Dans cette note, la distribution χ 2 est utilisée pour tester la cohérence d'un ensemble de données avec une distribution de probabilité fixe. Le critère d’accord est souvent Ô Votre appartenance à une catégorie particulière est comparée aux fréquences théoriquement attendues si les données avaient réellement la distribution spécifiée.
Les tests utilisant le critère d'adéquation χ 2 sont effectués en plusieurs étapes. Tout d’abord, une distribution de probabilité spécifique est déterminée et comparée aux données originales. Deuxièmement, une hypothèse est émise sur les paramètres de la distribution de probabilité sélectionnée (par exemple, son espérance mathématique) ou leur évaluation est effectuée. Troisièmement, sur la base de la distribution théorique, la probabilité théorique correspondant à chaque catégorie est déterminée. Enfin, la statistique du test χ2 est utilisée pour vérifier la cohérence des données et de la distribution :
Où f 0- fréquence observée, f e- fréquence théorique ou attendue, k- nombre de catégories restantes après fusion, r- nombre de paramètres à estimer.
Téléchargez la note au format ou, exemples au format
Utilisation du test d'adéquation χ2 pour la distribution de Poisson

Pour calculer à l'aide de cette formule dans Excel, il est pratique d'utiliser la fonction =SUMPRODUCT() (Fig. 1).
Pour estimer le paramètre λ vous pouvez utiliser l'estimation . Fréquence théorique X succès (X = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 et plus) correspondant au paramètre λ = 2,9 peut être déterminé à l’aide de la fonction =POISSON.DIST(X;;FALSE). Multiplier la probabilité de Poisson par la taille de l'échantillon n, on obtient la fréquence théorique f e(Fig.2).

Riz. 2. Taux d'arrivée réels et théoriques par minute
Comme il ressort de la Fig. 2, la fréquence théorique de neuf arrivées ou plus ne dépasse pas 1,0. Pour garantir que chaque catégorie contient une fréquence de 1,0 ou plus, la catégorie « 9 ou plus » doit être combinée avec la catégorie « 8 ». Autrement dit, il reste neuf catégories (0, 1, 2, 3, 4, 5, 6, 7, 8 et plus). Puisque l’espérance mathématique de la distribution de Poisson est déterminée sur la base d’échantillons de données, le nombre de degrés de liberté est égal à k – p – 1 = 9 – 1 – 1 = 7. En utilisant un niveau de signification de 0,05, nous trouvons la valeur critique des statistiques χ 2, qui a 7 degrés de liberté selon la formule =CHI2.OBR(1-0,05;7) = 14,067. La règle de décision est formulée comme suit : hypothèse H 0 est rejetée si χ 2 > 14,067, sinon l'hypothèse H 0 ne s'écarte pas.
Pour calculer χ 2, nous utilisons la formule (1) (Fig. 3).

Riz. 3. Calcul du critère d'adéquation χ 2 pour la distribution de Poisson
Puisque χ 2 = 2,277< 14,067, следует, что гипотезу H 0 ne peut être rejeté. En d’autres termes, nous n’avons aucune raison d’affirmer que l’arrivée des clients à la banque n’obéit pas à la distribution de Poisson.
Application du test d'adéquation du χ 2 pour une distribution normale
Dans les notes précédentes, lors du test des hypothèses sur les variables numériques, nous avons supposé que la population étudiée était normalement distribuée. Pour vérifier cette hypothèse, vous pouvez utiliser des outils graphiques, par exemple une boîte à moustaches ou un graphique de distribution normale (pour plus de détails, voir). Pour les échantillons de grande taille, le test d'ajustement χ 2 pour une distribution normale peut être utilisé pour tester ces hypothèses.
Considérons, à titre d'exemple, les données sur les rendements sur 5 ans de 158 fonds d'investissement (Fig. 4). Supposons que vous souhaitiez savoir si les données sont normalement distribuées. Les hypothèses nulles et alternatives sont formulées comme suit : H 0: le rendement à 5 ans suit une distribution normale, H1: Le rendement à 5 ans ne suit pas une distribution normale. La distribution normale a deux paramètres : l'espérance mathématique μ et l'écart type σ, qui peuvent être estimés sur la base de données d'échantillon. Dans ce cas = 10,149 et S = 4,773.

Riz. 4. Un tableau ordonné contenant des données sur le rendement annuel moyen sur cinq ans de 158 fonds
Les données sur les rendements des fonds peuvent par exemple être regroupées en classes (intervalles) d'une largeur de 5 % (Fig. 5).

