Précédemment, nous avons discuté d'un nuage de points illustrant la distribution de données numériques bivariées (voir dernière section Représentation de données numériques bidimensionnelles remarques). Dans cette note, nous étudierons deux indicateurs quantitatifs qui caractérisent la force de la relation entre deux variables : la covariance et le coefficient de corrélation. La covariance évalue la force de la relation linéaire entre deux variables numériques X et Y. Exemple de covariance :
Téléchargez la note au format ou, exemples au format
Considérez le ratio de rendement et de dépenses annuel moyen sur cinq ans des fonds à très faible risque (Figure 1). Pour calculer la covariance de deux échantillons dans Excel jusqu'en 2007, la fonction =COVAR() est utilisée à partir de la version 2010, la fonction COVARICT.V() est utilisée ;

Riz. 1. Rendement annuel moyen sur cinq ans et ratio de coût des fonds communs de placement à très faible risque
Il est intéressant de noter que la covariance d'une variable aléatoire avec elle-même est égale à sa variance :

Si la covariance est positive, alors à mesure que les valeurs d'une variable aléatoire augmentent, les valeurs de la seconde ont tendance à augmenter, et si le signe est négatif, elles diminuent. Cependant, ce n'est que par la valeur absolue de la covariance qu'il est impossible de juger dans quelle mesure les valeurs sont interdépendantes, car son échelle dépend de leurs variances. L'échelle peut être normalisée en divisant la valeur de covariance par le produit des écarts types (les racines carrées des variances). Cela produit ce que l'on appelle le coefficient de corrélation de Pearson.
La force relative de la relation, ou relation, entre deux variables formant un échantillon bivarié est mesurée par le coefficient de corrélation, allant de -1 pour une relation inverse parfaite à +1 pour une relation directe parfaite. Le coefficient de corrélation est désigné par la lettre grecque ρ . La linéarité de la corrélation signifie que tous les points représentés sur le nuage de points se trouvent sur une ligne droite (Figure 2). Le panneau A montre la relation linéaire inverse entre les variables X et Y. Ainsi, le coefficient de corrélation ρ est égal à –1, c'est-à-dire que lorsque la variable X augmente, la variable Y diminue. Le panneau B montre une situation dans laquelle il n'y a pas de corrélation entre les variables X et Y. Dans ce cas, le coefficient de corrélation ρ vaut 0, et lorsque la variable X augmente, la variable Y ne montre aucune tendance spécifique : elle ne diminue ni n'augmente. Le panneau B montre une relation directe linéaire entre les variables X et Y. Ainsi, le coefficient de corrélation ρ est +1, et lorsque la variable X augmente, la variable Y augmente également.

Riz. 2. Trois types de dépendance entre deux variables
Lors de l'analyse d'échantillons contenant des données bivariées, le coefficient de corrélation de l'échantillon est calculé, désigné par la lettre r. Dans les situations réelles, le coefficient de corrélation prend rarement les valeurs exactes -1, 0 et +1. Sur la fig. 3 montre six nuages de points et les coefficients de corrélation correspondants r entre 100 valeurs des variables X et Y.

