La solution est rédigée au format Word.:
Règles de saisie des fonctionsPar exemple, x 1 2 +x 1 x 2, écrivez x1^2+x1*x2 Génère des directions de recherche, dans dans une plus grande mesure
correspondant à la géométrie de la fonction minimisée. Définition . Deux vecteurs à n dimensions x et y sont appelés conjugué par rapport à la matrice A (ou A-conjugué), si produit scalaire
(x, Aу) = 0 . Ici A est une matrice définie positive symétrique de taille n x n.
Schéma de l'algorithme de la méthode du gradient conjuguéDéfinir k = 0.
Ш. 1 Soit x 0 le point de départ ; ,
d 0 =-g 0 ; k=0.
 .
.Sh. 2 Déterminer x k +1 =x k +λ k d k, où
 ,
,Alors d k+1 =-g k+1 +β k d k ,
β k est trouvé à partir de la condition d k +1 Ad k =0 (conjugué par rapport à la matrice A).
Sh. 3 Mettez k = k + 1 → Sh 2.
Le critère d'arrêt d'une recherche unidimensionnelle selon chaque direction d k s'écrit :
sont choisis de telle manière que la direction d k soit A-conjuguée à toutes les directions précédemment construites.
Méthode Fletcher-Reeves Stratégie de la méthode Fletcher-Reeves< f(x k), k=0, 1, 2, ...consiste à construire une suite de points (x k ), k=0, 1, 2, ... telle que f(x k +1)
Les points de la séquence (x k) sont calculés selon la règle :
x k +1 =x k -t k ré k , k = 0, 1, 2,…

ré k = ▽f(x k) + b k -1 ▽f(x k -1)
La taille du pas est sélectionnée à partir de la condition du minimum de la fonction f(x) sur t dans la direction du mouvement, c'est-à-dire à la suite de la résolution du problème de minimisation unidimensionnelle :
f(x k -t k ré k) → min (t k >0) Au cas où f(x)= (x, Hx) + (b, x) + et les directions d k, d k -1 seront H-conjuguées, c'est-à-dire (d k , Hd k -1)=0
De plus, aux points de la séquence (x k) gradients de fonction f(x) sont mutuellement perpendiculaires, c'est-à-dire (▽f(x k +1),▽f(x k))=0, k =0, 1, 2…
Lors de la minimisation de fonctions non quadratiques, la méthode de Fletcher-Reeves n'est pas finie. Pour les fonctions non quadratiques, la modification suivante de la méthode de Fletcher-Reeves (méthode de Polak-Ribière) est utilisée, lorsque la valeur b k -1 est calculée comme suit :

Ici I est un ensemble d'indices : I = (0, n, 2n, 3n, ...), c'est à dire que la méthode Polak-Ribière implique l'utilisation de l'itération la plus rapide descente de pente toutes les n étapes, en remplaçant x 0 par x n +1.
La construction de la séquence(x k) se termine au point pour lequel |▽f(x k)|<ε.
La signification géométrique de la méthode du gradient conjugué est la suivante. D'une donnée point de départ La descente x 0 s'effectue dans la direction d 0 = ▽f(x 0). Au point x 1 le vecteur gradient ▽f(x 1) est déterminé Puisque x 1 est le point minimum de la fonction dans la direction d. 0, alors ▽f(x 1) orthogonal au vecteur d 0 . Ensuite, le vecteur d 1 est trouvé, H-conjugué à d 0 . Ensuite, le minimum de la fonction se trouve selon la direction d 1, etc.

