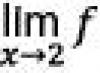La fonction de distribution dans ce cas, selon (5.7), prendra la forme :
où : m – espérance mathématique, s – moyenne écart type.
La distribution normale est également appelée gaussienne du nom du mathématicien allemand Gauss. Le fait que variable aléatoire a une distribution normale avec les paramètres : m,, notés comme suit : N (m,s), où : m =a =M ;
Très souvent dans les formules, l'espérance mathématique est notée UN . Si une variable aléatoire est distribuée selon la loi N(0,1), alors elle est appelée variable normale normalisée ou standardisée. La fonction de distribution correspondante a la forme :
|
|
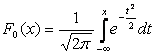 .
.Graphique de densité distribution normale, appelée courbe normale ou courbe de Gauss, est représentée sur la figure 5.4.

Riz. 5.4. Densité de distribution normale
La détermination des caractéristiques numériques d'une variable aléatoire par sa densité est envisagée à l'aide d'un exemple.
Exemple 6.
Une variable aléatoire continue est spécifiée par la densité de distribution : ![]() .
.
Déterminez le type de distribution, trouvez l'espérance mathématique M(X) et la variance D(X).
Comparaison densité donnée distribution normale avec (5.16), nous pouvons conclure qu’une loi de distribution normale avec m =4 est spécifiée. Par conséquent, espérance mathématique M(X)=4, variance D(X)=9.
Écart type s=3.
La fonction de Laplace, qui a la forme :
|
|
 ,
,est liée à la fonction de distribution normale (5.17), la relation :
F 0 (x) = Ф(x) + 0,5.
La fonction de Laplace est étrange.
Ф(-x)=-Ф(x).
Les valeurs de la fonction de Laplace Ф(х) sont tabulées et extraites du tableau en fonction de la valeur de x (voir annexe 1).
La distribution normale d'une variable aléatoire continue joue rôle important en théorie des probabilités et dans la description de la réalité, est très répandu dans événements aléatoires nature. Dans la pratique, nous rencontrons très souvent des variables aléatoires qui se forment précisément à la suite de la sommation de nombreux termes aléatoires. En particulier, une analyse des erreurs de mesure montre qu'elles sont la somme diverses sortes erreurs. La pratique montre que la distribution de probabilité des erreurs de mesure est proche de loi normale.
À l'aide de la fonction de Laplace, vous pouvez résoudre le problème du calcul de la probabilité de tomber dans un intervalle donné et un écart donné d'une variable aléatoire normale.
Quelle est l’idée derrière le raisonnement probabiliste ?La première étape, la plus naturelle, du raisonnement probabiliste est la suivante : si vous avez une variable qui prend des valeurs au hasard, alors vous aimeriez savoir avec quelles probabilités cette variable prend certaines valeurs. La totalité de ces probabilités précise la distribution de probabilité. Par exemple, étant donné un dé, vous pouvez supposer a priori qu'avec probabilités égales 1/6, il tombera sur n'importe quel bord. Et cela se produit à condition que l'os soit symétrique. Si l'os est asymétrique, vous pouvez alors déterminer fortes probabilités pour les visages qui tombent plus souvent, et des probabilités plus faibles pour les visages qui tombent moins souvent, sur la base de données expérimentales. Si un visage n'apparaît pas du tout, alors on peut lui attribuer une probabilité de 0. Il s'agit de la loi probabiliste la plus simple qui puisse être utilisée pour décrire les résultats du lancement d'un dé. Bien sûr, il s'agit d'un exemple extrêmement simple, mais des problèmes similaires se posent, par exemple, dans les calculs actuariels, lorsque le risque réel lors de l'émission d'une police d'assurance est calculé sur la base de données réelles.
Dans ce chapitre, nous examinerons les lois probabilistes qui surviennent le plus souvent dans la pratique.
Les graphiques de ces distributions peuvent être facilement tracés dans STATISTICA.
Répartition normale
La distribution de probabilité normale est particulièrement souvent utilisée en statistiques. La distribution normale fournit un bon modèle pour phénomènes réels, dans lequel :
1) il existe une forte tendance à regrouper les données autour d’un centre ;
2) les écarts positifs et négatifs par rapport au centre sont également probables ;
3) la fréquence des écarts diminue rapidement lorsque les écarts par rapport au centre deviennent importants.
Le mécanisme sous-jacent à la distribution normale, expliqué à l'aide du théorème central limite, peut être décrit au sens figuré comme suit. Imaginez que vous ayez des particules de pollen que vous avez laissé tomber au hasard dans un verre d'eau. Considérant particule séparée au microscope, tu verras phénomène étonnant- la particule bouge. Bien entendu, cela se produit parce que les molécules d’eau se déplacent et transmettent leur mouvement aux particules de pollen en suspension.
Mais comment se produit exactement le mouvement ? En voici plus question intéressante. Et ce mouvement est très bizarre !
Disponible nombre infini influences indépendantes sur une particule de pollen individuelle sous la forme d'impacts de molécules d'eau, qui forcent la particule à suivre une trajectoire très étrange. Au microscope, ce mouvement ressemble à une ligne brisée de manière répétée et chaotique. Ces déformations ne peuvent pas être prédites ; elles ne présentent aucun motif qui corresponde exactement aux impacts chaotiques des molécules sur une particule. Particule en suspension, ayant subi l'impact d'une molécule d'eau dans moment aléatoire temps, change la direction de son mouvement, puis se déplace pendant un certain temps par inertie, puis retombe sous l'impact de la molécule suivante, et ainsi de suite. Se pose billard incroyable dans un verre d'eau !
Étant donné que le mouvement des molécules a une direction et une vitesse aléatoires, l’ampleur et la direction des courbures de la trajectoire sont également complètement aléatoires et imprévisibles. Ce phénomène étonnant s'appelle Mouvement brownien, découvert au XIXème siècle, fait réfléchir à beaucoup de choses.
Si nous introduisons un système approprié et marquons les coordonnées de la particule à certains moments, nous obtiendrons alors la loi normale. Plus précisément, les déplacements de la particule de pollen résultant des impacts moléculaires obéiront à la loi normale.
Pour la première fois, la loi du mouvement d'une telle particule, appelée brownienne, a été décrite à un niveau de rigueur physique par A. Einstein. Lenzhevan a alors développé une approche plus simple et plus intuitive.
Les mathématiciens du XXe siècle ont consacré leurs meilleures pages à cette théorie, et le premier pas a été franchi il y a 300 ans, lorsqu'elle a été découverte. option la plus simple théorème central limite.
En théorie des probabilités, le centre théorème limite, connue à l'origine dans la formulation de Moivre et Laplace au 17ème siècle comme un développement de la célèbre loi grands nombres J. Bernoulli (1654-1705) (voir J. Bernoulli (1713), Ars Conjectandi), s'est aujourd'hui extrêmement développé et a atteint son apogée. V principe moderne invariance, dans la création de laquelle le Russe a joué un rôle important école de mathématiques. C’est dans ce principe que le mouvement d’une particule brownienne trouve son explication mathématique stricte.
L’idée est que lorsqu’on additionne un grand nombre grandeurs indépendantes(les impacts des molécules sur les particules de pollen) dans certaines conditions raisonnables s'avèrent tout à fait normaux quantités distribuées. Et cela se produit indépendamment, c’est-à-dire invariablement, de la distribution des valeurs initiales. En d'autres termes, si une certaine variable est influencée par de nombreux facteurs, ces influences sont indépendantes, relativement faibles et s'additionnent les unes aux autres, alors la valeur résultante a une distribution normale.
Par exemple, pratiquement nombre infini des facteurs déterminent le poids d’une personne (des milliers de gènes, des prédispositions, des maladies, etc.). Ainsi, on pourrait s’attendre à une répartition normale du poids dans une population composée de tous les individus.
Si vous êtes un financier et jouez en bourse, vous connaissez bien sûr des cas où les cours des actions se comportent comme des particules browniennes, subissant les impacts chaotiques de nombreux facteurs.

