આ નોંધમાં, χ 2 વિતરણનો ઉપયોગ નિશ્ચિત સંભાવના વિતરણ સાથે ડેટા સેટની સુસંગતતા ચકાસવા માટે થાય છે. કરાર માપદંડ ઘણીવાર ઓતમે ચોક્કસ કેટેગરીના છો તેની સરખામણી એ ફ્રીક્વન્સીઝ સાથે કરવામાં આવે છે જે સૈદ્ધાંતિક રીતે અપેક્ષિત છે જો ડેટા ખરેખર ઉલ્લેખિત વિતરણ ધરાવે છે.
χ 2 ગુડનેસ-ઓફ-ફિટ માપદંડનો ઉપયોગ કરીને પરીક્ષણ ઘણા તબક્કામાં કરવામાં આવે છે. પ્રથમ, ચોક્કસ સંભાવના વિતરણ નક્કી કરવામાં આવે છે અને મૂળ ડેટા સાથે તેની સરખામણી કરવામાં આવે છે. બીજું, એક પૂર્વધારણા પસંદ કરેલ સંભાવના વિતરણના પરિમાણો વિશે આગળ મૂકવામાં આવે છે (ઉદાહરણ તરીકે, તેની ગાણિતિક અપેક્ષા) અથવા તેમનું મૂલ્યાંકન હાથ ધરવામાં આવે છે. ત્રીજું, સૈદ્ધાંતિક વિતરણના આધારે, દરેક શ્રેણીને અનુરૂપ સૈદ્ધાંતિક સંભાવના નક્કી કરવામાં આવે છે. છેલ્લે, χ2 પરીક્ષણ આંકડાનો ઉપયોગ ડેટા અને વિતરણની સુસંગતતા ચકાસવા માટે થાય છે:
જ્યાં f0- અવલોકન કરેલ આવર્તન, f e- સૈદ્ધાંતિક અથવા અપેક્ષિત આવર્તન, k- મર્જ કર્યા પછી બાકી રહેલી શ્રેણીઓની સંખ્યા, આર- અંદાજિત પરિમાણોની સંખ્યા.
નોંધ ડાઉનલોડ કરો અથવા ફોર્મેટ કરો, ઉદાહરણો ફોર્મેટમાં
પોઈસન વિતરણ માટે χ2 ગુડનેસ-ઓફ-ફીટ ટેસ્ટનો ઉપયોગ કરવો

Excel માં આ સૂત્રનો ઉપયોગ કરીને ગણતરી કરવા માટે, =SUMPRODUCT() ફંક્શન (ફિગ. 1) નો ઉપયોગ કરવો અનુકૂળ છે.
પરિમાણનો અંદાજ કાઢવો λ તમે અંદાજનો ઉપયોગ કરી શકો છો . સૈદ્ધાંતિક આવર્તન એક્સસફળતાઓ (X = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 અને વધુ) પરિમાણને અનુરૂપ λ = 2.9 ફંક્શન =POISSON.DIST(X;;FALSE) નો ઉપયોગ કરીને નક્કી કરી શકાય છે. નમૂનાના કદ દ્વારા પોઈસન સંભાવનાનો ગુણાકાર n, અમને સૈદ્ધાંતિક આવર્તન મળે છે f e(ફિગ. 2).

ચોખા. 2. પ્રતિ મિનિટ વાસ્તવિક અને સૈદ્ધાંતિક આગમન દર
ફિગમાંથી નીચે મુજબ. 2, નવ કે તેથી વધુ આગમનની સૈદ્ધાંતિક આવર્તન 1.0 થી વધુ નથી. દરેક કેટેગરીમાં 1.0 અથવા તેથી વધુની આવર્તન છે તેની ખાતરી કરવા માટે, "9 અથવા તેથી વધુ" કેટેગરી "8" કેટેગરી સાથે જોડવી જોઈએ. એટલે કે, નવ શ્રેણીઓ રહે છે (0, 1, 2, 3, 4, 5, 6, 7, 8 અને વધુ). પોઈસન વિતરણની ગાણિતિક અપેક્ષા નમૂનાના ડેટાના આધારે નક્કી કરવામાં આવતી હોવાથી, સ્વતંત્રતાની ડિગ્રીની સંખ્યા k – p – 1 = 9 – 1 – 1 = 7 જેટલી છે. 0.05 ના મહત્વના સ્તરનો ઉપયોગ કરીને, આપણે શોધીએ છીએ χ 2 આંકડાઓનું નિર્ણાયક મૂલ્ય, જે સૂત્ર =CHI2.OBR(1-0.05;7) = 14.067 અનુસાર સ્વતંત્રતાના 7 ડિગ્રી ધરાવે છે. નિર્ણય નિયમ નીચે પ્રમાણે ઘડવામાં આવે છે: પૂર્વધારણા એચ 0નકારવામાં આવે છે જો χ 2 > 14.067, અન્યથા પૂર્વધારણા એચ 0વિચલિત થતું નથી.
χ 2 ની ગણતરી કરવા માટે આપણે સૂત્ર (1) (ફિગ. 3) નો ઉપયોગ કરીએ છીએ.

ચોખા. 3. પોઈસન વિતરણ માટે χ 2 -ગુડનેસ-ઓફ-ફિટ માપદંડની ગણતરી
χ 2 = 2.277 થી< 14,067, следует, что гипотезу એચ 0નકારી શકાય નહીં. બીજા શબ્દોમાં કહીએ તો, અમારી પાસે એવું કહેવાનું કોઈ કારણ નથી કે બેંકમાં ગ્રાહકોનું આગમન પોઈસન વિતરણનું પાલન કરતું નથી.
સામાન્ય વિતરણ માટે χ 2 -ગુડનેસ-ઓફ-ફીટ ટેસ્ટની અરજી
અગાઉની નોંધોમાં, જ્યારે સંખ્યાત્મક ચલો વિશે પૂર્વધારણાઓનું પરીક્ષણ કરવામાં આવ્યું હતું, ત્યારે અમે ધાર્યું હતું કે અભ્યાસ હેઠળની વસ્તી સામાન્ય રીતે વિતરિત કરવામાં આવી હતી. આ ધારણાને ચકાસવા માટે, તમે ગ્રાફિકલ ટૂલ્સનો ઉપયોગ કરી શકો છો, ઉદાહરણ તરીકે, બોક્સ પ્લોટ અથવા સામાન્ય વિતરણ ગ્રાફ (વધુ વિગતો માટે, જુઓ). મોટા નમૂનાના કદ માટે, સામાન્ય વિતરણ માટે χ 2 ગુડનેસ-ઓફ-ફીટ ટેસ્ટનો ઉપયોગ આ ધારણાઓને ચકાસવા માટે કરી શકાય છે.
ચાલો, ઉદાહરણ તરીકે, 158 રોકાણ ભંડોળના 5-વર્ષના વળતર પરના ડેટાને ધ્યાનમાં લઈએ (ફિગ. 4). ધારો કે તમે માનવા માંગો છો કે ડેટા સામાન્ય રીતે વિતરિત થાય છે કે કેમ. નલ અને વૈકલ્પિક પૂર્વધારણાઓ નીચે પ્રમાણે ઘડવામાં આવી છે: એચ 0: 5-વર્ષની ઉપજ સામાન્ય વિતરણને અનુસરે છે, એચ 1: 5-વર્ષની ઉપજ સામાન્ય વિતરણને અનુસરતી નથી. સામાન્ય વિતરણમાં બે પરિમાણો છે - ગાણિતિક અપેક્ષા μ અને પ્રમાણભૂત વિચલન σ, જે નમૂનાના ડેટાના આધારે અંદાજિત કરી શકાય છે. આ કિસ્સામાં = 10.149 અને એસ = 4,773.

ચોખા. 4. 158 ફંડના પાંચ વર્ષના સરેરાશ વાર્ષિક વળતર પરનો ડેટા ધરાવતો ઓર્ડર કરેલ એરે
ભંડોળના વળતર પરના ડેટાને જૂથબદ્ધ કરી શકાય છે, ઉદાહરણ તરીકે, 5% (ફિગ. 5) ની પહોળાઈ સાથે વર્ગો (અંતરાલ) માં.

