"Katren-Style" poursuit la publication de la série de Konstantin Kravchik sur les statistiques médicales. Dans deux articles précédents, l'auteur a traité de l'explication de concepts tels que et.
Constantin Kravtchik
Mathématicien-analyste. Spécialiste de la recherche statistique en médecine et sciences humaines
Ville : Moscou
Très souvent, dans les articles sur les études cliniques, on trouve une expression mystérieuse : « intervalle de confiance » (IC à 95 % ou IC à 95 % - intervalle de confiance). Par exemple, un article pourrait écrire : « Pour évaluer l’importance des différences, un test t de Student a été utilisé pour calculer l’intervalle de confiance de 95 %. »
Quelle est la valeur de « l’intervalle de confiance à 95 % » et pourquoi le calculer ?
Qu'est-ce qu'un intervalle de confiance ? - Il s'agit de la fourchette dans laquelle se situent les moyennes réelles de la population. Existe-t-il des moyennes « fausses » ? Dans un sens, oui, c’est le cas. Dans nous avons expliqué qu'il est impossible de mesurer le paramètre d'intérêt dans l'ensemble de la population, les chercheurs se contentent donc d'un échantillon limité. Dans cet échantillon (par exemple, basé sur le poids corporel), il existe une valeur moyenne (un certain poids), par laquelle nous jugeons la valeur moyenne dans l'ensemble de la population. Cependant, il est peu probable que le poids moyen d’un échantillon (surtout s’il est petit) coïncide avec le poids moyen de la population générale. Par conséquent, il est plus correct de calculer et d'utiliser la plage des valeurs moyennes de la population.
Par exemple, imaginez que l'intervalle de confiance à 95 % (IC à 95 %) pour l'hémoglobine est de 110 à 122 g/L. Cela signifie qu'il y a 95 % de chances que le taux d'hémoglobine moyen réel dans la population se situe entre 110 et 122 g/L. En d'autres termes, nous ne connaissons pas la valeur moyenne d'hémoglobine dans la population, mais nous pouvons, avec une probabilité de 95 %, indiquer une plage de valeurs pour ce trait.
Les intervalles de confiance sont particulièrement pertinents pour les différences de moyennes entre les groupes, ou tailles d'effet, comme on les appelle.
Disons que nous comparons l'efficacité de deux préparations à base de fer : une qui est sur le marché depuis longtemps et une qui vient d'être enregistrée. Après le traitement, nous avons évalué la concentration d'hémoglobine dans les groupes de patients étudiés et le programme statistique a calculé que la différence entre les valeurs moyennes des deux groupes était, avec une probabilité de 95 %, comprise entre 1,72 et 14,36 g/l (Tableau 1).
Tableau 1. Test pour des échantillons indépendants
(les groupes sont comparés par taux d'hémoglobine)
Cela doit être interprété comme suit : chez certains patients de la population générale qui prennent un nouveau médicament, l'hémoglobine sera plus élevée en moyenne de 1,72 à 14,36 g/l que chez ceux qui ont pris un médicament déjà connu.
En d'autres termes, dans la population générale, la différence des valeurs moyennes d'hémoglobine entre les groupes se situe dans ces limites avec une probabilité de 95 %. Ce sera au chercheur de juger si c’est beaucoup ou peu. Le point de tout cela est que nous ne travaillons pas avec une valeur moyenne, mais avec une plage de valeurs. Par conséquent, nous estimons de manière plus fiable la différence d'un paramètre entre les groupes.
Dans les progiciels statistiques, à la discrétion du chercheur, vous pouvez réduire ou élargir indépendamment les limites de l'intervalle de confiance. En abaissant les probabilités de l’intervalle de confiance, nous réduisons l’éventail des moyennes. Par exemple, à un IC de 90 %, la plage des moyennes (ou la différence des moyennes) sera plus étroite qu'à 95 %.
À l’inverse, augmenter la probabilité à 99 % élargit la plage de valeurs. Lors de la comparaison de groupes, la limite inférieure de l'IC peut franchir la barre zéro. Par exemple, si nous élargissons les limites de l’intervalle de confiance à 99 %, alors les limites de l’intervalle s’étendent de –1 à 16 g/l. Cela signifie qu'il existe dans la population générale des groupes dont la différence de moyenne pour la caractéristique étudiée est égale à 0 (M = 0).
À l'aide d'un intervalle de confiance, vous pouvez tester des hypothèses statistiques. Si l’intervalle de confiance dépasse la valeur zéro, alors l’hypothèse nulle, qui suppose que les groupes ne diffèrent pas sur le paramètre étudié, est vraie. L'exemple est décrit ci-dessus où nous avons élargi les limites à 99 %. Quelque part dans la population générale, nous avons trouvé des groupes qui ne différaient en rien.
Intervalle de confiance à 95 % de la différence d'hémoglobine, (g/l)

La figure montre l'intervalle de confiance à 95 % pour la différence des valeurs moyennes d'hémoglobine entre les deux groupes. La droite passe par le zéro, il y a donc une différence entre les moyennes de zéro, ce qui confirme l'hypothèse nulle selon laquelle les groupes ne diffèrent pas. La plage de différence entre les groupes va de –2 à 5 g/L. Cela signifie que l’hémoglobine peut soit diminuer de 2 g/L, soit augmenter de 5 g/L.
L'intervalle de confiance est un indicateur très important. Grâce à lui, vous pouvez voir si les différences entre les groupes étaient réellement dues à la différence de moyennes ou à un grand échantillon, car avec un grand échantillon les chances de trouver des différences sont plus grandes qu'avec un petit.
En pratique, cela pourrait ressembler à ceci. Nous avons pris un échantillon de 1 000 personnes, mesuré les taux d'hémoglobine et constaté que l'intervalle de confiance pour la différence de moyenne variait entre 1,2 et 1,5 g/l. Le niveau de signification statistique dans ce cas p
Nous constatons que la concentration en hémoglobine a augmenté, mais de manière presque imperceptible. La signification statistique est donc apparue précisément en raison de la taille de l'échantillon.
Les intervalles de confiance peuvent être calculés non seulement pour les moyennes, mais aussi pour les proportions (et les risques relatifs). Par exemple, nous nous intéressons à l’intervalle de confiance des proportions de patients ayant obtenu une rémission en prenant un médicament développé. Supposons que l’IC à 95 % pour les proportions, c’est-à-dire pour la proportion de ces patients, se situe dans la plage de 0,60 à 0,80. Ainsi, on peut dire que notre médicament a un effet thérapeutique dans 60 à 80 % des cas.
À partir de cet article, vous apprendrez :
Ce qui s'est passé intervalle de confiance?
Quel est le but 3 règles sigma?
Comment mettre en pratique ces connaissances ?
