Méthodes de gradient basées uniquement sur le calcul du gradient R.(x), sont des méthodes du premier ordre, puisque sur l'intervalle de pas elles remplacent la fonction non linéaire R.(x) linéaire.
Méthodes du second ordre qui utilisent non seulement les dérivées premières, mais aussi les dérivées secondes de R.(x) au point actuel. Cependant, ces méthodes ont leurs propres problèmes difficiles à résoudre - le calcul des dérivées secondes en un point, et de plus, loin d'être optimal, la matrice des dérivées secondes peut être mal conditionnée.
La méthode du gradient conjugué tente de combiner les avantages des méthodes du premier et du second ordre tout en éliminant leurs inconvénients. Sur étapes initiales(loin de l’optimum) la méthode se comporte comme une méthode du premier ordre, et au voisinage de l’optimum elle se rapproche des méthodes du second ordre.
La première étape est similaire à la première étape de la méthode de descente la plus raide, la deuxième étape et les étapes suivantes sont choisies à chaque fois dans la direction formée comme une combinaison linéaire des vecteurs gradient en un point donné et de la direction précédente.
L'algorithme de la méthode peut s'écrire comme suit (sous forme vectorielle) :
x 1 = x 0 – h grade R(x 0),
x je+1 = x je – h .
La valeur α peut être trouvée approximativement à partir de l'expression
L'algorithme fonctionne comme suit. Du point de départ X 0 je cherche min R.(x) dans le sens du gradient (par la méthode de descente rapide), puis, à partir du point trouvé et plus loin, la direction de recherche min est déterminée par la deuxième expression. La recherche du minimum dans la direction peut être effectuée de n'importe quelle manière : vous pouvez utiliser la méthode de balayage séquentiel sans ajuster le pas de balayage lorsque vous dépassez le minimum, de sorte que la précision de l'obtention du minimum dans la direction dépend de la taille du pas. h.
Pour une fonction quadratique R.(x) une solution peut être trouvée dans n mesures (p– dimension du problème). Pour d'autres fonctions, la recherche sera plus lente et, dans certains cas, elle pourra ne pas atteindre du tout l'optimum en raison de forte influence erreurs de calcul.
L'une des trajectoires possibles pour rechercher le minimum d'une fonction bidimensionnelle à l'aide de la méthode du gradient conjugué est illustrée à la Fig. 1.
Algorithme de la méthode du gradient conjugué pour trouver le minimum.
Étape initiale. Exécution de la méthode du gradient.
Définir l'approximation initiale x 1 0 ,X 2 0 . Détermination de la valeur du critère R.(x 1 0 ,X 2 0). Définissez k = 0 et passez à l’étape 1 de l’étape initiale.
Étape 1.  Et
Et 
 .
.
Étape 2. Si le module dégradé 
Étape 3.
x k+1 = x k – h diplômé R.(x k)).
Étape 4. R.(x 1k +1 , X 2k +1). Si R.(x 1k +1 , X 2k +1)< R.(x 1k, X 2 k), puis définissez k = k+1 et passez à l'étape 3. Si R.(x 1k +1 , X 2 k +1) ≥ R.(x 1k, X 2 k), puis rendez-vous sur la scène principale.
Scène principale.
Étape 1. Calculer R(x 1 k + g, x 2 k), R(x 1 k – g, x 2 k), R(x 1 k , x 2 k + g), R(x 1 k , x 2 k) . Conformément à l'algorithme, à partir d'un échantillon central ou apparié, calculer la valeur des dérivées partielles  Et
Et 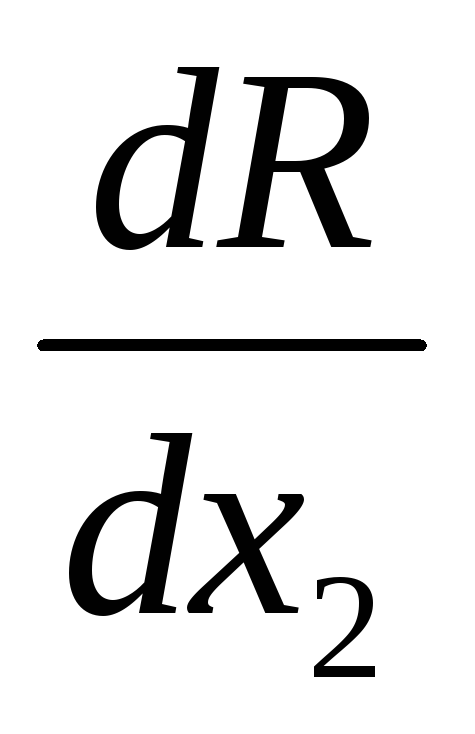 . Calculer la valeur du module de gradient
. Calculer la valeur du module de gradient  .
.
Étape 2. Si le module dégradé  , puis arrêtez le calcul et considérez le point (x 1 k, x 2 k) comme le point optimal. Sinon, passez à l'étape 3.
, puis arrêtez le calcul et considérez le point (x 1 k, x 2 k) comme le point optimal. Sinon, passez à l'étape 3.
Étape 3. Calculer le coefficient α selon la formule :

Étape 4. Effectuez l'étape de travail en calculant à l'aide de la formule
xk+1 = xk – h .
Étape 5. Déterminer la valeur du critère R.(x 1k +1 , X 2k +1). Définissez k = k+1 et passez à l’étape 1.
Exemple.
À titre de comparaison, considérons la solution de l’exemple précédent. Nous faisons le premier pas en utilisant la méthode de descente la plus raide (tableau 5).
Tableau 5
Le meilleur point a été trouvé. Nous calculons les dérivées à ce stade : RD/ dx 1 = –2.908; RD/ dx 2 =1,600 ; On calcule le coefficient α, qui prend en compte l'influence du gradient au point précédent : α = 3,31920 ∙ 3,3192/8,3104 2 =0,160. On fait une étape de travail conformément à l'algorithme de la méthode, on obtient X 1 = 0,502, X 2 = 1.368. Ensuite, tout se répète de la même manière. Ci-dessous, dans le tableau. 6 montre les coordonnées de recherche actuelles pour les prochaines étapes.
Tableau 6
Le terme « méthode du gradient conjugué » est un exemple de la façon dont des expressions dénuées de sens, devenues familières, sont considérées comme allant de soi et ne provoquent aucune confusion. Le fait est que, sauf cas particulier sans intérêt pratique, les gradients ne sont pas conjugués, et les directions conjuguées n'ont rien à voir avec les gradients. Le nom de la méthode reflète le fait que cette méthode trouver un extremum inconditionnel combine les concepts de gradient fonction objectif et les orientations associées.
Quelques mots sur la notation utilisée ci-dessous.
Le produit scalaire de deux vecteurs s'écrit $x^Ty$ et représente la somme des scalaires : $\sum_(i=1)^n\, x_i\,y_i$. Notez que $x^Ty = y^Tx$. Si x et y sont orthogonaux, alors $x^Ty = 0$. En général, les expressions qui se transforment en matrice 1x1, telles que $x^Ty$ et $x^TA_x$, sont traitées comme des scalaires.
La méthode du gradient conjugué a été initialement développée pour résoudre des systèmes de équations algébriques taper:
où x n'est pas vecteur célèbre, b est un vecteur connu et A est une matrice connue, carrée, symétrique et définie positive. Résoudre ce système équivaut à trouver le minimum de la forme quadratique correspondante.
