Melakukan analisis statistik apa pun tidak terpikirkan tanpa perhitungan. Pada artikel ini kita akan melihat cara menghitung varians, deviasi standar, koefisien variasi, dan indikator statistik lainnya di Excel.
Nilai maksimum dan minimum
Deviasi linier rata-rata
Deviasi linier rata-rata adalah rata-rata deviasi absolut (modulo) dari kumpulan data yang dianalisis. Rumus matematikanya adalah:
A– deviasi linier rata-rata,
X– indikator yang dianalisis,
X– nilai rata-rata indikator,
N
Di Excel fungsi ini disebut SROTCL.

Setelah memilih fungsi SROTCL, kami menunjukkan rentang data di mana penghitungan harus dilakukan. Klik "Oke".
Penyebaran
(modul 111)
Mungkin tidak semua orang tahu apa itu, jadi saya akan jelaskan, ini adalah ukuran yang mencirikan penyebaran data di sekitar ekspektasi matematis. Namun biasanya hanya sampel yang tersedia, sehingga digunakan rumus varians sebagai berikut:
![]()
hal 2– varians sampel dihitung dari data observasi,
X– nilai-nilai individu,
X– mean aritmatika untuk sampel,
N– jumlah nilai dalam kumpulan data yang dianalisis.
Fungsi Excel yang sesuai adalah DISP.G. Saat menganalisis sampel yang relatif kecil (hingga sekitar 30 observasi), Anda harus menggunakan , yang dihitung menggunakan rumus berikut.
![]()
Perbedaannya, seperti yang Anda lihat, hanya pada penyebutnya. Excel memiliki fungsi untuk menghitung varians sampel yang tidak bias DISP.B.

Pilih opsi yang diinginkan (umum atau selektif), tunjukkan rentangnya, dan klik tombol “OK”. Nilai yang dihasilkan mungkin sangat besar karena penyimpangan sebelumnya dikuadratkan. Dispersi dalam statistik merupakan indikator yang sangat penting, namun biasanya tidak digunakan dalam bentuk murni, melainkan untuk perhitungan lebih lanjut.
Deviasi standar
Deviasi standar (RMS) adalah akar dari varians. Indikator ini disebut juga deviasi standar dan dihitung dengan rumus:
oleh populasi umum

berdasarkan sampel

Anda cukup mengambil akar variansnya, namun Excel memiliki fungsi siap pakai untuk deviasi standar: STDEV.G Dan STDEV.V(untuk populasi umum dan sampel, masing-masing).

Standar dan deviasi standar, saya ulangi, adalah sinonim.
Selanjutnya, seperti biasa, tunjukkan rentang yang diinginkan dan klik “OK”. Standar deviasi memiliki satuan pengukuran yang sama dengan indikator yang dianalisis, sehingga dapat dibandingkan dengan data aslinya. Lebih lanjut tentang ini di bawah.
Koefisien variasi
Semua indikator yang dibahas di atas terikat pada skala sumber data dan tidak memungkinkan seseorang memperoleh gambaran kiasan tentang variasi populasi yang dianalisis. Untuk mendapatkan ukuran relatif penyebaran data, gunakan koefisien variasi, yang dihitung dengan membagi deviasi standar pada rata-rata aritmatika. Rumus koefisien variasi sederhana:
Tidak ada fungsi siap pakai untuk menghitung koefisien variasi di Excel, dan ini bukan masalah besar. Perhitungannya dapat dilakukan hanya dengan membagi standar deviasi dengan mean. Untuk melakukan ini, tulis di bilah rumus:
DEVIASI STANDAR.G()/RATA-RATA()
Rentang data ditunjukkan dalam tanda kurung. Jika perlu, gunakan standar deviasi sampel (STDEV.B).
Koefisien variasi biasanya dinyatakan sebagai persentase, sehingga Anda bisa membingkai sel dengan rumus dalam format persentase. Tombol yang diperlukan terletak pada pita pada tab "Beranda":

