To vprašanje je že dolgo podrobno raziskano, najbolj razširjena metoda pa je metoda polarnih koordinat, ki so jo leta 1958 predlagali George Box, Mervyn Muller in George Marsaglia. Ta metoda vam omogoča, da pridobite par neodvisnih normalno porazdeljenih naključnih spremenljivk z matematičnim pričakovanjem 0 in varianco 1, kot sledi:
Kjer sta Z 0 in Z 1 želeni vrednosti, s = u 2 + v 2 in sta u in v naključni spremenljivki, enakomerno porazdeljeni na intervalu (-1, 1), izbrani tako, da je izpolnjen pogoj 0< s < 1.
Mnogi ljudje uporabljajo te formule brez razmišljanja in mnogi niti ne sumijo na njihov obstoj, saj uporabljajo že pripravljene izvedbe. Toda obstajajo ljudje, ki se sprašujejo: »Od kod ta formula? In zakaj dobiš nekaj količin naenkrat?« V nadaljevanju bom poskušal podati jasen odgovor na ta vprašanja.
Za začetek naj vas spomnim, kaj so gostota verjetnosti, porazdelitvena funkcija naključne spremenljivke in inverzna funkcija. Recimo, da obstaja določena naključna spremenljivka, katere porazdelitev je določena s funkcijo gostote f(x), ki ima naslednjo obliko:

To pomeni, da je verjetnost, da bo vrednost dane naključne spremenljivke v intervalu (A, B), enaka površini osenčenega območja. In posledično mora biti površina celotnega osenčenega območja enaka eni, saj bo v vsakem primeru vrednost naključne spremenljivke padla v domeno definicije funkcije f.
Funkcija porazdelitve naključne spremenljivke je integral funkcije gostote. In v tem primeru bo njegov približni videz takšen:

Pomen tukaj je, da bo vrednost naključne spremenljivke manjša od A z verjetnostjo B. In posledično se funkcija nikoli ne zmanjša, njene vrednosti pa ležijo v intervalu.
Inverzna funkcija je funkcija, ki vrne argument izvirni funkciji, če je vanjo posredovana vrednost izvirne funkcije. Na primer, za funkcijo x 2 je inverzna funkcija ekstrakcije korena, za sin(x) je arcsin(x) itd.
Ker večina generatorjev psevdonaključnih števil proizvede samo enotno porazdelitev kot rezultat, jo je pogosto treba pretvoriti v kakšno drugo. V tem primeru za normalno Gaussovo:

Osnova vseh metod za pretvorbo enotne porazdelitve v katero koli drugo je metoda inverzne transformacije. Deluje na naslednji način. Najdemo funkcijo, ki je inverzna funkciji zahtevane porazdelitve, in ji kot argument posredujemo naključno spremenljivko, enakomerno porazdeljeno na interval (0, 1). Na izhodu dobimo vrednost z zahtevano porazdelitvijo. Zaradi jasnosti podajam naslednjo sliko.

Tako je enakomeren segment tako rekoč razmazan v skladu z novo porazdelitvijo, projiciran na drugo os preko inverzne funkcije. Toda težava je v tem, da integrala gostote Gaussove porazdelitve ni enostavno izračunati, zato so morali zgornji znanstveniki goljufati.
Obstaja porazdelitev hi-kvadrat (Pearsonova porazdelitev), ki je porazdelitev vsote kvadratov k neodvisnih normalnih naključnih spremenljivk. In v primeru, ko je k = 2, je ta porazdelitev eksponentna.

To pomeni, da če ima točka v pravokotnem koordinatnem sistemu naključne koordinate X in Y, porazdeljene normalno, potem po pretvorbi teh koordinat v polarni sistem (r, θ) kvadrat polmera (razdalja od izhodišča do točke) bo porazdeljen po eksponentnem zakonu, saj je kvadrat polmera vsota kvadratov koordinat (po Pitagorejevem zakonu). Gostota porazdelitve takih točk na ravnini bo videti takole:


Ker je enak v vseh smereh, bo imel kot θ enakomerno porazdelitev v območju od 0 do 2π. Velja tudi obratno: če definirate točko v polarnem koordinatnem sistemu z dvema neodvisnima naključnima spremenljivkama (enakomerno porazdeljen kot in eksponentno porazdeljen polmer), bodo pravokotne koordinate te točke neodvisne normalne naključne spremenljivke. In veliko lažje je pridobiti eksponentno porazdelitev iz enakomerne porazdelitve z isto metodo inverzne transformacije. To je bistvo polarne Box-Mullerjeve metode.
Zdaj pa izpeljimo formule.
![]() (1)
(1)
Za pridobitev r in θ je treba generirati dve naključni spremenljivki, enakomerno porazdeljeni na interval (0, 1) (imenujmo ju u in v), porazdelitev ene od njih (recimo v) pa je treba pretvoriti v eksponentno v dobimo polmer. Funkcija eksponentne porazdelitve izgleda takole:
Njegova inverzna funkcija je:
![]()
Ker je enotna porazdelitev simetrična, bo transformacija delovala podobno s funkcijo
![]()
Iz formule za porazdelitev hi-kvadrat sledi, da je λ = 0,5. Zamenjajte λ, v v to funkcijo in dobite kvadrat polmera in nato sam polmer:

Kot dobimo tako, da enotski segment raztegnemo na 2π:
Sedaj zamenjamo r in θ v formule (1) in dobimo:
 (2)
(2)
Te formule so že pripravljene za uporabo. X in Y bosta neodvisna in normalno porazdeljena z varianco 1 in matematičnim pričakovanjem 0. Da dobimo porazdelitev z drugimi značilnostmi, je dovolj, da pomnožimo rezultat funkcije s standardnim odklonom in dodamo matematično pričakovanje.
Vendar se je mogoče znebiti trigonometričnih funkcij tako, da določite kot ne neposredno, temveč posredno prek pravokotnih koordinat naključne točke v krogu. Nato bo prek teh koordinat mogoče izračunati dolžino vektorja radija in nato poiskati kosinus in sinus tako, da z njim delimo x oziroma y. Kako in zakaj deluje?
Izberimo naključno točko izmed enakomerno porazdeljenih v krogu enotskega polmera in označimo kvadrat dolžine vektorja radija te točke s črko s:

Izbor izvedemo tako, da določimo naključni pravokotni koordinati x in y, enakomerno porazdeljeni v intervalu (-1, 1), in zavržemo točke, ki ne pripadajo krogu, ter središčno točko, v kateri je kot radijnega vektorja ni definiran. To pomeni, da mora biti izpolnjen pogoj 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Dobimo formule kot na začetku članka. Pomanjkljivost te metode je zavrženje točk, ki niso vključene v krog. Se pravi z uporabo samo 78,5 % generiranih naključnih spremenljivk. Na starejših računalnikih je bilo pomanjkanje trigonometričnih funkcij še vedno velika prednost. Zdaj, ko en ukaz procesorja izračuna sinus in kosinus v trenutku, menim, da lahko ti metodi še vedno tekmujeta.
Osebno imam še dve vprašanji:
- Zakaj je vrednost s enakomerno porazdeljena?
- Zakaj je vsota kvadratov dveh normalnih naključnih spremenljivk porazdeljena eksponentno?

Če se podobna transformacija izvede za normalno naključno spremenljivko, se bo funkcija gostote njenega kvadrata izkazala za podobno hiperboli. In seštevanje dveh kvadratov normalnih naključnih spremenljivk je že veliko bolj zapleten proces, povezan z dvojno integracijo. In dejstvo, da bo rezultat eksponentna porazdelitev, je zame osebno še treba preveriti s praktično metodo ali sprejeti kot aksiom. In za tiste, ki jih zanima, predlagam, da si podrobneje ogledajo temo in pridobijo znanje iz teh knjig:
- Ventzel E.S. Teorija verjetnosti
- Knut D.E. Umetnost programiranja, 2. zvezek
Za zaključek je tukaj primer implementacije normalno porazdeljenega generatorja naključnih števil v JavaScriptu:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2,0 * Math.random() - 1,0; v = 2,0 * Math. random() - 1.0; s = u * u * v; while (s > 1.0 || s == 0.0); return r * v * dev + povprečje ) ) g = nov Gauss(); // ustvari objekt a = g.next(); // ustvarite par vrednosti in pridobite prvo b = g.next(); // pridobi drugi c = g.next(); // ponovno ustvarite par vrednosti in pridobite prvo
Parametra mean (matematično pričakovanje) in dev (standardni odklon) nista obvezna. Opozarjam vas na dejstvo, da je logaritem naraven.
Kot primer zvezne naključne spremenljivke razmislite o naključni spremenljivki X, enakomerno porazdeljeni po intervalu (a; b). Za naključno spremenljivko X pravimo, da je enakomerno porazdeljena na intervalu (a; b), če njegova porazdelitvena gostota na tem intervalu ni konstantna:
Iz normalizacijskega pogoja določimo vrednost konstante c. Območje pod krivuljo gostote porazdelitve mora biti enako enoti, v našem primeru pa je to območje pravokotnika z osnovo (b - α) in višino c (slika 1). 
riž. 1 Enakomerna gostota porazdelitve
Od tu najdemo vrednost konstante c: ![]()
Torej je gostota enakomerno porazdeljene naključne spremenljivke enaka 
Poiščimo porazdelitveno funkcijo s formulo:
1) za ![]()
2) za
3) za 0+1+0=1.
torej 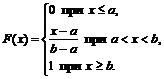
Porazdelitvena funkcija je zvezna in ne pada (slika 2). 
riž. 2 Porazdelitvena funkcija enakomerno porazdeljene naključne spremenljivke
Bomo našli matematično pričakovanje enakomerno porazdeljene naključne spremenljivke po formuli:
Disperzija enakomerne porazdelitve se izračuna po formuli in je enako
Primer št. 1. Vrednost razdelka merilne naprave je 0,2. Odčitki instrumenta so zaokroženi na najbližji cel razdelek. Poiščite verjetnost, da bo pri štetju nastala napaka: a) manjša od 0,04; b) velika 0,02
rešitev. Napaka zaokroževanja je naključna spremenljivka, ki je enakomerno porazdeljena v intervalu med sosednjimi celimi delitvami. Kot takšno razdelitev si oglejmo interval (0; 0,2) (slika a). Zaokroževanje se lahko izvede tako proti levi meji - 0, kot proti desni - 0,2, kar pomeni, da je lahko napaka manjša ali enaka 0,04 dvakrat, kar je treba upoštevati pri izračunu verjetnosti: 

