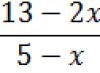It is already known that according to the distribution law one can find numerical characteristics random variable. It follows that if several random variables have identical distributions, then their numerical characteristics are the same.
Let's consider n mutually independent random variables X 1 , X 2 , ...., X p, which have the same distributions, and therefore the same characteristics (mathematical expectation, dispersion, etc.). Of greatest interest is the study of the numerical characteristics of the arithmetic mean of these quantities, which is what we will do in this section.
Let us denote the arithmetic mean of the random variables under consideration by :
= (X 1 +X 2 +…+X n)/n.
The following three provisions establish a connection between the numerical characteristics of the arithmetic mean X and the corresponding characteristics of each individual quantity.
1. Mathematical expectation of the average arithmetic one Covariably distributed mutually independent random quantities are equal to the mathematical expectation of each of the quantities:
M()=a
Proof. Using the properties of mathematical expectation ( constant factor can be taken out as a sign of mathematical expectation; the mathematical expectation of the sum is equal to the sum of the mathematical expectations of the terms), we have
M( )= M
Taking into account that the mathematical expectation of each of the quantities according to the condition is equal to A, we get
M()=na/n=a.
2. The dispersion of the arithmetic mean of n identically distributed mutually independent random variables is n times less than the dispersion D of each of the values:
D()=D/n.(* )
Proof. Using the properties of dispersion (the constant factor can be taken out of the dispersion sign by squaring it; the dispersion of the sum independent quantities equal to the sum of the variances of the terms), we have
D( )=D
Taking into account that the dispersion of each of the quantities according to the condition is equal to D, we get
D( )= nD/n 2 =D/n.
3. Average standard deviation the arithmetic mean of n identically distributed mutually independent random variables is several times less than the mean quadratic deviation s each of the quantities:
Proof. Because D()= D/n, then the standard deviation is equal to
s ( )= .
General conclusion from formulas (*) and (**): recalling that the dispersion and standard deviation serve as measures of the dispersion of a random variable, we conclude that the arithmetic mean is sufficient large number mutually independent random variables have significantly less dispersion than each individual variable.
Let us explain with an example the significance of this conclusion for practice.
Example. Usually to measure some physical quantity make several measurements, and then find the arithmetic mean of the obtained numbers, which is taken as an approximate value of the measured value. Assuming that the measurements are made under the same conditions, prove:
a) the arithmetic mean gives a more reliable result than individual measurements;
b) with an increase in the number of measurements, the reliability of this result increases.
Solution. a) It is known that individual measurements give different values of the measured quantity. The result of each measurement depends on many random reasons (temperature changes, instrument fluctuations, etc.), which cannot be fully taken into account in advance.
Therefore, we have the right to consider possible results n individual measurements as random variables X 1 , X 2 , ..., X p(the index indicates the measurement number). These quantities have the same probability distribution (measurements are made using the same method and with the same instruments), and therefore the same numerical characteristics; in addition, they are mutually independent (the result of each individual measurement does not depend on other measurements).
We already know that the arithmetic mean of such quantities has less dispersion than each individual quantity. In other words, the arithmetic mean turns out to be closer to true meaning measured quantity than the result of a single measurement. This means that the arithmetic mean of several measurements gives a more reliable result than a single measurement.
b) We already know that as the number of individual random variables increases, the dispersion of the arithmetic mean decreases. This means that as the number of measurements increases, the arithmetic mean of several measurements differs less and less from the true value of the measured value. Thus, by increasing the number of measurements, a more reliable result is obtained.
For example, if the standard deviation of an individual measurement is s = 6 m, and a total of n= 36 measurements, then the standard deviation of the arithmetic mean of these measurements is only 1 m. Indeed,
s ( )= ![]()
We see that the arithmetic mean of several measurements, as one would expect, turned out to be closer to the true value of the measured value than the result of a separate measurement.
Above we considered the question of finding the PDF for the sum of statistically independent random variables. In this section, we will again consider the sum of statistically independent variables, but our approach will be different and does not depend on the partial PDFs of the random variables in the sum. In particular, assume that the sum terms are statistically independent and identically distributed random variables, each of which has limited means and limited variance.
Let be defined as the normalized sum, called the sample mean
First, we will determine upper bounds on the tail probability, and then we will prove a very important theorem that determines the PDF in the limit when it tends to infinity.