Anda juga dapat mengubah format dengan memilih dari menu konteks setelah menyorot sel yang diinginkan dan mengklik kanan.
Koefisien variasi, tidak seperti indikator sebaran nilai lainnya, digunakan sebagai indikator variasi data yang independen dan sangat informatif. Dalam statistika secara umum diterima bahwa jika koefisien variasi kurang dari 33% maka kumpulan datanya homogen, jika lebih dari 33% maka heterogen. Informasi ini dapat berguna untuk karakterisasi awal data dan untuk mengidentifikasi peluang untuk analisis lebih lanjut. Selain itu, koefisien variasi, diukur sebagai persentase, memungkinkan Anda membandingkan tingkat penyebaran data yang berbeda, terlepas dari skala dan satuan pengukurannya. Properti yang berguna.
Koefisien osilasi
Indikator lain dari penyebaran data saat ini adalah koefisien osilasi. Ini adalah rasio rentang variasi (selisih antara nilai maksimum dan minimum) terhadap rata-rata. Tidak ada rumus Excel yang siap pakai, jadi Anda harus menggabungkan tiga fungsi: MAX, MIN, AVERAGE.

Koefisien osilasi menunjukkan tingkat variasi relatif terhadap mean, yang juga dapat digunakan untuk membandingkan kumpulan data yang berbeda.
Secara umum, dengan menggunakan Excel, banyak indikator statistik dihitung dengan sangat sederhana. Jika ada yang kurang jelas, Anda selalu dapat menggunakan kotak pencarian di fungsi sisipkan. Ya, Google siap membantu.
Menurut survei sampel, para deposan dikelompokkan berdasarkan besarnya simpanan mereka di Bank Tabungan kota:
Mendefinisikan:
1) ruang lingkup variasi;
2) ukuran simpanan rata-rata;
3) deviasi linier rata-rata;
4) penyebaran;
5) standar deviasi;
6) koefisien variasi iuran.
Larutan:
Seri distribusi ini berisi interval terbuka. Dalam deret seperti itu, nilai interval golongan pertama secara konvensional dianggap sama dengan nilai interval golongan berikutnya, dan nilai interval golongan terakhir sama dengan nilai interval golongan. yang sebelumnya.
Nilai interval grup kedua sama dengan 200, maka nilai grup pertama juga sama dengan 200. Nilai interval grup kedua dari belakang sama dengan 200, artinya interval terakhir juga akan sama. mempunyai nilai 200.
1) Mari kita definisikan rentang variasi sebagai selisih antara nilai atribut terbesar dan terkecil:
Kisaran variasi ukuran setoran adalah 1000 rubel.
2) Rata-rata besaran iuran akan ditentukan dengan menggunakan rumus rata-rata aritmatika tertimbang.
Mari kita tentukan terlebih dahulu nilai diskrit atribut pada setiap interval. Untuk melakukan ini, dengan menggunakan rumus mean aritmatika sederhana, kita menemukan titik tengah interval.
Nilai rata-rata interval pertama adalah:

yang kedua - 500, dll.
Mari kita masukkan hasil perhitungannya ke dalam tabel:
| Jumlah setoran, gosok. | Jumlah penabung, f | Tengah interval, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Total | 400 | - | 312000 |
Setoran rata-rata di Bank Tabungan kota adalah 780 rubel:
3) Simpangan linier rata-rata adalah rata-rata aritmatika dari simpangan absolut nilai-nilai individu suatu karakteristik dari rata-rata keseluruhan:

Tata cara menghitung simpangan linier rata-rata pada deret distribusi interval adalah sebagai berikut:
1. Rata-rata aritmatika tertimbang dihitung, seperti yang ditunjukkan pada paragraf 2).
2. Penyimpangan mutlak dari rata-rata ditentukan:
3. Deviasi yang dihasilkan dikalikan dengan frekuensi:
4. Tentukan jumlah simpangan tertimbang tanpa memperhitungkan tandanya:
5. Jumlah deviasi tertimbang dibagi dengan jumlah frekuensi:
Lebih mudah menggunakan tabel data perhitungan:
| Jumlah setoran, gosok. | Jumlah penabung, f | Tengah interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Total | 400 | - | - | - | 81280 |

Deviasi linier rata-rata dari jumlah setoran klien Bank Tabungan adalah 203,2 rubel.
4) Dispersi merupakan mean aritmatika dari kuadrat deviasi setiap nilai atribut terhadap mean aritmatika.
Perhitungan varians pada deret distribusi interval dilakukan dengan menggunakan rumus:

Tata cara penghitungan varians dalam hal ini adalah sebagai berikut:
1. Tentukan mean aritmatika tertimbang seperti yang ditunjukkan pada paragraf 2).
2. Temukan penyimpangan dari rata-rata:
3. Kuadratkan deviasi setiap pilihan dari rata-rata:
4. Kalikan kuadrat simpangan dengan bobot (frekuensi):
![]()
5. Ringkaslah produk yang dihasilkan:
![]()
6. Jumlah yang dihasilkan dibagi dengan jumlah bobot (frekuensi):

Mari kita masukkan perhitungannya ke dalam tabel:
| Jumlah setoran, gosok. | Jumlah penabung, f | Tengah interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Total | 400 | - | - | - | 23040000 |
Didefinisikan sebagai karakteristik generalisasi dari besar kecilnya variasi suatu sifat dalam agregat. Ini sama dengan akar kuadrat dari rata-rata deviasi kuadrat nilai individu atribut dari mean aritmatika, yaitu. Akar dan dapat ditemukan seperti ini:
1. Untuk baris utama:
2. Untuk rangkaian variasi:

Mengubah rumus deviasi standar membawanya ke bentuk yang lebih nyaman untuk perhitungan praktis:
Deviasi standar menentukan seberapa besar rata-rata pilihan tertentu menyimpang dari nilai rata-ratanya, dan juga merupakan ukuran absolut dari variabilitas suatu karakteristik dan dinyatakan dalam satuan yang sama dengan pilihan, dan oleh karena itu dapat ditafsirkan dengan baik.
Contoh mencari simpangan baku: ,
Untuk karakteristik alternatif, rumus deviasi standarnya terlihat seperti ini:
![]()
dimana p adalah proporsi unit dalam populasi yang mempunyai karakteristik tertentu;
q adalah proporsi unit yang tidak memiliki karakteristik ini.
Konsep deviasi linier rata-rata
Deviasi linier rata-rata didefinisikan sebagai mean aritmatika dari nilai absolut deviasi opsi individu dari .
1. Untuk baris utama:

2. Untuk rangkaian variasi:
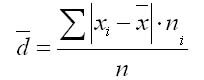
di mana jumlah n adalah jumlah frekuensi deret variasi.
Contoh mencari simpangan linier rata-rata:
Keuntungan dari deviasi absolut rata-rata sebagai ukuran dispersi pada rentang variasi sudah jelas, karena ukuran ini didasarkan pada memperhitungkan semua kemungkinan deviasi. Namun indikator ini memiliki kelemahan yang signifikan. Penolakan sewenang-wenang terhadap tanda-tanda penyimpangan aljabar dapat mengarah pada fakta bahwa sifat matematika dari indikator ini jauh dari dasar. Hal ini membuat sangat sulit untuk menggunakan deviasi absolut rata-rata ketika menyelesaikan masalah yang melibatkan perhitungan probabilistik.
Oleh karena itu, rata-rata deviasi linier sebagai ukuran variasi suatu karakteristik jarang digunakan dalam praktik statistik, yaitu ketika menjumlahkan indikator tanpa memperhitungkan tanda-tanda masuk akal secara ekonomi. Dengan bantuannya, misalnya, omset perdagangan luar negeri, komposisi pekerja, ritme produksi, dll dianalisis.
Berarti persegi
Rata-rata kuadrat diterapkan, misalnya untuk menghitung rata-rata ukuran sisi n bagian persegi, rata-rata diameter batang, pipa, dll. Dibagi menjadi dua jenis.
Persegi rata-rata sederhana. Jika, ketika mengganti nilai individual suatu karakteristik dengan nilai rata-rata, jumlah kuadrat dari nilai aslinya harus dijaga agar tidak berubah, maka rata-ratanya akan menjadi nilai rata-rata kuadrat.
Ini adalah akar kuadrat dari hasil bagi membagi jumlah kuadrat nilai atribut individu dengan nomornya:
Kuadrat rata-rata tertimbang dihitung menggunakan rumus:

dimana f adalah tanda bobot.
Rata-rata kubik
Rata-rata kubik berlaku, misalnya saat menentukan rata-rata panjang suatu sisi dan kubus. Ini dibagi menjadi dua jenis.
Rata-rata kubik sederhana:


Saat menghitung nilai rata-rata dan dispersi dalam deret distribusi interval, nilai sebenarnya dari atribut tersebut digantikan oleh nilai pusat interval, yang berbeda dari rata-rata aritmatika dari nilai yang termasuk dalam interval. Hal ini menyebabkan kesalahan sistematis saat menghitung varians. V.F. Sheppard menentukan hal itu kesalahan dalam perhitungan varians, yang disebabkan oleh penggunaan data yang dikelompokkan, adalah 1/12 kuadrat dari nilai interval, baik dalam arah naik maupun dalam arah menurunnya besaran dispersi.
Amandemen Sheppard harus digunakan jika distribusinya mendekati normal, berkaitan dengan suatu karakteristik dengan sifat variasi yang kontinu, dan didasarkan pada sejumlah besar data awal (n > 500). Namun, berdasarkan kenyataan bahwa dalam beberapa kasus kedua kesalahan, yang bertindak dalam arah yang berbeda, saling mengimbangi, terkadang ada kemungkinan untuk menolak melakukan koreksi.
Semakin kecil varians dan deviasi standarnya, maka populasinya akan semakin homogen dan rata-ratanya akan semakin khas.
Dalam praktik statistika, seringkali terdapat kebutuhan untuk membandingkan variasi berbagai karakteristik. Misalnya, sangat menarik untuk membandingkan variasi usia pekerja dan kualifikasinya, masa kerja dan upah, biaya dan keuntungan, masa kerja dan produktivitas tenaga kerja, dan lain-lain. Untuk perbandingan seperti itu, indikator variabilitas karakteristik absolut tidak cocok: tidak mungkin membandingkan variabilitas pengalaman kerja, yang dinyatakan dalam tahun, dengan variasi upah, yang dinyatakan dalam rubel.
Untuk melakukan perbandingan tersebut, serta perbandingan variabilitas karakteristik yang sama pada beberapa populasi dengan rata-rata aritmatika yang berbeda, digunakan indikator variasi relatif - koefisien variasi.
Rata-rata struktural
Untuk mengkarakterisasi tendensi sentral dalam distribusi statistik, seringkali rasional untuk menggunakan, bersama dengan mean aritmatika, nilai tertentu dari karakteristik X, yang, karena ciri-ciri tertentu dari lokasinya dalam deret distribusi, dapat mencirikan levelnya.
Hal ini sangat penting ketika dalam suatu rangkaian distribusi nilai ekstrim suatu karakteristik mempunyai batas yang tidak jelas. Dalam hal ini, penentuan mean aritmatika yang akurat biasanya tidak mungkin atau sangat sulit. Dalam kasus seperti ini, level rata-rata dapat ditentukan dengan mengambil, misalnya, nilai fitur yang terletak di tengah rangkaian frekuensi atau yang paling sering muncul di rangkaian saat ini.
Nilai-nilai tersebut hanya bergantung pada sifat frekuensi, yaitu pada struktur distribusi. Mereka khas di lokasi dalam serangkaian frekuensi, oleh karena itu nilai-nilai tersebut dianggap sebagai karakteristik pusat distribusi dan oleh karena itu menerima definisi rata-rata struktural. Mereka digunakan untuk mempelajari struktur internal dan struktur rangkaian distribusi nilai atribut. Indikator tersebut meliputi:
Deviasi standar(sinonim: deviasi standar, deviasi standar, deviasi persegi; istilah terkait: deviasi standar, penyebaran standar) - dalam teori probabilitas dan statistik, indikator paling umum dari dispersi nilai variabel acak relatif terhadap ekspektasi matematisnya. Dengan susunan nilai sampel yang terbatas, alih-alih ekspektasi matematis, yang digunakan adalah rata-rata aritmatika dari kumpulan sampel.
YouTube ensiklopedis
-
1 / 5
Simpangan baku diukur dalam satuan pengukuran variabel acak itu sendiri dan digunakan saat menghitung kesalahan standar rata-rata aritmatika, saat membangun interval kepercayaan, saat menguji hipotesis secara statistik, saat mengukur hubungan linier antara variabel acak. Didefinisikan sebagai akar kuadrat dari varians suatu variabel acak.