Formellement, la densité de distribution normale s'écrit comme suit :

où a et õ 2 sont les paramètres de la loi, interprétés respectivement comme la moyenne et la variance d'une variable aléatoire donnée (en raison du rôle particulier de la distribution normale, nous utiliserons des symboles spéciaux pour désigner sa fonction de densité et sa fonction de distribution). Graphique visuel densité normale- C'est la fameuse courbe en forme de cloche.
La fonction de distribution correspondante d'une variable aléatoire normale (a,õ 2) est notée Ф(x; a,õ 2) et est donnée par la relation :

La loi normale de paramètres a = 0 et õ 2 = 1 est dite standard.
Fonction inverse de la distribution normale standard appliquée à la valeur z, 0 Utilisez le calculateur de probabilités de STATISTICA pour calculer z à partir de x et vice versa. Principales caractéristiques de la loi normale : Moyenne, mode, médiane : E=x mod =x med =a ; Dispersion : D=õ 2 ; Asymétrie: Excès: D'après les formules, il ressort clairement que la distribution normale est décrite par deux paramètres : a - moyenne - moyenne ; õ - écart type - écart type, lire : « sigma ». Parfois avec l'écart type est appelé écart type, mais c'est une terminologie déjà obsolète. Voici quelques faits utiles sur la distribution normale. La valeur moyenne détermine la mesure de localisation de la densité. La densité d'une distribution normale est symétrique par rapport à la moyenne. La moyenne d'une distribution normale coïncide avec la médiane et le mode (voir graphiques). Densité de distribution normale avec variance 1 et moyenne 1 Densité de distribution normale avec moyenne 0 et variance 0,01 Densité de distribution normale avec moyenne 0 et variance 4 À mesure que la dispersion augmente, la densité de la distribution normale s'étale ou s'étale le long de l'axe OX ; lorsque la dispersion diminue, elle se contracte au contraire en se concentrant autour d'un point - le point de valeur maximale, qui coïncide avec la valeur moyenne. . Dans le cas limite de variance nulle, la variable aléatoire dégénère et prend une valeur unique égale à la moyenne. Il est utile de connaître les règles des 2 et 3 sigmas, ou des 2 et 3 écarts types, qui sont liées à la distribution normale et sont utilisées dans diverses applications. La signification de ces règles est très simple. Si à partir du point de moyenne ou, ce qui est la même chose, à partir du point de densité maximale d'une distribution normale, on place respectivement deux et trois écarts types (2 et 3 sigma) à droite et à gauche, alors le l'aire sous le graphique de densité normale calculée à partir de cet intervalle sera respectivement égale à 95,45% et 99,73% de l'aire totale sous le graphique (vérifiez-le sur le calculateur de probabilité STATISTICA !). En d’autres termes, cela peut être exprimé comme suit : 95,45 % et 99,73 % de toutes les observations indépendantes dans une population normale, comme la taille des pièces ou le cours des actions, se situent entre 2 et 3 écarts types par rapport à la moyenne. Répartition uniforme La distribution uniforme est utile pour décrire des variables dans lesquelles chaque valeur est également probable, en d'autres termes, les valeurs de la variable sont uniformément réparties sur une région. Vous trouverez ci-dessous les formules pour la fonction de densité et de distribution d'une variable aléatoire uniforme prenant des valeurs sur l'intervalle [a, b]. A partir de ces formules, il est facile de comprendre que la probabilité qu'une variable aléatoire uniforme prenne des valeurs de l'ensemble [c, d] [a, b], est égal à (d - c)/(b - a). Mettons une=0,b=1. Vous trouverez ci-dessous un graphique d'une densité de probabilité uniforme centrée sur le segment. Caractéristiques numériques de la loi uniforme : Distribution exponentielle Des événements se produisent qui, dans le langage courant, peuvent être qualifiés de rares. Si T est le temps entre les occurrences d'événements rares se produisant en moyenne avec une intensité X, alors la valeur Cette distribution a une propriété très intéressante d'absence de séquelle, ou, comme on dit aussi, la propriété de Markov, en l'honneur du célèbre mathématicien russe A. A. Markov, qui peut s'expliquer comme suit. Si la répartition entre les moments d'apparition de certains événements est indicative, alors la répartition comptée à partir de tout moment t jusqu'au prochain événement a également une distribution exponentielle (avec le même paramètre). En d'autres termes, pour un flux d'événements rares, le temps d'attente du prochain visiteur est toujours distribué de manière exponentielle, quel que soit le temps que vous avez déjà attendu. La distribution exponentielle est liée à la distribution de Poisson : dans un intervalle de temps unitaire, le nombre d'événements, dont les intervalles sont indépendants et distribués exponentiellement, a une distribution de Poisson. Si les intervalles entre les visites sur site ont une distribution exponentielle, alors le nombre de visites, par exemple dans une heure, est distribué selon la loi de Poisson. La distribution exponentielle est un cas particulier de la distribution de Weibull. Si le temps n'est pas continu, mais discret, alors un analogue de la distribution exponentielle est la distribution géométrique. La densité de distribution exponentielle est décrite par la formule : Cette distribution n'a qu'un seul paramètre, qui détermine ses caractéristiques. Le graphique de densité de distribution exponentielle ressemble à ceci : Basique caractéristiques numériques distribution exponentielle : Distribution Erlang Cette distribution continue est centrée sur (0,1) et a pour densité : L'espérance et la variance sont respectivement égales La distribution Erlang porte le nom de A. Erlang, qui l'a utilisée pour la première fois dans des problèmes de théorie des files d'attente et de la téléphonie. Une distribution d'Erlang avec les paramètres µ et n est la distribution de la somme de n variables aléatoires indépendantes et identiquement distribuées, dont chacune a une distribution exponentielle avec le paramètre nµ À La distribution n = 1 d'Erlang est la même que la distribution exponentielle ou exponentielle. Distribution de Laplace La fonction de densité de Laplace, ou double exponentielle comme on l'appelle également, est utilisée, par exemple, pour décrire la distribution des erreurs dans les modèles de régression. En regardant le graphique de cette distribution, vous verrez qu'elle se compose de deux distributions exponentielles, symétriques par rapport à l'axe OY. Si le paramètre de position est 0, alors la fonction de densité de distribution de Laplace a la forme : Les principales caractéristiques numériques de cette loi de distribution, en supposant que le paramètre de position est nul, sont les suivantes : En général, la densité de distribution de Laplace a la forme : a est la moyenne de la distribution ; b - paramètre d'échelle ; e - Nombre d'Euler (2,71...). Distribution gamma La densité de la distribution exponentielle a un mode au point 0, ce qui est parfois gênant pour les applications pratiques. Dans de nombreux exemples, on sait d'avance que le mode de la variable aléatoire considérée n'est pas égal à 0, par exemple, les intervalles entre les arrivées des clients dans une boutique e-commerce ou les visites sur un site internet ont un mode prononcé. Pour modéliser de tels événements, la distribution gamma est utilisée. La densité de distribution gamma a la forme : où Г est la fonction Г d'Euler, a > 0 est le paramètre « forme » et b > 0 est le paramètre d'échelle. Dans un cas particulier, nous avons la distribution d'Erlang et la distribution exponentielle. Principales caractéristiques de la distribution gamma : Vous trouverez ci-dessous deux tracés de densité gamma avec un paramètre d'échelle de 1 et des paramètres de forme de 3 et 5. Propriété utile de la distribution gamma : la somme d'un nombre quelconque de variables aléatoires indépendantes distribuées gamma (avec le même paramètre d'échelle b) (a l ,b) + (a 2 ,b) + --- +(a n ,b) obéit également à la distribution gamma, mais avec les paramètres a 1 + a 2 + + a n et b. Distribution lognormale Une variable aléatoire h est appelée logarithmiquement normale, ou lognormale, si son logarithme népérien (lnh) est soumis à la loi de distribution normale. La distribution lognormale est utilisée, par exemple, lors de la modélisation de variables telles que le revenu, l'âge des jeunes mariés ou un écart acceptable par rapport à la norme. substances nocives dans les produits alimentaires. Donc, si la valeur x a une distribution normale, alors la valeur y = e x a une distribution lognormale. Si vous remplacez une valeur normale par la puissance d'un exposant, vous pouvez facilement comprendre qu'une valeur lognormale est le résultat de multiplications répétées de variables indépendantes, tout comme une variable aléatoire normale est le résultat d'une sommation répétée. La densité de distribution lognormale a la forme : Principales caractéristiques de la distribution lognormale : Distribution du chi carré La somme des carrés de m variables normales indépendantes de moyenne 0 et de variance 1 a une distribution du chi carré avec m degrés de liberté. Cette distribution est le plus souvent utilisée dans l'analyse des données. Formellement, la densité de la distribution bien carrée à m degrés de liberté a la forme : Pour le négatif La densité x devient 0. Caractéristiques numériques de base de la distribution du Chi carré : Le graphique de densité est présenté dans la figure ci-dessous : Distribution binomiale La distribution binomiale est la plus importante distribution discrète, qui se concentre en quelques points seulement. Ces points distribution binomiale attribue des probabilités positives. La distribution binomiale est donc différente de distributions continues(normal, chi carré, etc.), qui attribuent des probabilités nulles à des points sélectionnés individuellement et sont appelés