The random variable defined by (2.1.187) is often encountered when estimating the average of a random variable over a number of observations, . In other words, can be considered as independent sample realizations from a distribution, and is an estimate of the mean.
The mathematical expectation is
![]() .
.
The variance is

If we consider it as an estimate of the mean, we see that its mathematical expectation is equal to , and its dispersion decreases with increasing sample size. If it increases without limit, the variance tends to zero. Parameter estimate (in in this case), which satisfies the conditions that its mathematical expectation tends to the true value of the parameter, and the variance strictly approaches zero, is called a consistent estimate.
The tail probability of a random variable can be estimated from above using the bounds given in Section. 2.1.5. Chebyshev’s inequality in relation to has the form
![]() ,
,
 . (2.1.188)
. (2.1.188)
In the limit when , from (2.1.188) it follows
 . (2.1.189)
. (2.1.189)
Consequently, the probability that the estimate of the mean differs from the true value by more than , tends to zero if it grows without limit. This provision is a form of law large numbers. Since the upper bound converges to zero relatively slowly, i.e. inversely proportional. expression (2.1.188) is called weak law of large numbers.
If we apply the Chernoff boundary containing an exponential dependence on a random variable, then we obtain a dense upper limit for the probability of one tail. Following the procedure outlined in Sect. 2.1.5, we find that the tail probability for is determined by the expression
where and . But , are statistically independent and identically distributed. Hence,
where is one of the quantities. The parameter , which gives the most accurate upper bound, is obtained by differentiating (2.1.191) and equating the derivative to zero. This leads to the equation
![]() (2.1.192)
(2.1.192)
Let us denote the solution (2.1.192) by . Then the bound for the upper tail probability is
 ,
. (2.1.193)
,
. (2.1.193)
Similarly, we will find that the lower tail probability has the bound
![]() ,
. (2.1.194)
,
. (2.1.194)
Example 2.1.7. Let , be a series of statistically independent random variables defined as follows:

We want to define a tight upper bound on the probability that the sum of is greater than zero. Since , the amount will have negative value for the mathematical expectation (average), therefore, we will look for the upper tail probability. For in (2.1.193) we have
 , (2.1.195)
, (2.1.195)
where is the solution to the equation
Hence,
 . (2.1.197)
. (2.1.197)
![]()
Consequently, for the boundary in (2.1.195) we obtain
We see that the upper bound decreases exponentially with , as expected. In contrast, according to the Chebyshev bound, the tail probability decreases inversely with .
Central limit theorem. In this section, we consider an extremely useful theorem concerning the IDF of a sum of random variables in the limit when the number of terms of the sum increases without limit. There are several versions of this theorem. Let us prove the theorem for the case when the random summable variables , , are statistically independent and identically distributed, each of them has a limited mean and limited variance.
For convenience, we define a normalized random variable
Thus, it has zero mean and unit variance.
Now let
Since each summand of the sum has zero mean and unit variance, the value normalized (by the factor ) has zero mean and unit variance. We want to define the FMI for the limit when .
The characteristic function is equal to
 , (2.1.200).
, (2.1.200).
![]() ,
,
or, equivalently,
![]() . (2.1.206)
. (2.1.206)
But that's just it characteristic function Gaussian random variable with zero mean and unit variance. Thus we have important result; The PDF of the sum of statistically independent and identically distributed random variables with limited mean and variance approaches Gaussian at . This result is known as central limit theorem.
Although we have assumed that the random variables in the sum are equally distributed, this assumption can be relaxed provided that certain additional restrictions are still imposed on the properties of the random variables being summed. There is one variation of the theorem, for example, when the assumption of an identical distribution of random variables is abandoned in favor of a condition imposed on the third absolute moment of the random variables of the sum. For a discussion of this and other versions of the central limit theorem, the reader is referred to Cramer (1946).
Let the standard deviations of several mutually independent random variables be known. How to find the standard deviation of the sum of these quantities? The answer to this question is given by the following theorem.
Theorem. Standard deviation of the sum finite number mutually independent random variables are equal to square root from the sum of the squares of the standard deviations of these quantities."
Proof. Let us denote by X the sum of the mutually independent quantities under consideration:
![]()
The variance of the sum of several mutually independent random variables is equal to the sum of the variances of the terms (see § 5, Corollary 1), therefore
or finally
Identically distributed mutually independent random variables
It is already known that according to the distribution law one can find the numerical characteristics of a random variable. It follows that if several random variables have identical distributions, then their numerical characteristics are the same.
