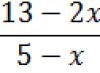Évaluer la qualité du modèle construit. La qualité du modèle s’est-elle améliorée par rapport au modèle monofactoriel ? Évaluez l'influence de facteurs significatifs sur le résultat à l'aide des coefficients d'élasticité, des coefficients et .
Coefficient de détermination R.-carré sera tiré des résultats de « Régression » (tableau « Statistiques de régression » pour le modèle (6)).
Par conséquent, la variation (changement) du prix d'un appartement Oui Selon cette équation, 76,77% s'explique par la variation de la ville de la région X 1 , nombre de pièces dans l'appartement X 2 et espace de vie X 4 .
Nous utilisons les données originales Oui je et résidus trouvés par l'outil de régression  (tableau « Sortie du reste » pour le modèle (6)). Calculons les erreurs relatives et trouvons la valeur moyenne
(tableau « Sortie du reste » pour le modèle (6)). Calculons les erreurs relatives et trouvons la valeur moyenne  .
.
RETRAIT DU RESTE
| Observation | Y prédit | Restes | Rel. erreur |
| 1 | 45,95089273 | -7,95089273 | 20,92340192 |
| 2 | 86,10296493 | -23,90296493 | 38,42920407 |
| 3 | 94,84442678 | 30,15557322 | 24,12445858 |
| 4 | 84,17648426 | -23,07648426 | 37,76838667 |
| 5 | 40,2537216 | 26,7462784 | 39,91981851 |
| 6 | 68,70572376 | 24,29427624 | 26,12287768 |
| 7 | 143,7464899 | -25,7464899 | 21,81905923 |
| 8 | 106,0907598 | 25,90924022 | 19,62821228 |
| 9 | 135,357993 | -42,85799303 | 46,33296544 |
| 10 | 114,4792566 | -9,47925665 | 9,027863476 |
| 11 | 41,48765602 | 0,512343975 | 1,219866607 |
| 12 | 103,2329236 | 21,76707636 | 17,41366109 |
| 13 | 130,3567798 | 39,64322022 | 23,3195413 |
| 14 | 35,41901876 | 2,580981242 | 6,7920559 |
| 15 | 155,4129693 | -24,91296925 | 19,0903979 |
| 16 | 84,32108188 | 0,678918123 | 0,798727204 |
| 17 | 98,0552279 | -0,055227902 | 0,056355002 |
| 18 | 144,2104618 | -16,21046182 | 12,66442329 |
| 19 | 122,8677535 | -37,86775351 | 44,55029825 |
| 20 | 100,0221225 | 59,97787748 | 37,48617343 |
| 21 | 53,27196558 | 6,728034423 | 11,21339071 |
| 22 | 35,06605378 | 5,933946225 | 14,47303957 |
| 23 | 114,4792566 | -24,47925665 | 27,19917406 |
| 24 | 113,1343153 | -30,13431529 | 36,30640396 |
| 25 | 40,43190991 | 4,568090093 | 10,15131132 |
| 26 | 39,34427892 | -0,344278918 | 0,882766457 |
| 27 | 144,4794501 | -57,57945009 | 66,25943623 |
| 28 | 56,4827667 | -16,4827667 | 41,20691675 |
| 29 | 95,38240332 | -15,38240332 | 19,22800415 |
| 30 | 228,6988826 | -1,698882564 | 0,748406416 |
| 31 | 222,8067278 | 12,19327221 | 5,188626473 |
| 32 | 38,81483144 | 1,185168555 | 2,962921389 |
| 33 | 48,36325811 | 18,63674189 | 27,81603267 |
| 34 | 126,6080021 | -3,608002113 | 2,933335051 |
| 35 | 84,85052935 | 15,14947065 | 15,14947065 |
| 36 | 116,7991162 | -11,79911625 | 11,23725357 |
| 37 | 84,17648426 | -13,87648426 | 19,73895342 |
| 38 | 113,9412801 | -31,94128011 | 38,95278062 |
| 39 | 215,494184 | 64,50581599 | 23,03779142 |
| 40 | 141,7795953 | 58,22040472 | 29,11020236 |
| Moyenne | 101,2375 | 22,51770962 |
En utilisant la colonne des erreurs relatives, nous trouvons la valeur moyenne =22.51% (en utilisant la fonction MOYENNE).
La comparaison montre que 22,51%>7%. La précision du modèle n’est donc pas satisfaisante.
En utilisant F – Critère de Fisher Vérifions la signification du modèle dans son ensemble. Pour ce faire, nous noterons à partir des résultats de l'utilisation de l'outil « Régression » (tableau « analyse de variance » pour le modèle (6)) F= 39,6702.
En utilisant la fonction FRIST on trouve la valeur F cr =3.252 pour le niveau de signification α = 5%, et nombres de degrés de liberté k 1 = 2 , k 2 = 37 .
F> F cr, donc l'équation du modèle (6) est significative, son utilisation est conseillée, la variable dépendante Oui est assez bien décrit par les variables factorielles incluses dans le modèle (6) X 1 , X 2. Et X 4 .
En utilisant en plus t –Test de l'étudiant Vérifions la signification des coefficients individuels du modèle.
t–Les statistiques des coefficients de l'équation de régression sont données dans les résultats de l'outil « Régression ». Les valeurs suivantes ont été obtenues pour le modèle sélectionné (6) :
| Chances | Erreur type | statistique t | Valeur P | 95 % inférieurs | Meilleurs 95 % | 95,0 % inférieurs | Meilleurs 95,0 % |
|
| Intersection en Y | -5,643572321 | 12,07285417 | -0,46745966 | 0,642988 | -30,1285 | 18,84131 | -30,1285 | 18,84131 |
| X4 | 2,591405557 | 0,461440597 | 5,61590284 | 2.27E-06 | 1,655561 | 3,52725 | 1,655561 | 3,52725 |
| X1 | 6,85963077 | 9,185748512 | 0,74676884 | 0,460053 | -11,7699 | 25,48919 | -11,7699 | 25,48919 |
| X2 | -1,985156991 | 7,795346067 | -0,25465925 | 0,800435 | -17,7949 | 13,82454 | -17,7949 | 13,82454 |
Valeur critique t cr trouvé pour le niveau de signification α=5% et nombre de degrés de liberté k=40–2–1=37 . t cr =2.026 (Fonction STUDAR).
Pour des cotes gratuites α
=–5.643
statistiques définies  ,
,  t cr Le coefficient libre n’est donc pas significatif et peut être exclu du modèle.
t cr Le coefficient libre n’est donc pas significatif et peut être exclu du modèle.