De nos jours, en raison d'une surabondance d'informations associées à un large assortiment de produits, d'orientations commerciales, de collaborateurs, de domaines d'activité, etc., il peut être difficile de mettre en évidence l'essentiel, ce qui mérite tout d’abord d’être pris en compte et de faire des efforts pour le gérer. Définition intervalle de confiance et analyse des valeurs réelles dépassant ses frontières - une technique qui vous aidera à mettre en évidence des situations, influencer les tendances changeantes. Vous pourrez développer des facteurs positifs et réduire l’influence des facteurs négatifs. Cette technologie est utilisée dans de nombreuses entreprises mondiales de renom.
Il y a ce qu'on appelle " alertes", lequel informer les gestionnaires que la valeur suivante est dans une certaine direction est allé au-delà intervalle de confiance. Qu'est-ce que cela signifie? C'est le signe qu'un événement inhabituel s'est produit, ce qui pourrait modifier la tendance existante dans cette direction. Ceci est un signalà ça pour le comprendre dans la situation et comprendre ce qui l’a influencée.
Par exemple, considérons plusieurs situations. Nous avons calculé les prévisions de ventes avec des limites de prévision pour 100 articles pour 2011 par mois et les ventes réelles en mars :
- Pour « l’huile de tournesol », ils ont dépassé la limite supérieure de la prévision et ne sont pas tombés dans l’intervalle de confiance.
- Pour la « Levure sèche », nous avons dépassé la limite inférieure des prévisions.
- La « bouillie d'avoine » a dépassé la limite supérieure.
Pour les autres produits, les ventes réelles se situent dans les limites prévues. Ceux. leurs ventes ont été conformes aux attentes. Nous avons donc identifié 3 produits qui dépassaient les frontières et avons commencé à comprendre ce qui les a poussés à dépasser les frontières :
- Pour l'Huile de Tournesol, nous sommes entrés dans un nouveau réseau de distribution, ce qui nous a apporté un volume de ventes supplémentaire, ce qui nous a amené à dépasser le plafond. Pour ce produit, il convient de recalculer les prévisions jusqu'à la fin de l'année, en tenant compte des prévisions de ventes de ce réseau.
- Pour la « Levure sèche », la voiture est restée bloquée à la douane, et il y a eu une pénurie dans les 5 jours, ce qui a affecté la baisse des ventes et dépassé la limite inférieure. Cela vaut peut-être la peine de déterminer la cause et d’essayer de ne pas répéter cette situation.
- Un événement de promotion des ventes a été lancé pour le porridge à l'avoine, ce qui a donné lieu à une augmentation significative des ventes et a permis à l'entreprise d'aller au-delà des prévisions.
Nous avons identifié 3 facteurs qui ont influencé le dépassement des limites prévues. Il peut y en avoir beaucoup plus dans la vie. Pour accroître la précision des prévisions et de la planification, facteurs qui conduisent au fait que les ventes réelles peuvent dépasser les prévisions, il convient de souligner et de construire des prévisions et des plans pour eux séparément. Et puis considérez leur impact sur les principales prévisions de ventes. Vous pouvez également évaluer régulièrement l’impact de ces facteurs et améliorer la situation. en réduisant l’influence des facteurs négatifs et en augmentant l’influence des facteurs positifs.
Avec un intervalle de confiance on peut :
- Sélectionnez un itinéraire, auxquels il convient de prêter attention, car des événements se sont produits dans ces directions et peuvent affecter changement de tendance.
- Identifier les facteurs, qui influencent réellement le changement de situation.
- Accepter décision éclairée(par exemple, sur les achats, la planification, etc.).
Voyons maintenant ce qu'est un intervalle de confiance et comment le calculer dans Excel à l'aide d'un exemple.
Qu'est-ce qu'un intervalle de confiance ?
L'intervalle de confiance correspond aux limites de prévision (supérieures et inférieures) à l'intérieur desquelles avec une probabilité donnée (sigma) les valeurs réelles apparaîtront.
Ceux. Nous calculons les prévisions - c'est notre ligne directrice principale, mais nous comprenons qu'il est peu probable que les valeurs réelles soient égales à 100 % à nos prévisions. Et la question se pose, dans quelles limites les valeurs réelles peuvent baisser, si la tendance actuelle continue? Et cette question nous aidera à répondre calcul de l'intervalle de confiance, c'est-à-dire - limites supérieure et inférieure de la prévision.
Qu'est-ce qu'un sigma de probabilité donné ?
Lors du calcul intervalle de confiance que nous pouvons définir la probabilité coups valeurs réelles dans les limites prévisionnelles données. Comment faire cela ? Pour ce faire, on fixe la valeur de sigma et, si sigma est égal à :
3 sigmas- alors la probabilité que la prochaine valeur réelle tombe dans l'intervalle de confiance sera de 99,7 %, soit 300 contre 1, ou il y a une probabilité de 0,3 % de dépasser les limites.
2 sigmas- alors, la probabilité que la prochaine valeur tombe dans les limites est ≈ 95,5%, c'est-à-dire les chances sont d'environ 20 contre 1, soit 4,5 % de chances d'aller par-dessus bord.
1 sigma- alors la probabilité est ≈ 68,3%, soit les chances sont d'environ 2 contre 1, ou il y a 31,7 % de chances que la prochaine valeur se situe en dehors de l'intervalle de confiance.
Nous avons formulé règle des 3 sigma,qui dit que probabilité de réussite une autre valeur aléatoire dans l'intervalle de confiance avec une valeur donnée trois sigma est de 99,7 %.
Le grand mathématicien russe Chebyshev a démontré le théorème selon lequel il existe une probabilité de 10 % de dépasser les limites prévues pour une valeur donnée de trois sigma. Ceux. la probabilité de tomber dans l'intervalle de confiance 3-sigma sera d'au moins 90 %, tandis qu'une tentative de calculer la prévision et ses limites « à l'œil nu » est semée d'erreurs beaucoup plus importantes.
Comment calculer soi-même un intervalle de confiance dans Excel ?
Examinons le calcul de l'intervalle de confiance dans Excel (c'est-à-dire les limites supérieure et inférieure de la prévision) à l'aide d'un exemple. Nous avons une série chronologique - ventes par mois pendant 5 ans. Voir fichier joint.
Pour calculer les limites de prévision, nous calculons :
- Prévisions de ventes().
- Sigma - écart type modèles de prévision à partir des valeurs réelles.
- Trois sigmas.
- Intervalle de confiance.
1. Prévisions de ventes.
=(RC[-14] (données de séries chronologiques)-RC[-1] (valeur du modèle))^2(au carré)

3. Pour chaque mois, résumons les valeurs d'écart par rapport à l'étape 8 Sum((Xi-Ximod)^2), c'est-à-dire Résumons janvier, février... pour chaque année.