ચોખા. 5. 158 ફંડના પાંચ વર્ષના સરેરાશ વાર્ષિક વળતર માટે આવર્તન વિતરણ
સામાન્ય વિતરણ સતત હોવાથી, સામાન્ય વિતરણ વળાંક અને દરેક અંતરાલની સીમાઓ દ્વારા બંધાયેલા આંકડાઓનો વિસ્તાર નક્કી કરવો જરૂરી છે. વધુમાં, સામાન્ય વિતરણ સૈદ્ધાંતિક રીતે –∞ થી +∞ સુધીનું હોવાથી, વર્ગની સીમાઓની બહાર આવતા આકારોના વિસ્તારને ધ્યાનમાં લેવો જરૂરી છે. તેથી, બિંદુ -10 ની ડાબી તરફના સામાન્ય વળાંક હેઠળનો વિસ્તાર, Z મૂલ્યની ડાબી બાજુએ પ્રમાણિત સામાન્ય વળાંક હેઠળ પડેલા આકૃતિના વિસ્તાર જેટલો છે.
Z = (–10 – 10.149) / 4.773 = –4.22
Z = –4.22 મૂલ્યની ડાબી બાજુએ પ્રમાણિત સામાન્ય વળાંક હેઠળ સ્થિત આકૃતિનો વિસ્તાર સૂત્ર =NORM.DIST(-10;10.149;4.773;TRUE) દ્વારા નિર્ધારિત કરવામાં આવે છે અને તે લગભગ 0.00001 ની બરાબર છે. બિંદુઓ –10 અને –5 વચ્ચેના સામાન્ય વળાંક હેઠળ પડેલા આકૃતિના ક્ષેત્રફળની ગણતરી કરવા માટે, તમારે પહેલા બિંદુ –5 ની ડાબી બાજુએ પડેલી આકૃતિના ક્ષેત્રફળની ગણતરી કરવાની જરૂર છે: =NORM.DIST( -5,10.149,4.773,TRUE) = 0.00075 . તેથી, બિંદુઓ –10 અને –5 વચ્ચેના સામાન્ય વળાંક હેઠળ પડેલા આકૃતિનો વિસ્તાર 0.00075 – 0.00001 = 0.00074 છે. એ જ રીતે, તમે દરેક વર્ગની સીમાઓ દ્વારા મર્યાદિત આકૃતિના ક્ષેત્રફળની ગણતરી કરી શકો છો (ફિગ. 6).

ચોખા. 6. 5-વર્ષના વળતરના દરેક વર્ગ માટે વિસ્તારો અને અપેક્ષિત ફ્રીક્વન્સીઝ
તે જોઈ શકાય છે કે ચાર આત્યંતિક વર્ગો (બે લઘુત્તમ અને બે મહત્તમ) માં સૈદ્ધાંતિક આવર્તન 1 કરતા ઓછી છે, તેથી અમે વર્ગોને જોડીશું, જેમ કે આકૃતિ 7 માં બતાવ્યા પ્રમાણે.

ચોખા. 7. સામાન્ય વિતરણ માટે χ 2 ગુડનેસ-ઓફ-ફીટ ટેસ્ટના ઉપયોગ સાથે સંકળાયેલી ગણતરીઓ
અમે ફોર્મ્યુલા (1) નો ઉપયોગ કરીને ડેટા અને સામાન્ય વિતરણ વચ્ચેના કરાર માટે χ 2 પરીક્ષણનો ઉપયોગ કરીએ છીએ. અમારા ઉદાહરણમાં, મર્જ કર્યા પછી, છ વર્ગો રહે છે. સેમ્પલ ડેટા પરથી અપેક્ષિત મૂલ્ય અને પ્રમાણભૂત વિચલનનો અંદાજ હોવાથી, સ્વતંત્રતાની ડિગ્રીની સંખ્યા છે k – પી – 1 = 6 – 2 – 1 = 3. 0.05 ના મહત્વના સ્તરનો ઉપયોગ કરીને, અમે શોધીએ છીએ કે χ 2 આંકડાનું નિર્ણાયક મૂલ્ય, જેમાં ત્રણ ડિગ્રી સ્વતંત્રતા છે = CI2.OBR(1-0.05;F3) = 7.815. χ 2 ગુડનેસ-ઓફ-ફિટ માપદંડના ઉપયોગ સાથે સંકળાયેલી ગણતરીઓ ફિગમાં બતાવવામાં આવી છે. 7.
તે જોઈ શકાય છે કે χ 2 -statistic = 3.964< χ U 2 7,815, следовательно гипотезу એચ 0નકારી શકાય નહીં. બીજા શબ્દોમાં કહીએ તો, અમારી પાસે એવું માનવા માટે કોઈ કારણ નથી કે ઉચ્ચ-વૃદ્ધિવાળા રોકાણ ભંડોળનું 5-વર્ષનું વળતર સામાન્ય રીતે વિતરિત થતું નથી.
કેટલીક તાજેતરની પોસ્ટ્સે સ્પષ્ટ ડેટાનું વિશ્લેષણ કરવા માટે વિવિધ અભિગમોની શોધ કરી છે. બે અથવા વધુ સ્વતંત્ર નમૂનાઓના પૃથ્થકરણમાંથી મેળવેલ સ્પષ્ટ માહિતી વિશેની પૂર્વધારણાઓનું પરીક્ષણ કરવાની પદ્ધતિઓ વર્ણવવામાં આવી છે. ચી-સ્ક્વેર પરીક્ષણો ઉપરાંત, નોનપેરામેટ્રિક પ્રક્રિયાઓ ધ્યાનમાં લેવામાં આવે છે. વિલ્કોક્સન રેન્ક ટેસ્ટનું વર્ણન કરવામાં આવ્યું છે, જેનો ઉપયોગ એવી પરિસ્થિતિઓમાં થાય છે જ્યાં એપ્લિકેશનની શરતો પૂરી થતી નથી t-બે સ્વતંત્ર જૂથોની ગાણિતિક અપેક્ષાઓની સમાનતા વિશેની પૂર્વધારણાને ચકાસવા માટેના માપદંડ, તેમજ ક્રુસ્કલ-વોલિસ ટેસ્ટ, જે ભિન્નતાના એક-પરિબળ વિશ્લેષણનો વિકલ્પ છે (ફિગ. 8).

