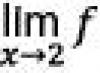Cualquier muestra da sólo una idea aproximada de la población general, y todas las características estadísticas de la muestra (media, moda, varianza...) son alguna aproximación o digamos una estimación de parámetros generales, que en la mayoría de los casos no son posibles de calcular debido. a la inaccesibilidad de la población en general (Figura 20) .
Figura 20. Error de muestreo
Pero se puede especificar el intervalo en el que, con un cierto grado de probabilidad, se encuentra el valor verdadero (general) de la característica estadística. Este intervalo se llama d intervalo de confianza (IC).
Entonces el valor promedio general con una probabilidad del 95% se encuentra dentro
desde hasta, (20)
Dónde t – valor de la tabla de la prueba de Student para α =0,05 y F= norte-1
También se puede encontrar un IC del 99%, en este caso t seleccionado para α =0,01.
¿Cuál es el significado práctico de un intervalo de confianza?
Un intervalo de confianza amplio indica que la media muestral no refleja con precisión la media poblacional. Esto suele deberse a un tamaño de muestra insuficiente o a su heterogeneidad, es decir. gran dispersión. Ambos dan un error de la media mayor y, en consecuencia, un IC más amplio. Y esta es la base para volver a la etapa de planificación de la investigación.
Los límites superior e inferior del IC proporcionan una estimación de si los resultados serán clínicamente significativos.
Detengámonos con cierto detalle en la cuestión de la importancia estadística y clínica de los resultados del estudio de las propiedades grupales. Recordemos que la tarea de la estadística es detectar al menos algunas diferencias en las poblaciones generales a partir de datos muestrales. El desafío para los médicos es detectar diferencias (no cualquier diferencia) que ayuden al diagnóstico o al tratamiento. Y las conclusiones estadísticas no siempre son la base de las conclusiones clínicas. Por tanto, una disminución estadísticamente significativa de la hemoglobina de 3 g/l no es motivo de preocupación. Y, a la inversa, si algún problema en el cuerpo humano no está muy extendido a nivel de toda la población, esto no es motivo para no abordarlo.
|
Veamos esta situación ejemplo. Los investigadores se preguntaron si los niños que han sufrido algún tipo de enfermedad infecciosa van a la zaga en crecimiento con respecto a sus compañeros. Para ello se realizó un estudio muestral en el que participaron 10 niños que habían padecido esta enfermedad. Los resultados se presentan en la Tabla 23. Tabla 23. Resultados del procesamiento estadístico
De estos cálculos se deduce que la altura media de la muestra de niños de 10 años que han padecido alguna enfermedad infecciosa es cercana a la normal (132,5 cm). Sin embargo, el límite inferior del intervalo de confianza (126,6 cm) indica que existe un 95% de probabilidad de que la verdadera talla promedio de estos niños corresponda al concepto de “talla baja”, es decir, Estos niños tienen retraso en el crecimiento. En este ejemplo, los resultados de los cálculos del intervalo de confianza son clínicamente significativos. |
|||||||||||||||||||
Intervalo de confianza para la expectativa matemática - este es un intervalo calculado a partir de datos que, con una probabilidad conocida, contiene la expectativa matemática de la población general. Una estimación natural de la expectativa matemática es la media aritmética de sus valores observados. Por lo tanto, a lo largo de la lección usaremos los términos “promedio” y “valor promedio”. En los problemas de cálculo de un intervalo de confianza, la respuesta que con mayor frecuencia se requiere es algo así como "El intervalo de confianza del número promedio [valor en un problema particular] es de [valor menor] a [valor mayor]". Utilizando un intervalo de confianza, es posible evaluar no solo los valores promedio, sino también el peso específico de una característica particular de la población general. En la lección se analizan los valores medios, la dispersión, la desviación estándar y el error, a través de los cuales llegaremos a nuevas definiciones y fórmulas. Características de la muestra y la población. .
Estimaciones puntuales y de intervalo de la media.
Si el valor promedio de la población se estima mediante un número (punto), entonces se toma como estimación del valor promedio desconocido de la población un promedio específico, que se calcula a partir de una muestra de observaciones. En este caso, el valor de la media muestral (una variable aleatoria) no coincide con el valor medio de la población general. Por lo tanto, al indicar la media muestral, se debe indicar simultáneamente el error muestral. La medida del error muestral es el error estándar, que se expresa en las mismas unidades que la media. Por lo tanto, se suele utilizar la siguiente notación: .