Algorithme de la méthode Fletcher-Reeves
Étape initiale.Définir x 0 , ε > 0.
Trouver le gradient d'une fonction dans point arbitraire

k=0.
Scène principale
Étape 1. Calculer ▽f(x k)
Étape 2. Vérifier le respect du critère d'arrêt |▽f(x k)|< ε
a) si le critère est rempli, le calcul est terminé, x * = x k
b) si le critère n'est pas rempli, alors passer à l'étape 3 si k=0, sinon passer à l'étape 4.
Étape 3. Déterminer d 0 = ▽f(x 0)
Étape 4. Déterminer ou dans le cas d'une fonction non quadratique

Étape 5. Déterminer d k = ▽f(x k) + b k -1 ▽f(x k -1)
Étape 6. Calculez la taille du pas t k à partir de la condition f(x k - t k d k) → min (t k >0)
Étape 7. Calculer x k+1 =x k -t k d k
Étape 8. Définissez k= k +1 et passez à l'étape 1.
Convergence de la méthode
Théorème 1. Si la fonction quadratique f(x) = (x, Hx) + (b, x) + a avec une matrice définie non négative H atteint son valeur minimale sur R n, alors la méthode Fletcher-Reeves garantit que le point minimum est trouvé en pas plus de n étapes.Théorème 2. Soit la fonction f(x) dérivable et bornée par le bas sur R m, et son pente satisfait la condition de Lipschitz. Alors, pour un point de départ arbitraire, pour la méthode Polac-Ribière on a
Le théorème 2 garantit la convergence de la suite (x k ) vers point fixe x * , où ▽f(x *)=0. Par conséquent, le point trouvé x * a besoin recherche supplémentaire pour son classement. La méthode Polak-Ribière garantit la convergence de la suite (x k ) vers le point minimum uniquement pour les fonctions hautement convexes.
L'estimation du taux de convergence a été obtenue uniquement pour fonctions fortement convexes, dans ce cas la suite (x k) converge vers le point minimum de la fonction f(x) avec la vitesse : |x k+n – x*| ≤ C|x k – x*|, k = (0, n, 2, …)
Exemple. Trouvez le minimum de la fonction en utilisant la méthode du gradient conjugué : f(X) = 2x 1 2 +2x 2 2 +2x 1 x 2 +20x 1 +10x 2 +10.
Solution. Comme direction de recherche, sélectionnez le vecteur dégradé au point actuel :
|
La méthode de Newton et les méthodes quasi-Newton évoquées dans le paragraphe précédent sont très efficaces pour résoudre des problèmes de minimisation sans contrainte. Cependant, ils présentent assez exigences élevéesà la quantité de mémoire informatique utilisée. Cela est dû au fait que choisir une direction de recherche nécessite de résoudre des systèmes équations linéaires, ainsi qu'avec le besoin émergent de stocker des matrices du type Par conséquent, pour les plus grandes, l'utilisation de ces méthodes peut être impossible. Dans une large mesure, les méthodes à direction conjuguée sont exemptes de cet inconvénient.
1. Le concept de méthodes de direction conjuguée.
Considérons le problème de la minimisation de la fonction quadratique
![]()
avec une matrice définie positive symétrique A Rappelons que sa solution nécessite une étape de la méthode de Newton et pas plus de la méthode quasi-Newton. Les méthodes de direction conjuguée permettent également de trouver le point minimum de la fonction (10.33) en pas plus. que des étapes. Ceci peut être réalisé grâce à une sélection spéciale de directions de recherche.
Nous dirons que les vecteurs non nuls sont mutuellement conjugués (par rapport à la matrice A) si pour tout
Par méthode des directions conjuguées pour minimiser la fonction quadratique (10.33), nous entendons la méthode
dans lequel les directions sont mutuellement conjuguées, et les étapes