P = 0,2 + 0,2 = 0,4
V drugem primeru lahko vrednost napake tudi presega 0,02 na obeh mejah delitve, torej je lahko večja od 0,02 ali manjša od 0,18. 
Potem je verjetnost napake, kot je ta:
Primer št. 2. Predpostavljeno je bilo, da je stabilnost gospodarskega položaja v državi (odsotnost vojn, naravnih nesreč itd.) V zadnjih 50 letih mogoče oceniti po naravi porazdelitve prebivalstva po starosti: v mirnem položaju bi moralo biti uniforma. Kot rezultat študije so bili za eno od držav pridobljeni naslednji podatki.
Ali obstaja razlog za domnevo, da je v državi prišlo do nestabilnosti?Rešitev izvedemo s pomočjo kalkulatorja. Tabela za izračun indikatorjev.
| Skupine | Sredina intervala, x i | Količina, f i | x i * f i | Akumulirana frekvenca, S | |x - x povprečje |*f | (x - x povprečje) 2 *f | Frekvenca, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Uteženo povprečje
Indikatorji variacije.
Absolutne variacije.
Razpon variacije je razlika med največjo in najmanjšo vrednostjo značilnosti primarne serije.
R = X max - X min
R = 70 - 0 = 70
Razpršenost- označuje mero razpršenosti okoli njene povprečne vrednosti (mera razpršenosti, tj. odstopanje od povprečja).
Standardni odklon.
Vsaka vrednost niza se od povprečne vrednosti 43 ne razlikuje za več kot 23,92
Preizkušanje hipotez o vrsti porazdelitve.
4. Preizkušanje hipoteze o enakomerna porazdelitev splošna populacija.
Da bi preverili hipotezo o enakomerni porazdelitvi X, tj. po zakonu: f(x) = 1/(b-a) v intervalu (a,b)
potrebno:
1. Ocenite parametra a in b - konca intervala, v katerem so bile opažene možne vrednosti X, z uporabo formul (znak * označuje ocene parametrov):
2. Poiščite gostoto verjetnosti pričakovane porazdelitve f(x) = 1/(b * - a *)
3. Poiščite teoretične frekvence:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Primerjajte empirične in teoretične frekvence z uporabo Pearsonovega kriterija, pri čemer upoštevajte število prostostnih stopenj k = s-3, kjer je s število začetnih intervalov vzorčenja; če je bila izvedena kombinacija majhnih frekvenc in torej samih intervalov, potem je s število intervalov, ki ostanejo po kombinaciji.
rešitev:
1. Poiščite ocene parametrov a * in b * enotne porazdelitve z uporabo formul:
2. Poiščite gostoto predpostavljene enakomerne porazdelitve:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Poiščimo teoretične frekvence:
n 1 = n*f(x)(x 1 - a *) = 1 * 0,0121(10-1,58) = 0,1
n 8 = n*f(x)(b * - x 7) = 1 * 0,0121(84,42-70) = 0,17
Preostali n s bo enak:
n s = n*f(x)(x i - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3,5E-5 | 0.000199 |
| Skupaj | 1 | 0.0532 |
Zato je kritično območje za to statistiko vedno desno: če je na tem segmentu gostota verjetnostne porazdelitve naključne spremenljivke konstantna, to je, če je diferencialna porazdelitvena funkcija f(x) ima naslednjo obliko:
![]()
Ta porazdelitev se včasih imenuje zakon enakomerne gostote. Za količino, ki je na določenem segmentu enakomerno porazdeljena, bomo rekli, da je na tem segmentu enakomerno porazdeljena.
Poiščimo vrednost konstante c. Ker je območje omejeno s porazdelitveno krivuljo in osjo Oh, je enako 1, potem
kjer z=1/(b-a).
Zdaj pa funkcija f(x)lahko predstavimo v obliki