Pour le coefficient de régression β
1
=6.859
statistiques définies  ,
,  β
1
n’est pas significatif, ce facteur ainsi que le facteur de la ville régionale peuvent être supprimés du modèle.
β
1
n’est pas significatif, ce facteur ainsi que le facteur de la ville régionale peuvent être supprimés du modèle.
Pour le coefficient de régression β
2
=-1,985
statistiques définies  ,
,  t cr, donc le coefficient de régression β
2
n'est pas significatif, celui-ci ainsi que le facteur du nombre de pièces de l'appartement peuvent être exclus du modèle.
t cr, donc le coefficient de régression β
2
n'est pas significatif, celui-ci ainsi que le facteur du nombre de pièces de l'appartement peuvent être exclus du modèle.
Pour le coefficient de régression β
4
=2.591
statistiques définies  ,
,  >t cr, donc le coefficient de régression β
4
est important, lui et le facteur de la surface habitable de l'appartement peuvent être conservés dans le modèle.
>t cr, donc le coefficient de régression β
4
est important, lui et le facteur de la surface habitable de l'appartement peuvent être conservés dans le modèle.
Les conclusions sur la signification des coefficients du modèle sont tirées au niveau de signification α=5%. En regardant la colonne P-value, on remarque que le coefficient libre α peut être considéré comme significatif au niveau de 0,64 = 64 % ; coefficient de régression β 1 – au niveau de 0,46 = 46% ; coefficient de régression β 2 – au niveau de 0,8 = 80 % ; et le coefficient de régression β 4 – au niveau de 2,27E-06= 2,26691790951854E-06 = 0,0000002%.
Lorsque de nouvelles variables factorielles sont ajoutées à l'équation, le coefficient de détermination augmente automatiquement R. 2
et l'erreur d'approximation moyenne diminue, même si la qualité du modèle ne s'améliore pas toujours. Par conséquent, pour comparer la qualité du modèle (3) et du modèle multiple sélectionné (6), nous utilisons des coefficients de détermination normalisés.
Ainsi, en ajoutant le facteur « ville de région » à l’équation de régression X 1 et le facteur « nombre de pièces dans l'appartement » X 2 la qualité du modèle s'est détériorée, ce qui plaide en faveur de la suppression de facteurs X 1 et X 2 du modèle.
Effectuons d'autres calculs.
Coefficients d'élasticité moyens
dans le cas d'un modèle linéaire sont déterminés par les formules  .
.
En utilisant la fonction MOYENNE on trouve : S Oui, avec une augmentation seulement du facteur X 4 d’un écart type – augmente de 0,914 S Oui
Coefficients delta
sont déterminés par les formules  .
.
Trouvons les coefficients de corrélation de paires à l'aide de l'outil « Corrélation » du package « Analyse des données » dans Excel.
| Oui | X1 | X2 | X4 |
|
| Oui | 1 | |||
| X1 | -0,01126 | 1 | ||
| X2 | 0,751061 | -0,0341 | 1 | |
| X4 | 0,874012 | -0,0798 | 0,868524 | 1 |
Le coefficient de détermination a été déterminé précédemment et est égal à 0,7677.
Calculons les coefficients delta :
 ;
; 

Puisque Δ 1 1
Et X 2
mal sélectionnés et ils doivent être supprimés du modèle. Cela signifie que selon l'équation du modèle linéaire à trois facteurs résultant, la variation du facteur résultant Oui(prix des appartements) s'explique à 104% par l'influence du facteur X 4
(surface habitable de l'appartement), de 4% influencé par le facteur X 2
(nombre de pièces), de 0,0859% influencé par le facteur X 1
(ville de la région).
Ministère de l'Éducation et des Sciences de la Fédération de Russie
Établissement d'enseignement autonome de l'État fédéral d'enseignement professionnel supérieur
Université fédérale d'Extrême-Orient
École d'économie et de gestion
Département d'informatique de gestion et de méthodes économiques et mathématiques
TRAVAUX DE LABORATOIRE
dans la discipline "Modélisation de simulation"
Spécialité 080801.65 « Informatique appliquée (en économie) »
ANALYSE DE RÉGRESSION
Rudakova
Ouliana Anatolyevna
Vladivostok
RAPPORT
Mission : envisager une procédure d'analyse de régression à partir de données (prix de vente et surface habitable) sur 23 biens immobiliers.
Le mode opératoire « Régression » permet de calculer les paramètres de l'équation de régression linéaire et de vérifier son adéquation au procédé étudié.
Pour résoudre le problème de l'analyse de régression dans MS Excel, sélectionnez dans le menu Serviceéquipe Analyse des donnéeset outil d'analyse" Régression".
Dans la boîte de dialogue qui apparaît, définissez les paramètres suivants : 1.
Intervalle de saisie Y- il s'agit de la plage de données pour l'attribut résultant. Il doit être composé d'une seule colonne. 2.
Intervalle de saisie Xest une plage de cellules contenant les valeurs de facteurs (variables indépendantes). Le nombre de plages d'entrée (colonnes) ne doit pas dépasser 16. .Case à cocher Balises, est défini si la première ligne de la plage contient un titre. 5.
Zéro constant.Cette case doit être cochée si la droite de régression doit passer par l'origine (et 0=0).
6.
