
| Memberikan mutasi | Tidak memberikan mutasi | |||||
| Frekuensi sebenarnya | Frekuensi yang diharapkan | Frekuensi sebenarnya | Frekuensi yang diharapkan | |||
| Dengan memberi makan | ||||||
| Tanpa memberi makan | ||||||
| total | ||||||
Metode No.1
Tentukan frekuensi tunggu:
2756 – X ![]() ;
;
2. 3561 – 3124
Jika jumlah observasi dalam kelompok kecil, saat menggunakan X 2, dalam kasus membandingkan frekuensi aktual dan frekuensi yang diharapkan untuk distribusi diskrit, beberapa ketidakakuratan dikaitkan untuk mengurangi ketidakakuratan, digunakan koreksi Yates.
Hingga akhir abad ke-19, distribusi normal dianggap sebagai hukum universal variasi data. Namun, K. Pearson mencatat bahwa frekuensi empiris dapat sangat berbeda dari distribusi normal. Timbul pertanyaan bagaimana membuktikannya. Tidak hanya diperlukan perbandingan grafis yang subjektif, tetapi juga pembenaran kuantitatif yang ketat.
Ini adalah bagaimana kriteria diciptakan χ 2(chi-square), yang menguji signifikansi perbedaan antara frekuensi empiris (yang diamati) dan teoritis (yang diharapkan). Hal ini terjadi pada tahun 1900, namun kriteria tersebut masih digunakan sampai sekarang. Selain itu, telah diadaptasi untuk memecahkan berbagai masalah. Pertama-tama, ini adalah analisis data nominal, yaitu. hal-hal yang dinyatakan bukan berdasarkan kuantitas, tetapi berdasarkan kategori tertentu. Misalnya kelas mobil, jenis kelamin peserta eksperimen, jenis tanaman, dll. Operasi matematika seperti penjumlahan dan perkalian tidak dapat diterapkan pada data tersebut; frekuensi hanya dapat dihitung untuk data tersebut.
Kami menunjukkan frekuensi yang diamati Tentang (Diamati), mengharapkan - E (Diharapkan). Sebagai contoh, mari kita ambil hasil pelemparan sebuah dadu sebanyak 60 kali. Jika simetris dan seragam, peluang terambilnya salah satu sisi adalah 1/6 sehingga banyaknya harapan terambilnya setiap sisi adalah 10 (1/6∙60). Kami menulis frekuensi yang diamati dan diharapkan dalam sebuah tabel dan menggambar histogram.
Hipotesis nol adalah frekuensinya konsisten, yaitu data aktual tidak bertentangan dengan data yang diharapkan. Hipotesis alternatifnya adalah bahwa penyimpangan frekuensi melampaui fluktuasi acak, yaitu perbedaan yang signifikan secara statistik. Untuk menarik kesimpulan yang tepat, kita perlu.
- Ukuran ringkasan dari perbedaan antara frekuensi yang diamati dan yang diharapkan.
- Distribusi ukuran ini jika hipotesis yang menyatakan tidak ada perbedaan benar.
Mari kita mulai dengan jarak antar frekuensi. Jika Anda hanya mengambil perbedaannya HAI - E, maka ukuran tersebut akan bergantung pada skala data (frekuensi). Misalnya, 20 - 5 = 15 dan 1020 - 1005 = 15. Dalam kedua kasus, selisihnya adalah 15. Namun dalam kasus pertama, frekuensi yang diharapkan 3 kali lebih kecil dari frekuensi yang diamati, dan dalam kasus kedua - hanya 1,5 %. Kita memerlukan ukuran relatif yang tidak bergantung pada skala.
Mari kita perhatikan fakta berikut ini. Secara umum, jumlah gradasi pengukuran frekuensi bisa jauh lebih besar, sehingga kemungkinan suatu pengamatan akan masuk dalam satu kategori atau lainnya cukup kecil. Jika demikian, maka distribusi variabel acak tersebut akan mematuhi hukum kejadian langka yang disebut hukum Poisson. Dalam hukum Poisson, seperti diketahui, nilai ekspektasi matematis dan variansnya bertepatan (parameter λ ). Artinya frekuensi yang diharapkan untuk beberapa kategori variabel nominal E saya akan simultan dan dispersinya. Selanjutnya hukum Poisson cenderung normal dengan jumlah pengamatan yang banyak. Menggabungkan dua fakta ini, kita memperoleh bahwa jika hipotesis tentang kesesuaian antara frekuensi yang diamati dan frekuensi yang diharapkan benar, maka, dengan jumlah observasi yang banyak, ekspresi
Akan memiliki.
Penting untuk diingat bahwa normalitas hanya akan muncul pada frekuensi yang cukup tinggi. Dalam statistika, secara umum diterima bahwa jumlah observasi (jumlah frekuensi) harus minimal 50 dan frekuensi yang diharapkan dalam setiap gradasi harus minimal 5. Hanya dalam hal ini, nilai yang ditunjukkan di atas akan memiliki standar normal distribusi. Anggap saja kondisi ini terpenuhi.