Konstruirajmo distribucijsko funkcijo
F(x ), zakaj najdemo izraz za F(x) na intervalu [ a, b]:


Grafa funkcij f (x) in F (x) izgledata takole:

Poiščimo numerične značilnosti.
Z uporabo formule za izračun matematičnega pričakovanja NSV imamo:

Tako je matematično pričakovanje naključne spremenljivke, enakomerno porazdeljene na intervalu [a, b] sovpada s sredino tega segmenta.
Poiščimo varianco enakomerno porazdeljene naključne spremenljivke:
iz česar takoj sledi, da je standardna deviacija:
![]()
Poiščimo zdaj verjetnost, da vrednost naključne spremenljivke z enakomerno porazdelitvijo pade na interval(a, b), v celoti pripada segmentu [a,b
]:

|
|

Geometrično je ta verjetnost površina osenčenega pravokotnika. Številke A in
bse imenujejo parametri porazdelitve in enolično določi enakomerno porazdelitev.Primer 1. Avtobusi na nekaterih progah vozijo po voznem redu. Interval gibanja je 5 minut. Poiščite verjetnost, da se potnik, ki se približa ustavi. Čakanje na naslednji avtobus bo manj kot 3 minute.
rešitev:
Čakalna doba CB-busa je enakomerno porazdeljena. Potem bo zahtevana verjetnost enaka:
![]()
Primer 2. Rob kocke x je izmerjen približno. Poleg tega
Ob upoštevanju roba kocke kot naključne spremenljivke, enakomerno porazdeljene v intervalu (
a,b), poiščite matematično pričakovanje in varianco prostornine kocke.rešitev:
Prostornina kocke je naključna spremenljivka, določena z izrazom Y = X 3. Potem je matematično pričakovanje:
Razpršenost:
Spletna storitev:
Porazdelitev se šteje za enotno, v kateri so vse vrednosti naključne spremenljivke (v območju njenega obstoja, na primer v intervalu) enako verjetne. Porazdelitvena funkcija za takšno naključno spremenljivko ima obliko:
Gostota porazdelitve: 
 1
1

riž. Grafa porazdelitvene funkcije (levo) in porazdelitvene gostote (desno).
Enakomerna porazdelitev - pojem in vrste. Razvrstitev in značilnosti kategorije "Enomerna porazdelitev" 2017, 2018.
Osnovne diskretne porazdelitve naključnih spremenljivk Definicija 1. Naključna spremenljivka X, ki ima vrednosti 1, 2, ..., n, ima enakomerno porazdelitev, če je Pm = P(X = m) = 1/n, m = 1, ..., n.
Očitno.
Razmislite o naslednjem problemu v žari, od katerih je M belih... .
Zakoni porazdelitve zveznih naključnih spremenljivk Definicija 5. Zvezna naključna spremenljivka X, ki ima vrednost na intervalu, ima enakomerno porazdelitev, če ima gostota porazdelitve obliko. (1) To je enostavno preveriti,.< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
Če je naključna spremenljivka ... .
Porazdelitev se šteje za enotno, v kateri so vse vrednosti naključne spremenljivke (v območju njenega obstoja, na primer v intervalu) enako verjetne. Porazdelitvena funkcija za tako naključno spremenljivko ima obliko: Porazdelitvena gostota: F(x) f(x) 1 0 a b x 0 a b x ... .
Zakoni normalne porazdelitve Enakomerna, eksponentna in Funkcija gostote verjetnosti enotnega zakona je naslednja: (10.17) kjer sta a in b dani števili, aEnotna porazdelitev verjetnosti je najenostavnejša in je lahko diskretna ali zvezna. Diskretna enakomerna porazdelitev je porazdelitev, pri kateri je verjetnost vsake vrednosti SV enaka, to je: kjer je N število ... . Definicija 16. Zvezna naključna spremenljivka ima na segmentu enakomerno porazdelitev, če je gostota porazdelitve te naključne spremenljivke na tem segmentu konstantna in zunaj njega enaka nič, to je (45) Prikazan je graf gostote za enakomerno porazdelitev...
Razmislite o enotni zvezni porazdelitvi. Izračunajmo matematično pričakovanje in varianco. Ustvarimo naključne vrednosti s funkcijo MS EXCEL RAND()
in dodatki Analysis Package, bomo ocenili srednjo vrednost in standardni odklon.







