Doğrusal regresyon modeli
Öyleyse, birkaç bağımsız rastgele değişken X1, X2, ..., Xn (tahmin ediciler) ve bunlara bağlı bir Y değeri olsun (tahmin ediciler için gerekli tüm dönüşümlerin zaten yapılmış olduğu varsayılır). Ayrıca ilişkinin doğrusal olduğunu ve hataların normal dağıldığını varsayıyoruz.Burada I bir n x n birim kare matristir.
Yani elimizde Y ve Xi değerlerinin k gözleminden oluşan veri var ve katsayıları tahmin etmek istiyoruz. Katsayı tahminlerini bulmanın standart yöntemi en küçük kareler yöntemidir. Ve bu yöntemin uygulanmasıyla elde edilebilecek analitik çözüm şu şekildedir:
Nerede B kapaklı - katsayıların vektörünün tahmini, sen bağımlı değişkenin değerlerinin bir vektörüdür ve X, k x n+1 boyutunda bir matristir (n, tahminlerin sayısıdır, k, gözlemlerin sayısıdır), burada ilk sütun birlerden oluşur, ikincisi - ilk tahmincinin, üçüncünün - ikincisinin vb. değerleri ve mevcut gözlemlerle tutarlı satırlar.
Summary.lm() işlevi ve ortaya çıkan sonuçların değerlendirilmesi
Şimdi R'de doğrusal bir regresyon modeli oluşturma örneğine bakalım:> kütüphane(uzak) > lm1<-lm(Species~Area+Elevation+Nearest+Scruz+Adjacent, data=gala) >özet(lm1) Çağrı: lm(formül = Türler ~ Alan + Yükseklik + En Yakın + Scruz + Bitişik, veri = gala) Artıklar: Min 1Q Medyan 3Q Max -111,679 -34,898 -7,862 33,460 182,584 Katsayılar: Tahmin Std. Hata t değeri Pr(>|t|) (Kesme) 7,068221 19,154198 0,369 0,715351 Alan -0,023938 0,022422 -1,068 0,296318 Yükseklik 0,319465 0,053663 5,953 3,82e-06 *** tahmin 0,009144 1,054136 0,009 0,993151 Scruz -0,240524 0,215402 -1,117 0,275208 Bitişik -0,074805 0,017700 -4,226 0,000297 *** --- Anlamlı. kodlar: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 Artık standart hata: 24 serbestlik derecesinde 60,98 Çoklu R-kare: 0,7658, Düzeltilmiş R-kare: 0,7171 F- istatistik: 5 ve 24 DF'de 15,7, p değeri: 6,838e-07
Tablo galası 30 Galapagos Adası hakkında bazı veriler içermektedir. Türlerin - adadaki farklı bitki türlerinin sayısının diğer bazı değişkenlere doğrusal olarak bağlı olduğu bir modeli ele alacağız.
Summary.lm() fonksiyonunun çıktısına bakalım.
İlk önce modelin nasıl yapıldığını hatırlatan bir çizgi geliyor.
Daha sonra artıkların dağılımı hakkında bilgi gelir: minimum, birinci çeyrek, medyan, üçüncü çeyrek, maksimum. Bu noktada, yalnızca artıkların bazı yüzdelik dilimlerine bakmak değil, aynı zamanda bunları örneğin Shapiro-Wilk testiyle normallik açısından test etmek de yararlı olacaktır.
Sonraki - en ilginç - katsayılar hakkında bilgi. Burada biraz teoriye ihtiyaç var.
İlk önce aşağıdaki sonucu yazıyoruz: 
Sınırlı sigma kare, gerçek sigma kare için tarafsız bir tahmindir. Burada B katsayıların gerçek vektörüdür ve en küçük kareler yöntemiyle elde edilen tahminleri katsayı olarak alırsak, kapaklı epsilon artıkların vektörüdür. Yani, hataların normal dağıldığı varsayımı altında, katsayıların vektörü de gerçek değer etrafında normal olarak dağılacak ve varyansı tarafsız olarak tahmin edilebilecektir. Bu, katsayıların sıfıra eşitliği hipotezini test edebileceğiniz ve dolayısıyla yordayıcıların önemini, yani Xi değerinin oluşturulan modelin kalitesini gerçekten büyük ölçüde etkileyip etkilemediğini kontrol edebileceğiniz anlamına gelir.