Intervalle de sortie/Nouvelle feuille de calcul/Nouveau classeur -spécifiez l'adresse de la cellule supérieure gauche de la plage de sortie. .Cases à cocher
en groupe Restessont définis s’il est nécessaire d’inclure les colonnes ou graphiques correspondants dans la plage de sortie. .La case Graphique de probabilité normale doit être cochée si vous souhaitez afficher un nuage de points de la dépendance des valeurs Y observées sur les intervalles centiles générés automatiquement. Après avoir cliqué sur le bouton OK dans la plage de sortie, nous obtenons un rapport. À l'aide d'un ensemble d'outils d'analyse de données, nous effectuerons une analyse de régression des données sources. L'outil d'analyse de régression est utilisé pour ajuster les paramètres d'une équation de régression à l'aide de la méthode des moindres carrés. La régression est utilisée pour analyser l'effet sur une seule variable dépendante des valeurs d'une ou plusieurs variables indépendantes. STATISTIQUES DE RÉGRESSION DE TABLE Ampleur pluriel Rest la racine du coefficient de détermination (R au carré). On l'appelle également indice de corrélation ou coefficient de corrélation multiple. Exprime le degré de dépendance des variables indépendantes (X1, X2) et de la variable dépendante (Y) et est égal à la racine carrée du coefficient de détermination ; cette valeur prend des valeurs comprises entre zéro et un. Dans notre cas, il est égal à 0,7, ce qui indique une relation significative entre les variables. Ampleur R au carré (coefficient de détermination), également appelée mesure de certitude, caractérise la qualité de la droite de régression résultante. Cette qualité s'exprime par le degré de correspondance entre les données sources et le modèle de régression (données calculées). La mesure de la certitude se situe toujours dans l'intervalle. Dans notre cas, la valeur R carré est de 0,48, soit près de 50 %, ce qui indique un mauvais ajustement de la droite de régression aux données originales. valeur trouvée R-carré = 48 %<75%, то, следовательно, также можно сделать вывод о невозможности прогнозирования с помощью найденной регрессионной зависимости. Таким образом, модель объясняет всего 48% вариации цены, что говорит о недостаточности выбранных факторов, либо о недостаточном объеме выборки. R carré normaliséest le même coefficient de détermination, mais ajusté en fonction de la taille de l'échantillon. R-carré normal = 1-(1-R-carré)*((n-1)/(n-k)), équation linéaire d'analyse de régression où n est le nombre d'observations ; k - nombre de paramètres. Il est préférable d'utiliser le R au carré normalisé lors de l'ajout de nouveaux régresseurs (facteurs), car à mesure qu’ils augmentent, la valeur R au carré augmentera également, mais cela n’indiquera pas une amélioration du modèle. Puisque dans notre cas, la valeur résultante est de 0,43 (ce qui ne diffère du R-carré que de 0,05), nous pouvons parler d'une confiance élevée dans le coefficient R-carré. Erreur typemontre la qualité de l'approximation (approximation) des résultats d'observation. Dans notre cas, l'erreur est 5.1. Calculons en pourcentage : 5,1/(57,4-40,1)=0,294 ≈ 29 % (Le modèle est considéré comme meilleur lorsque l'erreur standard est<30%)
Observations- le nombre de valeurs observées est indiqué (23). TABLEAU D'ANALYSE DE LA VARIANCE Pour obtenir l'équation de régression, une statistique est déterminée - une caractéristique de la précision de l'équation de régression, qui est le rapport de la partie de la variance de la variable dépendante expliquée par l'équation de régression à la partie inexpliquée (résiduelle) de l'écart. Dans la colonne df- le nombre de degrés de liberté k est donné. Pour le reste, c'est une valeur égale à n-(m+1), soit le nombre de points initiaux (23) moins le nombre de coefficients (2) et moins le terme libre (1). Dans la colonne SS- la somme des carrés des écarts par rapport à la valeur moyenne de la caractéristique résultante. Il présente : Somme de régression des carrés des écarts par rapport à la valeur moyenne de la caractéristique résultante des valeurs théoriques calculée à l'aide de l'équation de régression. La somme résiduelle des écarts des valeurs originales par rapport aux valeurs théoriques. La somme totale des carrés des écarts des valeurs initiales par rapport à la caractéristique résultante. Plus la somme de régression des carrés des écarts est grande (ou plus la somme résiduelle est petite), plus l'équation de régression se rapproche du nuage de points d'origine. Dans notre cas, le montant résiduel est d'environ 50 %. Par conséquent, l’équation de régression se rapproche très mal du nuage de points initial. Dans la colonne MS- variances d'échantillon non biaisées, régression et résiduel. Dans la colonne F La valeur des statistiques des critères a été calculée pour tester la signification de l'équation de régression. Pour effectuer un test statistique de significativité de l'équation de régression, une hypothèse nulle est formulée sur l'absence de relation entre les variables (tous les coefficients des variables sont égaux à zéro) et le niveau de signification est sélectionné. Le niveau de signification est la probabilité acceptable de commettre une erreur de type I – rejeter l’hypothèse nulle correcte à la suite des tests. Dans ce cas, commettre une erreur de type I revient à reconnaître dans un échantillon qu’il existe une relation entre les variables de la population alors qu’en réalité il n’y en a pas. Généralement, le niveau de signification est considéré comme étant de 5 %. En comparant la valeur obtenue = 9,4 avec la valeur du tableau = 3,5 (le nombre de degrés de liberté est respectivement de 2 et 20), on peut dire que l'équation de régression est significative (F>Fcr). Dans la colonne de signification F la probabilité de la valeur obtenue des statistiques de critère est calculée. Puisque dans notre cas cette valeur = 0,00123, soit inférieure à 0,05, on peut dire que l'équation de régression (dépendance) est significative avec une probabilité de 95 %. Les deux piliers décrits ci-dessus démontrent la fiabilité du modèle dans son ensemble. Le tableau suivant contient les coefficients des régresseurs et leurs estimations. La ligne d'origine Y n'est associée à aucun régresseur ; c'est un coefficient libre. En colonne chances les valeurs des coefficients de l'équation de régression sont enregistrées. Ainsi, l'équation a été obtenue : Y=25,6+0,009X1+0,346X2 L'équation de régression doit passer par le centre du nuage de points initiaux : 13,02≤M(b)≤38,26 Ensuite, comparez les valeurs des colonnes par paires Coefficients et erreur type. On constate que dans notre cas, toutes les valeurs absolues des coefficients dépassent les erreurs types. Cela peut indiquer l’importance des régresseurs, mais il s’agit là d’une analyse approximative. La colonne statistique t fournit une estimation plus précise de la signification des coefficients. Dans la colonne statistique t contient les valeurs du test t calculées à l'aide de la formule : t=(Coefficient)/(Erreur type) n-(k+1)=23-(2+1)=20
En utilisant la table de Student on trouve la valeur ttable = 2,086. Comparaison t avec ttable on trouve que le coefficient régresseur X2 est non significatif. Colonne valeur p représente la probabilité que la valeur critique de la statistique de test utilisée (statistique t de l'étudiant) dépasse la valeur calculée à partir de l'échantillon. Dans ce cas, nous comparons valeurs p avec le niveau de signification sélectionné (0,05). On voit que seul le coefficient régresseur X2=0,08>0,05 peut être considéré comme non significatif Les colonnes inférieures de 95 % et supérieures de 95 % fournissent des limites d'intervalle de confiance avec un niveau de confiance de 95 %. Chaque coefficient a ses propres limites : Coefficientttable*Erreur standard Les intervalles de confiance sont construits uniquement pour des valeurs statistiquement significatives. TABLE DE RETRAIT DU RESTE Reste
est l'écart d'un seul point (observation) par rapport à la droite de régression (valeur prédite). Hypothèse de normalité restes suppose que la distribution de la différence entre les valeurs prédites et observées est normale. Pour déterminer visuellement la nature de la distribution, activez la fonction tableau d'équilibre. Les tracés résiduels affichent les différences entre les valeurs Y d'origine et celles calculées à partir de la fonction de régression pour chaque valeur des composantes variables X1 et X2. Il est utilisé pour déterminer si la ligne ajustée utilisée est acceptable. Le tracé d'ajustement peut être utilisé pour fournir une représentation visuelle de la droite de régression. Les résidus standards sont des résidus normalisés pour estimer leur écart type.