Riz. 5. Distribution de fréquence pour les rendements annuels moyens sur cinq ans de 158 fonds
La distribution normale étant continue, il est nécessaire de déterminer l'aire des figures délimitée par la courbe de distribution normale et les limites de chaque intervalle. De plus, puisque la distribution normale s'étend théoriquement de –∞ à +∞, il est nécessaire de prendre en compte l'aire des formes en dehors des limites de classe. Ainsi, l'aire sous la courbe normale à gauche du point –10 est égale à l'aire de la figure située sous la courbe normale normalisée à gauche de la valeur Z égale à
Z = (–10 – 10,149) / 4,773 = –4,22
L'aire de la figure située sous la courbe normale normalisée à gauche de la valeur Z = –4,22 est déterminée par la formule =NORM.DIST(-10;10.149;4.773;TRUE) et est approximativement égale à 0,00001. Afin de calculer l'aire de la figure située sous la courbe normale entre les points –10 et –5, vous devez d'abord calculer l'aire de la figure située à gauche du point –5 : =NORM.DIST( -5,10.149,4.773,VRAI) = 0.00075 . Ainsi, l'aire de la figure située sous la courbe normale entre les points –10 et –5 est 0,00075 – 0,00001 = 0,00074. De même, vous pouvez calculer l'aire de la figure limitée par les limites de chaque classe (Fig. 6).

Riz. 6. Zones et fréquences attendues pour chaque classe de retours sur 5 ans
On peut voir que les fréquences théoriques dans les quatre classes extrêmes (deux minimum et deux maximum) sont inférieures à 1, nous allons donc combiner les classes, comme le montre la figure 7.

Riz. 7. Calculs associés à l'utilisation du test d'adéquation χ 2 pour la distribution normale
Nous utilisons le test χ 2 pour vérifier l'accord entre les données et la distribution normale en utilisant la formule (1). Dans notre exemple, après la fusion, il reste six classes. Puisque la valeur attendue et l’écart type sont estimés à partir de données d’échantillon, le nombre de degrés de liberté est k – p – 1 = 6 – 2 – 1 = 3. En utilisant un niveau de signification de 0,05, nous constatons que la valeur critique des statistiques χ 2, qui a trois degrés de liberté = CI2.OBR(1-0,05;F3) = 7,815. Les calculs associés à l'utilisation du critère d'adéquation χ 2 sont présentés dans la Fig. 7.
On peut voir que χ 2 -statistique = 3,964< χ U 2 7,815, следовательно гипотезу H 0 ne peut être rejeté. En d’autres termes, nous n’avons aucune base permettant d’affirmer que les rendements sur 5 ans des fonds d’investissement axés sur une forte croissance ne sont pas soumis à une distribution normale.
Plusieurs articles récents ont exploré différentes approches d’analyse des données catégorielles. L'invention concerne des méthodes permettant de tester des hypothèses sur des données catégorielles obtenues à partir de l'analyse de deux échantillons indépendants ou plus. En plus des tests du chi carré, des procédures non paramétriques sont prises en compte. Le test de rang de Wilcoxon est décrit, qui est utilisé dans les situations où les conditions d'application ne sont pas remplies. t-des critères pour tester l'hypothèse d'égalité des attentes mathématiques de deux groupes indépendants, ainsi que le test de Kruskal-Wallis, qui est une alternative à l'analyse de variance à un facteur (Fig. 8).