Riz. 3. Six nuages de points et coefficients de corrélation correspondants obtenus à l'aide d'Excel
Le panneau A montre une situation dans laquelle le coefficient de corrélation de l'échantillon régal à -0,9. Il existe une tendance claire : les petites valeurs de la variable X correspondent à de très grandes valeurs de la variable Y et, à l'inverse, les grandes valeurs de la variable X correspondent aux petites valeurs de la variable Y. Cependant, les données ne ne se trouvent pas sur la même ligne droite, la relation entre eux ne peut donc pas être qualifiée de linéaire. Le panneau B montre les données avec un coefficient de corrélation d’échantillon de –0,6. Les petites valeurs de la variable X correspondent aux grandes valeurs de la variable Y. Notez que la relation entre les variables X et Y n'est pas linéaire, comme dans le panneau A, et que la corrélation entre elles n'est plus aussi élevée. Le coefficient de corrélation entre les variables X et Y présenté dans le panneau B est de –0,3. Il existe une faible tendance selon laquelle les grandes valeurs de la variable X correspondent généralement aux petites valeurs de la variable Y. Les panneaux D – E illustrent une corrélation positive entre les données - les petites valeurs de la variable X correspondent à. grandes valeurs de la variable Y.
En discutant de la Fig. 3, nous avons utilisé le terme tendance car il n’y a pas de relation de cause à effet entre les variables X et Y. La présence d'une corrélation ne signifie pas la présence de relations de cause à effet entre les variables X et Y, c'est-à-dire changer la valeur d’une variable ne change pas nécessairement la valeur de l’autre. Une forte corrélation peut être due au hasard et expliquée par une troisième variable exclue de l’analyse. Dans de telles situations, des recherches supplémentaires sont nécessaires. Ainsi, on peut affirmer que les relations de cause à effet produisent une corrélation, mais la corrélation ne signifie pas l’existence de relations de cause à effet.
Exemple de coefficient de corrélation :

Dans Excel, la fonction =CORREL() est utilisée pour calculer le coefficient de corrélation (Fig. 4).

Riz. 4. Fonction CORREL dans Excel
Ainsi, le coefficient de corrélation indique une relation linéaire, ou relation, entre deux variables. Plus le coefficient de corrélation est proche de –1 ou +1, plus la relation linéaire entre les deux variables est forte. Le signe du coefficient de corrélation détermine la nature de la dépendance : directe (+) et inverse (–). Une forte corrélation n’est pas une relation de cause à effet. Cela indique uniquement la présence d'une tendance caractéristique de cet échantillon.
Des documents du livre Levin et al. Statistics for Managers sont utilisés. – M. : Williams, 2004. – p. 221-227
Calculons le coefficient de corrélation et la covariance pour différents types de relations entre variables aléatoires.
Coefficient de corrélation(critère de corrélation Pearson, anglais Coefficient de corrélation du moment du produit Pearson) détermine le degré linéaire relations entre variables aléatoires.
Comme il ressort de la définition, pour calculer coefficient de corrélation il est nécessaire de connaître la distribution des variables aléatoires X et Y. Si les distributions sont inconnues, alors pour estimer coefficient de corrélation utilisé coefficient de corrélation de l'échantillonr ( il est également désigné comme Rxy ou r xy) :

où S x – écart typeéchantillon d'une variable aléatoire x, calculé par la formule :