Let's consider n mutually independent random variables X v X v ..., Xfi, which have the same distributions, and therefore the same characteristics (mathematical expectation, dispersion, etc.). Of greatest interest is the study of the numerical characteristics of the arithmetic mean of these quantities, which is what we will do in this section.
Let us denote the arithmetic mean of the random variables under consideration by X:
The following three provisions establish a connection between the numerical characteristics of the arithmetic mean X and the corresponding characteristics of each individual quantity.
1. The mathematical expectation of the arithmetic mean of identically distributed mutually independent random variables is equal to the mathematical expectation a of each of the variables:
![]()
Proof. Using the properties of mathematical expectation (the constant factor can be taken out of the sign of the mathematical expectation; the mathematical expectation of the sum is equal to the sum of the mathematical expectations of the terms), we have

Taking into account that the mathematical expectation of each of the quantities according to the condition is equal to A, we get
2. The dispersion of the arithmetic mean of n identically distributed mutually independent random variables is n times less than the dispersion D of each of the variables:
Proof. Using the properties of dispersion (the constant factor can be taken out of the dispersion sign by squaring it; the dispersion of the sum of independent quantities is equal to the sum of the dispersions of the terms), we have
§ 9. Identically distributed mutually independent random variables 97
Taking into account that the dispersion of each of the quantities by condition is equal to D, we obtain
3. Standard deviation of the arithmetic mean of n identically distributed mutually independent random
values are 4n times less than the standard deviation a of each of the values:
Proof. Because D(X) = D/n then the standard deviation X equals
General conclusion from formulas (*) and (**): remembering that the dispersion and standard deviation serve as measures of the dispersion of a random variable, we conclude that the arithmetic mean of a sufficiently large number of mutually independent random variables has
significantly less scattering than each individual value.
Let us explain with an example the significance of this conclusion for practice.
Example. Usually, to measure a certain physical quantity, several measurements are made, and then the arithmetic mean of the obtained numbers is found, which is taken as an approximate value of the measured quantity. Assuming that the measurements are made under the same conditions, prove:
- a) the arithmetic mean gives a more reliable result than individual measurements;
- b) with an increase in the number of measurements, the reliability of this result increases.
Solution, a) It is known that individual measurements give unequal values of the measured quantity. The result of each measurement depends on many random reasons (temperature changes, instrument fluctuations, etc.), which cannot be fully taken into account in advance.
Therefore, we have the right to consider possible results n individual measurements as random variables X v X 2,..., X p(the index indicates the measurement number). These quantities have the same probability distribution (measurements are made using the same technique and the same instruments), and therefore the same numerical characteristics; in addition, they are mutually independent (the result of each individual measurement does not depend on other measurements).
We already know that the arithmetic mean of such quantities has less dispersion than each individual quantity. In other words, the arithmetic mean turns out to be closer to the true value of the measured value than the result of a separate measurement. This means that the arithmetic mean of several measurements gives a more case result than a single measurement.
b) We already know that as the number of individual random variables increases, the dispersion of the arithmetic mean decreases. This means that as the number of measurements increases, the arithmetic mean of several measurements differs less and less from the true value of the measured value. Thus, by increasing the number of measurements, a more reliable result is obtained.
For example, if the standard deviation of an individual measurement is a = 6 m, and a total of n= 36 measurements, then the standard deviation of the arithmetic mean of these measurements is only 1 m. Indeed,
We see that the arithmetic mean of several measurements, as one would expect, turned out to be closer to the true value of the measured value than the result of a separate measurement.
To solve many practical problems it is necessary to know the complex of conditions due to which the result of the cumulative impact large quantities random factors are almost independent of chance. These conditions are described in several theorems called common name the law of large numbers, where the random variable k is equal to 1 or 0 depending on whether the result of the kth trial is success or failure. Thus, Sn is the sum of n mutually independent random variables, each of which takes the values 1 and 0 with probabilities p and q.
The simplest form of the law of large numbers is Bernoulli's theorem, which states that if the probability of an event is the same in all trials, then as the number of trials increases, the frequency of the event tends to the probability of the event and ceases to be random.