Bu hipotezi test etmek için, bi katsayısının gerçek değeri 0 ise Öğrenci dağılımına sahip olan aşağıdaki istatistiklere ihtiyacımız var: 
Nerede ![]() katsayı tahmininin standart hatasıdır ve t(k-n-1) k-n-1 serbestlik derecesine sahip Öğrenci dağılımıdır.
katsayı tahmininin standart hatasıdır ve t(k-n-1) k-n-1 serbestlik derecesine sahip Öğrenci dağılımıdır.
Artık Summary.lm() çıktısını ayrıştırmaya devam etmeye hazırsınız.
Aşağıda, en küçük kareler yöntemiyle elde edilen katsayıların tahminleri, bunların standart hataları, t-istatistik değerleri ve bunun için p-değerleri yer almaktadır. Tipik olarak p değeri, 0,05 veya 0,01 gibi oldukça küçük önceden seçilmiş eşik değerleri ile karşılaştırılır. Ve p-istatistiği değeri eşikten küçük çıkarsa hipotez reddedilir, ancak daha fazlaysa maalesef somut bir şey söylenemez. Bu durumda Öğrenci dağılımı 0 civarında simetrik olduğundan p değerinin 1-F(|t|)+F(-|t|) olacağını hatırlatayım, burada F Öğrenci dağılım fonksiyonudur. k-n-1 serbestlik derecesine sahip. Ayrıca R, p değerinin yeterince küçük olduğu önemli katsayıları yıldız işaretleriyle yararlı bir şekilde belirtir. Yani çok düşük olasılıkla bu katsayılar 0'a eşittir. Signif satırında. kodlar yıldız işaretlerinin kodunun çözülmesini içerir: eğer üç tane varsa, o zaman p değeri 0'dan 0,001'e kadardır, eğer iki tane varsa, o zaman 0,001'den 0,01'e kadardır vb. Hiçbir simge yoksa p değeri 0,1'den büyüktür.
Örneğimizde, Yükseklik ve Bitişik tahmin edicilerinin gerçekten de Türlerin değerini etkilediğini büyük bir güvenle söyleyebiliriz, ancak diğer tahmin ediciler hakkında kesin bir şey söylenemez. Tipik olarak, bu gibi durumlarda, tahmin ediciler birer birer kaldırılır ve modelin diğer göstergelerinin (örneğin, daha fazla tartışılacak olan BIC veya Düzeltilmiş R-kare) nasıl değiştiğine bakılır.
Artık standart hata değeri basitçe kapaklı sigma tahminine karşılık gelir ve serbestlik dereceleri k-n-1 olarak hesaplanır.
Şimdi ilk olarak bakmanız gereken en önemli istatistikler: R-kare ve Düzeltilmiş R-kare: 
burada Yi, her gözlemdeki Y'nin gerçek değerleridir, tavanlı Yi, model tarafından tahmin edilen değerlerdir, çubuklu Y, Yi'nin tüm gerçek değerlerinin ortalamasıdır. ![]()
R-kare istatistiğiyle veya bazen denildiği gibi belirleme katsayısıyla başlayalım. Modelin koşullu varyansının gerçek Y değerlerinin varyansından ne kadar farklı olduğunu gösterir. Eğer bu katsayı 1'e yakınsa modelin koşullu varyansı oldukça küçüktür ve modelin verileri iyi tanımlaması muhtemeldir. . R-kare katsayısı çok daha küçükse, örneğin 0,5'ten azsa, o zaman yüksek derecede güven ile model gerçek durumu yansıtmaz.