sont obtenus comme solution à des problèmes de minimisation unidimensionnels :
Théorème 10.4. La méthode des directions conjuguées vous permet de trouver le point minimum de la fonction quadratique (10 33) en quelques étapes seulement.
Les méthodes de directions conjuguées diffèrent les unes des autres dans la manière dont les directions conjuguées sont construites. La plus connue d’entre elles est la méthode du gradient conjugué.
2. Méthode du gradient conjugué.
Dans cette méthode, les directions construisent une règle
![]()
Puisque la première étape de cette méthode coïncide avec l’étape de la méthode de descente la plus raide. On peut montrer (nous ne le ferons pas) que les directions (10.34) sont bien
conjugué par rapport à la matrice A. De plus, les gradients s'avèrent orthogonaux entre eux.
Exemple 10.5. Utilisons la méthode du gradient conjugué pour minimiser la fonction quadratique - de l'exemple 10.1. Écrivons-le sous la forme où
![]()
Prenons la première approximation
La 1ère étape de la méthode coïncide avec la première étape de la méthode de descente la plus raide. Par conséquent (voir exemple 10.1)
2ème étape. Calculons

Puisque la solution s’est avérée avoir été trouvée en deux étapes.
3. Méthode du gradient conjugué pour minimiser les fonctions non quadratiques.
Pour que cette méthode puisse être appliquée afin de minimiser un arbitraire fonction fluide la formule (10.35) pour calculer le coefficient est convertie sous la forme
![]()
ou à la vue
![]()
L'avantage des formules (10 36), (10.37) est qu'elles ne contiennent pas explicitement la matrice A.
La fonction est minimisée par la méthode du gradient conjugué conformément aux formules

Les coefficients sont calculés à l'aide de l'une des formules (10.36), (10.37).
Le processus itératif ici ne se termine plus après nombre finiétapes, et les directions ne sont pas, en général, conjuguées par rapport à une matrice.
Les problèmes de minimisation unidimensionnels (10.40) doivent être résolus numériquement. Nous notons également que souvent dans la méthode du gradient conjugué, le coefficient n'est pas calculé à l'aide des formules (10.36), (10.37), mais est supposé égal à zéro. Dans ce cas, l’étape suivante s’effectue en réalité en utilisant la méthode de descente la plus raide. Cette « mise à jour » de la méthode permet de réduire l’influence des erreurs de calcul.
Pour une fonction lisse fortement convexe pour certains conditions supplémentaires La méthode du gradient conjugué a un taux de convergence superlinéaire élevé. Dans le même temps, son intensité de travail est faible et comparable à la complexité de la méthode de descente la plus raide. Comme le montre la pratique informatique, son efficacité est légèrement inférieure aux méthodes quasi-Newton, mais impose des exigences nettement inférieures à la mémoire informatique utilisée. Dans le cas où le problème de minimiser une fonction avec très un grand nombre variables, la méthode du gradient conjugué semble être la seule méthode universelle appropriée.
Des expériences informatiques visant à évaluer l'efficacité d'une version parallèle de la méthode de relaxation supérieure ont été réalisées dans les conditions spécifiées dans l'introduction. Afin de former une matrice définie positive symétrique, les éléments de la sous-matrice ont été générés dans la plage de 0 à 1, les valeurs des éléments de la sous-matrice ont été obtenues à partir de la symétrie des matrices et , et les éléments sur le Les diagonales principales (sous-matrice) ont été générées dans la plage de à , où correspond la taille de la matrice.
Comme critère d'arrêt, nous avons utilisé le critère d'arrêt pour la précision (7.51) avec le paramètre un paramètre d'itération . Dans toutes les expériences, la méthode a trouvé une solution avec la précision requise en 11 itérations. Comme pour les expériences précédentes, nous fixerons l'accélération par rapport à programme parallèle, exécuté dans un seul thread.
| Résultats expérimentaux (méthode de relaxation supérieure) | n | 1 flux | |||||||
| Algorithme parallèle | 2 flux | 4 flux | 6 flux | ||||||
| 8 flux | T | 8 flux | T | 8 flux | T | 8 flux | T | ||
| 2500 | 0,73 | 0,47 | 1,57 | 0,30 | 2,48 | 0,25 | 2,93 | 0,22 | 3,35 |
| 5000 | 3,25 | 2,11 | 1,54 | 1,22 | 2,67 | 0,98 | 3,30 | 0,80 | 4,08 |
| 7500 | 7,72 | 5,05 | 1,53 | 3,18 | 2,43 | 2,36 | 3,28 | 1,84 | 4,19 |
| 10000 | 14,60 | 9,77 | 1,50 | 5,94 | 2,46 | 4,52 | 3,23 | 3,56 | 4,10 |
| 12500 | 25,54 | 17,63 | 1,45 | 10,44 | 2,45 | 7,35 | 3,48 | 5,79 | 4,41 |
| 15000 | 38,64 | 26,36 | 1,47 | 15,32 | 2,52 | 10,84 | 3,56 | 8,50 | 4,54 |

