Örnek.
Değişkenlerin değerlerine ilişkin deneysel veriler X Ve en tabloda verilmektedir.
Hizalamalarının bir sonucu olarak, fonksiyon elde edilir ![]()
Kullanma yöntem en küçük kareler , bu verilere doğrusal bir bağımlılıkla yaklaşın y=ax+b(parametreleri bul A Ve B). İki çizgiden hangisinin (en küçük kareler yöntemi anlamında) deneysel verileri daha iyi hizaladığını bulun. Bir çizim yapın.
En küçük kareler yönteminin (LSM) özü.
Görev, iki değişkenli fonksiyonun geçerli olduğu doğrusal bağımlılık katsayılarını bulmaktır. A Ve B
![]() en küçük değeri alır. Yani verilen A Ve B Deneysel verilerin bulunan düz çizgiden sapmalarının karelerinin toplamı en küçük olacaktır. En küçük kareler yönteminin asıl amacı budur.
en küçük değeri alır. Yani verilen A Ve B Deneysel verilerin bulunan düz çizgiden sapmalarının karelerinin toplamı en küçük olacaktır. En küçük kareler yönteminin asıl amacı budur.
Dolayısıyla, örneği çözmek iki değişkenli bir fonksiyonun ekstremumunu bulmaya indirgenir.
Katsayıları bulmak için formüllerin türetilmesi.
İki bilinmeyenli iki denklemden oluşan bir sistem derlenip çözülür. Bir fonksiyonun kısmi türevlerini bulma ![]() değişkenlere göre A Ve B, bu türevleri sıfıra eşitliyoruz.
değişkenlere göre A Ve B, bu türevleri sıfıra eşitliyoruz. 
Ortaya çıkan denklem sistemini herhangi bir yöntemi kullanarak çözeriz (örneğin ikame yöntemiyle veya Cramer'in yöntemi) ve en küçük kareler yöntemini (LSM) kullanarak katsayıları bulmak için formüller elde edin. 
Verilen A Ve B işlev ![]() en küçük değeri alır. Bu gerçeğin kanıtı veriliyor sayfanın sonundaki metinde aşağıda.
en küçük değeri alır. Bu gerçeğin kanıtı veriliyor sayfanın sonundaki metinde aşağıda.
En küçük kareler yönteminin tamamı budur. Parametreyi bulma formülü A toplamları ve parametreyi içerir N- deneysel veri miktarı. Bu tutarların değerlerinin ayrı ayrı hesaplanmasını öneririz. Katsayı B Hesaplamadan sonra bulunan A.
Orijinal örneği hatırlamanın zamanı geldi.
Çözüm.
Örneğimizde n=5. Gerekli katsayıların formüllerinde yer alan tutarların hesaplanmasında kolaylık sağlamak için tabloyu dolduruyoruz. 
Tablonun dördüncü satırındaki değerler, her sayı için 2. satırdaki değerlerin 3. satırdaki değerlerle çarpılmasıyla elde edilir. Ben.
Tablonun beşinci satırındaki değerler, her sayı için 2. satırdaki değerlerin karesi alınarak elde edilir. Ben.
Tablonun son sütunundaki değerler satırlar arasındaki değerlerin toplamıdır.
Katsayıları bulmak için en küçük kareler yönteminin formüllerini kullanıyoruz A Ve B. Tablonun son sütunundaki karşılık gelen değerleri bunların yerine koyarız: 
Buradan, y = 0,165x+2,184- istenen yaklaşık düz çizgi.
Hangi satırlardan hangisinin olduğunu bulmak için kalır y = 0,165x+2,184 veya ![]() orijinal verilere daha iyi yaklaşır, yani en küçük kareler yöntemini kullanarak bir tahmin yapar.
orijinal verilere daha iyi yaklaşır, yani en küçük kareler yöntemini kullanarak bir tahmin yapar.
En küçük kareler yönteminde hata tahmini.