Deviasi standar:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (xi − x ¯) 2 ;- Catatan: Seringkali terjadi perbedaan nama MSD (Root Mean Square Deviation) dan STD (Standard Deviation) dengan rumusnya. Misalnya, dalam modul numPy bahasa pemrograman Python, fungsi std() digambarkan sebagai “deviasi standar”, sedangkan rumusnya mencerminkan deviasi standar (pembagian dengan akar sampel). Di Excel, fungsi STANDARDEVAL() berbeda (dibagi dengan akar n-1).
Deviasi Standar(perkiraan simpangan baku suatu variabel acak X relatif terhadap ekspektasi matematisnya berdasarkan estimasi variansinya yang tidak bias) s (\gaya tampilan s):
σ = 1 n ∑ i = 1 n (xi − x ¯) 2 .(\displaystyle \sigma =(\sqrt ((\frac (1)(n))\sum _(i=1)^(n)\left(x_(i)-(\bar (x))\right) ^(2))).) Di manaσ 2 (\displaystyle \sigma ^(2)) - dispersi; - x saya (\gaya tampilan x_(i)) Saya unsur seleksi; n (\gaya tampilan n)
- ukuran sampel;- rata-rata aritmatika sampel:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) .
(\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ltitik +x_(n)).)
(\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ltitik +x_(n)).) (Perlu dicatat bahwa kedua perkiraan tersebut bias. Dalam kasus umum, tidak mungkin membuat estimasi yang tidak bias. Namun, estimasi yang didasarkan pada estimasi varians yang tidak bias adalah konsisten. Sesuai dengan Gost R 8.736-2011, standar deviasi dihitung menggunakan rumus kedua bagian ini. Silakan periksa hasilnya. Aturan tiga sigma 3 σ (\displaystyle 3\sigma ) ) - hampir semua nilai variabel acak yang terdistribusi normal terletak pada interval(x ¯ − 3 σ ; x ¯ + 3 σ) (\displaystyle \kiri((\bar (x))-3\sigma ;(\bar (x))+3\sigma \kanan))
. Lebih tepatnya - dengan probabilitas kira-kira 0,9973, nilai variabel acak yang terdistribusi normal terletak pada interval yang ditentukan (asalkan nilainya ) - hampir semua nilai variabel acak yang terdistribusi normal terletak pada interval x ¯ (\displaystyle (\bar (x))) benar, dan tidak diperoleh dari hasil pengolahan sampel). Jika nilai sebenarnya tidak diketahui, maka sebaiknya jangan digunakanσ (\displaystyle \sigma ) tidak diketahui, maka sebaiknya jangan digunakan .
, A
S
Misalnya, kita mempunyai tiga himpunan bilangan: (0, 0, 14, 14), (0, 6, 8, 14) dan (6, 6, 8, 8). Ketiga himpunan mempunyai nilai rata-rata sama dengan 7, dan simpangan baku masing-masing sama dengan 7, 5 dan 1. Himpunan terakhir mempunyai simpangan baku yang kecil, karena nilai-nilai dalam himpunan tersebut dikelompokkan di sekitar nilai rata-rata; himpunan pertama memiliki nilai deviasi standar terbesar - nilai dalam himpunan tersebut sangat berbeda dari nilai rata-rata.
Secara umum, deviasi standar dapat dianggap sebagai ukuran ketidakpastian. Misalnya, dalam fisika, simpangan baku digunakan untuk menentukan kesalahan serangkaian pengukuran besaran yang berurutan. Nilai ini sangat penting untuk menentukan masuk akalnya fenomena yang diteliti dibandingkan dengan nilai yang diprediksi oleh teori: jika nilai rata-rata pengukuran berbeda jauh dari nilai yang diprediksi oleh teori (deviasi standar besar), maka nilai yang diperoleh atau cara memperolehnya harus diperiksa kembali. diidentifikasi dengan risiko portofolio.
Iklim
