Проведение любого статистического анализа немыслимо без расчетов. В это статье рассмотрим, как рассчитать дисперсию, среднеквадратичное отклонение, коэффиент вариации и другие статистические показатели в Excel.
Максимальное и минимальное значение
Среднее линейное отклонение
Среднее линейное отклонение представляет собой среднее из абсолютных (по модулю) отклонений от в анализируемой совокупности данных. Математическая формула имеет вид:
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n
В Эксель эта функция называется СРОТКЛ .

После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК».
Дисперсия
{module 111}
Возможно, не все знают, что такое , поэтому поясню, — это мера, характеризующая разброс данных вокруг математического ожидания. Однако в распоряжении обычно есть только выборка, поэтому используют следующую формулу дисперсии:
![]()
s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅ – среднее арифметическое по выборке,
n – количество значений в анализируемой совокупности данных.
Соответствующая функция Excel — ДИСП.Г . При анализе относительно небольших выборок (примерно до 30-ти наблюдений) следует использовать , которая рассчитывается по следующей формуле.
![]()
Отличие, как видно, только в знаменателе. В Excel для расчета выборочной несмещенной дисперсии есть функция ДИСП.В .

Выбираем нужный вариант (генеральную или выборочную), указываем диапазон, жмем кнопку «ОК». Полученное значение может оказаться очень большим из-за предварительного возведения отклонений в квадрат. Дисперсия в статистике очень важный показатель, но ее обычно используют не в чистом виде, а для дальнейших расчетов.
Среднеквадратичное отклонение
Среднеквадратичное отклонение (СКО) – это корень из дисперсии. Этот показатель также называют стандартным отклонением и рассчитывают по формуле:
по генеральной совокупности

по выборке

Можно просто извлечь корень из дисперсии, но в Excel для среднеквадратичного отклонения есть готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).

Стандартное и среднеквадратичное отклонение, повторюсь, — синонимы.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднеквадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности. Для получения относительной меры разброса данных используют коэффициент вариации , который рассчитывается путем деления среднеквадратичного отклонения на среднее арифметическое . Формула коэффициента вариации проста:
Для расчета коэффициента вариации в Excel нет готовой функции, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
СТАНДОТКЛОН.Г()/СРЗНАЧ()
В скобках указывается диапазон данных. При необходимости используют среднее квадратичное отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на вкладке «Главная»:

Изменить формат также можно, выбрав из контекстного меню после выделения нужной ячейки и нажатия правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня — коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
В целом, с помощью Excel многие статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска во вставке функций. Ну, и Гугл в помощь.
По данным выборочного обследования произведена группировка вкладчиков по размеру вклада в Сбербанке города:
Определите:
1) размах вариации;
2) средний размер вклада;
3) среднее линейное отклонение;
4) дисперсию;
5) среднее квадратическое отклонение;
6) коэффициент вариации вкладов.
Решение:
Данный ряд распределения содержит открытые интервалы. В таких рядах условно принимается величина интервала первой группы равна величине интервала последующей, а величина интервала последней группы равна величине интервала предыдущей.
Величина интервала второй группы равна 200, следовательно, и величина первой группы также равна 200. Величина интервала предпоследней группы равна 200, значит и последний интервал будет иметь величину, равную 200.
1) Определим размах вариации как разность между наибольшим и наименьшим значением признака:
Размах вариации размера вклада равен 1000 рублей.
2) Средний размер вклада определим по формуле средней арифметической взвешенной.
Предварительно определим дискретную величину признака в каждом интервале. Для этого по формуле средней арифметической простой найдём середины интервалов.
Среднее значение первого интервала будет равно:

второго - 500 и т. д.
Занесём результаты вычислений в таблицу:
| Размер вклада, руб. | Число вкладчиков, f | Середина интервала, х | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Итого | 400 | - | 312000 |
Средний размер вклада в Сбербанке города будет равен 780 рублей:
3) Среднее линейное отклонение есть средняя арифметическая из абсолютных отклонений отдельных значений признака от общей средней:

Порядок расчёта среднего линейонго отклонения в интервальном ряду распределения следующий:
1. Вычисляется средняя арифметическая взвешенная, как показано в п. 2).
2. Определяются абсолютные отклонения вариант от средней:
3. Полученные отклонения умножаются на частоты:
4. Находится сумма взвешенных отклонений без учёта знака:
5. Сумма взвешенных отклонений делится на сумму частот:
Удобно пользоваться таблицей расчётных данных:
| Размер вклада, руб. | Число вкладчиков, f | Середина интервала, х | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Итого | 400 | - | - | - | 81280 |

Среднее линейное отклонение размера вклада клиентов Сбербанка составляет 203,2 рубля.
4) Дисперсия - это средняя арифметическая квадратов отклонений каждого значения признака от средней арифметической.
Расчёт дисперсии в интервальных рядах распределения производится по формуле:

Порядок расчёта дисперсии в этом случае следующий:
1. Определяют среднюю арифметическую взвешенную, как показано в п. 2).
2. Находят отклонения вариант от средней:
3. Возводят в квадрат отклонения каждой варианты от средней:
4. Умножают квадраты отклонений на веса (частоты):
![]()
5. Суммируют полученные произведения:
![]()
6. Полученная сумма делится на сумму весов (частот):