Riz. 8. Schéma fonctionnel des méthodes de test des hypothèses sur les données catégorielles
Des documents du livre Levin et al. Statistics for Managers sont utilisés. – M. : Williams, 2004. – p. 763-769
Distribution. Distribution de Pearson Densité de probabilité ... Wikipédia
distribution du chi carré- distribution du chi carré - Sujets protection de l'information FR distribution du chi carré ... Guide du traducteur technique
distribution du chi carré- Distribution de probabilité d'une variable aléatoire continue de valeurs de 0 à, dont la densité est donnée par la formule, où 0 pour paramètre =1,2,... ; – fonction gamma. Exemples. 1) Somme des carrés aléatoires normalisés indépendants... ... Dictionnaire de statistiques sociologiques
DISTRIBUTION DU CHI CARRÉ (chi2)- Distribution d'une variable aléatoire chi2. Si des échantillons aléatoires de taille 1 sont issus d'une distribution normale de moyenne (et de variance q2, alors chi2 = (X1 u)2/q2, où X est la valeur échantillonnée. Si la taille de l'échantillon est augmenté de manière aléatoire jusqu'à N, alors chi2 = … …
Densité de probabilité ... Wikipédia
- (Distribution Snedecor) Densité de probabilité... Wikipédia
Distribution de Fisher Densité de probabilité Fonction de distribution Paramètres d'un nombre avec ... Wikipedia
L'un des concepts de base de la théorie des probabilités et des statistiques mathématiques. Avec l'approche moderne, en tant que mathématique modèle du phénomène aléatoire étudié, l'espace de probabilité correspondant (W, S, P) est pris, où W est un ensemble de éléments élémentaires... Encyclopédie mathématique
Distribution gamma Densité de probabilité Fonction de distribution Paramètres ... Wikipédia
RÉPARTITION F- Distribution de probabilité théorique d'une variable aléatoire F. Si des échantillons aléatoires de taille N sont tirés indépendamment d'une population normale, chacun génère une distribution du Chi carré avec un degré de liberté = N. Le rapport de deux de ces... ... Dictionnaire explicatif de la psychologie
Livres
- Théorie des probabilités et statistiques mathématiques en problèmes : Plus de 360 problèmes et exercices, D. Borzykh Le manuel proposé contient des problèmes de différents niveaux de complexité. Cependant, l'accent est mis sur les tâches de complexité moyenne. Ceci est fait intentionnellement pour encourager les étudiants à...
- Théorie des probabilités et statistiques mathématiques dans les problèmes. Plus de 360 tâches et exercices, Borzykh D.A.. Le manuel proposé contient des tâches de différents niveaux de complexité. Cependant, l'accent est mis sur les tâches de complexité moyenne. Ceci est fait intentionnellement pour encourager les étudiants à...
Si la valeur obtenue du critère χ 2 est supérieure à la valeur critique, nous concluons qu'il existe une relation statistique entre le facteur de risque étudié et le résultat au niveau de signification approprié.
Exemple de calcul du test du Chi carré de Pearson
Déterminons la signification statistique de l'influence du facteur tabagisme sur l'incidence de l'hypertension artérielle à l'aide du tableau discuté ci-dessus :
1. Calculez les valeurs attendues pour chaque cellule :
2. Trouvez la valeur du test du chi carré de Pearson :
χ 2 = (40-33,6) 2 /33,6 + (30-36,4) 2 /36,4 + (32-38,4) 2 /38,4 + (48-41,6) 2 /41,6 = 4,396.
3. Nombre de degrés de liberté f = (2-1)*(2-1) = 1. À l'aide du tableau, nous trouvons la valeur critique du test du chi carré de Pearson, qui au niveau de signification p=0,05 et le le nombre de degrés de liberté 1 est 3,841.
4. Nous comparons la valeur obtenue du test du chi carré avec la valeur critique : 4,396 > 3,841, par conséquent, la dépendance de l'incidence de l'hypertension artérielle sur la présence de tabagisme est statistiquement significative. Le niveau de signification de cette relation correspond à p<0.05.
De plus, le test du Chi carré de Pearson est calculé à l'aide de la formule
Mais pour un tableau 2x2, des résultats plus précis sont obtenus par le critère de correction de Yates

Si  Que N(0) accepté,
Que N(0) accepté,
Au cas où ![]() accepté H(1)
accepté H(1)
Lorsque le nombre d'observations est faible et que les cellules du tableau contiennent une fréquence inférieure à 5, le test du chi carré n'est pas applicable et est utilisé pour tester des hypothèses. Test exact de Fisher . La procédure de calcul de ce critère demande beaucoup de travail et, dans ce cas, il est préférable d'utiliser des programmes informatiques d'analyse statistique.
À l'aide du tableau de contingence, vous pouvez calculer la mesure du lien entre deux caractéristiques qualitatives - c'est le coefficient d'association de Noël Q (analogue au coefficient de corrélation)