S
Riz. 7h50.
Les expériences démontrent une bonne accélération (environ 4 sur 8 threads).
Méthode du gradient conjugué Considérons le système d’équations linéaires (7.49) avec une matrice symétrique définie positive de taille . base méthode du gradient conjugué est prochaine propriété
: résoudre le système d'équations linéaires (7.49) avec une matrice définie positive symétrique équivaut à résoudre le problème de minimisation de la fonction
Va à zéro. Ainsi, la solution du système (7.49) peut être recherchée comme une solution au problème de minimisation inconditionnelle (7.56).
Algorithme séquentiel
Afin de résoudre le problème de minimisation (7.56), le processus itératif suivant est organisé.
L'étape préparatoire () est déterminée par les formules

Étapes de base
) sont déterminés par les formules
![]()
Voici l'écart de la ième approximation, le coefficient est trouvé à partir de la condition de conjugaison
Itinéraire et ; est une solution au problème de la minimisation d'une fonction dans la direction L'analyse des formules de calcul de la méthode montre qu'elles comprennent deux opérations de multiplication d'une matrice par un vecteur, quatre opérations de produit scalaire et cinq opérations sur des vecteurs. Cependant, à chaque itération, il suffit de calculer une fois le produit puis d'utiliser le résultat stocké. Quantité totale
![]()
le nombre d'opérations effectuées en une itération est
| (7.58) |
Opérations. On peut montrer que pour trouver une solution exacte à un système d'équations linéaires avec une matrice symétrique définie positive, il n'est pas nécessaire d'effectuer plus de n itérations, donc la complexité de l'algorithme pour trouver une solution exacte est de l'ordre de . Cependant, en raison d'erreurs d'arrondi ce processus généralement considéré comme itératif, le processus se termine soit lorsque la condition d'arrêt habituelle (7.51) est satisfaite, soit lorsque la condition de petitesse de la norme relative du résidu est satisfaite
![]()
Organisation du calcul parallèle
Lors du développement d'une version parallèle de la méthode du gradient conjugué pour résoudre des systèmes d'équations linéaires, il convient tout d'abord de tenir compte du fait que les itérations de la méthode sont effectuées séquentiellement et que, par conséquent, l'approche la plus appropriée consiste à paralléliser les calculs. mis en œuvre au cours des itérations.
L'analyse de l'algorithme séquentiel montre que les principaux coûts à la ième itération consistent à multiplier la matrice par les vecteurs et . En conséquence, des méthodes bien connues peuvent être utilisées pour organiser des calculs parallèles multiplication parallèle matrices par vecteur.
Des calculs supplémentaires d'un ordre inférieur de complexité sont diverses opérations de traitement vectoriel (produit scalaire, addition et soustraction, multiplication par un scalaire). L'organisation de ces calculs doit bien entendu être cohérente avec le choix de manière parallèle effectuer l'opération de multiplication d'une matrice par un vecteur.
Pour une analyse plus approfondie de l'efficacité des calculs parallèles résultants, nous choisirons un algorithme parallèle de multiplication matrice-vecteur avec division horizontale en bandes de la matrice. Dans ce cas, les opérations sur les vecteurs, moins gourmandes en calculs, seront également effectuées en mode multi-thread.
Effort de calcul méthode séquentielle les gradients conjugués sont déterminés par la relation (7.58). Déterminons le temps d'exécution mise en œuvre parallèle méthode du gradient conjugué. La complexité de calcul de l'opération parallèle de multiplication d'une matrice par un vecteur lors de l'utilisation d'un schéma de partitionnement matriciel horizontal en bandes est
Où est la longueur du vecteur, le nombre de threads et la surcharge nécessaire à la création et à la fermeture d'une section parallèle.
Toutes les autres opérations sur les vecteurs (produit scalaire, addition, multiplication par une constante) peuvent être effectuées en mode monothread, car ne sont pas déterminants dans la complexité globale de la méthode. Par conséquent, la complexité de calcul globale de la version parallèle de la méthode du gradient conjugué peut être estimée comme suit :