Ancak R-kare istatistiğinin ciddi bir dezavantajı vardır: öngörücülerin sayısı arttıkça bu istatistik yalnızca artabilir. Bu nedenle, tüm yeni yordayıcıların bağımlı değişken üzerinde hiçbir etkisi olmasa bile, daha fazla yordayıcıya sahip bir model, daha az yordayıcıya sahip bir modelden daha iyi gibi görünebilir. Burada Occam'ın usturasının prensibini hatırlayabilirsiniz. Bunu takip ederek mümkünse modeldeki gereksiz tahminlerden kurtulmaya değer çünkü daha basit ve anlaşılır hale geliyor. Bu amaçlar doğrultusunda düzeltilmiş R-kare istatistiği icat edildi. Her zamanki R-kareyi temsil eder, ancak çok sayıda tahmincinin cezası vardır. Ana fikir: Yeni bağımsız değişkenler modelin kalitesine büyük katkı sağlıyorsa bu istatistiğin değeri artar, değilse tam tersine azalır.
Örneğin, öncekiyle aynı modeli düşünün, ancak şimdi beş tahminci yerine iki tane bırakalım:
>lm2<-lm(Species~Elevation+Adjacent, data=gala)
>özet(lm2) Çağrı: lm(formül = Türler ~ Yükseklik + Bitişik, veri = gala) Artıklar: Min 1Ç Medyan 3Ç Maksimum -103,41 -34,33 -11,43 22,57 203,65 Katsayılar: Tahmin Std. Hata t değeri Pr(>|t|) (Kesme) 1,43287 15,02469 0,095 0,924727 Yükseklik 0,27657 0,03176 8,707 2,53e-09 *** Bitişik -0,06889 0,01549 -4,447 0,000134 *** --- . kodlar: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 Artık standart hata: 27 serbestlik derecesinde 60,86 Çoklu R-kare: 0,7376, Düzeltilmiş R-kare: 0,7181 F- istatistik: 2 ve 27 DF'de 37,94, p değeri: 1,434e-08
Gördüğünüz gibi R-kare istatistiğinin değeri azaldı, ancak düzeltilmiş R-karenin değeri biraz arttı.
Şimdi yordayıcıların tüm katsayılarının sıfıra eşit olduğu hipotezini kontrol edelim. Yani, Y'nin değerinin genel olarak Xi'nin değerlerine doğrusal olarak bağlı olup olmadığına dair bir hipotez. Bunu yapmak için, tüm katsayıların sıfıra eşit olduğu hipotezi doğruysa aşağıdaki istatistikleri kullanabilirsiniz:
İÇİNDE regresyon istatistikleriçoklu korelasyon katsayısı belirtilir (Çoğul R) ve kararlılık (R-kare) Y ile faktör özellikleri dizisi arasında (bu, korelasyon analizinde daha önce elde edilen değerlerle örtüşür)
Masanın orta kısmı (Varyans Analizi) regresyon denkleminin anlamlılığını test etmek için gereklidir.
Tablonun alt kısmı - tam
genel regresyon katsayılarının bi nihai tahminleri, anlamlılıklarının ve aralık tahminlerinin test edilmesi.
b katsayılarının vektörünün tahmini (sütun Oranlar):
Bu durumda regresyon denklemi tahmini şu şekilde olur:
Regresyon denkleminin ve ortaya çıkan regresyon katsayılarının anlamlılığının kontrol edilmesi gerekir.
Regresyon denkleminin anlamlılığını b=0,05 seviyesinde kontrol edelim, yani. hipotez H0: в1=в2=в3=…=вk=0. Bunu yapmak için F istatistiğinin gözlemlenen değeri hesaplanır:

Excel bunu sonuçlarda gösterir varyans analizi:
QR=527.4296; Qost=1109.8673 =>
Sütunda F değer belirtilir Fgözlemlenebilir.
F-dağıtım tablolarından veya yerleşik istatistiksel işlevi kullanarak FKEŞFETMEK anlamlılık seviyesi b=0.05 ve pay n1=k=4 ve payda n2=n-k-1=45'in serbestlik derecesi sayısı için F istatistiklerinin kritik değerini şuna eşit buluyoruz:
Fcr = 2,578739184
F istatistiğinin gözlemlenen değeri kritik değeri olan 8,1957 > 2,7587'yi aştığı için katsayılar vektörünün eşitliği hipotezi 0,05 hata olasılığıyla reddedilir. Sonuç olarak, b=(b1,b2,b3,b4)T vektörünün en az bir elemanı sıfırdan önemli ölçüde farklıdır.