Pour ce faire, utilisez la formule =SUMIF()
SUMIF(tableau avec les numéros de période à l'intérieur du cycle (pour les mois de 1 à 12) ; lien vers le numéro de période dans le cycle ; lien vers un tableau avec des carrés de la différence entre les données source et les valeurs de période)

4. Calculez l'écart type pour chaque période du cycle de 1 à 12 (étape 10 dans le fichier joint).
Pour ce faire, on extrait la racine de la valeur calculée à l'étape 9 et on la divise par le nombre de périodes de ce cycle moins 1 = SQRT((Sum(Xi-Ximod)^2/(n-1))
Utilisons les formules dans Excel =ROOT(R8 (lien vers (Somme(Xi-Ximod)^2)/(COUNTIF($O$8 :$O$67 (lien vers le tableau avec les numéros de cycle); O8 (lien vers un numéro de cycle spécifique que l'on compte dans le tableau))-1))
En utilisant la formule Excel = COUNTIF on compte le nombre n

Après avoir calculé l'écart type des données réelles du modèle de prévision, nous avons obtenu la valeur sigma pour chaque mois - étape 10 dans le fichier joint.
3. Calculons 3 sigma.
A l'étape 11, nous définissons le nombre de sigmas - dans notre exemple « 3 » (étape 11 dans le fichier joint):

Également pratique pour pratiquer les valeurs sigma :
1,64 sigma - 10 % de chance de dépasser la limite (1 chance sur 10) ;
1,96 sigma - 5 % de chance de dépasser les limites (1 chance sur 20) ;
2,6 sigma - 1% de chance de dépasser les limites (1 chance sur 100).
5) Calculer trois sigma, pour cela on multiplie les valeurs « sigma » de chaque mois par « 3 ».

3. Déterminez l’intervalle de confiance.
- Limite supérieure de prévision- prévision des ventes prenant en compte la croissance et la saisonnalité + (plus) 3 sigma ;
- Limite inférieure de prévision- prévision des ventes prenant en compte la croissance et la saisonnalité – (moins) 3 sigma ;
Pour faciliter le calcul de l'intervalle de confiance sur une longue période (voir fichier joint), nous utiliserons la formule Excel =Y8+RECHERCHEV(W8,$U$8:$V$19,2,0), Où
Y8- prévisions de ventes ;
W8- le numéro du mois pour lequel on prendra la valeur 3-sigma ;
Ceux. Limite supérieure de prévision= « prévisions de ventes » + « 3 sigma » (dans l'exemple, RECHERCHEV(numéro du mois ; tableau avec 3 valeurs sigma ; colonne de laquelle on extrait la valeur sigma égale au numéro du mois dans la ligne correspondante ; 0)).

Limite inférieure de prévision= « prévisions de ventes » moins « 3 sigma ».
Nous avons donc calculé l'intervalle de confiance dans Excel.
Nous avons maintenant une prévision et une plage avec des limites dans lesquelles les valeurs réelles se situeront avec une probabilité sigma donnée.
Dans cet article, nous avons examiné ce que sont le sigma et la règle des trois sigma, comment déterminer un intervalle de confiance et pourquoi vous pouvez utiliser cette technique dans la pratique.
Nous vous souhaitons des prévisions précises et du succès !
Comment Forecast4AC PRO peut vous aiderlors du calcul de l'intervalle de confiance?:
Forecast4AC PRO calculera automatiquement les limites supérieures ou inférieures de la prévision pour plus de 1 000 séries chronologiques simultanément ;
La possibilité d'analyser les limites de la prévision par rapport aux prévisions, à la tendance et aux ventes réelles sur le graphique en une seule touche ;
Dans le programme Forcast4AC PRO, il est possible de définir la valeur sigma de 1 à 3.
Rejoignez-nous !
Téléchargez des applications gratuites de prévisions et d'analyse commerciale:

- Novo Prévisions Lite- automatique calcul des prévisions V Exceller.
- 4analyses - Analyse ABC-XYZ et analyse des émissions Exceller.
- Qlik Sense Bureau et QlikViewPersonal Edition - Systèmes BI pour l'analyse et la visualisation des données.
Testez les capacités des solutions payantes :
- Novo Prévisions PRO- prévisions dans Excel pour de grands ensembles de données.
Intervalle de confiance(CI ; en anglais, intervalle de confiance - CI) obtenu dans une étude avec un échantillon donne une mesure de l'exactitude (ou de l'incertitude) des résultats de l'étude afin de tirer des conclusions sur la population de tous ces patients (la population générale). La définition correcte d'un IC à 95 % peut être formulée comme suit : 95 % de ces intervalles contiendront la vraie valeur dans la population. Cette interprétation est un peu moins précise : CI est la plage de valeurs dans laquelle vous pouvez être sûr à 95 % qu'elle contient la vraie valeur. Lors de l’utilisation d’un IC, l’accent est mis sur la détermination d’un effet quantitatif, par opposition à la valeur P résultant du test de signification statistique. La valeur P n’estime aucune quantité, mais sert plutôt à mesurer la force des preuves contre l’hypothèse nulle de « aucun effet ». La valeur de P en elle-même ne nous dit rien sur l’ampleur de la différence, ni même sur sa direction. Par conséquent, les valeurs P indépendantes ne sont absolument pas informatives dans les articles ou les résumés. En revanche, l’IC indique à la fois l’ampleur de l’effet d’intérêt immédiat, tel que le bénéfice d’un traitement, et la force des preuves. Par conséquent, DI est directement lié à la pratique de l’EBM.
L'approche d'estimation de l'analyse statistique, illustrée par l'IC, vise à mesurer la quantité d'un effet d'intérêt (sensibilité d'un test diagnostique, taux de cas prédits, réduction du risque relatif avec le traitement, etc.) et également à mesurer l'incertitude dans cet effet. effet. Le plus souvent, l'IC est la plage de valeurs de part et d'autre de l'estimation dans laquelle se situe probablement la vraie valeur, et vous pouvez en être sûr à 95 %. L’accord sur l’utilisation de la probabilité de 95 % est arbitraire, tout comme la valeur P.<0,05 для оценки статистической значимости, и авторы иногда используют 90% или 99% ДИ. Заметим, что слово «интервал» означает диапазон величин и поэтому стоит в единственном числе. Две величины, которые ограничивают интервал, называются «доверительными пределами».
CI repose sur l’idée qu’une même étude réalisée sur différents échantillons de patients ne produirait pas des résultats identiques, mais que leurs résultats seraient répartis autour d’une valeur vraie mais inconnue. En d’autres termes, CI le décrit comme une « variabilité dépendante de l’échantillon ». L'IC ne reflète pas une incertitude supplémentaire due à d'autres raisons ; en particulier, il n'inclut pas l'impact d'une perte de suivi sélective, d'une mauvaise observance ou d'une mesure des résultats inexacte, de l'absence de mise en aveugle, etc. L’IC sous-estime donc toujours le montant total de l’incertitude.