ચોખા. 8. સ્પષ્ટ ડેટા વિશે પૂર્વધારણાઓનું પરીક્ષણ કરવા માટેની પદ્ધતિઓનો બ્લોક ડાયાગ્રામ
લેવિન એટ અલ મેનેજર્સ માટે આંકડાશાસ્ત્ર પુસ્તકમાંથી સામગ્રીનો ઉપયોગ થાય છે – એમ.: વિલિયમ્સ, 2004. – પી. 763–769
વિતરણ. પીયર્સન વિતરણ સંભાવના ઘનતા ... વિકિપીડિયા
ચી-સ્ક્વેર વિતરણ- ચી ચોરસ વિતરણ - વિષયોની માહિતી સુરક્ષા EN ચી ચોરસ વિતરણ ... ટેકનિકલ અનુવાદકની માર્ગદર્શિકા
ચી-સ્ક્વેર વિતરણ- 0 થી મૂલ્યો સાથે સતત રેન્ડમ ચલનું સંભવિત વિતરણ, જેની ઘનતા સૂત્ર દ્વારા આપવામાં આવે છે, જ્યાં પરિમાણ =1,2,... માટે 0; - ગામા કાર્ય. ઉદાહરણો. 1) સ્વતંત્ર નોર્મલાઇઝ્ડ રેન્ડમ રેન્ડમના ચોરસનો સરવાળો... ... સમાજશાસ્ત્રીય આંકડાશાસ્ત્રનો શબ્દકોશ
ચી-સ્ક્વેર ડિસ્ટ્રિબ્યુશન (chi2)- રેન્ડમ વેરીએબલ chi2 નું વિતરણ જો 1 ના રેન્ડમ સેમ્પલ સરેરાશ સાથે સામાન્ય વિતરણમાંથી લેવામાં આવે છે, તો chi2 = (X1 u)2/q2, જ્યાં X એ નમૂનાનું મૂલ્ય છે. જો નમૂનાનું કદ છે. અવ્યવસ્થિત રીતે N સુધી વધ્યું, પછી chi2 = ……
સંભાવના ઘનતા ... વિકિપીડિયા
- (સ્નેડેકોર વિતરણ) સંભાવના ઘનતા ... વિકિપીડિયા
ફિશર વિતરણ સંભાવના ઘનતા વિતરણ કાર્ય સાથે સંખ્યાના પરિમાણો ... વિકિપીડિયા
સંભાવના સિદ્ધાંત અને ગાણિતિક આંકડાઓની મૂળભૂત વિભાવનાઓમાંની એક. આધુનિક અભિગમ સાથે, ગાણિતિક તરીકે રેન્ડમ ઘટનાના મોડેલનો અભ્યાસ કરવામાં આવી રહ્યો છે, અનુરૂપ સંભાવના જગ્યા (W, S, P) લેવામાં આવે છે, જ્યાં W એ પ્રાથમિક...નો સમૂહ છે. ગાણિતિક જ્ઞાનકોશ
ગામા વિતરણ સંભાવના ઘનતા વિતરણ કાર્ય પરિમાણો ... વિકિપીડિયા
વિતરણ એફ- રેન્ડમ ચલ F નું સૈદ્ધાંતિક સંભાવના વિતરણ. જો સામાન્ય વસ્તીમાંથી કદ N ના રેન્ડમ નમૂનાઓ સ્વતંત્ર રીતે દોરવામાં આવે, તો દરેક સ્વતંત્રતાની ડિગ્રી સાથે ચી-સ્ક્વેર વિતરણ બનાવે છે = N. આવા બેનો ગુણોત્તર... ... મનોવિજ્ઞાનનો સમજૂતીત્મક શબ્દકોશ
પુસ્તકો
- સમસ્યાઓમાં સંભાવના સિદ્ધાંત અને ગાણિતિક આંકડા: 360 થી વધુ સમસ્યાઓ અને કસરતો, બોર્ઝિખ ડી.. સૂચિત માર્ગદર્શિકામાં જટિલતાના વિવિધ સ્તરોની સમસ્યાઓ છે. જો કે, મુખ્ય ભાર મધ્યમ જટિલતાના કાર્યો પર છે. આ ઈરાદાપૂર્વક વિદ્યાર્થીઓને પ્રોત્સાહિત કરવા માટે કરવામાં આવે છે...
- સમસ્યાઓમાં સંભાવના સિદ્ધાંત અને ગાણિતિક આંકડા. 360 થી વધુ કાર્યો અને કસરતો, બોર્ઝિખ ડીએ. સૂચિત માર્ગદર્શિકામાં વિવિધ સ્તરની જટિલતાના કાર્યો છે. જો કે, મુખ્ય ભાર મધ્યમ જટિલતાના કાર્યો પર છે. આ ઈરાદાપૂર્વક વિદ્યાર્થીઓને પ્રોત્સાહિત કરવા માટે કરવામાં આવે છે...
જો χ 2 માપદંડનું પ્રાપ્ત મૂલ્ય નિર્ણાયક મૂલ્ય કરતાં વધારે હોય, તો અમે તારણ કાઢીએ છીએ કે અભ્યાસ કરેલ જોખમ પરિબળ અને મહત્વના યોગ્ય સ્તરે પરિણામ વચ્ચે આંકડાકીય સંબંધ છે.
પિયર્સન ચી-સ્ક્વેર ટેસ્ટની ગણતરીનું ઉદાહરણ
ચાલો ઉપર ચર્ચા કરેલ કોષ્ટકનો ઉપયોગ કરીને ધમનીના હાયપરટેન્શનની ઘટનાઓ પર ધૂમ્રપાન પરિબળના પ્રભાવનું આંકડાકીય મહત્વ નક્કી કરીએ:
1. દરેક કોષ માટે અપેક્ષિત મૂલ્યોની ગણતરી કરો:
2. પીયર્સન ચી-સ્ક્વેર ટેસ્ટનું મૂલ્ય શોધો:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. સ્વતંત્રતાની ડિગ્રીની સંખ્યા f = (2-1)*(2-1) = 1. કોષ્ટકનો ઉપયોગ કરીને, આપણે પીયર્સન ચી-સ્ક્વેર ટેસ્ટનું નિર્ણાયક મૂલ્ય શોધીએ છીએ, જે મહત્વના સ્તરે p=0.05 અને સ્વતંત્રતા 1 ની ડિગ્રીની સંખ્યા 3.841 છે.
4. અમે ચી-સ્ક્વેર ટેસ્ટના મેળવેલ મૂલ્યની નિર્ણાયક સાથે સરખામણી કરીએ છીએ: 4.396 > 3.841, તેથી, ધૂમ્રપાનની હાજરી પર ધમનીના હાયપરટેન્શનની ઘટનાઓની અવલંબન આંકડાકીય રીતે નોંધપાત્ર છે. આ સંબંધનું મહત્વ સ્તર p ને અનુરૂપ છે<0.05.
ઉપરાંત, પિયર્સન ચી-સ્ક્વેર ટેસ્ટની ગણતરી સૂત્રનો ઉપયોગ કરીને કરવામાં આવે છે
પરંતુ 2x2 કોષ્ટક માટે, યેટ્સ કરેક્શન માપદંડ દ્વારા વધુ સચોટ પરિણામો મેળવવામાં આવે છે.

જો  તે N(0)સ્વીકાર્યું,
તે N(0)સ્વીકાર્યું,
કિસ્સામાં ![]() સ્વીકાર્યું H(1)
સ્વીકાર્યું H(1)
જ્યારે અવલોકનોની સંખ્યા ઓછી હોય અને કોષ્ટક કોષોમાં 5 કરતા ઓછી આવર્તન હોય, ત્યારે ચી-સ્ક્વેર ટેસ્ટ લાગુ પડતો નથી અને તેનો ઉપયોગ પૂર્વધારણાઓ ચકાસવા માટે થાય છે. ફિશરની ચોક્કસ કસોટી . આ માપદંડની ગણતરી કરવાની પ્રક્રિયા તદ્દન શ્રમ-સઘન છે, અને આ કિસ્સામાં કમ્પ્યુટર આંકડાકીય વિશ્લેષણ પ્રોગ્રામ્સનો ઉપયોગ કરવો વધુ સારું છે.
આકસ્મિક કોષ્ટકનો ઉપયોગ કરીને, તમે બે ગુણાત્મક લાક્ષણિકતાઓ વચ્ચેના જોડાણના માપની ગણતરી કરી શકો છો - આ યુલ એસોસિએશન ગુણાંક છે પ્ર (સહસંબંધ ગુણાંકને અનુરૂપ)