Comme le montre la formule de calcul corrélations, le dénominateur (le produit des écarts types) normalise simplement le numérateur tel que corrélation s'avère être un nombre sans dimension de -1 à 1. Corrélation Et covariance fournir les mêmes informations (si elles sont connues écarts types), Mais corrélation plus pratique à utiliser, car c'est une quantité sans dimension.
Calculer coefficient de corrélation Et covariance de l'échantillon dans MS EXCEL, ce n'est pas difficile, car il existe des fonctions spéciales CORREL() et KOVAR() à cet effet. Il est beaucoup plus difficile de comprendre comment interpréter les valeurs obtenues ; la majeure partie de l'article y est consacrée.
Retraite théorique
Rappelons que connexion de corrélation appeler une relation statistique consistant dans le fait que différentes valeurs d'une variable correspondent à différentes moyenne les valeurs sont différentes (avec un changement de la valeur de X valeur moyenne Y change de façon régulière). On suppose que les deux les variables X et Y sont aléatoire valeurs et avoir une certaine dispersion aléatoire par rapport à elles valeur moyenne.
Note. Si une seule variable, par exemple Y, a un caractère aléatoire et que les valeurs de l'autre sont déterministes (fixées par le chercheur), alors on ne peut parler que de régression.
Ainsi, par exemple, lorsqu'on étudie la dépendance de la température annuelle moyenne, on ne peut pas parler de corrélations température et année d'observation et, en conséquence, appliquer des indicateurs corrélations avec leur interprétation correspondante.
Corrélation entre variables peut survenir de plusieurs manières :
- La présence d'une relation causale entre les variables. Par exemple, le montant des investissements dans la recherche scientifique (variable X) et le nombre de brevets reçus (Y). La première variable apparaît comme variable indépendante (facteur), deuxième - variable dépendante (résultat). Il faut se rappeler que la dépendance des quantités détermine la présence d'une corrélation entre elles, mais pas l'inverse.
- La présence de conjugaison (cause commune). Par exemple, à mesure que l'organisation se développe, le fonds salarial (masse salariale) et le coût de location des locaux augmentent. Il est évidemment faux de supposer que la location des locaux dépend de la masse salariale. Ces deux variables dépendent dans de nombreux cas de manière linéaire du nombre d’employés.
- Influence mutuelle des variables (quand l'une change, la deuxième variable change, et vice versa). Avec cette approche, deux formulations du problème sont autorisées ; Toute variable peut agir à la fois comme variable indépendante et comme variable dépendante.
Ainsi, indicateur de corrélation montre à quel point relation linéaire entre deux facteurs (s'il y en a un), et la régression vous permet de prédire un facteur en fonction de l'autre.
Corrélation, comme tout autre indicateur statistique, peut être utile lorsqu’il est utilisé correctement, mais son utilisation présente également des limites. S'il montre une relation linéaire clairement définie ou une absence totale de relation, alors corrélation reflétera cela à merveille. Mais, si les données montrent une relation non linéaire (par exemple quadratique), la présence de groupes de valeurs distincts ou de valeurs aberrantes, alors la valeur calculée coefficient de corrélation peut être trompeur (voir fichier exemple).
Corrélation proche de 1 ou -1 (c'est-à-dire proche en valeur absolue de 1) montre une forte relation linéaire entre les variables, une valeur proche de 0 ne montre aucune relation. Positif corrélation signifie qu'avec une augmentation d'un indicateur, l'autre augmente en moyenne, et avec un indicateur négatif, il diminue.
Pour calculer le coefficient de corrélation, il faut que les variables comparées satisfassent aux conditions suivantes :
- le nombre de variables doit être égal à deux ;
- les variables doivent être quantitatives (par exemple fréquence, poids, prix). La moyenne calculée de ces variables a une signification claire : prix moyen ou poids moyen du patient. Contrairement aux variables quantitatives, les variables qualitatives (nominales) prennent des valeurs uniquement à partir d'un ensemble fini de catégories (par exemple, le sexe ou le groupe sanguin). Ces valeurs sont classiquement associées à des valeurs numériques (par exemple, le sexe féminin est 1 et le sexe masculin est 2). Il est clair que dans ce cas le calcul valeur moyenne, qui est nécessaire pour trouver corrélations, est incorrect, et donc le calcul lui-même est incorrect corrélations;
- les variables doivent être des variables aléatoires et avoir .
Les données bidimensionnelles peuvent avoir des structures différentes. Certains d’entre eux nécessitent certaines approches pour travailler :
- Pour les données avec une relation non linéaire corrélation doit être utilisé avec prudence. Pour certains problèmes, il peut être utile de transformer une ou les deux variables pour produire une relation linéaire (cela nécessite de faire une hypothèse sur le type de relation non linéaire afin de suggérer le type de transformation nécessaire).
- En utilisant nuages de points Certaines données peuvent présenter des variations inégales (dispersion). Le problème des variations inégales est que les emplacements présentant des variations élevées fournissent non seulement les informations les moins précises, mais ont également le plus grand impact lors du calcul des statistiques. Ce problème est également souvent résolu en transformant les données, par exemple en utilisant des logarithmes.
- On peut observer que certaines données sont divisées en groupes (clustering), ce qui peut indiquer la nécessité de diviser la population en parties.
- Une valeur aberrante (une valeur fortement déviante) peut fausser la valeur calculée du coefficient de corrélation. Une valeur aberrante peut être due au hasard, à une erreur dans la collecte des données ou peut en réalité refléter une caractéristique de la relation. Étant donné que la valeur aberrante s'écarte considérablement de la valeur moyenne, elle contribue largement au calcul de l'indicateur. Les indicateurs statistiques sont souvent calculés avec et sans prise en compte des valeurs aberrantes.
Utiliser MS EXCEL pour calculer la corrélation
Prenons 2 variables comme exemple X Et Oui et, en conséquence, échantillon composé de plusieurs paires de valeurs (X i ; Y i). Pour plus de clarté, construisons .