Calcul de l'intervalle de confiance
Tableau A1.1. Erreurs types et intervalles de confiance pour certaines mesures cliniques
En règle générale, un IC est calculé à partir d'une estimation observée d'une quantité, telle que la différence (d) entre deux proportions, et de l'erreur standard (SE) dans l'estimation de cette différence. L'IC approximatif à 95 % obtenu de cette manière est d ± 1,96 SE. La formule change en fonction de la nature de la mesure du résultat et de la portée de l'IC. Par exemple, dans un essai randomisé contrôlé par placebo portant sur un vaccin acellulaire contre la coqueluche, 72 nourrissons sur 1 670 (4,3 %) ayant reçu le vaccin ont développé la coqueluche et 240 sur 1 665 (14,4 %) dans le groupe témoin. La différence en pourcentage, connue sous le nom de réduction du risque absolu, est de 10,1 %. L'ES de cette différence est de 0,99 %. En conséquence, l'IC à 95 % est de 10,1 % + 1,96 x 0,99 %, soit de 8,2 à 12,0.
Malgré leurs approches philosophiques différentes, les IC et les tests de signification statistique sont étroitement liés mathématiquement.
Ainsi, la valeur P est « significative », c’est-à-dire R.<0,05 соответствует 95% ДИ, который исключает величину эффекта, указывающую на отсутствие различия. Например, для различия между двумя средними пропорциями это ноль, а для относительного риска или отношения шансов - единица. При некоторых обстоятельствах эти два подхода могут быть не совсем эквивалентны. Преобладающая точка зрения: оценка с помощью ДИ - предпочтительный подход к суммированию результатов исследования, но ДИ и величина Р взаимодополняющи, и во многих статьях используются оба способа представления результатов.
L'incertitude (l'inexactitude) de l'estimation, exprimée en IC, est largement liée à la racine carrée de la taille de l'échantillon. Les petits échantillons fournissent moins d’informations que les grands, et l’IC est d’autant plus large dans un échantillon plus petit. Par exemple, un article comparant les performances de trois tests utilisés pour diagnostiquer une infection à Helicobacter pylori a rapporté une sensibilité du test respiratoire à l'urée de 95,8 % (IC à 95 % 75-100). Bien que le chiffre de 95,8 % soit impressionnant, le petit échantillon de 24 patients adultes atteints de J. pylori signifie qu'il existe une incertitude significative dans cette estimation, comme le montre l'IC large. En effet, la limite inférieure de 75 % est bien inférieure à l’estimation de 95,8 %. Si la même sensibilité était observée dans un échantillon de 240 personnes, l’IC à 95 % serait compris entre 92,5 et 98,0, ce qui donnerait davantage d’assurance sur la haute sensibilité du test.
Dans les essais contrôlés randomisés (ECR), les résultats non significatifs (c'est-à-dire ceux avec P > 0,05) sont particulièrement susceptibles d'être mal interprétés. L'IC est particulièrement utile ici car il montre dans quelle mesure les résultats sont cohérents avec l'effet réel cliniquement utile. Par exemple, dans un ECR comparant la suture colique et l’anastomose par agrafes, une infection de la plaie s’est développée chez 10,9 % et 13,5 % des patients, respectivement (P = 0,30). L'IC à 95 % de cette différence est de 2,6 % (−2 à +8). Même dans cette étude portant sur 652 patients, il reste possible qu'il existe une légère différence dans l'incidence des infections résultant des deux procédures. Moins il y a de recherche, plus l’incertitude est grande. Sung et coll. a réalisé un ECR pour comparer la perfusion d'octréotide à la sclérothérapie aiguë pour les saignements variqueux aigus chez 100 patients. Dans le groupe octréotide, le taux de contrôle des saignements était de 84 % ; dans le groupe sclérothérapie - 90 %, ce qui donne P = 0,56. Notez que les taux de saignements continus sont similaires à ceux d’infection des plaies dans l’étude mentionnée. Dans ce cas, cependant, l'IC à 95 % pour la différence entre les interventions est de 6 % (-7 à +19). Cette fourchette est assez large par rapport à la différence de 5 % qui présenterait un intérêt clinique. De toute évidence, l’étude n’exclut pas une différence significative d’efficacité. Par conséquent, la conclusion des auteurs selon laquelle la perfusion d’octréotide et la sclérothérapie sont tout aussi efficaces dans le traitement des saignements dus aux varices est définitivement invalide. Dans des cas comme celui-ci, où, comme ici, l'IC à 95 % pour la réduction du risque absolu (ARR) inclut zéro, l'IC pour le NNT (nombre nécessaire à traiter) est assez difficile à interpréter. Le NPL et son CI sont obtenus à partir des réciproques de l'ACP (en multipliant par 100 si ces valeurs sont données en pourcentages). Nous obtenons ici NPL = 100 : 6 = 16,6 avec un IC à 95 % de -14,3 à 5,3. Comme le montre la note de bas de page « d » du tableau. A1.1, ce CI comprend des valeurs de NPL de 5,3 à l'infini et de NPL de 14,3 à l'infini.
Des IC peuvent être construits pour les estimations ou comparaisons statistiques les plus couramment utilisées. Pour les ECR, cela inclut la différence entre les proportions moyennes, les risques relatifs, les rapports de cotes et les NLR. De même, des IC peuvent être obtenus pour toutes les principales estimations réalisées dans les études sur l’exactitude des tests de diagnostic – sensibilité, spécificité, valeur prédictive positive (qui sont toutes des proportions simples) et rapports de vraisemblance – estimations obtenues dans les méta-analyses et les comparaisons avec des témoins. études. Un programme informatique couvrant bon nombre de ces utilisations des inhalateurs-doseurs est disponible dans la deuxième édition de Statistics with Confidence. Des macros permettant de calculer les IC pour les proportions sont disponibles gratuitement pour Excel et les programmes statistiques SPSS et Minitab à l'adresse http://www.uwcm.ac.uk/study/medicine/epidemiology_statistics/research/statistics/proportions, htm.