Bunu yapmak için orijinal verilerin bu çizgilerden sapmalarının karelerinin toplamını hesaplamanız gerekir. ![]() Ve
Ve ![]() , daha küçük bir değer, en küçük kareler yöntemi anlamında orijinal verilere daha iyi yaklaşan bir çizgiye karşılık gelir.
, daha küçük bir değer, en küçük kareler yöntemi anlamında orijinal verilere daha iyi yaklaşan bir çizgiye karşılık gelir. 
O zamandan beri düz y = 0,165x+2,184 orijinal verilere daha iyi yaklaşır.
En küçük kareler (LS) yönteminin grafiksel gösterimi.
Grafiklerde her şey açıkça görülüyor. Kırmızı çizgi bulunan düz çizgidir y = 0,165x+2,184, mavi çizgi ![]() , pembe noktalar orijinal verilerdir.
, pembe noktalar orijinal verilerdir.

Uygulamada, çeşitli süreçleri (özellikle ekonomik, fiziksel, teknik, sosyal) modellerken, fonksiyonların yaklaşık değerlerini belirli sabit noktalarda bilinen değerlerinden hesaplamak için bir veya başka bir yöntem yaygın olarak kullanılır.
Bu tür fonksiyon yaklaşımı problemi sıklıkla ortaya çıkar:
deney sonucunda elde edilen tablo verilerini kullanarak, incelenen sürecin karakteristik miktarlarının değerlerini hesaplamak için yaklaşık formüller oluştururken;
sayısal entegrasyon, türev, çözüm diferansiyel denklemler vesaire.;
fonksiyonların değerlerini dikkate alınan aralığın ara noktalarında hesaplamak gerekiyorsa;
dikkate alınan aralığın dışındaki bir sürecin karakteristik miktarlarının değerlerini belirlerken, özellikle tahmin yaparken.
Bir tablo tarafından belirtilen belirli bir süreci modellemek için, en küçük kareler yöntemine dayalı olarak bu süreci yaklaşık olarak tanımlayan bir fonksiyon oluşturursak, buna yaklaşıklık fonksiyonu (regresyon) adı verilecek ve yaklaşıklık fonksiyonlarının oluşturulması probleminin kendisi çağrılacaktır. bir yakınsama problemi.
Bu makale, MS Excel paketinin bu tür sorunları çözme konusundaki yeteneklerini tartışmakta, ayrıca tablo halindeki regresyonları oluşturmak (oluşturmak) için yöntemler ve teknikler sunmaktadır. belirtilen işlevler(Bu, regresyon analizinin temelidir).
Excel'in regresyon oluşturmak için iki seçeneği vardır.
İncelenen süreç karakteristiği için bir veri tablosu temelinde oluşturulan bir diyagrama seçilen regresyonların (eğilim çizgileri) eklenmesi (yalnızca bir diyagram oluşturulmuşsa kullanılabilir);
Excel çalışma sayfasının yerleşik istatistiksel işlevlerini kullanarak, doğrudan kaynak veri tablosuna dayalı olarak regresyonlar (eğilim çizgileri) elde etmenize olanak tanır.
Grafiğe trend çizgileri ekleme
Bir süreci tanımlayan ve bir diyagramla temsil edilen bir veri tablosu için Excel'in aşağıdakileri yapmanıza olanak tanıyan etkili bir regresyon analiz aracı vardır:
en küçük kareler yöntemini temel alarak oluşturun ve diyagrama beş ekleyin regresyon türleri incelenmekte olan süreci değişen derecelerde doğrulukla modelleyen;
oluşturulan regresyon denklemini diyagrama ekleyin;
Seçilen regresyonun grafikte görüntülenen verilere uygunluk derecesini belirleyin.
Excel, grafik verilerine dayanarak, denklemle belirtilen doğrusal, polinom, logaritmik, güç, üstel regresyon türlerini elde etmenize olanak tanır:
y = y(x)
burada x, genellikle bir dizi doğal sayının (1; 2; 3; ...) değerlerini alan ve örneğin incelenen sürecin zamanının geri sayımını (özellikler) üreten bağımsız bir değişkendir.