Distribusi normal standar memiliki hampir semua nilai dalam ±3 (aturan tiga sigma). Jadi, kami memperoleh perbedaan frekuensi relatif untuk satu gradasi. Kita memerlukan ukuran yang dapat digeneralisasikan. Anda tidak bisa begitu saja menjumlahkan semua penyimpangan - kita mendapatkan 0 (coba tebak). Pearson menyarankan untuk menjumlahkan kuadrat penyimpangan ini.
![]()
Inilah tandanya kriteria χ 2 Pearson. Jika frekuensinya benar-benar sesuai dengan yang diharapkan, maka nilai kriterianya akan relatif kecil (karena sebagian besar deviasi berada di sekitar nol). Namun jika kriterianya ternyata besar, maka hal ini menunjukkan perbedaan yang signifikan antar frekuensi.
Kriteria menjadi “besar” ketika kemunculan nilai tersebut atau bahkan nilai yang lebih besar menjadi tidak mungkin terjadi. Dan untuk menghitung probabilitas seperti itu, perlu diketahui distribusi kriteria ketika percobaan diulang berkali-kali, ketika hipotesis kesesuaian frekuensi benar.
Seperti yang mudah dilihat, nilai chi-kuadrat juga bergantung pada banyaknya suku. Semakin banyak, semakin besar nilai yang seharusnya dimiliki kriteria tersebut, karena setiap istilah akan berkontribusi terhadap totalnya. Oleh karena itu, untuk setiap kuantitas mandiri syaratnya, akan ada distribusinya sendiri. Ternyata itu χ 2 adalah seluruh keluarga distribusi.
Dan di sini kita sampai pada suatu momen yang sulit. Apa itu angka mandiri ketentuan? Sepertinya istilah apa pun (yaitu deviasi) bersifat independen. K. Pearson juga berpikir demikian, tetapi ternyata dia salah. Faktanya, jumlah suku bebas akan lebih sedikit satu dari jumlah gradasi variabel nominalnya N. Mengapa? Karena jika kita mempunyai sampel yang jumlah frekuensinya sudah dihitung, maka salah satu frekuensi selalu dapat ditentukan sebagai selisih antara jumlah total dan jumlah frekuensi lainnya. Oleh karena itu variasinya akan lebih sedikit. Ronald Fisher menyadari fakta ini 20 tahun setelah Pearson mengembangkan kriterianya. Bahkan meja pun harus direnovasi.
Pada kesempatan ini, Fisher memperkenalkan konsep baru ke dalam statistik - derajat kebebasan(derajat kebebasan), yang mewakili jumlah suku independen dalam penjumlahan. Konsep derajat kebebasan mempunyai penjelasan matematis dan hanya muncul pada distribusi yang berhubungan dengan normal (Student's, Fisher-Snedecor dan chi-square itu sendiri).
Untuk lebih memahami arti derajat kebebasan, mari kita beralih ke analogi fisik. Bayangkan sebuah titik bergerak bebas di ruang angkasa. Ia mempunyai 3 derajat kebebasan, karena dapat bergerak ke segala arah dalam ruang tiga dimensi. Jika suatu titik bergerak sepanjang suatu permukaan, maka titik tersebut sudah mempunyai dua derajat kebebasan (maju mundur, kiri dan kanan), meskipun tetap berada dalam ruang tiga dimensi. Suatu titik yang bergerak sepanjang pegas kembali berada dalam ruang tiga dimensi, namun hanya mempunyai satu derajat kebebasan, karena dapat bergerak maju atau mundur. Seperti yang Anda lihat, ruang tempat benda berada tidak selalu sesuai dengan kebebasan bergerak yang sebenarnya.
Dengan cara yang kira-kira sama, distribusi suatu kriteria statistik mungkin bergantung pada jumlah elemen yang lebih sedikit daripada suku-suku yang diperlukan untuk menghitungnya. Secara umum jumlah derajat kebebasan lebih sedikit dibandingkan jumlah observasi dengan jumlah dependensi yang ada. Ini murni matematika, bukan sihir.
Jadi distribusinya χ 2 adalah keluarga distribusi, yang masing-masing bergantung pada parameter derajat kebebasan. Dan definisi formal uji chi-kuadrat adalah sebagai berikut. Distribusi χ 2(chi-kuadrat) s k derajat kebebasan adalah distribusi jumlah kuadrat k variabel acak normal standar independen.
Selanjutnya, kita dapat beralih ke rumus yang digunakan untuk menghitung fungsi distribusi chi-kuadrat, tetapi untungnya, semuanya telah lama dihitung untuk kita. Untuk memperoleh probabilitas yang menarik, Anda dapat menggunakan tabel statistik yang sesuai atau fungsi siap pakai dalam perangkat lunak khusus, yang bahkan tersedia di Excel.
Menarik untuk melihat bagaimana bentuk distribusi chi-kuadrat berubah bergantung pada jumlah derajat kebebasan.