Plusieurs estimations de l'effet du traitement
Bien que la construction d’IC soit souhaitable pour les principaux résultats de l’étude, elle n’est pas nécessaire pour tous les résultats. L’IC concerne les comparaisons cliniquement importantes. Par exemple, lorsque l’on compare deux groupes, l’IC correct est celui construit pour la différence entre les groupes, comme le montrent les exemples ci-dessus, et non l’IC qui peut être construit pour l’estimation dans chaque groupe. Non seulement il n’est pas utile de fournir des IC distincts pour les estimations de chaque groupe, mais cette présentation peut être trompeuse. De même, la bonne approche pour comparer l’efficacité des traitements dans différents sous-groupes consiste à comparer directement deux (ou plusieurs) sous-groupes. Il est incorrect de supposer qu'un traitement est efficace dans un seul sous-groupe si son IC exclut la valeur correspondant à aucun effet et que les autres ne le sont pas. Les IC sont également utiles pour comparer les résultats de plusieurs sous-groupes. Sur la fig. A 1.1 montre le risque relatif d'éclampsie chez les femmes atteintes de prééclampsie dans des sous-groupes de femmes issus d'un ECR contrôlé par placebo sur le sulfate de magnésium.
Riz. A1.2. Le graphique forestier montre les résultats de 11 essais cliniques randomisés du vaccin antirotavirus bovin pour la prévention de la diarrhée par rapport au placebo. Un intervalle de confiance de 95 % a été utilisé pour estimer le risque relatif de diarrhée. La taille du carré noir est proportionnelle à la quantité d’informations. De plus, l'estimation récapitulative de l'efficacité du traitement et l'intervalle de confiance à 95 % (indiqué par un losange) sont affichés. La méta-analyse a utilisé un modèle à effets aléatoires plus grand que certains modèles prédéfinis ; par exemple, il pourrait s'agir de la taille utilisée pour calculer la taille de l'échantillon. Un critère plus strict exige que l’ensemble de la gamme CI présente un bénéfice supérieur à un minimum prédéfini.
Nous avons déjà discuté de l’erreur consistant à considérer le manque de signification statistique comme une indication que deux traitements sont également efficaces. Il est tout aussi important de ne pas assimiler signification statistique et importance clinique. L'importance clinique peut être supposée lorsque le résultat est statistiquement significatif et que l'ampleur de l'estimation de l'efficacité du traitement
Les études peuvent montrer si les résultats sont statistiquement significatifs, lesquels sont cliniquement importants et lesquels ne le sont pas. Sur la fig. A1.2 montre les résultats de quatre tests, pour lesquels l'ensemble du CI<1, т.е. их результаты статистически значимы при Р <0,05 , . После высказанного предположения о том, что клинически важным различием было бы сокращение риска диареи на 20% (ОР = 0,8), все эти испытания показали клинически значимую оценку сокращения риска, и лишь в исследовании Treanor весь 95% ДИ меньше этой величины. Два других РКИ показали клинически важные результаты, которые не были статистически значимыми. Обратите внимание, что в трёх испытаниях точечные оценки эффективности лечения были почти идентичны, но ширина ДИ различалась (отражает размер выборки). Таким образом, по отдельности доказательная сила этих РКИ различна.
Il existe deux types d'estimations en statistiques : ponctuelles et par intervalles. Estimation ponctuelle est une statistique d'échantillon unique utilisée pour estimer un paramètre de population. Par exemple, la moyenne de l'échantillon est une estimation ponctuelle de l'espérance mathématique de la population et de la variance de l'échantillon S2- estimation ponctuelle de la variance de la population σ 2. il a été démontré que la moyenne de l'échantillon est une estimation impartiale des attentes mathématiques de la population. Une moyenne d'échantillon est dite non biaisée car la moyenne de toutes les moyennes d'échantillon (avec la même taille d'échantillon) n) est égale à l’espérance mathématique de la population générale.
Pour que la variance de l'échantillon S2 est devenu une estimation impartiale de la variance de la population σ 2, le dénominateur de la variance de l'échantillon doit être égal à n – 1 , pas n. En d’autres termes, la variance de la population est la moyenne de toutes les variances possibles de l’échantillon.
Lors de l'estimation des paramètres de population, il convient de garder à l'esprit que les statistiques d'échantillonnage telles que , dépendent d’échantillons spécifiques. Pour tenir compte de ce fait, obtenir estimation d'intervalle attente mathématique de la population générale, analyser la distribution des moyennes de l'échantillon (pour plus de détails, voir). L'intervalle construit est caractérisé par un certain niveau de confiance, qui représente la probabilité que le véritable paramètre de population soit estimé correctement. Des intervalles de confiance similaires peuvent être utilisés pour estimer la proportion d'une caractéristique r et la principale masse répartie de la population.
Téléchargez la note au format ou, exemples au format
Construire un intervalle de confiance pour l'espérance mathématique de la population avec un écart type connu
Construire un intervalle de confiance pour la part d'une caractéristique dans la population
Cette section étend le concept d'intervalle de confiance aux données catégorielles. Cela nous permet d'estimer la part de la caractéristique dans la population r en utilisant un exemple de partage rS=X/n. Comme indiqué, si les quantités nr Et n(1 – p) dépasse le nombre 5, la distribution binomiale peut être approchée normalement. Par conséquent, pour estimer la part d’une caractéristique dans la population r il est possible de construire un intervalle dont le niveau de confiance est égal à (1 – α)x100 %.

Où pS- proportion d'échantillon de la caractéristique égale à X/n, c'est-à-dire nombre de réussites divisé par la taille de l'échantillon, r- la part de la caractéristique dans la population générale, Z- valeur critique de la distribution normale standardisée, n- taille de l'échantillon.
Exemple 3. Supposons qu'un échantillon composé de 100 factures remplies au cours du dernier mois soit extrait du système d'information. Disons que 10 de ces factures ont été établies avec des erreurs. Ainsi, r= 10/100 = 0,1. Le niveau de confiance de 95 % correspond à la valeur critique Z = 1,96.
Ainsi, la probabilité qu'entre 4,12 % et 15,88 % des factures contiennent des erreurs est de 95 %.
Pour une taille d’échantillon donnée, l’intervalle de confiance contenant la proportion de la caractéristique dans la population apparaît plus large que pour une variable aléatoire continue. En effet, les mesures d'une variable aléatoire continue contiennent plus d'informations que les mesures de données catégorielles. En d'autres termes, les données catégorielles qui ne prennent que deux valeurs contiennent des informations insuffisantes pour estimer les paramètres de leur distribution.
