Exemple.
Données expérimentales sur les valeurs des variables X Et à sont données dans le tableau.
Grâce à leur alignement, la fonction est obtenue ![]()
En utilisant méthode moindres carrés , approximons ces données par une dépendance linéaire y=hache+b(trouver les paramètres UN Et b). Découvrez laquelle des deux droites (au sens de la méthode des moindres carrés) aligne le mieux les données expérimentales. Faites un dessin.
L'essence de la méthode des moindres carrés (LSM).
La tâche consiste à trouver les coefficients de dépendance linéaire auxquels la fonction de deux variables UN Et b
![]() prend la plus petite valeur. C'est-à-dire étant donné UN Et b la somme des carrés des écarts des données expérimentales par rapport à la droite trouvée sera la plus petite. C’est tout l’intérêt de la méthode des moindres carrés.
prend la plus petite valeur. C'est-à-dire étant donné UN Et b la somme des carrés des écarts des données expérimentales par rapport à la droite trouvée sera la plus petite. C’est tout l’intérêt de la méthode des moindres carrés.
Ainsi, résoudre l’exemple revient à trouver l’extremum d’une fonction de deux variables.
Dériver des formules pour trouver des coefficients.
Un système de deux équations à deux inconnues est compilé et résolu. Trouver les dérivées partielles d'une fonction ![]() par variables UN Et b, nous assimilons ces dérivées à zéro.
par variables UN Et b, nous assimilons ces dérivées à zéro. 
Nous résolvons le système d'équations résultant en utilisant n'importe quelle méthode (par exemple par méthode de substitution ou La méthode de Cramer) et obtenez des formules pour trouver des coefficients en utilisant la méthode des moindres carrés (LSM). 
Donné UN Et b fonction ![]() prend la plus petite valeur. La preuve de ce fait est donnée ci-dessous dans le texte en fin de page.
prend la plus petite valeur. La preuve de ce fait est donnée ci-dessous dans le texte en fin de page.
C'est toute la méthode des moindres carrés. Formule pour trouver le paramètre un contient les sommes ,, et le paramètre n- quantité de données expérimentales. Nous recommandons de calculer séparément les valeurs de ces montants. Coefficient b trouvé après calcul un.
Il est temps de se souvenir de l'exemple original.
Solution.
Dans notre exemple n=5. Nous remplissons le tableau pour faciliter le calcul des montants inclus dans les formules des coefficients requis. 
Les valeurs de la quatrième ligne du tableau sont obtenues en multipliant les valeurs de la 2ème ligne par les valeurs de la 3ème ligne pour chaque nombre je.
Les valeurs de la cinquième ligne du tableau sont obtenues en mettant au carré les valeurs de la 2ème ligne pour chaque nombre je.
Les valeurs de la dernière colonne du tableau sont les sommes des valeurs des lignes.
On utilise les formules de la méthode des moindres carrés pour trouver les coefficients UN Et b. Nous y substituons les valeurs correspondantes de la dernière colonne du tableau : 
Ainsi, y = 0,165x+2,184- la droite de rapprochement souhaitée.
Reste à savoir laquelle des lignes y = 0,165x+2,184 ou ![]() se rapproche mieux des données originales, c'est-à-dire des estimations utilisant la méthode des moindres carrés.
se rapproche mieux des données originales, c'est-à-dire des estimations utilisant la méthode des moindres carrés.
Estimation des erreurs de la méthode des moindres carrés.
Pour ce faire, vous devez calculer la somme des écarts carrés des données originales par rapport à ces lignes ![]() Et
Et ![]() , une valeur plus petite correspond à une droite qui se rapproche mieux des données originales au sens de la méthode des moindres carrés.
, une valeur plus petite correspond à une droite qui se rapproche mieux des données originales au sens de la méthode des moindres carrés. 
Depuis, puis directement y = 0,165x+2,184 se rapproche mieux des données originales.
Illustration graphique de la méthode des moindres carrés (LS).
Tout est clairement visible sur les graphiques. La ligne rouge est la ligne droite trouvée y = 0,165x+2,184, la ligne bleue est ![]() , les points roses sont les données originales.
, les points roses sont les données originales.

En pratique, lors de la modélisation de divers processus - notamment économiques, physiques, techniques, sociaux - l'une ou l'autre méthode de calcul des valeurs approximatives des fonctions à partir de leurs valeurs connues en certains points fixes est largement utilisée.
Ce type de problème d’approximation de fonctions se pose souvent :
lors de la construction de formules approximatives pour calculer les valeurs des quantités caractéristiques du processus étudié à l'aide de données tabulaires obtenues à la suite de l'expérience ;
en intégration numérique, différenciation, solution équations différentielles etc.;
s'il est nécessaire de calculer les valeurs de fonctions en des points intermédiaires de l'intervalle considéré ;
lors de la détermination des valeurs de grandeurs caractéristiques d'un processus en dehors de l'intervalle considéré, notamment lors de la prévision.
Si, pour modéliser un certain processus spécifié par un tableau, nous construisons une fonction qui décrit approximativement ce processus sur la base de la méthode des moindres carrés, elle sera appelée fonction d'approximation (régression), et le problème de construction de fonctions d'approximation lui-même sera appelé un problème d'approximation.
Cet article traite des capacités du package MS Excel pour résoudre ce type de problèmes. En outre, il fournit des méthodes et des techniques pour construire (créer) des régressions pour les tableaux. fonctions spécifiées(qui est la base de l’analyse de régression).
Excel propose deux options pour créer des régressions.
Ajout de régressions sélectionnées (lignes de tendance) à un diagramme construit sur la base d'un tableau de données pour la caractéristique du processus étudié (disponible uniquement si un diagramme a été construit) ;
Utilisation des fonctions statistiques intégrées de la feuille de calcul Excel, permettant d'obtenir des régressions (lignes de tendance) directement basées sur le tableau de données source.
Ajouter des lignes de tendance à un graphique
Pour un tableau de données décrivant un processus et représenté par un diagramme, Excel dispose d'un outil d'analyse de régression efficace qui vous permet de :
construire en fonction de la méthode des moindres carrés et en ajouter cinq au diagramme types de régressions, qui modélisent le processus étudié avec différents degrés de précision ;
ajoutez l'équation de régression construite au diagramme ;
déterminer le degré de correspondance de la régression sélectionnée avec les données affichées sur le graphique.
Sur la base des données graphiques, Excel vous permet d'obtenir des types de régressions linéaires, polynomiales, logarithmiques, de puissance et exponentielles, qui sont spécifiées par l'équation :
y = y(x)
où x est une variable indépendante qui prend souvent les valeurs d'une séquence de nombres naturels (1 ; 2 ; 3 ; ...) et produit, par exemple, un compte à rebours du temps du processus étudié (caractéristiques).
1 . La régression linéaire est idéale pour modéliser des caractéristiques dont les valeurs augmentent ou diminuent à un rythme constant. Il s’agit du modèle le plus simple à construire pour le processus étudié. Il est construit selon l'équation :
y = mx + b
où m est la tangente de l'angle d'inclinaison régression linéaireà l'axe des abscisses ; b - coordonnée du point d'intersection de la régression linéaire avec l'axe des ordonnées.
2 . Une ligne de tendance polynomiale est utile pour décrire des caractéristiques qui présentent plusieurs extrêmes distincts (maxima et minima). Le choix du degré polynomial est déterminé par le nombre d'extrema de la caractéristique étudiée. Ainsi, un polynôme du deuxième degré peut très bien décrire un processus qui n'a qu'un seul maximum ou minimum ; polynôme du troisième degré - pas plus de deux extrema; polynôme du quatrième degré - pas plus de trois extrema, etc.
Dans ce cas, la ligne de tendance est construite selon l'équation :
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
où les coefficients c0, c1, c2,...c6 sont des constantes dont les valeurs sont déterminées lors de la construction.
3 . La ligne de tendance logarithmique est utilisée avec succès lors de la modélisation de caractéristiques dont les valeurs changent initialement rapidement puis se stabilisent progressivement.
y = c ln(x) + b
4 . Une ligne de tendance en loi de puissance donne de bons résultats si les valeurs de la relation étudiée sont caractérisées par un changement constant du taux de croissance. Un exemple d’une telle dépendance est le graphique du mouvement uniformément accéléré d’une voiture. Si les données contiennent zéro ou valeurs négatives, vous ne pouvez pas utiliser une ligne de tendance de puissance.
Construit conformément à l'équation :
y = cxb
où les coefficients b, c sont des constantes.
5 . Une ligne de tendance exponentielle doit être utilisée lorsque le taux de changement des données augmente continuellement. Pour les données contenant des valeurs nulles ou négatives, ce type d'approximation n'est pas non plus applicable.
Construit conformément à l'équation :
y = c ebx
où les coefficients b, c sont des constantes.
Lors de la sélection d'une ligne de tendance, Excel calcule automatiquement la valeur de R2, qui caractérise la fiabilité de l'approximation : puis valeur plus proche R2 à l’unité, plus la ligne de tendance se rapproche de manière fiable du processus étudié. Si nécessaire, la valeur R2 peut toujours être affichée sur le graphique.
Déterminé par la formule :

Pour ajouter une ligne de tendance à une série de données :
activer un graphique basé sur une série de données, c'est-à-dire cliquer dans la zone du graphique. L'élément Diagramme apparaîtra dans le menu principal ;
Après avoir cliqué sur cet élément, un menu apparaîtra sur l'écran dans lequel vous devrez sélectionner la commande Ajouter une ligne de tendance.
Les mêmes actions peuvent être facilement mises en œuvre en déplaçant le pointeur de la souris sur le graphique correspondant à l'une des séries de données et en cliquant avec le bouton droit ; Dans le menu contextuel qui apparaît, sélectionnez la commande Ajouter une ligne de tendance. La boîte de dialogue Trend Line apparaîtra à l’écran avec l’onglet Type ouvert (Fig. 1).