continus. Vous pouvez mieux comprendre la distribution binomiale en considérant le jeu suivant. Imaginez que vous lancez une pièce de monnaie. Qu'il y ait une probabilité que les armoiries tombent p, et la probabilité d'atterrissage des têtes est q = 1 - p (on considère le plus cas général, lorsque la pièce est asymétrique, présente par exemple un décalage centre de gravité il y a un trou dans la pièce). Décrocher un blason est considéré comme un succès, tandis que décrocher une queue est considéré comme un échec. Ensuite, le nombre de têtes (ou de queues) tirées a une distribution binomiale. A noter que la prise en compte de pièces asymétriques ou de dés irréguliers présente un intérêt pratique. Comme le notait J. Neumann dans son élégant livre « Cours d'introduction théorie des probabilités et statistiques mathématiques", les gens ont longtemps deviné que la fréquence des points tombant sur dés dépend des propriétés de cet os lui-même et peut être modifié artificiellement. Les archéologues ont découvert deux paires d'os dans la tombe du pharaon : les « honnêtes » - avec des probabilités égales de chute de tous les côtés, et les faux - avec un déplacement délibéré du centre de gravité, ce qui a augmenté la probabilité de chute des six. Les paramètres de la distribution binomiale sont la probabilité de succès p (q = 1 - p) et le nombre de tests n. La distribution binomiale est utile pour décrire la distribution d'événements binomiaux, tels que le nombre d'hommes et de femmes dans des entreprises sélectionnées au hasard. L'utilisation de la distribution binomiale dans les problèmes de jeu est particulièrement importante. La formule exacte de la probabilité m de succès dans n essais s’écrit ainsi : p-probabilité de succès q est égal à 1-p, q>=0, p+q==1 n- nombre de tests, m =0,1...m Principales caractéristiques de la distribution binomiale : Le graphique de cette distribution à divers numéros les tests n et les probabilités de réussite p ont la forme : La distribution binomiale est liée aux distributions normale et de Poisson (voir ci-dessous) ; à certaines valeurs de paramètres à grand nombre tests, il se transforme en ces distributions. Ceci est facile à démontrer avec STATISTICA. Par exemple, en considérant un graphique d'une distribution binomiale avec des paramètres p = 0,7, n = 100 (voir figure), nous avons utilisé STATISTICA BASIC - vous pouvez voir que le graphique est très similaire à la densité d'une distribution normale (c'est vraiment le cas !). Diagramme de distribution binomiale avec paramètres p=0,05, n=100 est très similaire au graphique de distribution de Poisson. Comme déjà mentionné, la distribution binomiale est issue d'observations de la forme la plus simple jeu d'argent- lancer une pièce juste. Dans de nombreuses situations, ce modèle sert bien d'abord j'approche pour en savoir plus jeux stimulants Et processus aléatoires survenant lors du jeu en bourse. Il est remarquable que les caractéristiques essentielles de nombreux processus complexes peut être compris à partir d’un simple modèle binomial. Par exemple, considérons la situation suivante. Notons la perte d'un blason par 1 et la perte d'une queue par moins 1, et nous additionnerons les victoires et les défaites à des moments successifs dans le temps. Les graphiques montrent les trajectoires typiques d'un tel jeu pour 1 000 lancers, pour 5 000 lancers et pour 10 000 lancers. Remarquez comment la trajectoire est au-dessus ou en dessous de zéro pendant de longues périodes de temps, en d'autres termes, le temps pendant lequel l'un des joueurs gagne dans un jeu tout à fait équitable est très long, et les transitions de la victoire à la défaite sont relativement rares, et cela est difficile à concilier dans un esprit non préparé, pour qui l’expression « jeu absolument équitable » sonne comme un sortilège. Ainsi, bien que le jeu soit équitable au regard de ses conditions, le comportement d'une trajectoire typique n'est pas juste du tout et ne démontre pas d'équilibre ! Bien sûr, empiriquement, ce fait est connu de tous les joueurs ; une stratégie y est associée lorsque le joueur n'est pas autorisé à repartir avec les gains, mais est obligé de continuer à jouer. Considérons le nombre de lancers pendant lesquels un joueur gagne (trajectoire supérieure à 0) et le deuxième joueur perd (trajectoire inférieure à 0). À première vue, il semble que le nombre de ces lancers soit à peu près le même. Cependant (voir le livre passionnant : Feller V. « Introduction to Probability Theory and Its Applications. » Moscou : Mir, 1984, p. 106) avec 10 000 lancers d'une pièce idéale (c'est-à-dire pour les tests de Bernoulli avec p = q = 0,5, n=10 000), la probabilité que l'une des parties soit en tête dans plus de 9 930 procès et l'autre dans moins de 70, dépasse 0,1. Étonnamment, dans un jeu de 10 000 tirages au sort équitables, la probabilité que la direction change au plus 8 fois est supérieure à 0,14, et la probabilité de plus de 78 changements de direction est d'environ 0,12. Nous nous trouvons donc face à une situation paradoxale : dans une marche de Bernoulli symétrique, les « vagues » sur le graphique entre les retours successifs à zéro (voir graphiques) peuvent être étonnamment longues. Une autre circonstance est liée à cela, à savoir que pour T n /n (fraction de temps lorsque le graphique est au-dessus de l'axe des x) les valeurs les moins probables sont proches de 1/2. Les mathématiciens ont découvert la loi dite de l'arc sinus, selon laquelle pour chaque 0< а <1 вероятность неравенства
, где Т n - число шагов, в течение которых первый игрок находится в выигрыше, стремится к Distribution de l'arc sinus Cette distribution continue est centrée sur l'intervalle (0, 1) et a une densité : La distribution arc sinus est associée à une marche aléatoire. Il s'agit de la distribution de la fraction de temps pendant laquelle le premier joueur gagne en lançant une pièce symétrique, c'est-à-dire une pièce qui a des probabilités égales. Le S tombe sur les armoiries et les queues. D'une autre manière, un tel jeu peut être considéré comme une marche aléatoire d'une particule qui, à partir de zéro, effectue des sauts simples vers la droite ou vers la gauche avec des probabilités égales. Étant donné que les sauts de particules - chutes de têtes ou de queues - sont également probables, une telle marche est souvent qualifiée de symétrique. Si les probabilités étaient différentes, nous aurions alors une marche asymétrique. Le graphique de densité de distribution arc sinus est illustré dans la figure suivante : Le plus intéressant est l’interprétation qualitative du graphique, à partir de laquelle on peut tirer des conclusions surprenantes sur la série de victoires et de défaites dans un jeu équitable. En regardant le graphique, vous pouvez voir que la densité minimale est au point 1/2. "Et alors ?!" - demandez-vous. Mais si vous réfléchissez à ce constat, alors votre surprise ne connaîtra pas de limites ! Il s’avère que même si le jeu est défini comme équitable, il n’est en réalité pas aussi équitable qu’il y paraît à première vue. Les trajectoires aléatoires symétriques, dans lesquelles la particule passe un temps égal sur les demi-axes positif et négatif, c'est-à-dire à droite ou à gauche de zéro, sont précisément les moins probables. En passant au langage des joueurs, nous pouvons dire que lorsqu'on lance une pièce symétrique, les jeux dans lesquels les joueurs passent un temps égal à gagner et à perdre sont les moins probables. Au contraire, les jeux dans lesquels un joueur a beaucoup plus de chances de gagner et l'autre de perdre sont les plus probables. Étonnant paradoxe ! Calculer la probabilité que la fraction de temps t pendant laquelle le premier joueur gagne soit comprise entre t1 à t2, nécessaire à partir de la valeur de la fonction de distribution F(t2) soustrait la valeur de la fonction de distribution F(t1). Formellement on obtient : P(t1 Sur la base de ce fait, on peut calculer à l'aide de STATISTICA qu'à 10 000 pas, la particule reste du côté positif plus de 9 930 fois avec une probabilité de 0,1, c'est-à-dire qu'en gros, une telle position sera observée au moins dans un cas. sur dix (même si, à première vue, cela semble absurde ; voir la note remarquable de Yu. V. Prokhorov « Le Rambler de Bernoulli » dans l'encyclopédie « Probabilités et statistiques mathématiques », pp. 42-43, M. : Big Russian Encyclopedia, 1999 ) . Distribution binomiale négative Il s'agit d'une distribution discrète attribuée à des points entiers k = 0,1,2,... probabilités : p k =P(X=k)=C k r+k-1 p r (l-p) k ", où 0<р<1,r>0.
