Shembull.
Të dhëna eksperimentale për vlerat e variablave X Dhe në janë dhënë në tabelë.
Si rezultat i shtrirjes së tyre, fitohet funksioni ![]()
Duke përdorur metodë katrorët më të vegjël , përafroni këto të dhëna me një varësi lineare y=sëpatë+b(gjeni parametrat A Dhe b). Gjeni se cila nga dy rreshtat (në kuptimin e metodës së katrorëve më të vegjël) i përafron më mirë të dhënat eksperimentale. Bëni një vizatim.
Thelbi i metodës së katrorëve më të vegjël (LSM).
Detyra është të gjejmë koeficientët e varësisë lineare në të cilat funksionojnë dy ndryshore A Dhe b
![]() merr vlerën më të vogël. Kjo është, e dhënë A Dhe b shuma e devijimeve në katror të të dhënave eksperimentale nga drejtëza e gjetur do të jetë më e vogla. Kjo është e gjithë pika e metodës së katrorëve më të vegjël.
merr vlerën më të vogël. Kjo është, e dhënë A Dhe b shuma e devijimeve në katror të të dhënave eksperimentale nga drejtëza e gjetur do të jetë më e vogla. Kjo është e gjithë pika e metodës së katrorëve më të vegjël.
Kështu, zgjidhja e shembullit zbret në gjetjen e ekstremit të një funksioni të dy ndryshoreve.
Nxjerrja e formulave për gjetjen e koeficientëve.
Përpilohet dhe zgjidhet një sistem me dy ekuacione me dy të panjohura. Gjetja e derivateve të pjesshme të një funksioni ![]() sipas variablave A Dhe b, ne i barazojmë këto derivate me zero.
sipas variablave A Dhe b, ne i barazojmë këto derivate me zero. 
Ne zgjidhim sistemin rezultues të ekuacioneve duke përdorur çdo metodë (për shembull me metodën e zëvendësimit ose Metoda e Cramer-it) dhe merrni formulat për gjetjen e koeficientëve duke përdorur metodën e katrorëve më të vegjël (LSM). 
E dhënë A Dhe b funksionin ![]() merr vlerën më të vogël. Dëshmia e këtij fakti është dhënë më poshtë në tekstin në fund të faqes.
merr vlerën më të vogël. Dëshmia e këtij fakti është dhënë më poshtë në tekstin në fund të faqes.
Kjo është e gjithë metoda e katrorëve më të vegjël. Formula për gjetjen e parametrit a përmban shumat ,,, dhe parametrin n- sasia e të dhënave eksperimentale. Ne rekomandojmë llogaritjen e vlerave të këtyre shumave veç e veç. Koeficienti b gjetur pas llogaritjes a.
Është koha për të kujtuar shembullin origjinal.
Zgjidhje.
Në shembullin tonë n=5. Plotësojmë tabelën për lehtësinë e llogaritjes së shumave që përfshihen në formulat e koeficientëve të kërkuar. 
Vlerat në rreshtin e katërt të tabelës merren duke shumëzuar vlerat e rreshtit të dytë me vlerat e rreshtit të tretë për çdo numër i.
Vlerat në rreshtin e pestë të tabelës fitohen duke kuadruar vlerat në rreshtin e dytë për çdo numër i.
Vlerat në kolonën e fundit të tabelës janë shumat e vlerave nëpër rreshta.
Ne përdorim formulat e metodës së katrorëve më të vegjël për të gjetur koeficientët A Dhe b. Ne zëvendësojmë vlerat përkatëse nga kolona e fundit e tabelës në to: 
Prandaj, y = 0,165x+2,184- vijën e drejtë të përafërt të dëshiruar.
Mbetet për të gjetur se cila nga rreshtat y = 0,165x+2,184 ose ![]() përafron më mirë të dhënat origjinale, domethënë bën një vlerësim duke përdorur metodën e katrorëve më të vegjël.
përafron më mirë të dhënat origjinale, domethënë bën një vlerësim duke përdorur metodën e katrorëve më të vegjël.
Vlerësimi i gabimit të metodës së katrorëve më të vegjël.
Për ta bërë këtë, ju duhet të llogaritni shumën e devijimeve në katror të të dhënave origjinale nga këto rreshta ![]() Dhe
Dhe ![]() , një vlerë më e vogël i korrespondon një rreshti që përafron më mirë të dhënat origjinale në kuptimin e metodës së katrorëve më të vegjël.
, një vlerë më e vogël i korrespondon një rreshti që përafron më mirë të dhënat origjinale në kuptimin e metodës së katrorëve më të vegjël. 
Që atëherë, drejt y = 0,165x+2,184 përafron më mirë të dhënat origjinale.
Ilustrimi grafik i metodës së katrorëve më të vegjël (LS).
Gjithçka është qartë e dukshme në grafikët. Vija e kuqe është vija e drejtë e gjetur y = 0,165x+2,184, vija blu është ![]() , pikat rozë janë të dhënat origjinale.
, pikat rozë janë të dhënat origjinale.

Në praktikë, kur modeloni procese të ndryshme - në veçanti, ekonomike, fizike, teknike, sociale - përdoret gjerësisht një ose një metodë tjetër e llogaritjes së vlerave të përafërta të funksioneve nga vlerat e tyre të njohura në pika të caktuara fikse.
Ky lloj problemi i përafrimit të funksionit shpesh lind:
kur ndërtoni formula të përafërta për llogaritjen e vlerave të sasive karakteristike të procesit në studim duke përdorur të dhëna tabelare të marra si rezultat i eksperimentit;
në integrimin numerik, diferencimin, zgjidhjen ekuacionet diferenciale etj.;
nëse është e nevojshme, llogaritni vlerat e funksioneve në pikat e ndërmjetme të intervalit të konsideruar;
kur përcaktohen vlerat e sasive karakteristike të një procesi jashtë intervalit të konsideruar, veçanërisht gjatë parashikimit.
Nëse, për të modeluar një proces të caktuar të specifikuar nga një tabelë, ndërtojmë një funksion që përafërsisht përshkruan këtë proces bazuar në metodën e katrorëve më të vegjël, ai do të quhet funksion i përafërt (regresion) dhe vetë problemi i ndërtimit të funksioneve të përafërta do të quhet një problem përafrimi.
Ky artikull diskuton aftësitë e paketës MS Excel për zgjidhjen e këtij lloj problemi, përveç kësaj, ai ofron metoda dhe teknika për ndërtimin (krijimin) e regresioneve për tabela funksionet e specifikuara(e cila është baza e analizës së regresionit).
Excel ka dy opsione për ndërtimin e regresioneve.
Shtimi i regresioneve (vijave të prirjes) të zgjedhur në një diagram të ndërtuar mbi bazën e një tabele të dhënash për karakteristikën e procesit në studim (e disponueshme vetëm nëse është ndërtuar një diagram);
Përdorimi i funksioneve statistikore të integruara të fletës së punës Excel, duke ju lejuar të merrni regresione (linjat e trendit) direkt nga tabela e të dhënave burimore.
Shtimi i linjave të tendencës në një grafik
Për një tabelë të dhënash që përshkruan një proces dhe përfaqësohet nga një diagram, Excel ka një mjet efektiv të analizës së regresionit që ju lejon të:
ndërtoni bazuar në metodën e katrorëve më të vegjël dhe shtoni pesë në diagram llojet e regresioneve, të cilat modelojnë procesin në studim me shkallë të ndryshme saktësie;
shtoni në diagram ekuacionin e ndërtuar të regresionit;
përcaktoni shkallën e korrespondencës së regresionit të zgjedhur me të dhënat e shfaqura në grafik.
Bazuar në të dhënat e grafikut, Excel ju lejon të merrni lloje lineare, polinomiale, logaritmike, fuqie, eksponenciale të regresioneve, të cilat specifikohen nga ekuacioni:
y = y(x)
ku x është një variabël i pavarur që shpesh merr vlerat e një sekuence numrash natyrorë (1; 2; 3; ...) dhe prodhon, për shembull, një numërim mbrapsht të kohës së procesit në studim (karakteristikat).
1 . Regresioni linear është i mirë për modelimin e karakteristikave, vlerat e të cilave rriten ose ulen me një ritëm konstant. Ky është modeli më i thjeshtë për t'u ndërtuar për procesin në studim. Është ndërtuar në përputhje me ekuacionin:
y = mx + b
ku m është tangjentja e këndit të prirjes regresioni linear te boshti i abshisave; b - koordinata e pikës së prerjes së regresionit linear me boshtin e ordinatave.
2 . Një linjë prirje polinomiale është e dobishme për të përshkruar karakteristikat që kanë disa ekstreme të dallueshme (maksimum dhe minimum). Zgjedhja e shkallës polinomiale përcaktohet nga numri i ekstremeve të karakteristikës që studiohet. Kështu, një polinom i shkallës së dytë mund të përshkruajë mirë një proces që ka vetëm një maksimum ose minimum; polinomi i shkallës së tretë - jo më shumë se dy ekstreme; polinomi i shkallës së katërt - jo më shumë se tre ekstreme, etj.
Në këtë rast, linja e trendit ndërtohet në përputhje me ekuacionin:
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
ku koeficientët c0, c1, c2,... c6 janë konstante vlerat e të cilave përcaktohen gjatë ndërtimit.
3 . Linja e prirjes logaritmike përdoret me sukses gjatë modelimit të karakteristikave, vlerat e të cilave fillimisht ndryshojnë me shpejtësi dhe më pas stabilizohen gradualisht.
y = c ln(x) + b
4 . Linja e prirjes së ligjit të fuqisë jep rezultate të mira nëse vlerat e marrëdhënies në studim karakterizohen nga një ndryshim i vazhdueshëm në normën e rritjes. Një shembull i një varësie të tillë është grafiku i lëvizjes së njëtrajtshme të përshpejtuar të një makine. Nëse të dhënat përmbajnë zero ose vlerat negative, nuk mund të përdorni një linjë të trendit të energjisë.
Ndërtuar në përputhje me ekuacionin:
y = c xb
ku koeficientët b, c janë konstante.
5 . Një linjë trendi eksponenciale duhet të përdoret kur shkalla e ndryshimit të të dhënave është vazhdimisht në rritje. Për të dhënat që përmbajnë vlera zero ose negative, ky lloj përafrimi gjithashtu nuk është i zbatueshëm.
Ndërtuar në përputhje me ekuacionin:
y = c ebx
ku koeficientët b, c janë konstante.
Kur zgjedh një linjë trendi, Excel llogarit automatikisht vlerën e R2, e cila karakterizon besueshmërinë e përafrimit: vlerë më të afërt R2 në unitet, aq më e besueshme është linja e prirjes përafrohet me procesin në studim. Nëse është e nevojshme, vlera R2 mund të shfaqet gjithmonë në grafik.
Përcaktohet nga formula:

Për të shtuar një linjë trendi në një seri të dhënash:
aktivizoni një grafik bazuar në një seri të dhënash, p.sh. klikoni brenda zonës së grafikut. Artikulli Diagram do të shfaqet në menynë kryesore;
pasi të klikoni mbi këtë artikull, në ekran do të shfaqet një meny në të cilën duhet të zgjidhni komandën Shto linjën e trendit.
Të njëjtat veprime mund të zbatohen lehtësisht duke lëvizur treguesin e miut mbi grafikun që korrespondon me një nga seritë e të dhënave dhe duke klikuar me të djathtën; Në menynë e kontekstit që shfaqet, zgjidhni komandën Shto linjën e trendit. Kutia e dialogut Trendline do të shfaqet në ekran me skedën Type të hapur (Fig. 1).