L'essence des méthodes de prévision causale est d'établir un lien mathématique entre les variables résultantes et factorielles.
Une condition nécessaire à l'utilisation de méthodes de prévision causale est la disponibilité d'une grande quantité de données. Si les relations entre les variables peuvent être décrites mathématiquement correctement, la précision de la prévision causale sera alors assez élevée.
Les méthodes de prévision causale comprennent :
modèles de régression multivariée,
modélisation par simulation.
1.4.1 Modèles de régression multivariée
Un modèle de régression multivariée est une équation avec plusieurs variables indépendantes.
Pour construire un modèle de régression multivariée, diverses fonctions peuvent être utilisées ; les plus répandues sont les dépendances linéaires et de puissance :
Dans le modèle linéaire, les paramètres(b 1, b 2, ... b n) sont interprétés comme l'influence de chacune des variables indépendantes sur la valeur prédite si toutes les autres variables indépendantes sont égales à zéro.
DANS modèle de puissance les paramètres sont des coefficients d'élasticité. Ils montrent de quel pourcentage le résultat (y) changera en moyenne avec une modification du facteur correspondant de 1%, tandis que l'action des autres facteurs reste inchangée. Pour calculer les paramètres des équations de régression multiple, il est également utilisé méthode des moindres carrés.
Lors de la construction de modèles de régression, la qualité des données joue un rôle décisif. La collecte de données constitue la base des prévisions. Il existe donc un certain nombre d'exigences et de règles qui doivent être respectées lors de la collecte de données.
Premièrement, les données doivent être observable, c'est-à-dire obtenu à la suite d’une mesure et non d’un calcul.
Deuxièmement, à partir du tableau de données, il faut exclure les données en double et très divergentes. Plus il y a de données non dupliquées et plus la population est homogène, meilleure est l’équation. Par valeurs fortement différentes, nous entendons des observations qui ne rentrent pas dans la série générale. Par exemple, les données sur les salaires des travailleurs sont présentées sous forme de nombres à quatre et cinq chiffres (7 000, 10 000, 15 000), mais un seul nombre à six chiffres a été trouvé (250 000). C'est évidemment une erreur.
La troisième règle (exigence) est une assez grande quantité de données. Les statisticiens ont des opinions divergentes sur la quantité de données nécessaire pour construire une bonne équation. Selon certains, les données sont nécessaires 4 à 6 fois plus nombre de facteurs. D'autres affirment que au moins 10 fois plus nombre de facteurs, alors la loi des grands nombres, opérant pleinement, assure la suppression efficace des écarts aléatoires par rapport à la nature naturelle de la relation.
Construction d'un modèle de régression multivariée enMSExceller
Dans les feuilles de calcul Excel, il est possible de créer uniquement linéaire modèle de régression multivariée.
, (1.19)
Pour ce faire, vous devez sélectionner l'élément "Analyse des données" puis dans la fenêtre qui apparaît - outil "régression"

Figure 1.45 – Boîte de dialogue de l'outil « Régression »
Dans la fenêtre qui apparaît, vous devez remplir un certain nombre de champs, notamment :
Intervalle de saisie Oui – une plage de données, issue d’une colonne, contenant les valeurs de la variable résultante Y.
Intervalle de saisie X est une plage de données contenant les valeurs des variables factorielles.
Si la première ligne ou la première colonne de l'intervalle de saisie contient des en-têtes, vous devez alors cocher la case "étiquettes" .
Valeur par défaut appliquée niveau de fiabilité 95%. Si vous souhaitez définir un niveau différent, cochez la case et saisissez le niveau de fiabilité souhaité dans le champ à côté.
Case à cocher "Zéro constant" ne doit être vérifié que si vous souhaitez obtenir une équation de régression sans terme d'origine UN, de sorte que la droite de régression passe par l’origine.
La sortie des résultats de calcul peut être organisée de 3 manières :
V plage de cellules dans cette feuille de calcul (pour cela sur le terrain "Plage de sortie" définir la cellule supérieure gauche de la plage où les résultats du calcul seront affichés) ;
sur nouvelle feuille de calcul (dans le champ à côté vous pouvez saisir le nom souhaité de cette feuille) ;
V nouveau classeur .
Définir des cases à cocher "Restes" Et "Soldes standardisés" ordonne leur inclusion dans la plage de sortie.
Pour tracer les résidus pour chaque variable indépendante, cochez la case "Tableau des soldes."Restes autrement appelés erreurs de prévision. Elles sont définies comme la différence entre les valeurs Y réelles et prédites.
Interprétation des parcelles résiduelles
Il ne devrait y avoir aucune tendance dans les graphiques résiduels. Si une tendance peut être tracée, cela signifie que le modèle n'inclut pas un facteur inconnu pour nous, mais un facteur agissant naturellement et sur lequel il n'existe aucune donnée.
En cochant la case "Calendrier de sélection" une série de graphiques s'affichera montrant dans quelle mesure la droite de régression théorique correspond à celles observées, c'est-à-dire données réelles.
Interprétation des graphiques de sélection
Dans Excel, les points rouges sur les graphiques d'ajustement indiquent les valeurs théoriques Oui, points bleus - données originales. Si les points rouges se chevauchent bien avec les points bleus, cela indique visuellement une équation de régression réussie.
Une étape nécessaire de la prévision basée sur des modèles de régression multivariée consiste à évaluer la signification statistique de l'équation de régression, c'est-à-dire pertinence de l’équation de régression construite pour une utilisation à des fins de prévision. Pour résoudre ce problème, un certain nombre de coefficients sont calculés dans MS Excel. À savoir:
Coefficient de corrélation multiple
Caractérise la proximité et la direction de la connexion entre le résultat et plusieurs variables factorielles. Avec une dépendance à deux facteurs, le coefficient de corrélation multiple est calculé à l'aide de la formule : ![]() , (1.20)
, (1.20)
Coefficient de détermination multiple ( R. 2 ).