La forme quadratique est simplement une fonction scalaire et quadratique d'un vecteur x de la forme suivante :
$f\,(x) = (\frac(1)(2))\,x^TA_x\,-\,b^Tx\,+\,c$, (2)
La présence d'une telle connexion entre la matrice transformation linéaire Un et fonction scalaire f(x) permet d'illustrer certaines formules algèbre linéaire dessins intuitifs. Par exemple, une matrice A est dite définie positive si pour tout vecteur x non nul ce qui suit est vrai :
$x^TA_x\,>\,0$, (3)
La figure 1 montre à quoi ils ressemblent formes quadratiques respectivement pour une matrice définie positive (a), une matrice définie négative (b), une matrice définie positive (c), une matrice indéfinie (d).
Autrement dit, si la matrice A est définie positive, alors au lieu de résoudre le système d'équations 1, vous pouvez trouver le minimum de sa fonction quadratique. De plus, la méthode du gradient conjugué le fera en n étapes ou moins, où n est la dimension du vecteur inconnu x. Puisque tout fonction fluide au voisinage de son point minimum est bien approximé par une quadratique, la même méthode peut être utilisée pour minimiser et non fonctions quadratiques. Dans ce cas, la méthode cesse d’être finie, mais devient itérative.
Il est conseillé de commencer à considérer la méthode du gradient conjugué en considérant davantage méthode simple rechercher l'extremum d'une fonction - la méthode de descente la plus raide. La figure 2 montre la trajectoire de mouvement jusqu'au point minimum en utilisant la méthode de descente la plus raide. L'essence de cette méthode :
- au point initial x(0), le gradient est calculé, et le mouvement s'effectue dans le sens de l'antigradient jusqu'à ce que la fonction objectif diminue ;
- au point où la fonction cesse de décroître, la pente est à nouveau calculée et la descente continue dans une nouvelle direction ;
- le processus est répété jusqu'à ce que le point minimum soit atteint.

DANS dans ce cas chaque nouvelle direction de mouvement est orthogonale à la précédente. N'existe-t-il pas une manière plus intelligente de choisir une nouvelle direction ? Il existe, et cela s’appelle la méthode des directions conjuguées. Et la méthode du gradient conjugué appartient simplement au groupe des méthodes de direction conjuguée. La figure 3 montre la trajectoire du mouvement jusqu'au point minimum en utilisant la méthode du gradient conjugué.

La définition de la conjugaison est formulée ainsi : deux vecteurs x et y sont appelés A-conjugué (ou conjugué par rapport à la matrice A) ou A-orthogonal si produit scalaire x et Ay sont égaux à zéro, soit :
$x^TA_y\,=\,0$, (4)
La conjugaison peut être considérée comme une généralisation du concept d'orthogonalité. En effet, lorsque la matrice A est la matrice identité, conformément à l'égalité 4, les vecteurs x et y sont orthogonaux. Il existe une autre façon de démontrer la relation entre les concepts d'orthogonalité et de conjugaison : étirer mentalement la figure 3 de sorte que les lignes de niveau égal issues des ellipses se transforment en cercles et que les directions conjuguées deviennent simplement orthogonales.
Reste à savoir comment calculer les directions conjuguées. L'un des moyens possibles– utiliser des méthodes d'algèbre linéaire, en particulier le processus d'orthogonalisation de Gram – Schmidt. Mais pour cela, vous devez connaître la matrice A, donc pour la plupart des tâches (par exemple, la formation de réseaux neuronaux multicouches), cette méthode ne convient pas. Heureusement, il existe d'autres méthodes itératives pour calculer la direction conjuguée, la plus célèbre étant la formule de Fletcher-Reeves :
$d_((i+1)) = d_((i+1))\,+\,\beta_((i+1))\,d_i$ , (5)
$\beta_((i+1)) = \frac(r_((i+1))^T)(r_(i)^T)\,\frac(r_((i+1)))(r_( (i)))$, (6)
La formule 5 signifie que la nouvelle direction conjuguée est obtenue en ajoutant l'antigradient au point de retournement et la direction de mouvement précédente, multipliées par le coefficient calculé par la formule 6. Les directions calculées par la formule 5 s'avèrent conjuguées si la fonction minimisée est donné sous la forme 2. C'est-à-dire pour quadratique La méthode du gradient conjugué trouve des fonctions en au moins n étapes (n est la dimension de l'espace de recherche). Pour les fonctions vue générale l'algorithme cesse d'être fini et devient itératif. Parallèlement, Fletcher et Reeves proposent de reprendre la procédure algorithmique toutes les n+1 étapes.
Vous pouvez donner une autre formule pour déterminer la direction conjuguée, la formule de Polak-Ribiere :
$\beta_((i+1)) = \frac(r_((i+1))^T\,(r_((i+1))\,-\,r_((i))))(r_ (i)^T\,r_((i)))$, (7)
La méthode Fletcher-Reeves converge si point de départ est assez proche du minimum requis, alors que la méthode Polak-Reiber peut, dans de rares cas, boucler indéfiniment. Cependant, cette dernière converge souvent plus rapide que le premier méthode. Heureusement, la convergence de la méthode Polak-Reiber peut être garantie en choisissant $\beta = \max \(\beta;\,0\)$. Cela équivaut à redémarrer l'algorithme sous la condition $\beta \leq 0$. Un redémarrage de la procédure algorithmique est nécessaire pour oublier le dernier sens de recherche et relancer l'algorithme dans le sens de la descente la plus raide.
- L'antigradient est calculé en point arbitraire x(0) .
$d_((0)) = r_((0)) = -\,f"(x_((0)))$
- Il descend dans la direction calculée tandis que la fonction décroît, autrement dit en recherchant un (i) qui minimise
$f\,(x_((i))\,+\,a_((i))\,d_((i)))$
- Allez au point trouvé dans le paragraphe précédent
$x_((i+1)) = x_((i))\,+\,a_((i))\,d_((i))$
- Calcul de l'antigradient à ce stade
$r_((i+1)) = -\,f"(x_((i+1)))$
- Calculs utilisant la formule 6 ou 7. Pour redémarrer l'algorithme, c'est-à-dire oublier le dernier sens de recherche et relancer l'algorithme dans le sens de la descente la plus raide, pour la formule de Fletcher-Reeves 0 est attribué tous les n + 1 pas, pour le Polak -Formule Reiber - $\beta_ ((i+1)) = \max \(\beta_((i+1)),\,0\)$
- Calculer la nouvelle direction conjuguée
$d_((i+1)) = r_((i+1))\,+\,\beta_((i+1))\,d_((i))$
- Allez au point 2.