Après cela, vous avez besoin de :
Sélectionnez dans l'onglet Type type requis lignes de tendance (le type linéaire est sélectionné par défaut). Pour le type Polynôme, dans le champ Degré, précisez le degré du polynôme sélectionné.
1 . Le champ Construit sur la série répertorie toutes les séries de données du graphique en question. Pour ajouter une ligne de tendance à une série de données spécifique, sélectionnez son nom dans le champ Construit sur la série.

Si nécessaire, en allant dans l'onglet Paramètres (Fig. 2), vous pouvez définir les paramètres suivants pour la ligne de tendance :
modifiez le nom de la ligne de tendance dans le champ Nom de la courbe approximative (lissée).
définir le nombre de périodes (en avant ou en arrière) pour la prévision dans le champ Prévisions ;
afficher l'équation de la ligne de tendance dans la zone graphique, pour laquelle vous devez cocher la case « afficher l'équation sur le graphique » ;
afficher la valeur de fiabilité d'approximation R2 dans la zone du diagramme, pour laquelle vous devez cocher la case Placer la valeur de fiabilité d'approximation sur le diagramme (R^2) ;
définissez le point d'intersection de la ligne de tendance avec l'axe Y, pour lequel vous devez cocher la case pour l'intersection de la courbe avec l'axe Y en un point ;
Cliquez sur le bouton OK pour fermer la boîte de dialogue.
Pour commencer à éditer une ligne de tendance déjà tracée, il existe trois manières :
utiliser la commande Ligne de tendance sélectionnée du menu Format, après avoir sélectionné au préalable la ligne de tendance ;
sélectionnez la commande Formater la ligne de tendance dans le menu contextuel, appelée par un clic droit sur la ligne de tendance ;
double-cliquez sur la ligne de tendance.
La boîte de dialogue Format de ligne de tendance apparaîtra à l'écran (Fig. 3), contenant trois onglets : Affichage, Type, Paramètres, et le contenu des deux derniers coïncide complètement avec les onglets similaires de la boîte de dialogue Ligne de tendance (Fig. 1). -2). Dans l'onglet Affichage, vous pouvez définir le type de ligne, sa couleur et son épaisseur.

Pour supprimer une ligne de tendance déjà tracée, sélectionnez la ligne de tendance à supprimer et appuyez sur la touche Suppr.
Les avantages de l'outil d'analyse de régression considéré sont :
la relative facilité de construire une ligne de tendance sur des graphiques sans créer de tableau de données pour celle-ci ;
une liste assez large de types de lignes de tendance proposées, et cette liste comprend les types de régression les plus couramment utilisés ;
la capacité de prédire le comportement du processus étudié à n'importe quel niveau arbitraire (dans les limites bon sens) nombre de pas en avant et en arrière ;
la capacité d'obtenir l'équation de la ligne de tendance sous forme analytique ;
la possibilité, le cas échéant, d'obtenir une évaluation de la fiabilité de l'approximation.
Les inconvénients sont les suivants :
la construction d'une ligne de tendance n'est réalisée que s'il existe un diagramme construit sur une série de données ;
le processus de génération de séries de données pour la caractéristique étudiée sur la base des équations de ligne de tendance obtenues pour celle-ci est quelque peu encombré : les équations de régression requises sont mises à jour à chaque changement dans les valeurs de la série de données d'origine, mais uniquement dans la zone du diagramme , alors que série de données, généré sur la base de l'ancienne équation de ligne de tendance, reste inchangé ;
Dans les rapports de graphique croisé dynamique, la modification de l'affichage du graphique ou du rapport de tableau croisé dynamique associé ne conserve pas les courbes de tendance existantes, ce qui signifie qu'avant de tracer des courbes de tendance ou de formater un rapport de graphique croisé dynamique, vous devez vous assurer que la présentation du rapport répond aux exigences requises.
Les lignes de tendance peuvent être utilisées pour compléter les séries de données présentées sur des graphiques tels que des graphiques, des histogrammes, des graphiques à aires plates non standardisées, des graphiques à barres, des graphiques à nuages de points, des graphiques à bulles et des graphiques boursiers.
Vous ne pouvez pas ajouter de lignes de tendance aux séries de données dans les graphiques 3D, normalisés, radar, circulaires et en anneau.
Utiliser les fonctions intégrées d'Excel
Excel dispose également d'un outil d'analyse de régression pour tracer des lignes de tendance en dehors de la zone du graphique. Il existe un certain nombre de fonctions de feuille de calcul statistique que vous pouvez utiliser à cette fin, mais toutes vous permettent uniquement de créer des régressions linéaires ou exponentielles.
Excel dispose de plusieurs fonctions pour construire une régression linéaire, notamment :
PENTE et COUPE.
S'ORIENTER;
Et aussi plusieurs fonctions pour construire ligne exponentielle tendance, notamment :
LGRFPRIBL.
Il convient de noter que les techniques de construction de régressions utilisant les fonctions TENDANCE et CROISSANCE sont quasiment les mêmes. La même chose peut être dite à propos de la paire de fonctions LINEST et LGRFPRIBL. Pour ces quatre fonctions, la création d'un tableau de valeurs utilise des fonctionnalités d'Excel telles que les formules matricielles, ce qui encombre quelque peu le processus de construction des régressions. Notez également que la construction d'une régression linéaire, à notre avis, est plus facilement réalisée en utilisant les fonctions SLOPE et INTERCEPT, où la première d'entre elles détermine la pente de la régression linéaire, et la seconde détermine le segment intercepté par la régression sur le y -axe.
Les avantages de l'outil de fonctions intégré pour l'analyse de régression sont :
un processus assez simple et uniforme de génération de séries de données de la caractéristique étudiée pour toutes les fonctions statistiques intégrées qui définissent les lignes de tendance ;
méthodologie standard pour construire des lignes de tendance basées sur des séries de données générées ;
la capacité de prédire le comportement du processus étudié sur quantité requise avance ou recule.
Les inconvénients incluent le fait qu'Excel ne dispose pas de fonctions intégrées pour créer d'autres types de lignes de tendance (sauf linéaires et exponentielles). Cette circonstance ne permet souvent pas de sélectionner un modèle suffisamment précis du processus étudié, ni d'obtenir des prévisions proches de la réalité. De plus, lors de l'utilisation des fonctions TENDANCE et CROISSANCE, les équations des lignes de tendance ne sont pas connues.
Il convient de noter que les auteurs n’ont pas eu pour objectif de présenter le déroulement de l’analyse de régression de manière exhaustive. Sa tâche principale est de montrer, à l'aide d'exemples précis, les capacités du package Excel lors de la résolution de problèmes d'approximation ; démontrer les outils efficaces dont dispose Excel pour créer des régressions et des prévisions ; illustrent comment de tels problèmes peuvent être résolus relativement facilement, même par un utilisateur qui n'a pas de connaissances approfondies en analyse de régression.
Exemples de solutions tâches spécifiques
Envisageons de résoudre des problèmes spécifiques à l'aide des outils répertoriés dans le package Excel.
Problème 1
Avec un tableau de données sur les bénéfices d'une entreprise de transport automobile pour 1995-2002. vous devez faire ce qui suit :
Construisez un diagramme.
Ajoutez des lignes de tendance linéaires et polynomiales (quadratiques et cubiques) au graphique.
À l'aide des équations des lignes de tendance, obtenez des données tabulaires sur les bénéfices des entreprises pour chaque ligne de tendance pour 1995-2004.
Faites une prévision du bénéfice de l'entreprise pour 2003 et 2004.
Solution du problème

Dans la plage de cellules A4:C11 de la feuille de calcul Excel, entrez la feuille de calcul illustrée à la Fig. 4.
Après avoir sélectionné la plage de cellules B4:C11, nous construisons un diagramme.
Nous activons le diagramme construit et, selon la méthode décrite ci-dessus, après avoir sélectionné le type de ligne de tendance dans la boîte de dialogue Ligne de tendance (voir Fig. 1), nous ajoutons alternativement des lignes de tendance linéaires, quadratiques et cubiques au diagramme. Dans la même boîte de dialogue, ouvrez l'onglet Paramètres (voir Fig. 2), dans le champ Nom de la courbe approximative (lissée), saisissez le nom de la tendance à ajouter, et dans le champ Prévision pour : périodes, définissez le valeur 2, puisqu'il est prévu de faire une prévision de bénéfice pour deux ans à l'avance. Pour afficher l'équation de régression et la valeur de fiabilité d'approximation R2 dans la zone du diagramme, cochez les cases Afficher l'équation à l'écran et placez la valeur de fiabilité d'approximation (R ^ 2) sur le diagramme. Pour le meilleur perception visuelle nous modifions le type, la couleur et l'épaisseur des lignes de tendance construites, pour lesquelles nous utilisons l'onglet Affichage de la boîte de dialogue Format de ligne de tendance (voir Fig. 3). Le diagramme résultant avec les lignes de tendance ajoutées est présenté sur la Fig. 5.
Obtenir des données tabulaires sur les bénéfices des entreprises pour chaque ligne de tendance pour 1995-2004.


Utilisons les équations de courbe de tendance présentées dans la Fig. 5. Pour ce faire, dans les cellules de la plage D3:F3, saisissez des informations textuelles sur le type de ligne de tendance sélectionnée : Tendance linéaire, Tendance quadratique, Tendance cubique. Ensuite, entrez la formule de régression linéaire dans la cellule D4 et, à l'aide du marqueur de remplissage, copiez cette formule avec les références relatives à la plage de cellules D5:D13. Il convient de noter que chaque cellule avec une formule de régression linéaire de la plage de cellules D4:D13 a comme argument une cellule correspondante de la plage A4:A13. De même, pour la régression quadratique, remplissez la plage de cellules E4:E13, et pour la régression cubique, remplissez la plage de cellules F4:F13. Ainsi, une prévision du bénéfice de l'entreprise pour 2003 et 2004 a été établie. en utilisant trois tendances. Le tableau de valeurs résultant est présenté sur la Fig. 6.
