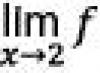El criterio de Durbin-Watson se reduce a probar una hipótesis:
- H 0 (hipótesis principal): ρ = 0
- H 1 (hipótesis alternativa): ρ > 0 o ρ
Para probar la hipótesis principal se utiliza la estadística de la prueba de Durbin-Watson - DW:Donde e i = y - y(x)
Esto se hace usando tres calculadoras:
- Ecuación de tendencia (regresión lineal y no lineal)
Consideremos la tercera opción. La ecuación de tendencia lineal es y = at + b
1. Encuentre los parámetros de la ecuación utilizando el método de mínimos cuadrados a través del servicio en línea Trend Equation.
Sistema de ecuaciones
Para nuestros datos, el sistema de ecuaciones tiene la forma
De la primera ecuación expresamos un 0 y lo sustituimos en la segunda ecuación.
Obtenemos un 0 = -12,78, un 1 = 26763,32
Ecuación de tendencia
y = -12,78 t + 26763,32
Evaluemos la calidad de la ecuación de tendencia utilizando el error de aproximación absoluto.
Dado que el error es superior al 15%, no es recomendable utilizar esta ecuación como tendencia.
Valores medios
Dispersión
Desviación estándarÍndice de determinación
, es decir. en el 97,01% de los casos afecta a los cambios de datos. En otras palabras, la precisión al seleccionar la ecuación de tendencia es alta.t y t 2 y 2 t∙y y(t) (y-y cp) 2 (yy(t)) 2 (t-t p) 2 (y-y(t)) : y 1990 1319 3960100 1739761 2624810 1340.26 18117.16 451.99 148.84 28041.86 1996 1288 3984016 1658944 2570848 1263.61 10732.96 594.99 38.44 31417.53 2001 1213 4004001 1471369 2427213 1199.73 817.96 176.08 1.44 16095.92 2002 1193 4008004 1423249 2388386 1186.96 73.96 36.54 0.04 7211.59 2003 1174 4012009 1378276 2351522 1174.18 108.16 0.03 0.64 210.94 2004 1159 4016016 1343281 2322636 1161.4 645.16 5.78 3.24 2786.55 2005 1145 4020025 1311025 2295725 1148.63 1552.36 13.17 7.84 4155.05 2006 1130 4024036 1276900 2266780 1135.85 2959.36 34.26 14.44 6614.41 2007 1117 4028049 1247689 2241819 1123.08 4542.76 36.94 23.04 6789.19 2008 1106 4032064 1223236 2220848 1110.3 6146.56 18.51 33.64 4758.73 20022 11844 40088320 14073730 23710587 11844 45696.4 1368.3 271.6 108081.77 Prueba de Durbin-Watson para la presencia de autocorrelación de residuos para una serie temporal.
y y(x) mi yo = yy(x) mi 2 (e i - e i-1) 2 1319 1340.26 -21.26 451.99 0 1288 1263.61 24.39 594.99 2084.14 1213 1199.73 13.27 176.08 123.72 1193 1186.96 6.04 36.54 52.19 1174 1174.18 -0.18 0.03 38.75 1159 1161.4 -2.4 5.78 4.95 1145 1148.63 -3.63 13.17 1.5 1130 1135.85 -5.85 34.26 4.95 1117 1123.08 -6.08 36.94 0.05 1106 1110.3 -4.3 18.51 3.15 1368.3 2313.41
Los valores críticos d 1 y d 2 se determinan sobre la base de tablas especiales para el nivel de significancia requerido a, el número de observaciones n y el número de variables explicativas m.
Sin consultar tablas, puede utilizar una regla aproximada y suponer que no existe autocorrelación de residuos si 1,5< DW < 2.5. Для более надежного вывода целесообразно обращаться к табличным значениям.
re 1< DW и d 2 < DW < 4 - d 2 .Ejemplo. Con base en datos de 24 meses, se construyó una ecuación de regresión para la dependencia de las ganancias de una organización agrícola de la productividad laboral (x1): y = 300 + 5x.