Pas kësaj ju duhet:
Zgjidhni në skedën Lloji lloji i kërkuar linjat e trendit (Lloji linear është zgjedhur si parazgjedhje). Për llojin Polynomial, në fushën Degree, specifikoni shkallën e polinomit të zgjedhur.
1 . Fusha e ndërtuar në seri rendit të gjitha seritë e të dhënave në grafikun në fjalë. Për të shtuar një linjë trendi në një seri specifike të dhënash, zgjidhni emrin e saj në fushën Ndërtuar në seri.

Nëse është e nevojshme, duke shkuar te skeda Parametrat (Fig. 2), mund të vendosni parametrat e mëposhtëm për linjën e trendit:
ndryshoni emrin e linjës së prirjes në Emrin e fushës së kurbës së përafërt (të zbutur).
caktoni numrin e periudhave (përpara ose prapa) për parashikimin në fushën Parashikimi;
shfaqni ekuacionin e vijës së prirjes në zonën e diagramit, për të cilën duhet të aktivizoni ekuacionin e shfaqjes në kutinë e kontrollit të diagramit;
shfaqni vlerën e besueshmërisë së përafrimit R2 në zonën e diagramit, për të cilën duhet të aktivizoni kutinë e kontrollit Vendos vlerën e besueshmërisë së përafrimit në diagram (R^2);
vendosni pikën e kryqëzimit të vijës së prirjes me boshtin Y, për të cilin duhet të aktivizoni kutinë e kontrollit për kryqëzimin e kurbës me boshtin Y në një pikë;
Klikoni butonin OK për të mbyllur kutinë e dialogut.
Për të filluar redaktimin e një linje tendence të vizatuar tashmë, ekzistojnë tre mënyra:
përdorni komandën Selected trend line nga menyja Format, pasi keni zgjedhur më parë linjën e trendit;
zgjidhni komandën Format line trend nga menyja e kontekstit, e cila thirret duke klikuar me të djathtën në vijën e trendit;
klikoni dy herë në vijën e trendit.
Kutia e dialogut Formati i linjës së tendencës do të shfaqet në ekran (Fig. 3), që përmban tre skeda: Pamja, Lloji, Parametrat dhe përmbajtja e dy të fundit përputhet plotësisht me skedat e ngjashme të kutisë së dialogut të linjës së trendit (Fig. 1 -2). Në skedën View, mund të vendosni llojin e linjës, ngjyrën dhe trashësinë e saj.

Për të fshirë një linjë tendence që është tërhequr tashmë, zgjidhni vijën e tendencës që do të fshihet dhe shtypni butonin Delete.
Përparësitë e mjetit të analizës së regresionit të konsideruar janë:
lehtësia relative e ndërtimit të një linje trendi në grafikët pa krijuar një tabelë të dhënash për të;
një listë mjaft e gjerë e llojeve të linjave të tendencave të propozuara, dhe kjo listë përfshin llojet më të përdorura të regresionit;
aftësia për të parashikuar sjelljen e procesit në studim në çdo nivel arbitrar (brenda sens të përbashkët) numri i hapave përpara dhe prapa;
aftësia për të marrë ekuacionin e linjës së trendit në formë analitike;
mundësia, nëse është e nevojshme, për të marrë një vlerësim të besueshmërisë së përafrimit.
Disavantazhet përfshijnë si më poshtë:
ndërtimi i një linje trendi kryhet vetëm nëse ekziston një diagram i ndërtuar mbi një seri të dhënash;
procesi i gjenerimit të serive të të dhënave për karakteristikën në studim bazuar në ekuacionet e linjës së trendit të marra për të është disi i rrëmujshëm: ekuacionet e kërkuara të regresionit përditësohen me çdo ndryshim në vlerat e serisë së të dhënave origjinale, por vetëm brenda zonës së diagramit. , ndërsa seritë e të dhënave, i krijuar bazuar në ekuacionin e linjës së trendit të vjetër, mbetet i pandryshuar;
Në raportet e PivotChart, ndryshimi i pamjes së një grafiku ose raporti të lidhur me PivotTable nuk ruan linjat ekzistuese të trendit, që do të thotë se përpara se të vizatoni vija trendi ose të formatoni ndryshe një raport PivotChart, duhet të siguroheni që paraqitja e raportit plotëson kërkesat e kërkuara.
Linjat e tendencës mund të përdoren për të plotësuar seritë e të dhënave të paraqitura në grafikët si grafikët, histogramët, grafikët e zonave të sheshta jo të standardizuara, grafikët me shirita, grafikët e shpërndarjes, grafikët me flluska dhe grafikët e aksioneve.
Ju nuk mund të shtoni linja prirje në seritë e të dhënave në grafikët 3D, të normalizuar, radar, byrek dhe donut.
Përdorimi i funksioneve të integruara të Excel
Excel ka gjithashtu një mjet për analizën e regresionit për vizatimin e linjave të tendencës jashtë zonës së grafikut. Ekzistojnë një numër funksionesh statistikore të fletës së punës që mund të përdorni për këtë qëllim, por të gjitha ato ju lejojnë vetëm të ndërtoni regresione lineare ose eksponenciale.
Excel ka disa funksione për ndërtimin e regresionit linear, në veçanti:
SHPJERI dhe PRERJE.
TRENDI;
Dhe gjithashtu disa funksione për ndërtimin vijë eksponenciale trend, në veçanti:
LGRFPRIBL.
Duhet të theksohet se teknikat për ndërtimin e regresioneve duke përdorur funksionet TREND dhe GROWTH janë pothuajse të njëjta. E njëjta gjë mund të thuhet për çiftin e funksioneve LINEST dhe LGRFPRIBL. Për këto katër funksione, krijimi i një tabele vlerash përdor veçori të Excel-it si formulat e grupeve, të cilat disi rrëmujnë procesin e ndërtimit të regresioneve. Le të theksojmë gjithashtu se ndërtimi i regresionit linear, sipas mendimit tonë, realizohet më lehtë duke përdorur funksionet SLOPE dhe INTERCEPT, ku i pari prej tyre përcakton pjerrësinë e regresionit linear dhe i dyti përcakton segmentin e ndërprerë nga regresioni në boshti y.
Përparësitë e veglës së funksioneve të integruara për analizën e regresionit janë:
një proces mjaft i thjeshtë dhe uniform për gjenerimin e serive të të dhënave të karakteristikës në studim për të gjitha funksionet statistikore të integruara që përcaktojnë linjat e trendit;
metodologji standarde për ndërtimin e linjave të trendit bazuar në seritë e gjeneruara të të dhënave;
aftësia për të parashikuar sjelljen e procesit në studim mbi sasia e kërkuar hapa përpara ose prapa.
Disavantazhet përfshijnë faktin se Excel nuk ka funksione të integruara për krijimin e llojeve të tjera (përveç lineare dhe eksponenciale) të linjave të trendit. Kjo rrethanë shpesh nuk lejon zgjedhjen e një modeli mjaft të saktë të procesit në studim, si dhe marrjen e parashikimeve që janë afër realitetit. Përveç kësaj, kur përdorni funksionet TREND dhe RRITJE, ekuacionet e linjave të trendit nuk dihen.
Duhet të theksohet se autorët nuk u përpoqën të paraqisnin kursin e analizës së regresionit me ndonjë shkallë të plotësisë. Detyra e tij kryesore është të tregojë, duke përdorur shembuj specifikë, aftësitë e paketës Excel kur zgjidh problemet e përafrimit; demonstroni se çfarë mjetesh efektive ka Excel për ndërtimin e regresioneve dhe parashikimit; ilustrojnë se si probleme të tilla mund të zgjidhen relativisht lehtë edhe nga një përdorues që nuk ka njohuri të gjera për analizën e regresionit.
Shembuj zgjidhjesh detyra specifike
Le të shohim zgjidhjen e problemeve specifike duke përdorur mjetet e listuara të Excel.
Problemi 1
Me një tabelë të dhënash për fitimin e një ndërmarrje transporti automobilistik për vitet 1995-2002. ju duhet të bëni sa më poshtë:
Ndërtoni një diagram.
Shtoni linjat e trendit linear dhe polinom (kuadratik dhe kub) në grafik.
Duke përdorur ekuacionet e linjës së prirjes, merrni të dhëna tabelare mbi fitimet e ndërmarrjes për secilën linjë prirje për 1995-2004.
Bëni një parashikim për fitimin e ndërmarrjes për 2003 dhe 2004.
Zgjidhja e problemit

Në rangun e qelizave A4:C11 të fletës së punës Excel, futni fletën e punës të paraqitur në Fig. 4.
Pasi kemi zgjedhur gamën e qelizave B4:C11, ndërtojmë një diagram.
Aktivizojmë diagramin e ndërtuar dhe, sipas metodës së përshkruar më sipër, pasi kemi zgjedhur llojin e linjës së trendit në kutinë e dialogut të linjës së tendencës (shih Fig. 1), shtojmë në mënyrë alternative në diagram linjat e trendit linear, kuadratik dhe kub. Në të njëjtën kuti dialogu, hapni skedën Parametrat (shih Fig. 2), në emrin e fushës së kurbës së përafërt (të zbutur), shkruani emrin e trendit që po shtohet dhe në fushën Parashikimi përpara për: periudhat, vendosni vlera 2, pasi është planifikuar të bëhet një parashikim fitimi për dy vitet e ardhshme. Për të shfaqur ekuacionin e regresionit dhe vlerën e besueshmërisë së përafrimit R2 në zonën e diagramit, aktivizoni ekuacionin e shfaqjes në kutitë e kontrollit të ekranit dhe vendosni vlerën e besueshmërisë së përafrimit (R^2) në diagram. Për më të mirën perceptimi vizual ndryshojmë llojin, ngjyrën dhe trashësinë e linjave të tendencave të ndërtuara, për të cilat përdorim skedën View në kutinë e dialogut Formati i linjës së trendit (shih Fig. 3). Diagrami që rezulton me linjat e tendencës së shtuar është paraqitur në Fig. 5.
Për të marrë të dhëna tabelare mbi fitimet e ndërmarrjeve për çdo linjë trendi për 1995-2004.


Le të përdorim ekuacionet e linjës së trendit të paraqitur në Fig. 5. Për ta bërë këtë, në qelizat e diapazonit D3:F3, futni informacionin e tekstit për llojin e linjës së tendencës së zgjedhur: Trendi linear, Trendi kuadratik, trendi kub. Më pas, futni formulën e regresionit linear në qelizën D4 dhe, duke përdorur shënuesin e mbushjes, kopjoni këtë formulë me referenca relative në diapazonin e qelizave D5:D13. Duhet të theksohet se çdo qelizë me një formulë regresioni linear nga diapazoni i qelizave D4:D13 ka si argument një qelizë përkatëse nga diapazoni A4:A13. Në mënyrë të ngjashme, për regresionin kuadratik, plotësoni gamën e qelizave E4:E13, dhe për regresionin kub, plotësoni gamën e qelizave F4:F13. Kështu, është përpiluar një parashikim për fitimin e ndërmarrjes për vitet 2003 dhe 2004. duke përdorur tre tendenca. Tabela rezultuese e vlerave është treguar në Fig. 6.
Ndërtoni një diagram.
Problemi 2
Shtoni linjat e tendencës logaritmike, fuqisë dhe eksponenciale në grafik.