DANScalculer des estimations extraites d'une population finie
Estimation de l'espérance mathématique. Facteur de correction pour la population finale ( fpc) a été utilisé pour réduire l'erreur type d'un facteur. Lors du calcul des intervalles de confiance pour les estimations des paramètres de population, un facteur de correction est appliqué dans les situations où les échantillons sont tirés sans être retournés. Ainsi, un intervalle de confiance pour l'espérance mathématique ayant un niveau de confiance égal à (1 – α)x100 %, est calculé par la formule :

Exemple 4. Pour illustrer l'utilisation du facteur de correction pour une population finie, revenons au problème du calcul de l'intervalle de confiance pour le montant moyen des factures, évoqué ci-dessus dans l'exemple 3. Supposons qu'une entreprise émette 5 000 factures par mois, et X̅=110,27 dollars, S= 28,95 $, N = 5000, n = 100, α = 0,05, t99 = 1,9842. En utilisant la formule (6) on obtient :
Estimation de la part d'une fonctionnalité. Lors d'un choix sans retour, l'intervalle de confiance pour la proportion de l'attribut ayant un niveau de confiance égal à (1 – α)x100 %, est calculé par la formule :

Intervalles de confiance et questions éthiques
Lorsqu’on échantillonne une population et qu’on tire des conclusions statistiques, des problèmes éthiques se posent souvent. Le principal est la façon dont les intervalles de confiance et les estimations ponctuelles des statistiques d’échantillon concordent. La publication d’estimations ponctuelles sans préciser les intervalles de confiance associés (généralement au niveau de confiance de 95 %) et la taille de l’échantillon à partir duquel elles sont dérivées peut créer de la confusion. Cela peut donner à l'utilisateur l'impression que l'estimation ponctuelle est exactement ce dont il a besoin pour prédire les propriétés de l'ensemble de la population. Il est donc nécessaire de comprendre que dans toute recherche, l’accent ne doit pas être mis sur les estimations ponctuelles, mais sur les estimations par intervalles. En outre, une attention particulière doit être accordée à la sélection correcte de la taille des échantillons.
Le plus souvent, les objets de manipulations statistiques sont les résultats d'enquêtes sociologiques auprès de la population sur certaines questions politiques. Dans le même temps, les résultats de l'enquête sont publiés à la une des journaux, et l'erreur d'échantillonnage et la méthodologie d'analyse statistique sont publiées quelque part au milieu. Pour prouver la validité des estimations ponctuelles obtenues, il est nécessaire d'indiquer la taille de l'échantillon sur la base duquel elles ont été obtenues, les limites de l'intervalle de confiance et son niveau de signification.
Remarque suivante
Des documents du livre Levin et al. Statistics for Managers sont utilisés. – M. : Williams, 2004. – p. 448-462
Théorème central limite déclare qu’avec une taille d’échantillon suffisamment grande, la distribution des moyennes de l’échantillon peut être approchée par une distribution normale. Cette propriété ne dépend pas du type de répartition de la population.
Cible– enseigner aux étudiants des algorithmes pour calculer les intervalles de confiance des paramètres statistiques.
Lors du traitement statistique des données, la moyenne arithmétique calculée, le coefficient de variation, le coefficient de corrélation, les critères de différence et d'autres statistiques ponctuelles doivent recevoir des limites de confiance quantitatives, qui indiquent d'éventuelles fluctuations de l'indicateur dans des directions de plus en plus grandes au sein de l'intervalle de confiance.
Exemple 3.1
.
La répartition du calcium dans le sérum sanguin des singes, comme établie précédemment, est caractérisée par les indicateurs d'échantillon suivants : = 11,94 mg% ;  = 0,127 mg% ; n= 100. Il est nécessaire de déterminer l'intervalle de confiance de la moyenne générale (
= 0,127 mg% ; n= 100. Il est nécessaire de déterminer l'intervalle de confiance de la moyenne générale (  ) avec probabilité de confiance P.
= 0,95.
) avec probabilité de confiance P.
= 0,95.
La moyenne générale se situe avec une certaine probabilité dans l'intervalle :
 , Où
, Où  – moyenne arithmétique de l'échantillon ; t– Test de l’étudiant ;
– moyenne arithmétique de l'échantillon ; t– Test de l’étudiant ;  – erreur de moyenne arithmétique.
– erreur de moyenne arithmétique.
En utilisant le tableau « Valeurs du test t de Student », nous trouvons la valeur
 avec une probabilité de confiance de 0,95 et le nombre de degrés de liberté k= 100-1 = 99. Il est égal à 1,982. Avec les valeurs de la moyenne arithmétique et de l'erreur statistique, nous la substituons dans la formule :
avec une probabilité de confiance de 0,95 et le nombre de degrés de liberté k= 100-1 = 99. Il est égal à 1,982. Avec les valeurs de la moyenne arithmétique et de l'erreur statistique, nous la substituons dans la formule :
ou 11h69  12,19
12,19
Ainsi, avec une probabilité de 95%, on peut affirmer que la moyenne générale de cette distribution normale se situe entre 11,69 et 12,19 mg%.
Exemple 3.2
. Déterminer les limites de l'intervalle de confiance à 95 % pour la variance générale (  ) répartition du calcium dans le sang des singes, si l'on sait que
) répartition du calcium dans le sang des singes, si l'on sait que  = 1,60, à n
= 100.
= 1,60, à n
= 100.
Pour résoudre le problème, vous pouvez utiliser la formule suivante :
Où  – erreur statistique de dispersion.
– erreur statistique de dispersion.
Nous trouvons l'erreur de variance d'échantillonnage à l'aide de la formule :  . Il est égal à 0,11. Signification t- critère avec une probabilité de confiance de 0,95 et le nombre de degrés de liberté k= 100–1 = 99 est connu de l’exemple précédent.
. Il est égal à 0,11. Signification t- critère avec une probabilité de confiance de 0,95 et le nombre de degrés de liberté k= 100–1 = 99 est connu de l’exemple précédent.
Utilisons la formule et obtenons :
ou 1,38  1,82
1,82
Plus précisément, l'intervalle de confiance de la variance générale peut être construit en utilisant  (chi carré) - Test de Pearson. Les points critiques pour ce critère sont donnés dans un tableau spécial. Lors de l'utilisation du critère
(chi carré) - Test de Pearson. Les points critiques pour ce critère sont donnés dans un tableau spécial. Lors de l'utilisation du critère  Pour construire un intervalle de confiance, un niveau de signification bilatéral est utilisé. Pour la limite inférieure, le niveau de signification est calculé à l'aide de la formule
Pour construire un intervalle de confiance, un niveau de signification bilatéral est utilisé. Pour la limite inférieure, le niveau de signification est calculé à l'aide de la formule  , pour le haut –
, pour le haut –  . Par exemple, pour le niveau de confiance
. Par exemple, pour le niveau de confiance  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. En conséquence, selon le tableau de répartition des valeurs critiques
= 0,990. En conséquence, selon le tableau de répartition des valeurs critiques  , avec des niveaux de confiance et un nombre de degrés de liberté calculés k= 100 – 1= 99, trouvez les valeurs
, avec des niveaux de confiance et un nombre de degrés de liberté calculés k= 100 – 1= 99, trouvez les valeurs  Et
Et  . Nous obtenons
. Nous obtenons  est égal à 135,80, et
est égal à 135,80, et 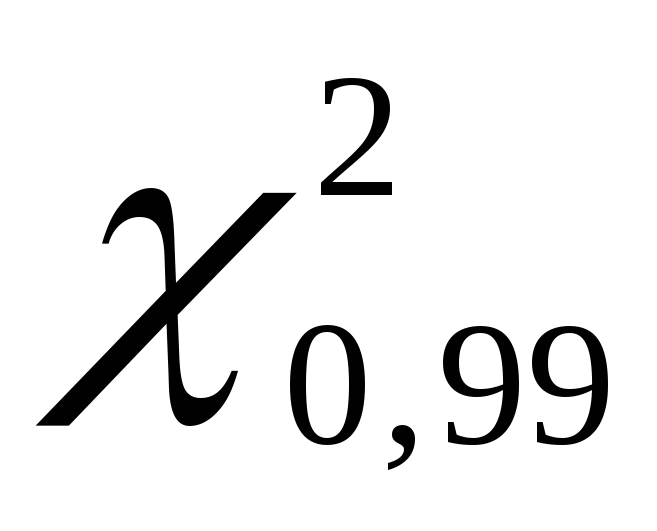 est égal à 70,06.