R 2 est la proportion de variation de la valeur théorique par rapport aux valeurs réelles de y, expliquée par les facteurs inclus dans le modèle. Le reste des valeurs théoriques dépend d'autres facteurs non impliqués dans le modèle. R 2 peut prendre des valeurs de 0 à 1. Si , alors la qualité du modèle est élevée. Cet indicateur est particulièrement utile pour comparer plusieurs modèles et choisir le meilleur.
Coefficient de détermination normalisé R. 2
L'indicateur R2 présente l'inconvénient que de grandes valeurs du coefficient de détermination peuvent être obtenues grâce à un petit nombre d'observations. Normalisé fournit des informations sur la valeur que vous pourriez obtenir dans un autre ensemble de données beaucoup plus volumineux que dans ce cas.
Le normalisé est calculé à l'aide de la formule :
![]() , (1.21)
, (1.21)
où est le coefficient de détermination multiple normalisé,
Coefficient de détermination multiple,
Le volume du granulat,
Nombre de variables factorielles.
Erreur type de régression indique l'ampleur approximative de l'erreur de prédiction. Utilisé comme quantité de base pour mesurer la qualité du modèle évalué. Calculé à l'aide de la formule :
où est la somme des carrés des restes,
Nombre de degrés de liberté des résidus.
Autrement dit, l’erreur standard de régression montre l’erreur quadratique par degré de liberté.
| CONCLUSION DES RÉSULTATS | |||||||||
| Statistiques de régression | |||||||||
| Pluriel R | 0.973101 | ||||||||
| Carré R | 0.946926 | ||||||||
| R carré normalisé | 0.940682 | ||||||||
| Erreur type | 0.59867 | ||||||||
| Observations | 20 | ||||||||
| Analyse de variance | |||||||||
| df | SS | MS | F | Signification F | |||||
| Régression | 2 | 108.7071 | 54.35355 | 151.6535 | 1.45E-11 | ||||
| Reste | 17 | 6.092905 | 0.358406 | ||||||
| Total | 19 | 114.8 | |||||||
| Chances | Erreur type | statistique t | Valeur P | 95 % inférieurs | Meilleurs 95 % | 95,0 % inférieurs | Meilleurs 95,0 % |
||
| Intersection en Y | 1.835307 | 0.471065 | 3.89608 | 0.001162 | 0.841445 | 2.829169 | 0.841445 | 2.829169 |
|
| x1 | 0.945948 | 0.212576 | 4.449917 | 0.000351 | 0.49745 | 1.394446 | 0.49745 | 1.394446 |
|
| x2 | 0.085618 | 0.060483 | 1.415561 | 0.174964 | -0.04199 | 0.213227 | -0.04199 | 0.213227 |
|
La méthode d'analyse de variance consiste à décomposer la somme totale des écarts carrés d'une variable à de la valeur moyenne en deux parties :
expliqué par la régression (ou le facteur),
résiduel.
La pertinence d'un modèle de régression pour la prédiction dépend de la proportion de la variation totale du trait oui explique la variation expliquée par la régression. Évidemment, si la somme des écarts carrés expliqués par la régression est supérieure au résidu, alors une conclusion est tirée sur la signification statistique de l'équation de régression. Cela équivaut au fait que le coefficient de détermination se rapproche de l'unité.
Désignations dans le tableau « Analyse des écarts » :
La deuxième colonne du tableau s'appelle et signifie le nombre de degrés de liberté. Pour la variance totale, le nombre de degrés de liberté est égal à : , pour la variance factorielle (ou variance expliquée par régression), pour la variance résiduelle.
où n est le nombre d'observations,
m – nombre de variables factorielles du modèle.
La troisième colonne du tableau s'appelle . Il représente la somme des carrés des écarts. La somme totale des écarts au carré est déterminée par la formule :
, (1.24)
Somme factorielle des carrés :
, (1.26)
La quatrième colonne est appelée valeur moyenne des écarts carrés. Déterminé par la formule :
À l'aide du test F de Fisher, la signification statistique du coefficient de détermination de l'équation de régression est déterminée. Pour ce faire, une hypothèse nulle est avancée, selon laquelle entre les variables résultantes et factorielles pas de connexion. Cela n'est possible que si tous les paramètres de l'équation de régression linéaire multiple et le coefficient de corrélation sont égaux à zéro.
Pour tester cette hypothèse, il est nécessaire de calculer la valeur réelle du test F de Fisher et de la comparer avec celle du tableau. La valeur réelle du critère F est calculée à l'aide de la formule :
![]() , (1.28)
, (1.28)
Sélectionné à partir de tableaux statistiques spéciaux par :
un niveau de signification donné () et
nombre de degrés de liberté.
Dans MS Excel, la valeur tabulaire du critère F peut être déterminée à l'aide de la fonction : =DFIST(probabilité, degrés de liberté1, degrés de liberté2)
Par exemple : =FDISC(0,05;df1;df2)
Niveau de signification 1 est choisi pour être le même que celui sur lequel les paramètres du modèle de régression ont été calculés. La valeur par défaut est 95 %.
Si , alors l'hypothèse avancée est rejetée et la signification statistique de l'équation de régression est reconnue. Dans le cas de prévisions particulièrement importantes, il est recommandé d'augmenter de 4 fois la valeur tabulaire du critère F, c'est-à-dire que la condition est vérifiée :
=151.65; = 3.59
La valeur calculée dépasse largement la valeur du tableau. Cela signifie que le coefficient de détermination est significativement différent de zéro, de sorte que l'hypothèse d'absence de dépendance à la régression doit être rejetée.
Estimons maintenant la signification des coefficients de régression basés sur t-Test de Student. Il vous permet de déterminer laquelle des variables factorielles (x) a le plus grand impact sur la variable résultante (y).
Les erreurs types sont généralement désignées par .
L'indice désigne le paramètre de l'équation de régression pour lequel cette erreur est calculée
Calculé à l'aide de la formule :
 , (1.29)
, (1.29)
où est l'écart type de la variable résultante,
RMS pour la caractéristique,
Coefficient de détermination pour l'équation multiple
les régressions,
Le coefficient de détermination de la dépendance du facteur avec
tous les autres facteurs de l’équation.
Nombre de degrés de liberté pour la somme des carrés résiduelle
déviations.
Dans MS Excel, les erreurs types sont calculées automatiquement (situées dans la 3ème colonne du 3ème tableau).
Valeur réellet-Test de Student dans MS Excel, il se situe dans la 4ème colonne du 3ème tableau et s'appelle statistiques t.