પ્ર 0 થી 1 ની રેન્જમાં આવેલું છે. એકની નજીકનો ગુણાંક લાક્ષણિકતાઓ વચ્ચે મજબૂત જોડાણ સૂચવે છે. જો તે શૂન્યની બરાબર છે, તો ત્યાં કોઈ જોડાણ નથી .
ફી-સ્ક્વેર ગુણાંક (φ 2) એ જ રીતે વપરાય છે
બેન્ચમાર્ક કાર્ય
કોષ્ટક ખોરાક સાથે અને વગર ડ્રોસોફિલાના જૂથોમાં પરિવર્તનની આવર્તન વચ્ચેના સંબંધનું વર્ણન કરે છે
આકસ્મિક કોષ્ટક વિશ્લેષણ
આકસ્મિક કોષ્ટકનું વિશ્લેષણ કરવા માટે, એક H 0 પૂર્વધારણા આગળ મૂકવામાં આવે છે, એટલે કે, અભ્યાસના પરિણામ પર અભ્યાસ કરવામાં આવતી લાક્ષણિકતાના પ્રભાવની ગેરહાજરી આ માટે, અપેક્ષિત આવર્તનની ગણતરી કરવામાં આવે છે અને એક અપેક્ષા કોષ્ટક બનાવવામાં આવે છે.
રાહ જોવાનું ટેબલ
| જૂથો | ચિલો પાક | કુલ | ||||
| મ્યુટેશન આપ્યું | મ્યુટેશન આપ્યું નથી | |||||
| વાસ્તવિક આવર્તન | અપેક્ષિત આવર્તન | વાસ્તવિક આવર્તન | અપેક્ષિત આવર્તન | |||
| ખોરાક સાથે | ||||||
| ખોરાક આપ્યા વિના | ||||||
| કુલ | ||||||
પદ્ધતિ નંબર 1
રાહ જોવાની આવર્તન નક્કી કરો:
2756 - એક્સ ![]() ;
;
2. 3561 – 3124
જો જૂથોમાં અવલોકનોની સંખ્યા ઓછી હોય, તો X 2 નો ઉપયોગ કરતી વખતે, વાસ્તવિક અને અપેક્ષિત ફ્રીક્વન્સીઝની અલગ ડિસ્ટ્રિબ્યુશન સાથે સરખામણી કરવાના કિસ્સામાં, અચોક્કસતા ઘટાડવા માટે, યેટ્સ કરેક્શનનો ઉપયોગ કરવામાં આવે છે.
19મી સદીના અંત સુધી, સામાન્ય વિતરણને ડેટામાં વિવિધતાનો સાર્વત્રિક કાયદો માનવામાં આવતો હતો. જો કે, કે. પીયરસને નોંધ્યું હતું કે પ્રયોગમૂલક ફ્રીક્વન્સીઝ સામાન્ય વિતરણ કરતા ઘણી અલગ હોઈ શકે છે. આ કેવી રીતે સાબિત કરવું તે પ્રશ્ન ઊભો થયો. માત્ર એક ગ્રાફિકલ સરખામણી, જે વ્યક્તિલક્ષી છે, જરૂરી હતી, પણ એક કડક જથ્થાત્મક સમર્થન પણ જરૂરી હતું.
આ રીતે માપદંડની શોધ થઈ χ 2(ચી-ચોરસ), જે પ્રયોગમૂલક (નિરીક્ષણ) અને સૈદ્ધાંતિક (અપેક્ષિત) ફ્રીક્વન્સીઝ વચ્ચેના તફાવતના મહત્વની ચકાસણી કરે છે. આ 1900 માં થયું હતું, પરંતુ માપદંડ આજે પણ ઉપયોગમાં છે. તદુપરાંત, તે સમસ્યાઓની વિશાળ શ્રેણીને હલ કરવા માટે સ્વીકારવામાં આવ્યું છે. સૌ પ્રથમ, આ નજીવા ડેટાનું વિશ્લેષણ છે, એટલે કે. તે કે જે જથ્થા દ્વારા નહીં, પરંતુ અમુક શ્રેણી સાથે જોડાયેલા દ્વારા વ્યક્ત કરવામાં આવે છે. ઉદાહરણ તરીકે, કારનો વર્ગ, પ્રયોગમાં ભાગ લેનારનું લિંગ, છોડનો પ્રકાર વગેરે. આવા ડેટા પર સરવાળો અને ગુણાકાર જેવી ગાણિતિક ક્રિયાઓ ફક્ત તેમના માટે જ ગણી શકાય છે.
અમે અવલોકન કરેલ ફ્રીક્વન્સીઝ સૂચવીએ છીએ વિશે (નિરીક્ષણ), અપેક્ષિત - ઇ (અપેક્ષિત). ઉદાહરણ તરીકે, ચાલો 60 વખત ડાઇ રોલ કરવાનું પરિણામ લઈએ. જો તે સપ્રમાણ અને સમાન હોય, તો કોઈપણ બાજુ મેળવવાની સંભાવના 1/6 છે અને તેથી દરેક બાજુ મેળવવાની અપેક્ષિત સંખ્યા 10 (1/6∙60) છે. અમે કોષ્ટકમાં અવલોકન કરેલ અને અપેક્ષિત ફ્રીક્વન્સીઝ લખીએ છીએ અને હિસ્ટોગ્રામ દોરીએ છીએ.
શૂન્ય પૂર્વધારણા એ છે કે ફ્રીક્વન્સીઝ સુસંગત છે, એટલે કે, વાસ્તવિક ડેટા અપેક્ષિત ડેટા સાથે વિરોધાભાસી નથી. વૈકલ્પિક પૂર્વધારણા એ છે કે ફ્રીક્વન્સીઝમાં વિચલનો રેન્ડમ વધઘટથી આગળ વધે છે, એટલે કે, વિસંગતતાઓ આંકડાકીય રીતે નોંધપાત્ર છે. સખત નિષ્કર્ષ દોરવા માટે, અમને જરૂર છે.
- અવલોકન કરેલ અને અપેક્ષિત ફ્રીક્વન્સીઝ વચ્ચેની વિસંગતતાનું સારાંશ માપ.
- આ માપનું વિતરણ જો કોઈ ભિન્નતા નથી તેવી પૂર્વધારણા સાચી છે.
ચાલો ફ્રીક્વન્સી વચ્ચેના અંતરથી શરૂઆત કરીએ. જો તમે માત્ર તફાવત લો ઓ - ઇ, તો પછી આવા માપ ડેટાના સ્કેલ (ફ્રીક્વન્સીઝ) પર આધારિત રહેશે. ઉદાહરણ તરીકે, 20 - 5 = 15 અને 1020 - 1005 = 15. બંને કિસ્સાઓમાં, તફાવત 15 છે. પરંતુ પ્રથમ કિસ્સામાં, અપેક્ષિત ફ્રીક્વન્સીઝ અવલોકન કરતા 3 ગણી ઓછી છે, અને બીજા કિસ્સામાં - માત્ર 1.5 %. અમને સંબંધિત માપની જરૂર છે જે સ્કેલ પર આધારિત નથી.
ચાલો નીચેના તથ્યો પર ધ્યાન આપીએ. સામાન્ય રીતે, ગ્રેડેશનની સંખ્યા કે જેમાં ફ્રીક્વન્સીઝ માપવામાં આવે છે તે ઘણી મોટી હોઈ શકે છે, તેથી એક અવલોકન એક કે બીજી કેટેગરીમાં આવે તેવી સંભાવના ઘણી ઓછી છે. જો એમ હોય, તો આવા રેન્ડમ ચલનું વિતરણ દુર્લભ ઘટનાઓના કાયદાનું પાલન કરશે, જેને પોઈસનનો કાયદો. પોઈસનના કાયદામાં, જેમ કે જાણીતું છે, ગાણિતિક અપેક્ષા અને તફાવતનું મૂલ્ય એકરૂપ થાય છે (પેરામીટર λ ). આનો અર્થ એ છે કે નામાંકિત ચલની અમુક શ્રેણી માટે અપેક્ષિત આવર્તન ઇ iએક સાથે હશે અને તેનું વિખેરવું. વધુમાં, પોઈસનનો નિયમ મોટી સંખ્યામાં અવલોકનો સાથે સામાન્ય છે. આ બે હકીકતોને જોડીને, અમે મેળવીએ છીએ કે જો અવલોકન કરેલ અને અપેક્ષિત ફ્રીક્વન્સીઝ વચ્ચેના કરાર વિશેની પૂર્વધારણા સાચી હોય, તો, મોટી સંખ્યામાં અવલોકનો સાથે, અભિવ્યક્તિ
હશે.
તે યાદ રાખવું અગત્યનું છે કે સામાન્યતા ફક્ત પૂરતી ઊંચી ફ્રીક્વન્સીઝ પર જ દેખાશે. આંકડાઓમાં, તે સામાન્ય રીતે સ્વીકારવામાં આવે છે કે અવલોકનોની કુલ સંખ્યા (આવર્તનનો સરવાળો) ઓછામાં ઓછો 50 હોવો જોઈએ અને દરેક ગ્રેડેશનમાં અપેક્ષિત આવર્તન ઓછામાં ઓછી 5 હોવી જોઈએ. માત્ર આ કિસ્સામાં, ઉપર દર્શાવેલ મૂલ્ય પ્રમાણભૂત સામાન્ય હશે. વિતરણ ચાલો માની લઈએ કે આ શરત પૂરી થઈ છે.
પ્રમાણભૂત સામાન્ય વિતરણમાં લગભગ તમામ મૂલ્યો ±3 (ત્રણ-સિગ્મા નિયમ) ની અંદર હોય છે. આમ, અમે એક ગ્રેડેશન માટે ફ્રીક્વન્સીઝમાં સંબંધિત તફાવત મેળવ્યો. અમને સામાન્યીકરણ કરી શકાય તેવા માપની જરૂર છે. તમે ફક્ત તમામ વિચલનો ઉમેરી શકતા નથી - અમને 0 મળે છે (શા માટે અનુમાન કરો). પિયરસને આ વિચલનોના વર્ગો ઉમેરવાનું સૂચન કર્યું.
![]()
આ નિશાની છે માપદંડ χ 2પીયર્સન. જો ફ્રીક્વન્સી ખરેખર અપેક્ષિત લોકોને અનુરૂપ હોય, તો માપદંડનું મૂલ્ય પ્રમાણમાં નાનું હશે (કારણ કે મોટાભાગના વિચલનો શૂન્યની આસપાસ છે). પરંતુ જો માપદંડ મોટો હોય, તો આ ફ્રીક્વન્સીઝ વચ્ચે નોંધપાત્ર તફાવત સૂચવે છે.
માપદંડ "મોટો" બની જાય છે જ્યારે આવા અથવા તેનાથી વધુ મૂલ્યની ઘટના અસંભવિત બને છે. અને આવી સંભાવનાની ગણતરી કરવા માટે, જ્યારે આવર્તન કરારની પૂર્વધારણા સાચી હોય ત્યારે પ્રયોગ ઘણી વખત પુનરાવર્તિત થાય ત્યારે માપદંડનું વિતરણ જાણવું જરૂરી છે.
જોવામાં સરળ છે તેમ, ચી-સ્ક્વેર મૂલ્ય પણ શરતોની સંખ્યા પર આધારિત છે. જેટલું વધારે છે, માપદંડનું મૂલ્ય જેટલું વધારે હોવું જોઈએ, કારણ કે દરેક શબ્દ કુલમાં ફાળો આપશે. તેથી, દરેક જથ્થા માટે સ્વતંત્રશરતો, તેનું પોતાનું વિતરણ હશે. તે તારણ આપે છે કે χ 2વિતરણનો આખો પરિવાર છે.
અને અહીં આપણે એક નાજુક ક્ષણ પર આવીએ છીએ. સંખ્યા શું છે સ્વતંત્રશરતો? એવું લાગે છે કે કોઈપણ શબ્દ (એટલે કે વિચલન) સ્વતંત્ર છે. કે. પીયર્સન પણ આવું વિચારતા હતા, પરંતુ તે ખોટા નીકળ્યા. વાસ્તવમાં, સ્વતંત્ર પદોની સંખ્યા નામાંકિત ચલના ગ્રેડેશનની સંખ્યા કરતાં એક ઓછી હશે. n. શા માટે? કારણ કે જો આપણી પાસે એવો નમૂનો હોય કે જેના માટે ફ્રીક્વન્સીના સરવાળાની પહેલેથી જ ગણતરી કરવામાં આવી હોય, તો ફ્રીક્વન્સીમાંથી એક હંમેશા કુલ સંખ્યા અને અન્ય તમામના સરવાળા વચ્ચેના તફાવત તરીકે નક્કી કરી શકાય છે. આથી ભિન્નતા થોડી ઓછી હશે. રોનાલ્ડ ફિશરે પીયર્સન દ્વારા તેનો માપદંડ વિકસાવ્યાના 20 વર્ષ પછી આ હકીકતની નોંધ લીધી. ટેબલો પણ ફરીથી કરવા પડ્યા.
આ પ્રસંગે ફિશરે આંકડાશાસ્ત્રમાં એક નવો ખ્યાલ રજૂ કર્યો - સ્વતંત્રતાની ડિગ્રી(સ્વતંત્રતાની ડિગ્રી), જે સરવાળામાં સ્વતંત્ર પદોની સંખ્યા દર્શાવે છે. સ્વતંત્રતાની ડિગ્રીની વિભાવનામાં ગાણિતિક સમજૂતી હોય છે અને તે સામાન્ય (વિદ્યાર્થી, ફિશર-સ્નેડેકોર અને ચી-સ્ક્વેર પોતે) સાથે સંકળાયેલા વિતરણમાં જ દેખાય છે.
સ્વતંત્રતાની ડિગ્રીના અર્થને વધુ સારી રીતે સમજવા માટે, ચાલો આપણે ભૌતિક એનાલોગ તરફ વળીએ. ચાલો અવકાશમાં મુક્તપણે ફરતા બિંદુની કલ્પના કરીએ. તેની પાસે સ્વતંત્રતાની 3 ડિગ્રી છે, કારણ કે ત્રિ-પરિમાણીય અવકાશમાં કોઈપણ દિશામાં આગળ વધી શકે છે. જો કોઈ બિંદુ કોઈપણ સપાટી સાથે આગળ વધે છે, તો તે પહેલાથી જ બે ડિગ્રી સ્વતંત્રતા ધરાવે છે (આગળ અને પાછળ, ડાબે અને જમણે), જો કે તે ત્રિ-પરિમાણીય અવકાશમાં ચાલુ રહે છે. ઝરણાની સાથે ફરતું બિંદુ ફરીથી ત્રિ-પરિમાણીય અવકાશમાં છે, પરંતુ તેમાં માત્ર એક ડિગ્રી સ્વતંત્રતા છે, કારણ કે આગળ કે પાછળ જઈ શકે છે. જેમ તમે જોઈ શકો છો, ઑબ્જેક્ટ જ્યાં સ્થિત છે તે જગ્યા હંમેશા ચળવળની વાસ્તવિક સ્વતંત્રતાને અનુરૂપ નથી.
લગભગ એ જ રીતે, આંકડાકીય માપદંડનું વિતરણ તેની ગણતરી કરવા માટે જરૂરી શરતો કરતાં ઘટકોની નાની સંખ્યા પર આધારિત હોઈ શકે છે. સામાન્ય રીતે, સ્વતંત્રતાની ડિગ્રીની સંખ્યા વર્તમાન અવલંબનની સંખ્યા દ્વારા અવલોકનોની સંખ્યા કરતા ઓછી છે. આ શુદ્ધ ગણિત છે, કોઈ જાદુ નથી.
તેથી વિતરણ χ 2વિતરણનું કુટુંબ છે, જેમાંથી દરેક સ્વતંત્રતા પરિમાણની ડિગ્રી પર આધારિત છે. અને ચી-સ્ક્વેર ટેસ્ટની ઔપચારિક વ્યાખ્યા નીચે મુજબ છે. વિતરણ χ 2(ચી-ચોરસ) s kસ્વતંત્રતાની ડિગ્રી એ ચોરસના સરવાળાનું વિતરણ છે kસ્વતંત્ર પ્રમાણભૂત સામાન્ય રેન્ડમ ચલો.
આગળ, આપણે સૂત્ર પર જ આગળ વધી શકીએ કે જેના દ્વારા ચી-સ્ક્વેર ડિસ્ટ્રિબ્યુશન ફંક્શનની ગણતરી કરવામાં આવે છે, પરંતુ, સદનસીબે, આપણા માટે દરેક વસ્તુની લાંબા સમયથી ગણતરી કરવામાં આવી છે. રસની સંભાવના મેળવવા માટે, તમે અનુરૂપ આંકડાકીય કોષ્ટકનો ઉપયોગ કરી શકો છો અથવા વિશિષ્ટ સૉફ્ટવેરમાં તૈયાર ફંક્શનનો ઉપયોગ કરી શકો છો, જે એક્સેલમાં પણ ઉપલબ્ધ છે.
સ્વતંત્રતાની ડિગ્રીની સંખ્યાના આધારે ચી-સ્ક્વેર વિતરણનો આકાર કેવી રીતે બદલાય છે તે જોવું રસપ્રદ છે.