Misalkan ada dua kota dengan rata-rata suhu maksimum harian yang sama, namun yang satu terletak di pesisir pantai dan yang lainnya di dataran. Diketahui bahwa kota-kota yang terletak di pesisir pantai memiliki berbagai suhu maksimum siang hari yang lebih rendah dibandingkan kota-kota yang terletak di pedalaman. Oleh karena itu, simpangan baku suhu harian maksimum untuk kota pesisir akan lebih kecil dibandingkan kota kedua, meskipun nilai rata-rata dari nilai tersebut adalah sama, yang dalam praktiknya berarti probabilitas suhu udara maksimum pada setiap hari dalam setahun akan berbeda lebih tinggi dari nilai rata-rata, lebih tinggi untuk kota yang terletak di pedalaman.
Olahraga
Mari kita asumsikan ada beberapa tim sepak bola yang dinilai berdasarkan serangkaian parameter, misalnya jumlah gol yang dicetak dan kebobolan, peluang mencetak gol, dll. Kemungkinan besar tim terbaik di grup ini akan memiliki nilai yang lebih baik. pada lebih banyak parameter. Semakin kecil deviasi standar tim untuk setiap parameter yang disajikan, semakin mudah diprediksi hasil tim tersebut; Sebaliknya, tim dengan standar deviasi yang besar sulit memprediksi hasilnya, yang pada gilirannya disebabkan oleh ketidakseimbangan, misalnya pertahanan yang kuat tetapi serangan yang lemah.
Penggunaan standar deviasi parameter tim memungkinkan, pada tingkat tertentu, untuk memprediksi hasil pertandingan antara dua tim, menilai kekuatan dan kelemahan tim, dan oleh karena itu metode pertarungan yang dipilih.
Dalam pengujian statistik hipotesis, ketika mengukur hubungan linier antara variabel acak.
Deviasi standar:
Deviasi Standar(perkiraan simpangan baku dari variabel acak Lantai, dinding di sekitar kita dan langit-langit, X relatif terhadap ekspektasi matematisnya berdasarkan estimasi varians yang tidak bias):
dimana sebarannya; - Lantai, dinding di sekitar kita dan langit-langit, x saya (\gaya tampilan x_(i)) unsur seleksi; - ukuran sampel; - rata-rata aritmatika sampel:
Perlu dicatat bahwa kedua perkiraan tersebut bias. Dalam kasus umum, tidak mungkin membuat estimasi yang tidak bias. Namun, estimasi yang didasarkan pada estimasi varians yang tidak bias adalah konsisten.
(\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ltitik +x_(n)).)
(\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\ltitik +x_(n)).)() - hampir semua nilai variabel acak yang terdistribusi normal terletak pada interval. Lebih tepatnya - dengan keyakinan tidak kurang dari 99,7%, nilai variabel acak yang terdistribusi normal terletak pada interval yang ditentukan (asalkan nilainya benar dan tidak diperoleh dari pemrosesan sampel).
Jika nilai sebenarnya tidak diketahui, maka kita seharusnya tidak menggunakan, tapi Lantai, dinding di sekitar kita dan langit-langit, tidak diketahui, maka sebaiknya jangan digunakan. Dengan demikian, aturan tiga sigma diubah menjadi aturan tiga Lantai, dinding di sekitar kita dan langit-langit, tidak diketahui, maka sebaiknya jangan digunakan .
, A
Nilai simpangan baku yang besar menunjukkan besarnya penyebaran nilai dalam himpunan yang disajikan dengan nilai rata-rata himpunan tersebut; Oleh karena itu, nilai yang kecil menunjukkan bahwa nilai-nilai dalam himpunan dikelompokkan di sekitar nilai tengah.
Misalnya, kita mempunyai tiga himpunan bilangan: (0, 0, 14, 14), (0, 6, 8, 14) dan (6, 6, 8, 8). Ketiga himpunan mempunyai nilai rata-rata sama dengan 7, dan simpangan baku masing-masing sama dengan 7, 5 dan 1. Himpunan terakhir mempunyai simpangan baku yang kecil, karena nilai-nilai dalam himpunan tersebut dikelompokkan di sekitar nilai rata-rata; himpunan pertama memiliki nilai deviasi standar terbesar - nilai dalam himpunan tersebut sangat berbeda dari nilai rata-rata.