Se obtuvieron los siguientes resultados intermedios:
∑ε2 = 18500
∑(ε t - ε t-1) 2 = 41500
Calcular el criterio de Durbin-Watson (con n=24 y k=1 (número de factores), valor inferior d = 1,27, valor superior d = 1,45. Sacar conclusiones.Solución.
DW = 41500/18500 = 2,24
d 2 = 4- 1,45 = 2,55
Dado que DW > 2,55, hay motivos para creer que no existe autocorrelación. Esta es una de las confirmaciones de la alta calidad de la ecuación de regresión resultante y = 300 + 5x.
La prueba de Durbin-Watson (o prueba DW) es una prueba estadística que se utiliza para encontrar la autocorrelación de primer orden de elementos de la secuencia en estudio. Se utiliza con mayor frecuencia en el análisis de series temporales y residuos de modelos de regresión. El criterio lleva el nombre de James Durbin y Geoffrey Watson. El criterio de Durbin-Watson se calcula mediante la siguiente fórmula
donde ρ1 es el coeficiente de autocorrelación de primer orden.
En ausencia de autocorrelación d = 2, con autocorrelación positiva d tiende a cero y con autocorrelación negativa - a 4:

En la práctica, la aplicación de la prueba de Durbin-Watson se basa en comparar el valor de d con los valores teóricos de dL y dU para un número dado de observaciones n, el número de variables independientes del modelo k y el nivel de significancia. α.
si d< dL, то гипотеза о независимости случайных отклонений отвергается (следовательно присутствует положительная автокорреляция);
Si d > dU, entonces la hipótesis no se rechaza;
si dL< d < dU, то нет достаточных оснований для принятия решений.
Cuando el valor calculado de d excede 2, entonces no es el coeficiente d en sí el que se compara con dL y dU, sino la expresión (4 − d).
Además, utilizando este criterio se detecta la presencia de cointegración entre dos series temporales. En este caso, se prueba la hipótesis de que el valor real del criterio es cero. Utilizando el método de Monte Carlo se obtuvieron valores críticos para niveles de significancia dados. Si el valor real del criterio de Durbin-Watson excede el valor crítico, entonces se rechaza la hipótesis nula de ausencia de cointegración.
Defectos:
Incapaz de detectar autocorrelación de segundo y superior orden.
Proporciona resultados fiables sólo para muestras grandes.
13. Indicadores comparables de cercanía de la conexión
Los indicadores comparables de la cercanía de la comunicación incluyen:
1) coeficientes de elasticidad parcial;
2) coeficientes de regresión parcial estandarizados;
3) coeficiente de determinación parcial.
Si las variables factoriales tienen unidades de medida incomparables, entonces la relación entre ellas se mide utilizando indicadores comparables de la cercanía de la conexión. Utilizando indicadores comparables de la cercanía de la conexión, se caracteriza el grado de dependencia entre las variables factoriales y de resultado en un modelo de regresión múltiple.
El coeficiente de elasticidad parcial se calcula mediante la fórmula:

– el valor medio de la variable factorial xi para la población de muestra,
– el valor medio de la variable resultante y para la población de muestra;
– la primera derivada de la variable resultante y con respecto a la variable factorial x.
El coeficiente de elasticidad parcial se mide como porcentaje y caracteriza la cantidad de cambio en la variable resultante y cuando cambia un 1% del nivel promedio de la variable factorial xi, siempre que todas las demás variables factoriales incluidas en el modelo de regresión sean constantes.
Para un modelo de regresión lineal, el coeficiente de elasticidad parcial se calcula mediante la fórmula:

donde βi es el coeficiente del modelo de regresión múltiple.
Para calcular los coeficientes de regresión parcial estandarizados, es necesario construir un modelo de regresión múltiple en una escala estándar (normalizada). Esto significa que todas las variables incluidas en el modelo de regresión están estandarizadas mediante fórmulas especiales. A través del proceso de estandarización, el punto de referencia para cada variable normalizada se establece en su valor promedio sobre la población de la muestra. En este caso, se toma su desviación estándar β como unidad de medida de la variable estandarizada.