(4ème colonne) = (2ème colonne) / (3ème colonne)
statistique t = Coefficients/Erreur type
Valeur du tableaut-Test de Student dépend du niveau de signification accepté (généralement 0,05 ; 0,01) et du nombre de degrés de liberté.
où n est le nombre d'unités dans la population,
m est le nombre de facteurs dans l'équation.
Dans MS Excel, la valeur du tableau du test de l'étudiant peut être déterminée à l'aide de la fonction :
STUDRIST(probabilité ; nombre de degrés de liberté)
Par exemple : =STUDISCOVER(0.05,7)
Si , alors on conclut que le coefficient de l’équation de régression est statistiquement significatif (fiable) et peut être inclus dans le modèle et utilisé à des fins de prévision.
1.4.2 Méthode de simulation Monte Carlo
La méthode de simulation doit son nom à la ville de Monte Carlo, située dans la Principauté de Monaco, l'un des plus petits pays du monde, situé sur la côte méditerranéenne, près de la frontière entre la France et l'Italie.
La méthode de simulation Monte Carlo consiste à générer des valeurs aléatoires conformément à des contraintes spécifiées. Lorsque l'on commence à réaliser une modélisation de simulation, il est tout d'abord nécessaire de développer un modèle économique et mathématique (EMM) de l'indicateur prédit, reflétant la relation entre les variables factorielles, ainsi que le degré et la nature de leur influence sur le résultat. . Étant donné que dans les conditions de marché modernes, le sujet des relations économiques est simultanément influencé par de nombreux facteurs de nature et de direction différentes et que le degré de leur influence n'est pas déterministe, il semble nécessaire de diviser les variables EMM en deux groupes : stochastiques et déterministes ;
Ensuite, vous devez déterminer les types de distributions de probabilité pour chaque variable stochastique et les paramètres d'entrée correspondants, et simuler les valeurs des variables stochastiques à l'aide d'un générateur de nombres aléatoires MS Excel ou d'un autre logiciel.
L'outil « génération de nombres aléatoires » est disponible pour les utilisateurs de MS Excel 2007 après avoir activé le complément. Pack d'analyse. La procédure d'activation du module complémentaire est décrite ci-dessus (voir page 10, Fig. 1.5-1.8). Pour effectuer une simulation dans le menu DONNÉES vous devez sélectionner un élément "Analyse des données", dans la boîte de dialogue qui apparaît, sélectionnez un outil dans la liste "Génération de nombres aléatoires" et cliquez sur OK. 
Figure 1.46 - Interface du menu d'analyse des données
Dans la boîte de dialogue qui apparaît, vous devez sélectionner le type de distribution de probabilité pour chaque variable stochastique et définir les paramètres d'entrée appropriés. 
Figure 1.47 - Boîte de dialogue Générateur de nombres aléatoires
Cette étape est l’une des plus difficiles, donc lors de sa réalisation, il est nécessaire d’utiliser les connaissances et l’expérience d’experts. Sélection du type de distribution de probabilité peut également être réalisée sur la base des informations statistiques disponibles. En pratique, les types de distributions de probabilité les plus couramment utilisés sont normales, triangulaires et uniformes.
Distribution normale (ou loi de Moivre-Gauss-Laplace) suppose que les variantes du paramètre prédit tendent vers la valeur moyenne. Les valeurs d'une variable qui diffèrent significativement de la moyenne, c'est-à-dire situées dans les « queues » de la distribution, ont une faible probabilité.
Répartition triangulaire est un dérivé de la distribution normale et suppose une distribution linéairement croissante à mesure qu'elle se rapproche de la valeur moyenne.
Répartition uniforme est utilisé dans le cas où toutes les valeurs de l'indicateur variable ont la même probabilité de mise en œuvre.
Lorsque la variable est importante et impossibilité de choisir la loi de distribution il peut être vu du point de vue répartition discrète. Les types de distributions de probabilité répertoriés ci-dessus nécessitent la détermination des paramètres d'entrée présentés dans le tableau 1.11.
Tableau 1.11 - Paramètres d'entrée des principaux types de distributions de probabilité
| Type de probabiliste distribution | Paramètres d'entrée |
| 1 Répartition normale |
|
| 2 Répartition triangulaire |
|
| 3 Répartition uniforme |
|
| 4 Distribution discrète |
|
À la suite d'une série d'expériences, une distribution des valeurs des variables stochastiques sera obtenue, sur la base de laquelle la valeur de l'indicateur prédit devra être calculée.
La prochaine étape nécessaire consiste à effectuer une analyse économique et statistique des résultats de la modélisation de simulation, dans laquelle il est recommandé de calculer les caractéristiques statistiques suivantes :
valeur moyenne;
écart type ;
dispersion;
valeur minimale et maximale ;
plage de swing;
coefficient d'asymétrie;
excès.

Figure 1.48 - Histogramme des valeurs prédites des indicateurs
La mise en œuvre de ces étapes permettra d'obtenir une évaluation probabiliste des valeurs de l'indicateur prédit (prévision à intervalle).
Lors de l’étude de phénomènes complexes, il est nécessaire de prendre en compte plus de deux facteurs aléatoires. Une compréhension correcte de la nature de la relation entre ces facteurs ne peut être obtenue que si tous les facteurs aléatoires considérés sont examinés en même temps. Une étude conjointe de trois facteurs aléatoires ou plus permettra au chercheur d'établir des hypothèses plus ou moins raisonnables sur les dépendances causales entre les phénomènes étudiés. Une forme simple de relation multiple est une relation linéaire entre trois caractéristiques. Les facteurs aléatoires sont notés X 1 , X 2 et X 3. Coefficients de corrélation appariés entre X 1 et X 2 est noté r 12, respectivement entre X 1 et X 3 - r 12, entre X 2 et X 3 - r 23. Pour mesurer l'étroitesse de la relation linéaire entre trois caractéristiques, plusieurs coefficients de corrélation sont utilisés, notés R. 1 et 23, R. 2 et 13, R. 3 ּ 12 et coefficients de corrélation partielle, notés r 12.3 , r 13.2 , r 23.1 .
Le coefficient de corrélation multiple R 1,23 de trois facteurs est un indicateur de l'étroitesse de la relation linéaire entre l'un des facteurs (indice avant le point) et la combinaison de deux autres facteurs (indices après le point).
Les valeurs du coefficient R sont toujours comprises entre 0 et 1. À mesure que R s'approche de un, le degré de relation linéaire entre les trois caractéristiques augmente.