Note: Pour plus d'informations sur la création de diagrammes, consultez l'article. Dans le fichier d'exemple pour la construction nuages de points utilisé parce que Ici, nous nous sommes écartés de l'exigence selon laquelle la variable X soit aléatoire (cela simplifie la génération de différents types de relations : construction de tendances et d'un spread donné). Pour les données réelles, vous devez utiliser un diagramme à nuages de points (voir ci-dessous).
Calculs corrélations Traçons les relations entre les variables pour différents cas : linéaire, quadratique et à manque de communication.
Note: Dans le fichier d'exemple, vous pouvez définir les paramètres de la tendance linéaire (pente, ordonnée à l'origine) et le degré de dispersion par rapport à cette ligne de tendance. Vous pouvez également ajuster les paramètres quadratiques.
Dans le fichier d'exemple pour la construction nuages de points s'il n'y a pas de dépendance des variables, un diagramme de dispersion est utilisé. Dans ce cas, les points du diagramme sont disposés sous la forme d’un nuage.

Note: Veuillez noter qu'en modifiant l'échelle du diagramme le long de l'axe vertical ou horizontal, le nuage de points peut prendre l'apparence d'une ligne verticale ou horizontale. Il est clair que les variables resteront indépendantes.
Comme mentionné ci-dessus, pour calculer coefficient de corrélation dans MS EXCEL, il existe une fonction CORREL(). Vous pouvez également utiliser la fonction similaire PEARSON(), qui renvoie le même résultat.
Pour être sûr que les calculs corrélations sont produits par la fonction CORREL() en utilisant les formules ci-dessus ; le fichier d'exemple montre le calcul ; corrélations en utilisant des formules plus détaillées :
=COVARIANCE.G(B28:B88;D28:D88)/STDEV.G(B28:B88)/STDEV.G(D28:D88)
=COVARIANCE.B(B28:B88;D28:D88)/STDEV.B(B28:B88)/STDEV.B(D28:D88)
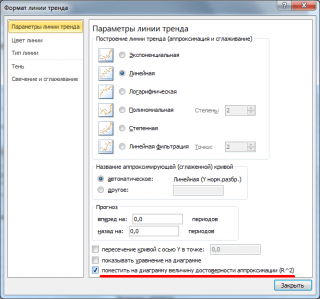
Note: Carré coefficient de corrélation r est égal à coefficient de détermination R2, qui est calculé lors de la construction d'une droite de régression à l'aide de la fonction QPIRSON(). La valeur de R2 peut également être sortie vers diagramme de dispersion en créant une tendance linéaire à l'aide de la fonctionnalité standard MS EXCEL (sélectionnez le graphique, sélectionnez l'onglet Mise en page, puis dans le groupe Analyse cliquez sur le bouton Ligne de tendance et sélectionnez approximation linéaire). Pour plus d'informations sur la création d'une ligne de tendance, voir, par exemple, .
Utiliser MS EXCEL pour calculer la covariance
Covariance a un sens proche de (également une mesure de dispersion) à la différence qu'il est défini pour 2 variables, et dispersion- pour un. Par conséquent, cov(x;x)=VAR(x).