La distribution binomiale négative se retrouve dans de nombreuses applications. Dans l'ensemble r > 0, la distribution binomiale négative est interprétée comme la distribution du temps d'attente pour le rème « succès » dans un schéma de test de Bernoulli avec la probabilité de « succès » p, par exemple, le nombre de lancers qui doivent être effectués avant que le deuxième emblème ne soit dessiné, auquel cas on l'appelle parfois la distribution Pascal et est un analogue discret de la distribution gamma. À r = 1 la distribution binomiale négative coïncide avec la distribution géométrique. Si Y est une variable aléatoire ayant une distribution de Poisson avec un paramètre aléatoire, qui à son tour a une distribution gamma avec densité Alors U aura une distribution binomiale négative avec paramètres ; Distribution de Poisson La distribution de Poisson est parfois appelée distribution d'événements rares. Des exemples de variables distribuées selon la loi de Poisson sont : le nombre d'accidents, le nombre de défauts dans le processus de production, etc. La distribution de Poisson est définie par la formule : Principales caractéristiques d'une variable aléatoire de Poisson : La distribution de Poisson est liée à la distribution exponentielle et à la distribution de Bernoulli. Si le nombre d'événements a une distribution de Poisson, alors les intervalles entre les événements ont une distribution exponentielle ou exponentielle. Diagramme de distribution de Poisson : Comparez le graphique de la distribution de Poisson avec le paramètre 5 avec le graphique de la distribution de Bernoulli à p=q=0,5,n=100. Vous verrez que les graphiques sont très similaires. Dans le cas général, il existe le schéma suivant (voir, par exemple, l'excellent livre : Shiryaev A.N. « Probabilité ». Moscou : Nauka, p. 76) : si dans les tests de Bernoulli n prend de grandes valeurs, et la probabilité de succès / ? est relativement petit, de sorte que le nombre moyen de succès (produit et nar) n'est ni petit ni grand, alors la distribution de Bernoulli avec paramètres n, p peut être remplacée par la distribution de Poisson avec paramètre = np. La distribution de Poisson est largement utilisée dans la pratique, par exemple dans les cartes de contrôle qualité en tant que distribution d'événements rares. Comme autre exemple, considérons le problème suivant lié aux lignes téléphoniques et tiré de la pratique (voir : Feller V. Introduction à la théorie des probabilités et ses applications. Moscou : Mir, 1984, p. 205, ainsi que Molina E. S. (1935 ) Probabilités en ingénierie, Génie électrique, 54, p. 423-427 ; Monographie des publications techniques du système téléphonique Bell B-854). Cette tâche peut être facilement traduite dans une langue moderne, par exemple dans la langue des communications mobiles, ce à quoi les lecteurs intéressés sont invités. Le problème est formulé comme suit. Supposons qu'il y ait deux centraux téléphoniques - A et B. Le central téléphonique A doit assurer la communication entre 2 000 abonnés et le central B. La qualité de la communication doit être telle qu'un seul appel sur 100 attend que la ligne soit libre. La question est : combien de lignes téléphoniques devez-vous installer pour garantir la qualité de communication requise ? Évidemment, il est stupide de créer 2 000 lignes, car beaucoup d’entre elles seront gratuites pendant longtemps. D'après des considérations intuitives, il est clair qu'il existe apparemment un nombre optimal de lignes N. Comment calculer ce nombre ? Commençons par un modèle réaliste qui décrit l'intensité de l'accès d'un abonné au réseau, en notant que l'exactitude du modèle peut bien entendu être vérifiée à l'aide de critères statistiques standard. Supposons donc que chaque abonné utilise la ligne en moyenne 2 minutes par heure et que les connexions des abonnés soient indépendantes (cependant, comme le souligne à juste titre Feller, cette dernière se produit à moins qu'un événement ne se produise qui affecte tous les abonnés, par exemple une guerre ou un ouragan). Ensuite, nous avons 2000 essais de Bernoulli (lancers à pile ou face) ou connexions réseau avec une probabilité de succès p=2/60=1/30. Il faut trouver un N tel que la probabilité que plus de N utilisateurs soient simultanément connectés au réseau ne dépasse pas 0,01. Ces calculs peuvent être facilement résolus dans le système STATISTICA. Résoudre le problème avec STATISTICA. Étape 1. Ouvrez le module Statistiques de base. Créez un fichier binoml.sta contenant 110 observations. Nommez la première variable BINÔME, la deuxième variable - POISSON. Étape 2. BINÔME, ouvre la fenêtre Variable 1(voir photo). Entrez la formule dans la fenêtre comme indiqué sur la figure. Cliquez sur le bouton D'ACCORD. Étape 3. Double-cliquez sur le titre POISSON, ouvre la fenêtre Variable 2(voir photo) Entrez la formule dans la fenêtre comme indiqué sur la figure. Notez que nous calculons le paramètre de distribution de Poisson en utilisant la formule =n×p. D'ACCORD.
Donc = 2000 × 1/30. Cliquez sur le bouton STATISTICA calculera les probabilités et les écrira dans le fichier généré.Étape 4. Faites défiler jusqu'au numéro d'observation 86. Vous verrez que la probabilité qu'il y ait 86 utilisateurs simultanés ou plus sur 2 000 utilisateurs du réseau en une heure est de 0,01347 si la distribution binomiale est utilisée. La probabilité que 86 personnes ou plus sur 2 000 utilisateurs du réseau travaillent simultanément en une heure est de 0,01293, en utilisant l'approximation de Poisson pour la distribution binomiale. Puisque nous n'avons besoin que d'une probabilité ne dépassant pas 0,01, 87 lignes suffiront pour fournir la qualité de communication requise. Des résultats similaires peuvent être obtenus en utilisant l'approximation normale de la distribution binomiale (vérifiez ceci !). A noter que V. Feller ne disposait pas du système STATISTICA et utilisait des tableaux de distributions binomiales et normales. En utilisant le même raisonnement, on peut résoudre le problème suivant discuté par W. Feller. Il est nécessaire de vérifier s'il faut plus ou moins de lignes pour desservir de manière fiable les usagers lorsqu'on les divise en 2 groupes de 1000 personnes chacun. Il s'avère que lorsque les utilisateurs sont divisés en groupes, 10 lignes supplémentaires seront nécessaires pour atteindre le même niveau de qualité. Vous pouvez également prendre en compte les changements d’intensité de connexion réseau tout au long de la journée. Distribution géométrique Si des tests de Bernoulli indépendants sont effectués et que le nombre d'essais jusqu'au prochain « succès » est compté, alors ce nombre a une distribution géométrique. Ainsi, si vous lancez une pièce de monnaie, le nombre de lancers que vous devez effectuer avant l’apparition des armoiries suivantes obéit à une loi géométrique. La distribution géométrique est déterminée par la formule : F(x) = p(1-p)x-1 p - probabilité de succès, x = 1, 2,3... Le nom de la distribution est lié à la progression géométrique. La distribution géométrique est un analogue discret de la distribution exponentielle. Si le temps change par quanta, alors la probabilité de succès à chaque instant est décrite par une loi géométrique. Si le temps est continu, alors la probabilité est décrite par une loi exponentielle ou exponentielle. Distribution hypergéométrique Il s'agit d'une distribution de probabilité discrète d'une variable aléatoire X, prenant des valeurs entières m = 0, 1,2,...,n avec des probabilités : où N, M et n sont des entiers non négatifs et M<
N, n < N. La distribution hypergéométrique est généralement associée au choix sans remplacement et détermine, par exemple, la probabilité de trouver exactement m boules noires dans un échantillon aléatoire de taille n à partir d'une population contenant N boules, dont M noires et N - M blanches (voir, pour exemple, l'encyclopédie « Probabilités » et statistiques mathématiques », M. : Grande Encyclopédie russe, p. L'espérance mathématique de la distribution hypergéométrique ne dépend pas de N et coïncide avec l'espérance mathématique µ=np de la distribution binomiale correspondante. Variance de la distribution hypergéométrique Cette distribution se produit extrêmement fréquemment dans les applications de contrôle qualité. Distribution polynomiale La distribution polynomiale, ou multinomiale, généralise naturellement la distribution. Alors qu'une distribution binomiale se produit lorsqu'une pièce de monnaie est lancée avec deux résultats (tête ou crête), une distribution polynomiale se produit lorsqu'un dé est lancé et qu'il y a plus de deux résultats possibles. Formellement, il s'agit d'une distribution de probabilité conjointe de variables aléatoires X 1,...,X k, prenant des valeurs entières non négatives n 1,...,n k, satisfaisant la condition n 1 + ... + n k = n, avec probabilités : Le nom « distribution multinomiale » s'explique par le fait que des probabilités multinomiales surviennent lors du développement du polynôme (p 1 + ... + p k) n Distribution bêta La distribution bêta a une densité de la forme : La distribution bêta standard est centrée sur l'intervalle de 0 à 1. À l'aide de transformations linéaires, la valeur bêta peut être transformée afin qu'elle prenne des valeurs sur n'importe quel intervalle. Caractéristiques numériques de base d'une grandeur ayant une distribution bêta : Distribution des valeurs extrêmes La distribution des valeurs extrêmes (type I) a une densité de la forme : Cette distribution est parfois également appelée distribution des valeurs extrêmes. La distribution des valeurs extrêmes est utilisée dans la modélisation d'événements extrêmes, par exemple le niveau des crues, les vitesses de tourbillon, le maximum des indices boursiers pour une année donnée, etc. Cette distribution est utilisée par exemple en théorie de la fiabilité pour décrire le temps de défaillance des circuits électriques, ainsi que dans les calculs actuariels. Distributions de Rayleigh La distribution de Rayleigh a une densité de la forme : où b est le paramètre d'échelle. La distribution de Rayleigh est concentrée dans la plage de 0 à l'infini. Au lieu de la valeur 0, STATISTICA vous permet de saisir une valeur différente pour le paramètre seuil, qui sera soustraite des données d'origine avant d'ajuster la distribution de Rayleigh. Par conséquent, la valeur du paramètre seuil doit être inférieure à toutes les valeurs observées. Si deux variables 1 et 2 sont indépendantes l’une de l’autre et sont normalement distribuées avec la même variance, alors la variable La distribution de Rayleigh est utilisée, par exemple, en théorie du tir. Distribution de Weibull La distribution de Weibull doit son nom au chercheur suédois Waloddi Weibull, qui a utilisé cette distribution pour décrire les temps de défaillance de différents types dans la théorie de la fiabilité. Formellement, la densité de distribution de Weibull s'écrit : Parfois, la densité de distribution de Weibull s'écrit également : B - paramètre d'échelle ; Paramètre de forme C ; E est la constante d'Euler (2,718...). Paramètre de position. Typiquement, la distribution de Weibull est centrée sur le demi-axe de 0 à l'infini. Si au lieu de la limite 0, nous introduisons le paramètre a, qui est souvent nécessaire dans la pratique, alors la distribution dite de Weibull à trois paramètres apparaît. La distribution de Weibull est largement utilisée en théorie