Construisez un diagramme.
Problème 2
Ajoutez des lignes de tendance logarithmiques, de puissance et exponentielles au graphique.
Dérivez les équations des lignes de tendance obtenues, ainsi que les valeurs de fiabilité de l'approximation R2 pour chacune d'elles.
À l'aide des équations de ligne de tendance, obtenez des données tabulaires sur les bénéfices de l'entreprise pour chaque ligne de tendance pour 1995-2002.
Solution du problème
Faites une prévision des bénéfices de l'entreprise pour 2003 et 2004 à l'aide de ces lignes de tendance.


En suivant la méthodologie donnée pour résoudre le problème 1, nous obtenons un diagramme auquel sont ajoutées des lignes de tendance logarithmiques, de puissance et exponentielles (Fig. 7). Ensuite, en utilisant les équations de ligne de tendance obtenues, nous remplissons un tableau de valeurs pour le bénéfice de l'entreprise, y compris les valeurs prévues pour 2003 et 2004. (Fig. 8).
Sur la fig. 5 et fig. on voit que le modèle à tendance logarithmique correspond à la valeur la plus faible de fiabilité d'approximation
R2 = 0,8659
Les valeurs les plus élevées de R2 correspondent aux modèles à tendance polynomiale : quadratique (R2 = 0,9263) et cubique (R2 = 0,933).
Problème 3
Avec le tableau des données sur les bénéfices d'une entreprise de transport automobile pour 1995-2002, donné dans la tâche 1, vous devez effectuer les étapes suivantes.
Obtenez des séries de données pour les lignes de tendance linéaires et exponentielles à l'aide des fonctions TREND et GROW.
À l’aide des fonctions TENDANCE et CROISSANCE, faites une prévision du bénéfice de l’entreprise pour 2003 et 2004.
Solution du problème
Construisez un diagramme pour les données originales et la série de données résultante.
sélectionnez la plage de cellules D4:D11, qui doit être remplie avec les valeurs de la fonction TENDANCE correspondant aux données connues sur le bénéfice de l'entreprise ;
Appelez la commande Fonction depuis le menu Insertion. Dans la boîte de dialogue Assistant de fonction qui apparaît, sélectionnez la fonction TENDANCE dans la catégorie Statistique, puis cliquez sur le bouton OK. La même opération peut être effectuée en cliquant sur le bouton (Insérer une fonction) dans la barre d'outils standard.
Dans la boîte de dialogue Arguments de fonction qui apparaît, entrez la plage de cellules C4:C11 dans le champ Known_values_y ; dans le champ Known_values_x - la plage de cellules B4:B11 ;
Pour transformer la formule saisie en formule matricielle, utilisez la combinaison de touches + + .
La formule que nous avons saisie dans la barre de formule ressemblera à : =(TREND(C4:C11,B4:B11)).
En conséquence, la plage de cellules D4:D11 est remplie des valeurs correspondantes de la fonction TREND (Fig. 9).

Faire une prévision du bénéfice de l'entreprise pour 2003 et 2004. nécessaire:
sélectionnez la plage de cellules D12:D13 où les valeurs prédites par la fonction TENDANCE seront saisies.
appelez la fonction TREND et dans la boîte de dialogue Arguments de fonction qui apparaît, entrez dans le champ Known_values_y - la plage de cellules C4:C11 ; dans le champ Known_values_x - la plage de cellules B4:B11 ; et dans le champ New_values_x - la plage de cellules B12:B13.
transformez cette formule en formule matricielle en utilisant la combinaison de touches Ctrl + Maj + Entrée.
La formule saisie ressemblera à : =(TREND(C4:C11;B4:B11;B12:B13)), et la plage de cellules D12:D13 sera remplie avec les valeurs prédites de la fonction TREND (voir Fig. 9).
La série de données est également renseignée à l'aide de la fonction CROISSANCE, qui est utilisée dans l'analyse des dépendances non linéaires et fonctionne exactement de la même manière que son homologue linéaire TENDANCE.
La figure 10 montre le tableau en mode d'affichage de formule.


Pour les données initiales et la série de données obtenues, le diagramme présenté à la Fig. 11.
Problème 4
Avec le tableau des données de réception des demandes de prestations par le service de répartition d'une entreprise de transport automobile pour la période du 1er au 11 du mois en cours, vous devez effectuer les actions suivantes.
Obtenez des séries de données pour la régression linéaire : en utilisant les fonctions SLOPE et INTERCEPT ; en utilisant la fonction LINEST.
Obtenez une série de données pour la régression exponentielle à l'aide de la fonction LGRFPRIBL.
A l'aide des fonctions ci-dessus, faites une prévision de la réception des candidatures au service dispatch pour la période du 12 au 14 du mois en cours.
Créez un diagramme pour les séries de données originales et reçues.
Solution du problème
Notez que contrairement aux fonctions TENDANCE et CROISSANCE, aucune des fonctions listées ci-dessus (SLOPE, INTERCEPT, LINEST, LGRFPRIB) n'est une régression. Ces fonctions ne jouent qu'un rôle de support, déterminant les paramètres de régression nécessaires.
Pour les régressions linéaires et exponentielles construites à l'aide des fonctions SLOPE, INTERCEPT, LINEST, LGRFPRIB, l'apparence de leurs équations est toujours connue, contrairement aux régressions linéaires et exponentielles correspondant aux fonctions TENDANCE et CROISSANCE.
1 . Construisons une régression linéaire avec l'équation :
y = mx+b
en utilisant les fonctions SLOPE et INTERCEPT, avec la pente de régression m déterminée par la fonction SLOPE, et le terme libre b par la fonction INTERCEPT.
Pour ce faire, nous effectuons les actions suivantes :
entrez le tableau d'origine dans la plage de cellules A4:B14 ;
la valeur du paramètre m sera déterminée dans la cellule C19. Sélectionnez dans la catégorie Fonction statistique Inclinaison; entrez la plage de cellules B4:B14 dans le champ known_values_y et la plage de cellules A4:A14 dans le champ known_values_x.
La formule sera saisie dans la cellule C19 : =SLOPE(B4:B14,A4:A14);
En utilisant une technique similaire, la valeur du paramètre b dans la cellule D19 est déterminée. Et son contenu ressemblera à : =SEGMENT(B4:B14,A4:A14). Ainsi, les valeurs des paramètres m et b nécessaires à la construction d'une régression linéaire seront respectivement stockées dans les cellules C19, D19 ;
2 Ensuite, entrez la formule de régression linéaire dans la cellule C4 sous la forme : =$C*A4+$D. Dans cette formule, les cellules C19 et D19 sont écrites avec des références absolues (l'adresse de la cellule ne doit pas changer lors d'une éventuelle copie). Le signe de référence absolue $ peut être saisi soit au clavier, soit à l'aide de la touche F4, après avoir placé le curseur sur l'adresse de la cellule.
y = mx+b
À l’aide de la poignée de recopie, copiez cette formule dans la plage de cellules C4:C17. Nous obtenons la série de données requise (Fig. 12). Étant donné que le nombre de candidatures est un nombre entier, vous devez définir le format numérique avec le nombre de décimales sur 0 dans l'onglet Nombre de la fenêtre Format de cellule.
. Construisons maintenant une régression linéaire donnée par l'équation :
en utilisant la fonction LINEST.
Pour ce faire :
Entrez la fonction LINEST dans la plage de cellules C20:D20 sous forme de formule matricielle : =(LINEST(B4:B14,A4:A14)). En conséquence, nous obtenons la valeur du paramètre m dans la cellule C20, et la valeur du paramètre b dans la cellule D20 ;
3 entrez la formule dans la cellule D4 : =$C*A4+$D ;
en utilisant la fonction LGRFPRIBL, cela s'effectue de la même manière :
Dans la plage de cellules C21:D21, nous entrons la fonction LGRFPRIBL sous forme de formule matricielle : =( LGRFPRIBL (B4:B14,A4:A14)). Dans ce cas, la valeur du paramètre m sera déterminée dans la cellule C21, et la valeur du paramètre b sera déterminée dans la cellule D21 ;
la formule est saisie dans la cellule E4 : =$D*$C^A4 ;
à l'aide du marqueur de remplissage, cette formule est copiée dans la plage de cellules E4:E17, où se trouvera la série de données pour la régression exponentielle (voir Fig. 12).

Sur la fig. La figure 13 montre un tableau dans lequel vous pouvez voir les fonctions que nous utilisons avec les plages de cellules requises, ainsi que les formules.
Ampleur R. 2 appelé coefficient de détermination.
La tâche de construction d'une dépendance de régression est de trouver le vecteur des coefficients m du modèle (1) auquel le coefficient R prend la valeur maximale.
Pour évaluer la signification de R, le test F de Fisher est utilisé, calculé à l'aide de la formule

Où n- taille de l'échantillon (nombre d'expériences) ;
k est le nombre de coefficients du modèle.
Si F dépasse une valeur critique pour les données n Et k et la probabilité de confiance acceptée, alors la valeur de R est considérée comme significative. Tableaux valeurs critiques F sont donnés dans des ouvrages de référence sur les statistiques mathématiques.
Ainsi, la signification de R est déterminée non seulement par sa valeur, mais aussi par le rapport entre le nombre d'expériences et le nombre de coefficients (paramètres) du modèle. En effet, le rapport de corrélation pour n=2 pour un modèle linéaire simple est égal à 1 (une seule droite peut toujours être tracée passant par 2 points sur un plan). Cependant, si les données expérimentales sont variables aléatoires, cette valeur R doit être considérée avec beaucoup de prudence. Habituellement, pour obtenir un R significatif et une régression fiable, ils s'efforcent de garantir que le nombre d'expériences dépasse largement le nombre de coefficients du modèle (n>k).