Poisson's theorem states that the frequency of an event in a series independent tests tends to the arithmetic mean of its probabilities and ceases to be random.
Limit theorems of probability theory, the Moivre-Laplace theorem explain the nature of the stability of the frequency of occurrence of an event. This nature lies in the fact that the limiting distribution of the number of occurrences of an event with an unlimited increase in the number of trials (if the probability of the event is the same in all trials) is a normal distribution.
Central limit theorem explains the widespread distribution of the normal distribution law. The theorem states that whenever a random variable is formed as a result of the addition of a large number of independent random variables with finite variances, the distribution law of this random variable turns out to be an almost normal law.
Lyapunov's theorem explains the widespread distribution of the normal distribution law and explains the mechanism of its formation. The theorem allows us to state that whenever a random variable is formed as a result of the addition of a large number of independent random variables, the variances of which are small compared to the dispersion of the sum, the distribution law of this random variable turns out to be an almost normal law. And since random variables are always generated infinite number reasons and most often none of them has a dispersion comparable to the dispersion of the random variable itself, then most random variables encountered in practice are subject to normal law distributions.
The qualitative and quantitative statements of the law of large numbers are based on Chebyshev inequality. It determines the upper limit of the probability that the deviation of the value of a random variable from its mathematical expectation is greater than a certain given number. It is remarkable that Chebyshev’s inequality gives an estimate of the probability of an event for a random variable whose distribution is unknown, only its mathematical expectation and variance are known.
Chebyshev's inequality. If a random variable x has variance, then for any x > 0 the inequality is true, where M x and D x - mathematical expectation and variance of the random variable x.
Bernoulli's theorem. Let x n be the number of successes in n Bernoulli trials and p the probability of success in an individual trial. Then for any s > 0 it is true.
Lyapunov's theorem. Let s 1, s 2, …, s n, …- unlimited sequence independent random variables with mathematical expectations m 1, m 2, …, m n, … and variances s 1 2, s 2 2, …, s n 2 …. Let's denote.
Then = Ф(b) - Ф(a) for any real numbers a and b, where Ф(x) is the normal distribution function.
Let a discrete random variable be given. Let us consider the dependence of the number of successes Sn on the number of trials n. On each trial, Sn increases by 1 or 0. This statement can be written as:
Sn = 1 +…+ n. (1.1)
Law of Large Numbers. Let (k) be a sequence of mutually independent random variables with identical distributions. If the mathematical expectation = M(k) exists, then for any > 0 for n
In other words, the probability that the average S n /n differs from the mathematical expectation by less than an arbitrarily given value tends to one.
Central limit theorem. Let (k) be a sequence of mutually independent random variables with identical distributions. Let's assume that they exist. Let Sn = 1 +…+ n , Then for any fixed
F () -- F () (1.3)
Here F (x) -- normal function I distribute. This theorem was formulated and proved by Linlberg. Lyapunov and other authors proved it earlier, under more restrictive conditions. It is necessary to imagine that the theorem formulated above is only a very special case of a much more general theorem, which in turn is closely related to many other limit theorems. Note that (1.3) is much stronger than (1.2), since (1.3) gives an estimate for the probability that the difference is greater than. On the other hand, the law of large numbers (1.2) is true even if the random variables k do not have finite variance, so it applies to more general case than the central limit theorem (1.3). Let us illustrate the last two theorems with examples.
Examples. a) Consider a sequence of independent throws of a symmetrical die. Let k be the number of points obtained during the kth throw. Then
M(k)=(1+2+3+4+5+6)/6=3.5,
a D(k)=(1 2 +2 2 +3 2 +4 2 +5 2 +6 2)/6-(3.5) 2 =35/12 and S n /n
is the average number of points resulting from n throws.