Si es necesario asociar la estimación del promedio con una cierta probabilidad, entonces el parámetro de interés en la población debe estimarse no mediante un número, sino mediante un intervalo. Un intervalo de confianza es un intervalo en el que, con una cierta probabilidad PAG Se encuentra el valor del indicador de población estimada. Intervalo de confianza en el que es probable PAG = 1 - α Se encuentra la variable aleatoria, calculada de la siguiente manera:
![]() ,
,
α = 1 - PAG, que se puede encontrar en el apéndice de casi cualquier libro sobre estadística.
En la práctica, la media poblacional y la varianza no se conocen, por lo que la varianza poblacional se reemplaza por la varianza muestral y la media poblacional por la media muestral. Por tanto, el intervalo de confianza en la mayoría de los casos se calcula de la siguiente manera:
![]() .
.
La fórmula del intervalo de confianza se puede utilizar para estimar la media poblacional si
- se conoce la desviación estándar de la población;
- o se desconoce la desviación estándar de la población, pero el tamaño de la muestra es mayor que 30.
La media muestral es una estimación insesgada de la media poblacional. A su vez, la varianza muestral  no es una estimación insesgada de la varianza poblacional. Para obtener una estimación insesgada de la varianza poblacional en la fórmula de varianza muestral, el tamaño de la muestra norte debe ser reemplazado por norte-1.
no es una estimación insesgada de la varianza poblacional. Para obtener una estimación insesgada de la varianza poblacional en la fórmula de varianza muestral, el tamaño de la muestra norte debe ser reemplazado por norte-1.
Ejemplo 1. Se recopiló información de 100 cafés seleccionados al azar en una determinada ciudad de que el número promedio de empleados en ellos es 10,5 con una desviación estándar de 4,6. Determine el intervalo de confianza del 95% para el número de empleados de una cafetería.
¿Dónde está el valor crítico de la distribución normal estándar para el nivel de significancia? α = 0,05 .
Así, el intervalo de confianza del 95% para el número medio de empleados de cafeterías osciló entre 9,6 y 11,4.
Ejemplo 2. Para una muestra aleatoria de una población de 64 observaciones, se calcularon los siguientes valores totales:
suma de valores en observaciones,
suma de desviaciones al cuadrado de valores de la media ![]() .
.
Calcule el intervalo de confianza del 95% para la expectativa matemática.
Calculemos la desviación estándar:
 ,
,
Calculemos el valor medio:
![]() .
.
Sustituimos los valores en la expresión del intervalo de confianza:
¿Dónde está el valor crítico de la distribución normal estándar para el nivel de significancia? α = 0,05 .
Obtenemos:
Así, el intervalo de confianza del 95% para la expectativa matemática de esta muestra osciló entre 7,484 y 11,266.
Ejemplo 3. Para una muestra de población aleatoria de 100 observaciones, la media calculada es 15,2 y la desviación estándar es 3,2. Calcule el intervalo de confianza del 95% para el valor esperado y luego el intervalo de confianza del 99%. Si el poder de la muestra y su variación permanecen sin cambios y el coeficiente de confianza aumenta, ¿se estrechará o ampliará el intervalo de confianza?
Sustituimos estos valores en la expresión del intervalo de confianza:
¿Dónde está el valor crítico de la distribución normal estándar para el nivel de significancia? α = 0,05 .
Obtenemos:
![]() .
.
Así, el intervalo de confianza del 95% para la media de esta muestra osciló entre 14,57 y 15,82.
Nuevamente sustituimos estos valores en la expresión del intervalo de confianza:
¿Dónde está el valor crítico de la distribución normal estándar para el nivel de significancia? α = 0,01 .
Obtenemos:
![]() .
.
Así, el intervalo de confianza del 99% para la media de esta muestra osciló entre 14,37 y 16,02.
Como vemos, a medida que aumenta el coeficiente de confianza, el valor crítico de la distribución normal estándar también aumenta y, en consecuencia, los puntos inicial y final del intervalo se ubican más lejos de la media y, por lo tanto, aumenta el intervalo de confianza para la expectativa matemática. .
Estimaciones puntuales y de intervalo de gravedad específica.
La proporción de algún atributo de la muestra se puede interpretar como una estimación puntual de la proporción. pag de la misma característica en la población general. Si es necesario asociar este valor con la probabilidad, entonces se debe calcular el intervalo de confianza de la gravedad específica. pag característica en la población con probabilidad PAG = 1 - α :
 .
.
Ejemplo 4. En alguna ciudad hay dos candidatos. A Y B se postulan para alcalde. Se encuestó aleatoriamente a 200 vecinos de la ciudad, de los cuales el 46% respondió que votaría por el candidato A, 26% - por el candidato B y el 28% no sabe por quién votará. Determine el intervalo de confianza del 95% para la proporción de residentes de la ciudad que apoyan al candidato. A.