Dengan bertambahnya derajat kebebasan, distribusi chi-kuadrat cenderung normal. Hal ini dijelaskan oleh aksi teorema limit pusat, yang menyatakan bahwa jumlah sejumlah besar variabel acak independen mempunyai distribusi normal. Itu tidak mengatakan apa pun tentang kotak)).
Pengujian hipotesis menggunakan uji chi-square
Sekarang kita sampai pada pengujian hipotesis menggunakan metode chi-kuadrat. Secara umum, teknologinya tetap ada. Hipotesis nol adalah bahwa frekuensi yang diamati sesuai dengan frekuensi yang diharapkan (yaitu tidak ada perbedaan di antara keduanya karena diambil dari populasi yang sama). Jika demikian, maka penyebarannya akan relatif kecil, dalam batas fluktuasi acak. Besar kecilnya dispersi ditentukan dengan menggunakan uji chi-kuadrat. Selanjutnya, kriteria itu sendiri dibandingkan dengan nilai kritis (untuk tingkat signifikansi dan derajat kebebasan yang sesuai), atau, lebih tepat, tingkat p yang diamati dihitung, yaitu. kemungkinan diperolehnya nilai kriteria yang sama atau bahkan lebih besar jika hipotesis nolnya benar.

Karena kita tertarik pada kesepakatan frekuensi, maka hipotesis akan ditolak bila kriterianya lebih besar dari tingkat kritis. Itu. kriterianya sepihak. Namun, terkadang (terkadang) hipotesis kiri perlu diuji. Misalnya ketika data empiris sangat mirip dengan data teoritis. Kemudian kriterianya mungkin jatuh ke wilayah yang tidak terduga, tetapi di sebelah kiri. Faktanya adalah bahwa dalam kondisi alami, kecil kemungkinannya untuk memperoleh frekuensi yang secara praktis bertepatan dengan frekuensi teoritis. Selalu ada keacakan yang menimbulkan kesalahan. Namun jika tidak ada kesalahan seperti itu, mungkin data tersebut dipalsukan. Namun hipotesis sisi kanan biasanya diuji.
Mari kita kembali ke masalah dadu. Mari kita hitung nilai uji chi-kuadrat menggunakan data yang tersedia.
Sekarang mari kita cari nilai tabel kriteria pada 5 derajat kebebasan ( k) dan tingkat signifikansi 0,05 ( α ).