Nxirrni ekuacionet e linjave të prirjeve të marra, si dhe vlerat e besueshmërisë së përafrimit R2 për secilën prej tyre.
Duke përdorur ekuacionet e linjës së trendit, merrni të dhëna tabelare mbi fitimin e ndërmarrjes për secilën linjë trendi për 1995-2002.
Zgjidhja e problemit
Bëni një parashikim të fitimit të kompanisë për 2003 dhe 2004 duke përdorur këto linja prirje.


Duke ndjekur metodologjinë e dhënë në zgjidhjen e problemit 1, marrim një diagram me linja logaritmike, fuqie dhe tendencash eksponenciale të shtuara në të (Fig. 7). Më pas, duke përdorur ekuacionet e marra të linjës së trendit, ne plotësojmë një tabelë vlerash për fitimin e ndërmarrjes, duke përfshirë vlerat e parashikuara për 2003 dhe 2004. (Fig. 8).
Në Fig. 5 dhe fig. mund të shihet se modeli me prirje logaritmike i korrespondon vlerës më të ulët të besueshmërisë së përafrimit
R2 = 0,8659
Vlerat më të larta të R2 korrespondojnë me modelet me një prirje polinomiale: kuadratike (R2 = 0,9263) dhe kub (R2 = 0,933).
Problemi 3
Me tabelën e të dhënave për fitimin e një ndërmarrje transporti motorik për vitet 1995-2002, të dhënë në detyrën 1, duhet të kryeni hapat e mëposhtëm.
Merrni seritë e të dhënave për linjat e prirjeve lineare dhe eksponenciale duke përdorur funksionet TREND dhe GROW.
Duke përdorur funksionet TREND dhe RRITJE, bëni një parashikim të fitimit të ndërmarrjes për 2003 dhe 2004.
Zgjidhja e problemit
Ndërtoni një diagram për të dhënat origjinale dhe seritë e të dhënave që rezultojnë.
zgjidhni gamën e qelizave D4:D11, të cilat duhet të plotësohen me vlerat e funksionit TREND që korrespondojnë me të dhënat e njohura për fitimin e ndërmarrjes;
Thirrni komandën Funksion nga menyja Insert. Në kutinë e dialogut Function Wizard që shfaqet, zgjidhni funksionin TREND nga kategoria Statistikore dhe më pas klikoni butonin OK. I njëjti veprim mund të kryhet duke klikuar butonin (Insert Function) në shiritin standard të veglave.
Në kutinë e dialogut "Argumentet e funksionit" që shfaqet, futni gamën e qelizave C4:C11 në fushën Vlerat e_njohura_y; në fushën Vlerat_njohura_x - diapazoni i qelizave B4:B11;
Për ta bërë formulën e futur të bëhet një formulë grupi, përdorni kombinimin e tastit + + .
Formula që kemi futur në shiritin e formulave do të duket si: =(TREND(C4:C11,B4:B11)).
Si rezultat, diapazoni i qelizave D4:D11 është i mbushur me vlerat përkatëse të funksionit TREND (Fig. 9).

Për të bërë një parashikim të fitimit të ndërmarrjes për 2003 dhe 2004. nevojshme:
zgjidhni gamën e qelizave D12:D13 ku do të futen vlerat e parashikuara nga funksioni TREND.
thirrni funksionin TREND dhe në kutinë e dialogut Argumentet e funksionit që shfaqet, futni në fushën Vlerat_y_njohura - gamën e qelizave C4:C11; në fushën Vlerat_njohura_x - diapazoni i qelizave B4:B11; dhe në fushën New_values_x - diapazoni i qelizave B12:B13.
kthejeni këtë formulë në një formulë grupi duke përdorur kombinimin e tastit Ctrl + Shift + Enter.
Formula e futur do të duket si: =(TREND(C4:C11;B4:B11;B12:B13)), dhe diapazoni i qelizave D12:D13 do të plotësohet me vlerat e parashikuara të funksionit TREND (shih Fig. 9).
Seria e të dhënave plotësohet në mënyrë të ngjashme duke përdorur funksionin GROWTH, i cili përdoret në analizën e varësive jolineare dhe funksionon saktësisht në të njëjtën mënyrë si homologu i tij linear TREND.
Figura 10 tregon tabelën në modalitetin e shfaqjes së formulës.


Për të dhënat fillestare dhe seritë e të dhënave të marra, diagrami i paraqitur në Fig. 11.
Problemi 4
Me tabelën e të dhënave për marrjen e aplikacioneve për shërbime nga shërbimi dispeçer i një ndërmarrje transporti motorik për periudhën nga data 1 deri në 11 të muajit aktual, duhet të kryeni veprimet e mëposhtme.
Merrni seritë e të dhënave për regresionin linear: duke përdorur funksionet SLOPE dhe INTERCEPT; duke përdorur funksionin LINEST.
Merrni një seri të dhënash për regresionin eksponencial duke përdorur funksionin LGRFPRIBL.
Duke përdorur funksionet e mësipërme, bëni një parashikim për marrjen e aplikacioneve në shërbimin e dërgimit për periudhën nga data 12 deri në 14 të muajit aktual.
Krijo një diagram për serinë e të dhënave origjinale dhe të marra.
Zgjidhja e problemit
Vini re se, ndryshe nga funksionet TREND dhe GROWTH, asnjë nga funksionet e listuara më sipër (SHPJETËSIA, INTERCEPT, LINEST, LGRFPRIB) nuk janë regresioni. Këto funksione luajnë vetëm një rol mbështetës, duke përcaktuar parametrat e nevojshëm të regresionit.
Për regresionet lineare dhe eksponenciale të ndërtuara duke përdorur funksionet SLOPE, INTERCEPT, LINEST, LGRFPRIB, pamja e ekuacioneve të tyre është gjithmonë e njohur, në ndryshim nga regresionet lineare dhe eksponenciale që korrespondojnë me funksionet TREND dhe GROWTH.
1 . Le të ndërtojmë një regresion linear me ekuacionin:
y = mx+b
duke përdorur funksionet SLOPE dhe INTERCEPT, me pjerrësinë e regresionit m të përcaktuar nga funksioni SLOPE, dhe termin e lirë b nga funksioni INTERCEPT.
Për ta bërë këtë, ne kryejmë veprimet e mëposhtme:
futni tabelën origjinale në diapazonin e qelizave A4:B14;
vlera e parametrit m do të përcaktohet në qelizën C19. Zgjidhni nga kategoria Funksioni statistikor Pjerrësia; futni gamën e qelizave B4:B14 në fushën e vlerave_y_njohur dhe gamën e qelizave A4:A14 në fushën e vlerave_x_njohur.
Formula do të futet në qelizën C19: =SLOPE(B4:B14,A4:A14);
Duke përdorur një teknikë të ngjashme, përcaktohet vlera e parametrit b në qelizën D19. Dhe përmbajtja e tij do të duket si: =SEGMENT(B4:B14,A4:A14). Kështu, vlerat e parametrave m dhe b të kërkuara për ndërtimin e një regresioni linear do të ruhen në qelizat C19, D19, përkatësisht;
2 Më pas, futni formulën e regresionit linear në qelizën C4 në formën: =$C*A4+$D. Në këtë formulë, qelizat C19 dhe D19 shkruhen me referenca absolute (adresa e qelizës nuk duhet të ndryshojë gjatë kopjimit të mundshëm). Shenja e referencës absolute $ mund të shtypet ose nga tastiera ose duke përdorur tastin F4, pasi të vendosni kursorin në adresën e qelizës.
y = mx+b
Duke përdorur dorezën e mbushjes, kopjoni këtë formulë në gamën e qelizave C4:C17. Ne marrim seritë e kërkuara të të dhënave (Fig. 12). Për shkak të faktit se numri i kërkesave është një numër i plotë, duhet të vendosni formatin e numrave me numrin e numrave dhjetorë në 0 në skedën Number në dritaren e Formatit të qelizës.
. Tani le të ndërtojmë një regresion linear të dhënë nga ekuacioni:
duke përdorur funksionin LINEST.
Për ta bërë këtë:
Futni funksionin LINEST si një formulë grupi në diapazonin e qelizave C20:D20: =(LINEST(B4:B14,A4:A14)). Si rezultat, marrim vlerën e parametrit m në qelizën C20 dhe vlerën e parametrit b në qelizën D20;
3 shkruani formulën në qelizën D4: =$C*A4+$D;
duke përdorur funksionin LGRFPRIBL kryhet në mënyrë të ngjashme:
Në rangun e qelizave C21:D21 ne futim funksionin LGRFPRIBL si formulë grupi: =( LGRFPRIBL (B4:B14,A4:A14)). Në këtë rast, vlera e parametrit m do të përcaktohet në qelizën C21, dhe vlera e parametrit b do të përcaktohet në qelizën D21;
formula futet në qelizën E4: =$D*$C^A4;
duke përdorur shënuesin mbushës, kjo formulë kopjohet në diapazonin e qelizave E4:E17, ku do të vendoset seria e të dhënave për regresionin eksponencial (shih Fig. 12).

Në Fig. Figura 13 tregon një tabelë ku mund të shihni funksionet që përdorim me diapazonin e kërkuar të qelizave, si dhe formulat.
Madhësia R 2 thirrur koeficienti i përcaktimit.
Detyra e ndërtimit të një varësie regresioni është gjetja e vektorit të koeficientëve m të modelit (1) në të cilin koeficienti R merr vlerën e tij maksimale.
Për të vlerësuar rëndësinë e R, përdoret testi F Fisher, i llogaritur duke përdorur formulën

Ku n- madhësia e mostrës (numri i eksperimenteve);
k është numri i koeficientëve të modelit.
Nëse F tejkalon një vlerë kritike për të dhënat n Dhe k dhe probabilitetin e pranuar të besimit, atëherë vlera e R konsiderohet e rëndësishme. Tabelat vlerat kritike F janë dhënë në librat e referencës për statistikat matematikore.
Kështu, rëndësia e R përcaktohet jo vetëm nga vlera e tij, por edhe nga marrëdhënia midis numrit të eksperimenteve dhe numrit të koeficientëve (parametrave) të modelit. Në të vërtetë, raporti i korrelacionit për n=2 për një model të thjeshtë linear është i barabartë me 1 (gjithmonë mund të vizatoni një vijë të vetme të drejtë përmes 2 pikave në një plan). Megjithatë, nëse të dhënat eksperimentale janë variablat e rastësishëm, kësaj vlere R duhet t'i besohet me shumë kujdes. Zakonisht, për të marrë një regresion të rëndësishëm R dhe të besueshëm, ata përpiqen të sigurojnë që numri i eksperimenteve të tejkalojë ndjeshëm numrin e koeficientëve të modelit (n>k).
Për të ndërtuar një lineare modeli i regresionit nevojshme:
1) përgatit një listë me n rreshta dhe m kolona që përmbajnë të dhëna eksperimentale (kolona që përmban vlerën e daljes Y duhet të jetë ose i pari ose i fundit në listë); Për shembull, le të marrim të dhënat nga detyra e mëparshme, duke shtuar një kolonë të quajtur "Nr. Periudha", numëroni numrat e periudhës nga 1 në 12. (këto do të jenë vlerat X)
2) shkoni te menyja Data/Analiza e të dhënave/Regresioni

Nëse artikulli "Analiza e të dhënave" në menynë "Mjetet" mungon, atëherë duhet të shkoni te artikulli "Shtesa" në të njëjtën meny dhe të kontrolloni kutinë e kontrollit "Paketa e analizës".