Q est compris entre 0 et 1. Un coefficient proche de un indique un lien fort entre les caractéristiques. S'il est égal à zéro, il n'y a pas de connexion .
Le coefficient phi carré (φ 2) est utilisé de la même manière
TÂCHE DE RÉFÉRENCE
Le tableau décrit la relation entre la fréquence de mutation dans les groupes de drosophiles avec et sans alimentation.
Analyse du tableau de contingence
Pour analyser le tableau de contingence, une hypothèse H 0 est avancée, c'est-à-dire l'absence d'influence de la caractéristique étudiée sur le résultat de l'étude. Pour cela, la fréquence attendue est calculée et un tableau d'espérance est construit.
Table d'attente
| groupes | Cultures Chilo | Total | ||||
| A donné des mutations | N'a pas donné de mutations | |||||
| Fréquence réelle | Fréquence attendue | Fréquence réelle | Fréquence attendue | |||
| Avec alimentation | ||||||
| Sans alimentation | ||||||
| total | ||||||
Méthode n°1
Déterminez la fréquence d’attente :
2756-X ![]() ;
;
2. 3561 – 3124
Si le nombre d'observations dans les groupes est faible, lors de l'utilisation de X 2, dans le cas de la comparaison des fréquences réelles et attendues pour des distributions discrètes, une certaine inexactitude est associée. Pour réduire l'inexactitude, la correction de Yates est utilisée.
Jusqu'à la fin du XIXe siècle, la distribution normale était considérée comme la loi universelle de variation des données. Cependant, K. Pearson a noté que les fréquences empiriques peuvent différer considérablement de la distribution normale. La question s'est posée de savoir comment le prouver. Il fallait non seulement une comparaison graphique, subjective, mais aussi une justification quantitative stricte.
C'est ainsi qu'a été inventé le critère χ 2(chi carré), qui teste la signification de la différence entre les fréquences empiriques (observées) et théoriques (attendues). Cela s'est produit en 1900, mais ce critère est toujours utilisé aujourd'hui. De plus, il a été adapté pour résoudre un large éventail de problèmes. Il s'agit tout d'abord de l'analyse des données nominales, c'est-à-dire ceux qui s'expriment non pas par la quantité, mais par l'appartenance à une catégorie. Par exemple, la classe de la voiture, le sexe du participant à l'expérience, le type d'installation, etc. Les opérations mathématiques telles que l'addition et la multiplication ne peuvent pas être appliquées à de telles données ; elles ne peuvent être calculées que pour elles.
Nous notons les fréquences observées À propos (Observé), attendu - E (attendu). A titre d'exemple, prenons le résultat de lancer un dé 60 fois. S'il est symétrique et uniforme, la probabilité d'obtenir n'importe quel côté est de 1/6 et donc le nombre attendu d'obtenir chaque côté est de 10 (1/6∙60). Nous écrivons les fréquences observées et attendues dans un tableau et dessinons un histogramme.
L’hypothèse nulle est que les fréquences sont cohérentes, c’est-à-dire que les données réelles ne contredisent pas les données attendues. Une autre hypothèse est que les écarts de fréquence vont au-delà des fluctuations aléatoires, c'est-à-dire que les écarts sont statistiquement significatifs. Pour tirer une conclusion rigoureuse, il nous faut.
- Une mesure récapitulative de l’écart entre les fréquences observées et attendues.
- La distribution de cette mesure si l'hypothèse selon laquelle il n'y a pas de différences est vraie.
Commençons par la distance entre les fréquences. Si tu prends juste la différence O-E, alors une telle mesure dépendra de l'échelle des données (fréquences). Par exemple, 20 - 5 = 15 et 1020 - 1005 = 15. Dans les deux cas, la différence est de 15. Mais dans le premier cas, les fréquences attendues sont 3 fois inférieures à celles observées, et dans le second cas - seulement 1,5 %. Nous avons besoin d’une mesure relative qui ne dépend pas de l’échelle.
Faisons attention aux faits suivants. En général, le nombre de gradations dans lesquelles les fréquences sont mesurées peut être beaucoup plus grand, de sorte que la probabilité qu'une seule observation tombe dans une catégorie ou une autre est assez faible. Si tel est le cas, alors la distribution d’une telle variable aléatoire obéira à la loi des événements rares, connue sous le nom de loi de Poisson. Dans la loi de Poisson, comme on le sait, la valeur de l'espérance mathématique et de la variance coïncident (paramètre λ ). Cela signifie que la fréquence attendue pour certaines catégories de la variable nominale E je sera simultanée et sa dispersion. De plus, la loi de Poisson tend à se normaliser avec un grand nombre d'observations. En combinant ces deux faits, nous obtenons que si l’hypothèse sur l’accord entre les fréquences observées et attendues est correcte, alors, avec un grand nombre d'observations, expression
Aurai.
Il est important de se rappeler que la normalité n’apparaîtra qu’à des fréquences suffisamment élevées. En statistiques, il est généralement admis que le nombre total d'observations (somme des fréquences) doit être d'au moins 50 et que la fréquence attendue dans chaque gradation doit être d'au moins 5. Seulement dans ce cas, la valeur indiquée ci-dessus aura une norme normale distribution. Supposons que cette condition soit remplie.
La distribution normale standard a presque toutes les valeurs comprises entre ±3 (la règle des trois sigma). Ainsi, nous avons obtenu la différence relative des fréquences pour une gradation. Nous avons besoin d’une mesure généralisable. Vous ne pouvez pas simplement additionner tous les écarts - nous obtenons 0 (devinez pourquoi). Pearson a proposé d'additionner les carrés de ces écarts.
![]()
C'est le signe critère χ 2 Pearson. Si les fréquences correspondent réellement à celles attendues, alors la valeur du critère sera relativement faible (puisque la plupart des écarts sont autour de zéro). Mais si le critère s'avère large, cela indique des différences significatives entre les fréquences.
Le critère devient « grand » lorsque l’occurrence d’une valeur telle ou même supérieure devient improbable. Et pour calculer une telle probabilité, il faut connaître la distribution du critère lorsque l'expérience est répétée plusieurs fois, lorsque l'hypothèse d'accord de fréquence est correcte.
Comme il est facile de le constater, la valeur du chi carré dépend également du nombre de termes. Plus il y en a, plus le critère doit avoir de valeur, car chaque terme contribuera au total. Donc pour chaque quantité indépendant termes, il y aura sa propre distribution. Il s'avère que χ 2 est toute une famille de distributions.
Et nous arrivons ici à un moment délicat. Qu'est-ce qu'un nombre indépendant termes? Il semble que tout terme (c'est-à-dire l'écart) soit indépendant. K. Pearson le pensait également, mais il s'est avéré qu'il avait tort. En fait, le nombre de termes indépendants sera inférieur d'un au nombre de gradations de la variable nominale n. Pourquoi? Parce que si nous avons un échantillon pour lequel la somme des fréquences a déjà été calculée, alors l'une des fréquences peut toujours être déterminée comme la différence entre le nombre total et la somme de toutes les autres. La variation sera donc un peu moindre. Ronald Fisher a remarqué ce fait 20 ans après que Pearson ait développé son critère. Même les tables ont dû être refaites.
A cette occasion, Fisher a introduit un nouveau concept dans les statistiques - degré de liberté(degrés de liberté), qui représente le nombre de termes indépendants dans la somme. Le concept de degrés de liberté a une explication mathématique et n'apparaît que dans les distributions associées à la normale (Student, Fisher-Snedecor et le chi carré lui-même).
Pour mieux comprendre la signification des degrés de liberté, tournons-nous vers un analogue physique. Imaginons un point se déplaçant librement dans l'espace. Il a 3 degrés de liberté, car peut se déplacer dans n’importe quelle direction dans un espace tridimensionnel. Si un point se déplace le long d'une surface, il possède déjà deux degrés de liberté (avant et arrière, gauche et droite), bien qu'il continue de se trouver dans un espace tridimensionnel. Un point se déplaçant le long d'un ressort se trouve à nouveau dans un espace tridimensionnel, mais n'a qu'un seul degré de liberté, car peut avancer ou reculer. Comme vous pouvez le constater, l’espace où se trouve l’objet ne correspond pas toujours à une réelle liberté de mouvement.
De la même manière, la distribution d'un critère statistique peut dépendre d'un nombre d'éléments inférieur au nombre de termes nécessaires à son calcul. En général, le nombre de degrés de liberté est inférieur au nombre d'observations par le nombre de dépendances existantes. Ce sont des mathématiques pures, pas de magie.
Donc la répartition χ 2 est une famille de distributions dont chacune dépend du paramètre des degrés de liberté. Et la définition formelle du test du chi carré est la suivante. Distribution χ 2(chi carré) s k les degrés de liberté sont la distribution de la somme des carrés k variables aléatoires normales standard indépendantes.
Ensuite, nous pourrions passer à la formule elle-même, qui calcule la fonction de distribution du chi carré, mais heureusement, tout est calculé pour nous depuis longtemps. Pour obtenir la probabilité d'intérêt, vous pouvez utiliser soit le tableau statistique correspondant, soit une fonction toute prête dans un logiciel spécialisé, disponible même dans Excel.
Il est intéressant de voir comment la forme de la distribution du Chi carré change en fonction du nombre de degrés de liberté.