1 . Doğrusal regresyon, değerleri sabit bir oranda artan veya azalan özellikleri modellemek için iyidir. Bu, incelenen süreç için oluşturulacak en basit modeldir. Aşağıdaki denkleme göre inşa edilir:
y = mx + b
burada m eğim açısının tanjantıdır doğrusal regresyon apsis eksenine; b - doğrusal regresyonun ordinat ekseni ile kesişme noktasının koordinatı.
2 . Bir polinom eğilim çizgisi, birkaç farklı uç noktaya (maksimum ve minimum) sahip özellikleri tanımlamak için kullanışlıdır. Polinom derecesinin seçimi, incelenen özelliğin ekstremum sayısına göre belirlenir. Dolayısıyla, ikinci dereceden bir polinom, yalnızca bir maksimumu veya minimumu olan bir süreci iyi tanımlayabilir; üçüncü dereceden polinom - en fazla iki ekstrema; dördüncü dereceden polinom - en fazla üç ekstrema vb.
Bu durumda trend çizgisi aşağıdaki denkleme göre oluşturulur:
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
burada c0, c1, c2,... c6 katsayıları inşaat sırasında değerleri belirlenen sabitlerdir.
3 . Logaritmik eğilim çizgisi, değerleri başlangıçta hızla değişen ve daha sonra yavaş yavaş sabitlenen özelliklerin modellenmesinde başarıyla kullanılır.
y = c ln(x) + b
4 . Güç yasası eğilim çizgisi, incelenen ilişkinin değerleri büyüme oranındaki sürekli bir değişiklikle karakterize ediliyorsa iyi sonuçlar verir. Böyle bir bağımlılığın bir örneği, bir arabanın eşit şekilde hızlandırılmış hareketinin grafiğidir. Veriler sıfır içeriyorsa veya negatif değerler, bir güç trend çizgisi kullanamazsınız.
Denkleme göre oluşturulmuştur:
y = cxb
burada b, c katsayıları sabittir.
5 . Verilerdeki değişim hızı sürekli arttığında üstel eğilim çizgisi kullanılmalıdır. Sıfır veya negatif değer içeren veriler için bu tür bir yaklaşım da uygulanamaz.
Denkleme göre oluşturulmuştur:
y = c ebx
burada b, c katsayıları sabittir.
Bir eğilim çizgisi seçerken Excel, yaklaşımın güvenilirliğini karakterize eden R2 değerini otomatik olarak hesaplar: daha yakın değer R2'den birliğe doğru eğilim çizgisi, incelenen sürece ne kadar güvenilir bir şekilde yaklaşıyorsa. Gerektiğinde R2 değeri her zaman grafikte görüntülenebilir.
Formülle belirlenir:

Bir veri serisine trend çizgisi eklemek için:
bir dizi veriye dayalı olarak bir grafiği etkinleştirin, yani grafik alanının içine tıklayın. Diyagram öğesi ana menüde görünecektir;
Bu öğeye tıkladıktan sonra ekranda Trend çizgisi ekle komutunu seçmeniz gereken bir menü görünecektir.
Aynı eylemler, fare işaretçisini veri serilerinden birine karşılık gelen grafiğin üzerine getirip sağ tıklatarak kolayca uygulanabilir; Görüntülenen içerik menüsünde Trend çizgisi ekle komutunu seçin. Tür sekmesi açılmış olarak ekranda Trend Çizgisi iletişim kutusu görünecektir (Şekil 1).

Bundan sonra ihtiyacınız var:
Tür sekmesinde seçin gerekli tür trend çizgileri (Doğrusal tür varsayılan olarak seçilidir). Polinom türü için Derece alanında seçilen polinomun derecesini belirtin.
1 . Yerleşik seriler alanı, söz konusu grafikteki tüm veri serilerini listeler. Belirli bir veri serisine trend çizgisi eklemek için Oluşturulan seriler alanında bu çizginin adını seçin.