3) në kutinë e dialogut "Regresion", vendosni:
· intervali i hyrjes Y;
· intervali i hyrjes X;
· intervali i daljes - qeliza e sipërme e majtë e intervalit në të cilin do të vendosen rezultatet e llogaritjes (rekomandohet t'i vendosni ato në një fletë pune të re);

4) klikoni "Ok" dhe analizoni rezultatet.
Metoda e zakonshme e katrorëve më të vegjël (OLS). - metodë matematikore, përdoret për të zgjidhur detyra të ndryshme, bazuar në minimizimin e shumës së devijimeve në katror të disa funksioneve nga variablat e dëshiruar. Mund të përdoret për të "zgjidhur" sisteme ekuacionesh të mbipërcaktuara (kur numri i ekuacioneve tejkalon numrin e të panjohurave), për të gjetur një zgjidhje në rastin e atyre të zakonshme (jo të mbipërcaktuara). sistemet jolineare ekuacionet për përafrimin e vlerave të pikave të një funksioni të caktuar. OLS është një nga metodat bazë të analizës së regresionit për vlerësimin e parametrave të panjohur të modeleve të regresionit nga të dhënat e mostrës.
YouTube enciklopedik
1 / 5
✪ Metoda e katrorëve më të vegjël. Subjekti
✪ Metoda e katrorëve më të vegjël, mësimi 1/2. Funksioni linear
✪ Ekonometria. Leksioni 5. Metoda e katrorëve më të vegjël
✪ Mitin I.V - Përpunimi i rezultateve fizike. eksperiment - Metoda e katrorëve më të vegjël (Leksioni 4)
✪ Ekonometria: Thelbi i metodës së katrorëve më të vegjël #2
Titra
Histori
te fillimi i XIX V. shkencëtarët nuk kishin rregulla të caktuara për të zgjidhur një sistem ekuacionesh në të cilin numri i të panjohurave është më i vogël se numri i ekuacioneve; Deri në atë kohë, u përdorën teknika private, në varësi të llojit të ekuacioneve dhe zgjuarsisë së kalkulatorëve, dhe për këtë arsye kalkulatorë të ndryshëm, bazuar në të njëjtat të dhëna vëzhgimi, arritën në konkluzione të ndryshme. Gauss (1795) ishte përgjegjës për aplikimin e parë të metodës, dhe Lezhandre (1805) e zbuloi në mënyrë të pavarur dhe e publikoi atë nën emër modern(fr. Méthode des moindres quarrés) . Laplace e lidhi metodën me teorinë e probabilitetit dhe matematikani amerikan Adrain (1808) shqyrtoi aplikimet e saj në teorinë e probabilitetit. Metoda u përhap dhe u përmirësua nga kërkimet e mëtejshme nga Encke, Bessel, Hansen dhe të tjerë.
Thelbi i metodës së katrorëve më të vegjël
Le x (\displaystyle x)- komplet n (\displaystyle n) ndryshore të panjohura (parametra), f i (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- një grup funksionesh nga ky grup variablash. Detyra është të zgjidhni vlera të tilla x (\displaystyle x), në mënyrë që vlerat e këtyre funksioneve të jenë sa më afër vlerave të caktuara y i (\displaystyle y_(i)). Në thelb ne po flasim për për “zgjidhjen” e një sistemi ekuacionesh të mbipërcaktuar f i (x) = y i (\displaystyle f_(i)(x)=y_(i)), i = 1 , … , m (\style display i=1,\ldpiks ,m) në kuptimin e treguar të afërsisë maksimale të së majtës dhe pjesët e duhura sistemeve. Thelbi i metodës së katrorëve më të vegjël është të zgjedhësh si "masë afërsie" shumën e devijimeve në katror të anëve të majtë dhe të djathtë. | f i (x) − y i |
(\displaystyle |f_(i)(x)-y_(i)|).. Kështu, thelbi i MNC mund të shprehet si më poshtë: ∑ i e i 2 = ∑ i (y i − f i (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\shuma _(i)(y_(i)-f_( i)(x))^(2)\shigjeta djathtas \min _(x)) Nëse sistemi i ekuacioneve ka një zgjidhje, atëherë shuma minimale e katrorëve do të jetë e barabartë me zero dhe zgjidhjet e sakta të sistemit të ekuacioneve mund të gjenden në mënyrë analitike ose, për shembull, duke përdorur të ndryshme metodat numerike optimizimi. Nëse sistemi është i mbipërcaktuar, domethënë, thënë lirshëm, numri i ekuacioneve të pavarura x (\displaystyle x) më shumë sasi variablat e dëshiruar, atëherë sistemi nuk ka një zgjidhje të saktë dhe metoda e katrorëve më të vegjël na lejon të gjejmë një vektor "optimal". në kuptimin e afërsisë maksimale të vektorëve y (\displaystyle y) Dhe f (x) (\displaystyle f(x)) ose afërsia maksimale e vektorit të devijimit
e (\displaystyle e)
në zero (afërsia kuptohet në kuptimin e distancës Euklidiane). Shembull - sistemi i ekuacioneve lineare
Në veçanti, metoda e katrorëve më të vegjël mund të përdoret për të "zgjidhur" sistemin,Ku ekuacionet lineare A x = b (\displaystyle Ax=b) A (\displaystyle A) matricë drejtkëndëshe madhësia
m × n , m > n (\shfaqja m\herë n,m>n) (d.m.th. numri i rreshtave të matricës A është më i madh se numri i variablave të kërkuar). Një sistem i tillë ekuacionesh në x (\displaystyle x) rast i përgjithshëm nuk ka zgjidhje. Prandaj, ky sistem mund të "zgjidhet" vetëm në kuptimin e zgjedhjes së një vektori të tillë në kuptimin e afërsisë maksimale të vektorëve për të minimizuar "distancën" ndërmjet vektorëve A x (\displaystyle Axe) b (\displaystyle b). Për ta bërë këtë, mund të aplikoni kriterin e minimizimit të shumës së katrorëve të diferencave midis anës së majtë dhe të djathtë të ekuacioneve të sistemit, d.m.th. (A x − b) T (A x − b) → min (\style ekrani (Ax-b)^(T)(Ax-b)\shigjeta djathtas \min ). Është e lehtë të tregosh se zgjidhja e këtij problemi të minimizimit çon në zgjidhje
sistemin e ardhshëm.ekuacionet
A T A x = A T b ⇒ x = (A T A) − 1 A T b (\displaystyle A^(T)Ax=A^(T)b\Djathtas shigjeta x=(A^(T)A)^(-1)A^ (T)b) n (\displaystyle n) OLS në analizën e regresionit (përafrimi i të dhënave) variablat e dëshiruar, atëherë sistemi nuk ka një zgjidhje të saktë dhe metoda e katrorëve më të vegjël na lejon të gjejmë një vektor "optimal". Le të ketë x (\displaystyle x) vlerat e disa ndryshoreve variablat e dëshiruar, atëherë sistemi nuk ka një zgjidhje të saktë dhe metoda e katrorëve më të vegjël na lejon të gjejmë një vektor "optimal". në kuptimin e afërsisë maksimale të vektorëve x (\displaystyle x)(kjo mund të jetë rezultat i vëzhgimeve, eksperimenteve, etj.) dhe variablave të lidhur për të minimizuar "distancën" ndërmjet vektorëve. Sfida është të sigurohet që marrëdhënia ndërmjet vlerat më të mira parametrave për të minimizuar "distancën" ndërmjet vektorëve, duke përafruar maksimalisht vlerat f (x , b) (\displaystyle f(x,b)) ndaj vlerave reale variablat e dëshiruar, atëherë sistemi nuk ka një zgjidhje të saktë dhe metoda e katrorëve më të vegjël na lejon të gjejmë një vektor "optimal".. Në fakt, kjo zbret në rastin e "zgjidhjes" së një sistemi të mbipërcaktuar ekuacionesh në lidhje me për të minimizuar "distancën" ndërmjet vektorëve:
F (x t , b) = y t , t = 1 , ... , n (\shfaqja e stilit f(x_(t),b)=y_(t),t=1,\ldpika ,n).
Në analizën e regresionit dhe në veçanti në ekonometri, modele probabiliste varësitë ndërmjet variablave
Y t = f (x t, b) + ε t (\stil ekrani y_(t)=f(x_(t),b)+\varepsilon _(t)),
Ku ε t (\displaystyle \varepsilon _(t))- të ashtuquajturat gabime të rastësishme modele.
Prandaj, devijimet e vlerave të vëzhguara variablat e dëshiruar, atëherë sistemi nuk ka një zgjidhje të saktë dhe metoda e katrorëve më të vegjël na lejon të gjejmë një vektor "optimal". nga modeli f (x , b) (\displaystyle f(x,b)) supozohet tashmë në vetë modelin. Thelbi i metodës së katrorëve më të vegjël (e zakonshme, klasike) është gjetja e parametrave të tillë për të minimizuar "distancën" ndërmjet vektorëve, në të cilën shuma e devijimeve në katror (gabimet, për modelet e regresionit ato shpesh quhen mbetje regresioni) e t (\displaystyle e_(t)) do të jetë minimale:
b ^ O L S = arg min b R S S (b) (\shfaqja e stilit (\kapelë (b))_(OLS)=\arg \min _(b)RSS(b)),Ku R S S (\displaystyle RSS)- Anglisht Shuma e mbetur e katrorëve përcaktohet si:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\shuma _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).Në rastin e përgjithshëm, ky problem mund të zgjidhet me metodat e optimizimit (minimizimit) numerik. Në këtë rast ata flasin për katrorët më të vegjël jolinearë(NLS ose NLLS - Katroret më të vogla jo-lineare angleze). Në shumë raste mund të merrni zgjidhje analitike. Për të zgjidhur problemin e minimizimit është e nevojshme të gjendet pika të palëvizshme funksionet R S S (b) (\displaystyle RSS(b)), duke e diferencuar sipas parametrave të panjohur për të minimizuar "distancën" ndërmjet vektorëve, duke barazuar derivatet me zero dhe duke zgjidhur sistemin rezultues të ekuacioneve:
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\i pjesshëm f(x_(t),b))(\i pjesshëm b))=0).OLS në rastin e regresionit linear
Varësia e regresionit le të jetë lineare:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).Le yështë vektori i kolonës së vëzhgimeve të ndryshores që shpjegohet, dhe X (\displaystyle X)- Kjo (n × k) (\style ekrani ((n\herë k)))- matrica e vëzhgimeve të faktorëve (rreshtat e matricës janë vektorë të vlerave të faktorëve në këtë vëzhgim, sipas kolonave - vektor i vlerave këtë faktor në të gjitha vëzhgimet). Paraqitja matricore e modelit linear ka formën:
y = X b + ε (\displaystyle y=Xb+\varepsilon ).Atëherë vektori i vlerësimeve të ndryshores së shpjeguar dhe vektori i mbetjeve të regresionit do të jenë të barabartë
y ^ = X b , e = y − y ^ = y − X b (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).Prandaj, shuma e katrorëve të mbetjeve të regresionit do të jetë e barabartë me
R S S = e T e = (y − X b) T (y − X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Diferencimi i këtij funksioni në lidhje me vektorin e parametrave për të minimizuar "distancën" ndërmjet vektorëve dhe duke barazuar derivatet me zero, marrim një sistem ekuacionesh (në forma matrice):
(X T X) b = X T y (\style ekrani (X^(T)X)b=X^(T)y).Në formën e matricës së deshifruar, ky sistem ekuacionesh duket si ky:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x 3 x ∑ t x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b k 3 = ⋮ b ∑ x t 3 y t ⋮ ∑ x t k y t) , (\displaystyle (\fille(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\shuma x_(t1)x_(tk)\\\ shuma x_(t2)x_(t1)&\ shuma x_(t2)^(2)&\ shuma x_(t2)x_(t3)&\ldots &\ shuma x_(t2)x_(tk)\\\ shuma x_(t3)x_(t1)&\ shuma x_(t3) x_(t2)&\ shuma x_(t3)^(2)&\ldots &\ shuma x_ (t3)x_(tk)\\\vdots &\vdots &\vdots &\ddots &\vdots \\\ shuma x_(tk)x_(t1)&\ shuma x_(tk)x_(t2)&\ shuma x_ (tk)x_(t3)&\ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\fille(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\ vdots \\b_(k)\\\ fund (pmatrix))=(\fille(pmatrix)\sum x_(t1)y_(t)\\\ shuma x_(t2)y_(t)\\ \shuma x_(t3)y_(t)\\\vpika \\\ shuma x_(tk)y_(t)\\\fund (pmatrix)),) ku merren të gjitha shumat për të gjithë vlerat e pranueshme t (\displaystyle t).