de la fiabilité et en assurance. Comme décrit ci-dessus, la distribution exponentielle est souvent utilisée comme modèle pour estimer le temps jusqu'à la défaillance en supposant que la probabilité de défaillance d'un objet est constante. Si la probabilité de défaillance change avec le temps, la distribution de Weibull est appliquée. À avec =1 ou, dans une autre paramétrisation, avec la distribution de Weibull, comme le montrent facilement les formules, se transforme en distribution exponentielle, et avec - en distribution de Rayleigh. Des méthodes spéciales ont été développées pour estimer les paramètres de la distribution de Weibull (voir, par exemple, le livre : Lawless (1982) Statistical models and METHODS for Lifetime Data, Belmont, CA : Lifetime Learning, qui décrit les méthodes d'estimation, ainsi que les problèmes survenant lors de l'estimation du paramètre de position pour une distribution Weibull à trois paramètres). Souvent, lors de l'analyse de fiabilité, il est nécessaire de prendre en compte la probabilité de défaillance dans un court intervalle de temps après le moment précis. à condition que jusqu'au moment La panne ne s'est pas produite. Cette fonction est appelée fonction de risque, ou fonction de taux de défaillance, et est formellement définie comme suit : H(t) - fonction de taux de défaillance ou fonction de risque à l'instant t ; f(t) - densité de distribution des temps de défaillance ; F(t) - fonction de distribution des temps de défaillance (intégrale de la densité sur l'intervalle). En général, la fonction de taux de défaillance s’écrit comme suit : Lorsque la fonction de risque est égale à une constante, ce qui correspond au fonctionnement normal de l'appareil (voir formules). Lorsque la fonction risque diminue, ce qui correspond au rodage de l'appareil. Lorsque la fonction risque diminue, ce qui correspond au vieillissement du dispositif. Les fonctions de risque typiques sont présentées dans le graphique. Des tracés de densité de Weibull avec divers paramètres sont présentés ci-dessous. Il faut faire attention à trois plages de valeurs du paramètre a : Dans la première région, la fonction de risque diminue (période d'ajustement), dans la deuxième région, la fonction de risque est égale à une constante, dans la troisième région, la fonction de risque augmente. Vous pouvez facilement comprendre ce qui a été dit à l'aide de l'exemple de l'achat d'une voiture neuve : il y a d'abord une période d'adaptation de la voiture, puis une longue période de fonctionnement normal, puis les pièces de la voiture s'usent et le risque de panne augmente fortement. Il est important que toutes les périodes d'exploitation puissent être décrites par la même famille de distribution. C'est l'idée derrière la distribution Weibull. Présentons les principales caractéristiques numériques de la distribution de Weibull. Distribution de Pareto Dans divers problèmes de statistiques appliquées, les distributions dites tronquées sont assez courantes. Par exemple, cette distribution est utilisée en assurance ou en fiscalité, lorsque les intérêts portent sur des revenus dépassant une certaine valeur c 0 Caractéristiques numériques de base de la distribution de Pareto : Distribution logistique La distribution logistique a une fonction de densité : A - paramètre de position ; B - paramètre d'échelle ; E - Nombre d'Euler (2,71...). Hôtelling T 2 distribution Cette distribution continue, centrée sur l'intervalle (0, Г), a pour densité : où sont les paramètres n et k, n >_k >_1, sont appelés degrés de liberté. À k = 1 Hotelling, la distribution P se réduit à la distribution de Student, et pour tout k >1 peut être considéré comme une généralisation de la distribution de Student au cas multivarié. La distribution de Hotelling est basée sur la distribution normale. Soit un vecteur aléatoire à k dimensions Y avoir une distribution normale avec un vecteur de moyennes nul et une matrice de covariance. Considérons la quantité où les vecteurs aléatoires Z i sont indépendants les uns des autres et de Y et sont distribués de la même manière que Y. Alors la variable aléatoire T 2 =Y T S -1 Y a une distribution T 2 -Hotelling à n degrés de liberté (Y est un vecteur colonne, T est l'opérateur de transposition). où est la variable aléatoire t n a une distribution de Student avec n degrés de liberté (voir « Probabilités et statistiques mathématiques », Encyclopédie, p. 792). Si Y a une distribution normale de moyenne non nulle, alors la distribution correspondante est appelée non central Hotelling T 2 -distribution à n degrés de liberté et paramètre de non-centralité v. La distribution T 2 de Hotelling est utilisée en statistique mathématique dans la même situation que la distribution ^ de Student, mais uniquement dans le cas multivarié. Si les résultats des observations X 1,..., X n sont des vecteurs aléatoires indépendants, normalement distribués avec un vecteur de moyennes µ et une matrice de covariance non singulière, alors les statistiques a une distribution Hotelling T 2 avec n - 1 degrés de liberté. Ce fait constitue la base du critère Hotelling. Dans STATISTICA, le test d'Hotelling est disponible par exemple dans le module Statistiques de base et tableaux (voir la boîte de dialogue ci-dessous). Distribution Maxwell La distribution de Maxwell est apparue en physique pour décrire la distribution des vitesses des molécules d'un gaz parfait. Cette distribution continue est centrée sur (0, ) et a pour densité : La fonction de distribution a la forme : où Ф(x) est la fonction de distribution normale standard. La distribution de Maxwell a un coefficient d'asymétrie positif et un seul mode en un point (c'est-à-dire que la distribution est unimodale). La distribution de Maxwell a des moments de fin de n'importe quel ordre ; l'espérance mathématique et la variance sont égales, respectivement, et La distribution de Maxwell est naturellement liée à la distribution normale. Si X 1, X 2, X 3 sont des variables aléatoires indépendantes qui ont une distribution normale avec les paramètres 0 et õ 2, alors la variable aléatoire Répartition de Cauchy Cette étonnante distribution n'a parfois pas de valeur moyenne, puisque sa densité tend très lentement vers zéro à mesure que x augmente en valeur absolue. De telles distributions sont appelées distributions à queue lourde. Si vous avez besoin de proposer une distribution qui n'a pas de moyenne, appelez-la immédiatement distribution de Cauchy. La distribution de Cauchy est unimodale et symétrique par rapport au mode, qui est à la fois médian et a une fonction de densité de la forme : Où c > 0 - paramètre d'échelle et a est le paramètre central, qui détermine simultanément les valeurs du mode et de la médiane. L'intégrale de la densité, c'est-à-dire la fonction de distribution, est donnée par la relation : Répartition des étudiants Le statisticien anglais W. Gosset, connu sous le pseudonyme de « Student » et qui débuta sa carrière par une étude statistique de la qualité de la bière anglaise, obtint le résultat suivant en 1908. Laisser x 0 , x 1 ,.., x m - indépendant, (0, s 2) - variables aléatoires normalement distribuées : Cette distribution, désormais connue sous le nom de distribution Student (en abrégé La distribution t(m), où m est le nombre de degrés de liberté), est à la base du fameux test t, conçu pour comparer les moyennes de deux populations. Fonction de densité f t (x) ne dépend pas de la variance õ 2 des variables aléatoires et, de plus, est unimodal et symétrique par rapport au point x = 0. Caractéristiques numériques de base de la distribution de Student : La distribution t est importante dans les cas où des estimations de la moyenne sont prises en compte et où la variance de l'échantillon est inconnue. Dans ce cas, la variance d'échantillon et la distribution t sont utilisées. Pour les grands degrés de liberté (supérieurs à 30), la distribution t coïncide pratiquement avec la distribution normale standard. Le graphique de la fonction de densité de distribution t se déforme à mesure que le nombre de degrés de liberté augmente comme suit : le pic augmente, les queues vont plus abruptement jusqu'à 0 et le graphique de la fonction de densité de distribution t semble être compressé latéralement. Distribution F Considérons m 1 + m 2 indépendants et (0, s 2) quantités normalement distribuées Évidemment, la même variable aléatoire peut également être définie comme le rapport de deux variables distribuées du chi carré indépendantes et correctement normalisées et , c'est-à-dire Le célèbre statisticien anglais R. Fisher montra en 1924 que la densité de probabilité d'une variable aléatoire F(m 1, m 2) est donnée par la fonction : où Г(у) est la valeur de la fonction gamma d'Euler. indiquer y, et la loi elle-même est appelée la distribution F avec les nombres de degrés de liberté du numérateur et du dénominateur égaux respectivement à m,1l m7 Caractéristiques numériques de base de la distribution F : La distribution F apparaît dans l'analyse discriminante, l'analyse de régression, l'analyse de variance et d'autres types d'analyse de données multivariées. Définition.
Normale est la distribution de probabilité d'une variable aléatoire continue, qui est décrite par la densité de probabilité La loi de distribution normale est également appelée la loi de Gauss. La loi de distribution normale occupe une place centrale dans la théorie des probabilités. Cela est dû au fait que cette loi se manifeste dans tous les cas où une variable aléatoire est le résultat de l'action d'un grand nombre de facteurs différents. Toutes les autres lois de distribution se rapprochent de la loi normale. On peut facilement montrer que les paramètres Trouvons la fonction de distribution F(x)