સ્વતંત્રતાની વધતી જતી ડિગ્રી સાથે, ચી-સ્ક્વેર વિતરણ સામાન્ય થવાનું વલણ ધરાવે છે. આ કેન્દ્રીય મર્યાદા પ્રમેયની ક્રિયા દ્વારા સમજાવવામાં આવ્યું છે, જે મુજબ મોટી સંખ્યામાં સ્વતંત્ર રેન્ડમ ચલોનો સરવાળો સામાન્ય વિતરણ ધરાવે છે. તે ચોરસ વિશે કશું કહેતું નથી)).
ચિ-સ્ક્વેર ટેસ્ટનો ઉપયોગ કરીને પૂર્વધારણા પરીક્ષણ
હવે આપણે chi-square પદ્ધતિનો ઉપયોગ કરીને પૂર્વધારણાઓનું પરીક્ષણ કરવા આવીએ છીએ. સામાન્ય રીતે, ટેકનોલોજી રહે છે. શૂન્ય પૂર્વધારણા એ છે કે અવલોકન કરાયેલ ફ્રીક્વન્સીઝ અપેક્ષિત રાશિઓને અનુરૂપ છે (એટલે કે તેમની વચ્ચે કોઈ તફાવત નથી કારણ કે તે સમાન વસ્તીમાંથી લેવામાં આવ્યા છે). જો આવું છે, તો સ્કેટર રેન્ડમ વધઘટની મર્યાદામાં પ્રમાણમાં નાનું હશે. ચી-સ્ક્વેર ટેસ્ટનો ઉપયોગ કરીને વિક્ષેપનું માપ નક્કી કરવામાં આવે છે. આગળ, ક્યાં તો માપદંડની તુલના નિર્ણાયક મૂલ્ય (અનુરૂપ મહત્વના સ્તર અને સ્વતંત્રતાની ડિગ્રી માટે) સાથે કરવામાં આવે છે, અથવા, વધુ સાચું શું છે, અવલોકન કરેલ પી-સ્તરની ગણતરી કરવામાં આવે છે, એટલે કે. જો નલ પૂર્વધારણા સાચી હોય તો સમાન અથવા તેનાથી વધુ માપદંડ મૂલ્ય મેળવવાની સંભાવના.

કારણ કે અમે ફ્રીક્વન્સીઝના કરારમાં રસ ધરાવીએ છીએ, પછી જ્યારે માપદંડ નિર્ણાયક સ્તર કરતા વધારે હોય ત્યારે પૂર્વધારણાને નકારી કાઢવામાં આવશે. તે. માપદંડ એકતરફી છે. જો કે, કેટલીકવાર (ક્યારેક) ડાબા હાથની પૂર્વધારણાનું પરીક્ષણ કરવું જરૂરી છે. ઉદાહરણ તરીકે, જ્યારે પ્રયોગમૂલક ડેટા સૈદ્ધાંતિક ડેટા સાથે ખૂબ સમાન હોય છે. પછી માપદંડ અસંભવિત પ્રદેશમાં આવી શકે છે, પરંતુ ડાબી બાજુએ. હકીકત એ છે કે કુદરતી પરિસ્થિતિઓમાં, તે ફ્રીક્વન્સીઝ મેળવવાની શક્યતા નથી કે જે વ્યવહારિક રીતે સૈદ્ધાંતિક રાશિઓ સાથે સુસંગત હોય. હંમેશા કેટલીક રેન્ડમનેસ હોય છે જે ભૂલ આપે છે. પરંતુ જો આવી કોઈ ભૂલ નથી, તો કદાચ ડેટા ખોટો હતો. પરંતુ હજુ પણ, જમણી બાજુની પૂર્વધારણા સામાન્ય રીતે પરીક્ષણ કરવામાં આવે છે.
ચાલો ડાઇસ સમસ્યા પર પાછા ફરો. ચાલો ઉપલબ્ધ ડેટાનો ઉપયોગ કરીને ચી-સ્ક્વેર ટેસ્ટના મૂલ્યની ગણતરી કરીએ.
હવે ચાલો સ્વતંત્રતાના 5 ડિગ્રી પર માપદંડનું કોષ્ટક મૂલ્ય શોધીએ ( k) અને મહત્વ સ્તર 0.05 ( α ).