Entre le coefficient de corrélation multiple, par ex. R. 2 ּ 13 et deux coefficients de corrélation de paires r 12 et r 23 il existe une relation : chacun des coefficients appariés ne peut excéder en valeur absolue R. 2 et 13 .
Les formules de calcul de coefficients de corrélation multiples avec des valeurs connues des coefficients de corrélation de paires r 12, r 13 et r 23 ont la forme :
Coefficient de corrélation multiple au carré R. 2 s'appelle coefficient de détermination multiple. Il montre la proportion de variation de la variable dépendante sous l'influence des facteurs étudiés.
L'importance de la corrélation multiple est évaluée par F-critère:
![]()
n – taille de l'échantillon ; k- nombre de facteurs. Dans notre cas k = 3.
hypothèse nulle sur l'égalité du coefficient de corrélation multiple dans la population à zéro ( ho:r=0) est accepté si f f<ft, et est rejeté si
f f³ f T.
valeur théorique f-des critères sont déterminés pour v 1 = k- 1 et v 2 = n - k degrés de liberté et niveau de signification accepté a (Annexe 1).
Exemple de calcul du coefficient de corrélation multiple. Lors de l'étude de la relation entre les facteurs, des coefficients de corrélation de paires ont été obtenus ( n =15): r 12 ==0,6 ; g13 = 0,3 ; r 23 = - 0,2.
Il est nécessaire de connaître la dépendance de la fonctionnalité X 2 du signe X 1 et X 3, c'est-à-dire calculer le coefficient de corrélation multiple :

Valeur du tableau F-critères avec n 1 = 2 et n 2 = 15 – 3 = 12 degrés de liberté avec a = 0,05 F 0,05 = 3,89 et à a = 0,01 F 0,01 = 6,93.
Ainsi, la relation entre les signes R. 2,13 = 0,74 est significatif à
Niveau de signification de 1 % F f > F 0,01 .
A en juger par le coefficient de détermination multiple R. 2 = (0,74) 2 = 0,55, variation des traits X 2 est associé à 55 % à l'effet des facteurs étudiés, et 45 % de la variation (1-R 2) ne peut s'expliquer par l'influence de ces variables.
Corrélation linéaire partielle
Coefficient de corrélation partielle est un indicateur qui mesure le degré de conjugaison de deux caractéristiques.
Les statistiques mathématiques permettent d'établir une corrélation entre deux caractéristiques avec une valeur constante de la troisième, sans mener d'expérience particulière, mais en utilisant des coefficients de corrélation appariés r 12 , r 13 , r 23 .
Les coefficients de corrélation partielle sont calculés à l'aide des formules :

Les chiffres avant le point indiquent les caractéristiques sur lesquelles la relation est étudiée, et le nombre après le point indique l'influence de la caractéristique qui est exclue (éliminée). L'erreur et le critère de signification pour la corrélation partielle sont déterminés à l'aide des mêmes formules que pour la corrélation par paires :
 .
.
Valeur théorique t- le critère est déterminé pour v = n– 2 degrés de liberté et niveau de signification accepté a (Annexe 1).
L'hypothèse nulle selon laquelle le coefficient de corrélation partielle dans la population est égal à zéro ( H o: r= 0) est accepté si t f< t t, et est rejeté si
t f³ t T.
Les coefficients partiels peuvent prendre des valeurs comprises entre -1 et +1. Privé coefficients de détermination trouvé en mettant au carré les coefficients de corrélation partielle :
D 12.3 = r 2 12ּ3 ; d 13.2 = r 2 13ּ2 ; d 23ּ1 = r 2 23ּ1 .
Déterminer le degré d'influence partielle de facteurs individuels sur un trait efficace tout en excluant (éliminant) son lien avec d'autres traits qui faussent cette corrélation est souvent d'un grand intérêt. Il arrive parfois qu'à valeur constante de la caractéristique éliminée, il soit impossible de constater son influence statistique sur la variabilité des autres caractéristiques. Pour comprendre la technique de calcul du coefficient de corrélation partielle, prenons un exemple. Il y a trois options X, Oui Et Z. Pour la taille de l'échantillon n= 180 coefficients de corrélation appariés sont déterminés
r xy = 0,799; rxz = 0,57; r yz = 0,507.
Déterminons les coefficients de corrélation partielle :

Coefficient de corrélation partielle entre paramètre X Et Oui Z (r xyּz = 0,720) montre que seule une petite partie de la relation entre ces caractéristiques dans la corrélation globale ( r xy= 0,799) est dû à l'influence de la troisième caractéristique ( Z). Une conclusion similaire doit être tirée concernant le coefficient de corrélation partielle entre le paramètre X et paramètre Z avec une valeur de paramètre constante Oui (r X zּу = 0,318 et rxz= 0,57). Au contraire, le coefficient de corrélation partielle entre les paramètres Oui Et Z avec une valeur de paramètre constante X r yz ּ x= 0,105 est significativement différent du coefficient de corrélation global r y z = 0,507. Il ressort clairement de cela que si vous sélectionnez des objets avec la même valeur de paramètre X, puis la relation entre les signes Oui Et Z ils en auront une très faible, puisqu'une partie importante de cette relation est due à la variation du paramètre X.
Dans certaines circonstances, le coefficient de corrélation partielle peut être de signe opposé à celui de la paire.
Par exemple, lors de l'étude de la relation entre les caractéristiques X, Oui Et Z- des coefficients de corrélation appariés ont été obtenus (avec n = 100): r xy = 0,6 ; r X z= 0,9;
ry z = 0,4.
Coefficients de corrélation partielle excluant l'influence de la troisième caractéristique :

L'exemple montre que les valeurs du coefficient de paire et du coefficient de corrélation partielle diffèrent en signe.
La méthode de corrélation partielle permet de calculer le coefficient de corrélation partielle du second ordre. Ce coefficient indique la relation entre les première et deuxième caractéristiques avec une valeur constante des troisième et quatrième. La détermination du coefficient partiel du second ordre s'effectue à partir des coefficients partiels du premier ordre selon la formule :

Où r 12 . 4 , r 13 et 4, r 23 ּ4 - coefficients partiels dont la valeur est déterminée par la formule des coefficients partiels, à l'aide de coefficients de corrélation par paires r 12 , r 13 , r 14 , r 23 , r 24 , r 34 .
Essayons d'abord de trouver une réponse à chacune des questions que nous avons identifiées dans une situation où notre modèle causal ne contient que deux variables indépendantes.