Où est le nombre d'itérations de la méthode.
Résultats des expériences informatiques
Des expériences informatiques visant à évaluer l'efficacité d'une version parallèle de la méthode du gradient conjugué pour résoudre des systèmes d'équations linéaires avec une matrice définie positive symétrique ont été réalisées dans les conditions spécifiées dans l'introduction. Les éléments sur la diagonale principale de la matrice ) ont été générés dans la plage de à , où est la taille de la matrice, les éléments restants ont été générés symétriquement dans la plage de 0 à 1. Le critère d'arrêt pour la précision (7.51) avec le paramètre a été utilisé comme critère d'arrêt
Les résultats des expériences informatiques sont donnés dans le tableau 7.21 (le temps de fonctionnement des algorithmes est indiqué en secondes).
Méthode de descente la plus raide
Lorsque vous utilisez la méthode de descente la plus raide à chaque itération, la taille du pas UN k
est sélectionné à partir de la condition minimale de la fonction f(x) dans le sens de la descente, c'est-à-dire
f(x[k]-un k f"(x[k]))
= f(x[k] -af"(x[k]))
.
Cette condition signifie que le mouvement le long de l'antigradient se produit aussi longtemps que la valeur de la fonction f(x) diminue. AVEC point mathématique vue à chaque itération il faut résoudre le problème de minimisation unidimensionnelle selon UN fonctions
j (un) = f(x[k]-af"(x[k])) .
L'algorithme de la méthode de descente la plus raide est le suivant.
1. Définissez les coordonnées du point de départ X.
2. Au point X[k], k = 0, 1, 2, ... calcule la valeur du dégradé f"(x[k]) .
3. La taille du pas est déterminée un k , par minimisation unidimensionnelle sur UN fonctions j (un) = f(x[k]-af"(x[k])).
4. Les coordonnées du point sont déterminées X[k+ 1]:
X je [k+ 1]=x je [k]- UN k f" je (X[k]), je = 1,..., p.
5. Les conditions d'arrêt du processus de stération sont vérifiées. S'ils sont remplis, les calculs s'arrêtent. Sinon, passez à l'étape 1.
Dans la méthode considérée, la direction du mouvement à partir du point X[k] touche la ligne de niveau au point x[k+ 1] (Fig. 2.9). La trajectoire de descente est en zigzag, avec des liens en zigzag adjacents orthogonaux les uns aux autres. En effet, une étape un k est choisi en minimisant par UN fonctions q (un) = f(x[k] -af"(x[k])) . Condition préalable fonction minimale d j (a)/da = 0. Après avoir calculé la dérivée fonction complexe, on obtient la condition d'orthogonalité des vecteurs de directions de descente en points voisins :
d j (a)/da = -f"(x[k+ 1]f"(x[k]) = 0.
Les méthodes de gradient convergent vers un minimum avec grande vitesse(à vitesse progression géométrique) pour des fonctions convexes lisses. De telles fonctions ont le plus grand M et le moins m valeurs propres de la matrice des dérivées secondes (matrice de Hesse)

diffèrent peu les uns des autres, c'est-à-dire la matrice N(x) bien conditionné. Rappelons que valeurs propres je, je, je =1, …, Résultats expérimentaux (méthode de relaxation supérieure), les matrices sont les racines de l'équation caractéristique