Avec des degrés de liberté croissants, la distribution du chi carré tend à être normale. Ceci s'explique par l'action du théorème central limite, selon lequel la somme d'un grand nombre de variables aléatoires indépendantes a une distribution normale. Cela ne dit rien sur les carrés)).
Test d'hypothèse à l'aide du test du chi carré
Nous arrivons maintenant à tester des hypothèses en utilisant la méthode du chi carré. En général, la technologie demeure. L’hypothèse nulle est que les fréquences observées correspondent à celles attendues (c’est-à-dire qu’il n’y a pas de différence entre elles car elles sont issues de la même population). Si tel est le cas, la dispersion sera relativement faible, dans la limite de fluctuations aléatoires. La mesure de dispersion est déterminée à l’aide du test du chi carré. Ensuite, soit le critère lui-même est comparé à la valeur critique (pour le niveau de signification et les degrés de liberté correspondants), soit, ce qui est plus correct, le niveau p observé est calculé, c'est-à-dire la probabilité d'obtenir une valeur de critère identique, voire supérieure, si l'hypothèse nulle est vraie.

Parce que on s'intéresse à l'accord des fréquences, alors l'hypothèse sera rejetée lorsque le critère est supérieur au niveau critique. Ceux. le critère est unilatéral. Cependant, il est parfois (parfois) nécessaire de tester l’hypothèse de gauche. Par exemple, lorsque les données empiriques sont très similaires aux données théoriques. Le critère peut alors tomber dans une région improbable, mais à gauche. Le fait est que dans des conditions naturelles, il est peu probable d’obtenir des fréquences qui coïncident pratiquement avec celles théoriques. Il y a toujours une part de hasard qui donne lieu à une erreur. Mais s’il n’y a pas d’erreur de ce type, les données ont peut-être été falsifiées. Néanmoins, l’hypothèse du côté droit est généralement testée.
Revenons au problème des dés. Calculons la valeur du test du chi carré en utilisant les données disponibles.
Trouvons maintenant la valeur tabulaire du critère à 5 degrés de liberté ( k) et niveau de signification 0,05 ( α ).