એટલે કે χ 2 0.05; 5 = 11,1.
ચાલો વાસ્તવિક અને ટેબ્યુલેટેડ મૂલ્યોની તુલના કરીએ. 3.4 ( χ 2) < 11,1 (χ 2 0.05; 5). ગણતરી કરેલ માપદંડ નાનો હોવાનું બહાર આવ્યું છે, જેનો અર્થ છે કે ફ્રીક્વન્સીઝની સમાનતા (કરાર) ની પૂર્વધારણાને નકારી કાઢવામાં આવી નથી. આકૃતિમાં, પરિસ્થિતિ આના જેવી દેખાય છે.

જો ગણતરી કરેલ મૂલ્ય નિર્ણાયક ક્ષેત્રની અંદર આવે છે, તો નલ પૂર્વધારણા નકારવામાં આવશે.
પી-લેવલની પણ ગણતરી કરવી વધુ યોગ્ય રહેશે. આ કરવા માટે, તમારે સ્વતંત્રતાની ડિગ્રીની આપેલ સંખ્યા માટે કોષ્ટકમાં સૌથી નજીકનું મૂલ્ય શોધવાની અને અનુરૂપ મહત્વના સ્તરને જોવાની જરૂર છે. પણ આ છેલ્લી સદી છે. અમે વ્યક્તિગત કમ્પ્યુટરનો ઉપયોગ કરીશું, ખાસ કરીને એમએસ એક્સેલ. એક્સેલમાં ચી-સ્ક્વેર સંબંધિત અનેક કાર્યો છે.

નીચે તેમનું સંક્ષિપ્ત વર્ણન છે.
CH2.OBR- ડાબી બાજુએ આપેલ સંભાવના પર માપદંડનું નિર્ણાયક મૂલ્ય (આંકડાકીય કોષ્ટકોની જેમ)
CH2.OBR.PH- જમણી બાજુએ આપેલ સંભાવના માટે માપદંડનું નિર્ણાયક મૂલ્ય. ફંક્શન અનિવાર્યપણે પાછલા એકનું ડુપ્લિકેટ કરે છે. પરંતુ અહીં તમે તરત જ સ્તર સૂચવી શકો છો α , તેને 1 માંથી બાદ કરવાને બદલે. આ વધુ અનુકૂળ છે, કારણ કે મોટાભાગના કિસ્સાઓમાં, તે વિતરણની યોગ્ય પૂંછડી છે જે જરૂરી છે.
CH2.DIST– ડાબી બાજુએ પી-લેવલ (ઘનતાની ગણતરી કરી શકાય છે).
CH2.DIST.PH- જમણી બાજુએ પી-લેવલ.
CHI2.TEST- આપેલ બે ફ્રીક્વન્સી રેન્જ માટે તરત જ ચી-સ્ક્વેર ટેસ્ટ કરે છે. સ્વતંત્રતાની ડિગ્રીની સંખ્યાને કૉલમમાં ફ્રીક્વન્સીની સંખ્યા કરતાં એક ઓછી ગણવામાં આવે છે (જેમ કે તે હોવું જોઈએ), પી-લેવલ મૂલ્ય પરત કરે છે.
ચાલો આપણા પ્રયોગ માટે 5 ડિગ્રી સ્વતંત્રતા અને આલ્ફા 0.05 માટે નિર્ણાયક (ટેબ્યુલર) મૂલ્યની ગણતરી કરીએ. એક્સેલ ફોર્મ્યુલા આના જેવો દેખાશે:
CH2.OBR(0.95;5)
CH2.OBR.PH(0.05;5)
પરિણામ સમાન હશે - 11.0705. આ તે મૂલ્ય છે જે આપણે કોષ્ટકમાં જોઈએ છીએ (1 દશાંશ સ્થાન પર ગોળાકાર).
ચાલો છેલ્લે સ્વતંત્રતા માપદંડના 5 ડિગ્રી માટે p-સ્તરની ગણતરી કરીએ χ 2= 3.4. અમને જમણી બાજુની સંભાવનાની જરૂર છે, તેથી અમે HH (જમણી પૂંછડી) ના ઉમેરા સાથે ફંક્શન લઈએ છીએ.
CH2.DIST.PH(3.4;5) = 0.63857
આનો અર્થ એ છે કે 5 ડિગ્રી સ્વતંત્રતા સાથે માપદંડ મૂલ્ય મેળવવાની સંભાવના છે χ 2= 3.4 અને વધુ લગભગ 64% બરાબર છે. સ્વાભાવિક રીતે, પૂર્વધારણાને નકારી કાઢવામાં આવતી નથી (p-સ્તર 5% કરતા વધારે છે), ફ્રીક્વન્સીઝ ખૂબ સારી સમજૂતીમાં છે.
હવે ચાલો CH2.TEST ફંક્શનનો ઉપયોગ કરીને ફ્રીક્વન્સી એગ્રીમેન્ટ વિશેની પૂર્વધારણા તપાસીએ.

કોઈ કોષ્ટકો નથી, કોઈ બોજારૂપ ગણતરીઓ નથી. ફંક્શન આર્ગ્યુમેન્ટ્સ તરીકે અવલોકન કરેલ અને અપેક્ષિત ફ્રીક્વન્સી સાથે કૉલમનો ઉલ્લેખ કરીને, અમે તરત જ પી-લેવલ મેળવીએ છીએ. સુંદરતા.
હવે કલ્પના કરો કે તમે કોઈ શંકાસ્પદ વ્યક્તિ સાથે ડાઇસ રમી રહ્યા છો. 1 થી 5 સુધીના પોઈન્ટનું વિતરણ સમાન રહે છે, પરંતુ તે 26 છગ્ગા ફટકારે છે (થ્રોની કુલ સંખ્યા 78 થઈ જાય છે).

આ કિસ્સામાં પી-લેવલ 0.003 છે, જે 0.05 કરતા ઘણું ઓછું છે. ડાઇસની માન્યતા પર શંકા કરવાના સારા કારણો છે. ચી-સ્ક્વેર વિતરણ ચાર્ટ પર તે સંભાવના કેવી દેખાય છે તે અહીં છે.