Regresyon denkleminin bireysel katsayılarının önemini kontrol edelim, yani. hipotez ![]() .
.
Regresyon katsayılarının anlamlılığının test edilmesi, anlamlılık düzeyi için t-istatistikleri temel alınarak gerçekleştirilir.
T istatistiklerinin gözlemlenen değerleri sütundaki sonuç tablosunda belirtilmiştir. T-istatistikler.
|
Katsayılar (bi) |
t-istatistikleri (tob) |
||
|
Y-kavşağı | |||
|
Değişken X5 | |||
|
Değişken X7 | |||
|
Değişken X10 | |||
|
Değişken X15 |
Anlamlılık seviyesi b=0,05 ve serbestlik derecesi sayısı n=n – k - 1 için bulunan kritik değer tcr ile karşılaştırılmaları gerekir.
Bunu yapmak için yerleşik Excel istatistik işlevini kullanıyoruz STUDISPOBR,Önerilen menüye olasılık b = 0,05 ve serbestlik derecesi sayısı n = n–k-1 = 50-4-1 = 45 girilerek. (Tcr değerlerini matematiksel istatistik tablolarından bulabilirsiniz.
tcr = 2,014103359 elde ederiz.
Çünkü t-istatistiklerinin gözlemlenen değeri, modulo 2.0141>|-0.0872|, 2.0141>|0.2630|, 2.0141>|0.7300|, 2.0141>|-1.6629 | kritik değerinden küçüktür.
Sonuç olarak bu katsayıların sıfıra eşit olduğu hipotezi 0,05 hata olasılığı ile reddedilmez, yani. karşılık gelen katsayılar önemsizdir.
T-istatistiklerinin gözlemlenen değeri modulo |3.7658|>2.0141 kritik değerinden daha büyük olduğundan, H0 hipotezi reddedilir, yani. - önemli
Regresyon katsayılarının önemi, sonuç tablosunun aşağıdaki sütunlarıyla da kontrol edilir:
Kolon P-Anlam model parametrelerinin önemini %5 sınır seviyesinde gösterir; p≤0,05 ise ilgili katsayı anlamlı kabul edilir, eğer p>0,05 ise önemsizdir.
Ve son sütunlar - %95'in altında Ve üst %95 Ve alt %98 Ve ilk %98 - bunlar, r = 0,95 (her zaman verilir) ve r = 0,98 (karşılık gelen ek güvenilirlik ayarlandığında verilir) için belirtilen güvenilirlik seviyelerine sahip regresyon katsayılarının aralık tahminleridir.
Alt ve üst sınırlar aynı işarete sahipse (sıfır güven aralığına dahil edilmez), ilgili regresyon katsayısı anlamlı kabul edilir, aksi halde önemsiz kabul edilir
Tablodan da anlaşılacağı üzere b3 katsayısı için p değeri p=0,0005<0,05 и доверительные интервалы не включают ноль, т.е. по всем проверочным критериям этот коэффициент является значимым.
Önemsiz regresörlerin hariç tutulduğu aşamalı regresyon analizi algoritmasına göre, bir sonraki aşamada, önemsiz regresyon katsayısına sahip bir değişkenin değerlendirmeden çıkarılması gerekir.
Regresyon değerlendirmesi sırasında çok sayıda önemsiz katsayının belirlenmesi durumunda, regresyon denkleminden ilk çıkarılacak olan, t istatistiğinin () mutlak değer olarak minimum olduğu regresördür. Bu prensibe göre bir sonraki aşamada regresyon katsayısı b2 önemsiz olan X5 değişkenini hariç tutmak gerekir.
REGRESYON ANALİZİNİN II. AŞAMASI.