Pour construire un linéaire modèle de régression nécessaire:
1) préparer une liste de n lignes et m colonnes contenant des données expérimentales (colonne contenant la valeur de sortie Oui doit être soit le premier, soit le dernier de la liste ); Par exemple, reprenons les données de la tâche précédente, en ajoutant une colonne appelée « N° de période », numérotons les numéros de période de 1 à 12. (ce seront les valeurs X)
2) allez dans le menu Données/Analyse des données/Régression

Si l'élément « Analyse des données » dans le menu « Outils » est manquant, vous devez alors accéder à l'élément « Compléments » dans le même menu et cocher la case « Package d'analyse ».
3) dans la boîte de dialogue "Régression", définissez :
· intervalle d'entrée Y ;
· intervalle d'entrée X ;
· intervalle de sortie - la cellule supérieure gauche de l'intervalle dans laquelle les résultats du calcul seront placés (il est recommandé de les placer sur une nouvelle feuille de calcul) ;

4) cliquez sur "Ok" et analysez les résultats.
Méthode des moindres carrés ordinaires (OLS) - méthode mathématique, utilisé pour résoudre diverses tâches, basé sur la minimisation de la somme des écarts carrés de certaines fonctions par rapport aux variables souhaitées. Il peut être utilisé pour « résoudre » des systèmes d'équations surdéterminés (lorsque le nombre d'équations dépasse le nombre d'inconnues), pour trouver une solution dans le cas d'équations ordinaires (non surdéterminées). systèmes non linéaireséquations pour approximer les valeurs ponctuelles d'une certaine fonction. OLS est l'une des méthodes de base d'analyse de régression pour estimer les paramètres inconnus des modèles de régression à partir de données d'échantillon.
YouTube encyclopédique
1 / 5
✪ Méthode des moindres carrés. Sujet
✪ Méthode des moindres carrés, leçon 1/2. Fonction linéaire
✪ Économétrie. Cours 5. Méthode des moindres carrés
✪ Mitin I.V. - Traitement des résultats physiques. expérience - Méthode des moindres carrés (Leçon 4)
✪ Économétrie : L'essence de la méthode des moindres carrés #2
Sous-titres
Histoire
À début XIX V. les scientifiques n'avaient pas certaines règles résoudre un système d'équations dans lequel le nombre d'inconnues est inférieur au nombre d'équations ; Jusqu'alors, des techniques privées étaient utilisées, en fonction du type d'équations et de l'esprit des calculateurs, et donc différentes calculatrices, basées sur les mêmes données d'observation, arrivaient à diverses conclusions. Gauss (1795) fut responsable de la première application de la méthode, et Legendre (1805) la découvrit et la publia indépendamment sous nom moderne(fr. Méthode des moindres carrés) . Laplace a relié la méthode à la théorie des probabilités, et le mathématicien américain Adrain (1808) a examiné ses applications en théorie des probabilités. La méthode a été largement répandue et améliorée grâce à des recherches ultérieures menées par Encke, Bessel, Hansen et d'autres.
L'essence de la méthode des moindres carrés
Laisser x (style d'affichage x)- trousse n (style d'affichage n) variables inconnues (paramètres), f je (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- un ensemble de fonctions issues de cet ensemble de variables. La tâche est de sélectionner de telles valeurs x (style d'affichage x), pour que les valeurs de ces fonctions soient les plus proches possible de certaines valeurs oui je (\ displaystyle y_ (i)). Essentiellement nous parlons de sur la « solution » d’un système d’équations surdéterminé f je (x) = y je (\displaystyle f_(i)(x)=y_(i)), je = 1 , … , m (\displaystyle i=1,\ldots,m) dans le sens indiqué de proximité maximale de la gauche et bonnes pièces systèmes. L'essence de la méthode des moindres carrés est de sélectionner comme « mesure de proximité » la somme des écarts au carré des côtés gauche et droit. | f je (x) - oui je |
(\displaystyle |f_(i)(x)-y_(i)|).. Ainsi, l’essence de MNC peut s’exprimer comme suit : ∑ je e je 2 = ∑ je (y je − f je (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( je)(x))^(2)\rightarrow \min _(x)) Si le système d'équations a une solution, alors la somme minimale des carrés sera égal à zéro et des solutions exactes du système d'équations peuvent être trouvées analytiquement ou, par exemple, en utilisant divers méthodes numériques optimisation. Si le système est surdéterminé, c'est-à-dire, en gros, le nombre d'équations indépendantes x (style d'affichage x) plus de quantité variables souhaitées, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur « optimal » dans le sens d'une proximité maximale des vecteurs y (style d'affichage y) Et f (x) (\displaystyle f(x)) ou proximité maximale du vecteur de déviation
e (style d'affichage e)
à zéro (la proximité s’entend au sens de distance euclidienne). Exemple - système d'équations linéaires
En particulier, la méthode des moindres carrés peut être utilisée pour « résoudre » le système,Où équations linéaires UNE X = b (\ displaystyle Ax = b) UNE (\style d'affichage A) matrice rectangulaire taille
m × n , m > n (\displaystyle m\times n,m>n) (c'est-à-dire que le nombre de lignes de la matrice A est supérieur au nombre de variables recherchées). Un tel système d'équations dans x (style d'affichage x) cas général n'a pas de solution. Par conséquent, ce système ne peut être « résolu » que dans le sens du choix d’un tel vecteur dans le sens d'une proximité maximale des vecteurs pour minimiser la "distance" entre les vecteurs UNE x (\ displaystyle Axe) b (style d'affichage b). Pour ce faire, vous pouvez appliquer le critère de minimisation de la somme des carrés des différences entre les côtés gauche et droit des équations système, c'est-à-dire (A x − b) T (A x − b) → min (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min ). Il est facile de montrer que la résolution de ce problème de minimisation conduit à la solution
prochain système.équations
A T A x = A T b ⇒ x = (A T A) − 1 A T b (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (T)b) n (style d'affichage n) OLS dans l'analyse de régression (approximation des données) variables souhaitées, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur « optimal » Qu'il y ait x (style d'affichage x) valeurs d'une variable variables souhaitées, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur « optimal » dans le sens d'une proximité maximale des vecteurs x (style d'affichage x)(cela pourrait être le résultat d'observations, d'expériences, etc.) et variables associées pour minimiser la "distance" entre les vecteurs. Le défi est de garantir que la relation entre meilleures valeurs paramètres pour minimiser la "distance" entre les vecteurs, se rapprochant au maximum des valeurs f (x, b) (\displaystyle f(x,b)) aux valeurs réelles variables souhaitées, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur « optimal ». En fait, cela revient au cas de « résoudre » un système d’équations surdéterminé par rapport à pour minimiser la "distance" entre les vecteurs:
F (x t , b) = y t , t = 1 , … , n (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots,n).
En analyse de régression et en particulier en économétrie, modèles probabilistes dépendances entre variables
Y t = f (x t , b) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
Où ε t (\displaystyle \varepsilon _(t))- le soi-disant erreurs aléatoires modèles.
En conséquence, les écarts des valeurs observées variables souhaitées, alors le système n'a pas de solution exacte et la méthode des moindres carrés nous permet de trouver un vecteur « optimal » du modèle f (x, b) (\displaystyle f(x,b)) est déjà supposé dans le modèle lui-même. L'essence de la méthode des moindres carrés (ordinaire, classique) est de trouver de tels paramètres pour minimiser la "distance" entre les vecteurs, auquel la somme des écarts carrés (erreurs, pour les modèles de régression, elles sont souvent appelées résidus de régression) et t (\ displaystyle e_ (t)) sera minime :
b ^ O L S = arg min b R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS(b)),Où R S S (\ displaystyle RSS)- Anglais La somme résiduelle des carrés est définie comme :
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\somme _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).Dans le cas général, ce problème peut être résolu par des méthodes d'optimisation (minimisation) numérique. Dans ce cas, ils parlent de moindres carrés non linéaires(NLS ou NLLS - Anglais Moindres Carrés Non Linéaires). Dans de nombreux cas, vous pouvez obtenir solution analytique. Pour résoudre le problème de minimisation, il faut trouver points fixes fonctions R S S (b) (\ displaystyle RSS (b)), en le différenciant selon des paramètres inconnus pour minimiser la "distance" entre les vecteurs, égalisant les dérivées à zéro et résolvant le système d'équations résultant :
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_ (t),b))(\frac (\partial f(x_(t),b))(\partial b))=0).OLS dans le cas d'une régression linéaire
Soit la dépendance de régression linéaire :
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).Laisser oui est le vecteur colonne des observations de la variable expliquée, et X (style d'affichage X)- Ce (n × k) (\displaystyle ((n\times k)))-matrice d'observations factorielles (les lignes de la matrice sont des vecteurs de valeurs factorielles dans cette observation, par colonnes - vecteur de valeurs ce facteur dans toutes les observations). La représentation matricielle du modèle linéaire a la forme :
y = X b + ε (\displaystyle y=Xb+\varepsilon ).Alors le vecteur des estimations de la variable expliquée et le vecteur des résidus de régression seront égaux
y ^ = X b , e = y − y ^ = y − X b (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).En conséquence, la somme des carrés des résidus de régression sera égale à
R S S = e T e = (y − X b) T (y − X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Différencier cette fonction par rapport au vecteur de paramètres pour minimiser la "distance" entre les vecteurs et en assimilant les dérivées à zéro, on obtient un système d'équations (en forme matricielle):
(X T X) b = X T y (\displaystyle (X^(T)X)b=X^(T)y).Sous forme matricielle déchiffrée, ce système d'équations ressemble à ceci :
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 ∑ x t 3 x t 2 ∑ x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y t ∑ x t 2 y t ∑ x t 3 y t ⋮ ∑ x t k y t) , (\displaystyle (\begin(pmatrix)\sum x_(t1)^(2)&\sum x_(t1)x_(t2)&\sum x_(t1)x_(t3)&\ldots &\somme x_(t1)x_(tk)\\\somme x_(t2)x_(t1)&\somme x_(t2)^(2)&\somme x_(t2)x_(t3)&\ldots &\ somme x_(t2)x_(tk)\\\somme x_(t3)x_(t1)&\somme x_(t3)x_(t2)&\somme x_(t3)^(2)&\ldots &\somme x_ (t3)x_(tk)\\\vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_(tk)x_(t1)&\sum x_(tk)x_(t2)&\sum x_ (tk)x_(t3)&\ldots &\sum x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\vdots \\b_(k)\\\end(pmatrix))=(\begin(pmatrix)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \somme x_(t3)y_(t)\\\vdots \\\somme x_(tk)y_(t)\\\end(pmatrix)),) où toutes les sommes sont prises pour tous valeurs acceptables t (style d'affichage t).