La variable factor x se convierte a una escala estandarizada mediante la fórmula:

donde xij es el valor de la variable xj en la i-ésima observación;
G(xj) – desviación estándar de la variable factorial xi;
![]()
La variable resultante y se convierte a una escala estandarizada mediante la fórmula:

donde G(y) es la desviación estándar de la variable resultante y.
Los coeficientes de regresión parcial estandarizados caracterizan por qué proporción de su desviación estándar G(y) la variable resultante y cambiará cuando la variable factor x cambie en el valor de su desviación estándar G(x), siempre que todas las demás variables factoriales incluidas en la regresión modelo son constantes.
El coeficiente de regresión parcial estandarizado caracteriza el grado de dependencia directa o directa entre las variables de resultado y factoriales. Pero debido al hecho de que existe una dependencia entre las variables factoriales incluidas en el modelo de regresión múltiple, la variable factorial no sólo tiene un efecto directo, sino también indirecto sobre la variable de resultado.
El coeficiente de determinación parcial se utiliza para caracterizar el grado de influencia indirecta de la variable factorial x sobre la variable resultante y:
![]()
donde βi es el coeficiente de regresión parcial estandarizado;
r(xixj) – coeficiente de correlación parcial entre las variables factoriales xi y xj.
El coeficiente de determinación parcial caracteriza el porcentaje de variación en la variable de resultado causada por la variación de la i-ésima variable del factor incluida en el modelo de regresión múltiple, siempre que todas las demás variables de los factores incluidas en el modelo de regresión sean constantes.
Los coeficientes de regresión parcial estandarizados y los coeficientes de elasticidad parcial pueden dar resultados diferentes. Esta discrepancia puede explicarse, por ejemplo, por una desviación estándar demasiado grande de una de las variables factoriales o por el efecto ambiguo de una de las variables factoriales sobre la variable de resultado.
Un requisito previo importante para construir un modelo de regresión cualitativo utilizando MCO es la independencia de los valores de las desviaciones aleatorias de los valores de las desviaciones en todas las demás observaciones. La ausencia de dependencia garantiza la ausencia de correlación entre cualquier desviación, es decir ![]() y, en particular, entre desviaciones adyacentes
y, en particular, entre desviaciones adyacentes ![]() .
.
Autocorrelación (correlación serial) sobras se define como la correlación entre valores adyacentes de desviaciones aleatorias en el tiempo (series de tiempo) o en el espacio (datos transversales). Suele ocurrir en series temporales y muy raramente en datos espaciales.
Son posibles los siguientes casos:
Estos casos pueden indicar una oportunidad para mejorar la ecuación estimando una nueva fórmula no lineal o incluyendo una nueva variable explicativa.
En los problemas económicos, la autocorrelación positiva es mucho más común que la autocorrelación negativa.
Si la naturaleza de las desviaciones es aleatoria., entonces podemos suponer que en la mitad de los casos los signos de desviaciones adyacentes coinciden y en la mitad son diferentes.
La autocorrelación en los residuos puede deberse a varias razones de diferente naturaleza.
1. Puede estar relacionado con los datos de origen y ser causado por la presencia de errores de medición en los valores de la característica resultante.
2. En algunos casos, la autocorrelación puede ser consecuencia de una especificación errónea del modelo. El modelo puede no incluir un factor que tenga un impacto significativo en el resultado y cuya influencia se refleje en los residuos, por lo que estos últimos pueden resultar autocorrelacionados. Muy a menudo este factor es el factor tiempo.
Se debe distinguir de la verdadera autocorrelación de residuos situaciones en las que la causa de la autocorrelación radica en la especificación incorrecta de la forma funcional del modelo. En este caso, se debe cambiar la forma del modelo en lugar de utilizar métodos especiales para calcular los parámetros de la ecuación de regresión en presencia de autocorrelación en los residuos.