Model, X7, X10, X15 faktör özelliklerini içerir ve X5'i hariç tutar.
|
SONUÇLARIN SONUÇLANMASI | ||||||||||||||||||
|
Regresyon istatistikleri | ||||||||||||||||||
|
Çoğul R | ||||||||||||||||||
|
R-kare | ||||||||||||||||||
|
Normalleştirilmiş R-kare | ||||||||||||||||||
|
Standart hata | ||||||||||||||||||
|
Gözlemler | ||||||||||||||||||
|
Varyans analizi | ||||||||||||||||||
|
(serbestlik derecesi sayısı n) |
(kare sapmaların toplamı Q) |
(ortalama kare MS=SS/n) |
(Fob'lar = MSR/MSost) |
Önem F |
||||||||||||||
|
Regresyon | ||||||||||||||||||
|
Oranlar |
Standart hata |
t-istatistikleri |
P-Değeri |
İlk %95 (bimaks) |
Daha düşük %98 (bimin) | |||||||||||||
|
Y-kavşağı | ||||||||||||||||||
|
Değişken X7 | ||||||||||||||||||
|
Değişken X10 | ||||||||||||||||||
|
Değişken X15 | ||||||||||||||||||
Çoklu korelasyon katsayısı Ortaya çıkan gösterge (bağımlı değişken) arasındaki istatistiksel ilişkinin yakınlık derecesinin bir ölçüsü olarak kullanılır. sen ve bir dizi açıklayıcı (bağımsız) değişken veya başka bir deyişle, faktörlerin sonuç üzerindeki ortak etkisinin yakınlığını değerlendirir.
Çoklu korelasyon katsayısı, aşağıdakiler de dahil olmak üzere çeşitli formüller (5) kullanılarak hesaplanabilir:
çift korelasyon katsayılarından oluşan bir matris kullanarak
 ,
(3.18)
,
(3.18)
nerede R- çift korelasyon katsayıları matrisinin belirleyicisi sen, ,
,
R 11 - faktörler arası korelasyon matrisinin belirleyicisi  ;
;

 .
(3.19)
.
(3.19)
İki bağımsız değişkenin olduğu bir model için formül (3.18) basitleştirilmiştir
 .
(3.20)
.
(3.20)
Çoklu korelasyon katsayısının karesi belirleme katsayısı R 2. İkili regresyonda olduğu gibi, R 2, regresyon modelinin kalitesini gösterir ve ortaya çıkan özelliğin toplam varyasyonunun payını yansıtır sen regresyon fonksiyonundaki değişikliklerle açıklanır F(X) (bkz. 2.4). Ek olarak, belirleme katsayısı formül kullanılarak bulunabilir.
 .
(3.21)
.
(3.21)
Ancak kullanım R Modele regresörler eklenirken belirleme katsayısı arttığı için çoklu regresyon durumunda 2 tamamen doğru değildir. Bunun nedeni, ilave değişkenler eklendiğinde artık varyansın azalmasıdır. Ve eğer faktör sayısı gözlem sayısına yaklaşırsa, o zaman artık varyans sıfıra eşit olacak ve çoklu korelasyon katsayısı ve dolayısıyla belirleme katsayısı bire yaklaşacaktır, ancak gerçekte faktörler ile sonuç arasındaki ilişki ve regresyon denkleminin açıklayıcı gücü çok daha düşük olabilir.
Ortaya çıkan karakteristikteki varyasyonun çeşitli faktör karakteristiklerinin değişimi ile ne kadar iyi açıklandığı konusunda yeterli bir değerlendirme elde etmek için, düzeltilmiş belirleme katsayısı
 (3.22)
(3.22)
Düzeltilmiş belirleme katsayısı her zaman daha azdır R 2. Üstelik farklı olarak R 2, her zaman pozitiftir,  negatif değer de alabilir.
negatif değer de alabilir.
Örnek (örnek 1'in devamı). Çoklu korelasyon katsayısını formül (3.20)'ye göre hesaplayalım:
Çoklu korelasyon katsayısının 0,8601'e eşit değeri, taşıma maliyeti ile yükün ağırlığı ve taşındığı mesafe arasında güçlü bir ilişki olduğunu gösterir.