Si une constante est incluse dans le modèle (comme d'habitude), alors x t 1 = 1 (\ displaystyle x_ (t1) = 1) devant tout le monde t (style d'affichage t), donc à gauche coin supérieur la matrice du système d'équations est le nombre d'observations n (style d'affichage n), et dans les éléments restants de la première ligne et de la première colonne - simplement les sommes des valeurs des variables : ∑ x t j (\displaystyle \sum x_(tj)) et le premier élément du côté droit du système est ∑ y t (\displaystyle \sum y_(t)).
La solution de ce système d'équations donne formule générale Estimations MCO pour le modèle linéaire :
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y (\displaystyle (\hat (b))_(OLS)=(X^(T )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n ))X^(T)y=V_(x)^(-1)C_(xy)).À des fins analytiques, la dernière représentation de cette formule s'avère utile (dans le système d'équations lors de la division par n, des moyennes arithmétiques apparaissent à la place des sommes). Si dans un modèle de régression les données centré, alors dans cette représentation la première matrice a la signification d'un échantillon de matrice de covariance de facteurs, et la seconde est un vecteur de covariances de facteurs avec la variable dépendante. Si en plus les données sont également normaliséà MSE (c'est-à-dire, en fin de compte standardisé), alors la première matrice a la signification d'un échantillon matrice de corrélation facteurs, le deuxième vecteur est le vecteur des corrélations d’échantillon des facteurs avec la variable dépendante.
Une propriété importante des estimations MCO pour les modèles avec constante- la droite de régression construite passe par le centre de gravité des données de l'échantillon, c'est-à-dire que l'égalité est satisfaite :
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\hat (b))_(j)(\bar (x))_(j)).En particulier, dans en dernier recours, lorsque le seul régresseur est une constante, on obtient que l'estimateur MCO paramètre unique(la constante elle-même) est égale à la valeur moyenne de la variable expliquée. C'est-à-dire la moyenne arithmétique, connue pour sa bonnes propriétés des lois grands nombres, est également une estimation des moindres carrés - elle satisfait au critère de la somme minimale des carrés des écarts par rapport à celle-ci.
Les cas particuliers les plus simples
Dans le cas d'une régression linéaire appariée y t = a + b x t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)) une fois évalué dépendance linéaire d'une variable à l'autre, les formules de calcul sont simplifiées (on peut s'en passer algèbre matricielle). Le système d'équations a la forme :
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatrix))(\begin(pmatrix)a\\b\\\end(pmatrix))=(\begin(pmatrix)(\bar (y))\\ (\overline (xy))\\\end(pmatrix))).À partir de là, il est facile de trouver des estimations de coefficients :
( b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . (\displaystyle (\begin(cases) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline (xy))-(\bar (x))(\bar (y)))((\overline (x^(2)))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x)).\end(cases)))Bien que dans le cas général, les modèles avec une constante soient préférables, dans certains cas, des considérations théoriques permettent de savoir qu'une constante une (\style d'affichage a) doit être égal à zéro. Par exemple, en physique, la relation entre la tension et le courant est U = I ⋅ R (\displaystyle U=I\cdot R); Lors de la mesure de tension et de courant, il est nécessaire d'estimer la résistance. Dans ce cas, nous parlons du modèle y = bx (\ displaystyle y = bx). Dans ce cas, au lieu du système d’équations, nous avons la seule équation
(∑ x t 2) b = ∑ x t y t (\displaystyle \left(\sum x_(t)^(2)\right)b=\sum x_(t)y_(t)).
Par conséquent, la formule d'estimation du coefficient unique a la forme
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t )y_(t))(\sum _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Le cas d'un modèle polynomial
Si les données sont ajustées par une fonction de régression polynomiale d'une variable f (x) = b 0 + ∑ i = 1 k b je x i (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)), puis percevoir les degrés x je (\ displaystyle x ^ (i)) comme facteurs indépendants pour chacun je (\style d'affichage i) il est possible d'estimer les paramètres du modèle sur la base de la formule générale d'estimation des paramètres d'un modèle linéaire. Pour ce faire, il suffit de prendre en compte dans la formule générale qu'avec une telle interprétation x t je x t j = x t je x t j = x t je + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j)) dans le sens d'une proximité maximale des vecteurs x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). Ainsi, équations matricielles V dans ce cas prendra la forme :
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 b 1 ⋮ b k ] = [ ∑ n y t ∑ n y t ⋮ ∑ n x t k y t ] .
(\displaystyle (\begin(pmatrix)n&\sum \limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\sum \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ somme \limits _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatrix)).)
Propriétés statistiques des estimateurs OLS Tout d’abord, notons que pour les modèles linéaires, les estimations MCO sont estimations linéaires , comme suit de la formule ci-dessus. Pour des estimations MCO impartiales, il est nécessaire et suffisant d’effectuer la condition la plus importante analyse de régression : conditionnelle aux facteurs, l'espérance mathématique d'une erreur aléatoire doit être égale à zéro. Cet état
- , en particulier, est satisfait si espérance mathématique erreurs aléatoires
- est égal à zéro, et
les facteurs et les erreurs aléatoires sont des variables indépendantes aléatoires . La deuxième condition – la condition d’exogénéité des facteurs – est fondamentale. Si cette propriété n’est pas satisfaite, alors nous pouvons supposer que presque toutes les estimations seront extrêmement insatisfaisantes : elles ne seront même pas cohérentes (c’est-à-dire même très grand volume les données ne permettent pas d'obtenirévaluations qualitatives dans ce cas). Dans le cas classique, une hypothèse plus forte est faite sur le déterminisme des facteurs, par opposition à une erreur aléatoire, ce qui signifie automatiquement que la condition d'exogénéité est remplie. Dans le cas général, pour la cohérence des estimations, il suffit de satisfaire la condition d'exogénéité ainsi que la convergence de la matrice V X ( displaystyle V_ (x))
à une matrice non singulière à mesure que la taille de l’échantillon augmente jusqu’à l’infini.
Pour qu'en plus de la cohérence et de l'impartialité, les estimations des moindres carrés (ordinaires) soient également efficaces (les meilleures de la classe des estimations linéaires sans biais), des propriétés supplémentaires d'erreur aléatoire doivent être remplies : Ces hypothèses peuvent être formulées pour la matrice de covariance du vecteur d'erreur aléatoire.
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Un modèle linéaire qui satisfait à ces conditions est appelé. Les estimations MCO pour la régression linéaire classique sont impartiales, cohérentes et constituent les estimations les plus efficaces de la classe de toutes les estimations linéaires non biaisées (dans la littérature anglaise, l'abréviation est parfois utilisée BLEU (Meilleur estimateur linéaire sans biais) - la meilleure estimation linéaire sans biais ; V Littérature russe le théorème de Gauss-Markov est plus souvent cité). Comme il est facile de le montrer, la matrice de covariance du vecteur d'estimations de coefficients sera égale à :
V (b ^ O L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
L'efficacité signifie que cette matrice de covariance est « minimale » (toute combinaison linéaire de coefficients, et en particulier les coefficients eux-mêmes, ont une variance minimale), c'est-à-dire que dans la classe des estimateurs linéaires sans biais, les estimateurs OLS sont les meilleurs. Les éléments diagonaux de cette matrice sont les variances des estimations de coefficients - paramètres importants qualité des évaluations reçues. Cependant, il n’est pas possible de calculer la matrice de covariance car la variance des erreurs aléatoires est inconnue. Il peut être prouvé qu'une estimation impartiale et cohérente (pour un modèle linéaire classique) de la variance des erreurs aléatoires est la quantité :
S 2 = R S S / (n − k) (\displaystyle s^(2)=RSS/(n-k)).
En substituant cette valeur dans la formule de la matrice de covariance, nous obtenons une estimation de la matrice de covariance. Les estimations qui en résultent sont également impartiales et cohérentes. Il est également important que l'estimation de la variance d'erreur (et donc la variance des coefficients) et les estimations des paramètres du modèle soient des variables aléatoires indépendantes, ce qui permet d'obtenir des statistiques de test pour tester les hypothèses sur les coefficients du modèle.
Il convient de noter que si les hypothèses classiques ne sont pas satisfaites, les estimations des paramètres MCO ne sont pas les plus efficaces et, où W (style d'affichage W) est une matrice symétrique à poids défini positif. Les moindres carrés conventionnels sont un cas particulier de cette approche, où la matrice de poids est proportionnelle à la matrice d'identité. Comme on le sait, pour les matrices (ou opérateurs) symétriques, il existe un développement W = P T P (\ displaystyle W = P ^ (T) P). Par conséquent, la fonctionnelle spécifiée peut être représentée comme suit e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)), c'est-à-dire que cette fonctionnelle peut être représentée comme la somme des carrés de quelques « restes » transformés. Ainsi, on peut distinguer une classe de méthodes des moindres carrés - les méthodes LS (Least Squares).