Nëse një konstante përfshihet në model (si zakonisht), atëherë x t 1 = 1 (\displaystyle x_(t1)=1) para të gjithëve t (\displaystyle t), pra në të majtë këndi i sipërm matrica e sistemit të ekuacioneve është numri i vëzhgimeve n (\displaystyle n), dhe në elementët e mbetur të rreshtit të parë dhe kolonës së parë - thjesht shumat e vlerave të variablave: ∑ x t j (\displaystyle \shuma x_(tj)) dhe elementi i parë i anës së djathtë të sistemit është ∑ y t (\displaystyle \shuma y_(t)).
Zgjidhja e këtij sistemi ekuacionesh jep formulë e përgjithshme Vlerësimet OLS për modelin linear:
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y (\kapelë (b))_(OLS)=(X^(T )X)^(-1)X^(T)y=\majtas((\frac (1)(n))X^(T)X\djathtas)^(-1)(\frac (1)(n )) X^(T)y=V_(x)^(-1)C_(xy)).Për qëllime analitike, paraqitja e fundit e kësaj formule rezulton e dobishme (në sistemin e ekuacioneve kur pjesëtohet me n, në vend të shumave shfaqen mesataret aritmetike). Nëse në një model regresioni të dhënat të përqendruar, atëherë në këtë paraqitje matrica e parë ka kuptimin e një matrice modeli të kovariancës së faktorëve, dhe e dyta është një vektor i kovariancave të faktorëve me variablin e varur. Nëse përveç kësaj të dhënat janë gjithashtu normalizuar te MSE (domethënë në fund të fundit të standardizuara), atëherë matrica e parë ka kuptimin e një kampioni matrica e korrelacionit faktorët, vektori i dytë është vektori i korrelacioneve mostër të faktorëve me variablin e varur.
Një veti e rëndësishme e vlerësimeve të OLS për modelet me konstante- linja e ndërtuar e regresionit kalon nëpër qendrën e gravitetit të të dhënave të mostrës, domethënë plotësohet barazia:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\kapelë (b))_(j)(\bar (x))_(j)).Në veçanti, në si mjet i fundit, kur i vetmi regresor është një konstante, marrim atë vlerësues OLS parametër i vetëm(vetë konstanta) është e barabartë me vlerën mesatare të ndryshores së shpjeguar. Kjo është, mesatarja aritmetike, e njohur për të veti të mira nga ligjet numra të mëdhenj, është gjithashtu një vlerësim i katrorëve më të vegjël - ai plotëson kriterin e shumës minimale të devijimeve në katror prej tij.
Rastet më të thjeshta të veçanta
Në rastin e regresionit linear të çiftuar y t = a + b x t + ε t (\stil ekrani y_(t)=a+bx_(t)+\varepsilon _(t)) kur vlerësohet varësia lineare një variabël nga një tjetër, formulat e llogaritjes janë thjeshtuar (mund të bëni pa algjebër matricë). Sistemi i ekuacioneve ka formën:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2))\\\end(pmatrix))(\fille(pmatrix)a\\b\\\end(pmatrix))=(\fille(pmatrix)(\bar (y))\\ (\overline (xy))\\\fund (pmatrix))).Nga këtu është e lehtë të gjesh vlerësimet e koeficientëve:
(b ^ = Cov (x, y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2, a ^ = y ¯ − b x ¯ . (\displaystyle (\fillimi(rastet) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline (xy))-(\bar (x))(\bar (y)))(\overline (x^(2)))-(\overline (x))^(2)),\\( \hat (a))=(\bar (y))-b(\bar (x)).\fund (raste)))Pavarësisht se në rastin e përgjithshëm preferohen modelet me konstante, në disa raste dihet nga konsideratat teorike se një konstante a (\displaystyle a) duhet të jetë e barabartë me zero. Për shembull, në fizikë marrëdhënia midis tensionit dhe rrymës është U = I ⋅ R (\displaystyle U=I\cdot R); Kur matni tensionin dhe rrymën, është e nevojshme të vlerësoni rezistencën. Në këtë rast, ne po flasim për modelin y = b x (\displaystyle y=bx). Në këtë rast, në vend të sistemit të ekuacioneve kemi ekuacioni i vetëm
(∑ x t 2) b = ∑ x t y t (\displaystyle \majtas(\shuma x_(t)^(2)\djathtas)b=\shuma x_(t)y_(t)).
Prandaj, formula për vlerësimin e koeficientit të vetëm ka formën
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t )y_(t))(\shuma _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Rasti i një modeli polinom
Nëse të dhënat përshtaten me një funksion regresioni polinomial të një ndryshoreje f (x) = b 0 + ∑ i = 1 k b i x i (\displaystyle f(x)=b_(0)+\sum \ limitet _(i=1)^(k)b_(i)x^(i)), pastaj, perceptimi i shkallëve x i (\displaystyle x^(i)) si faktorë të pavarur për secilin i (\displaystyle i)është e mundur të vlerësohen parametrat e modelit bazuar në formulën e përgjithshme për vlerësimin e parametrave të një modeli linear. Për ta bërë këtë, mjafton të merret parasysh në formulën e përgjithshme që me një interpretim të tillë x t i x t j = x t i x t j = x t i + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j)) në kuptimin e afërsisë maksimale të vektorëve x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). Prandaj, ekuacionet e matricës V në këtë rast do të marrë formën:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ k ] b n y t ∑ n t y t ⋮ ∑ n x t k y t ] .
(\displaystyle (\begin(pmatrix)n&\sum \ limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\sum \ limits _( n)x_(t)&\sum \ limitet _(n)x_(t)^(2)&\ldots &\sum \ limitet _(n)x_(t)^(k+1)\\\vpika & \vdots &\ddots &\vdots \\\ shuma \ limitet _(n)x_(t)^(k)&\sum \ limitet _(n)x_(t)^(k+1)&\ldots &\ shuma \limits _(n)x_(t)^(2k)\end(pmatrix))(\fille(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\fund(bmatrix)).)
Vetitë statistikore të vlerësuesve OLS Para së gjithash, vërejmë se për modelet lineare vlerësimet OLS janë vlerësime lineare , siç vijon nga formula e mësipërme. Për vlerësime të paanshme OLS, është e nevojshme dhe e mjaftueshme për të kryer kushti më i rëndësishëm Analiza e regresionit: e kushtëzuar nga faktorët, pritshmëria matematikore e një gabimi të rastësishëm duhet të jetë e barabartë me zero. Kjo gjendje
- , në veçanti, është i kënaqur nëse pritje matematikore gabime të rastësishme
- barazohet me zero, dhe
faktorët dhe gabimet e rastësishme janë variabla të pavarur-të rastësishëm. Kushti i dytë - kushti i ekzogjenitetit të faktorëve - është themelor. Nëse kjo pronë nuk është e kënaqur, atëherë mund të supozojmë se pothuajse çdo vlerësim do të jetë jashtëzakonisht i pakënaqshëm: ato nuk do të jenë as të qëndrueshme (d.m.th., madje edhe shumë vëllim i madh të dhënat nuk lejojnë të merren vlerësimet cilësore në këtë rast). Në rastin klasik, bëhet një supozim më i fortë për determinizmin e faktorëve, në krahasim me një gabim të rastësishëm, që automatikisht do të thotë se plotësohet kushti i ekzogjenitetit. Në rastin e përgjithshëm, për konsistencën e vlerësimeve, mjafton të plotësohet kushti i ekzogjenitetit së bashku me konvergjencën e matricës V x (\displaystyle V_(x))
në një matricë jo njëjës ndërsa madhësia e kampionit rritet deri në pafundësi.
Në mënyrë që, përveç konsistencës dhe paanshmërisë, vlerësimet e katrorëve më të vegjël (të zakonshëm) të jenë gjithashtu efektivë (më të mirët në klasën e vlerësimeve lineare të paanshme), duhet të plotësohen vetitë shtesë të gabimit të rastësishëm: Këto supozime mund të formulohen për matricën e kovariancës së vektorit të gabimit të rastësishëm.
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Një model linear që plotëson këto kushte quhet. Vlerësimet OLS për regresionin linear klasik janë të paanshme, të qëndrueshme dhe vlerësimet më efektive në klasën e të gjitha vlerësimeve lineare të paanshme (në literaturën angleze shkurtimi përdoret ndonjëherë BLU (Vlerësuesi më i mirë linear i paanshëm) - vlerësimi më i mirë linear i paanshëm; V Letërsia ruse më shpesh citohet teorema Gauss-Markov). Siç është e lehtë të tregohet, matrica e kovariancës së vektorit të vlerësimeve të koeficientëve do të jetë e barabartë me:
V (b ^ O L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
Efikasiteti do të thotë që kjo matricë e kovariancës është "minimale" (çdo kombinim linear i koeficientëve, dhe në veçanti vetë koeficientët, kanë variancë minimale), domethënë, në klasën e vlerësuesve linearë të paanshëm, vlerësuesit OLS janë më të mirët. Elementet diagonale të kësaj matrice janë variancat e vlerësimeve të koeficientëve - parametra të rëndësishëm cilësinë e vlerësimeve të marra. Megjithatë, nuk është e mundur të llogaritet matrica e kovariancës sepse varianca e gabimit të rastësishëm është e panjohur. Mund të vërtetohet se një vlerësim i paanshëm dhe konsistent (për një model linear klasik) i variancës së gabimeve të rastit është sasia:
S 2 = R S S / (n − k) (\stil ekrani s^(2)=RSS/(n-k)).
Duke e zëvendësuar këtë vlerë në formulën për matricën e kovariancës, marrim një vlerësim të matricës së kovariancës. Vlerësimet që rezultojnë janë gjithashtu të paanshme dhe të qëndrueshme. Është gjithashtu e rëndësishme që vlerësimi i variancës së gabimit (dhe rrjedhimisht varianca e koeficientëve) dhe vlerësimet e parametrave të modelit të jenë variabla të rastësishëm të pavarur, gjë që bën të mundur marrjen e statistikave të testit për testimin e hipotezave për koeficientët e modelit.