est égal à 70,06.
Pour trouver des limites de confiance pour la variance générale en utilisant  Utilisons les formules : pour la limite inférieure
Utilisons les formules : pour la limite inférieure  , pour la limite supérieure
, pour la limite supérieure  . Remplaçons les valeurs trouvées par les données problématiques
. Remplaçons les valeurs trouvées par les données problématiques  en formules :
en formules : 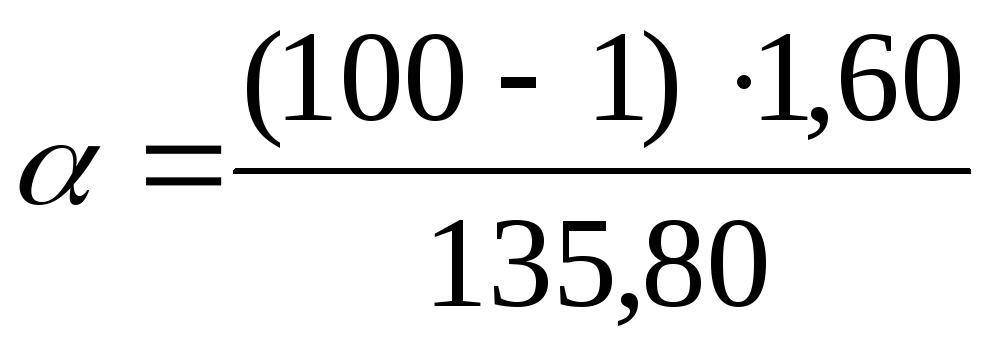 =
1,17;
=
1,17; = 2,26. Ainsi, avec une probabilité de confiance P.= 0,99 ou 99 % de variance générale sera comprise entre 1,17 et 2,26 mg% inclus.
= 2,26. Ainsi, avec une probabilité de confiance P.= 0,99 ou 99 % de variance générale sera comprise entre 1,17 et 2,26 mg% inclus.
Exemple 3.3 . Parmi les 1000 graines de blé du lot reçu au silo, 120 graines ont été trouvées infectées par l'ergot. Il est nécessaire de déterminer les limites probables de la proportion générale de graines infectées dans un lot de blé donné.
Il convient de déterminer les limites de confiance de la part générale pour toutes ses valeurs possibles à l'aide de la formule :
 ,
,
Où n – nombre d'observations ; m– taille absolue de l'un des groupes ; t– écart normalisé.
La proportion de l'échantillon de graines infectées est  ou 12%. Avec probabilité de confiance R.= 95 % d'écart normalisé ( t-Test de l'étudiant à k
=
ou 12%. Avec probabilité de confiance R.= 95 % d'écart normalisé ( t-Test de l'étudiant à k
=
 )t
= 1,960.
)t
= 1,960.
Nous substituons les données disponibles dans la formule :
Les limites de l’intervalle de confiance sont donc égales à  = 0,122-0,041 = 0,081, soit 8,1 % ;
= 0,122-0,041 = 0,081, soit 8,1 % ;  = 0,122 + 0,041 = 0,163, soit 16,3 %.
= 0,122 + 0,041 = 0,163, soit 16,3 %.
Ainsi, avec une probabilité de confiance de 95 %, on peut affirmer que la proportion générale de semences infectées se situe entre 8,1 et 16,3 %.
Exemple 3.4 . Le coefficient de variation caractérisant la variation du calcium (mg%) dans le sérum sanguin des singes était égal à 10,6 %. Taille de l'échantillon n= 100. Il est nécessaire de déterminer les limites de l'intervalle de confiance à 95 % pour le paramètre général CV.
Limites de l'intervalle de confiance pour le coefficient de variation général CV sont déterminés par les formules suivantes :
 Et
Et  , Où K
valeur intermédiaire calculée par la formule
, Où K
valeur intermédiaire calculée par la formule  .
.
Sachant cela avec une probabilité de confiance R.= 95 % d'écart normalisé (test de Student à k
=
 )t
= 1,960, calculons d'abord la valeur À:
)t
= 1,960, calculons d'abord la valeur À:
 .
.
 ou 9,3%
ou 9,3%
 soit 12,3%
soit 12,3%
Ainsi, le coefficient de variation général avec un niveau de confiance de 95 % se situe entre 9,3 et 12,3 %. Avec des prélèvements répétés, le coefficient de variation ne dépassera pas 12,3% et ne sera pas inférieur à 9,3% dans 95 cas sur 100.
Questions pour la maîtrise de soi :

Problèmes pour une solution indépendante.
1. Le pourcentage moyen de matière grasse dans le lait pendant la lactation des vaches croisées Kholmogory était le suivant : 3,4 ; 3.6 ; 3.2 ; 3.1 ; 2,9 ; 3,7 ; 3.2 ; 3.6 ; 4,0 ; 3.4 ; 4.1 ; 3,8 ; 3.4 ; 4,0 ; 3.3 ; 3,7 ; 3,5 ; 3.6 ; 3.4 ; 3.8. Établissez des intervalles de confiance pour la moyenne générale à un niveau de confiance de 95 % (20 points).
2. Sur 400 plants de seigle hybrides, les premières fleurs sont apparues en moyenne 70,5 jours après le semis. L'écart type était de 6,9 jours. Déterminer l'erreur de la moyenne et les intervalles de confiance pour la moyenne générale et la variance au niveau de signification W= 0,05 et W= 0,01 (25 points).