Belirleme katsayısı şuna eşittir: R 2 =0,7399.
Düzeltilmiş belirleme katsayısı formül (3.22) kullanılarak hesaplanır:
 =0,7092.
=0,7092.
Düzeltilmiş belirleme katsayısının değerinin, belirleme katsayısının değerinden farklı olduğunu unutmayın.
Böylece bağımlı değişkendeki (ulaşım maliyeti) değişimin %70,9'u bağımsız değişkenlerdeki (kargo ağırlığı ve taşıma mesafesi) değişimle açıklanmaktadır. Bağımlı değişkendeki değişimin kalan %29,1'i modelde dikkate alınmayan faktörlerle açıklanmaktadır.
Düzeltilmiş belirleme katsayısının değeri oldukça büyüktür, bu nedenle ulaşım maliyetini belirleyen en önemli faktörleri modelde dikkate alabildik.
SONUÇLARIN SONUÇLANMASI
| Regresyon istatistikleri | |
| Regresyon istatistikleri | 0,998364 |
| Çoğul R | 0,99673 |
| R-kare | 0,996321 |
| Normalleştirilmiş R-kare | 0,42405 |
| Standart hata | 10 |
Gözlemler
Öncelikle tablo 8.3a'da sunulan hesaplamaların en üst kısmına, yani regresyon istatistiklerine bakalım.
Çoğu durumda, R-kare değeri uç değerler olarak adlandırılan bu değerlerin arasında yer alır; sıfır ile bir arasında.
R-kare değerinin bire yakın olması, oluşturulan modelin ilgili değişkenlerdeki değişkenliğin neredeyse tamamını açıkladığı anlamına gelir. Tersine, sıfıra yakın bir R-kare değeri, oluşturulan modelin kalitesinin zayıf olduğu anlamına gelir.
Örneğimizde kesinlik ölçüsü 0,99673'tür, bu da regresyon çizgisinin orijinal verilere çok iyi uyduğunu gösterir.
Çoğul R- çoklu korelasyon katsayısı R - bağımsız değişkenlerin (X) ve bağımlı değişkenin (Y) bağımlılık derecesini ifade eder.
Çoklu R, belirleme katsayısının kareköküne eşittir; bu miktar sıfırdan bire kadar değerler alır.
Basit doğrusal regresyon analizinde çoklu R, Pearson korelasyon katsayısına eşittir. Aslında bizim durumumuzda çoklu R, önceki örnekteki Pearson korelasyon katsayısına eşittir (0,998364).
| Oranlar | Normalleştirilmiş R-kare | Regresyon katsayıları | |
| t-istatistiği | 2,694545455 | 0,33176878 | 8,121757129 |
| Y-kavşağı | 2,305454545 | 0,04668634 | 49,38177965 |
| Değişken X 1 | |||
* Hesaplamaların kısaltılmış bir versiyonu sağlanmıştır
Şimdi hesaplamaların tablo 8.3b'de sunulan orta kısmını düşünün. Burada regresyon katsayısı b (2,305454545) ve ordinat ekseni boyunca yer değiştirme verilmiştir; sabit a (2,694545455).
Hesaplamalara dayanarak regresyon denklemini aşağıdaki gibi yazabiliriz:
Y= x*2,305454545+2,694545455 Değişkenler arasındaki ilişkinin yönü işaretlere (negatif veya pozitif) göre belirlenir. regresyon katsayıları
(katsayı b). Eğer işaret regresyon katsayısı
(katsayı b). Eğer işaret- pozitif, bağımlı değişken ile bağımsız değişken arasındaki ilişki pozitif olacaktır. Bizim durumumuzda regresyon katsayısının işareti pozitif olduğundan ilişki de pozitiftir.
- Negatif, bağımlı değişken ile bağımsız değişken arasındaki ilişki negatiftir (ters).