Yaitu χ 2 0,05; 5 = 11,1.
Mari kita bandingkan nilai aktual dan nilai tabulasi. 3.4 ( χ 2) < 11,1 (χ 2 0,05; 5). Kriteria yang dihitung ternyata lebih kecil, artinya hipotesis kesetaraan (kesepakatan) frekuensi tidak ditolak. Pada gambar, situasinya terlihat seperti ini.

Jika nilai yang dihitung berada dalam wilayah kritis, hipotesis nol akan ditolak.
Akan lebih tepat jika menghitung level p juga. Untuk melakukan ini, Anda perlu mencari nilai terdekat dalam tabel untuk sejumlah derajat kebebasan tertentu dan melihat tingkat signifikansi yang sesuai. Tapi ini adalah abad terakhir. Kami akan menggunakan komputer pribadi, khususnya MS Excel. Excel memiliki beberapa fungsi yang berkaitan dengan chi-kuadrat.

Di bawah ini adalah uraian singkatnya.
CH2.OBR– nilai kritis kriteria pada probabilitas tertentu di sebelah kiri (seperti dalam tabel statistik)
CH2.OBR.PH– nilai kritis kriteria untuk probabilitas tertentu di sebelah kanan. Fungsi ini pada dasarnya menduplikasi fungsi sebelumnya. Namun di sini Anda bisa langsung menunjukkan levelnya α , daripada mengurangkannya dengan 1. Ini lebih mudah karena dalam banyak kasus, distribusi yang tepatlah yang dibutuhkan.
CH2.DIST– level-p di sebelah kiri (kepadatan dapat dihitung).
CH2.DIST.PH– level-p di sebelah kanan.
CHI2.UJI– segera melakukan uji chi-kuadrat untuk dua rentang frekuensi tertentu. Jumlah derajat kebebasan dianggap kurang satu dari jumlah frekuensi dalam kolom (sebagaimana mestinya), sehingga menghasilkan nilai tingkat p.
Mari kita hitung untuk percobaan kita nilai kritis (tabel) untuk 5 derajat kebebasan dan alfa 0,05. Rumus Excelnya akan terlihat seperti ini:
CH2.OBR(0,95;5)
CH2.OBR.PH(0,05;5)
Hasilnya akan sama - 11.0705. Ini adalah nilai yang kita lihat di tabel (dibulatkan menjadi 1 tempat desimal).
Mari kita hitung tingkat p untuk kriteria 5 derajat kebebasan χ 2= 3.4. Kita membutuhkan probabilitas di sebelah kanan, jadi kita ambil fungsi dengan penjumlahan HH (ekor kanan)
CH2.DIST.PH(3,4;5) = 0,63857
Artinya dengan 5 derajat kebebasan peluang diperolehnya nilai kriteria adalah χ 2= 3,4 dan lebih sama dengan hampir 64%. Tentu saja, hipotesisnya tidak ditolak (level p lebih besar dari 5%), frekuensinya sangat sesuai.
Sekarang mari kita periksa hipotesis tentang kesepakatan frekuensi menggunakan fungsi CHI2.TEST.

Tanpa tabel, tanpa perhitungan yang rumit. Dengan menentukan kolom dengan frekuensi yang diamati dan diharapkan sebagai argumen fungsi, kita segera memperoleh tingkat-p. Kecantikan.
Sekarang bayangkan Anda sedang bermain dadu dengan pria yang mencurigakan. Pembagian poin dari 1 hingga 5 tetap sama, tetapi ia mendapatkan 26 angka enam (jumlah total lemparan menjadi 78).

P-level dalam hal ini ternyata 0,003, jauh lebih kecil dari 0,05. Ada alasan bagus untuk meragukan validitas dadu tersebut. Berikut adalah tampilan probabilitas pada grafik distribusi chi-kuadrat.