. Le graphique de densité d'une distribution normale est appelé courbe normale ou Courbe de Gauss. Une courbe normale a les propriétés suivantes : 1) La fonction est définie sur toute la droite numérique. 2) Devant tout le monde X la fonction de distribution ne prend que des valeurs positives. 3) L'axe OX est l'asymptote horizontale du graphique de densité de probabilité, car avec augmentation illimitée de la valeur absolue de l'argument X, la valeur de la fonction tend vers zéro. 4) Trouvez l'extremum de la fonction. Parce que à oui’
> 0
à x
<
m Et oui’
< 0
à x
>
m, puis au point x = t la fonction a un maximum égal à 5) La fonction est symétrique par rapport à une droite x = un, parce que différence (x – une) est inclus dans la fonction de densité de distribution au carré. 6) Pour trouver les points d'inflexion du graphique, nous trouverons la dérivée seconde de la fonction densité. À x
=
m+ et x
=
m- la dérivée seconde est égale à zéro, et en passant par ces points elle change de signe, c'est-à-dire en ces points, la fonction a un point d’inflexion. En ces points, la valeur de la fonction est égale à Traçons la fonction de densité de distribution (Fig. 5). Des graphiques ont été construits pour T=0 et trois valeurs possibles de l'écart type = 1, = 2 et = 7. Comme vous pouvez le constater, à mesure que la valeur de l'écart type augmente, le graphique devient plus plat et la valeur maximale diminue. Si UN> 0, alors le graphique se déplacera dans une direction positive si UN
< 0 – в отрицательном. À UN= 0 et = 1 la courbe s'appelle normalisé. Équation de courbe normalisée : Fonction de Laplace Trouvons la probabilité qu'une variable aléatoire distribuée selon une loi normale tombe dans un intervalle donné. Notons Parce que intégral qui s'appelle Fonction de Laplace ou intégrale de probabilité. Les valeurs de cette fonction pour différentes valeurs X calculés et présentés dans des tableaux spéciaux. Sur la fig. La figure 6 montre un graphique de la fonction de Laplace. La fonction de Laplace a les propriétés suivantes : 1) F(0)
= 0; 2) F(-x)
= - F(x); 3) F(
)
= 1. La fonction de Laplace est aussi appelée fonction d'erreur et désigne erf x. E Sur la fig. La figure 7 montre un graphique de la fonction de Laplace normalisée. P. règle des trois sigma Lorsque l'on considère la loi de distribution normale, un cas particulier important se démarque, connu sous le nom de règle des trois sigma. Écrivons la probabilité que l'écart d'une variable aléatoire normalement distribuée par rapport à l'espérance mathématique soit inférieur à une valeur donnée : Si l'on prend = 3, alors en utilisant les tableaux de valeurs de la fonction de Laplace on obtient : Ceux. la probabilité qu'une variable aléatoire s'écarte de son espérance mathématique d'un montant supérieur au triple de l'écart type est pratiquement nulle. Cette règle s'appelle règle des trois sigma. En pratique, on pense que si la règle des trois sigma est satisfaite pour une variable aléatoire, alors cette variable aléatoire a une distribution normale. Conclusion de la conférence : Au cours de la conférence, nous avons examiné les lois de la distribution des quantités continues. En préparation du cours magistral et des cours pratiques suivants, vous devez compléter de manière indépendante vos notes de cours lors de l'étude approfondie de la littérature recommandée et de la résolution des problèmes proposés. Si le chercheur, après avoir utilisé les méthodes décrites dans le paragraphe précédent, est convaincu que l'hypothèse d'une distribution normale ne peut être acceptée, alors il se pourrait bien qu'en utilisant les méthodes existantes, il soit possible de transformer les données originales de telle manière que leur la distribution obéira à la loi de distribution normale. Pour expliquer l'idée de transformations, considérons un exemple qualitatif. Soit la courbe de distribution f(x) avoir la forme montrée sur la Fig. 3.7, c'est-à-dire il y a une branche gauche très raide et une droite plate. Cette distribution diffère de la normale. Pour effectuer les opérations de transformation, chaque observation est transformée à l'aide d'une transformation logarithmique. Dans ce cas, la branche gauche de la courbe de distribution est fortement étirée et la distribution prend une forme approximativement normale. Si la transformation aboutit à des valeurs situées entre 0 et 1, alors toutes les valeurs observées, pour faciliter les calculs et pour éviter d'obtenir des paramètres négatifs, doivent être multipliées par 10 au degré approprié afin que toutes les valeurs converties nouvellement obtenues soient supérieur à un, c'est-à-dire des conversions doivent être faites Riz. 3.7. Conversion de la fonction f(x) en distribution normale Une distribution asymétrique avec un sommet est réduite à une transformation normale a) réciproque b) réciproque des racines carrées La conversion « réciproque » est la plus « forte ». La position médiane entre la transformation logarithmique et la « réciproque » est occupée par la transformation « réciproque des racines carrées ». Pour normaliser une distribution décalée vers la droite par exemple, on utilise des transformations de puissance et limité ? Examinons plus en détail la méthodologie pour résoudre ce problème En pratique, la nécessité même de mesurer la plupart des quantités est due au fait qu’elles ne restent pas constantes, mais changent en fonction des changements d’autres quantités. Dans ce cas, le but de l'expérimentation est d'établir le type de dépendance fonctionnelle La définition d'une relation implique de spécifier le type de modèle et de définir ses paramètres. Dans la théorie des expériences, paramètres indépendants X=(x 1 , ..., x n) est généralement appelé facteurs, et variables dépendantes y – réponses. L'espace de coordonnées de coordonnées x 1, x 2, ..., x i, ..., x n est appelé espace des facteurs. Expérience pour déterminer le type de fonction où x est un scalaire, appelé un facteur. Expérience pour déterminer une fonction de la forme Où X=(x 1 , x 2 , ..., x i , ..., x k) – vecteur, – multifactoriel. La représentation géométrique de la fonction de réponse dans l'espace factoriel est surface de réponse. Dans une expérience à un facteur, k=1, la surface de réponse est une ligne sur un plan ; dans une expérience à deux facteurs, k=2, c'est une surface dans un espace tridimensionnel. Dans le cas général, les connexions sont assez diverses et complexes. On distingue généralement les types de connexions suivants. Connexions fonctionnelles(ou dépendances). Ce sont des connexions quand, quand une valeur change X une autre quantité Oui change de sorte que chaque valeur x i correspond à une valeur complètement définie (sans ambiguïté) y i (Fig. 4.1a). Ainsi, si nous choisissons que toutes les conditions expérimentales soient absolument identiques, alors en répétant les tests, nous obtiendrons la même dépendance, c'est-à-dire les courbes correspondront parfaitement à tous les tests. Malheureusement, de telles conditions ne se produisent pas dans la réalité. En pratique, il n'est pas possible de maintenir des conditions constantes (par exemple, fluctuations des propriétés physico-chimiques de la charge lors de la modélisation des processus de transfert de chaleur et de masse dans les fours métallurgiques). Dans ce cas, l'influence de chaque facteur aléatoire individuellement peut être faible, mais ensemble, ils peuvent affecter de manière significative les résultats de l'expérience. Dans ce cas, on parle de relation stochastique (probabiliste) entre variables. Figure 4.1. Types de connexions : a – connexion fonctionnelle, tous les points se trouvent sur la ligne ; b – la connexion est assez étroite, les points sont regroupés près de la droite de régression, mais tous ne se trouvent pas dessus ; c – connexion faible Stochasticité de la communication est-ce une variable aléatoire Oui réagit aux changements chez les autres X changer sa loi de distribution (voir Fig. 4.1b). Ainsi, la variable dépendante ne prend pas une valeur spécifique, mais une parmi plusieurs valeurs. En répétant les tests, nous obtiendrons d'autres valeurs de la fonction de réponse, et la même valeur de x dans différentes implémentations correspondra à différentes valeurs de y dans l'intervalle . La dépendance que vous recherchez Sur la figure 4.1b, cette courbe de dépendance passe par le centre de la bande de points expérimentaux (espérance mathématique), qui peuvent ne pas se trouver sur la courbe souhaitée. Lors de l'analyse des relations stochastiques, les principaux types suivants de dépendances entre variables peuvent être distingués. 1. Dépendances entre une variable aléatoire X d'une autre variable aléatoire Oui et leurs valeurs moyennes conditionnelles sont appelées corrélationnel. Moyenne conditionnelle 2. Dépendance d'une variable aléatoire Ouià partir d'une variable non aléatoire X ou la dépendance de l'espérance mathématique M y d'une variable aléatoire Oui de la valeur déterministe X appelé régression. La dépendance donnée caractérise l'influence des changements de valeur Xà la valeur moyenne Oui. Les dépendances stochastiques sont caractérisées forme, lien étroit et valeurs numériques des coefficients de l'équation de régression. Formulaire de contact définit le type de dépendance fonctionnelle où b 0 , ..., b j , ..., b k sont les coefficients de l'équation. Pour expliquer l'essence des méthodes utilisées, nous nous limiterons d'abord au cas où x est un scalaire. En général, les types de dépendances fonctionnelles en technologie sont assez divers : exponentielles Notez que la tâche de choisir le type de dépendance fonctionnelle est une tâche non formalisable, car la même courbe dans une zone donnée peut être décrite avec à peu près la même précision par diverses expressions analytiques. Cela conduit à une conclusion pratique importante. Même à l'ère des ordinateurs personnels, la décision de choisir l'un ou l'autre modèle mathématique appartient au chercheur. Seul l'expérimentateur sait à quoi servira ce modèle dans le futur et sur la base de quels concepts ses paramètres seront interprétés. Lors du traitement des résultats expérimentaux, il est hautement souhaitable d'utiliser la forme de la fonction
Figure 4.2.
Champ de corrélation