Para detectar la autocorrelación, se utiliza un método gráfico. O pruebas estadísticas.
Método gráfico Consiste en trazar errores versus tiempo (en el caso de series temporales) o variables explicativas y determinar visualmente la presencia o ausencia de autocorrelación.
El criterio más conocido para detectar la autocorrelación de primer orden es el criterio Durbin-Watson. Estadística DW Durbin-Watson se indica en todos los programas informáticos especiales como una de las características más importantes de la calidad de un modelo de regresión.
Primero, utilizando la ecuación de regresión empírica construida, se determinan los valores de desviación. ![]() . Y luego la estadística de Durbin-Watson se calcula mediante la fórmula:
. Y luego la estadística de Durbin-Watson se calcula mediante la fórmula:
 .
.
Estadística DW varía de 0 a 4. DW=0 corresponde positivo autocorrelación, con negativo autocorrelación DW=4 . Cuando sin autocorrelación, el coeficiente de autocorrelación es cero y las estadísticas DW = 2 .
El algoritmo para identificar la autocorrelación de residuos basado en la prueba de Durbin-Watson es el siguiente.
Se plantea una hipótesis sobre la ausencia de autocorrelación de residuos. Las hipótesis alternativas consisten, respectivamente, en la presencia de autocorrelación positiva o negativa en los residuos. A continuación, utilizando tablas especiales, se determinan los valores críticos del criterio de Durbin-Watson (- el límite inferior para reconocer la autocorrelación positiva) y (- el límite superior para reconocer la ausencia de autocorrelación positiva) para un número determinado de observaciones, el número de variables independientes del modelo y el nivel de significancia. A partir de estos valores, el intervalo numérico se divide en cinco segmentos. La aceptación o rechazo de cada hipótesis con probabilidad se realiza de la siguiente manera:
– autocorrelación positiva, aceptada;
![]() – zona de incertidumbre;
– zona de incertidumbre;
![]() – no hay autocorrelación;
– no hay autocorrelación;
– zona de incertidumbre;
![]() – autocorrelación negativa, aceptada.
– autocorrelación negativa, aceptada.
 |
Si el valor real de la prueba de Durbin-Watson cae en la zona de incertidumbre, entonces en la práctica se supone la existencia de autocorrelación de los residuos y se rechaza la hipótesis.
Se puede demostrar que las estadísticas DW está estrechamente relacionado con el coeficiente de autocorrelación de primer orden:

La relación se expresa mediante la fórmula: ![]() .
.
Valores r varían de –1 (en el caso de autocorrelación negativa) a +1 (en el caso de autocorrelación positiva). Proximidad r a cero indica la ausencia de autocorrelación.
A falta de tablas de valores críticos DW puede utilizar la siguiente regla “aproximada”: con un número suficiente de observaciones (12-15), con 1-3 variables explicativas, si ![]() , entonces las desviaciones de la línea de regresión pueden considerarse mutuamente independientes.
, entonces las desviaciones de la línea de regresión pueden considerarse mutuamente independientes.
O aplicar una transformación reductora de autocorrelación a los datos (por ejemplo, una transformación de autocorrelación o un método de media móvil).
Existen varias limitaciones para el uso de la prueba de Durbin-Watson.
1. Criterio DW Se aplica sólo a aquellos modelos que contienen un término ficticio.
2. Se supone que las desviaciones aleatorias se determinan mediante un esquema iterativo.
![]() ,
,
3. Los datos estadísticos deben tener la misma frecuencia (no debe haber lagunas en las observaciones).
4. El criterio de Durbin-Watson no es aplicable a modelos autorregresivos que también contienen entre los factores una variable dependiente con un desfase temporal (retraso) de un período.
![]() ,
,
¿Dónde está la estimación del coeficiente de autocorrelación de primer orden? Corriente continua)– varianza muestral del coeficiente de la variable rezagada y t -1 , norte– número de observaciones.