અહીં ચી-સ્ક્વેર ટેસ્ટ પોતે 17.8 છે, જે કુદરતી રીતે, ટેબલ એક (11.1) કરતા વધારે છે.
મને આશા છે કે હું સમજૂતીનો માપદંડ શું છે તે સમજાવવામાં સક્ષમ હતો χ 2(પિયર્સન ચી-સ્ક્વેર) અને આંકડાકીય પૂર્વધારણાઓ ચકાસવા માટે તેનો ઉપયોગ કેવી રીતે કરી શકાય.
છેલ્લે, ફરી એકવાર એક મહત્વપૂર્ણ સ્થિતિ વિશે! ચી-સ્ક્વેર ટેસ્ટ માત્ર ત્યારે જ યોગ્ય રીતે કાર્ય કરે છે જ્યારે તમામ ફ્રીક્વન્સીઝની સંખ્યા 50 કરતાં વધી જાય અને દરેક ગ્રેડેશન માટે લઘુત્તમ અપેક્ષિત મૂલ્ય 5 કરતાં ઓછું ન હોય. જો કોઈપણ કેટેગરીમાં અપેક્ષિત આવર્તન 5 કરતાં ઓછી હોય, પરંતુ તમામ ફ્રીક્વન્સીઝનો સરવાળો ઓળંગે. 50, પછી આવી શ્રેણીને સૌથી નજીકની સાથે જોડવામાં આવે છે જેથી તેમની કુલ આવર્તન 5 કરતાં વધી જાય. જો આ શક્ય ન હોય, અથવા ફ્રીક્વન્સીનો સરવાળો 50 કરતા ઓછો હોય, તો અનુમાનના પરીક્ષણની વધુ સચોટ પદ્ધતિઓનો ઉપયોગ કરવો જોઈએ. અમે તેમના વિશે બીજી વાર વાત કરીશું.
નીચે ચી-સ્ક્વેર ટેસ્ટનો ઉપયોગ કરીને એક્સેલમાં પૂર્વધારણા કેવી રીતે ચકાસવી તે અંગેનો વિડિયો છે.
માં એપ્લિકેશનને ધ્યાનમાં લોએમ.એસએક્સેલસરળ પૂર્વધારણાઓનું પરીક્ષણ કરવા માટે પીયર્સન ચી-સ્ક્વેર ટેસ્ટ.
પ્રાયોગિક ડેટા પ્રાપ્ત કર્યા પછી (એટલે કે જ્યારે ત્યાં કેટલાક હોય છે નમૂના) સામાન્ય રીતે વિતરણ કાયદાની પસંદગી કરવામાં આવે છે જે આપેલ દ્વારા રજૂ કરાયેલ રેન્ડમ ચલનું શ્રેષ્ઠ વર્ણન કરે છે નમૂના. પસંદ કરેલ સૈદ્ધાંતિક વિતરણ કાયદા દ્વારા પ્રાયોગિક ડેટાને કેટલી સારી રીતે વર્ણવવામાં આવે છે તે તપાસવું એનો ઉપયોગ કરીને હાથ ધરવામાં આવે છે કરાર માપદંડ. શૂન્ય પૂર્વધારણા, સામાન્ય રીતે કેટલાક સૈદ્ધાંતિક કાયદામાં રેન્ડમ ચલના વિતરણની સમાનતા વિશે એક પૂર્વધારણા છે.
ચાલો પહેલા એપ્લિકેશન જોઈએ પીયર્સનનો ગુડનેસ-ઓફ-ફીટ ટેસ્ટ X 2 (ચી-ચોરસ)સરળ પૂર્વધારણાઓના સંબંધમાં (સૈદ્ધાંતિક વિતરણના પરિમાણો જાણીતા માનવામાં આવે છે). પછી - , જ્યારે માત્ર વિતરણનો આકાર ઉલ્લેખિત હોય, અને આ વિતરણના પરિમાણો અને મૂલ્ય આંકડા X 2 તેના આધારે મૂલ્યાંકન/ગણતરી કરવામાં આવે છે નમૂનાઓ.
નોંધ: અંગ્રેજી ભાષાના સાહિત્યમાં, અરજીની પ્રક્રિયા પિયર્સન ગુડનેસ-ઓફ-ફિટ ટેસ્ટ X 2 એક નામ છે ફિટ ટેસ્ટની ચી-સ્ક્વેર સારીતા.
ચાલો પૂર્વધારણાઓનું પરીક્ષણ કરવાની પ્રક્રિયાને યાદ કરીએ:
- પર આધારિત છે નમૂનાઓમૂલ્યની ગણતરી કરવામાં આવે છે આંકડા, જે ચકાસવામાં આવી રહેલી પૂર્વધારણાના પ્રકારને અનુરૂપ છે. ઉદાહરણ તરીકે, વપરાયેલ માટે t- આંકડા(જો ખબર ન હોય તો);
- સત્યને આધીન નલ પૂર્વધારણા, આનું વિતરણ આંકડાજાણીતું છે અને તેનો ઉપયોગ સંભાવનાઓની ગણતરી કરવા માટે થઈ શકે છે (ઉદાહરણ તરીકે, માટે t- આંકડાઆ);
- ના આધારે ગણવામાં આવે છે નમૂનાઓઅર્થ આંકડાઆપેલ મૂલ્ય માટે નિર્ણાયક મૂલ્ય સાથે સરખામણી ();
- નલ પૂર્વધારણાઅસ્વીકાર જો કિંમત આંકડાજટિલ કરતાં વધારે (અથવા જો આ મૂલ્ય મેળવવાની સંભાવના હોય તો આંકડા() ઓછા મહત્વ સ્તર, જે સમકક્ષ અભિગમ છે).
ચાલો હાથ ધરીએ પૂર્વધારણા પરીક્ષણવિવિધ વિતરણો માટે.
અલગ કેસ
ધારો કે બે લોકો ડાઇસ રમી રહ્યા છે. દરેક ખેલાડી પાસે ડાઇસનો પોતાનો સેટ હોય છે. ખેલાડીઓ એકસાથે 3 ડાઇસ ફેરવે છે. દરેક રાઉન્ડ તે જીતે છે જે એક સમયે સૌથી વધુ છગ્ગા ફટકારે છે. પરિણામો નોંધવામાં આવે છે. 100 રાઉન્ડ પછી, એક ખેલાડીને શંકા હતી કે તેના વિરોધીની ડાઇસ અસમપ્રમાણ છે, કારણ કે તે ઘણીવાર જીતે છે (તે ઘણીવાર છગ્ગા ફેંકે છે). તેણે વિશ્લેષણ કરવાનું નક્કી કર્યું કે આવા સંખ્યાબંધ દુશ્મન પરિણામોની સંભાવના કેટલી છે.
નોંધ: કારણ કે ત્યાં 3 સમઘન છે, પછી તમે એક સમયે 0 રોલ કરી શકો છો; 1; 2 અથવા 3 છગ્ગા, એટલે કે. રેન્ડમ ચલ 4 મૂલ્યો લઈ શકે છે.
સંભાવના સિદ્ધાંત પરથી આપણે જાણીએ છીએ કે જો ડાઇસ સપ્રમાણ હોય, તો સિક્સ મેળવવાની સંભાવના પાળે છે. તેથી, 100 રાઉન્ડ પછી, ફોર્મ્યુલાનો ઉપયોગ કરીને સિક્સરની ફ્રીક્વન્સીની ગણતરી કરી શકાય છે.
=BINOM.DIST(A7,3,1/6,FALSE)*100
સૂત્ર ધારે છે કે કોષમાં A7 એક રાઉન્ડમાં વળેલા સિક્સરની અનુરૂપ સંખ્યા ધરાવે છે.
નોંધ: ગણતરીઓ આપવામાં આવે છે ડિસ્ક્રીટ શીટ પર ઉદાહરણ ફાઇલ.
સરખામણી માટે અવલોકન કર્યું(અવલોકન કરેલ) અને સૈદ્ધાંતિક આવર્તન(અપેક્ષિત) વાપરવા માટે અનુકૂળ.

જો અવલોકન કરેલ ફ્રીક્વન્સી સૈદ્ધાંતિક વિતરણથી નોંધપાત્ર રીતે વિચલિત થાય છે, નલ પૂર્વધારણાસૈદ્ધાંતિક કાયદા અનુસાર રેન્ડમ ચલના વિતરણ વિશે નકારવું જોઈએ. એટલે કે, જો પ્રતિસ્પર્ધીનો ડાઇસ અસમપ્રમાણ હોય, તો અવલોકન કરેલ ફ્રીક્વન્સી તેનાથી "નોંધપાત્ર રીતે અલગ" હશે. દ્વિપદી વિતરણ.
અમારા કિસ્સામાં, પ્રથમ નજરમાં, ફ્રીક્વન્સીઝ એકદમ નજીક છે અને ગણતરીઓ વિના અસ્પષ્ટ નિષ્કર્ષ દોરવાનું મુશ્કેલ છે. લાગુ પીયર્સનનો ફિટ-ઑફ-ફિટ ટેસ્ટ X 2, જેથી વ્યક્તિલક્ષી નિવેદનને બદલે "નોંધપાત્ર રીતે અલગ", જે સરખામણીના આધારે કરી શકાય. હિસ્ટોગ્રામ, ગાણિતિક રીતે સાચા વિધાનનો ઉપયોગ કરો.
અમે હકીકત એ છે કે કારણે ઉપયોગ મોટી સંખ્યામાં કાયદોવધતા વોલ્યુમ સાથે અવલોકન કરેલ આવર્તન (અવલોકન કરેલ). નમૂનાઓ n સૈદ્ધાંતિક કાયદાને અનુરૂપ સંભાવના તરફ વલણ ધરાવે છે (અમારા કિસ્સામાં, દ્વિપદી કાયદો). અમારા કિસ્સામાં, નમૂનાનું કદ n 100 છે.
ચાલો પરિચય આપીએ પરીક્ષણ આંકડા, જેને આપણે X 2 દ્વારા દર્શાવીએ છીએ:

જ્યાં O l એ ઘટનાઓની અવલોકન કરેલ આવર્તન છે કે રેન્ડમ ચલ એ અમુક સ્વીકાર્ય મૂલ્યો લીધા છે, E l એ અનુરૂપ સૈદ્ધાંતિક આવર્તન છે (અપેક્ષિત). L એ મૂલ્યોની સંખ્યા છે જે રેન્ડમ ચલ લઈ શકે છે (અમારા કિસ્સામાં તે 4 છે).
સૂત્ર પરથી જોઈ શકાય છે, આ આંકડાસૈદ્ધાંતિક રાશિઓ માટે અવલોકન કરેલ ફ્રીક્વન્સીઝની નિકટતાનું માપ છે, એટલે કે. તેનો ઉપયોગ આ ફ્રીક્વન્સીઝ વચ્ચેના "અંતર"નો અંદાજ કાઢવા માટે થઈ શકે છે. જો આ "અંતરો" નો સરવાળો "ખૂબ મોટો" હોય, તો આ ફ્રીક્વન્સીઝ "નોંધપાત્ર રીતે અલગ" હોય છે. તે સ્પષ્ટ છે કે જો આપણું ક્યુબ સપ્રમાણ હોય (એટલે કે લાગુ દ્વિપદી કાયદો), પછી "અંતર" નો સરવાળો "ખૂબ મોટો" હશે તેવી સંભાવના નાની હશે. આ સંભાવનાની ગણતરી કરવા માટે આપણે વિતરણ જાણવાની જરૂર છે આંકડા X 2 ( આંકડારેન્ડમ પર આધારિત X 2 ની ગણતરી નમૂનાઓ, તેથી તે રેન્ડમ ચલ છે અને તેથી, તેનું પોતાનું છે સંભાવના વિતરણ).
બહુપરીમાણીય એનાલોગમાંથી મોઇવર-લાપ્લેસ અભિન્ન પ્રમેયતે જાણીતું છે કે n->∞ માટે આપણું રેન્ડમ ચલ X 2 એ એસિમ્પટોટિક રીતે L - 1 ડિગ્રી સ્વતંત્રતા સાથે છે.
તેથી જો ગણતરી કરેલ મૂલ્ય આંકડા X 2 (આવર્તન વચ્ચેના "અંતર" નો સરવાળો) ચોક્કસ મર્યાદિત મૂલ્ય કરતા વધારે હશે, પછી અમારી પાસે નકારવાનું કારણ હશે નલ પૂર્વધારણા. તપાસવા જેવું જ પેરામેટ્રિક પૂર્વધારણાઓ, મર્યાદા મૂલ્ય દ્વારા સેટ કરવામાં આવે છે મહત્વ સ્તર. જો X 2 આંકડા ગણતરી કરેલ કરતા ઓછા અથવા તેના સમાન મૂલ્ય લેશે તેવી સંભાવના ( પી- અર્થ), ઓછું હશે મહત્વ સ્તર, તે નલ પૂર્વધારણાનકારી શકાય છે.
અમારા કિસ્સામાં, આંકડાકીય મૂલ્ય 22.757 છે. X2 આંકડા 22.757 કરતા વધારે અથવા તેના બરાબર મૂલ્ય લેશે તેવી સંભાવના ખૂબ નાની છે (0.000045) અને સૂત્રોનો ઉપયોગ કરીને ગણતરી કરી શકાય છે.
=CHI2.DIST.PH(22.757,4-1)અથવા
=CHI2.TEST(નિરીક્ષણ કરેલ; અપેક્ષિત)
નોંધ: CHI2.TEST() ફંક્શન ખાસ કરીને બે સ્પષ્ટ ચલ (જુઓ) વચ્ચેના સંબંધને ચકાસવા માટે રચાયેલ છે.
સંભાવના 0.000045 સામાન્ય કરતાં નોંધપાત્ર રીતે ઓછી છે મહત્વ સ્તર 0.05. તેથી, ખેલાડી પાસે તેના પ્રતિસ્પર્ધીને અપ્રમાણિકતા અંગે શંકા કરવાનું દરેક કારણ છે ( નલ પૂર્વધારણાતેની પ્રામાણિકતા નકારી છે).

ઉપયોગ કરતી વખતે માપદંડ X 2તે ખાતરી કરવા માટે જરૂરી છે કે વોલ્યુમ નમૂનાઓ n પૂરતો મોટો હતો, અન્યથા વિતરણ અંદાજ માન્ય રહેશે નહીં આંકડા X 2. સામાન્ય રીતે એવું માનવામાં આવે છે કે આ માટે તે પર્યાપ્ત છે કે અવલોકન કરેલ ફ્રીક્વન્સીઝ (ઓબ્ઝર્વ્ડ) 5 કરતા વધારે હોય. જો આવું ન હોય, તો નાની ફ્રીક્વન્સીઝને એકમાં જોડવામાં આવે છે અથવા અન્ય ફ્રીક્વન્સીમાં ઉમેરવામાં આવે છે, અને સંયુક્ત મૂલ્ય કુલ અસાઇન કરવામાં આવે છે. સંભાવના અને, તે મુજબ, સ્વતંત્રતાની ડિગ્રીની સંખ્યામાં ઘટાડો થાય છે X 2 વિતરણો.
એપ્લિકેશનની ગુણવત્તા સુધારવા માટે માપદંડ X 2(), પાર્ટીશન અંતરાલો ઘટાડવા માટે જરૂરી છે (L વધારો અને તે મુજબ, સંખ્યા વધારવી સ્વતંત્રતાની ડિગ્રી), જોકે, દરેક અંતરાલ (db>5) માં સમાવિષ્ટ અવલોકનોની સંખ્યા પરની મર્યાદા દ્વારા આને અટકાવવામાં આવે છે.
સતત કેસ
પિયર્સન ગુડનેસ-ઓફ-ફિટ ટેસ્ટ X 2 ના કિસ્સામાં પણ અરજી કરી શકાય છે.
ચાલો ચોક્કસ ધ્યાનમાં લઈએ નમૂના, 200 મૂલ્યોનો સમાવેશ કરે છે. શૂન્ય પૂર્વધારણાજણાવે છે કે નમૂનામાંથી બનાવેલ છે.
નોંધ: માં રેન્ડમ ચલો સતત શીટ પર ઉદાહરણ ફાઇલફોર્મ્યુલાનો ઉપયોગ કરીને બનાવેલ છે =NORM.ST.INV(RAND()). તેથી, નવા મૂલ્યો નમૂનાઓશીટની પુનઃગણતરી વખતે દર વખતે જનરેટ થાય છે.
વર્તમાન ડેટા સેટ યોગ્ય છે કે કેમ તે દૃષ્ટિની આકારણી કરી શકાય છે.

ડાયાગ્રામમાંથી જોઈ શકાય છે તેમ, નમૂનાના મૂલ્યો સીધી રેખા સાથે ખૂબ સારી રીતે બંધબેસે છે. જો કે, માટે તરીકે પૂર્વધારણા પરીક્ષણલાગુ પીયર્સન X 2 ગુડનેસ-ઓફ-ફીટ ટેસ્ટ.
આ કરવા માટે, અમે રેન્ડમ ચલના ફેરફારની શ્રેણીને 0.5 ના પગલા સાથે અંતરાલોમાં વિભાજીત કરીએ છીએ. ચાલો આપણે અવલોકન કરેલ અને સૈદ્ધાંતિક ફ્રીક્વન્સીઝની ગણતરી કરીએ. અમે FREQUENCY() ફંક્શનનો ઉપયોગ કરીને અવલોકન કરેલ ફ્રીક્વન્સીઝ અને NORM.ST.DIST() ફંક્શનનો ઉપયોગ કરીને સૈદ્ધાંતિક ફ્રિક્વન્સીની ગણતરી કરીએ છીએ.
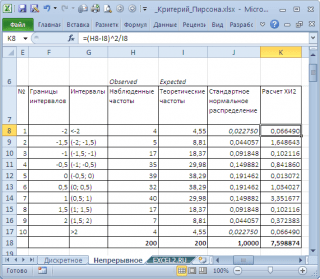
નોંધ: માટે સમાન સ્વતંત્ર કેસ, તેની ખાતરી કરવી જરૂરી છે નમૂનાતદ્દન મોટું હતું, અને અંતરાલમાં >5 મૂલ્યોનો સમાવેશ થાય છે.
ચાલો X2 આંકડાની ગણતરી કરીએ અને આપેલ માટેના નિર્ણાયક મૂલ્ય સાથે તેની તુલના કરીએ મહત્વ સ્તર(0.05). કારણ કે અમે રેન્ડમ ચલના ફેરફારની શ્રેણીને 10 અંતરાલોમાં વિભાજીત કરીએ છીએ, પછી સ્વતંત્રતાની ડિગ્રીની સંખ્યા 9 છે. સૂત્રનો ઉપયોગ કરીને નિર્ણાયક મૂલ્યની ગણતરી કરી શકાય છે.
=CHI2.OBR.PH(0.05;9) અથવા
=CHI2.OBR(1-0.05;9)
ઉપરનો ચાર્ટ દર્શાવે છે કે આંકડાકીય મૂલ્ય 8.19 છે, જે નોંધપાત્ર રીતે વધારે છે નિર્ણાયક મૂલ્ય – નલ પૂર્વધારણાનામંજૂર નથી.
નીચે જ્યાં છે નમૂનાઅસંભવિત મહત્વ લીધું અને તેના આધારે માપદંડ પીયર્સન સંમતિ X 2નલ પૂર્વધારણાને નકારી કાઢવામાં આવી હતી (જોકે રેન્ડમ મૂલ્યો સૂત્રનો ઉપયોગ કરીને જનરેટ કરવામાં આવ્યા હતા. =NORM.ST.INV(RAND()), પૂરી પાડે છે નમૂનાથી પ્રમાણભૂત સામાન્ય વિતરણ).

શૂન્ય પૂર્વધારણાનકારવામાં આવ્યું છે, જો કે દૃષ્ટિની રીતે ડેટા સીધી રેખાની તદ્દન નજીક સ્થિત છે.
ચાલો એક ઉદાહરણ તરીકે પણ લઈએ નમૂના U(-3; 3) થી. આ કિસ્સામાં, ગ્રાફ પરથી પણ તે સ્પષ્ટ છે કે નલ પૂર્વધારણાનકારી કાઢવી જોઈએ.

માપદંડ પીયર્સન સંમતિ X 2તેની પુષ્ટિ પણ કરે છે નલ પૂર્વધારણાનકારી કાઢવી જોઈએ.