Construyamos un intervalo de confianza en MS EXCEL para estimar el valor medio de la distribución en el caso de un valor de dispersión conocido.
Por supuesto la elección nivel de confianza Depende completamente del problema que se esté resolviendo. Por tanto, el grado de confianza de un pasajero aéreo en la fiabilidad de un avión debería ser sin duda mayor que el grado de confianza de un comprador en la fiabilidad de una bombilla eléctrica.
Formulación de problemas
Supongamos que desde población habiendo sido tomado muestra tamaño n. Se supone que desviación estándar esta distribución es conocida. Es necesario en base a esto muestras evaluar lo desconocido media de distribución(μ, ) y construir el correspondiente de dos caras intervalo de confianza.
Estimación puntual
Como se sabe de estadística(denotémoslo X promedio) es estimación insesgada de la media este población y tiene una distribución N(μ;σ 2 /n).
Nota: Qué hacer si necesitas construir intervalo de confianza en el caso de una distribución que no es ¿normal? En este caso viene al rescate quien afirma que con un tamaño suficientemente grande muestras n de distribución no ser normal, distribución muestral de estadísticas X promedio voluntad aproximadamente corresponder distribución normal con parámetros N(μ;σ 2 /n).
Entonces, estimación puntual promedio valores de distribución tenemos - esto media muestral, es decir. X promedio. Ahora comencemos intervalo de confianza.
Construyendo un intervalo de confianza
Normalmente, conociendo la distribución y sus parámetros, podemos calcular la probabilidad de que la variable aleatoria tome un valor del intervalo que especificamos. Ahora hagamos lo contrario: encuentre el intervalo en el que caerá la variable aleatoria con una probabilidad dada. Por ejemplo, de las propiedades distribución normal Se sabe que con una probabilidad del 95%, una variable aleatoria distribuida sobre ley normal, estará dentro del rango de aproximadamente +/- 2 desde valor promedio(ver artículo sobre). Este intervalo nos servirá de prototipo. intervalo de confianza.
Ahora veamos si conocemos la distribución. , calcular este intervalo? Para responder a la pregunta, debemos indicar la forma de la distribución y sus parámetros.
Conocemos la forma de distribución: esto es distribución normal(recuerda que estamos hablando de distribución muestral estadística X promedio).
El parámetro μ nos es desconocido (solo es necesario estimarlo usando intervalo de confianza), pero tenemos una estimación del mismo X promedio, calculado en base a muestras, que se puede utilizar.
Segundo parámetro - desviación estándar de la media muestral lo daremos por conocido, es igual a σ/√n.
Porque no sabemos μ, entonces construiremos el intervalo +/- 2 desviaciones estándar no de valor promedio, y de su estimación conocida X promedio. Aquellos. al calcular intervalo de confianza NO asumiremos que X promedio cae dentro del rango +/- 2 desviaciones estándar de μ con una probabilidad del 95%, y asumiremos que el intervalo es +/- 2 desviaciones estándar de X promedio con 95% de probabilidad cubrirá μ – promedio de la población general, de donde se toma muestra. Estas dos afirmaciones son equivalentes, pero la segunda nos permite construir intervalo de confianza.
Además, aclaremos el intervalo: una variable aleatoria distribuida en ley normal, con un 95% de probabilidad cae dentro del intervalo +/- 1,960 desviaciones estándar, no +/- 2 desviaciones estándar. Esto se puede calcular usando la fórmula =REV.EST.NORM((1+0.95)/2), cm. archivo de ejemplo Intervalo de hoja.

Ahora podemos formular un enunciado probabilístico que nos servirá para formar intervalo de confianza:
"La probabilidad de que media poblacional ubicado desde promedio de la muestra dentro de 1.960 " desviaciones estándar de la media muestral", igual al 95%".
El valor de probabilidad mencionado en la declaración tiene un nombre especial. , que está asociado con nivel de significancia α (alfa) mediante una expresión simple nivel de confianza =1 -α . En nuestro caso nivel de significancia α =1-0,95=0,05 .
Ahora, basándonos en este enunciado probabilístico, escribimos una expresión para calcular intervalo de confianza:

donde Z α/2 – estándar distribución normal(este valor de la variable aleatoria z, Qué PAG(z>=Zα/2 )=α/2).
Nota: Cuantil α/2 superior define el ancho intervalo de confianza V desviaciones estándar media muestral. Cuantil α/2 superior estándar distribución normal siempre mayor que 0, lo cual es muy conveniente.