Gerekirse Parametreler sekmesine (Şekil 2) giderek trend çizgisi için aşağıdaki parametreleri ayarlayabilirsiniz:
Yaklaşık (düzleştirilmiş) eğrinin adı alanında trend çizgisinin adını değiştirin.
Tahmin alanında tahmin için dönem sayısını (ileri veya geri) ayarlayın;
diyagram alanında denklemi göster onay kutusunu etkinleştirmeniz gereken trend çizgisinin denklemini görüntüleyin;
yaklaşık güvenilirlik değeri R2'yi diyagram alanında görüntüleyin; bunun için Yaklaşım güvenilirlik değerini diyagrama yerleştir (R^2) onay kutusunu etkinleştirmeniz gerekir;
trend çizgisinin Y ekseni ile kesişme noktasını ayarlayın; bunun için eğrinin Y ekseni ile bir noktada kesişmesi için onay kutusunu etkinleştirmeniz gerekir;
İletişim kutusunu kapatmak için Tamam düğmesini tıklayın.
Zaten çizilmiş bir trend çizgisini düzenlemeye başlamanın üç yolu vardır:
daha önce trend çizgisini seçtikten sonra Format menüsünden Seçilen trend çizgisi komutunu kullanın;
trend çizgisine sağ tıklanarak çağrılan içerik menüsünden Trend çizgisini formatla komutunu seçin;
trend çizgisine çift tıklayın.
Ekranda üç sekme içeren Trend Çizgisi Formatı iletişim kutusu görünecektir (Şekil 3): Görünüm, Tür, Parametreler ve son ikisinin içeriği, Trend Çizgisi iletişim kutusunun benzer sekmeleriyle tamamen örtüşmektedir (Şekil 1). -2). Görünüm sekmesinde çizgi türünü, rengini ve kalınlığını ayarlayabilirsiniz.

Daha önce çizilmiş bir trend çizgisini silmek için silinecek trend çizgisini seçin ve Sil tuşuna basın.
Dikkate alınan regresyon analiz aracının avantajları şunlardır:
bir veri tablosu oluşturmadan grafikler üzerinde bir trend çizgisi oluşturmanın göreceli kolaylığı;
önerilen trend çizgisi türlerinin oldukça geniş bir listesi ve bu liste en sık kullanılan regresyon türlerini içerir;
İncelenmekte olan sürecin davranışını herhangi bir düzeyde (içinde) tahmin etme yeteneği sağduyu) ileri ve geri adım sayısı;
trend çizgisi denklemini analitik biçimde elde etme yeteneği;
Gerekirse, yaklaşımın güvenilirliğine ilişkin bir değerlendirme elde etme olasılığı.
Dezavantajları aşağıdakileri içerir:
bir trend çizgisinin oluşturulması yalnızca bir dizi veri üzerine kurulu bir diyagram varsa gerçekleştirilir;
elde edilen eğilim çizgisi denklemlerine dayanarak incelenen karakteristik için veri serisi oluşturma süreci biraz karmaşıktır: gerekli regresyon denklemleri, orijinal veri serisinin değerlerindeki her değişiklikle birlikte, ancak yalnızca diyagram alanı içinde güncellenir. , sırasında veri serisi Eski trend çizgisi denklemine göre oluşturulan değişmeden kalır;
PivotChart raporlarında, bir grafiğin veya ilişkili PivotTable raporunun görünümünü değiştirmek mevcut eğilim çizgilerini korumaz; bu, eğilim çizgileri çizmeden veya PivotChart raporunu başka şekilde biçimlendirmeden önce rapor düzeninin gerekli gereksinimleri karşıladığından emin olmanız gerektiği anlamına gelir.
Eğilim çizgileri, grafik, histogram, düz standartlaştırılmamış alan grafikleri, çubuk grafikler, dağılım grafikleri, kabarcık grafikleri ve hisse senedi grafikleri gibi grafiklerde sunulan veri serilerini desteklemek için kullanılabilir.