De l'algorithme ci-dessus, il s'ensuit qu'à l'étape 2, une minimisation unidimensionnelle de la fonction est effectuée. Pour ce faire, vous pouvez notamment utiliser la méthode de Fibonacci, la méthode du nombre d'or ou encore la méthode de la bissection. La méthode de Newton – Raphson permet une convergence plus rapide, mais pour cela il faut pouvoir calculer la matrice de Hesse. DANS ce dernier cas, la variable utilisée pour l'optimisation est calculée à chaque étape d'itération à l'aide de la formule :
$$a = -\,\frac((f")^T\,(x)\,d)(d^T\,f""(x)\,d)$$
$f""(x)\,= \begin(pmatrix) \frac(\partial^2\,f)(\partial x_1\,\partial x_1)&\frac(\partial^2\,f)(\ partiel x_1\,\partial x_2)&\cdots&\frac(\partial^2\,f)(\partial x_1\,\partial x_n)& \\ \frac(\partial^2\,f)(\partial x_2 \,\partial x_1)&\frac(\partial^2\,f)(\partial x_2\,\partial x_2)& \cdots&\frac(\partial^2\,f)(\partial x_2\,\partial x_n)& \\ \vdots&\vdots&\ddots&\vdots &\\ \frac(\partial^2\,f)(\partial x_n\,\partial x_1)& \frac(\partial^2\,f)( \partial x_n\,\partial x_2)&\cdots&\frac(\partial^2\,f)(\partial x_n\,\partial x_n) \end(pmatrix)$
Matrice de Hesse
Quelques mots sur l'utilisation de la méthode des directions conjuguées dans l'enseignement réseaux de neurones. Dans ce cas, l'apprentissage basé sur l'époque est utilisé, c'est-à-dire que lors du calcul de la fonction objectif, tous les modèles de l'ensemble d'apprentissage sont présentés et le carré moyen de la fonction d'erreur (ou une modification de celle-ci) est calculé. Il en va de même lors du calcul du gradient, c'est-à-dire que le gradient total sur l'ensemble de l'ensemble d'entraînement est utilisé. Le dégradé pour chaque exemple est calculé à l'aide de l'algorithme rétropropagation(RetourProp).
En conclusion, nous présentons l’un des algorithmes possibles pour l’implémentation logicielle de la méthode du gradient conjugué. Dans ce cas, la conjugaison est calculée à l'aide de la formule de Fletcher-Reeves et pour l'optimisation unidimensionnelle, l'une des méthodes ci-dessus est utilisée. Selon certains experts faisant autorité, la vitesse de convergence de l'algorithme dépend peu de la formule d'optimisation utilisée à l'étape 2 de l'algorithme ci-dessus, nous pouvons donc recommander, par exemple, la méthode du nombre d'or, qui ne nécessite pas de calcul de dérivées.
Une variante de la méthode des directions conjuguées qui utilise la formule de Fletcher-Reeves pour calculer les directions conjuguées.
r:= -f"(x) // antigradient de la fonction objectif
d:= r // direction de départ la descente coïncide avec l'antigradient
Sigma new : = r T * r // carré du module antigradient
Sigma 0 : = Sigma nouveau
// Boucle de recherche (sortie sur compteur ou erreur)
pendant que je< i max and Sigma new >Eps 2 * Sigma 0
commencer
j:=0
Sigma d : = d T * d
// Cycle de minimisation unidimensionnel (descente dans la direction d)
répéter
une: =
x : = x + une
j: = j + 1
jusqu'à (j >= j max) ou (a 2 * Sigma d<= Eps 2)
R: = -f"(x) // antigradient de la fonction objectif au nouveau point
Sigma ancien : = Sigma nouveau
Sigma nouveau : = r T * r
bêta : = Sigma nouveau / Sigma ancien
d: = r + bêta * d // Calculer la direction conjuguée
k : = k + 1
Si (k = n) ou (r T * d<= 0) then // Рестарт алгоритма
commencer
d:=r
k:=0
fin
Je : = je + 1
fin
La méthode du gradient conjugué est une méthode du premier ordre, et en même temps son taux de convergence est quadratique. Cela se compare avantageusement aux méthodes de gradient conventionnelles. Par exemple, la méthode de descente la plus raide et la méthode de descente de coordonnées pour une fonction quadratique ne convergent que dans la limite, tandis que la méthode du gradient conjugué optimise la fonction quadratique dans un nombre fini d'itérations. Lors de l'optimisation des fonctions générales, la méthode de la direction conjuguée converge 4 à 5 fois plus vite que la méthode de descente la plus raide. Dans ce cas, contrairement aux méthodes du second ordre, les calculs fastidieux des dérivées partielles secondes ne sont pas nécessaires.
Littérature
- N.N.Moiseev, Yu.P.Ivanilov, E.M.Stolyarova "Méthodes d'optimisation", M. Nauka, 1978
- A. Fiacco, G. McCormick "Programmation non linéaire", M. Mir, 1972
- W.I. Zangwill "Programmation non linéaire", M. Radio soviétique, 1973
- Jonathan Richard Shewchuk "Méthodes de gradients de second ordre", School of Computer Science Carnegie Mellon University Pittsburg, 1994
Les méthodes de gradient discutées ci-dessus ne trouvent le point minimum d'une fonction dans le cas général que dans un nombre infini d'itérations. La méthode du gradient conjugué génère des directions de recherche plus cohérentes avec la géométrie de la fonction minimisée. Cela augmente considérablement la vitesse de leur convergence et permet, par exemple, de minimiser la fonction quadratique
f(x) = (x, Hx) + (b, x) + une
avec une matrice définie positive symétrique H en un nombre fini d'étapes n, égal au nombre de variables de la fonction. Toute fonction lisse située à proximité du point minimum peut être bien approchée par une fonction quadratique, c'est pourquoi les méthodes de gradient conjugué sont utilisées avec succès pour minimiser les fonctions non quadratiques. Dans ce cas, ils cessent d’être finis et deviennent itératifs.
Par définition, deux vecteurs à n dimensions x et y sont appelés conjugués à la matrice H (ou H-conjugué) si le produit scalaire (x, H) = 0. Ici H est une matrice définie positive symétrique de taille nxn.
L’un des problèmes les plus importants des méthodes de gradient conjugué est celui de la construction efficace de directions. La méthode Fletcher-Reeves résout ce problème en transformant à chaque étape l'antigradient -f(x[k]) dans la direction p[k], H-conjugué aux directions p, p, ..., p trouvées précédemment. Considérons d'abord cette méthode en relation avec le problème de la minimisation d'une fonction quadratique.
Les directions p[k] sont calculées à l'aide des formules :
p[k] = -f’(x[k])+k-1p, k >= 1; p = -f'(x).
Les valeurs de k-1 sont choisies pour que les directions p[k], p soient H-conjuguées :
(p[k], Hp)= 0.
En conséquence, pour la fonction quadratique
le processus itératif de minimisation a la forme
x =x[k] +akp[k],
où p[k] est la direction de descente au kième pas ; ak est la taille du pas. Ce dernier est choisi à partir de la condition du minimum de la fonction f(x) dans a dans la direction du mouvement, c'est-à-dire à la suite de la résolution du problème de minimisation unidimensionnel :
f(х[k] + акр[k]) = f(x[k] + ар [k]).
Pour une fonction quadratique
L'algorithme de la méthode du gradient conjugué de Fletcher-Reeves est le suivant.
1. Au point x, p = -f’(x) est calculé.
2. A la kième étape, l'étape ak est déterminée à l'aide des formules ci-dessus. et le point x.
3. Les valeurs f(x) et f’(x) sont calculées.
4. Si f’(x) = 0, alors le point x est le point minimum de la fonction f(x). Sinon, la nouvelle direction p est déterminée à partir de la relation
et le passage à l'itération suivante est effectué. Cette procédure trouvera le minimum d’une fonction quadratique en n étapes maximum. Lors de la minimisation de fonctions non quadratiques, la méthode Fletcher-Reeves devient itérative à partir de finie. Dans ce cas, après la (n+1)ième itération, les procédures 1 à 4 sont répétées cycliquement avec x remplacé par x[n+1], et les calculs se terminent à , où est un nombre donné. Dans ce cas, la modification suivante de la méthode est utilisée :
x = x[k] +akp[k],
p[k] = -f’(x[k])+k-1p, k >= 1;
f(x[k] + akp[k]) = f(x[k] + ap[k];
Ici I est un ensemble d'indices : I = (0, n, 2n, 3n, ...), c'est à dire que la méthode est mise à jour toutes les n étapes.