T a une distribution exponentielle de paramètre (lambda). La distribution exponentielle est souvent utilisée pour décrire les intervalles entre des événements aléatoires successifs, tels que les intervalles entre les visites d'un site Web impopulaire, car ces visites sont des événements rares.![]()




![]()





























![]()

![]()
![]()







![]() ne dépasse pas la variance de la distribution binomiale npq. Aux moments de tout ordre de la distribution hypergéométrique tendent les valeurs correspondantes des moments de la distribution binomiale.
ne dépasse pas la variance de la distribution binomiale npq. Aux moments de tout ordre de la distribution hypergéométrique tendent les valeurs correspondantes des moments de la distribution binomiale.



![]() aura une distribution de Rayleigh.
aura une distribution de Rayleigh.


![]()




















![]() a une distribution de Maxwell. Ainsi, la distribution de Maxwell peut être considérée comme la distribution de la longueur d'un vecteur aléatoire dont les coordonnées dans un système de coordonnées cartésiennes dans un espace tridimensionnel sont indépendantes et normalement distribuées avec une moyenne 0 et une variance õ 2.
a une distribution de Maxwell. Ainsi, la distribution de Maxwell peut être considérée comme la distribution de la longueur d'un vecteur aléatoire dont les coordonnées dans un système de coordonnées cartésiennes dans un espace tridimensionnel sont indépendantes et normalement distribuées avec une moyenne 0 et une variance õ 2.
![]()




![]() et mettre
et mettre





 Et
Et  , inclus dans la densité de distribution sont, respectivement, l'espérance mathématique et l'écart type de la variable aléatoire X.
, inclus dans la densité de distribution sont, respectivement, l'espérance mathématique et l'écart type de la variable aléatoire X.![]()


 .
.
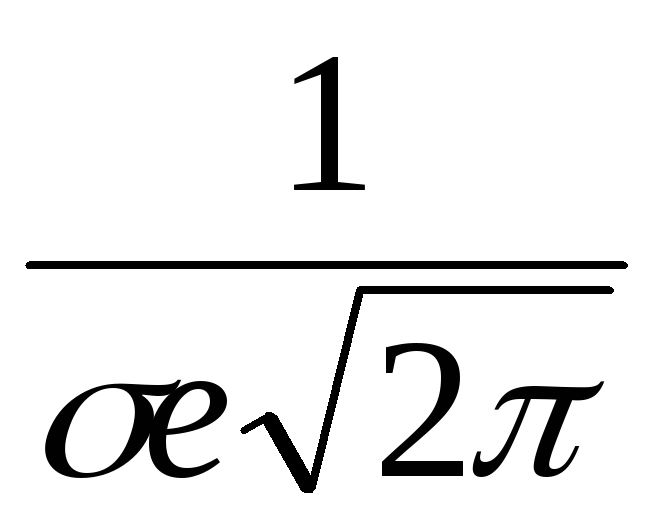 .
.



 n'est pas exprimée par des fonctions élémentaires, alors la fonction est introduite en considération
n'est pas exprimée par des fonctions élémentaires, alors la fonction est introduite en considération
![]() ,
,
![]() toujours utilisé normalisé Fonction de Laplace, qui est liée à la fonction de Laplace par la relation :
toujours utilisé normalisé Fonction de Laplace, qui est liée à la fonction de Laplace par la relation :



 Dans certains cas, d'autres transformations peuvent être appliquées :
Dans certains cas, d'autres transformations peuvent être appliquées :