3B, normalleştirilmiş, radar, pasta ve halka grafiklerindeki veri serilerine trend çizgileri ekleyemezsiniz.
Excel'in yerleşik işlevlerini kullanma
Excel'de ayrıca grafik alanının dışındaki trend çizgilerini çizmek için bir regresyon analiz aracı da bulunur. Bu amaç için kullanılabilecek çok sayıda istatistiksel çalışma sayfası işlevi vardır, ancak bunların tümü yalnızca doğrusal veya üstel regresyonlara izin verir.
Excel'in doğrusal regresyon oluşturmak için çeşitli işlevleri vardır, özellikle:
EĞİM ve KESME.
TREND;
Ve ayrıca bina için çeşitli işlevler üstel çizgi eğilim, özellikle:
LGRFPRIBL.
TREND ve BÜYÜME işlevlerini kullanarak regresyon oluşturma tekniklerinin neredeyse aynı olduğunu belirtmek gerekir. Aynı şey LINEST ve LGRFPRIBL işlev çifti için de söylenebilir. Bu dört işlev için bir değer tablosu oluşturmak, regresyon oluşturma sürecini biraz karmaşıklaştıran dizi formülleri gibi Excel özelliklerini kullanır. Ayrıca, bizim görüşümüze göre doğrusal regresyon oluşturmanın en kolay şekilde SLOPE ve INTERCEPT işlevleri kullanılarak gerçekleştirildiğine dikkat edin; bunlardan birincisi doğrusal regresyonun eğimini belirler ve ikincisi, y üzerindeki regresyon tarafından kesilen parçayı belirler. -eksen.
Regresyon analizi için yerleşik işlevler aracının avantajları şunlardır:
eğilim çizgilerini tanımlayan tüm yerleşik istatistiksel işlevler için incelenmekte olan karakteristiğe ait veri serilerinin oluşturulmasına yönelik oldukça basit, tek tip bir süreç;
oluşturulan veri serilerine dayalı trend çizgileri oluşturmak için standart metodoloji;
incelenen sürecin davranışını tahmin etme yeteneği gerekli miktar ileri veya geri adım atar.
Dezavantajları arasında Excel'in diğer (doğrusal ve üstel hariç) eğilim çizgileri türlerini oluşturmak için yerleşik işlevlere sahip olmaması yer alır. Bu durum çoğu zaman incelenen sürecin yeterince doğru bir modelinin seçilmesine ve gerçeğe yakın tahminlerin elde edilmesine izin vermez. Ayrıca TREND ve BÜYÜME fonksiyonları kullanıldığında trend çizgilerinin denklemleri bilinmemektedir.
Yazarların, regresyon analizinin gidişatını herhangi bir bütünlük derecesiyle sunmaya çalışmadıklarına dikkat edilmelidir. Ana görevi, yaklaşım problemlerini çözerken Excel paketinin yeteneklerini belirli örnekler kullanarak göstermektir; Regresyonlar ve tahminler oluşturmak için Excel'in hangi etkili araçlara sahip olduğunu gösterin; regresyon analizi konusunda geniş bilgiye sahip olmayan bir kullanıcı tarafından bile bu tür problemlerin nasıl nispeten kolay çözülebileceğini göstermektedir.
Çözüm örnekleri belirli görevler
Excel paketinde listelenen araçları kullanarak belirli sorunları çözmeyi düşünelim.
Sorun 1
Bir motorlu taşımacılık işletmesinin 1995-2002 dönemine ilişkin kârına ilişkin bir veri tablosu ile. aşağıdakileri yapmanız gerekir:
Bir diyagram oluşturun.
Grafiğe doğrusal ve polinom (ikinci dereceden ve kübik) eğilim çizgileri ekleyin.
Eğilim çizgisi denklemlerini kullanarak, 1995-2004 yılları için her bir eğilim çizgisi için işletme karlarına ilişkin tablo halinde veriler elde edin.