Uji chi-kuadrat itu sendiri di sini ternyata 17,8, yang tentu saja lebih besar dari uji tabel (11.1).
Saya harap saya bisa menjelaskan apa itu kriteria kesepakatan χ 2(Pearson chi-square) dan bagaimana penggunaannya untuk menguji hipotesis statistik.
Terakhir, sekali lagi tentang syarat penting! Uji chi-kuadrat hanya berfungsi dengan baik jika jumlah semua frekuensi melebihi 50, dan nilai minimum yang diharapkan untuk setiap gradasi tidak kurang dari 5. Jika dalam kategori mana pun frekuensi yang diharapkan kurang dari 5, namun jumlah semua frekuensi melebihi 50, maka kategori tersebut digabungkan dengan kategori terdekat sehingga frekuensi totalnya melebihi 5. Jika hal ini tidak memungkinkan, atau jumlah frekuensinya kurang dari 50, maka metode pengujian hipotesis yang lebih akurat harus digunakan. Kita akan membicarakannya lain kali.
Di bawah ini adalah video cara menguji hipotesis di Excel menggunakan uji chi-kuadrat.
Pertimbangkan aplikasi diMSUNGGULUji chi-square Pearson untuk menguji hipotesis sederhana.
Setelah memperoleh data percobaan (yaitu bila ada beberapa mencicipi) biasanya pilihan hukum distribusi dibuat yang paling menggambarkan variabel acak yang diwakili oleh suatu variabel tertentu contoh. Pengecekan seberapa baik data eksperimen dijelaskan oleh hukum distribusi teoritis yang dipilih dilakukan dengan menggunakan kriteria kesepakatan. Hipotesis nol, biasanya terdapat hipotesis tentang persamaan distribusi suatu variabel acak terhadap beberapa hukum teoritis.
Mari kita lihat aplikasinya terlebih dahulu Uji kesesuaian Pearson X 2 (chi-kuadrat) sehubungan dengan hipotesis sederhana (parameter distribusi teoritis dianggap diketahui). Kemudian - , ketika hanya bentuk distribusi yang ditentukan, dan parameter distribusi serta nilainya statistik X 2 dinilai/dihitung berdasarkan hal yang sama sampel.
Catatan: Dalam literatur berbahasa Inggris, prosedur penerapannya Tes kesesuaian Pearson X 2 memiliki nama Uji kesesuaian chi-kuadrat.
Mari kita mengingat kembali prosedur pengujian hipotesis:
- berdasarkan sampel nilainya dihitung statistik, yang sesuai dengan jenis hipotesis yang diuji. Misalnya untuk bekas T-statistik(jika tidak diketahui);
- tunduk pada kebenaran hipotesis nol, distribusi ini statistik diketahui dan dapat digunakan untuk menghitung probabilitas (misalnya, untuk T-statistik Ini );
- dihitung berdasarkan sampel arti statistik dibandingkan dengan nilai kritis untuk nilai tertentu();
- hipotesis nol tolak jika bernilai statistik lebih besar dari kritis (atau jika kemungkinan mendapatkan nilai ini statistik() lebih sedikit tingkat signifikansi, yang merupakan pendekatan yang setara).
Mari kita lakukan pengujian hipotesis untuk berbagai distribusi.
Kasus diskrit
Misalkan dua orang sedang bermain dadu. Setiap pemain memiliki set dadunya sendiri. Pemain bergiliran melempar 3 dadu sekaligus. Setiap putaran dimenangkan oleh orang yang mendapatkan angka enam terbanyak dalam satu waktu. Hasilnya dicatat. Salah satu pemain, setelah 100 putaran, mempunyai kecurigaan bahwa dadu lawannya tidak simetris, karena dia sering menang (dia sering melempar angka enam). Dia memutuskan untuk menganalisis seberapa besar kemungkinan hasil dari musuh sebanyak itu.
Catatan: Karena Ada 3 kubus, lalu Anda bisa menggulung 0 sekaligus; 1; 2 atau 3 angka enam, mis. variabel acak dapat mengambil 4 nilai.
Dari teori probabilitas kita mengetahui bahwa jika dadu simetris, maka peluang mendapatkan angka enam akan mengikuti. Oleh karena itu, setelah 100 putaran, frekuensi angka enam dapat dihitung menggunakan rumus
=BINOM.DIST(A7,3,1/6,SALAH)*100
Rumusnya mengasumsikan bahwa di dalam sel A7 berisi jumlah angka enam yang digulirkan dalam satu putaran.
Catatan: Perhitungan diberikan dalam contoh file pada lembar Diskrit.
Sebagai perbandingan diamati(Diamati) dan frekuensi teoretis(Diharapkan) nyaman digunakan.