Corrélation multiple R et coefficient de détermination R2
Pour estimer la relation globale de toutes les variables indépendantes avec la variable dépendante, utilisez coefficient de corrélation multiple R. Différence entre les coefficients de corrélation multiples R. à partir du coefficient de corrélation bivarié G c'est que cela ne peut être que positif. Pour deux variables indépendantes, il peut être estimé comme suit :
Le coefficient de corrélation multiple peut également être déterminé en estimant les coefficients de régression partielle qui composent l'équation (9.1). Pour deux variables, cette équation prendra évidemment la forme suivante :
![]() (9.2)
(9.2)
Si nos variables indépendantes sont transformées en unités de la distribution normale standard, ou distribution Z, l'équation (9.2) devient évidemment :
![]() (9.3)
(9.3)
Dans l'équation (9.3), le coefficient β désigne la valeur standardisée du coefficient de régression DANS.
Les coefficients de régression standardisés eux-mêmes peuvent être calculés à l'aide des formules suivantes :
Maintenant, la formule de calcul du coefficient de corrélation multiple ressemblera à ceci :
![]()
Une autre façon d'estimer le coefficient de corrélation R. est le calcul du coefficient de corrélation bivarié r entre les valeurs de la variable dépendante Y et les valeurs correspondantes calculées sur la base de l'équation de régression linéaire (9.2). Autrement dit, la valeur R. peut être évalué comme suit :
A côté de ce coefficient, on peut estimer, comme dans le cas d'une régression simple, la valeur R. 2, qui est aussi généralement désigné par coefficient de détermination. Tout comme dans la situation d'évaluation de la relation entre deux variables, le coefficient de détermination R. 2 montre quel pourcentage de la variance de la variable dépendante Oui , c'est-à-dire , s’avère être lié à la dispersion de toutes les variables indépendantes – . Autrement dit, le coefficient de détermination peut être évalué comme suit :
Nous pouvons également estimer le pourcentage de variance résiduelle dans la variable dépendante qui n’est associée à aucune des variables indépendantes 1 – R. 2. La racine carrée de cette valeur, c'est-à-dire la quantité , tout comme dans le cas d'une corrélation bivariée, est appelée coefficient d'aliénation.
Partie corrélation
Coefficient de détermination R. La figure 2 montre quel pourcentage de la variance de la variable dépendante peut être attribué à la variance de toutes les variables indépendantes incluses dans le modèle causal. Plus ce coefficient est grand, plus le modèle causal que nous proposons est significatif. Si ce coefficient s'avère pas trop grand, alors la contribution des variables que nous étudions à la variance totale de la variable dépendante s'avère également insignifiante. Toutefois, en pratique, il est souvent nécessaire d’estimer non seulement la contribution totale de toutes les variables, mais également la contribution individuelle de chacune des variables indépendantes considérées. Une telle contribution peut être définie comme partie de corrélation.
Comme nous le savons, dans le cas d'une corrélation bivariée, le pourcentage de variance de la variable dépendante associé à la variance de la variable indépendante peut être noté r 2. Cependant, une partie de cette variance dans le cas de l'étude des effets de plusieurs variables indépendantes est simultanément due à la variance de la variable indépendante, que nous utilisons comme contrôle. Ces relations sont clairement montrées sur la Fig. 9.1.

Riz. 9.1. Le rapport des variances de la personne à charge (Oui ) et deux indépendants (X 1EtX 2) variables dans l'analyse de corrélation avec deux variables indépendantes
Comme le montre la fig. 9.1, toutes dérogations Oui , associé à nos deux variables indépendantes, se compose de trois parties, étiquetées une, b Et Avec. Parties UN Et b écarts Oui appartiennent séparément aux variances de deux variables indépendantes – X 1 et X 2. Dans le même temps, la dispersion de la partie c relie simultanément à la fois la dispersion de la variable dépendante Y et la dispersion de nos deux variables X. Par conséquent, afin d’évaluer la relation de la variable X 1 avec variable Oui, ce qui n'est pas dû à l'influence de la variable X 2 par variable Oui , nécessaire à partir de la quantité R" 2 soustraire la valeur de la corrélation au carré Oui Avec X 2:
![]() (9.6)
(9.6)
De la même manière, on peut estimer la part de la corrélation Y avec X 2, ce qui n’est pas dû à sa corrélation avec X 1.
![]() (9.7)
(9.7)
Ampleur sr dans les équations (9.6) et (9.7) est celui que nous recherchons partie de corrélation.
La corrélation d'une pièce peut également être définie en termes de corrélation bivariée habituelle :

D'une autre manière, la corrélation partielle est appelée corrélation semi-partielle. Ce nom signifie que lors du calcul d'une corrélation, l'effet de la deuxième variable indépendante est éliminé par rapport aux valeurs de la première variable indépendante, mais n'est pas éliminé par rapport à la variable dépendante. Effet X 1 est en quelque sorte ajusté en utilisant les valeurs X 2, le coefficient de corrélation n'est donc pas calculé entre Oui Et X 1 et entre Oui et , et les valeurs sont calculées en fonction des valeurs X 2, comme indiqué dans le chapitre sur la régression linéaire simple (voir la sous-section 7.4.2). Ainsi, la relation suivante s’avère valide :
Afin d'évaluer la corrélation d'une variable indépendante avec une variable dépendante en l'absence d'influence d'autres variables indépendantes à la fois sur la variable indépendante elle-même et sur la variable dépendante, le concept de corrélation partielle est utilisé dans l'analyse de régression.
Corrélations partielles
Privé, ou partielle, corrélation est déterminé en statistique mathématique par la proportion de la variance de la variable dépendante associée à la variance d'une variable indépendante donnée, par rapport à la totalité de la variance de cette variable dépendante, sans compter la partie de celle-ci qui est associée à la variance des autres variables indépendantes. Formellement, pour le cas de deux variables indépendantes, cela peut s’exprimer ainsi :

Les valeurs de corrélation partielle elles-mêmes pr peut être trouvé sur la base des valeurs de corrélation bivariées :

La corrélation partielle peut ainsi être définie comme la corrélation bivariée ordinaire entre les valeurs ajustées de la variable dépendante et indépendante. La correction elle-même est effectuée en fonction des valeurs de la variable indépendante, qui fait office de variable de contrôle. En d’autres termes, la corrélation partielle entre la variable dépendante Oui et variable indépendante X je peux être défini comme la corrélation habituelle entre les valeurs et les valeurs de , avec les valeurs de et prédites en fonction des valeurs de la deuxième variable indépendante X 2.