En nuestro caso, con α=0,05, cuantil α/2 superior es igual a 1,960. Para otros niveles de significancia α (10%; 1%) cuantil α/2 superior Zα/2 se puede calcular usando la fórmula =NORM.ST.REV(1-α/2) o, si se conoce nivel de confianza, =NORM.ST.OBR((1+nivel de confianza)/2).
Generalmente al construir intervalos de confianza para estimar la media usar solo α superior/2-cuantil y no usar α inferior/2-cuantil. Esto es posible porque estándar distribución normal simétricamente respecto al eje x ( su densidad de distribución simétrico sobre promedio, es decir 0). Por lo tanto, no es necesario calcular cuantil α/2 inferior(simplemente se llama α /2-cuantil), porque es igual α superior/2-cuantil con un signo menos.
Recordemos que, a pesar de la forma de la distribución del valor x, la variable aleatoria correspondiente X promedio repartido aproximadamente Bien N(μ;σ 2 /n) (ver artículo sobre). Por lo tanto, en general, la expresión anterior para intervalo de confianza es sólo una aproximación. Si el valor x se distribuye entre ley normal N(μ;σ 2 /n), entonces la expresión para intervalo de confianza es exacto.
Cálculo del intervalo de confianza en MS EXCEL.
Resolvamos el problema.
El tiempo de respuesta de un componente electrónico a una señal de entrada es una característica importante del dispositivo. Un ingeniero quiere construir un intervalo de confianza para el tiempo de respuesta promedio con un nivel de confianza del 95%. Por experiencia previa, el ingeniero sabe que la desviación estándar del tiempo de respuesta es de 8 ms. Se sabe que para evaluar el tiempo de respuesta el ingeniero realizó 25 mediciones, el valor promedio fue de 78 ms.
Solución: Un ingeniero quiere saber el tiempo de respuesta de un dispositivo electrónico, pero entiende que el tiempo de respuesta no es un valor fijo, sino una variable aleatoria que tiene su propia distribución. Entonces, lo mejor que puede esperar es determinar los parámetros y la forma de esta distribución.
Desafortunadamente, por las condiciones del problema no conocemos la forma de la distribución del tiempo de respuesta (no tiene por qué ser así). normal). , esta distribución también se desconoce. solo el es conocido desviación estándarσ=8. Por lo tanto, si bien no podemos calcular las probabilidades y construir intervalo de confianza.
Sin embargo, a pesar de que desconocemos la distribución tiempo respuesta separada, sabemos que según CPT, distribución muestral tiempo promedio de respuesta es aproximadamente normal(asumiremos que las condiciones CPT se llevan a cabo, porque tamaño muestras bastante grande (n=25)) .
Además, promedio esta distribución es igual a valor promedio distribución de una única respuesta, es decir µ. A desviación estándar de esta distribución (σ/√n) se puede calcular usando la fórmula =8/ROOT(25) .
También se sabe que el ingeniero recibió estimación puntual parámetro μ igual a 78 ms (X avg). Por lo tanto, ahora podemos calcular probabilidades, porque conocemos la forma de distribución ( normal) y sus parámetros (X avg y σ/√n).
El ingeniero quiere saber expectativa matemática Distribuciones de tiempo de respuesta μ. Como se indicó anteriormente, este μ es igual a expectativa matemática de la distribución muestral del tiempo de respuesta promedio. si usamos distribución normal N(Х avg; σ/√n), entonces el μ deseado estará en el rango +/-2*σ/√n con una probabilidad de aproximadamente el 95%.
Nivel de significancia es igual a 1-0,95=0,05.
Finalmente, busquemos el borde izquierdo y derecho. intervalo de confianza.
Borde izquierdo: =78-REV.ST.NORM(1-0.05/2)*8/RAÍZ(25) =
74,864
Borde derecho: =78+INV.EST.NORM.(1-0.05/2)*8/RAÍZ(25)=81.136
Borde izquierdo: =REV.NORM(0.05/2; 78; 8/RAÍZ(25))
Borde derecho: =REV.NORM(1-0.05/2; 78; 8/RAÍZ(25))
Respuesta: intervalo de confianza en Nivel de confianza del 95% y σ=8mseg es igual 78+/-3,136 ms.
EN archivo de ejemplo en la hoja Sigma conocido, creó un formulario para el cálculo y la construcción. de dos caras intervalo de confianza por arbitrario muestras con σ dado y nivel de significancia.