Il a été prouvé (théorème d'Aitken) que pour un modèle de régression linéaire généralisée (dans lequel aucune restriction n'est imposée sur la matrice de covariance des erreurs aléatoires), les plus efficaces (dans la classe des estimations linéaires non biaisées) sont les soi-disant estimations. Moindres carrés généralisés (GLS - Moindres carrés généralisés)- Méthode LS avec une matrice de poids égale à la matrice de covariance inverse des erreurs aléatoires : W = V ε − 1 (\displaystyle W=V_(\varepsilon )^(-1)).
On peut montrer que la formule pour les estimations GLS des paramètres d'un modèle linéaire a la forme
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
La matrice de covariance de ces estimations sera donc égale à
V (b ^ G L S) = (X T V − 1 X) − 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
En fait, l’essence de l’OLS réside dans une certaine transformation (linéaire) (P) des données originales et dans l’application de l’OLS ordinaire aux données transformées. Le but de cette transformation est que pour les données transformées, les erreurs aléatoires satisfont déjà aux hypothèses classiques.
MCO pondéré
Dans le cas d'une matrice de poids diagonale (et donc d'une matrice de covariance d'erreurs aléatoires), nous avons ce que l'on appelle les moindres carrés pondérés (WLS). Dans ce cas, la somme des carrés pondérée des résidus du modèle est minimisée, c'est-à-dire que chaque observation reçoit un « poids » inversement proportionnel à la variance de l'erreur aléatoire dans cette observation : e T W e = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma_(t)^(2)))). En fait, les données sont transformées en pondérant les observations (en divisant par un montant proportionnel à l'espérance écart type erreurs aléatoires), et l’OLS habituel est appliqué aux données pondérées.
ISBN 978-5-7749-0473-0 .
L'analyse de régression est l'une des méthodes permettant d'étudier les relations stochastiques entre les caractéristiques.
L'analyse de régression est la dérivation d'une équation de régression utilisée pour trouver valeur moyenne une variable aléatoire (attribut de résultat) si la valeur d'une autre (ou d'autres) variables (attributs de facteur) est connue. Il comprend les étapes suivantes :
- sélection de la forme de connexion (type d'équation de régression analytique) ;
- estimation des paramètres de l'équation ;
- évaluation de la qualité de l'équation de régression analytique.
Dans le cas d'une relation linéaire par paire, l'équation de régression prendra la forme : y i =a+b·x i +u i . Possibilités équation donnée a et b sont estimés à partir des données observation statistique x et y. Le résultat d'une telle évaluation est l'équation : , où , sont des estimations des paramètres a et b , est la valeur de l'attribut résultant (variable) obtenu à partir de l'équation de régression (valeur calculée).
Le plus souvent utilisé pour estimer des paramètres méthode des moindres carrés (LSM).
La méthode des moindres carrés fournit les meilleures estimations (cohérentes, efficaces et impartiales) des paramètres de l'équation de régression. Mais seulement si certaines hypothèses concernant le terme aléatoire (u) et la variable indépendante (x) sont remplies (voir hypothèses OLS).
Le problème de l'estimation des paramètres d'une équation de paire linéaire à l'aide de la méthode des moindres carrés est la suivante : obtenir de telles estimations des paramètres , , pour lesquelles la somme des écarts carrés valeurs réelles l'attribut effectif - y i à partir des valeurs calculées - est minime.
Officiellement Test MCO peut s'écrire ainsi :  .
.
Classification des méthodes des moindres carrés
- Méthode des moindres carrés.
- Méthode probabilité maximale(pour un modèle de régression linéaire classique normal, la normalité des résidus de régression est postulée).
- La méthode des moindres carrés généralisés MCO est utilisée dans le cas d'autocorrélation d'erreurs et dans le cas d'hétéroscédasticité.
- Méthode des moindres carrés pondérés ( cas particulier OLS avec résidus hétéroscédastiques).
Illustrons le propos méthode classique moindres carrés graphiquement. Pour ce faire, nous allons construire un nuage de points basé sur des données d'observation (x i , y i , i=1;n) dans système rectangulaire coordonnées (un tel tracé de points est appelé champ de corrélation). Essayons de trouver une droite la plus proche des points champ de corrélation. Selon la méthode des moindres carrés, la droite est sélectionnée pour que la somme des carrés des distances verticales entre les points du champ de corrélation et cette droite soit minimale. 
Notation mathématique pour ce problème :  .
.
Les valeurs de y i et x i =1...n nous sont connues ; ce sont des données d'observation. Dans la fonction S, ils représentent des constantes. Les variables de cette fonction sont les estimations requises des paramètres - , . Pour trouver le minimum d'une fonction de deux variables, il faut calculer les dérivées partielles de cette fonction pour chacun des paramètres et les assimiler à zéro, c'est-à-dire 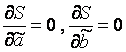 .
.
En conséquence, nous obtenons un système de 2 équations linéaires normales : 
En résolvant ce système, nous trouvons les estimations de paramètres requises : 
L'exactitude du calcul des paramètres de l'équation de régression peut être vérifiée en comparant les montants (il peut y avoir un certain écart en raison de l'arrondi des calculs).
Pour calculer les estimations des paramètres, vous pouvez créer le tableau 1.
Le signe du coefficient de régression b indique le sens de la relation (si b >0, la relation est directe, si b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formellement, la valeur du paramètre a est la valeur moyenne de y avec x égal à zéro. Si le facteur d'attribut n'a pas et ne peut pas avoir une valeur nulle, alors l'interprétation ci-dessus du paramètre a n'a pas de sens.
Évaluer l'étroitesse de la relation entre les caractéristiques
réalisée à l'aide du coefficient de corrélation de paire linéaire - r x,y. Il peut être calculé à l'aide de la formule :  . De plus, le coefficient de corrélation linéaire des paires peut être déterminé via le coefficient de régression b :
. De plus, le coefficient de corrélation linéaire des paires peut être déterminé via le coefficient de régression b :  .
.
La plage de valeurs acceptables du coefficient de corrélation linéaire des paires va de –1 à +1. Le signe du coefficient de corrélation indique le sens de la relation. Si r x, y >0, alors la connexion est directe ; si r x, y<0, то связь обратная.
Si ce coefficient est proche de l'unité en grandeur, alors la relation entre les caractéristiques peut être interprétée comme une relation linéaire assez étroite. Si son module est égal à un ê r x , y ê =1, alors la relation entre les caractéristiques est fonctionnellement linéaire. Si les caractéristiques x et y sont linéairement indépendantes, alors r x,y est proche de 0.
Pour calculer r x,y, vous pouvez également utiliser le tableau 1.
Tableau 1
| N observations | x je | et je | x je ∙y je | ||
| 1 | x1 | et 1 | x 1 et 1 | ||
| 2 | x2 | et 2 | x 2 et 2 | ||
| ... | |||||
| n | xn | o n | x n y n | ||
| Somme de colonne | ∑x | ∑y | ∑xy | ||
| Valeur moyenne |
|
|
 ,
,
où d 2 est la variance de y expliquée par l'équation de régression ;
e 2 - variance résiduelle (inexpliquée par l'équation de régression) de y ;
s 2 y - variance totale (totale) de y.
Le coefficient de détermination caractérise la proportion de variation (dispersion) de l'attribut résultant y expliquée par la régression (et, par conséquent, le facteur x) dans la variation totale (dispersion) y. Le coefficient de détermination R 2 yx prend des valeurs de 0 à 1. En conséquence, la valeur 1-R 2 yx caractérise la proportion de variance y causée par l'influence d'autres facteurs non pris en compte dans les erreurs de modèle et de spécification.
Avec régression linéaire appariée, R 2 yx =r 2 yx.
Méthode des moindres carrés
Méthode des moindres carrés ( MCO, MCO, moindres carrés ordinaires) - l'une des méthodes de base d'analyse de régression pour estimer les paramètres inconnus des modèles de régression à l'aide d'échantillons de données. La méthode est basée sur la minimisation de la somme des carrés des résidus de régression.
Il convient de noter que la méthode des moindres carrés elle-même peut être appelée une méthode permettant de résoudre un problème dans n'importe quel domaine si la solution est ou satisfait à un critère permettant de minimiser la somme des carrés de certaines fonctions des variables requises. Par conséquent, la méthode des moindres carrés peut également être utilisée pour une représentation approximative (approximation) d'une fonction donnée par d'autres fonctions (plus simples), lors de la recherche d'un ensemble de quantités qui satisfont des équations ou des contraintes, dont le nombre dépasse le nombre de ces quantités. , etc.
L’essence de la multinationale
Soit un modèle (paramétrique) d'une relation probabiliste (de régression) entre la variable (expliquée) oui et de nombreux facteurs (variables explicatives) x
où est le vecteur des paramètres de modèle inconnus
- erreur de modèle aléatoire.Qu'il y ait également des exemples d'observations des valeurs de ces variables. Soit le numéro d'observation (). Viennent ensuite les valeurs des variables de la ème observation. Ensuite, pour des valeurs données des paramètres b, il est possible de calculer les valeurs théoriques (modèles) de la variable expliquée y :
La taille des résidus dépend des valeurs des paramètres b.