La signification géométrique de la méthode du gradient conjugué est la suivante (Fig. 1.19). A partir d'un point de départ donné x, la descente s'effectue dans la direction p = -f"(x). Au point x, le vecteur gradient f"(x) est déterminé. Puisque x est le point minimum de la fonction dans la direction de p, alors f’(x) est orthogonal au vecteur p. Ensuite, le vecteur p est trouvé, H-conjugué à p. Ensuite, le minimum de la fonction se trouve le long de la direction p, etc.
Riz. 1.19. Trajectoire de descente dans la méthode du gradient conjugué
Les méthodes de direction conjuguée sont parmi les plus efficaces pour résoudre les problèmes de minimisation. Il convient cependant de noter qu’ils sont sensibles aux erreurs qui surviennent lors du processus de comptage. Avec un grand nombre de variables, l'erreur peut tellement augmenter que le processus devra être répété même pour une fonction quadratique, c'est-à-dire que le processus correspondant ne s'inscrit pas toujours en n étapes.
Méthodes numériques d'optimisation sans contrainte du second ordre, variantes des algorithmes de la méthode de Newton
Caractéristiques des méthodes du second ordre. Les méthodes d'optimisation sans contrainte du second ordre utilisent les dérivées partielles secondes de la fonction minimisée f(x). L'essence de ces méthodes est la suivante.
Une condition nécessaire pour l'extremum d'une fonction de plusieurs variables f(x) au point x* est que son gradient en ce point soit égal à zéro :
Le développement de f'(x) au voisinage du point x[k] en une série de Taylor, jusqu'aux termes du premier ordre, permet de réécrire l'équation précédente sous la forme
f"(x) f’(x[k]) + f"(x[k]) (x - x[k]) 0.
Ici f"(x[k]) Н(х[k]) est la matrice des dérivées secondes (matrice hessienne) de la fonction minimisée. Par conséquent, le processus itératif de construction d'approximations successives pour résoudre le problème de minimisation de la fonction f (x) est décrit par l’expression
x x[k] - H-1(x[k]) f’(x[k]) ,
où H-1(x[k]) est la matrice inverse de la matrice de Hesse, et H-1(x[k])f'(x[k]) р[k] est la direction de descente.
La méthode de minimisation qui en résulte est appelée méthode de Newton. Il est évident que dans cette méthode, la taille du pas dans la direction p[k] est supposée égale à l’unité. La séquence de points (x[k]), obtenue à la suite de l'application du processus itératif, converge sous certaines hypothèses vers un point stationnaire x* de la fonction f(x). Si la matrice hessienne H(x*) est définie positive, le point x* sera un point de strict minimum local de la fonction f(x). La séquence x[k] converge vers le point x* seulement si la matrice hessienne de la fonction objectif est définie positive à chaque itération.
Si la fonction f(x) est quadratique, alors, quelle que soit l'approximation initiale x et le degré de ravin, en utilisant la méthode de Newton, son minimum est trouvé en une seule étape. Cela s'explique par le fait que la direction de descente р[k] H-1(x[k])f'(x[k]) en tout point x coïncide toujours avec la direction vers le point minimum x*. Si la fonction f(x) n’est pas quadratique, mais convexe, la méthode de Newton garantit sa décroissance monotone d’itération en itération. Lors de la minimisation des fonctions de ravin, le taux de convergence de la méthode de Newton est plus élevé que celui des méthodes de gradient. Dans ce cas, le vecteur p[k] n'indique pas la direction vers le point minimum de la fonction f(x), cependant, il a une grande composante le long de l'axe du ravin et est beaucoup plus proche de la direction vers le minimum que le antigradient.
Un inconvénient important de la méthode de Newton est la dépendance de la convergence des fonctions non convexes à l'approximation initiale x. Si x est suffisamment éloigné du point minimum, alors la méthode peut diverger, c'est-à-dire qu'au cours de l'itération, chaque point suivant sera plus éloigné du point minimum que le précédent. La convergence de la méthode, quelle que soit l'approximation initiale, est assurée en choisissant non seulement la direction de descente p[k] H-1(x[k])f'(x[k]), mais également la taille du pas a dans cette direction. L'algorithme correspondant est appelé méthode de Newton avec contrôle par étapes. Le processus itératif dans ce cas est déterminé par l'expression
x x[k] - akH-1(x[k])f’(x[k]).
La taille du pas ak est sélectionnée à partir de la condition du minimum de la fonction f(x) dans a dans la direction du mouvement, c'est-à-dire à la suite de la résolution du problème de minimisation unidimensionnel :
f(x[k] – ak H-1(x[k])f'(x[k]) (f(x[k] - aH-1(x[k])f'(x[k]) ).
Cette version de l’algorithme est également appelée méthode de Newton-Raphson. Une interprétation graphique de cette version de la méthode de Newton est présentée dans la Fig. 1.20. Les éléments de légende de la figure montrent des graphiques de fonctions unidimensionnelles qui sont sujettes à optimisation afin de déterminer l'étape.
Riz. 1.20. Interprétation géométrique de la méthode Newton-Raphson
L'algorithme de la méthode Newton-Raphson est le suivant. Certaines actions sont effectuées avant le début du processus d'itération. À savoir, il est nécessaire d'obtenir un vecteur de formules qui composent le gradient f'([x]) (c'est-à-dire un vecteur de dérivées partielles premières) et une matrice de formules qui composent la matrice de Hesse H(x) (c'est-à-dire , une matrice de dérivées partielles secondes). Ensuite, dans la boucle itérative, les valeurs des composantes du vecteur x sont substituées dans ces formules et ces tableaux deviennent des tableaux de nombres.
1. Au point de départ x, un vecteur est calculé qui détermine la direction de descente p - H-1(x)f’(). Ainsi, le problème multidimensionnel est réduit à un problème d’optimisation unidimensionnel.
2. À la kième itération, l'étape ak est déterminée (selon le schéma illustré sur la Fig. 1.20 ; à cet effet, un problème d'optimisation unidimensionnelle est résolu) et le point x.
3. La valeur f(x) est calculée.
4. Les conditions de sortie du sous-programme qui implémente cet algorithme sont vérifiées. Ces conditions sont similaires aux conditions de sortie d'un sous-programme par la méthode de descente la plus raide. Si ces conditions sont remplies, les calculs sont terminés. Sinon, une nouvelle direction est calculée
ð –H-1(x[k])f’([k])
et le passage à l'itération suivante est effectué, c'est-à-dire à l'étape 2.
Le nombre de calculs par itération par la méthode de Newton est, en règle générale, beaucoup plus important que dans les méthodes de gradient. Cela s'explique par la nécessité de calculer et d'inverser la matrice des dérivées secondes de la fonction objectif (ou de résoudre un système d'équations, ce qui demande moins de travail). Cependant, l'obtention d'une solution avec un degré de précision suffisamment élevé à l'aide de la méthode de Newton nécessite généralement beaucoup moins d'itérations qu'à l'aide des méthodes de gradient. De ce fait, la méthode de Newton est nettement plus efficace. Il a un taux de convergence superlinéaire ou quadratique selon les exigences satisfaites par la fonction f(x) minimisée. Cependant, dans certains problèmes, la complexité de l'itération à l'aide de la méthode de Newton peut être très importante en raison de la nécessité de calculer la matrice des dérivées secondes de la fonction minimisée, ce qui nécessitera un temps de calcul important.