Función CONFIANZA.NORM()
Si los valores muestras están en el rango B20:B79
, A nivel de significancia igual a 0,05; luego la fórmula de MS EXCEL:
=PROMEDIO(B20:B79)-CONFIANZA.NORM(0.05;σ; CONTAR(B20:B79))
devolverá el borde izquierdo intervalo de confianza.
El mismo límite se puede calcular mediante la fórmula:
=PROMEDIO(B20:B79)-NORM.ST.REV(1-0.05/2)*σ/RAÍZ(COUNT(B20:B79))
Nota: La función CONFIDENCE.NORM() apareció en MS EXCEL 2010. En versiones anteriores de MS EXCEL, se utilizaba la función TRUST().
Intervalo de confianza– los valores límite de una cantidad estadística que, con una probabilidad de confianza dada γ, estarán en este intervalo al muestrear un volumen mayor. Se denota como P(θ - ε. En la práctica, la probabilidad de confianza γ se elige entre valores bastante cercanos a la unidad: γ = 0,9, γ = 0,95, γ = 0,99.Objeto del servicio. Con este servicio, puede determinar:
- intervalo de confianza para la media general, intervalo de confianza para la varianza;
- intervalo de confianza para la desviación estándar, intervalo de confianza para la participación general;
Ejemplo No. 1. En una granja colectiva, de un rebaño total de 1.000 ovejas, 100 fueron sometidas a una esquila de control selectiva. Como resultado se estableció un recorte de lana promedio de 4,2 kg por oveja. Determine con una probabilidad de 0,99 el error cuadrático medio de la muestra al determinar la esquila promedio de lana por oveja y los límites dentro de los cuales se contiene el valor de esquila si la varianza es 2,5. La muestra no es repetitiva.
Ejemplo No. 2. De un lote de productos importados en el puesto de Aduanas del Norte de Moscú, se tomaron 20 muestras del producto "A" mediante muestreo aleatorio repetido. Como resultado de la prueba se estableció el contenido de humedad promedio del producto “A” en la muestra, el cual resultó ser igual al 6% con una desviación estándar del 1%.
Determine con una probabilidad de 0,683 los límites del contenido de humedad promedio del producto en todo el lote de productos importados.
Ejemplo No. 3. Una encuesta de 36 estudiantes mostró que el número promedio de libros de texto leídos por ellos durante el año académico era igual a 6. Suponiendo que el número de libros de texto leídos por un estudiante por semestre tiene una ley de distribución normal con una desviación estándar igual a 6, encuentre : A) con una confiabilidad de 0,99 estimación de intervalo para la expectativa matemática de esta variable aleatoria; B) ¿Con qué probabilidad podemos decir que el número promedio de libros de texto leídos por un estudiante por semestre, calculado a partir de esta muestra, se desviará de la expectativa matemática en valor absoluto en no más de 2?
Clasificación de intervalos de confianza.
Por tipo de parámetro a evaluar:Por tipo de muestra:
- Intervalo de confianza para una muestra infinita;
- Intervalo de confianza para la muestra final;
Cálculo del error muestral medio para muestreo aleatorio.
La discrepancia entre los valores de los indicadores obtenidos de la muestra y los parámetros correspondientes de la población general se denomina error de representatividad.Designaciones de los principales parámetros de la población general y muestral.
| Fórmulas de error de muestreo promedio | |||
| reselección | repetir la selección | ||
| para promedio | para compartir | para promedio | para compartir |
Fórmulas para calcular el tamaño de la muestra utilizando un método de muestreo puramente aleatorio.
INTERVALOS DE CONFIANZA PARA FRECUENCIAS Y FRACCIONES
© 2008
Instituto Nacional de Salud Pública, Oslo, Noruega
El artículo describe y discute el cálculo de intervalos de confianza para frecuencias y proporciones utilizando los métodos de Wald, Wilson, Clopper - Pearson, utilizando la transformación angular y el método de Wald con corrección de Agresti - Coull. El material presentado proporciona información general sobre los métodos para calcular intervalos de confianza para frecuencias y proporciones y tiene como objetivo despertar el interés de los lectores de revistas no solo en el uso de intervalos de confianza al presentar los resultados de su propia investigación, sino también en la lectura de literatura especializada antes de comenzar a trabajar. sobre futuras publicaciones.