C'est χ 2 0,05 ; 5 = 11,1.
Comparons les valeurs réelles et tabulées. 3.4 ( χ 2) < 11,1 (χ 2 0,05 ; 5). Le critère calculé s'est avéré plus petit, ce qui signifie que l'hypothèse d'égalité (accord) des fréquences n'est pas rejetée. Sur la figure, la situation ressemble à ceci.

Si la valeur calculée se situe dans la région critique, l’hypothèse nulle serait rejetée.
Il serait plus correct de calculer également le niveau p. Pour ce faire, vous devez trouver dans le tableau la valeur la plus proche pour un nombre de degrés de liberté donné et regarder le niveau de signification correspondant. Mais nous sommes au siècle dernier. Nous utiliserons un ordinateur personnel, notamment MS Excel. Excel a plusieurs fonctions liées au chi carré.

Vous en trouverez ci-dessous une brève description.
CH2.OBR– valeur critique du critère à une probabilité donnée à gauche (comme dans les tableaux statistiques)
CH2.OBR.PH– valeur critique du critère pour une probabilité donnée à droite. La fonction duplique essentiellement la précédente. Mais ici vous pouvez immédiatement indiquer le niveau α , plutôt que de le soustraire de 1. C'est plus pratique, car dans la plupart des cas, c'est la queue droite de la distribution qui est nécessaire.
CH2.DIST– niveau p à gauche (la densité peut être calculée).
CH2.DIST.PH– niveau p à droite.
CHI2.TEST– effectue immédiatement un test du chi carré pour deux plages de fréquences données. Le nombre de degrés de liberté est considéré comme étant inférieur de un au nombre de fréquences dans la colonne (comme il se doit), renvoyant la valeur du niveau p.
Calculons pour notre expérience la valeur critique (tabulaire) pour 5 degrés de liberté et alpha 0,05. La formule Excel ressemblera à ceci :
CH2.OBR(0,95;5)
CH2.OBR.PH(0,05;5)
Le résultat sera le même - 11.0705. C'est la valeur que l'on voit dans le tableau (arrondie à 1 décimale).
Calculons enfin le niveau p pour le critère de 5 degrés de liberté χ 2= 3,4. Nous avons besoin d'une probabilité à droite, nous prenons donc une fonction avec l'ajout de HH (queue droite)
CH2.DIST.PH(3,4;5) = 0,63857
Cela signifie qu'avec 5 degrés de liberté, la probabilité d'obtenir la valeur du critère est χ 2= 3,4 et plus équivaut à près de 64 %. Bien entendu, l’hypothèse n’est pas rejetée (p-level supérieur à 5 %), les fréquences sont en très bon accord.
Vérifions maintenant l'hypothèse sur l'accord de fréquence à l'aide de la fonction CH2.TEST.

Pas de tableaux, pas de calculs fastidieux. En spécifiant des colonnes avec des fréquences observées et attendues comme arguments de fonction, nous obtenons immédiatement le niveau p. Beauté.
Imaginez maintenant que vous jouez aux dés avec un type suspect. La répartition des points de 1 à 5 reste la même, mais il obtient 26 six (le nombre total de lancers devient 78).

Dans ce cas, le niveau P s'avère être de 0,003, ce qui est bien inférieur à 0,05. Il y a de bonnes raisons de douter de la validité des dés. Voici à quoi ressemble cette probabilité sur un graphique de distribution du chi carré.