Duhet të theksohet se nëse supozimet klasike nuk përmbushen, vlerësimet e parametrave OLS nuk janë më efikaset dhe, ku W (\displaystyle W)është një matricë simetrike pozitive e caktuar e peshës. Sheshet më të vogla konvencionale janë një rast i veçantë i kësaj qasjeje, ku matrica e peshës është proporcionale me matricën e identitetit. Siç dihet, për matricat (ose operatorët) simetrik ka një zgjerim W = P T P (\shfaqje stil W=P^(T)P). Prandaj, funksioni i specifikuar mund të përfaqësohet si më poshtë e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), domethënë, ky funksional mund të përfaqësohet si shuma e katrorëve të disa "mbeturave" të transformuara. Kështu, ne mund të dallojmë një klasë të metodave të katrorëve më të vegjël - metodat LS (Katroret më të vegjël).
Është vërtetuar (teorema e Aitken) se për një model të përgjithësuar të regresionit linear (në të cilin nuk vendosen kufizime në matricën e kovariancës së gabimeve të rastit), më efektive (në klasën e vlerësimeve lineare të paanshme) janë të ashtuquajturat vlerësime. katrorët më të vegjël të përgjithësuar (GLS - katrorët më të vegjël të përgjithësuar)- Metoda LS me një matricë peshe të barabartë me matricën e kovariancës së kundërt të gabimeve të rastit: W = V ε - 1 (\displaystyle W=V_(\varepsilon )^(-1)).
Mund të tregohet se formula për vlerësimet GLS të parametrave të një modeli linear ka formën
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
Në përputhje me rrethanat, matrica e kovariancës së këtyre vlerësimeve do të jetë e barabartë me
V (b ^ G L S) = (X T V − 1 X) − 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
Në fakt, thelbi i OLS qëndron në një transformim të caktuar (linear) (P) të të dhënave origjinale dhe aplikimin e OLS të zakonshme në të dhënat e transformuara. Qëllimi i këtij transformimi është që për të dhënat e transformuara, gabimet e rastësishme tashmë plotësojnë supozimet klasike.
OLS me peshë
Në rastin e një matrice të peshës diagonale (dhe për rrjedhojë e një matrice të kovariancës së gabimeve të rastit), kemi të ashtuquajturat katrorët më të vegjël të ponderuar (WLS). Në këtë rast, shuma e ponderuar e katrorëve të mbetjeve të modelit minimizohet, domethënë, çdo vëzhgim merr një "peshë" që është në përpjesëtim të zhdrejtë me variancën e gabimit të rastësishëm në këtë vëzhgim: e T W e = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma_(t)^(2)))). Në fakt, të dhënat transformohen duke peshuar vëzhgimet (duke pjesëtuar me një shumë proporcionale me atë të pritur devijimi standard gabime të rastësishme), dhe OLS e zakonshme zbatohet për të dhënat e ponderuara.
ISBN 978-5-7749-0473-0.
Një nga metodat për studimin e marrëdhënieve stokastike midis karakteristikave është analiza e regresionit.
Analiza e regresionit është derivimi i një ekuacioni regresioni që përdoret për të gjetur vlera mesatare një ndryshore e rastësishme (atribut rezultati) nëse dihet vlera e një ndryshoreje tjetër (ose të tjera) (atribute-faktor). Ai përfshin hapat e mëposhtëm:
- përzgjedhja e formës së lidhjes (lloji i ekuacionit të regresionit analitik);
- vlerësimi i parametrave të ekuacionit;
- vlerësimi i cilësisë së ekuacionit të regresionit analitik.
Në rastin e një lidhjeje lineare dyshe, ekuacioni i regresionit do të marrë formën: y i =a+b·x i +u i . Opsionet ekuacioni i dhënë a dhe b janë vlerësuar nga të dhënat vëzhgimi statistikor x dhe y. Rezultati i një vlerësimi të tillë është ekuacioni: , ku , janë vlerësimet e parametrave a dhe b , është vlera e atributit rezultues (variabli) i marrë nga ekuacioni i regresionit (vlera e llogaritur).
Më shpesh përdoret për të vlerësuar parametrat metoda e katrorëve më të vogël (LSM).
Metoda e katrorëve më të vegjël siguron vlerësimet më të mira (të qëndrueshme, efikase dhe të paanshme) të parametrave të ekuacionit të regresionit. Por vetëm nëse plotësohen supozime të caktuara në lidhje me termin e rastësishëm (u) dhe variablin e pavarur (x) (shih supozimet OLS).
Problemi i vlerësimit të parametrave të një ekuacioni të çiftit linear duke përdorur metodën e katrorëve më të vegjëlështë si më poshtë: merrni vlerësime të tilla të parametrave, , për të cilat shuma e devijimeve në katror vlerat aktuale atributi efektiv - y i nga vlerat e llogaritura - është minimal.
Formalisht Kriteri OLS mund të shkruhet kështu:  .
.
Klasifikimi i metodave të katrorëve më të vegjël
- Metoda e katrorëve më të vegjël.
- Metoda gjasat maksimale(për një model klasik të regresionit linear normal, është postuluar normaliteti i mbetjeve të regresionit).
- Metoda e përgjithësuar e katrorëve më të vegjël OLS përdoret në rastin e autokorrelacionit të gabimeve dhe në rastin e heteroskedasticitetit.
- Metoda e katrorëve më të vegjël të ponderuar ( rast i veçantë OLS me mbetje heteroskedastike).
Le të ilustrojmë çështjen metodë klasike katrorët më të vegjël grafikisht. Për ta bërë këtë, ne do të ndërtojmë një grafik shpërndarjeje bazuar në të dhënat e vëzhgimit (x i, y i, i=1;n) në sistem drejtkëndor koordinatat (një grafik i tillë pikash quhet fushë korrelacioni). Le të përpiqemi të gjejmë një vijë të drejtë që është më afër pikave fushë korrelacioni. Sipas metodës së katrorëve më të vegjël, vija zgjidhet në mënyrë që shuma e katrorëve të distancave vertikale ndërmjet pikave të fushës së korrelacionit dhe kësaj linje të jetë minimale. 
Shënimi matematikor për këtë problem:  .
.
Vlerat e y i dhe x i =1...n janë të njohura për ne; Në funksionin S ato paraqesin konstante. Variablat në këtë funksion janë vlerësimet e kërkuara të parametrave - , . Për të gjetur minimumin e një funksioni të dy variablave, është e nevojshme të llogariten derivatet e pjesshme të këtij funksioni për secilin prej parametrave dhe t'i barazojmë me zero, d.m.th. 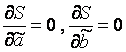 .
.
Si rezultat, marrim një sistem prej 2 ekuacionesh normale lineare: 
Duke zgjidhur këtë sistem, gjejmë vlerësimet e kërkuara të parametrave: 
Korrektësia e llogaritjes së parametrave të ekuacionit të regresionit mund të kontrollohet duke krahasuar shumat (mund të ketë disa mospërputhje për shkak të rrumbullakimit të llogaritjeve).
Për të llogaritur vlerësimet e parametrave, mund të ndërtoni Tabelën 1.
Shenja e koeficientit të regresionit b tregon drejtimin e marrëdhënies (nëse b >0, marrëdhënia është e drejtpërdrejtë, nëse b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formalisht, vlera e parametrit a është vlera mesatare e y me x e barabartë me zero. Nëse atributi-faktor nuk ka dhe nuk mund të ketë një vlerë zero, atëherë interpretimi i mësipërm i parametrit a nuk ka kuptim.
Vlerësimi i afërsisë së marrëdhënies ndërmjet karakteristikave
kryhet duke përdorur koeficientin e korrelacionit të çiftit linear - r x,y. Mund të llogaritet duke përdorur formulën:  . Përveç kësaj, koeficienti i korrelacionit të çiftit linear mund të përcaktohet përmes koeficientit të regresionit b:
. Përveç kësaj, koeficienti i korrelacionit të çiftit linear mund të përcaktohet përmes koeficientit të regresionit b:  .
.
Gama e vlerave të pranueshme të koeficientit të korrelacionit të çiftit linear është nga -1 në +1. Shenja e koeficientit të korrelacionit tregon drejtimin e marrëdhënies. Nëse r x, y >0, atëherë lidhja është e drejtpërdrejtë; nëse r x, y<0, то связь обратная.
Nëse ky koeficient është afër unitetit në madhësi, atëherë marrëdhënia midis karakteristikave mund të interpretohet si një linjë mjaft e ngushtë. Nëse moduli i tij është i barabartë me një ê r x, y ê =1, atëherë lidhja ndërmjet karakteristikave është funksionale lineare. Nëse tiparet x dhe y janë linearisht të pavarura, atëherë r x,y është afër 0.
Për të llogaritur r x, y, mund të përdorni gjithashtu tabelën 1.
Tabela 1
| N vëzhgime | x i | y i | x i ∙y i | ||
| 1 | x 1 | y 1 | x 1 y 1 | ||
| 2 | x 2 | y 2 | x 2 y 2 | ||
| ... | |||||
| n | x n | y n | x n y n | ||
| Shuma e kolonës | ∑x | ∑y | ∑xy | ||
| Vlera mesatare |
|
|
 ,
,
ku d 2 është varianca e y e shpjeguar nga ekuacioni i regresionit;
e 2 - varianca e mbetur (e pashpjegueshme nga ekuacioni i regresionit) të y;
s 2 y - varianca totale (totali) e y.
Koeficienti i përcaktimit karakterizon proporcionin e variacionit (dispersionit) të atributit rezultant y të shpjeguar me regresion (dhe, rrjedhimisht, faktorin x) në variacionin total (dispersion) y. Koeficienti i përcaktimit R 2 yx merr vlera nga 0 në 1. Prandaj, vlera 1-R 2 yx karakterizon proporcionin e variancës y të shkaktuar nga ndikimi i faktorëve të tjerë që nuk merren parasysh në model dhe gabimet e specifikimit.
Me regresion linear të çiftuar, R 2 yx =r 2 yx.
Metoda e katrorëve më të vegjël
Metoda e katrorit më të vogël ( OLS, OLS, katrorët më të vegjël të zakonshëm) - një nga metodat bazë të analizës së regresionit për vlerësimin e parametrave të panjohur të modeleve të regresionit duke përdorur të dhënat e mostrës. Metoda bazohet në minimizimin e shumës së katrorëve të mbetjeve të regresionit.
Duhet të theksohet se vetë metoda e katrorëve më të vegjël mund të quhet metodë për zgjidhjen e një problemi në çdo fushë nëse zgjidhja qëndron ose plotëson ndonjë kriter për minimizimin e shumës së katrorëve të disa funksioneve të ndryshoreve të kërkuara. Prandaj, metoda e katrorëve më të vegjël mund të përdoret gjithashtu për një paraqitje të përafërt (përafrim) të një funksioni të caktuar me funksione të tjera (më të thjeshta), kur gjendet një grup sasish që plotësojnë ekuacionet ose kufizimet, numri i të cilave e kalon numrin e këtyre sasive. , etj.
Thelbi i MNC
Le të jepet një model (parametrik) i një marrëdhënieje probabilistike (regresioni) midis ndryshores (e shpjeguar). y dhe shumë faktorë (variabla shpjegues) x
ku është vektori i parametrave të modelit të panjohur
- gabim i rastësishëm i modelit.Le të ketë edhe vëzhgime mostër të vlerave të këtyre variablave. Le të jetë numri i vëzhgimit (). Pastaj janë vlerat e variablave në vëzhgimin e th. Pastaj, për vlerat e dhëna të parametrave b, është e mundur të llogariten vlerat teorike (modele) të ndryshores së shpjeguar y:
Madhësia e mbetjeve varet nga vlerat e parametrave b.