Normalmente el valor se calcula mediante la fórmula ![]() , A Corriente continua) igual al cuadrado del error estándar S do estimaciones de coeficientes Con.
, A Corriente continua) igual al cuadrado del error estándar S do estimaciones de coeficientes Con.
Si existe autocorrelación de los residuos, la fórmula de regresión resultante suele considerarse insatisfactoria. La autocorrelación de errores de primer orden indica una especificación errónea del modelo. Por lo tanto, deberías intentar ajustar el modelo en sí. Después de mirar el gráfico de error, puede buscar otra fórmula de dependencia (no lineal), incluir factores que no se tuvieron en cuenta antes, aclarar el período de cálculo o dividirlo en partes.
Si todos estos métodos no ayudan y la autocorrelación es causada por algunas propiedades internas de la serie ( y yo), puedes usar una transformación llamada esquema autorregresivo de primer orden RA(1). (por autorregresión Esta conversión se llama porque el valor del error está determinado por el valor de la misma cantidad, pero con un retraso. el retraso máximo es 1, entonces esto es autorregresión primer orden).
Fórmula RA(1) tiene la forma: . .
¿Dónde está el coeficiente de autocorrelación de primer orden de los errores de regresión?
consideremos RA(1) usando la regresión pareada como ejemplo:
![]() .
.
Entonces las observaciones vecinas corresponden a la fórmula:
![]() (1),
(1),
![]() (2).
(2).
Multiplica (2) por y resta de (1):
Hagamos cambios de variables.
obtenemos teniendo en cuenta:
![]() (6)
.
(6)
.
Dado que las varianzas aleatorias satisfacen los supuestos de MCO, las estimaciones A * Y b tendrá las propiedades de los mejores estimadores lineales insesgados. A partir de los valores transformados de todas las variables, las estimaciones de los parámetros se calculan utilizando mínimos cuadrados ordinarios. A* Y b, que luego puede usarse en regresión.
Eso. Si los residuos de la ecuación de regresión original están autocorrelacionados, entonces se utilizan las siguientes transformaciones para estimar los parámetros de la ecuación:
1) Convertir variables originales en Y incógnita para formar (3), (4).
2) Utilizando el método habitual de mínimos cuadrados para la ecuación (6), determine las estimaciones A * Y b.
4) Escriba la ecuación original (1) con parámetros. A Y b(Dónde A- de la cláusula 3, a b se toma directamente de la ecuación (6)).
Para convertir RA(1) es importante estimar el coeficiente de autocorrelación ρ . Esto se hace de varias maneras. Lo más sencillo es evaluar. ρ basado en estadísticas DW:
![]() ,
,
Dónde r tomado como una estimación ρ . Este método funciona bien con una gran cantidad de observaciones.
En el caso de que haya motivos para creer que la autocorrelación positiva de las desviaciones es muy grande ( ![]() ), se puede utilizar método de primera diferencia (método de eliminación de tendencia), la ecuación toma la forma
), se puede utilizar método de primera diferencia (método de eliminación de tendencia), la ecuación toma la forma
![]() .
.
A partir de la ecuación utilizando el método de mínimos cuadrados se estima el coeficiente b. Parámetro A aquí no se determina directamente, pero se sabe por mínimos cuadrados que .
En el caso de autocorrelación negativa completa de desviaciones ()
Obtenemos la ecuación de regresión:
o ![]() .
.
Se calculan los promedios de 2 períodos y luego se calculan a partir de ellos. A Y b. Este modelo se llama modelo de regresión de media móvil.
donde ρ 1 es el coeficiente de autocorrelación de primer orden.
En ausencia de autocorrelación de errores. d= 2, con autocorrelación positiva d tiende a cero y con autocorrelación negativa d tiende a 4:

En la práctica, la aplicación del criterio de Durbin-Watson se basa en comparar el valor d con valores teóricos d l Y d Ud. para un número dado de observaciones norte, número de variables independientes del modelo k y nivel de significancia α.