L'essence de la méthode des moindres carrés (ordinaire, classique) est de trouver des paramètres b pour lesquels la somme des carrés des résidus (eng. Somme résiduelle des carrés) sera minime :
Dans le cas général, ce problème peut être résolu par des méthodes d'optimisation (minimisation) numérique. Dans ce cas, ils parlent de moindres carrés non linéaires(NLS ou NLLS - anglais) Moindres carrés non linéaires). Dans de nombreux cas, il est possible d'obtenir une solution analytique. Pour résoudre le problème de minimisation, il faut trouver les points stationnaires de la fonction en la différenciant par rapport aux paramètres inconnus b, en assimilant les dérivées à zéro et en résolvant le système d'équations résultant :
Si les erreurs aléatoires du modèle sont normalement distribuées, ont la même variance et ne sont pas corrélées, les estimations des paramètres OLS sont identiques aux estimations du maximum de vraisemblance (MLM).
OLS dans le cas d'un modèle linéaire
Soit la dépendance de régression linéaire :
Laisser oui est un vecteur colonne d'observations de la variable expliquée, et est une matrice d'observations factorielles (les lignes de la matrice sont les vecteurs de valeurs de facteurs dans une observation donnée, les colonnes sont le vecteur de valeurs d'un facteur donné dans toutes les observations). La représentation matricielle du modèle linéaire est :
Alors le vecteur des estimations de la variable expliquée et le vecteur des résidus de régression seront égaux
En conséquence, la somme des carrés des résidus de régression sera égale à
En différenciant cette fonction par rapport au vecteur de paramètres et en assimilant les dérivées à zéro, on obtient un système d'équations (sous forme matricielle) :
.La solution de ce système d'équations donne la formule générale des estimations des moindres carrés pour un modèle linéaire :
À des fins analytiques, cette dernière représentation de cette formule est utile. Si dans un modèle de régression les données centré, alors dans cette représentation la première matrice a la signification d'un échantillon de matrice de covariance de facteurs, et la seconde est un vecteur de covariances de facteurs avec la variable dépendante. Si en plus les données sont également normaliséà MSE (c'est-à-dire, en fin de compte standardisé), alors la première matrice a la signification d'une matrice de corrélation d'échantillons de facteurs, le deuxième vecteur - un vecteur de corrélations d'échantillons de facteurs avec la variable dépendante.
Une propriété importante des estimations MCO pour les modèles avec constante- la droite de régression construite passe par le centre de gravité des données de l'échantillon, c'est-à-dire que l'égalité est satisfaite :
En particulier, dans le cas extrême, lorsque le seul régresseur est une constante, on constate que l'estimation MCO du seul paramètre (la constante elle-même) est égale à la valeur moyenne de la variable expliquée. C'est-à-dire que la moyenne arithmétique, connue pour ses bonnes propriétés issues des lois des grands nombres, est également une estimation des moindres carrés - elle satisfait au critère de la somme minimale des écarts carrés par rapport à celle-ci.
Exemple : régression la plus simple (par paires)
Dans le cas de la régression linéaire appariée, les formules de calcul sont simplifiées (on peut se passer de l'algèbre matricielle) :
Propriétés des estimateurs OLS
Tout d’abord, nous notons que pour les modèles linéaires, les estimations MCO sont des estimations linéaires, comme le découle de la formule ci-dessus. Pour les estimations MCO non biaisées, il est nécessaire et suffisant de remplir la condition la plus importante de l’analyse de régression : l’espérance mathématique d’une erreur aléatoire, conditionnelle aux facteurs, doit être égale à zéro. Cette condition est notamment remplie si
- l'espérance mathématique des erreurs aléatoires est nulle, et
- les facteurs et les erreurs aléatoires sont des variables aléatoires indépendantes.
La deuxième condition – la condition d’exogénéité des facteurs – est fondamentale. Si cette propriété n'est pas remplie, alors nous pouvons supposer que presque toutes les estimations seront extrêmement insatisfaisantes : elles ne seront même pas cohérentes (c'est-à-dire que même une très grande quantité de données ne nous permet pas d'obtenir des estimations de haute qualité dans ce cas ). Dans le cas classique, une hypothèse plus forte est faite sur le déterminisme des facteurs, par opposition à une erreur aléatoire, ce qui signifie automatiquement que la condition d'exogénéité est remplie. Dans le cas général, pour la cohérence des estimations, il suffit de satisfaire la condition d'exogénéité ainsi que la convergence de la matrice vers une matrice non singulière à mesure que la taille de l'échantillon augmente jusqu'à l'infini.
à une matrice non singulière à mesure que la taille de l’échantillon augmente jusqu’à l’infini.
Ces hypothèses peuvent être formulées pour la matrice de covariance du vecteur d'erreur aléatoire
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Un modèle linéaire qui satisfait à ces conditions est appelé. Les estimations MCO pour la régression linéaire classique sont impartiales, cohérentes et constituent les estimations les plus efficaces de la classe de toutes les estimations linéaires non biaisées (dans la littérature anglaise, l'abréviation est parfois utilisée BLEU (Meilleur estimateur linéaire sans évaluation) - la meilleure estimation linéaire sans biais ; dans la littérature russe, le théorème de Gauss-Markov est plus souvent cité). Comme il est facile de le montrer, la matrice de covariance du vecteur d'estimations de coefficients sera égale à :
MCO généralisé
La méthode des moindres carrés permet une large généralisation. Au lieu de minimiser la somme des carrés des résidus, on peut minimiser une forme quadratique définie positive du vecteur des résidus, où est une matrice de poids défini positif symétrique. Les moindres carrés conventionnels sont un cas particulier de cette approche, où la matrice de poids est proportionnelle à la matrice d'identité. Comme le montre la théorie des matrices symétriques (ou opérateurs), pour de telles matrices, il existe une décomposition. Par conséquent, la fonctionnelle spécifiée peut être représentée comme suit, c'est-à-dire que cette fonctionnelle peut être représentée comme la somme des carrés de certains « restes » transformés. Ainsi, on peut distinguer une classe de méthodes des moindres carrés - les méthodes LS (Least Squares).
Il a été prouvé (théorème d'Aitken) que pour un modèle de régression linéaire généralisée (dans lequel aucune restriction n'est imposée sur la matrice de covariance des erreurs aléatoires), les plus efficaces (dans la classe des estimations linéaires non biaisées) sont les soi-disant estimations. Moindres carrés généralisés (GLS - Moindres carrés généralisés)- Méthode LS avec une matrice de poids égale à la matrice de covariance inverse des erreurs aléatoires : .
On peut montrer que la formule pour les estimations GLS des paramètres d'un modèle linéaire a la forme
La matrice de covariance de ces estimations sera donc égale à
En fait, l’essence de l’OLS réside dans une certaine transformation (linéaire) (P) des données originales et dans l’application de l’OLS ordinaire aux données transformées. Le but de cette transformation est que pour les données transformées, les erreurs aléatoires satisfont déjà aux hypothèses classiques.
MCO pondéré
Dans le cas d'une matrice de poids diagonale (et donc d'une matrice de covariance d'erreurs aléatoires), nous avons ce que l'on appelle les moindres carrés pondérés (WLS). Dans ce cas, la somme des carrés pondérée des résidus du modèle est minimisée, c'est-à-dire que chaque observation reçoit un « poids » inversement proportionnel à la variance de l'erreur aléatoire dans cette observation : . En fait, les données sont transformées en pondérant les observations (en divisant par un montant proportionnel à l'écart type estimé des erreurs aléatoires), et une MCO ordinaire est appliquée aux données pondérées.
Quelques cas particuliers d'utilisation de MNC en pratique
Approximation de la dépendance linéaire
Considérons le cas où, à la suite de l'étude de la dépendance d'une certaine quantité scalaire sur une certaine quantité scalaire (cela pourrait être, par exemple, la dépendance de la tension sur l'intensité du courant : , où est une valeur constante, la résistance de le conducteur), des mesures de ces grandeurs ont été effectuées, à la suite desquelles les valeurs et leurs valeurs correspondantes. Les données de mesure doivent être enregistrées dans un tableau.
Tableau. Résultats de mesure.
| Numéro de mesure | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
La question est : quelle valeur du coefficient peut-on choisir pour décrire au mieux la dépendance ? Selon la méthode des moindres carrés, cette valeur doit être telle que la somme des carrés des écarts des valeurs par rapport aux valeurs
était minime
La somme des écarts au carré a un extremum - un minimum, ce qui nous permet d'utiliser cette formule. Retrouvons à partir de cette formule la valeur du coefficient. Pour ce faire, on transforme son côté gauche comme suit :
La dernière formule nous permet de trouver la valeur du coefficient, ce qui était requis dans le problème.
Histoire
Jusqu'au début du 19ème siècle. les scientifiques n'avaient pas certaines règles pour résoudre un système d'équations dans lequel le nombre d'inconnues est inférieur au nombre d'équations ; Jusqu'à cette époque, on utilisait des techniques privées qui dépendaient du type d'équations et de l'esprit des calculateurs, et donc différents calculateurs, basés sur les mêmes données d'observation, arrivaient à des conclusions différentes. Gauss (1795) fut le premier à utiliser la méthode, et Legendre (1805) la découvrit et la publia indépendamment sous son nom moderne (français. Méthode des moindres carrés ) . Laplace a lié la méthode à la théorie des probabilités, et le mathématicien américain Adrain (1808) a examiné ses applications en théorie des probabilités. La méthode a été largement répandue et améliorée grâce à des recherches ultérieures menées par Encke, Bessel, Hansen et d'autres.
Utilisations alternatives de l'OLS
L'idée de la méthode des moindres carrés peut également être utilisée dans d'autres cas non directement liés à l'analyse de régression. Le fait est que la somme des carrés est l’une des mesures de proximité les plus courantes pour les vecteurs (métrique euclidienne dans les espaces de dimension finie).
Une application est la « solution » de systèmes d’équations linéaires dans lesquels le nombre d’équations est supérieur au nombre de variables.
où la matrice n'est pas carrée, mais rectangulaire de taille .