Thelbi i metodës së katrorëve më të vegjël (e zakonshme, klasike) është gjetja e parametrave b për të cilët shuma e katrorëve të mbetjeve (eng. Shuma e mbetur e katrorëve) do të jetë minimale:
Në rastin e përgjithshëm, ky problem mund të zgjidhet me metodat e optimizimit (minimizimit) numerik. Në këtë rast ata flasin për katrorët më të vegjël jolinearë(NLS ose NLLS - Anglisht) Sheshet më të vogla jo-lineare). Në shumë raste është e mundur të merret një zgjidhje analitike. Për të zgjidhur problemin e minimizimit, është e nevojshme të gjenden pikat stacionare të funksionit duke e diferencuar atë në lidhje me parametrat e panjohur b, duke barazuar derivatet në zero dhe duke zgjidhur sistemin rezultues të ekuacioneve:
Nëse gabimet e rastësishme të modelit shpërndahen normalisht, kanë të njëjtën variancë dhe janë të pakorreluara, vlerësimet e parametrave OLS janë të njëjta me vlerësimet e gjasave maksimale (MLM).
OLS në rastin e një modeli linear
Varësia e regresionit le të jetë lineare:
Le yështë një vektor kolone e vëzhgimeve të ndryshores së shpjeguar dhe është një matricë e vëzhgimeve të faktorëve (rreshtet e matricës janë vektorët e vlerave të faktorëve në një vëzhgim të caktuar, kolonat janë vektori i vlerave të një faktori të caktuar në të gjitha vëzhgimet). Paraqitja matricore e modelit linear është:
Atëherë vektori i vlerësimeve të ndryshores së shpjeguar dhe vektori i mbetjeve të regresionit do të jenë të barabartë
Prandaj, shuma e katrorëve të mbetjeve të regresionit do të jetë e barabartë me
Duke e diferencuar këtë funksion në lidhje me vektorin e parametrave dhe duke barazuar derivatet me zero, marrim një sistem ekuacionesh (në formë matrice):
.Zgjidhja e këtij sistemi ekuacionesh jep formulën e përgjithshme për vlerësimet e katrorëve më të vegjël për një model linear:
Për qëllime analitike, paraqitja e fundit e kësaj formule është e dobishme. Nëse në një model regresioni të dhënat të përqendruar, atëherë në këtë paraqitje matrica e parë ka kuptimin e një matrice modeli të kovariancës së faktorëve, dhe e dyta është një vektor i kovariancave të faktorëve me variablin e varur. Nëse përveç kësaj të dhënat janë gjithashtu normalizuar te MSE (domethënë në fund të fundit të standardizuara), atëherë matrica e parë ka kuptimin e një matrice të korrelacionit të mostrës së faktorëve, vektori i dytë - një vektor i korrelacioneve mostër të faktorëve me variablin e varur.
Një veti e rëndësishme e vlerësimeve të OLS për modelet me konstante- linja e ndërtuar e regresionit kalon nëpër qendrën e gravitetit të të dhënave të mostrës, domethënë plotësohet barazia:
Në veçanti, në rastin ekstrem, kur i vetmi regresor është një konstante, gjejmë se vlerësimi OLS i parametrit të vetëm (vetë konstanta) është i barabartë me vlerën mesatare të ndryshores së shpjeguar. Kjo do të thotë, mesatarja aritmetike, e njohur për vetitë e saj të mira nga ligjet e numrave të mëdhenj, është gjithashtu një vlerësim i katrorëve më të vegjël - ai plotëson kriterin e shumës minimale të devijimeve në katror prej tij.
Shembull: regresioni më i thjeshtë (në çift).
Në rastin e regresionit linear të çiftuar, formulat e llogaritjes janë thjeshtuar (mund të bëni pa algjebër matricë):
Vetitë e vlerësuesve OLS
Para së gjithash, vërejmë se për modelet lineare, vlerësimet OLS janë vlerësime lineare, siç vijon nga formula e mësipërme. Për vlerësimet e paanshme OLS, është e nevojshme dhe e mjaftueshme të përmbushet kushti më i rëndësishëm i analizës së regresionit: pritshmëria matematikore e një gabimi të rastësishëm, e kushtëzuar nga faktorët, duhet të jetë e barabartë me zero. Ky kusht, në veçanti, plotësohet nëse
- pritshmëria matematikore e gabimeve të rastësishme është zero, dhe
- faktorët dhe gabimet e rastësishme janë variabla të rastësishme të pavarura.
Kushti i dytë - kushti i ekzogjenitetit të faktorëve - është themelor. Nëse kjo pronë nuk plotësohet, atëherë mund të supozojmë se pothuajse çdo vlerësim do të jetë jashtëzakonisht i pakënaqshëm: ato as nuk do të jenë të qëndrueshme (d.m.th., edhe një sasi shumë e madhe e të dhënave nuk na lejon të marrim vlerësime me cilësi të lartë në këtë rast ). Në rastin klasik, bëhet një supozim më i fortë për determinizmin e faktorëve, në krahasim me një gabim të rastësishëm, që automatikisht do të thotë se plotësohet kushti i ekzogjenitetit. Në rastin e përgjithshëm, për konsistencën e vlerësimeve, mjafton të plotësohet kushti i ekzogjenitetit së bashku me konvergjencën e matricës me një matricë jo të vetme, ndërsa madhësia e kampionit rritet deri në pafundësi.
në një matricë jo njëjës ndërsa madhësia e kampionit rritet deri në pafundësi.
Këto supozime mund të formulohen për matricën e kovariancës së vektorit të gabimit të rastësishëm
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Një model linear që plotëson këto kushte quhet. Vlerësimet OLS për regresionin linear klasik janë të paanshme, të qëndrueshme dhe vlerësimet më efektive në klasën e të gjitha vlerësimeve lineare të paanshme (në literaturën angleze shkurtimi përdoret ndonjëherë BLU (Vlerësuesi më i mirë linear i pabazuar) - vlerësimi më i mirë linear i paanshëm; në literaturën ruse më shpesh citohet teorema e Gauss-Markov). Siç është e lehtë të tregohet, matrica e kovariancës së vektorit të vlerësimeve të koeficientëve do të jetë e barabartë me:
OLS e përgjithësuar
Metoda e katrorëve më të vegjël lejon një përgjithësim të gjerë. Në vend që të minimizohet shuma e katrorëve të mbetjeve, mund të minimizohet një formë e caktuar kuadratike pozitive e vektorit të mbetjeve, ku është një matricë simetrike e peshës së caktuar pozitive. Sheshet më të vogla konvencionale janë një rast i veçantë i kësaj qasjeje, ku matrica e peshës është proporcionale me matricën e identitetit. Siç dihet nga teoria e matricave (ose operatorëve) simetrike, për matrica të tilla ka një zbërthim. Rrjedhimisht, funksioni i specifikuar mund të përfaqësohet si më poshtë, domethënë, ky funksional mund të përfaqësohet si shuma e katrorëve të disa "mbetjeve" të transformuara. Kështu, ne mund të dallojmë një klasë të metodave të katrorëve më të vegjël - metodat LS (Katroret më të vegjël).
Është vërtetuar (teorema e Aitken) se për një model të përgjithësuar të regresionit linear (në të cilin nuk vendosen kufizime në matricën e kovariancës së gabimeve të rastit), më efektive (në klasën e vlerësimeve lineare të paanshme) janë të ashtuquajturat vlerësime. katrorët më të vegjël të përgjithësuar (GLS - katrorët më të vegjël të përgjithësuar)- Metoda LS me matricë peshe të barabartë me matricën e kovariancës së kundërt të gabimeve të rastit: .
Mund të tregohet se formula për vlerësimet GLS të parametrave të një modeli linear ka formën
Në përputhje me rrethanat, matrica e kovariancës së këtyre vlerësimeve do të jetë e barabartë me
Në fakt, thelbi i OLS qëndron në një transformim të caktuar (linear) (P) të të dhënave origjinale dhe aplikimin e OLS të zakonshme në të dhënat e transformuara. Qëllimi i këtij transformimi është që për të dhënat e transformuara, gabimet e rastësishme tashmë plotësojnë supozimet klasike.
OLS me peshë
Në rastin e një matrice të peshës diagonale (dhe për rrjedhojë e një matrice të kovariancës së gabimeve të rastit), kemi të ashtuquajturat katrorët më të vegjël të ponderuar (WLS). Në këtë rast, shuma e ponderuar e katrorëve të mbetjeve të modelit minimizohet, domethënë, çdo vëzhgim merr një "peshë" që është në përpjesëtim të zhdrejtë me variancën e gabimit të rastit në këtë vëzhgim: . Në fakt, të dhënat transformohen duke peshuar vëzhgimet (duke pjesëtuar me një shumë proporcionale me devijimin standard të vlerësuar të gabimeve të rastit), dhe OLS e zakonshme zbatohet për të dhënat e ponderuara.
Disa raste të veçanta të përdorimit të MNC në praktikë
Përafrimi i varësisë lineare
Le të shqyrtojmë rastin kur, si rezultat i studimit të varësisë së një sasie të caktuar skalare nga një sasi e caktuar skalare (Kjo mund të jetë, për shembull, varësia e tensionit nga forca aktuale: , ku është një vlerë konstante, rezistenca e përcjellësi), u kryen matjet e këtyre sasive, si rezultat i të cilave vlerat dhe vlerat përkatëse të tyre. Të dhënat e matjes duhet të regjistrohen në një tabelë.
Tabela. Rezultatet e matjes.
| Matja nr. | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
Pyetja është: cila vlerë e koeficientit mund të zgjidhet për të përshkruar më mirë varësinë? Sipas metodës së katrorëve më të vegjël, kjo vlerë duhet të jetë e tillë që shuma e devijimeve në katror të vlerave nga vlerat
ishte minimale
Shuma e devijimeve në katror ka një ekstrem - një minimum, i cili na lejon të përdorim këtë formulë. Le të gjejmë nga kjo formulë vlerën e koeficientit. Për ta bërë këtë, ne transformojmë anën e saj të majtë si më poshtë:
Formula e fundit na lejon të gjejmë vlerën e koeficientit, që është ajo që kërkohej në problem.
Histori
Deri në fillim të shekullit XIX. shkencëtarët nuk kishin rregulla të caktuara për zgjidhjen e një sistemi ekuacionesh në të cilin numri i të panjohurave është më i vogël se numri i ekuacioneve; Deri në atë kohë përdoreshin teknika private që vareshin nga lloji i ekuacioneve dhe nga zgjuarsia e kalkulatorëve, dhe për këtë arsye kalkulatorë të ndryshëm, bazuar në të njëjtat të dhëna vëzhgimi, arrinin në përfundime të ndryshme. Gauss (1795) ishte i pari që përdori metodën, dhe Lezhandre (1805) e zbuloi dhe botoi në mënyrë të pavarur atë me emrin e tij modern (frëngjisht. Méthode des moindres quarrés ) . Laplace e lidhi metodën me teorinë e probabilitetit dhe matematikani amerikan Adrain (1808) shqyrtoi aplikimet e saj në teorinë e probabilitetit. Metoda u përhap dhe u përmirësua nga kërkimet e mëtejshme nga Encke, Bessel, Hansen dhe të tjerë.