İşletmenin 2003 ve 2004 yılı karı için bir tahmin yapın.
Sorun çözümü

Excel çalışma sayfasının A4:C11 hücreleri aralığına, Şekil 2'de gösterilen çalışma sayfasını girin. 4.
B4:C11 hücre aralığını seçtikten sonra bir diyagram oluşturuyoruz.
Oluşturulan diyagramı etkinleştiriyoruz ve yukarıda açıklanan yönteme göre Trend Çizgisi iletişim kutusunda trend çizgisi türünü seçtikten sonra (bkz. Şekil 1), diyagrama dönüşümlü olarak doğrusal, karesel ve kübik trend çizgileri ekliyoruz. Aynı iletişim kutusunda, Parametreler sekmesini açın (bkz. Şekil 2), yaklaşık (düzleştirilmiş) eğrinin adı alanına, eklenen trendin adını girin ve İleriye yönelik tahmin: dönemler alanına, değeri 2, çünkü iki yıl sonrası için kar tahmini yapılması planlanıyor. Regresyon denklemini ve yaklaşım güvenilirlik değeri R2'yi diyagram alanında görüntülemek için denklemi ekranda göster onay kutularını etkinleştirin ve yaklaşım güvenilirlik değerini (R^2) diyagrama yerleştirin. En iyisi için görsel algı Trend Çizgisi Formatı iletişim kutusunun Görünüm sekmesini kullandığımız, oluşturulan trend çizgilerinin türünü, rengini ve kalınlığını değiştiririz (bkz. Şekil 3). Eklenen trend çizgileri ile ortaya çıkan diyagram, Şekil 1'de gösterilmektedir. 5.
1995-2004 yılları için her bir trend çizgisi için kurumsal karlara ilişkin tablo halinde veri elde etmek.


Şekil 2'de sunulan trend çizgisi denklemlerini kullanalım. 5. Bunu yapmak için D3:F3 aralığındaki hücrelere seçilen trend çizgisinin türü hakkında metin bilgilerini girin: Doğrusal trend, Karesel trend, Kübik trend. Daha sonra, D4 hücresine doğrusal regresyon formülünü girin ve doldurma işaretini kullanarak bu formülü, D5:D13 hücre aralığına göreli referanslarla kopyalayın. D4:D13 hücre aralığından doğrusal regresyon formülüne sahip her hücrenin, A4:A13 aralığından karşılık gelen bir hücreye argüman olarak sahip olduğuna dikkat edilmelidir. Benzer şekilde, ikinci dereceden regresyon için E4:E13 hücre aralığını doldurun ve kübik regresyon için F4:F13 hücre aralığını doldurun. Böylece işletmenin 2003 ve 2004 yılı kârına ilişkin bir tahmin derlendi. üç trendi kullanıyor. Ortaya çıkan değer tablosu Şekil 2'de gösterilmektedir. 6.
Bir diyagram oluşturun.
Sorun 2
Grafiğe logaritmik, güç ve üstel eğilim çizgileri ekleyin.
Elde edilen trend çizgilerinin denklemlerini ve her biri için R2 yaklaşımının güvenilirlik değerlerini türetin.
Eğilim çizgisi denklemlerini kullanarak, 1995-2002 yılları için her bir eğilim çizgisi için işletmenin kârına ilişkin tablo halindeki verileri elde edin.
Sorun çözümü
Bu trend çizgilerini kullanarak şirketin 2003 ve 2004 karı hakkında bir tahmin yapın.


Problem 1'in çözümünde verilen metodolojiyi takip ederek, logaritmik, güç ve üstel eğilim çizgilerinin eklendiği bir diyagram elde ediyoruz (Şekil 7). Daha sonra, elde edilen trend çizgisi denklemlerini kullanarak, 2003 ve 2004 yılları için öngörülen değerleri de içeren, işletmenin karı için bir değerler tablosu dolduruyoruz. (Şekil 8).