Un tel système d’équations, dans le cas général, n’a pas de solution (si le rang est effectivement supérieur au nombre de variables). Par conséquent, ce système ne peut être « résolu » que dans le sens de choisir un tel vecteur pour minimiser la « distance » entre les vecteurs et . Pour ce faire, vous pouvez appliquer le critère de minimisation de la somme des carrés des différences entre les côtés gauche et droit des équations système, c'est-à-dire. Il est facile de montrer que la résolution de ce problème de minimisation conduit à résoudre le système d’équations suivant
Après nivellement, on obtient une fonction de la forme suivante : g (x) = x + 1 3 + 1 .
Nous pouvons approximer ces données en utilisant la relation linéaire y = a x + b en calculant les paramètres correspondants. Pour ce faire, nous devrons appliquer la méthode dite des moindres carrés. Vous devrez également faire un dessin pour vérifier quelle ligne alignera le mieux les données expérimentales.
Yandex.RTB R-A-339285-1
Qu'est-ce que l'OLS exactement (méthode des moindres carrés)
La principale chose que nous devons faire est de trouver de tels coefficients de dépendance linéaire auxquels la valeur de la fonction de deux variables F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 sera la le plus petit. En d'autres termes, pour certaines valeurs de a et b, la somme des carrés des écarts des données présentées par rapport à la droite résultante aura une valeur minimale. C’est le sens de la méthode des moindres carrés. Tout ce que nous devons faire pour résoudre l’exemple est de trouver l’extremum de la fonction de deux variables.
Comment dériver des formules pour calculer les coefficients
Afin de dériver des formules de calcul des coefficients, vous devez créer et résoudre un système d'équations à deux variables. Pour ce faire, nous calculons les dérivées partielles de l'expression F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 par rapport à a et b et les assimilons à 0.
δ F (a , b) δ a = 0 δ F (a , b) δ b = 0 ⇔ - 2 ∑ i = 1 n (y i - (a x i + b)) x i = 0 - 2 ∑ i = 1 n ( y i - (a x i + b)) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = 1 n y i ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Pour résoudre un système d'équations, vous pouvez utiliser n'importe quelle méthode, par exemple la substitution ou la méthode de Cramer. En conséquence, nous devrions disposer de formules permettant de calculer des coefficients en utilisant la méthode des moindres carrés.
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 1 n x i n
Nous avons calculé les valeurs des variables auxquelles la fonction
F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 prendra la valeur minimale. Dans le troisième paragraphe, nous prouverons pourquoi il en est exactement ainsi.
Il s’agit de l’application pratique de la méthode des moindres carrés. Sa formule, qui permet de trouver le paramètre a, comprend ∑ i = 1 n x i, ∑ i = 1 n y i, ∑ i = 1 n x i y i, ∑ i = 1 n x i 2, ainsi que le paramètre
n – il désigne la quantité de données expérimentales. Nous vous conseillons de calculer chaque montant séparément. La valeur du coefficient b est calculée immédiatement après a.
Revenons à l'exemple original.
Exemple 1
Ici, nous avons n égal à cinq. Pour faciliter le calcul des montants requis inclus dans les formules de coefficients, remplissons le tableau.
| je = 1 | je = 2 | je = 3 | je = 4 | je = 5 | ∑ je = 1 5 | |
| x je | 0 | 1 | 2 | 4 | 5 | 12 |
| et je | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x je y je | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x je 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Solution
La quatrième ligne comprend les données obtenues en multipliant les valeurs de la deuxième ligne par les valeurs de la troisième pour chaque individu i. La cinquième ligne contient les données de la deuxième, au carré. La dernière colonne affiche les sommes des valeurs des lignes individuelles.
Utilisons la méthode des moindres carrés pour calculer les coefficients a et b dont nous avons besoin. Pour ce faire, remplacez les valeurs requises de la dernière colonne et calculez les montants :
n ∑ i = 1 n x i y i - ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n - ∑ i = 1 n x i 2 b = ∑ i = 1 n y i - a ∑ i = 1 n x i n ⇒ a = 5 33, 8 - 12 12, 9 5 46 - 12 2 b = 12, 9 - une 12 5 ⇒ une ≈ 0, 165 b ≈ 2, 184
Il s'avère que la ligne droite d'approximation requise ressemblera à y = 0, 165 x + 2, 184. Nous devons maintenant déterminer quelle ligne se rapprochera le mieux des données - g (x) = x + 1 3 + 1 ou 0, 165 x + 2, 184. Estimons en utilisant la méthode des moindres carrés.
Pour calculer l'erreur, nous devons trouver la somme des écarts carrés des données par rapport aux droites σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 et σ 2 = ∑ i = 1 n (y i - g (x i)) 2, la valeur minimale correspondra à une ligne plus adaptée.
σ 1 = ∑ i = 1 n (y i - (a x i + b i)) 2 = = ∑ i = 1 5 (y i - (0, 165 x i + 2, 184)) 2 ≈ 0, 019 σ 2 = ∑ i = 1 n (y i - g (x i)) 2 = = ∑ i = 1 5 (y i - (x i + 1 3 + 1)) 2 ≈ 0,096
Répondre: puisque σ 1< σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0,165 x + 2,184.
La méthode des moindres carrés est clairement illustrée dans l’illustration graphique. La ligne rouge marque la droite g (x) = x + 1 3 + 1, la ligne bleue marque y = 0, 165 x + 2, 184. Les données originales sont indiquées par des points roses.
Expliquons pourquoi exactement des approximations de ce type sont nécessaires.
Ils peuvent être utilisés dans des tâches nécessitant un lissage des données, ainsi que dans celles où les données doivent être interpolées ou extrapolées. Par exemple, dans le problème discuté ci-dessus, on pourrait trouver la valeur de la quantité observée y à x = 3 ou à x = 6. Nous avons consacré un article séparé à de tels exemples.
Preuve de la méthode OLS
Pour que la fonction prenne une valeur minimale lors du calcul de a et b, il faut qu'en un point donné la matrice de la forme quadratique du différentiel de la fonction de la forme F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 est défini positif. Montrons à quoi cela devrait ressembler.
Exemple 2
On a une différentielle du second ordre de la forme suivante :
d 2 F (a ; b) = δ 2 F (a ; b) δ a 2 d 2 a + 2 δ 2 F (a ; b) δ a δ b d a d b + δ 2 F (a ; b) δ b 2 d 2 b
Solution
δ 2 F (a ; b) δ a 2 = δ δ F (a ; b) δ a δ a = = δ - 2 ∑ i = 1 n (y i - (a x i + b)) x i δ a = 2 ∑ i = 1 n (x i) 2 δ 2 F (a; b) δ a δ b = δ δ F (a; b) δ a δ b = = δ - 2 ∑ i = 1 n (y i - (a x i + b) ) x je δ b = 2 ∑ je = 1 n x je δ 2 F (a ; b) δ b 2 = δ δ F (a ; b) δ b δ b = δ - 2 ∑ i = 1 n (y i - (a x i + b)) δ b = 2 ∑ je = 1 n (1) = 2 n
En d'autres termes, nous pouvons l'écrire ainsi : d 2 F (a ; b) = 2 ∑ i = 1 n (x i) 2 d 2 a + 2 2 ∑ x i i = 1 n d a d b + (2 n) d 2 b.
Nous avons obtenu une matrice de forme quadratique M = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
Dans ce cas, les valeurs des éléments individuels ne changeront pas en fonction de a et b . Cette matrice est-elle positive définie ? Pour répondre à cette question, vérifions si ses mineurs angulaires sont positifs.
Nous calculons coin mineur premier ordre : 2 ∑ i = 1 n (x i) 2 > 0 . Puisque les points x i ne coïncident pas, l'inégalité est stricte. Nous garderons cela à l’esprit dans les calculs ultérieurs.
On calcule le mineur angulaire du deuxième ordre :
d e t (M) = 2 ∑ i = 1 n (x i) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2
Après cela, nous prouvons l'inégalité n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 en utilisant l'induction mathématique.
- Vérifions s'il y aura cette inégalité valable pour n arbitraire. Prenons 2 et calculons :
2 ∑ i = 1 2 (x i) 2 - ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 - x 1 + x 2 2 = = x 1 2 - 2 x 1 x 2 + x 2 2 = x1 + x2 2 > 0
Nous avons la bonne égalité (si les valeurs x 1 et x 2 ne coïncident pas).
- Faisons l'hypothèse que cette inégalité sera vraie pour n, c'est-à-dire n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 – vrai.
- Nous allons maintenant prouver la validité pour n + 1, c'est-à-dire que (n + 1) ∑ i = 1 n + 1 (x i) 2 - ∑ i = 1 n + 1 x i 2 > 0, si n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 > 0 .
On calcule :
(n + 1) ∑ je = 1 n + 1 (x je) 2 - ∑ je = 1 n + 1 x je 2 = = (n + 1) ∑ je = 1 n (x je) 2 + x n + 1 2 - ∑ je = 1 n x i + x n + 1 2 = = n ∑ i = 1 n (x i) 2 + n x n + 1 2 + ∑ i = 1 n (x i) 2 + x n + 1 2 - - ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + n x n + 1 2 - x n + 1 ∑ i = 1 n x i + ∑ i = 1 n (x i) 2 = = ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + x n + 1 2 - 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 - 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 - 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x i 2 + + (x n + 1 - x 1) 2 + (x n + 1 - x 2) 2 + . . . + (x n - 1 - x n) 2 > 0
L'expression contenue dans croisillons, sera supérieur à 0 (d'après ce que nous avons supposé à l'étape 2), et les termes restants seront supérieurs à 0, puisqu'ils sont tous des carrés de nombres. Nous avons prouvé l'inégalité.
Répondre: les a et b trouvés correspondront valeur la plus basse fonctions F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2, ce qui signifie qu'elles sont les paramètres requis de la méthode des moindres carrés (LSM).
Si vous remarquez une erreur dans le texte, veuillez la surligner et appuyer sur Ctrl+Entrée