Le critère du chi carré lui-même s'avère ici être de 17,8, ce qui est naturellement supérieur à celui du tableau (11.1).
J'espère avoir pu expliquer quel est le critère d'accord χ 2(Chi carré de Pearson) et comment il peut être utilisé pour tester des hypothèses statistiques.
Enfin, encore une fois sur une condition importante ! Le test du Chi carré ne fonctionne correctement que lorsque le nombre de toutes les fréquences dépasse 50 et que la valeur minimale attendue pour chaque gradation n'est pas inférieure à 5. Si dans une catégorie, la fréquence attendue est inférieure à 5, mais que la somme de toutes les fréquences dépasse 50, alors cette catégorie est combinée avec la plus proche afin que leur fréquence totale dépasse 5. Si cela n'est pas possible ou si la somme des fréquences est inférieure à 50, des méthodes plus précises pour tester les hypothèses doivent être utilisées. Nous en reparlerons une autre fois.
Vous trouverez ci-dessous une vidéo expliquant comment tester une hypothèse dans Excel à l'aide du test du chi carré.
Considérez la candidature dansMSEXCELLERTest du chi carré de Pearson pour tester des hypothèses simples.
Après avoir obtenu des données expérimentales (c'est-à-dire lorsqu'il existe des échantillon) on choisit généralement la loi de distribution qui décrit le mieux la variable aléatoire représentée par un échantillonnage. La vérification de la qualité de la description des données expérimentales par la loi de distribution théorique sélectionnée est effectuée à l'aide de critères d'accord. Hypothèse nulle, il existe généralement une hypothèse sur l'égalité de la distribution d'une variable aléatoire avec une loi théorique.
Regardons d'abord l'application Test d'adéquation de Pearson X 2 (chi carré) par rapport à des hypothèses simples (les paramètres de la distribution théorique sont considérés comme connus). Puis - , lorsque seule la forme de la distribution est précisée, et les paramètres de cette distribution et la valeur statistiques X2 sont évalués/calculés sur la base des mêmes échantillons.
Note: Dans la littérature anglophone, la procédure de candidature Test d'adéquation de Pearson X2 a un nom Le test d'ajustement du chi carré.
Rappelons la procédure de test des hypothèses :
- basé sur échantillons la valeur est calculée statistiques, ce qui correspond au type d’hypothèse testée. Par exemple, pour utilisé t-statistiques(si inconnu);
- soumis à la vérité hypothèse nulle, la répartition de ce statistiques est connu et peut être utilisé pour calculer des probabilités (par exemple, pour t-statistiques Ce );
- calculé sur la base échantillons signification statistiques par rapport à la valeur critique pour une valeur donnée ();
- hypothèse nulle rejeter si valeur statistiques supérieure à critique (ou si la probabilité d'obtenir cette valeur statistiques() moins niveau de signification, ce qui est une approche équivalente).
Réalisons test d'hypothèse pour diverses distributions.
Boîtier discret
Supposons que deux personnes jouent aux dés. Chaque joueur possède son propre jeu de dés. Les joueurs lancent à tour de rôle 3 dés à la fois. Chaque tour est remporté par celui qui obtient le plus de six à la fois. Les résultats sont enregistrés. Après 100 tours, un des joueurs soupçonnait que les dés de son adversaire étaient asymétriques, car il gagne souvent (il lance souvent des six). Il a décidé d’analyser la probabilité d’un tel nombre d’issues ennemies.
Note: Parce que Il y a 3 cubes, vous pouvez alors en lancer 0 à la fois ; 1 ; 2 ou 3 six, c'est-à-dire une variable aléatoire peut prendre 4 valeurs.
De la théorie des probabilités, nous savons que si les dés sont symétriques, alors la probabilité d'obtenir des six obéit. Par conséquent, après 100 tours, les fréquences des six peuvent être calculées à l'aide de la formule
=BINOM.DIST(A7,3,1/6,FALSE)*100
La formule suppose que dans la cellule A7 contient le nombre correspondant de six lancés en un tour.
Note: Les calculs sont donnés en exemple de fichier sur la feuille Discrète.
A titre de comparaison observé(Observé) et fréquences théoriques(Attendu) pratique à utiliser.

Si les fréquences observées s'écartent significativement de la distribution théorique, hypothèse nulle sur la distribution d'une variable aléatoire selon une loi théorique doit être rejetée. Autrement dit, si les dés de l'adversaire sont asymétriques, alors les fréquences observées seront « significativement différentes » de distribution binomiale.
Dans notre cas, à première vue, les fréquences sont assez proches et sans calculs il est difficile de tirer une conclusion sans ambiguïté. En vigueur Test d'adéquation de Pearson X 2, de sorte qu'au lieu de l'affirmation subjective « substantiellement différent », qui peut être formulée sur la base d'une comparaison histogrammes, utilisez une affirmation mathématiquement correcte.
Nous utilisons le fait qu'en raison de loi des grands nombres fréquence observée (Observée) avec un volume croissant échantillons n tend vers la probabilité correspondant à la loi théorique (dans notre cas, loi binomiale). Dans notre cas, la taille de l’échantillon n est de 100.
Présentons test statistiques, que l'on note X 2 :