Palabras clave: intervalo de confianza, frecuencia, proporción
Una de las publicaciones anteriores mencionó brevemente la descripción de datos cualitativos e informó que su estimación de intervalo es preferible a la estimación puntual para describir la frecuencia de aparición de la característica que se está estudiando en la población. De hecho, dado que la investigación se realiza utilizando datos de muestra, la proyección de los resultados sobre la población debe contener un elemento de imprecisión muestral. El intervalo de confianza es una medida de la precisión del parámetro que se estima. Es interesante que algunos libros sobre estadística básica para médicos ignoren por completo el tema de los intervalos de confianza para las frecuencias. En este artículo veremos varias formas de calcular intervalos de confianza para frecuencias, lo que implica características de muestra como la no repetición y la representatividad, así como la independencia de las observaciones entre sí. En este artículo, la frecuencia no se entiende como un número absoluto que muestra cuántas veces ocurre un valor particular en el agregado, sino como un valor relativo que determina la proporción de participantes del estudio en quienes ocurre la característica estudiada.
En la investigación biomédica, los intervalos de confianza del 95% son los más utilizados. Este intervalo de confianza es el área dentro de la cual la verdadera proporción cae el 95% de las veces. En otras palabras, podemos decir con un 95% de confianza que el valor real de la frecuencia de aparición de un rasgo en la población estará dentro del intervalo de confianza del 95%.
La mayoría de los manuales de estadística para investigadores médicos informan que el error de frecuencia se calcula mediante la fórmula
donde p es la frecuencia de aparición de la característica en la muestra (valor de 0 a 1). La mayoría de los artículos científicos nacionales indican la frecuencia de aparición de un rasgo en una muestra (p), así como sus errores en la forma p ± s. Sin embargo, es más apropiado presentar un intervalo de confianza del 95% para la frecuencia de aparición de un rasgo en la población, que incluirá valores de
 |
 a.
a.
Algunos manuales recomiendan que, para muestras pequeñas, se reemplace el valor de 1,96 con el valor t para N – 1 grados de libertad, donde N es el número de observaciones en la muestra. El valor t se calcula utilizando tablas para la distribución t, disponibles en casi todos los libros de texto de estadística. El uso de la distribución t para el método de Wald no proporciona ventajas visibles en comparación con otros métodos que se analizan a continuación y, por lo tanto, algunos autores no lo recomiendan.
El método presentado anteriormente para calcular intervalos de confianza para frecuencias o proporciones se denomina Wald en honor a Abraham Wald (1902-1950), ya que su uso generalizado comenzó después de la publicación de Wald y Wolfowitz en 1939. Sin embargo, el método en sí fue propuesto por Pierre Simon Laplace (1749-1827) en 1812.
El método Wald es muy popular, pero su aplicación plantea importantes problemas. El método no se recomienda para tamaños de muestra pequeños, así como en los casos en que la frecuencia de aparición de una característica tiende a 0 o 1 (0% o 100%) y es simplemente imposible para frecuencias de 0 y 1. Además, el la aproximación de la distribución normal, que se utiliza al calcular el error, “no funciona” en los casos en que n · p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Dado que la nueva variable tiene una distribución normal, los límites inferior y superior del intervalo de confianza del 95% para la variable φ serán φ-1,96 y φ+1,96izquierda">


En lugar de 1,96 para muestras pequeñas, se recomienda sustituir el valor t por N – 1 grados de libertad. Este método no produce valores negativos y permite estimaciones más precisas de los intervalos de confianza para las frecuencias que el método de Wald. Además, se describe en muchos libros de referencia nacionales sobre estadísticas médicas, lo que, sin embargo, no ha llevado a su uso generalizado en la investigación médica. No se recomienda el cálculo de intervalos de confianza mediante transformación angular para frecuencias cercanas a 0 o 1.
Aquí suele terminar la descripción de los métodos para estimar intervalos de confianza en la mayoría de los libros sobre conceptos básicos de estadística para investigadores médicos, y este problema es típico no sólo de la literatura nacional sino también de la extranjera. Ambos métodos se basan en el teorema del límite central, lo que implica una muestra grande.