Pour calculer la covariance dans MS EXCEL (à partir de la version 2010), les fonctions COVARIATION.Г() et COVARIATION.В() sont utilisées. Dans le premier cas, la formule de calcul est similaire à celle ci-dessus (fin .G représente Population), dans la seconde, au lieu du multiplicateur 1/n, on utilise 1/(n-1), c'est-à-dire fin .DANS représente Échantillon.
Note: La fonction COVAR(), présente dans MS EXCEL dans les versions antérieures, est similaire à la fonction COVARIATION.G().
Note: Les fonctions CORREL() et COVAR() sont présentées dans la version anglaise comme CORREL et COVAR. Les fonctions COVARIANCE.G() et COVARIANCE.B() comme COVARIANCE.P et COVARIANCE.S.
Formules supplémentaires pour le calcul covariances:
=SOMMEPRODUIT(B28:B88-MOYENNE(B28:B88);(D28:D88-MOYENNE(D28:D88)))/COUNT(D28:D88)
=SOMMEPRODUIT(B28:B88-MOYENNE(B28:B88),(D28:D88))/COMPTE(D28:D88)
=SOMME PRODUIT(B28:B88;D28:D88)/COMTE(D28:D88)-MOYENNE(B28:B88)*MOYENNE(D28:D88)
Ces formules utilisent la propriété covariances:
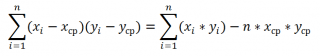
Si les variables x Et oui indépendantes, alors leur covariance est 0. Si les variables ne sont pas indépendantes, alors la variance de leur somme est égale à :
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
UN dispersion leur différence est égale
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Estimation de la signification statistique du coefficient de corrélation
Afin de tester l'hypothèse, nous devons connaître la distribution de la variable aléatoire, c'est-à-dire coefficient de corrélation r. Habituellement, l'hypothèse n'est pas testée pour r, mais pour la variable aléatoire t r :

qui a n-2 degrés de liberté.
Si la valeur calculée de la variable aléatoire |t r | est supérieure à la valeur critique t α,n-2 (α-spécifiée), alors l'hypothèse nulle est rejetée (la relation entre les valeurs est statistiquement significative).

Module complémentaire du package d'analyse
B pour calculer la covariance et la corrélation il y a des instruments du même nom analyse.

Après avoir appelé l'outil, une boîte de dialogue apparaît contenant les champs suivants :

- Intervalle de saisie: vous devez saisir un lien vers une plage avec des données sources pour 2 variables
- Regroupement: En règle générale, les données sources sont saisies dans 2 colonnes
- Libellés sur la première ligne: si la case est cochée, alors Intervalle de saisie doit contenir des en-têtes de colonnes. Il est recommandé de cocher la case pour que le résultat du Add-in contienne des colonnes informatives
- Intervalle de sortie: la plage de cellules où seront placés les résultats du calcul. Il suffit d'indiquer la cellule supérieure gauche de cette plage.
Le complément renvoie les valeurs calculées de corrélation et de covariance (pour la covariance, les variances des deux variables aléatoires sont également calculées).

Dans le cas d'une variable aléatoire multidimensionnelle (vecteur aléatoire), la caractéristique de la dispersion de ses composantes et des relations entre elles est la matrice de covariance.
Matrice de covariance est défini comme l'espérance mathématique du produit d'un vecteur aléatoire centré par le même vecteur transposé :
Où 
La matrice de covariance a la forme

où les variances des coordonnées vectorielles aléatoires sont situées le long de la diagonale o n =D Xi, o 22 =D X2, o kk = D Xk, et les éléments restants représentent les covariances entre les coordonnées
°12 = M"x i x 2 j a 1* = M-jc,** >
La matrice de covariance est une matrice symétrique, c'est-à-dire ![]()
Par exemple, considérons la matrice de covariance d'un vecteur bidimensionnel

La matrice de covariance est obtenue de la même manière pour tout vecteur de dimension /^.
Les dispersions de coordonnées peuvent être représentées comme
où est Gi,C2,...,0 ? - écarts types de coordonnées vectorielles aléatoires.
Comme on le sait, le coefficient de corrélation est le rapport de la covariance au produit des écarts types :