Jika frekuensi yang diamati menyimpang secara signifikan dari distribusi teoritis, hipotesis nol tentang distribusi variabel acak menurut hukum teoritis harus ditolak. Artinya, jika dadu lawannya asimetris, maka frekuensi yang diamati akan “berbeda secara signifikan” dari distribusi binomial.
Dalam kasus kami, pada pandangan pertama, frekuensinya cukup dekat dan tanpa perhitungan sulit untuk menarik kesimpulan yang jelas. Berlaku Tes kesesuaian Pearson X 2, sehingga bukannya pernyataan subjektif “berbeda secara substansial”, yang dapat dibuat berdasarkan perbandingan histogram, gunakan pernyataan yang benar secara matematis.
Kami menggunakan fakta itu karena hukum bilangan besar frekuensi yang diamati (Diamati) dengan meningkatnya volume sampel n cenderung ke probabilitas yang sesuai dengan hukum teoritis (dalam kasus kami, hukum binomial). Dalam kasus kami, ukuran sampel n adalah 100.
Mari kita perkenalkan tes statistik, yang dilambangkan dengan X 2:

di mana O l adalah frekuensi pengamatan kejadian dimana variabel acak telah mengambil nilai tertentu yang dapat diterima, E l adalah frekuensi teoritis yang sesuai (Diharapkan). L adalah jumlah nilai yang dapat diambil oleh variabel acak (dalam kasus kami adalah 4).
Seperti yang terlihat dari rumusnya, ini statistik adalah ukuran kedekatan frekuensi yang diamati dengan frekuensi teoritis, yaitu. ini dapat digunakan untuk memperkirakan “jarak” antara frekuensi-frekuensi ini. Jika jumlah “jarak” ini “terlalu besar”, maka frekuensinya “berbeda secara signifikan”. Jelas bahwa jika kubus kita simetris (yaitu dapat diterapkan hukum binomial), maka kemungkinan jumlah “jarak” akan menjadi “terlalu besar” akan kecil. Untuk menghitung probabilitas ini kita perlu mengetahui distribusinya statistik X 2 ( statistik X 2 dihitung berdasarkan random sampel, oleh karena itu, ini adalah variabel acak dan, oleh karena itu, memiliki variabelnya sendiri distribusi probabilitas).
Dari analog multidimensi Teorema integral Moivre-Laplace diketahui bahwa untuk n->∞ variabel acak kita X 2 asimtotik dengan L - 1 derajat kebebasan.
Jadi jika dihitung nilainya statistik X 2 (jumlah “jarak” antar frekuensi) akan lebih besar dari nilai batas tertentu, maka kita mempunyai alasan untuk menolak hipotesis nol. Sama seperti memeriksa hipotesis parametrik, nilai batas diatur melalui tingkat signifikansi. Jika probabilitas bahwa statistik X 2 akan mengambil nilai kurang dari atau sama dengan nilai yang dihitung ( P-arti), akan lebih sedikit tingkat signifikansi, Itu hipotesis nol dapat ditolak.
Dalam kasus kami, nilai statistiknya adalah 22.757. Peluang statistik X2 mengambil nilai lebih besar atau sama dengan 22,757 sangat kecil (0,000045) dan dapat dihitung dengan menggunakan rumus
=CHI2.DIST.PH(22.757,4-1) atau
=CHI2.TEST(Diamati; Diharapkan)
Catatan: Fungsi CHI2.TEST() dirancang khusus untuk menguji hubungan antara dua variabel kategori (lihat).
Probabilitas 0,000045 jauh lebih kecil dari biasanya tingkat signifikansi 0,05. Jadi, pemain punya banyak alasan untuk mencurigai lawannya tidak jujur ( hipotesis nol kejujurannya ditolak).