3. Lors de l'étude de la longueur des feuilles de 502 spécimens de fraises de jardin, les données suivantes ont été obtenues :
 = 7,86 cm ; σ = 1,32 cm,
= 7,86 cm ; σ = 1,32 cm,  = ± 0,06 cm. Déterminer les intervalles de confiance pour la moyenne arithmétique de la population avec des niveaux de signification de 0,01 ; 0,02 ; 0,05. (25points).
= ± 0,06 cm. Déterminer les intervalles de confiance pour la moyenne arithmétique de la population avec des niveaux de signification de 0,01 ; 0,02 ; 0,05. (25points).
4. Dans une étude portant sur 150 hommes adultes, la taille moyenne était de 167 cm et σ = 6 cm. Quelles sont les limites de la moyenne générale et de la variance générale avec une probabilité de confiance de 0,99 et 0,95 ? (25points).
5. La répartition du calcium dans le sérum sanguin des singes est caractérisée par les indicateurs sélectifs suivants :
 = 11,94 mg%, σ
= 1,27, n
= 100. Construisez un intervalle de confiance à 95 % pour la moyenne générale de cette distribution. Calculez le coefficient de variation (25 points).
= 11,94 mg%, σ
= 1,27, n
= 100. Construisez un intervalle de confiance à 95 % pour la moyenne générale de cette distribution. Calculez le coefficient de variation (25 points).
6. La teneur totale en azote du plasma sanguin de rats albinos âgés de 37 et 180 jours a été étudiée. Les résultats sont exprimés en grammes pour 100 cm 3 de plasma. A l'âge de 37 jours, 9 rats avaient : 0,98 ; 0,83 ; 0,99 ; 0,86 ; 0,90 ; 0,81 ; 0,94 ; 0,92 ; 0,87. A l'âge de 180 jours, 8 rats avaient : 1,20 ; 1,18 ; 1,33 ; 1,21 ; 1,20 ; 1,07 ; 1,13 ; 1.12. Définissez des intervalles de confiance pour la différence à un niveau de confiance de 0,95 (50 points).
7. Déterminer les limites de l'intervalle de confiance à 95 % pour la variance générale de la distribution du calcium (mg %) dans le sérum sanguin des singes, si pour cette distribution la taille de l'échantillon est n = 100, erreur statistique de la variance de l'échantillon s σ 2 = 1,60 (40 points).
8. Déterminez les limites de l'intervalle de confiance à 95 % pour la variance générale de la distribution de 40 épillets de blé sur la longueur (σ 2 = 40,87 mm 2). (25points).
9. Le tabagisme est considéré comme le principal facteur prédisposant aux maladies pulmonaires obstructives. Le tabagisme passif n’est pas considéré comme un tel facteur. Les scientifiques ont douté de l'innocuité du tabagisme passif et ont examiné la perméabilité des voies respiratoires des non-fumeurs, des fumeurs passifs et actifs. Pour caractériser l'état des voies respiratoires, nous avons pris l'un des indicateurs de la fonction respiratoire externe - le débit volumétrique maximum à mi-expiration. Une diminution de cet indicateur est un signe d'obstruction des voies respiratoires. Les données de l'enquête sont présentées dans le tableau.
|
Nombre de personnes examinées |
Débit mi-expiratoire maximum, l/s |
||
|
Écart type |
|||
|
Non-fumeurs |
|||
|
travailler dans un espace non-fumeur | |||
|
travailler dans une pièce enfumée | |||
|
Fumeur |
|||
|
fumer un petit nombre de cigarettes | |||
|
nombre moyen de fumeurs de cigarettes | |||
|
fumer un grand nombre de cigarettes | |||
À l’aide des données du tableau, trouvez des intervalles de confiance à 95 % pour la moyenne globale et la variance globale de chaque groupe. Quelles sont les différences entre les groupes ? Présentez les résultats graphiquement (25 points).
10. Déterminer les limites des intervalles de confiance à 95 % et 99 % pour la variance générale du nombre de porcelets dans 64 mises bas, si l'erreur statistique de la variance de l'échantillon s σ 2 = 8,25 (30 points).
11. On sait que le poids moyen des lapins est de 2,1 kg. Déterminer les limites des intervalles de confiance à 95 % et 99 % pour la moyenne générale et la variance à n= 30, σ = 0,56 kg (25 points).
12. La teneur en grains de l'épi a été mesurée pour 100 épis ( X), longueur de l'oreille ( Oui) et la masse de grain dans l'épi ( Z). Trouver des intervalles de confiance pour la moyenne générale et la variance à P. 1
= 0,95, P. 2
= 0,99, P. 3
= 0,999 si
 = 19, = 6,766 cm, = 0,554 g ; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 points).
= 19, = 6,766 cm, = 0,554 g ; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 points).
13. Dans 100 épis de blé d'hiver sélectionnés au hasard, le nombre d'épillets a été compté. La population échantillonnée était caractérisée par les indicateurs suivants :
 = 15 épillets et σ = 2,28 pcs. Déterminer avec quelle précision le résultat moyen a été obtenu (
= 15 épillets et σ = 2,28 pcs. Déterminer avec quelle précision le résultat moyen a été obtenu (  ) et construisez un intervalle de confiance pour la moyenne générale et la variance aux niveaux de signification de 95 % et 99 % (30 points).
) et construisez un intervalle de confiance pour la moyenne générale et la variance aux niveaux de signification de 95 % et 99 % (30 points).
14. Nombre de côtes sur les coquilles de mollusques fossiles Orthobonites calligramme:
On sait que n = 19, σ = 4,25. Déterminer les limites de l'intervalle de confiance pour la moyenne générale et la variance générale au niveau de signification W = 0,01 (25 points).
15. Pour déterminer le rendement laitier dans une ferme laitière commerciale, la productivité de 15 vaches a été déterminée quotidiennement. Selon les données de l'année, chaque vache a donné en moyenne la quantité de lait suivante par jour (l) : 22 ; 19 ; 25 ; 20 ; 27 ; 17 ; 30 ; 21 ; 18 ; 24 ; 26 ; 23 ; 25 ; 20 ; 24. Construisez des intervalles de confiance pour la variance générale et la moyenne arithmétique. Peut-on s’attendre à ce que la production annuelle moyenne de lait par vache soit de 10 000 litres ? (50points).
16. Afin de déterminer le rendement moyen en blé de l'entreprise agricole, le fauchage a été effectué sur des parcelles d'essai de 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 et 2 hectares. La productivité (c/ha) des parcelles était de 39,4 ; 38 ; 35,8 ; 40 ; 35 ; 42,7 ; 39,3 ; 41,6 ; 33 ; 42 ; 29 respectivement. Construisez des intervalles de confiance pour la variance générale et la moyenne arithmétique. Peut-on espérer que le rendement agricole moyen soit de 42 c/ha ? (50points).