Dans certains cas, il est conseillé de combiner les méthodes du gradient et la méthode de Newton. Au début du processus de minimisation, lorsque le point x est éloigné du point extremum x*, certaines variantes des méthodes de gradient peuvent être utilisées. Ensuite, lorsque le taux de convergence de la méthode du gradient diminue, vous pouvez passer à la méthode de Newton. Ou, en raison de l'accumulation d'erreurs au cours du processus de calcul, la matrice de Hesse à certaines itérations peut s'avérer négative ou ne peut pas être inversée. Dans de tels cas, les routines d'optimisation s'appuient sur H-1(x[k]) E, où E est la matrice d'identité. L'itération s'effectue selon la méthode de descente la plus raide.
Dans une autre modification de la méthode de Newton, appelée méthode de Levenberg-Marquardt (méthode de Newton avec ajustement matriciel), la régularisation de cette matrice est utilisée pour assurer la définition positive de la matrice hessienne aux points de la séquence. Dans la méthode de Levenberg-Marquardt, les points sont construits selon la loi : , où est une séquence de nombres positifs qui assurent la définition positive de la matrice. Habituellement, la valeur est prise comme un ordre de grandeur supérieur au plus grand élément de la matrice. C'est le cas dans un certain nombre de programmes standards. Si, alors , sinon Il est évident que si , alors la méthode de Levenberg-Marquardt est la méthode de Newton, et si est grand, alors puisque pour les grands, la méthode de Levenberg-Marquardt est proche de la méthode du gradient. Ainsi, en sélectionnant les valeurs du paramètre, il est possible de s'assurer que la méthode de Levenberg-Marquardt converge
Les sous-sections précédentes traitaient des méthodes de Cauchy et de Newton. Il a été noté que la méthode de Cauchy est efficace lors de la recherche à des distances significatives du point minimum X* et « fonctionne » mal au voisinage de ce point, alors que la méthode de Newton n’est pas très fiable lors de la recherche X*à distance, cependant, il s'avère très efficace dans les cas où x(k) est proche du point minimum. Cette sous-section et les suivantes traitent des méthodes qui ont les propriétés positives des méthodes de Cauchy et de Newton et sont basées sur le calcul des valeurs des dérivées premières uniquement. Ainsi, ces méthodes, d’une part, sont très fiables lors de la recherche X* depuis un endroit éloigné X* et, d'autre part, convergent rapidement au voisinage du point minimum.
Méthodes qui permettent d'obtenir des solutions à des problèmes avec des fonctions objectives quadratiques en approximativement Nétapes, sous réserve de l'utilisation de fractions non décimales, nous appellerons quadratiquement convergente. Parmi ces méthodes, nous pouvons distinguer une classe d'algorithmes basés sur la construction directions conjuguées. Ci-dessus, la condition de conjugaison du système de directions a été formulée s k) , k = 1, 2, 3,…, r ≤ N, et matrice symétrique AVEC commande N N. Un lien a également été établi entre la construction des directions indiquées et la transformation d'une fonction quadratique arbitraire sous la forme de la somme des valeurs totales.
1) Des problèmes de ce type surviennent, par exemple, dans l'analyse de régression - Note traduction
carrés; il a été conclu qu'une recherche séquentielle le long de chacun des N directions ayant la propriété AVEC-conjugaison, permet de trouver le point minimum de la fonction quadratique N variables. La procédure permettant de déterminer un système de directions conjuguées en utilisant uniquement les valeurs de la fonction objectif est considérée. Ci-dessous, une approximation quadratique est utilisée pour obtenir des directions conjuguées f(x) et les valeurs des composantes du gradient. De plus, nous exigerons que les méthodes considérées garantissent que la fonction objectif diminue lors du passage d'itération en itération.
Soit deux points divergents arbitraires dans l'espace des variables contrôlées x(0) et x(1) . Le gradient de la fonction quadratique est
f(x) = q(x) =Cx + b = g(x) (3.60)
La notation g(x) est introduite ici pour faciliter l'écriture de la formule. Ainsi,
g(x (0)) = Cx (0) + b,
g(x (1)) = Cx (1) + b.
Écrivons le changement de pente lors du déplacement d'un point X(0) pour pointer X (1) :
g(x) = g(x (1)) -g(x (0)) = C(x (1) - x (0)), (3.61)
g(x) = C x
L'égalité (3.61) exprime une propriété des fonctions quadratiques qui sera utilisée ci-dessous.
En 1952, Estens et Stiefel ont proposé un algorithme itératif efficace pour résoudre des systèmes d'équations linéaires, qui était essentiellement la méthode du gradient conjugué. Ils ont considéré les membres gauches des équations linéaires comme des composantes du gradient d'une fonction quadratique et ont résolu le problème de la minimisation de cette fonction. Plus tard, Fletcher et Reeves ont justifié la convergence quadratique de la méthode et l'ont généralisée au cas des fonctions non quadratiques. Fried et Metzler ont démontré (avec quelques imprécisions cependant) la possibilité d'utiliser la méthode de résolution de systèmes linéaires avec une matrice creuse de coefficients. (Voir l'Annexe A pour la définition d'une matrice clairsemée.) Ils ont souligné la facilité de mise en œuvre de la méthode par rapport à d'autres algorithmes plus généraux, ce qui est une caractéristique particulièrement importante du point de vue de notre présentation.
Nous considérerons la méthode sous l'hypothèse que la fonction objectif est quadratique :
f(x) = q(x) = a + b T x + ½ x TCx,
les itérations sont effectuées selon la formule (3.42), c'est-à-dire
x = x +α s(x).
Les directions de recherche à chaque itération sont déterminées à l'aide des formules suivantes :
s(k) = -g(k) + (3,62)
s (0) = –g (0) , (3.63)
Où g(k) = f(x). Puisqu'après avoir déterminé le système de directions, une recherche séquentielle est effectuée le long de chacune des directions, il est utile de rappeler que la condition est généralement utilisée comme critère pour mettre fin à une recherche unidimensionnelle.
f (x)Ts(k) = 0 (3,64)
Valeurs ,je= 1, 2, 3,...,k-1, sont choisis de telle manière que la direction s(k) était AVEC-connecté à toutes les directions de recherche précédemment construites. Considérons la première direction
s (1) = –g(1) + y (0) s (0) = –g(1) –γ (0) g (0)
et impose la condition de sa conjugaison avec s (0)
s (1)T C s(0) = 0,
où TC s(0) = 0.
Lors de l'itération initiale
s (0) = ;
ainsi,
TC = 0
En utilisant la propriété des fonctions quadratiques (3.61), on obtient
T g = 0, (3.65)
γ (0) = – ( gT g (1))/( gT g(0)). (3,66)
De l’équation (3.65), il résulte que
g (1) T g (1) + y (0) g (0) T g (1) – g (1) T g(0) – y (0) g (0) T g(0) = 0.
Avec un choix approprié de α (0) et compte tenu de la formule (3.64), on a
g (1) T g(0) = 0.
Ainsi,
s (2) = –g(2) + y (0) s(0) + y (1) s (1) .
et choisissons γ (0) γ (1) pour que les conditions soient satisfaites
art(2) TC s(0) = 0 et s(2) C s(1) = 0,
c'est-à-dire les conditions AVEC-conjugaison de la direction s (2) avec les directions s (0) et s (1). A l'aide des formules (3.61) et (3.64), on peut montrer (ceci est laissé en exercice au lecteur) qu'ici γ (0) = 0, et dans le cas général γ ( je) = 0, je = 0, 1, 2,...,k-2,à n'importe quelle valeur k. Il s'ensuit que la formule générale des directions de recherche peut être écrite sous la forme proposée par Fletcher et Reeves :
s ( k) = –g (k) + s (3,68)
Si f(x)- fonction quadratique, pour trouver le point minimum à déterminer N-1 de ces instructions et exécuter N recherche le long d'une ligne droite (en l'absence d'erreurs d'arrondi). Si la fonction f(x) n'est pas quadratique, le nombre de directions et de recherches correspondantes augmente.