où O l est la fréquence observée des événements pour lesquels la variable aléatoire a pris certaines valeurs acceptables, E l est la fréquence théorique correspondante (attendue). L est le nombre de valeurs que peut prendre une variable aléatoire (dans notre cas c'est 4).
Comme le montre la formule, ceci statistiques est une mesure de la proximité des fréquences observées par rapport aux fréquences théoriques, c'est-à-dire il peut être utilisé pour estimer les « distances » entre ces fréquences. Si la somme de ces « distances » est « trop grande », alors ces fréquences sont « significativement différentes ». Il est clair que si notre cube est symétrique (c'est-à-dire applicable loi binomiale), alors la probabilité que la somme des « distances » soit « trop grande » sera faible. Pour calculer cette probabilité, nous devons connaître la distribution statistiques X2 ( statistiques X 2 calculé sur la base du hasard échantillons, c'est donc une variable aléatoire et a donc son propre distribution de probabilité).
De l’analogue multidimensionnel Théorème intégral de Moivre-Laplace on sait que pour n->∞ notre variable aléatoire X 2 est asymptotiquement à L - 1 degrés de liberté.
Donc si la valeur calculée statistiques X 2 (la somme des « distances » entre les fréquences) sera supérieure à une certaine valeur limite, nous aurons alors des raisons de rejeter hypothèse nulle. Identique à vérifier hypothèses paramétriques, la valeur limite est réglée via niveau de signification. Si la probabilité que la statistique X2 prenne une valeur inférieure ou égale à celle calculée ( p-signification), sera moindre niveau de signification, Que hypothèse nulle peut être rejeté.
Dans notre cas, la valeur statistique est de 22,757. La probabilité que la statistique X2 prenne une valeur supérieure ou égale à 22,757 est très faible (0,000045) et peut être calculée à l'aide des formules
=CHI2.DIST.PH(22.757,4-1) ou
=CHI2.TEST(Observé ; Attendu)
Note: La fonction CHI2.TEST() est spécifiquement conçue pour tester la relation entre deux variables catégorielles (voir).
La probabilité 0,000045 est nettement inférieure à la normale niveau de signification 0,05. Ainsi, le joueur a toutes les raisons de soupçonner son adversaire de malhonnêteté ( hypothèse nulle son honnêteté est niée).

Lors de l'utilisation critère X 2 il faut s'assurer que le volume échantillons n était suffisamment grand, sinon l'approximation de la distribution ne serait pas valide statistiques X 2. On pense généralement que pour cela, il suffit que les fréquences observées (Observées) soient supérieures à 5. Si ce n'est pas le cas, alors les petites fréquences sont combinées en une ou ajoutées à d'autres fréquences, et la valeur combinée se voit attribuer un total probabilité et, par conséquent, le nombre de degrés de liberté est réduit X2 distributions.
Afin d'améliorer la qualité de l'application critère X 2(), il faut réduire les intervalles de partition (augmenter L et, par conséquent, augmenter le nombre degrés de liberté), cependant, cela est empêché par la limitation du nombre d'observations incluses dans chaque intervalle (db>5).
Cas continu
Test d'adéquation de Pearson X2 peut également être appliqué en cas de .
Considérons un certain échantillon, composé de 200 valeurs. Hypothèse nulle déclare que échantillon fabriqué à partir de .
Note: Variables aléatoires dans exemple de fichier sur la feuille continue généré à l'aide de la formule =NORM.ST.INV(RAND()). Donc de nouvelles valeurs échantillons sont générés à chaque recalcul de la feuille.
La pertinence de l’ensemble de données existant peut être évaluée visuellement.

Comme le montre le diagramme, les valeurs de l'échantillon s'adaptent assez bien le long de la ligne droite. Cependant, comme pour test d'hypothèse en vigueur Test d'ajustement du Pearson X 2.
Pour ce faire, nous divisons la plage de changement de la variable aléatoire en intervalles avec un pas de 0,5. Calculons les fréquences observées et théoriques. Nous calculons les fréquences observées à l'aide de la fonction FREQUENCY(), et les fréquences théoriques à l'aide de la fonction NORM.ST.DIST().
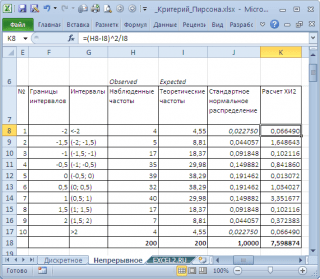
Note: Idem que pour cas discret, il faut s'assurer que échantillonétait assez grand et l'intervalle comprenait> 5 valeurs.
Calculons la statistique X2 et comparons-la avec la valeur critique pour un niveau de signification(0,05). Parce que nous avons divisé la plage de changement d'une variable aléatoire en 10 intervalles, le nombre de degrés de liberté est alors de 9. La valeur critique peut être calculée à l'aide de la formule
=CHI2.OBR.PH(0,05;9) ou
=CHI2.OBR(1-0,05;9)
Le graphique ci-dessus montre que la valeur statistique est de 8,19, ce qui est nettement plus élevé. valeur critique – hypothèse nulle n'est pas rejeté.
Ci-dessous, où échantillon a pris une signification improbable et basée sur critère Consentement de Pearson X 2 l'hypothèse nulle a été rejetée (même si les valeurs aléatoires ont été générées à l'aide de la formule =NORM.ST.INV(RAND()), fournissant échantillon depuis distribution normale standard).

Hypothèse nulle rejeté, bien que visuellement les données soient situées assez près d'une ligne droite.
Prenons également comme exemple échantillon de U(-3; 3). Dans ce cas, même à partir du graphique, il est évident que hypothèse nulle devrait être rejeté.

Critère Consentement de Pearson X 2 confirme également que hypothèse nulle devrait être rejeté.