- Si d < dL, entonces se rechaza la hipótesis sobre la independencia de las desviaciones aleatorias (por tanto, existe una autocorrelación positiva);
- Si d > du, entonces la hipótesis no se rechaza;
- Si dL < d < du, entonces no hay motivos suficientes para tomar decisiones.
Cuando el valor calculado d excede 2, entonces con d l Y d Ud. No es el coeficiente en sí lo que se compara. d, y la expresión (4 − d) .
Además, utilizando este criterio se detecta la presencia de cointegración entre dos series temporales. En este caso, se prueba la hipótesis de que el valor real del criterio es cero. Utilizando el método de Monte Carlo se obtuvieron valores críticos para niveles de significancia dados. Si el valor real del criterio de Durbin-Watson excede el valor crítico, entonces se rechaza la hipótesis nula de ausencia de cointegración.
Defectos
prueba h de Durbin
Criterio h Durbin se utiliza para identificar la autocorrelación de residuos en un modelo con rezagos distribuidos:

- Dónde norte- número de observaciones en el modelo;
- V- error estándar de la variable de resultado rezagada.
A medida que aumenta el tamaño de la muestra, la distribución h-la estadística tiende a ser normal con expectativa matemática cero y varianza igual a 1. Por tanto, la hipótesis sobre la ausencia de autocorrelación de residuos se rechaza si el valor real h-la estadística resulta ser mayor que el valor crítico de la distribución normal.
Prueba de Durbin-Watson para datos de panel
Para datos de panel, se utiliza una prueba de Durbin-Watson ligeramente modificada:

A diferencia de la prueba de Durbin-Watson para series temporales, en este caso el rango de incertidumbre es muy estrecho, especialmente para paneles con un gran número de individuos.
Ver también
- Método de serie
- Prueba Ljung-Box Q
- método de Cochran-Orcutt
Notas
Literatura
- Anayolyev S. Efectos individuales aleatorios y estadísticos de Durbin-Watson // Teoría Econométrica (Problemas y Soluciones). - 2002-2003.
Campo de golf
Fundación Wikimedia.
2010.
Vea qué es el "Criterio de Durbin-Watson" en otros diccionarios:
La prueba de Durbin Watson (o prueba DW) es una prueba estadística que se utiliza para probar la autocorrelación de primer orden de elementos de la secuencia en estudio. Se utiliza con mayor frecuencia en el análisis de series de tiempo y... ... Wikipedia Criterio de Durbin-Watson - un indicador condicional que se utiliza para identificar la autocorrelación en series temporales (indicado por d). El indicador d se calcula mediante la fórmula donde yt+1 e yt son los niveles correspondientes de la serie. En ausencia... ...
Diccionario económico-matemático Criterio de Durbin-Watson Guía del traductor técnico
La autocorrelación es una relación estadística entre variables aleatorias de la misma serie, pero tomadas con un desplazamiento, por ejemplo, para un proceso aleatorio con un desplazamiento en el tiempo. Este concepto es ampliamente utilizado en econometría. Disponibilidad... ... Wikipedia
La prueba de autocorrelación de Breusch Godfrey, también llamada prueba LM de correlación serial de Breusch Godfrey, es un procedimiento utilizado en econometría para probar la autocorrelación de un orden arbitrario en forma aleatoria ... ... Wikipedia
Una prueba estadística diseñada para encontrar la autocorrelación de series temporales. En lugar de probar la aleatoriedad de cada coeficiente individual, prueba varios coeficientes de autocorrelación a la vez para detectar diferencias desde cero: donde n... ... Wikipedia
Una prueba estadística diseñada para encontrar la autocorrelación de series temporales. En lugar de probar la aleatoriedad de cada coeficiente individual, prueba varios coeficientes de autocorrelación a la vez para detectar diferencias desde cero.... ... Wikipedia
La estadística Box-Pierce es una prueba estadística diseñada para encontrar la autocorrelación de series temporales. En lugar de probar la aleatoriedad de cada coeficiente individual, prueba varios coeficientes a la vez para detectar diferencias desde cero... Wikipedia
La prueba de Ljung Box es un criterio estadístico diseñado para encontrar la autocorrelación de series temporales. En lugar de probar la aleatoriedad de cada coeficiente individual, prueba varios coeficientes a la vez para detectar diferencias desde cero... ... Wikipedia
Gráfica de 100 variables aleatorias con onda sinusoidal oculta. La función de autocorrelación le permite ver la periodicidad de una serie de datos. La autocorrelación es una relación estadística entre variables aleatorias de la misma serie, pero tomadas con un desplazamiento,... ... Wikipedia
La prueba de Durbin-Watson (o prueba DW) es una prueba estadística que se utiliza para encontrar la autocorrelación de los residuos de primer orden de un modelo de regresión. El criterio lleva el nombre de James Durbin y Geoffrey Watson. El criterio de Durbin-Watson se calcula mediante la siguiente fórmula:
donde ρ 1 es el coeficiente de autocorrelación de primer orden.