Cependant, en pratique, en règle générale, les fonctions minimisées ont des matrices de dérivées secondes mal conditionnées (t/m<< 1). Les valeurs de ces fonctions dans certaines directions changent beaucoup plus rapidement (parfois de plusieurs ordres de grandeur) que dans d'autres directions. Leurs surfaces planes dans le cas le plus simple sont fortement allongées, et dans les cas plus complexes elles se courbent et apparaissent comme des ravins. Les fonctions avec de telles propriétés sont appelées ravine. La direction de l'antigradient de ces fonctions (voir Fig. 2.10) s'écarte considérablement de la direction vers le point minimum, ce qui entraîne un ralentissement de la vitesse de convergence.
Les expériences démontrent une bonne accélération (environ 4 sur 8 threads).
Les méthodes de gradient discutées ci-dessus ne trouvent le point minimum d'une fonction dans le cas général que dans un nombre infini d'itérations. La méthode du gradient conjugué génère des directions de recherche plus cohérentes avec la géométrie de la fonction minimisée. Cela augmente considérablement la vitesse de leur convergence et permet, par exemple, de minimiser la fonction quadratique
f(x) = (x, Hx) + (b, x) + une
avec une matrice définie positive symétrique N en un nombre fini d'étapes p,égal au nombre de variables de fonction. Toute fonction lisse à proximité du point minimum peut être bien approchée par une fonction quadratique, c'est pourquoi les méthodes de gradient conjugué sont utilisées avec succès pour minimiser les fonctions non quadratiques. Dans ce cas, ils cessent d’être finis et deviennent itératifs.
Par définition, deux Résultats expérimentaux (méthode de relaxation supérieure) vecteur dimensionnel X Et à appelé Définition . Deux vecteurs à n dimensions x et y sont appelés par rapport à la matrice H(ou H-conjugué), si le produit scalaire (x, Eh bien) = 0. Ici N- matrice de taille définie positive symétrique n X p.
L’un des problèmes les plus importants des méthodes de gradient conjugué est celui de la construction efficace de directions. La méthode Fletcher-Reeves résout ce problème en transformant l'antigradient à chaque étape -f(x[k]) dans la direction p[k], H-conjuguer avec les directions trouvées précédemment r, r, ..., r[k-1]. Considérons d'abord cette méthode en relation avec le problème de la minimisation d'une fonction quadratique.
Instructions r[k] est calculé à l'aide des formules :
p[k] = -f"(x[k]) +bk-1 p[k-l], k>= 1;
p = -f"(x) .
valeurs b k-1 sont choisis pour que les directions p[k], r[k-1] étaient H-conjuguer:
(p[k], HP[k- 1])= 0.
En conséquence, pour la fonction quadratique
le processus itératif de minimisation a la forme
x[k+l] =x[k]+un k p[k],
Où r[k] - direction de descente vers k- m pas; UN k - taille du pas. Cette dernière est choisie parmi la condition minimale de la fonction f(x) Par UN dans la direction du mouvement, c'est-à-dire suite à la résolution du problème de minimisation unidimensionnelle :
f(x[k] + UN k r[k]) = f(x[k] + ar [k]) .
Pour une fonction quadratique
L'algorithme de la méthode du gradient conjugué de Fletcher-Reeves est le suivant.
1. Au point X calculé p = -f"(x) .
2. Activé k- m pas, en utilisant les formules ci-dessus, le pas est déterminé UN k . et période X[k+ 1].
3. Les valeurs sont calculées f(x[k+1]) Et f"(x[k+1]) .
4. Si f"(x) = 0, alors pointez X[k+1] est le point minimum de la fonction f(x). Sinon, une nouvelle direction est déterminée p[k+l] de la relation
et le passage à l'itération suivante est effectué. Cette procédure trouvera le minimum d'une fonction quadratique en pas plus de n mesures. Lors de la minimisation de fonctions non quadratiques, la méthode Fletcher-Reeves devient itérative à partir de finie. Dans ce cas, après (p+ 1) la ème itération de la procédure 1 à 4 est répétée cycliquement avec remplacement X sur X[n+1] , et les calculs se terminent à, où est un nombre donné. Dans ce cas, la modification suivante de la méthode est utilisée :
x[k+l] =x[k]+un k p[k],
p[k] = -f"(x[k])+ b k- 1 p[k-l], k>= 1;
p= -f"( x);
f(x[k] + un k p[k]) = f(x[k] +ap[k];