Saat menggunakan kriteria X 2 perlu untuk memastikan bahwa volumenya sampel n cukup besar, jika tidak, perkiraan distribusi tidak akan valid statistik X 2. Biasanya diyakini bahwa untuk ini frekuensi yang diamati (Observed) cukup lebih besar dari 5. Jika hal ini tidak terjadi, maka frekuensi-frekuensi kecil digabungkan menjadi satu atau ditambahkan ke frekuensi lain, dan nilai gabungan tersebut diberi total probabilitas dan, karenanya, jumlah derajat kebebasan berkurang X 2 distribusi.
Untuk meningkatkan kualitas aplikasi kriteria X 2(), perlu untuk mengurangi interval partisi (menambah L dan, karenanya, menambah jumlahnya derajat kebebasan), namun hal ini dapat dicegah dengan pembatasan jumlah observasi yang disertakan dalam setiap interval (db>5).
Kasus berkelanjutan
Tes kesesuaian Pearson X 2 juga dapat diterapkan jika terjadi.
Mari kita pertimbangkan hal tertentu mencicipi, terdiri dari 200 nilai. Hipotesis nol menyatakan bahwa mencicipi terbuat dari.
Catatan: Variabel acak dalam contoh file pada lembar Berkelanjutan dihasilkan menggunakan rumus =NORM.ST.INV(RAND()). Oleh karena itu, nilai-nilai baru sampel dihasilkan setiap kali sheet dihitung ulang.
Apakah kumpulan data yang ada sudah sesuai dapat dinilai secara visual.

Seperti dapat dilihat dari diagram, nilai sampel cukup sesuai dengan garis lurus. Namun, seperti untuk pengujian hipotesis berlaku Tes kesesuaian Pearson X 2.
Untuk melakukan ini, kita membagi rentang perubahan variabel acak menjadi interval dengan langkah 0,5. Mari kita hitung frekuensi observasi dan frekuensi teoritis. Kami menghitung frekuensi yang diamati menggunakan fungsi FREQUENCY(), dan frekuensi teoritis menggunakan fungsi NORM.ST.DIST().
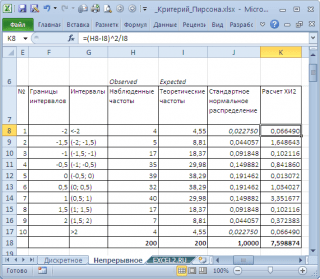
Catatan: Sama seperti untuk kasus diskrit, hal ini perlu untuk dipastikan mencicipi cukup besar, dan intervalnya mencakup >5 nilai.
Mari kita hitung statistik X2 dan bandingkan dengan nilai kritis tertentu tingkat signifikansi(0,05). Karena kita membagi rentang perubahan suatu variabel acak menjadi 10 interval, maka banyaknya derajat kebebasannya adalah 9. Nilai kritisnya dapat dihitung dengan menggunakan rumus
=CHI2.OBR.PH(0,05;9) atau
=CHI2.OBR(1-0,05;9)
Diagram di atas menunjukkan bahwa nilai statistiknya adalah 8,19, yang jauh lebih tinggi nilai kritis – hipotesis nol tidak ditolak.
Di bawah ini tempatnya mencicipi mengambil signifikansi yang tidak terduga dan didasarkan pada kriteria Persetujuan Pearson X 2 hipotesis nol ditolak (meskipun nilai acak dihasilkan menggunakan rumus =NORM.ST.INV(RAND()), menyediakan mencicipi dari distribusi normal standar).

Hipotesis nol ditolak, meskipun secara visual letak datanya cukup dekat dengan garis lurus.
Mari kita ambil juga sebagai contoh mencicipi dari kamu(-3;3). Dalam hal ini, bahkan dari grafik terlihat jelas bahwa hipotesis nol harus ditolak.

Kriteria Persetujuan Pearson X 2 juga menegaskan hal itu hipotesis nol harus ditolak.