Teniendo en cuenta las deficiencias de estimar intervalos de confianza utilizando los métodos anteriores, Clopper y Pearson propusieron en 1934 un método para calcular el llamado intervalo de confianza exacto, dada la distribución binomial del rasgo en estudio. Este método está disponible en muchas calculadoras en línea, pero los intervalos de confianza obtenidos de esta manera son en la mayoría de los casos demasiado amplios. Al mismo tiempo, se recomienda el uso de este método en los casos en que sea necesaria una evaluación conservadora. El grado de conservadurismo del método aumenta a medida que disminuye el tamaño de la muestra, especialmente cuando N< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Según muchos estadísticos, la evaluación más óptima de los intervalos de confianza de las frecuencias se realiza mediante el método de Wilson, propuesto en 1927, pero prácticamente no utilizado en la investigación biomédica nacional. Este método no sólo permite estimar intervalos de confianza para frecuencias muy pequeñas y muy grandes, sino que también es aplicable para un pequeño número de observaciones. En general, el intervalo de confianza según la fórmula de Wilson tiene la forma
 |
 |
donde toma el valor 1,96 al calcular el intervalo de confianza del 95%, N es el número de observaciones y p es la frecuencia de aparición de la característica en la muestra. Este método está disponible en calculadoras online, por lo que su uso no supone ningún problema. y no recomiendo usar este método para n p< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Además del método de Wilson, también se cree que el método de Wald con corrección de Agresti-Coll proporciona una estimación óptima del intervalo de confianza para las frecuencias. La corrección de Agresti-Coll es una sustitución en la fórmula de Wald de la frecuencia de aparición de una característica en una muestra (p) por p`, al calcular cuál se suma 2 al numerador y 4 al denominador, es decir, p` = (X + 2) / (N + 4), donde X es el número de participantes del estudio que tienen la característica que se está estudiando y N es el tamaño de la muestra. Esta modificación produce resultados muy similares a la fórmula de Wilson, excepto cuando la frecuencia del evento se acerca al 0% o al 100% y la muestra es pequeña. Además de los métodos anteriores para calcular intervalos de confianza para frecuencias, se han propuesto correcciones de continuidad para los métodos de Wald y Wilson para muestras pequeñas, pero los estudios han demostrado que su uso es inadecuado.
Consideremos la aplicación de los métodos anteriores para calcular intervalos de confianza utilizando dos ejemplos. En el primer caso, estudiamos una muestra grande de 1.000 participantes del estudio seleccionados aleatoriamente, de los cuales 450 tienen el rasgo que se está estudiando (este podría ser un factor de riesgo, un resultado o cualquier otro rasgo), lo que representa una frecuencia de 0,45, o 45 %. En el segundo caso, el estudio se lleva a cabo utilizando una muestra pequeña, digamos, solo 20 personas, y solo 1 participante del estudio (5%) tiene el rasgo estudiado. Los intervalos de confianza utilizando el método de Wald, el método de Wald con corrección de Agresti-Coll y el método de Wilson se calcularon utilizando una calculadora en línea desarrollada por Jeff Sauro (http://www./wald.htm). Los intervalos de confianza corregidos por continuidad de Wilson se calcularon utilizando la calculadora proporcionada por Wassar Stats: sitio web para computación estadística (http://faculty.vassar.edu/lowry/prop1.html). Los cálculos de la transformación angular de Fisher se realizaron manualmente utilizando el valor t crítico para 19 y 999 grados de libertad, respectivamente. Los resultados del cálculo se presentan en la tabla para ambos ejemplos.
Intervalos de confianza calculados de seis maneras diferentes para dos ejemplos descritos en el texto
Método de cálculo del intervalo de confianza |
P=0,0500, o 5% | IC del 95% para X=450, N=1000, P=0,4500 o 45% |
–0,0455–0,2541 | ||
Wald con corrección de Agresti-Coll | <,0001–0,2541 | |
Wilson con corrección de continuidad | ||
Clopper-Pearson "método exacto" | ||
transformación angular | <0,0001–0,1967 |
Como puede verse en la tabla, para el primer ejemplo el intervalo de confianza calculado utilizando el método Wald “generalmente aceptado” entra en la región negativa, lo que no puede ocurrir con las frecuencias. Desafortunadamente, estos incidentes no son infrecuentes en la literatura rusa. La forma tradicional de presentar los datos en términos de frecuencia y su error enmascara parcialmente este problema. Por ejemplo, si la frecuencia de aparición de un rasgo (en porcentaje) se presenta como 2,1 ± 1,4, entonces esto no es tan “ofensivo para la vista” como 2,1% (IC del 95%: –0,7; 4,9), aunque y significa la misma cosa. El método Wald con corrección de Agresti-Coll y cálculo mediante transformación angular da un límite inferior que tiende a cero. El método de Wilson con corrección de continuidad y el "método exacto" producen intervalos de confianza más amplios que el método de Wilson. Para el segundo ejemplo, todos los métodos dan aproximadamente los mismos intervalos de confianza (las diferencias aparecen solo en milésimas), lo cual no es sorprendente, ya que la frecuencia de ocurrencia del evento en este ejemplo no es muy diferente del 50% y el tamaño de la muestra es bastante grande.