Tablo 8.3c'de. Artıkların türetilmesinin sonuçları sunulmaktadır. Bu sonuçların raporda görünmesi için “Regresyon” aracını çalıştırırken “Artıklar” onay kutusunu etkinleştirmeniz gerekir.
| Tablo 8.3c. | Kalanlar | Gözlem | Tahmin edilen Y |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
Kalanlar
Standart bakiyeler Raporun bu bölümünü kullanarak her noktanın oluşturulan regresyon çizgisinden sapmalarını görebiliriz. En büyük mutlak değerÇoklu korelasyon katsayısı x 1 , x 2 ,…, x m faktörlü sonuç niteliği y , genel durumda hangisinin şu şekle sahip olduğunu belirleme formülü
burada ∆ r korelasyon matrisinin determinantıdır; ∆ 11 – korelasyon matrisinin r yy öğesinin cebirsel toplamı.
Yalnızca iki faktör özelliği dikkate alınırsa çoklu korelasyon katsayısını hesaplamak için aşağıdaki formül kullanılabilir: 
Çoklu korelasyon katsayısının oluşturulması, yalnızca kısmi korelasyon katsayılarının anlamlı olduğu ve ortaya çıkan karakteristik ile modele dahil edilen faktörler arasındaki ilişkinin gerçekten mevcut olduğu durumlarda tavsiye edilir.
Belirleme katsayısı
Genel formül: R2 = RSS/TSS=1-ESS/TSSburada RSS, açıklanan sapmaların kareleri toplamıdır, ESS, açıklanmayan (kalan) kareler toplamıdır, TSS, sapmaların kareleri toplamıdır (TSS=RSS+ESS)
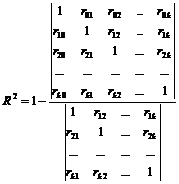 ,
,
burada r ij - regresörler xi ve xj arasındaki çift korelasyon katsayıları, a r ben 0 - regresör xi ve y arasındaki çiftli korelasyon katsayıları;
- düzeltilmiş (normalleştirilmiş) belirleme katsayısı.
Çoklu korelasyon katsayısının karesi ![]() isminde çoklu belirleme katsayısı; ortaya çıkan özelliğin varyansının ne kadarını gösterir sen x 1, x 2, ..., x m faktör özelliklerinin etkisiyle açıklanır. Ortaya çıkan özelliğin artık ve toplam varyansının oranı yoluyla belirleme katsayısını hesaplamaya yönelik formülün aynı sonucu vereceğini unutmayın.
isminde çoklu belirleme katsayısı; ortaya çıkan özelliğin varyansının ne kadarını gösterir sen x 1, x 2, ..., x m faktör özelliklerinin etkisiyle açıklanır. Ortaya çıkan özelliğin artık ve toplam varyansının oranı yoluyla belirleme katsayısını hesaplamaya yönelik formülün aynı sonucu vereceğini unutmayın.
Çoklu korelasyon katsayısı ve belirleme katsayısı 0 ile 1 arasında değişmektedir. 1'e ne kadar yakınsa ilişki o kadar güçlüdür ve buna bağlı olarak gelecekte oluşturulacak regresyon denklemi ilişkiyi o kadar doğru tanımlayacaktır. sen x 1, x 2, …, x m'den. Çoklu korelasyon katsayısının değeri küçükse (0,3'ten az), bu, seçilen faktör özellikleri kümesinin sonuçta ortaya çıkan özelliğin değişimini yeterince tanımlamadığı veya faktör ile sonuç değişkenleri arasındaki ilişkinin doğrusal olmadığı anlamına gelir.
Çoklu korelasyon katsayısı bir hesap makinesi kullanılarak hesaplanır. Çoklu korelasyon katsayısının ve belirleme katsayısının önemi Fisher testi kullanılarak test edilmiştir.
Aşağıdaki sayılardan hangisi çoklu belirleme katsayısının değeri olabilir:
a) 0,4;
b) -1;
c) -2,7;
2.7.
Çoklu doğrusal korelasyon katsayısı 0,75'tir. Bağımlı değişken y'deki değişimin yüzde kaçı modelde dikkate alınır ve bu, x 1 ve x 2 faktörlerinin etkisinden kaynaklanır.
a) 56,2 (R2 =0,75 2 =0,5625);