Certains chercheurs, sur la base de l'expérience acquise dans la réalisation d'expériences informatiques, suggèrent qu'après la mise en œuvre de chaque série de N ou N+ 1 étapes reviennent à l'itération initiale de l'algorithme, mettant s(x) = -g(x). Cette proposition reste un sujet d'étude, car minimiser des fonctions de forme générale entraîne dans certains cas un ralentissement de la convergence. D'autre part, les transitions cycliques vers l'itération initiale augmentent la fiabilité de l'algorithme, puisque la probabilité de construire des directions linéairement dépendantes diminue. Si la direction résultante s'avère être une combinaison linéaire d'une ou plusieurs directions obtenues précédemment, alors la méthode peut ne pas conduire à une solution, car la recherche dans le sous-espace correspondant R N a déjà été réalisé. Il convient toutefois de noter qu’en pratique, de telles situations sont assez rares. La méthode s'avère très efficace pour résoudre des problèmes pratiques ; elle se caractérise par la simplicité d'un schéma de calcul à un paramètre et une petite quantité de mémoire informatique requise pour la recherche. Le niveau relativement faible d'exigences en mémoire informatique rend la méthode Fletcher-Reeves (FR) et ses modifications particulièrement utiles pour résoudre des problèmes à grande échelle.
Exemple 3.9. Méthode Fletcher-Reeves
Trouver le point minimum d'une fonction
f(x) = 4x+ 3x – 4xx + x
Si X = T.
Étape 1. f(x) =T,
s (0) = – f(x (0)) = – T.
Étape 2.Recherchez en ligne droite :
x = x –α f(x (0)) → α = ⅛,
X =T- ⅛ T = [– ⅛, 0]T
Étape 3. k = 1.
s (1) = – T-[¼, 1] T = [– ¼, ½] T.
Étape 4. Recherchez le long d'une ligne droite :
x = x+ α s(1) → α = ¼,
X =[– ⅛, 0]T- ¼ [¼, ½] T = [– , ]T,
f(x (2)) = T.
Ainsi, x = x*. La solution a été obtenue à la suite de deux recherches unidimensionnelles, puisque la fonction objectif est quadratique et qu'il n'y a pas d'erreurs d'arrondi.
Mil et Cantrell ont généralisé l'approche de Fletcher et Reeves en proposant la formule
x = x +α {– f(x (k)) + γ s(x)} (3.69)
où α et γ - des paramètres dont les valeurs sont déterminées à chaque itération. Cette méthode, connue sous le nom méthode de gradient avec mémoire,est très efficace en termes de nombre d'itérations nécessaires pour résoudre le problème, mais nécessite plus de calculs de valeurs de fonction et de composantes de gradient que la méthode Fletcher-Reeves. Par conséquent, l'algorithme de Mil et Cantrell n'est utile que dans les cas où l'estimation des valeurs de la fonction objectif et des composantes du gradient n'est associée à aucune difficulté.
Rappelons que la considération de la méthode Fletcher-Reeves a été réalisée en supposant que la fonction objectif était quadratique et qu'il n'y avait pas d'erreurs d'arrondi lors de la recherche le long de la ligne. Cependant, lors de la mise en œuvre de plusieurs méthodes, des directions conjuguées sont déterminées sans prendre en compte l'une de ces hypothèses (voire les deux). Parmi ces méthodes, celle qui mérite probablement le plus d'attention est celle développée par Polzk et Ribière en 1969. La méthode repose sur une procédure de recherche exacte le long d'une ligne et sur une hypothèse plus générale d'approximation de la fonction objectif. En même temps
γ
=  , (3.70)
, (3.70)
où, comme auparavant,
g(x)= g(x) -g(x). (3.71)
Si α - un paramètre dont la valeur est déterminée à la suite d'une recherche le long d'une ligne droite, et γ est un paramètre dont la valeur est calculée à l'aide de la formule (3.70), alors Méthode du gradient conjugué Polak-Ribiera est implémenté en utilisant les relations suivantes :
x = x +α s(x),
s(x) = – f (x) + γ s(x). (3.72)
Il est facile de voir que la seule différence entre les méthodes de Polak-Ribier et de Fletcher-Reeves réside dans les méthodes de choix du paramètre γ.
D'autres méthodes similaires sont également connues, qui reposent également sur la réalisation de calculs exacts lors d'une recherche unidimensionnelle et sur une approximation plus générale (que quadratique) de la fonction objectif (voir par exemple). Crowder et Wolf en 1972, puis Powell, ont prouvé que les méthodes à gradient conjugué ont un taux de convergence linéaire en l'absence de retour périodique à l'itération initiale. Ces retours sont effectués selon une procédure particulière qui interrompt le processus de construction des vecteurs de direction de recherche, puis les calculs se poursuivent par analogie avec la construction s(x(0)). Il a été noté plus haut que, pour plusieurs raisons, la présence d'une procédure de retour à l'itération initiale augmente la stabilité de l'algorithme, puisqu'elle permet d'éviter de construire des vecteurs de directions de recherche linéairement dépendants. Powell a prouvé que la méthode Polak-Ribière est également caractérisée par un taux de convergence linéaire en l'absence de retours à l'itération initiale, mais elle présente un avantage incontestable sur la méthode Fletcher-Reeves lors de la résolution de problèmes avec des fonctions objectives générales et est moins sensible aux erreurs d'arrondi lors de la réalisation de recherches unidimensionnelles.
Le développement de procédures et de méthodes efficaces garantissant un retour à l'itération initiale tout en étant peu sensibles aux erreurs d'arrondi reste l'objet de recherches actives. Beal a proposé une méthode de gradients conjugués, similaire à la procédure standard de Fletcher-Reeves, mais en même temps n'utilise pas la direction le long du gradient lors du retour à l'itération initiale. Il a montré comment, à partir de l'analyse de la direction obtenue juste avant de revenir à l'itération initiale, il est possible de réduire le nombre de calculs nécessaires lors de la résolution de problèmes nécessitant des retours multiples. Powell a examiné la stratégie de Beal, ainsi que d'autres stratégies de retour à l'itération initiale, et a proposé d'utiliser une procédure de retour soit après chaque série de Nétapes, ou lorsque l'inégalité est satisfaite
| g(x)Tg(x) | ≥ 0.2 ||g(x)|| . (3.73)
Il a démontré que la stratégie de Beale, complétée par la condition (3.73), peut être appliquée avec succès à la fois avec la formule de Fletcher - Reeves et avec la formule de Polak - Ribière, et a mené un certain nombre d'expériences informatiques dont les résultats confirment la supériorité de la méthode Polak - Ribière (avec réversion) . Shannault a étudié les effets des erreurs d'arrondi dans les recherches de lignes et de diverses stratégies de retour en arrière sur les performances des méthodes de gradient conjugué. Il a montré que la stratégie de Beale (utilisant la formule appropriée à deux paramètres), complétée par la condition de retour en arrière de Powell, conduit à une réduction significative de la précision requise d'une recherche unidimensionnelle et, par conséquent, à une augmentation significative de l'efficacité de la recherche complète. schéma de calcul de la méthode du gradient conjugué. Shannault a également présenté des résultats numériques qui indiquent la supériorité de la méthode Polak-Ribière utilisant des procédures de retour en arrière et d'arrondi lors de la recherche le long d'une ligne. Les travaux démontrent le rôle majeur des méthodes de gradient conjugué dans la résolution de problèmes de programmation non linéaire de grande dimension.