Përdorimet alternative të OLS
Ideja e metodës së katrorëve më të vegjël mund të përdoret edhe në raste të tjera që nuk lidhen drejtpërdrejt me analizën e regresionit. Fakti është se shuma e katrorëve është një nga matjet më të zakonshme të afërsisë për vektorët (metrika Euklidiane në hapësirat me dimensione të fundme).
Një aplikim është "zgjidhja" e sistemeve të ekuacioneve lineare në të cilat numri i ekuacioneve është më i madh se numri i variablave
ku matrica nuk është katrore, por me madhësi drejtkëndore.
Një sistem i tillë ekuacionesh, në rastin e përgjithshëm, nuk ka zgjidhje (nëse rangu është në të vërtetë më i madh se numri i ndryshoreve). Prandaj, ky sistem mund të "zgjidhet" vetëm në kuptimin e zgjedhjes së një vektori të tillë për të minimizuar "distancën" midis vektorëve dhe . Për ta bërë këtë, mund të aplikoni kriterin e minimizimit të shumës së katrorëve të dallimeve midis anëve të majtë dhe të djathtë të ekuacioneve të sistemit, d.m.th. Është e lehtë të tregohet se zgjidhja e këtij problemi të minimizimit çon në zgjidhjen e sistemit të mëposhtëm të ekuacioneve
Pas nivelimit, marrim një funksion të formës së mëposhtme: g (x) = x + 1 3 + 1 .
Ne mund t'i përafrojmë këto të dhëna duke përdorur marrëdhënien lineare y = a x + b duke llogaritur parametrat përkatës. Për ta bërë këtë, do të na duhet të aplikojmë të ashtuquajturën metodë të katrorëve më të vegjël. Do t'ju duhet gjithashtu të bëni një vizatim për të kontrolluar se cila linjë do t'i rreshtojë më mirë të dhënat eksperimentale.
Yandex.RTB R-A-339285-1
Çfarë është saktësisht OLS (metoda e katrorëve më të vegjël)
Gjëja kryesore që duhet të bëjmë është të gjejmë koeficientë të tillë të varësisë lineare në të cilat vlera e funksionit të dy ndryshoreve F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 do të jetë më i vogli. Me fjalë të tjera, për vlera të caktuara të a dhe b, shuma e devijimeve në katror të të dhënave të paraqitura nga vija e drejtë që rezulton do të ketë një vlerë minimale. Ky është kuptimi i metodës së katrorëve më të vegjël. Gjithçka që duhet të bëjmë për të zgjidhur shembullin është të gjejmë ekstremin e funksionit të dy ndryshoreve.
Si të nxjerrim formulat për llogaritjen e koeficientëve
Për të nxjerrë formulat për llogaritjen e koeficientëve, duhet të krijoni dhe zgjidhni një sistem ekuacionesh me dy variabla. Për ta bërë këtë, ne llogarisim derivatet e pjesshme të shprehjes F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 në lidhje me a dhe b dhe i barazojmë me 0.
δ F (a , b) δ a = 0 δ F (a , b) δ b = 0 ⇔ - 2 ∑ i = 1 n (y i - (a x i + b)) x i = 0 - 2 ∑ i = 1 n ( y i - (a x i + b)) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = ∑ i = ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Për të zgjidhur një sistem ekuacionesh, mund të përdorni çdo metodë, për shembull, zëvendësimin ose metodën e Cramer. Si rezultat, ne duhet të kemi formula që mund të përdoren për të llogaritur koeficientët duke përdorur metodën e katrorëve më të vegjël.
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 1 n
Ne kemi llogaritur vlerat e variablave në të cilat funksioni
F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 do të marrë vlerën minimale. Në paragrafin e tretë do të vërtetojmë pse është pikërisht kështu.
Ky është aplikimi i metodës së katrorëve më të vegjël në praktikë. Formula e tij, e cila përdoret për të gjetur parametrin a, përfshin ∑ i = 1 n x i, ∑ i = 1 n y i, ∑ i = 1 n x i y i, ∑ i = 1 n x i 2, si dhe parametrin
n – tregon sasinë e të dhënave eksperimentale. Ne ju këshillojmë të llogarisni secilën shumë veç e veç. Vlera e koeficientit b llogaritet menjëherë pas a.
Le të kthehemi te shembulli origjinal.
Shembulli 1
Këtu kemi n të barabartë me pesë. Për ta bërë më të përshtatshëm llogaritjen e shumave të kërkuara të përfshira në formulat e koeficientëve, le të plotësojmë tabelën.
| i = 1 | i=2 | i=3 | i=4 | i=5 | ∑ i = 1 5 | |
| x i | 0 | 1 | 2 | 4 | 5 | 12 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Zgjidhje
Rreshti i katërt përfshin të dhënat e marra duke shumëzuar vlerat nga rreshti i dytë me vlerat e të tretit për çdo individ i. Rreshti i pestë përmban të dhënat nga i dyti, në katror. Kolona e fundit tregon shumat e vlerave të rreshtave individualë.
Le të përdorim metodën e katrorëve më të vegjël për të llogaritur koeficientët a dhe b që na duhen. Për ta bërë këtë, zëvendësoni vlerat e kërkuara nga kolona e fundit dhe llogaritni shumat:
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 3 x 5 n - 12 12, 9 5 46 - 12 2 b = 12, 9 - a 12 5 ⇒ a ≈ 0, 165 b ≈ 2, 184
Rezulton se vija e drejtë e përafërt e kërkuar do të duket si y = 0, 165 x + 2, 184. Tani duhet të përcaktojmë se cila rresht do të përafrojë më mirë të dhënat - g (x) = x + 1 3 + 1 ose 0, 165 x + 2, 184. Le të vlerësojmë duke përdorur metodën e katrorëve më të vegjël.
Për të llogaritur gabimin, duhet të gjejmë shumën e devijimeve në katror të të dhënave nga vijat e drejta σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 dhe σ 2 = ∑ i = 1 n (y i - g (x i)) 2, vlera minimale do të korrespondojë me një vijë më të përshtatshme.
σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 = = ∑ i = 1 5 (y i - (0, 165 x i + 2, 184)) 2 ≈ 0, 019 σ 2 = ∑ i = 1 n (y i - g (x i)) 2 = = ∑ i = 1 5 (y i - (x i + 1 3 + 1)) 2 ≈ 0,096
Përgjigje: që nga σ 1< σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0,165 x + 2,184.
Metoda e katrorëve më të vegjël tregohet qartë në ilustrimin grafik. Vija e kuqe shënon vijën e drejtë g (x) = x + 1 3 + 1, vija blu shënon y = 0, 165 x + 2, 184. Të dhënat origjinale tregohen me pika rozë.
Le të shpjegojmë pse nevojiten saktësisht përafrime të këtij lloji.
Ato mund të përdoren në detyra që kërkojnë zbutjen e të dhënave, si dhe në ato ku të dhënat duhet të interpolohen ose ekstrapolohen. Për shembull, në problemin e diskutuar më sipër, mund të gjendet vlera e sasisë së vëzhguar y në x = 3 ose në x = 6. Ne i kemi kushtuar një artikull të veçantë shembujve të tillë.
Vërtetim i metodës OLS
Në mënyrë që funksioni të marrë një vlerë minimale kur llogariten a dhe b, është e nevojshme që në një pikë të caktuar matrica e formës kuadratike të diferencialit të funksionit të formës F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 është definitive pozitive. Le t'ju tregojmë se si duhet të duket.
Shembulli 2
Ne kemi një diferencial të rendit të dytë të formës së mëposhtme:
d 2 F (a ; b) = δ 2 F (a ; b) δ a 2 d 2 a + 2 δ 2 F (a ; b) δ a δ b d a d b + δ 2 F (a ; b) δ b 2 d 2 b
Zgjidhje
δ 2 F (a ; b) δ a 2 = δ δ F (a ; b) δ a δ a = = δ - 2 ∑ i = 1 n (y i - (a x i + b)) x i δ a = 2 ∑ i = 1 n (x i) 2 δ 2 F (a; b) δ a δ b = δ δ F (a; b) δ a δ b = = δ - 2 ∑ i = 1 n (y i - (a x i + b) ) x i δ b = 2 ∑ i = 1 n x i δ 2 F (a ; b) δ b 2 = δ δ F (a ; b) δ b δ b = δ - 2 ∑ i = 1 n (y i - (a x i + b)) δ b = 2 ∑ i = 1 n (1) = 2 n
Me fjalë të tjera, mund ta shkruajmë kështu: d 2 F (a ; b) = 2 ∑ i = 1 n (x i) 2 d 2 a + 2 2 ∑ x i i = 1 n d a d b + (2 n) d 2 b.
Përftuam një matricë të formës kuadratike M = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
Në këtë rast, vlerat e elementeve individuale nuk do të ndryshojnë në varësi të a dhe b. A është kjo matricë pozitive e përcaktuar? Për t'iu përgjigjur kësaj pyetjeje, le të kontrollojmë nëse minoret këndore të saj janë pozitive.
Ne llogarisim këndore e vogël renditja e parë: 2 ∑ i = 1 n (x i) 2 > 0 . Meqenëse pikat x i nuk përkojnë, pabarazia është e rreptë. Këtë do ta kemi parasysh në llogaritjet e mëtejshme.
Ne llogarisim minorin këndor të rendit të dytë:
d e t (M) = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2
Pas kësaj, vazhdojmë të vërtetojmë pabarazinë n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 duke përdorur induksionin matematik.
- Le të kontrollojmë nëse do të ketë kjo pabarazi e vlefshme për n arbitrare. Le të marrim 2 dhe të llogarisim:
2 ∑ i = 1 2 (x i) 2 - ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 - x 1 + x 2 2 = = x 1 2 - 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
Ne kemi marrë një barazi të saktë (nëse vlerat x 1 dhe x 2 nuk përkojnë).
- Le të supozojmë se kjo pabarazi do të jetë e vërtetë për n, d.m.th. n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 – e vërtetë.
- Tani do të vërtetojmë vlefshmërinë për n + 1, d.m.th. që (n + 1) ∑ i = 1 n + 1 (x i) 2 - ∑ i = 1 n + 1 x i 2 > 0, nëse n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 .
Ne llogarisim:
(n + 1) ∑ i = 1 n + 1 (x i) 2 - ∑ i = 1 n + 1 x i 2 = = (n + 1) ∑ i = 1 n (x i) 2 + x n + 1 2 - ∑ i = 1 n x i + x n + 1 2 = = n ∑ i = 1 n (x i) 2 + n x n + 1 2 + ∑ i = 1 n (x i) 2 + x n + 1 2 - - ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + n x n + 1 2 - x n + 1 ∑ i = 1 n x i + ∑ i = n (x i) 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + x n + 1 2 - 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 - 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 - 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + + (x n + 1 - x 1) 2 + (x n + 1 - x 2) 2 + . . . + (x n - 1 - x n) 2 > 0
Shprehja e përfshirë në mbajtëset, do të jetë më i madh se 0 (bazuar në atë që supozuam në hapin 2), dhe termat e mbetur do të jenë më të mëdhenj se 0, pasi të gjithë janë katrorë numrash. Ne kemi vërtetuar pabarazinë.
Përgjigje: a dhe b e gjetura do të përputhen vlera më e ulët funksionet F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2, që do të thotë se janë parametrat e dëshiruar të metodës së katrorëve më të vegjël (LSM).
Nëse vëreni një gabim në tekst, ju lutemi theksoni atë dhe shtypni Ctrl+Enter