En ausencia de autocorrelación de errores. d= 2, con autocorrelación positiva d tiende a cero y con autocorrelación negativa d tiende a 4:

En la práctica, la aplicación del criterio de Durbin-Watson se basa en comparar el valor d con valores teóricos dL Y du para un número dado de observaciones norte, número de variables independientes del modelo k y nivel de significancia α.
Si d < dL, entonces se rechaza la hipótesis sobre la independencia de las desviaciones aleatorias (por tanto, existe una autocorrelación positiva);
Si d > du, entonces la hipótesis no se rechaza;
Si dL < d < du, entonces no hay motivos suficientes para tomar decisiones.
Cuando el valor calculado d excede 2, entonces con dL Y du No es el coeficiente en sí lo que se compara. d, y la expresión (4 − d).
Además, utilizando este criterio se detecta la presencia de cointegración entre dos series temporales. En este caso, se prueba la hipótesis de que el valor real del criterio es cero. Utilizando el método de Monte Carlo se obtuvieron valores críticos para niveles de significancia dados. Si el valor real del criterio de Durbin-Watson excede el valor crítico, entonces se rechaza la hipótesis nula de ausencia de cointegración.
Incapaz de detectar autocorrelación de segundo y superior orden.
Da resultados fiables sólo para muestras grandes].
Criterio h Durbin se utiliza para identificar la autocorrelación de residuos en un modelo con rezagos distribuidos:

Dónde norte- número de observaciones en el modelo;
V- error estándar de la variable de resultado rezagada.
A medida que aumenta el tamaño de la muestra, la distribución h-la estadística tiende a ser normal con expectativa matemática cero y varianza igual a 1. Por lo tanto, la hipótesis sobre la ausencia de autocorrelación de residuos se rechaza si el valor real h-la estadística resulta ser mayor que el valor crítico de la distribución normal.
Prueba de Durbin-Watson para datos de panel
Para datos de panel, se utiliza una prueba de Durbin-Watson ligeramente modificada:

A diferencia de la prueba de Durbin-Watson para series temporales, en este caso el área de incertidumbre es muy estrecha, especialmente para paneles con un gran número de individuos.
- Métodos para eliminar la autocorrelación (desviaciones de la tendencia, diferencias secuenciales, incluido el factor tiempo).
La esencia de todos los métodos de eliminación de tendencia es eliminar la influencia del factor tiempo en la formación de ecuaciones de series temporales. Los métodos principales se dividen en 2 grupos:
Basado en la transformación de niveles de series en nuevas variables que no contienen tendencia. Utilizamos las variables obtenidas más para analizar la relación de la serie temporal estudiada. Estos métodos implican eliminar el componente de tendencia. t de cada nivel de la serie temporal. 1.Método de diferencia secuencial. 2.Método de desviación de las tendencias.
Modelos basados en el estudio de las relaciones entre los niveles iniciales de series temporales, excluyendo el impacto del factor tiempo sobre las variables dependientes e independientes: inclusión del factor tiempo en el modelo de regresión.