Méthodes quasi-Newton
Ces méthodes sont similaires aux méthodes discutées dans la sous-section. 3.3.5, puisqu’ils s’appuient également sur les propriétés des fonctions quadratiques. Conformément aux méthodes décrites ci-dessus, la recherche d'une solution s'effectue selon un système de directions conjuguées, tandis que les méthodes quasi-Newton présentent les caractéristiques positives de la méthode de Newton, mais n'utilisent que les dérivées premières. Dans toutes les méthodes de cette classe, la construction des vecteurs de direction de recherche est réalisée à l'aide de la formule (3.42), dans laquelle s(x(k)) s’écrit
s(x) = –UN f (x), (3.74)
Où UN- matrice de commande NN, qui s'appelle métrique. Les méthodes de recherche dans les directions déterminées par cette formule sont appelées méthodes métrique variable, puisque la matrice A change à chaque itération. Plus précisément, la méthode de métrique variable est quasi-newtonien méthode, si, conformément à celle-ci, le mouvement du point de test satisfait à la condition suivante :
X =C g. (3.75)
Malheureusement, la littérature spécialisée n'a pas élaboré de recommandations uniformes et fermes pour l'utilisation des termes ci-dessus ; nous les considérerons comme interchangeables, car ils contiennent des informations tout aussi importantes sur les caractéristiques du développement et de la mise en œuvre des méthodes en question.
Pour approximer la matrice inverse de la matrice hessienne, nous utilisons la relation de récurrence suivante :
UN = UN+ UN(3.76)
Où UN- matrice de correction. Matrice UN sera utilisé dans les formules (3.74) et (3.42). La tâche est de construire une matrice UN pour que la séquence UN (0) , UN (1) , UN (2) ,...,UN(k +1) a donné une approximation de N -1 = f (x*) -1 ; afin d'obtenir une solution X* une recherche supplémentaire en ligne droite est nécessaire si f(x)- fonction quadratique. Comme cela a été souligné à plusieurs reprises ci-dessus, il existe certaines raisons de croire qu'une méthode garantissant la recherche des optima des fonctions quadratiques peut conduire au succès dans la résolution de problèmes avec des fonctions objectives non linéaires de forme générale.
Revenons à la propriété importante des fonctions quadratiques (3.75) et supposons que la matrice AVEC-1 est approximé par la formule
AVEC-1 = β UN, (3.77)
où p est une quantité scalaire. L’approximation la plus préférable est celle qui satisfait (3.75), c’est-à-dire
x= UN g. (3.78)
Cependant, il est clair qu’il est impossible de construire une telle approximation, puisque pour trouver g, il faut connaître la matrice UN. Les notations suivantes sont utilisées ici :
x= x– x, (3.79)
g= g(x) – g(x). (3.80)
En revanche, on peut exiger que la nouvelle approximation satisfasse à la formule (3.75) :
x= β UN g. (3.81)
En remplaçant l'expression (3.76) dans (3.81), on obtient
UN g= x– UN g. (3.82)
En utilisant la substitution directe, vous pouvez vérifier que la matrice
UNE = – (3.83)
est la solution de cette équation. Ici à Et z- des vecteurs arbitraires, c'est-à-dire la formule (3.83) définit une certaine famille de solutions. Si tu mets
oui = x Et z =UN g, (3.84)
on obtient alors une formule qui met en œuvre la formule bien connue et largement utilisée Méthode Davidon- Fletcher- Powell(DFP) :
UN= UN +  –
–  . (3.85)
. (3.85)
On peut montrer que cette formule récurrente préserve les propriétés de symétrie et de définition positive des matrices. Donc si UN(0) est une matrice définie positive symétrique, alors les matrices UN (1) , UN(2) , ... s'avèrent également symétriques et définis positifs en l'absence d'erreurs d'arrondi ; c'est généralement pratique de choisir UN (0) = je.
Première variante f(x)égal à
f(x) = f (x) x. (3.86)
En utilisant les formules (3.42) et (3.74), on obtient
f(x) = f (x) α UN f (x), (3.87)
f(x) = – α f (x) UN f (x), (3.88)
et les inégalités f (x(k+1)) < f(xk) est satisfait pour toute valeur de α > 0, si UN est une matrice définie positive. Ainsi, l'algorithme garantit que la fonction objectif diminue lors du passage d'itération en itération. La méthode Davidon-Fletcher-Powell reste la méthode de gradient la plus utilisée depuis plusieurs années. Il est stable et est utilisé avec succès pour résoudre une grande variété de problèmes qui se posent dans la pratique. Le principal inconvénient des méthodes de ce type est la nécessité de stocker une matrice dans la mémoire de l'ordinateur. UN commande N N.
La méthode est conçue pour résoudre le problème (5.1) et appartient à la classe des méthodes du premier ordre. La méthode est une modification de la méthode de descente (montée) la plus raide et prend automatiquement en compte les caractéristiques de la fonction objectif, accélérant ainsi la convergence.
Description de l'algorithme
Étape 0. Le point d'approche initial est sélectionné, paramètre de longueur de pas , précision de la solution et la direction de recherche initiale est calculée.
Étape k. Sur k-ème étape, le minimum (maximum) de la fonction objectif se trouve sur une droite tracée à partir du point dans la direction . Le point minimum (maximum) trouvé détermine le prochain kème approximation, après quoi la direction de recherche est déterminée
La formule (5.4) peut être réécrite sous la forme équivalente
![]() .
.
L'algorithme termine son travail dès que la condition est remplie ; la valeur de la dernière approximation obtenue est prise comme solution.
La méthode de Newton
La méthode est conçue pour résoudre le problème (5.1) et appartient à la classe des méthodes du second ordre. La méthode est basée sur le développement de Taylor de la fonction cible et sur le fait qu'au point extrême, le gradient de la fonction est nul, c'est-à-dire.
En effet, supposons qu'un point soit suffisamment proche du point de l'extremum souhaité. Considérons jeème composante du gradient de la fonction objectif et développez-la en un point en utilisant la formule de Taylor précise aux dérivées du premier ordre :
![]() . (5.5)
. (5.5)
Nous réécrivons la formule (5.5) sous forme matricielle en tenant compte du fait que :
où est la matrice hessienne de la fonction objectif au point .
Supposons que la matrice hessienne soit non singulière. Alors il a une matrice inverse. En multipliant les deux côtés de l'équation (5.6) par la gauche, nous obtenons , d'où
![]() . (5.7)
. (5.7)
La formule (5.7) définit l’algorithme de la méthode de Newton : recalcul des approximations par k
L'algorithme termine son travail dès que la condition est remplie
![]() ,
,
où est la précision donnée de la solution ; la valeur de la dernière approximation obtenue est prise comme solution.
Méthode Newton-Raphson
La méthode est une méthode du premier ordre et est destinée à résoudre des systèmes néquations non linéaires c n inconnu:
En particulier, cette méthode peut être appliquée lors de la recherche de points stationnaires de la fonction objectif du problème (5.1), lorsqu'il est nécessaire de résoudre le système d'équations à partir de la condition .