Расчёты оформим в таблицу:
| Размер вклада, руб. | Число вкладчиков, f | Середина интервала, х | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Итого | 400 | - | - | - | 23040000 |
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
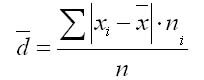
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Среднеквадрати́ческое отклоне́ние (синонимы: среднее квадрати́ческое отклоне́ние , среднеквадрати́чное отклоне́ние , квадрати́чное отклоне́ние ; близкие термины: станда́ртное отклоне́ние , станда́ртный разбро́с ) - в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания . При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок.
Энциклопедичный YouTube
-
1 / 5
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического , при построении доверительных интервалов , при статистической проверке гипотез , при измерении линейной взаимосвязи между случайными величинами. Определяется как квадратный корень из дисперсии случайной величины .
Среднеквадратическое отклонение:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; {\displaystyle s={\sqrt {{\frac {n}{n-1}}\sigma ^{2}}}={\sqrt {{\frac {1}{n-1}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}};}- Примечание: Очень часто встречаются разночтения в названиях СКО (Среднеквадратического отклонения) и СТО (Стандартного отклонения) с их формулами. Например, в модуле numPy языка программирования Python функция std() описывается как "standart deviation", в то время как формула отражает СКО (деление на корень из выборки). В Excel же функция СТАНДОТКЛОН() другая (деление на корень из n-1).
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии) s {\displaystyle s} :
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . {\displaystyle \sigma ={\sqrt {{\frac {1}{n}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}}.}где σ 2 {\displaystyle \sigma ^{2}} - дисперсия ; x i {\displaystyle x_{i}} - i -й элемент выборки; n {\displaystyle n} - объём выборки; - среднее арифметическое выборки:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . {\displaystyle {\bar {x}}={\frac {1}{n}}\sum _{i=1}^{n}x_{i}={\frac {1}{n}}(x_{1}+\ldots +x_{n}).}Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
В соответствии с ГОСТ Р 8.736-2011 среднеквадратическое отклонение считается по второй формуле данного раздела. Пожалуйста, сверьте результаты.
Правило трёх сигм
Правило трёх сигм ( 3 σ {\displaystyle 3\sigma } ) - практически все значения нормально распределённой случайной величины лежат в интервале (x ¯ − 3 σ ; x ¯ + 3 σ) {\displaystyle \left({\bar {x}}-3\sigma ;{\bar {x}}+3\sigma \right)} . Более строго - приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале (при условии, что величина x ¯ {\displaystyle {\bar {x}}} истинная, а не полученная в результате обработки выборки).
Если же истинная величина x ¯ {\displaystyle {\bar {x}}} неизвестна, то следует пользоваться не σ {\displaystyle \sigma } , а s . Таким образом, правило трёх сигм преобразуется в правило трёх s .
Интерпретация величины среднеквадратического отклонения
Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить. отождествляется с риском портфеля.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой на равнине. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
При статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
Среднеквадратическое отклонение:
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины Пол, стены вокруг нас и потолок,x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
где - дисперсия ; - Пол, стены вокруг нас и потолок,i -й элемент выборки; - объём выборки; - среднее арифметическое выборки:
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
Правило трёх сигм
Правило трёх сигм () - практически все значения нормально распределённой случайной величины лежат в интервале . Более строго - не менее чем с 99,7 % достоверностью значение нормально распределенной случайной величины лежит в указанном интервале (при условии, что величина истинная, а не полученная в результате обработки выборки).
Если же истинная величина неизвестна, то следует пользоваться не , а Пол, стены вокруг нас и потолок,s . Таким образом, правило трёх сигм преобразуется в правило трёх Пол, стены вокруг нас и потолок,s .
Интерпретация величины среднеквадратического отклонения
Большое значение среднеквадратического отклонения показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределенности. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Практическое применение
На практике среднеквадратическое отклонение позволяет определить, насколько значения в множестве могут отличаться от среднего значения.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Технический анализ
См. также
Литература
Эта статья предлагается к удалению. Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/17 декабря 2012.
Пока процесс обсуждения не завершён, статью можно попытаться улучшить, однако следует воздерживаться от переименований или удаления содержания, подробнее см. руководство к дальнейшему действию.
Не снимайте пометку о выставлении на удаление до окончания обсуждения. Администраторам: ссылки сюда, история (последнее изменение), журналы , удалить .* Боровиков, В. STATISTICA. Искусство анализа данных на компьютере: Для профессионалов / В. Боровиков. - СПб. : Питер, 2003. - 688 с. - ISBN 5-272-00078-1 .
Статистические показатели Описательная
статистикаНепрерывные
данныеКоэффициент сдвига Среднее (Арифметическое , Геометрическое , Гармоническое) · Медиана · Мода · Размах Вариация Ранг · Среднеквадратическое отклонение · Коэффициент вариации · Квантиль (Дециль, Процентиль/Перцентиль/Центиль) Моменты Математическое ожидание · Дисперсия · Асимметрия · Эксцесс Дискретные
данныеЧастота · Таблица контингентности Статистический
вывод и
проверка
гипотезСтатистический
выводДоверительный интервал (Частотная вероятность) · Достоверный интервал (Байесовский вывод) · Статистическая значимость · Мета-анализ Планирование
экспериментаГенеральная совокупность · Планирование выборки · Районированная выборка · Репликация · Группировка · Чувствительность и специфичность Объём выборки Статистическая мощность · Мера эффекта · Стандартная ошибка Общая оценка Байесовская оценка решения ·