Après normalisation par le dernier rapport des termes de la matrice de covariance, la matrice de corrélation est obtenue

qui est symétrique et défini non négatif.
Un analogue multidimensionnel de la dispersion d'une variable aléatoire est la dispersion généralisée, qui est comprise comme la valeur du déterminant de la matrice de covariance
![]()
Une autre caractéristique générale du degré de dispersion d'une variable aléatoire multivariée est la trace de la matrice de covariance
où Скк sont les éléments diagonaux de la matrice de covariance.
Souvent, dans l'analyse statistique multivariée, la distribution normale est utilisée.
Une généralisation de la densité de probabilité normale au cas d'un vecteur aléatoire de dimension ^ est la fonction
où q = (pj, q 2 , M^) m - vecteur colonne des attentes mathématiques ;
|X| - déterminant de la matrice de covariance X ;
1 - matrice de covariance inverse.
Matrice X -1, inverse de la matrice X de dimension puh p, peut être obtenu de diverses manières. L'une d'elles est la méthode Jordan-Gauss. Dans ce cas, l'équation matricielle est compilée
Où X- vecteur colonne de variables dont le nombre est égal à i ; b- i est un vecteur colonne dimensionnel de côtés droits.
Multiplions l'équation (6.21) de gauche par la matrice inverse XG 1 :
![]()
Puisque le produit de la matrice inverse et de celle donnée donne la matrice identité E, Que
![]()
Si à la place b prendre le vecteur unitaire

alors le produit X -1 -ex donne la première colonne de la matrice inverse. Si l'on prend le deuxième vecteur unitaire

alors le produit E 1 e 2 donne la première colonne de la matrice inverse, etc. Ainsi, en résolvant séquentiellement les équations
![]()
en utilisant la méthode Jordan-Gauss, on obtient toutes les colonnes de la matrice inverse.
Une autre méthode pour obtenir la matrice inverse de la matrice E consiste à calculer des compléments algébriques Un tJ .= (/= 1, 2,..., p; j = 1, 2, ..., p) aux éléments d'une matrice E donnée, en les substituant à la place des éléments de la matrice E et en transportant une telle matrice :

La matrice inverse est obtenue après division des éléments DANS au déterminant de la matrice E :
Une caractéristique importante de l’obtention de la matrice inverse dans ce cas est que la matrice de covariance E est faiblement conditionnée. Cela conduit au fait que des erreurs assez graves peuvent survenir lors de l'inversion de telles matrices. Tout cela nécessite de garantir la précision nécessaire du processus de calcul ou l'utilisation de méthodes spéciales lors du calcul de telles matrices.
Exemple.Écrire une expression de densité de probabilité pour une variable aléatoire bidimensionnelle normalement distribuée (X contre X 2)
à condition que les espérances mathématiques, les variances et les covariances de ces quantités aient les valeurs suivantes :
Solution. La matrice de covariance inverse pour la matrice (6.19) peut être obtenue en utilisant l’expression inverse matricielle suivante pour la matrice X :

où A est le déterminant de la matrice X.
A et, L 12, A 21, A 22- des ajouts algébriques aux éléments correspondants de la matrice X.
Alors pour la matrice ]r- ! nous obtenons l'expression

Puisque a 12 = 01О2Р et °2i =a 2 a iP> et a i2 a 2i = cyfst|r, alors,

Trouvons le travail


La fonction de densité de probabilité s’écrira sous la forme

En remplaçant les données initiales, nous obtenons l'expression suivante pour la fonction de densité de probabilité