Ici je- de nombreux index : je= (0, n, 2 p, salaire, ...), c'est-à-dire que la méthode est mise à jour tous les n mesures.
La signification géométrique de la méthode du gradient conjugué est la suivante (Fig. 2.11). A partir d'un point de départ donné X la descente s'effectue dans le sens r = -f"(x). Au point X le vecteur gradient est déterminé f"(x). Parce que X est le point minimum de la fonction dans la direction r, Que f"(x) orthogonal au vecteur r. On trouve alors le vecteur r , H-conjugué à r. Ensuite, on trouve le minimum de la fonction dans la direction r etc.

Riz. 2.11 .
Les méthodes de direction conjuguée sont parmi les plus efficaces pour résoudre les problèmes de minimisation. Il convient toutefois de noter qu’ils sont sensibles aux erreurs qui surviennent lors du processus de comptage. À grand nombre variables, l'erreur peut tellement augmenter que le processus devra être répété même pour une fonction quadratique, c'est-à-dire le processus correspondant ne rentre pas toujours dans n mesures.
Méthodes de gradient basées uniquement sur le calcul du gradient R.(x), sont des méthodes du premier ordre, puisque sur l'intervalle de pas elles remplacent la fonction non linéaire R.(x) linéaire.
Méthodes du second ordre qui utilisent non seulement les dérivées premières, mais aussi les dérivées secondes de R.(x) au point actuel. Cependant, ces méthodes ont leurs propres problèmes difficiles à résoudre - le calcul des dérivées secondes en un point, et de plus, loin d'être optimal, la matrice des dérivées secondes peut être mal conditionnée.
La méthode du gradient conjugué est une tentative de combiner les avantages des méthodes du premier et du deuxième ordre tout en éliminant leurs inconvénients. Sur étapes initiales(loin de l’optimum) la méthode se comporte comme une méthode du premier ordre, et au voisinage de l’optimum elle se rapproche des méthodes du second ordre.
La première étape est similaire à la première étape de la méthode de descente la plus raide, la deuxième étape et les étapes suivantes sont choisies à chaque fois dans la direction formée comme une combinaison linéaire des vecteurs gradient en un point donné et de la direction précédente.
L'algorithme de la méthode peut s'écrire comme suit (sous forme vectorielle) :
x 1 = x 0 – h grade R(x 0),
x je+1 = x je – h .
La valeur α peut être trouvée approximativement à partir de l'expression
L'algorithme fonctionne comme suit. Du point de départ X 0 je cherche min R.(x) dans le sens du gradient (en utilisant la méthode de descente la plus raide), puis, à partir du point trouvé et plus loin, la direction de recherche min est déterminée par la deuxième expression. La recherche du minimum dans la direction peut être effectuée de n'importe quelle manière : vous pouvez utiliser la méthode de balayage séquentiel sans ajuster le pas de balayage lorsque vous dépassez le minimum, de sorte que la précision de l'obtention du minimum dans la direction dépend de la taille du pas. h.