The law of large numbers states that it is plausible that for large n this average will be close to 3.5. The Central Limit Theorem states the probability that |Sn -- 3.5n |< (35n/12) 1/2 близка к Ф() -- Ф(-). При n = 1000 и а=1 мы находим, что вероятность неравенства 3450 < Sn < 3550 равна примерно 0,68. Выбрав для а значение а 0 = 0,6744, удовлетворяющее соотношению Ф(0)-- Ф(-- 0)=1/2, мы получим, что для Sn шансы находиться внутри или вне интервала 3500 36 примерно одинаковы.
b) Sampling. Let's assume that in population,
consisting of N families, Nk families have exactly k children each
(k = 0, 1 ...; Nk = N). If a family is selected at random, then the number of children in it is a random variable that takes a value with probability p = N/N. In back-to-back selection, one can view a sample of size n as a collection of n independent random variables or "observations" 1, ..., n that all have the same distribution; S n /n is the sample mean. The law of large numbers states that for a sufficiently large random sample its mean will probably be close to, that is, the population mean. The central limit theorem allows one to estimate the likely magnitude of the discrepancy between these means and determine the sample size required for a reliable estimate. In practice, and and are usually unknown; however, in most cases it is easy to obtain a preliminary estimate for and can always be enclosed within reliable boundaries. If we want a probability of 0.99 or greater that the sample mean S n /n differs from the unknown population mean by less than 1/10, then the sample size must be taken such that
The x root of the equation Ф(x) - Ф(-- x) = 0.99 is equal to x = 2.57 ..., and therefore n must be such that 2.57 or n > 660. A careful preliminary estimate makes it possible to find the required sample size.
c) Poisson distribution.
Suppose that the random variables k have a Poisson distribution (p(k;)). Then Sn has a Poisson distribution with mathematical expectation and variance equal to n.
By writing instead of n, we conclude that for n

The summation is performed over all k from 0 to. Ph-la (1.5) also holds when in an arbitrary way.
They say they are independent (and) identically distributed, if each of them has the same distribution as the others, and all quantities are independent in the aggregate. The phrase "independent identically distributed" is often abbreviated as i.i.d.(from English independent and identically-distributed ), sometimes - “n.o.r”.
Applications
The assumption that random variables are independent and identically distributed is widely used in probability theory and statistics, as it allows one to greatly simplify theoretical calculations and prove interesting results.
One of the key theorems of probability theory - the central limit theorem - states that if is a sequence of independent identically distributed random variables, then, as they tend to infinity, the distribution of their average - random variable converges to the normal distribution.
In statistics, it is generally assumed that a statistical sample is a sequence of i.i.d. realizations of some random variable (such a sample is called simple).
Wikimedia Foundation. 2010.
- I.e.
- Intel 8048
See what “Independent identically distributed random variables” are in other dictionaries:
Gambler's Ruin Problem- The problem of the player's ruin is a problem from the field of probability theory. discussed in detail Russian mathematician A. N. Shiryaev in the monograph “Probability” ... Wikipedia
Sustainable distribution- in probability theory, this is a distribution that can be obtained as a limit on the distribution of sums of independent random variables. Contents 1 Definition 2 Notes ... Wikipedia
Levy-Khinchin formula for stable distribution- A stable distribution in probability theory is a distribution that can be obtained as a limit on the distribution of sums of independent random variables. Contents 1 Definition 2 Remarks 3 Properties stable distributions... Wikipedia
Infinitely divisible distribution- in probability theory, this is the distribution of a random variable such that it can be represented in the form of an arbitrary number of independent, identically distributed terms. Contents 1 Definition ... Wikipedia
Cramer-Lundberg model- Kramer Lundberg model mathematical model, which allows you to assess the risks of ruin of an insurance company. Within the framework of this model, it is assumed that insurance premiums are received uniformly, at a rate from the conditional monetary units per unit... ... Wikipedia
Levy-Khinchin formula for infinitely divisible distribution- An infinitely divisible distribution in probability theory is a distribution of a random variable such that it can be represented as an arbitrary number of independent, identically distributed terms. Contents 1 Definition 2 ... ... Wikipedia
Cramer model- This article should be Wikified. Please format it according to the article formatting rules. The Cramer Lundberg model is a mathematical model that allows one to assess the risks of bankruptcy of an insurance company... Wikipedia
Acceptance statistical control- totality statistical methods control of mass products in order to determine their compliance with specified requirements. P.S. j. an effective means of ensuring the good quality of mass products. P.S. to. is carried out on... ... Great Soviet Encyclopedia
Multinomial distribution- Multinomial (polynomial) distribution in probability theory is a generalization binomial distribution in case of independent tests random experiment with several possible outcomes. Definition Let independent... ... Wikipedia
Polynomial distribution- Multinomial (polynomial) distribution in probability theory is a generalization of the binomial distribution to the case of independent tests of a random experiment with several possible outcomes. Definition: Let the independent be equally... ... Wikipedia