Cet article décrit la syntaxe de la formule et l'utilisation des fonctions COVARIANCE.G dans Microsoft Excel.
Renvoie la covariance de la population : la moyenne arithmétique des produits des variances pour chaque paire de points de données dans deux ensembles de données. La covariance est utilisée pour déterminer la relation entre deux ensembles de données. Par exemple, vous pouvez vérifier si un niveau de revenu plus élevé correspond à un niveau d’éducation plus élevé.
Syntaxe
COVARIANCE.G(tableau1,tableau2)
Les arguments de la fonction COVARIANCE.G sont décrits ci-dessous.
Tableau1- argument requis. La première plage de cellules contenant des entiers.
Tableau2- argument requis. La deuxième plage de cellules avec des entiers.
Remarques
Exemple
Copiez les exemples de données du tableau suivant et collez-les dans la cellule A1 d'une nouvelle feuille de calcul Excel. Pour afficher les résultats de la formule, sélectionnez-les et appuyez sur F2, puis sur Entrée. Si nécessaire, modifiez la largeur des colonnes pour voir toutes les données.
Mathématiquement covariance (Anglais Covariance) est une mesure de la dépendance linéaire de deux variables aléatoires. Dans la théorie du portefeuille, cet indicateur est utilisé pour déterminer la relation entre le rendement d'un titre particulier et le rendement d'un portefeuille de titres. Pour calculer la covariance des rendements, vous devez utiliser la formule suivante :
Où ok je– rentabilité du titre à la i-ème période ;
Rendement attendu (moyen) d'un titre ;
p je– rendement du portefeuille au cours de la ième période ;
Rendement attendu (moyen) du portefeuille ;
n– nombre d'observations.
Il est à noter que le dénominateur de la formule est substitué ( n-1) si la covariance est calculée sur la base d'un échantillon d'une population d'observations. Si la population entière est prise en compte dans les calculs, alors le dénominateur est remplacé n.
Exemple. Le tableau présente la dynamique de rentabilité des actions de la société A et de la société B, ainsi que la dynamique de rentabilité du portefeuille-titres.

Pour utiliser la formule ci-dessus pour calculer la covariance du rendement de chaque action avec le portefeuille, vous devez calculer le rendement moyen, qui sera :
- pour les actions de la société A 4,986% ;
- pour les actions de la société B 5,031% ;
- pour le portefeuille 3,201%.

Ainsi, la covariance des actions de la société A avec le portefeuille sera de -0,313, et celle des actions de la société B sera de 0,242.
Cov(kA,kp) = ((5,93-4,986)(2,27-3,201) + (5,85-4,986)(2,39-3,201) + (5,21-4,986)(3,47-3,201) + (5,37-4,986)(3,21-3,201) + (4,99-4,986)(2,95-3,201) + (4,87-4,986)(2,97-3,201) + (4,70-4,986)(3,32-3,201) + (4,75-4,986)(3,65-3,201) + (4,33-4,986)(3,97-3,201) + (3,86-4,986)(3,81-3,201))/(10-1) = -0,313
Cov (kB, kp) = ((4,25-5,031)(2,27-3,201) + (4,47-5,031)(2,39-3,201) + (4,68-5,031)(3,47-3,201) + (4,71-5,031)(3,21-3,201) + (4,77-5,031)(2,95-3,201) + (5,25-5,031)(2,97-3,201) + (5,45-5,031)(3,32-3,201) + (5,33-5,031)(3,65-3,201) + (5,55-5,031)(3,97-3,201) + (5,85-5,031)(3,81-3,201))/(10-1) = 0,242
Des calculs similaires peuvent être effectués dans Microsoft Excel en utilisant la fonction « COVARIANCE.B » pour un échantillon d'une population ou la fonction « COVARIATION.G » pour l'ensemble de la population.
Interprétation de la covariance
La valeur du coefficient de covariance peut être négative ou positive. Sa valeur négative indique que le rendement du titre et celui du portefeuille évoluent dans des directions différentes. Autrement dit, si le rendement du titre augmente, le rendement du portefeuille baissera, et vice versa. Une valeur positive indique que les rendements du titre et du portefeuille évoluent dans la même direction.
Une valeur faible (proche de 0) du coefficient de covariance est observée lorsque les fluctuations du rendement du titre et du rendement du portefeuille sont de nature aléatoire.