Secara umum, deviasi standar dapat dianggap sebagai ukuran ketidakpastian. Misalnya, dalam fisika, deviasi standar digunakan untuk menentukan kesalahan serangkaian pengukuran besaran yang berurutan. Nilai ini sangat penting untuk menentukan masuk akalnya fenomena yang diteliti dibandingkan dengan nilai yang diprediksi oleh teori: jika nilai rata-rata pengukuran berbeda jauh dari nilai yang diprediksi oleh teori (deviasi standar besar), maka nilai yang diperoleh atau cara memperolehnya harus diperiksa kembali.
Penerapan Praktis
Dalam praktiknya, deviasi standar memungkinkan Anda menentukan seberapa besar perbedaan nilai dalam suatu himpunan dari nilai rata-rata.
Iklim
Misalkan ada dua kota dengan rata-rata suhu maksimum harian yang sama, namun satu kota terletak di pesisir pantai dan kota lainnya berada di pedalaman. Diketahui bahwa kota-kota yang terletak di pesisir pantai memiliki berbagai suhu maksimum siang hari yang lebih rendah dibandingkan kota-kota yang terletak di pedalaman. Oleh karena itu, simpangan baku suhu harian maksimum untuk kota pesisir akan lebih kecil dibandingkan kota kedua, meskipun nilai rata-rata dari nilai tersebut adalah sama, yang dalam praktiknya berarti probabilitas suhu udara maksimum pada setiap hari dalam setahun akan berbeda lebih tinggi dari nilai rata-rata, lebih tinggi untuk kota yang terletak di pedalaman.
Olahraga
Mari kita asumsikan ada beberapa tim sepak bola yang dinilai berdasarkan serangkaian parameter, misalnya jumlah gol yang dicetak dan kebobolan, peluang mencetak gol, dll. Kemungkinan besar tim terbaik di grup ini akan memiliki nilai yang lebih baik. pada lebih banyak parameter. Semakin kecil deviasi standar tim untuk setiap parameter yang disajikan, semakin mudah diprediksi hasil tim tersebut; Sebaliknya, tim dengan standar deviasi yang besar sulit memprediksi hasilnya, yang pada gilirannya disebabkan oleh ketidakseimbangan, misalnya pertahanan yang kuat tetapi serangan yang lemah.
Penggunaan standar deviasi parameter tim memungkinkan, pada tingkat tertentu, untuk memprediksi hasil pertandingan antara dua tim, menilai kekuatan dan kelemahan tim, dan oleh karena itu metode pertarungan yang dipilih.
Analisis teknis
Lihat juga
Literatur
Artikel ini diusulkan untuk dihapus. Penjelasan alasan dan pembahasan terkait dapat dilihat di halaman Wikipedia: Akan dihapus/17 Desember 2012.
Meskipun proses diskusi belum selesai, Anda dapat mencoba memperbaiki artikel, namun sebaiknya jangan mengganti nama atau menghapus konten, lihat panduan tindakan lebih lanjut untuk lebih jelasnya.
Jangan menghilangkan tanda penghapusan sampai diskusi berakhir. Administrator: tautan di sini, riwayat (terakhir diubah), log, hapus.* Borovikov, V. STATISTIK. Seni analisis data di komputer: Untuk profesional / V. Borovikov. - Sankt Peterburg. : Petrus, 2003. - 688 hal. - ISBN 5-272-00078-1.
Indikator statistik Deskriptif
statistikKontinu
dataFaktor geser Rentang Mode Median Rata-rata (Aritmatika, Geometris, Harmonik). Variasi Peringkat · Deviasi standar· Koefisien variasi · Kuantil (Desil, Persentil/Persentil/Sentil) Momen Ekspektasi · Varians · Skewness · Kurtosis Diskrit
dataFrekuensi · Tabel kontingensi Statistik
keluaran dan
penyelidikan
hipotesisStatistik
kesimpulanInterval Keyakinan (Probabilitas Frekuenist) Interval Kredibilitas (Inferensi Bayesian) Analisis Meta Signifikansi Statistik Perencanaan
percobaanPopulasi · Desain pengambilan sampel · Pengambilan sampel area · Replikasi · Pengelompokan · Sensitivitas dan spesifisitas Ukuran sampel Kekuatan statistik · Ukuran efek · Kesalahan standar Peringkat keseluruhan Estimasi solusi Bayesian ·