Para los lectores interesados en este problema, podemos recomendar los trabajos de R. G. Newcombe y Brown, Cai y Dasgupta, que proporcionan los pros y los contras de utilizar 7 y 10 métodos diferentes para calcular intervalos de confianza, respectivamente. Entre los manuales nacionales, recomendamos el libro Y, que, además de una descripción detallada de la teoría, presenta los métodos de Wald y Wilson, así como un método para calcular intervalos de confianza teniendo en cuenta la distribución de frecuencia binomial. Además de las calculadoras en línea gratuitas (http://www. /wald. htm y http://faculty. vassar. edu/lowry/prop1.html), se pueden calcular intervalos de confianza para frecuencias (¡y no sólo!) utilizando el Programa CIA (Análisis de Intervalos de Confianza), que se puede descargar desde http://www. escuela de medicina. sotón. C.A. reino unido/cia/ .
El próximo artículo analizará formas univariadas de comparar datos cualitativos.
Referencias
Banerji A. Estadísticas médicas en lenguaje claro: un curso introductorio / A. Banerjee. – M.: Medicina Práctica, 2007. – 287 p. Estadísticas médicas / . – M.: Agencia de Información Médica, 2007. – 475 p. Glanz S. Estadísticas médicas y biológicas / S. Glanz. – M.: Praktika, 1998. Tipos de datos, pruebas de distribución y estadísticas descriptivas // Ecología humana – 2008. – No. 1. – P. 52–58. Zhizhin K. S.. Estadística médica: libro de texto / . – Rostov s/f: Phoenix, 2007. – 160 p. Estadística médica aplicada / , . – San Petersburgo. : Foliot, 2003. – 428 p. Lakin G.F.. Biometría / . – M.: Escuela Superior, 1990. – 350 p. Médico V. A.. Estadística matemática en medicina / , . – M.: Finanzas y Estadísticas, 2007. – 798 p. Estadística matemática en la investigación clínica / , . – M.: GEOTAR-MED, 2001. – 256 p. Junkerov V.. Y. Procesamiento médico y estadístico de datos de investigaciones médicas / , . – San Petersburgo. : VmedA, 2002. – 266 p. Agresti A. Lo aproximado es mejor que lo exacto para la estimación de intervalos de proporciones binomiales / A. Agresti, B. Coull // Estadístico estadounidense. – 1998. – N 52. – P. 119–126. Altman D. Estadísticas con confianza // D. Altman, D. Machin, T. Bryant, M. J. Gardner. – Londres: BMJ Books, 2000. – 240 p. Marrón L.D. Estimación de intervalos para una proporción binomial / L. D. Brown, T. T. Cai, A. Dasgupta // Ciencia estadística. – 2001. – N 2. – P. 101–133. Clopper C.J. El uso de límites de confianza o fiduciales ilustrados en el caso del binomio / C. J. Clopper, E. S. Pearson // Biometrika. – 1934. – N 26. – P. 404–413. García-Pérez M. A. Sobre el intervalo de confianza del parámetro binomial / M. A. García-Pérez // Calidad y cantidad. – 2005. – N 39. – P. 467–481. Motulsky H. Bioestadística intuitiva // H. Motulsky. – Oxford: Oxford University Press, 1995. – 386 p. Newcombe R.G. Intervalos de confianza bilaterales para una proporción única: comparación de siete métodos / R. G. Newcombe // Estadística en medicina. – 1998. – N. 17. – P. 857–872. Sauro J. Estimación de tasas de finalización a partir de muestras pequeñas utilizando intervalos de confianza binomiales: comparaciones y recomendaciones / J. Sauro, J. R. Lewis // Actas de la reunión anual de la sociedad de factores humanos y ergonomía. – Orlando, Florida, 2005. Wald A. Límites de confianza para funciones de distribución continua // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. – 1939. – N 10. – P. 105–118. Wilson EB. Inferencia probable, ley de sucesión e inferencia estadística / E. B. Wilson // Journal of American Statistical Association. – 1927. – N 22. – P. 209–212.INTERVALOS DE CONFIANZA PARA PROPORCIONES
A. M. Grjibovski
Instituto Nacional de Salud Pública, Oslo, Noruega
El artículo presenta varios métodos para calcular intervalos de confianza para proporciones binomiales, a saber, los métodos de Wald, Wilson, arcoseno, Agresti-Coull y exacto de Clopper-Pearson. El artículo ofrece sólo una introducción general al problema de la estimación del intervalo de confianza de una proporción binomial y su objetivo no es sólo estimular a los lectores a utilizar intervalos de confianza al presentar los resultados de su propia investigación empírica, sino también animarles a consultar libros de estadística. antes de analizar datos propios y preparar manuscritos.
Palabras clave: intervalo de confianza, proporción
Información del contacto:
– Asesor Principal, Instituto Nacional de Salud Pública, Oslo, Noruega