Soit le point une solution du système (5.9), et soit situé près de . En développant la fonction en un point en utilisant la formule de Taylor, nous avons
d'où (par condition) il s'ensuit
![]() , (5.11)
, (5.11)
où est la matrice jacobienne de la fonction vectorielle. Supposons que la matrice de Jacobi soit non singulière. Alors il a une matrice inverse. En multipliant les deux côtés de l'équation (5.11) par la gauche, on obtient ![]() , où
, où
![]() . (5.12)
. (5.12)
La formule (5.12) définit l'algorithme de la méthode de Newton-Raphson : recalcul des approximations de k la ème itération est effectuée conformément à la formule
Dans le cas d'une variable, lorsque le système (5.9) dégénère en une seule équation, la formule (5.13) prend la forme
![]() , (5.14)
, (5.14)
où est la valeur de la dérivée de la fonction au point .
Sur la fig. La figure 5.2 montre un schéma de mise en œuvre de la méthode de Newton-Raphson lors de la recherche d'une solution à l'équation.

Remarque 5.1. En règle générale, la convergence des méthodes numériques dépend fortement de l’approximation initiale.
Remarque 5.2. Les méthodes de Newton et de Newton-Raphson nécessitent une grande quantité de calculs (il faut calculer et inverser les matrices de Hesse et de Jacobi à chaque étape).
Remarque 5.3. Lors de l'utilisation de méthodes, il est nécessaire de prendre en compte la possibilité de présence de nombreux extrema dans la fonction objectif (propriété multimodalité).
LITTÉRATURE
1. Afanasyev M.Yu., Souvorov B.P. Recherche opérationnelle en économie : manuel. – M. : Faculté d'économie de l'Université d'État de Moscou, TEIS, 2003 – 312 p.
2. Bazara M, Shetty K. Programmation non linéaire. Théorie et algorithmes : Trans. de l'anglais – M. : Mir, 1982 – 583 p.
3. Berman G..N. Recueil de problèmes pour le cours d'analyse mathématique : Manuel pour les universités. – Saint-Pétersbourg : « Littérature spéciale », 1998. – 446 p.
4. Wagner G. Fondamentaux de la recherche opérationnelle : en 3 volumes. Par. de l'anglais – M. : Mir, 1972. – 336 p.
5. Ventzel E. C. Recherche opérationnelle. Objectifs, principes, méthodologie - M. : Nauka, 1988. - 208 p.
6. Demidovitch B.P. Recueil de problèmes et d'exercices sur l'analyse mathématique . – M. : Nauka, 1977. – 528 p.
7. Degtyarev Yu.I. Recherche opérationnelle. – M. : Plus haut. école, 1986. – 320 p.
8. Noureev R.M. Collection de problèmes en microéconomie. – M. : NORME, 2006. – 432 p.
9. Solodovnikov A. AVEC., Babaytsev V.A., Brailov A.V. Mathématiques en économie : Manuel : En 2 parties - M. : Finance et Statistiques, 1999. - 224 p.
10. Taha H. Introduction à la recherche opérationnelle, 6e éd. : Trans. de l'anglais – M. : Maison d'édition Williams, 2001. – 912 p.
11. Himmelblau D. Programmation non linéaire appliquée : Trad. de l'anglais – M. : Mir, 1975 – 534 p.
12. Shikin E. DANS., Shikina G.E. Recherche opérationnelle : Manuel - M. : TK Welby, Prospekt Publishing House, 2006. - 280 p.
13. Recherche opérationnelle en économie: Manuel. manuel pour les universités / N.Sh Kremer, B.A. Putko, I.M. Trishin, M.N. Éd. prof. N. Sh. Kremer. – M. : Banques et bourses, UNITY, 1997. – 407 p.
14. Matrices et vecteurs: Manuel. allocation / Ryumkin V.I. – Tomsk : TSU, 1999. – 40 p.
15. Systèmes d'équations linéaires: Manuel. allocation / Ryumkin V.I. – Tomsk : TSU, 2000. – 45 p.
| INTRODUCTION……………………………………………………............................. ...... | |
| 1. BASES DE LA PROGRAMMATION MATHÉMATIQUE………………... | |
| 1.1. Énoncé du problème de programmation mathématique........................................................ ....... | |
| 1.2. Types de ZMP…………….…………................................................. .. | |
| 1.3. Concepts de base de la programmation mathématique................................... | |
| 1.4. Dérivée directionnelle. Pente…………......................................... | |
| 1.5. Hyperplans tangents et normales………….................................................. .......... | |
| 1.6. Décomposition de Taylor……………………………………………………………….. .......... | |
| 1.7. ZNLP et les conditions d’existence de sa solution.................................................. .......... ....... | |
| 1.8. Tâches……………..…….................................. ..................................................... | |
| 2. SOLUTION DU PROBLEME DE PROGRAMMATION NON LINÉAIRE SANS CONTRAINTES............................................... ........................ ........................ .................................. .................. .. | |
| 2.1. Conditions nécessaires pour résoudre une loi non restrictive non restrictive..................................... .............. | |
| 2.2. Conditions suffisantes pour résoudre le ZNLP sans restrictions.................................. | |
| 2.3. Méthode classique pour résoudre ZNLP sans restrictions.................................. | |
| 2.4. Tâches…………….................................................. ....................................................... ............ | |
| 3. SOLUTION DU PROBLEME DE PROGRAMMATION NON LINÉAIRE AVEC CONTRAINTES D'ÉGALITÉ....................................... ............ ....................................... ... | |
| 3.1. Méthode du multiplicateur de Lagrange............................................................ ....................... | |
| 3.1.1. Objectif et justification de la méthode du multiplicateur de Lagrange…………… | |
| 3.1.2. Schéma de mise en œuvre de la méthode du multiplicateur de Lagrange……………………... | |
| 3.1.3. Interprétation des multiplicateurs de Lagrange…………………………………………………… | |
| 3.2. Méthode de substitution…………………………….................................................. ............ ............ | |
| 3.3. Tâches………………………………………………………………........................ ........... | |
| 4. SOLUTION DU PROBLEME DE PROGRAMMATION NON LINÉAIRE SOUS CONTRAINTES D'INÉGALITÉ…………………………………………………………….. | |
| 4.1. Méthode du multiplicateur de Lagrange généralisé…………………………………… | |
| 4.2. Conditions Kuhn-Tucker……………………………………………………………........ | |
| 4.2.1. Nécessité des conditions Kuhn-Tucker…………………………………… | |
| 4.2.2. Suffisance des conditions de Kuhn-Tucker………………………………….. | |
| 4.2.3. Méthode Kuhn-Tucker………………………................................................. . ......... | |
| 4.3. Tâches………………………………………………………………........................ ........... | |
| 5. MÉTHODES NUMÉRIQUES POUR RÉSOUDRE UN PROBLÈME DE PROGRAMMATION NON LINÉAIRE………………………………………………………………………………… | |
| 5.1. La notion d'algorithme…………………………………………………………… ............... | |
| 5.2. Classification des méthodes numériques…………………………………………………………… | |
| 5.3. Algorithmes de méthodes numériques……………………………………………... | |
| 5.3.1. Méthode de descente (montée) la plus rapide………………………………… | |
| 5.3.2. Méthode du gradient conjugué……………………………………………………………. | |
| 5.3.3. La méthode de Newton............................................................ ...................... ............... | |
| 5.3.4. Méthode Newton-Raphson……………………………………………... | |
| LITTÉRATURE………………………………..................................... ........................ |
Pour les définitions des fonctions linéaires et non linéaires, voir la section 1.2