 Dans ce cas, pour a les valeurs suivantes sont prises : a = 1,5 avec un déplacement modéré et a = 2 avec un décalage vers la droite fortement prononcé. Nous recommandons au lecteur de proposer des transformations qui satisferaient le chercheur dans un cas donné.
Dans ce cas, pour a les valeurs suivantes sont prises : a = 1,5 avec un déplacement modéré et a = 2 avec un décalage vers la droite fortement prononcé. Nous recommandons au lecteur de proposer des transformations qui satisferaient le chercheur dans un cas donné.4. Analyse des résultats de l'expérience passive. Dépendances empiriques
4.1. Caractéristiques des types de connexions entre séries d'observations
 =f( X). Pour ce faire, ils doivent être simultanément déterminés comme valeurs X, et leurs valeurs correspondantes
=f( X). Pour ce faire, ils doivent être simultanément déterminés comme valeurs X, et leurs valeurs correspondantes  , et l'objectif de l'expérience est d'établir un modèle mathématique de la dépendance étudiée. En fait, nous parlons d'établir communications entre deux séries d’observations (mesures).
, et l'objectif de l'expérience est d'établir un modèle mathématique de la dépendance étudiée. En fait, nous parlons d'établir communications entre deux séries d’observations (mesures). (4.1)
(4.1) =f( X), (4.1a)
=f( X), (4.1a)
 ne peut être trouvé que grâce au traitement conjoint des valeurs x et y obtenues.
ne peut être trouvé que grâce au traitement conjoint des valeurs x et y obtenues. , mais occupe une certaine bande autour de lui. Ces écarts sont causés par des erreurs de mesure, le caractère incomplet du modèle et des facteurs pris en compte, le caractère aléatoire des processus étudiés eux-mêmes et d'autres raisons.
, mais occupe une certaine bande autour de lui. Ces écarts sont causés par des erreurs de mesure, le caractère incomplet du modèle et des facteurs pris en compte, le caractère aléatoire des processus étudiés eux-mêmes et d'autres raisons. i est la moyenne arithmétique pour l'implémentation de la variable aléatoire Ouià condition que la variable aléatoire X prend la valeur
i est la moyenne arithmétique pour l'implémentation de la variable aléatoire Ouià condition que la variable aléatoire X prend la valeur  je.
je. =f( X) et se caractérise équation de régression. Si l'équation de relation est linéaire, alors nous avons une régression multivariée linéaire, dans ce cas les dépendances Oui depuis X sont décrits par l'équation d'une ligne droite dans un espace à k dimensions
=f( X) et se caractérise équation de régression. Si l'équation de relation est linéaire, alors nous avons une régression multivariée linéaire, dans ce cas les dépendances Oui depuis X sont décrits par l'équation d'une ligne droite dans un espace à k dimensions (4.2)
(4.2) , logarithmique
, logarithmique  etc.
etc. =f(X) à choisir en fonction de leurs conditions de conformité avec la nature physique des phénomènes étudiés ou des idées existantes sur les particularités du comportement de la grandeur étudiée. Malheureusement, cette possibilité n'est pas toujours disponible, puisque les expériences sont le plus souvent réalisées pour étudier des phénomènes insuffisamment ou incomplètement étudiés.
=f(X) à choisir en fonction de leurs conditions de conformité avec la nature physique des phénomènes étudiés ou des idées existantes sur les particularités du comportement de la grandeur étudiée. Malheureusement, cette possibilité n'est pas toujours disponible, puisque les expériences sont le plus souvent réalisées pour étudier des phénomènes insuffisamment ou incomplètement étudiés.
 =f( X) à partir d'un facteur avec une forme jusqu'alors inconnue de la fonction de réponse, pour déterminer approximativement le type d'équation de régression, il est utile de construire d'abord une droite de régression empirique (Fig. 4.2). Pour ce faire, toute la plage des changements de x dans le champ de corrélation est divisée en intervalles égauxx. Tous les points compris dans un intervalle donnéx j sont attribués à son milieu
=f( X) à partir d'un facteur avec une forme jusqu'alors inconnue de la fonction de réponse, pour déterminer approximativement le type d'équation de régression, il est utile de construire d'abord une droite de régression empirique (Fig. 4.2). Pour ce faire, toute la plage des changements de x dans le champ de corrélation est divisée en intervalles égauxx. Tous les points compris dans un intervalle donnéx j sont attribués à son milieu  . Pour ce faire, calculez des moyennes partielles pour chaque intervalle
. Pour ce faire, calculez des moyennes partielles pour chaque intervalle
 (4.3)
(4.3)
Ici n j est le nombre de points dans l'intervallex j, et  , où k* est le nombre d'intervalles de partition, n est la taille de l'échantillon.
, où k* est le nombre d'intervalles de partition, n est la taille de l'échantillon.
Connectez ensuite les points séquentiellement  segments droits. La ligne brisée résultante est appelée droite de régression empirique. En fonction du type de droite de régression empirique, vous pouvez, en première approximation, sélectionner le type d'équation de régression
segments droits. La ligne brisée résultante est appelée droite de régression empirique. En fonction du type de droite de régression empirique, vous pouvez, en première approximation, sélectionner le type d'équation de régression  =f( X).
=f( X).
Sous connexion étroite le degré de proximité de la dépendance stochastique par rapport à la dépendance fonctionnelle est compris, c'est-à-dire il s'agit d'un indicateur de l'étroitesse du regroupement des données expérimentales par rapport à l'équation du modèle adopté (voir Fig. 4.1b). Nous clarifierons davantage cette position.
Lois des distributions de variables aléatoires.
La plupart des logiciels obéissent à une certaine loi de distribution, sachant qu'il est possible de prédire la probabilité que le logiciel étudié tombe dans certains intervalles. Ceci est très important lors de l’analyse des indicateurs économiques, car dans ce cas, il devient possible de mettre en œuvre une politique réfléchie prenant en compte la possibilité qu'une situation particulière se présente.
Il existe de nombreuses lois sur la distribution. Certains des plus activement utilisés dans l’analyse économétrique comprennent :
Distribution normale (distribution gaussienne) ;
Répartition χ 2 ;
Répartition des étudiants ;
Répartition des pêcheurs.
Pour faciliter l'utilisation de ces lois, des tableaux de points critiques ont été élaborés qui permettent d'estimer rapidement et efficacement les probabilités correspondantes.
La distribution normale (distribution gaussienne) est un cas extrême de presque toutes les distributions de probabilité réelles. Par conséquent, il est utilisé dans un très grand nombre d’applications réelles de la théorie des probabilités.
NE X a une distribution normale si sa densité de probabilité a la forme :
 (14)
(14)
Cela équivaut à
 (15)
(15)
Un SV qui a une distribution normale est appelé normalement distribué ou normal. Des graphiques de la densité de probabilité et de la fonction de distribution de la SV normale sont présentés sur les figures 1 et 2.

0 m – σ m m + σ x
Figure 1. Diagramme de densité de probabilité de la distribution normale de SV X.

Figure 2. Fonction de distribution SV normale.
Comme le montrent les formules (1) et (2), la distribution normale dépend des paramètres m et σ et est entièrement déterminé par eux. En même temps m = M(X),
σ = σ (X), ceux. D (X) = σ 2, π = 3,14159…, e = 2,71828….
Si NE X a une distribution normale avec des paramètres M (X) = m Et
σ (Х) = σ, alors symboliquement cela peut s'écrire comme ceci :
X ~ N (m, σ) ou X ~ N (m, σ 2).
Un cas particulier très important de la distribution normale est la situation où m = 0 Et σ = 1. Dans ce cas, ils parlent de distribution normale standardisée (standard).
Le CO normal standardisé est désigné par U (U ~ N (0,1)), en tenant compte du fait que
 ;
;  (16)
(16)
Les tableaux de fonctions ont été spécialement développés pour les calculs pratiques
f(u), f(u) distribution normale standardisée, mais ce qu'on appelle Tableau des valeurs de Laplace F (
vous).
La fonction de Laplace a la forme :
 (17)
(17)
Ce tableau peut être utilisé pour n'importe quel SV normal
X (X ~ N (m, σ)) lors du calcul des probabilités correspondantes :
Notez que si X ~ N(m, σ), Que  ~N(0,1).
~N(0,1).
Comme le montrent les figures précédentes, un SV normalement distribué X se comporte de manière tout à fait prévisible. Le graphique de sa densité de probabilité (Fig. 1) est symétrique par rapport à la droite X = m. L'aire de la figure sous le graphique de densité de probabilité doit rester égale à l'unité pour toutes les valeurs m et σ. Par conséquent, plus la valeur σ , plus le graphique est raide.
De plus, les relations suivantes sont valides :
P ( X – M (X) < σ) = 0,68; Р ( Х – M (Х) < 2σ) = 0,95;
P ( X – M (X) < 3σ) = 0,9973 .
En d'autres termes, les valeurs d'un SV normalement distribué
X (X ~ N (m, σ)) 99,73% concentrés dans la région [ m – 3σ, m + 3σ ].
Le fait important est que une combinaison linéaire d'un nombre arbitraire de SV normales a une distribution normale. En même temps, si X ~ N (m x, σ x) et Y ~ N (m y, σ y)– des SV indépendants, alors
Z = aX + bY ~ N (m z , σ), (19)
Où m z = une m x + b m y ; σ z 2 = une 2 σ x 2 + b 2 σ y 2.
De nombreux indicateurs économiques ont une loi de distribution normale ou proche de la normale. Par exemple, le revenu de la population, le profit des entreprises de l'industrie, le volume de la consommation, etc. ont une distribution proche de la normale.
La distribution normale est utilisée pour tester diverses hypothèses en statistique (sur la valeur de l'espérance mathématique avec une variance connue, sur l'égalité des espérances mathématiques, etc.).
Souvent, lors de la modélisation de processus économiques, il est nécessaire de considérer les SV, qui sont une combinaison algébrique de plusieurs SV. Un certain nombre de lois de distribution théoriques spécialement développées jouent un rôle important à cet égard. Ceux-ci incluent χ 2– distribution, distributions Student et Fisher.
Distribution χ 2 (chi – carré)
Laisser Х je, je = 1, 2, …, n– SV indépendants normalement distribués avec des attentes mathématiques je suis et écarts types σ je en conséquence, c'est-à-dire Х je ~ N (m je, σ je).
Puis SV  , je = 1, 2, …, n, sont des SV indépendantes ayant une distribution normale standardisée, U je ~ N (0,1).
, je = 1, 2, …, n, sont des SV indépendantes ayant une distribution normale standardisée, U je ~ N (0,1).
NE χ 2 a une distribution du chi carré avec n degrés de liberté (χ 2 ~ χ n 2), si  (20).
(20).
Noter que nombre de degrés de liberté(ce numéro est noté v ) du SV étudié est déterminé par le nombre de SV, ses composants, diminué du nombre de connexions linéaires entre eux.
Par exemple, le nombre de degrés de liberté d'un SV, qui est une composition n variables aléatoires, qui à leur tour sont liées méquations linéaires, déterminées par le nombre v = m – n. Ainsi, U 2 ~ χ 1 2 .
De la définition (20), il s'ensuit que la distribution de χ 2 est déterminée par un paramètre - le nombre de degrés de liberté v .
Le graphique de densité de probabilité du SV, qui a une distribution χ 2, se situe uniquement dans le premier quart du système de coordonnées cartésiennes et a une apparence asymétrique avec une « queue » droite allongée (Fig. 3). Mais avec une augmentation du nombre de degrés de liberté, la distribution de χ 2 se rapproche progressivement de la normale :

Riz. 3. Graphique de densité de probabilité de SV X, qui a une distribution χ 2.
M (χ 2) = v = n – m,
D (χ 2) = 2 v = 2 (n – m).
Si X Et Oui– deux SV indépendants χ 2 – distribués avec nombre de degrés de liberté n Et k respectivement (X ~ χ n 2, Y ~ χ k 2), alors leur somme (X + Oui) est aussi χ 2– SV distribué avec plusieurs degrés de liberté v = n + k.
Distribution χ 2 utilisé pour trouver des estimations d’intervalle et tester des hypothèses statistiques. Dans ce cas, un tableau des points critiques est utilisé χ 2– les répartitions.