Pour une fonction quadratique R.(x) une solution peut être trouvée dans n mesures (p– dimension du problème). Pour d'autres fonctions, la recherche sera plus lente et, dans certains cas, elle pourra ne pas atteindre du tout l'optimum en raison de forte influence erreurs de calcul.
L'une des trajectoires possibles pour rechercher le minimum d'une fonction bidimensionnelle à l'aide de la méthode du gradient conjugué est illustrée à la Fig. 1.
Algorithme de la méthode du gradient conjugué pour trouver le minimum.
Étape initiale. Exécution de la méthode du gradient.
Définir l'approximation initiale x 1 0 ,X 2 0 . Détermination de la valeur du critère R.(x 1 0 ,X 2 0). Définissez k = 0 et passez à l’étape 1 de l’étape initiale.
Étape 1.  Et
Et 
 .
.
Étape 2. Si le module dégradé 
Étape 3.
x k+1 = x k – h diplômé R.(x k)).
Étape 4. R.(x 1k +1 , X 2k +1). Si R.(x 1k +1 , X 2k +1)< R.(x 1k, X 2 k), puis définissez k = k+1 et passez à l'étape 3. Si R.(x 1k +1 , X 2 k +1) ≥ R.(x 1k, X 2 k), puis rendez-vous sur la scène principale.
Scène principale.
Étape 1. Calculer R(x 1 k + g, x 2 k), R(x 1 k – g, x 2 k), R(x 1 k , x 2 k + g), R(x 1 k , x 2 k) . Conformément à l'algorithme, à partir d'un échantillon central ou apparié, calculer la valeur des dérivées partielles  Et
Et 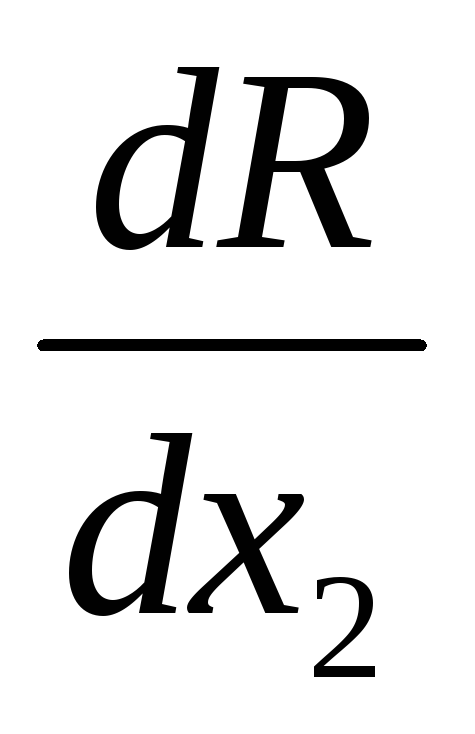 . Calculer la valeur du module de gradient
. Calculer la valeur du module de gradient  .
.
Étape 2. Si le module dégradé  , puis arrêtez le calcul et considérez le point (x 1 k, x 2 k) comme le point optimal. Sinon, passez à l'étape 3.
, puis arrêtez le calcul et considérez le point (x 1 k, x 2 k) comme le point optimal. Sinon, passez à l'étape 3.
Étape 3. Calculer le coefficient α selon la formule :

Étape 4. Effectuez l'étape de travail en calculant à l'aide de la formule
xk+1 = xk – h .
Étape 5. Déterminer la valeur du critère R.(x 1k +1 , X 2k +1). Définissez k = k+1 et passez à l’étape 1.
Exemple.
À titre de comparaison, considérons la solution de l’exemple précédent. Nous faisons le premier pas en utilisant la méthode de descente la plus raide (tableau 5).
Tableau 5
Le meilleur point a été trouvé. Nous calculons les dérivées à ce stade : RD/ dx 1 = –2.908; RD/ dx 2 =1,600 ; On calcule le coefficient α, qui prend en compte l'influence du gradient au point précédent : α = 3,31920 ∙ 3,3192/8,3104 2 =0,160. On fait une étape de travail conformément à l'algorithme de la méthode, on obtient X 1 = 0,502, X 2 = 1.368. Ensuite, tout se répète de la même manière. Ci-dessous, dans le tableau. 6 montre les coordonnées de recherche actuelles pour les prochaines étapes.
Tableau 6