Şek. 5 ve Şek. Logaritmik eğilime sahip modelin, yaklaşım güvenilirliğinin en düşük değerine karşılık geldiği görülebilir.
R2 = 0,8659
R2'nin en yüksek değerleri polinom eğilimi olan modellere karşılık gelir: ikinci dereceden (R2 = 0,9263) ve kübik (R2 = 0,933).
Sorun 3
Görev 1'de verilen, bir motorlu taşımacılık kuruluşunun 1995-2002 dönemine ilişkin kârına ilişkin veri tablosuyla aşağıdaki adımları uygulamanız gerekir.
TREND ve BÜYÜME işlevlerini kullanarak doğrusal ve üstel eğilim çizgileri için veri serileri elde edin.
TREND ve BÜYÜME işlevlerini kullanarak işletmenin 2003 ve 2004 yılı kârına ilişkin bir tahmin yapın.
Sorun çözümü
Orijinal veriler ve elde edilen veri serileri için bir diyagram oluşturun.
işletmenin kârına ilişkin bilinen verilere karşılık gelen TREND fonksiyonunun değerleriyle doldurulması gereken D4:D11 hücre aralığını seçin;
Ekle menüsünden İşlev komutunu çağırın. Görüntülenen İşlev Sihirbazı iletişim kutusunda İstatistik kategorisinden TREND işlevini seçin ve ardından Tamam düğmesine tıklayın. Aynı işlem standart araç çubuğundaki (Fonksiyon Ekle) düğmesine tıklanarak da yapılabilir.
Görüntülenen İşlev Bağımsız Değişkenleri iletişim kutusunda Bilinen_değerler_y alanına C4:C11 hücre aralığını girin; Bilinen_değerler_x alanında - B4:B11 hücre aralığı;
Girilen formülün bir dizi formülü haline gelmesi için ++ tuş birleşimini kullanın.
Formül çubuğuna girdiğimiz formül şu şekilde görünecektir: =(TREND(C4:C11,B4:B11)).
Sonuç olarak, D4:D11 hücre aralığı TREND fonksiyonunun karşılık gelen değerleriyle doldurulur (Şekil 9).

İşletmenin 2003 ve 2004 yılı kârına ilişkin tahmin yapmak. gerekli:
TREND fonksiyonu tarafından tahmin edilen değerlerin girileceği D12:D13 hücre aralığını seçin.
TREND işlevini çağırın ve beliren İşlev Bağımsız Değişkenleri iletişim kutusunda Bilinen_değerler_y alanına - C4:C11 hücre aralığını girin; Bilinen_değerler_x alanında - B4:B11 hücre aralığı; ve New_values_x alanında - B12:B13 hücre aralığı.
Ctrl + Shift + Enter tuş kombinasyonunu kullanarak bu formülü bir dizi formülüne dönüştürün.
Girilen formül şu şekilde görünecektir: =(TREND(C4:C11;B4:B11;B12:B13)) ve D12:D13 hücre aralığı, TREND fonksiyonunun öngörülen değerleriyle doldurulacaktır (bkz. 9).
Veri serisi, doğrusal olmayan bağımlılıkların analizinde kullanılan ve doğrusal karşılığı TREND ile tamamen aynı şekilde çalışan BÜYÜME işlevi kullanılarak benzer şekilde doldurulur.
Şekil 10'da formül görüntüleme modundaki tablo gösterilmektedir.


İlk veriler ve elde edilen veri serileri için, Şekil 1'de gösterilen diyagram. 11.
Sorun 4
Bir motorlu taşıt işletmesinin sevkıyat servisi tarafından cari ayın 1'inden 11'ine kadar olan süre için hizmet başvurularının alınmasına ilişkin veri tablosu ile aşağıdaki işlemleri gerçekleştirmelisiniz.
Doğrusal regresyon için veri serileri alma: EĞİM ve KESME NOKTASI işlevlerini kullanma; DOT işlevini kullanarak.
LGRFPRIBL işlevini kullanarak üstel regresyon için bir veri serisi elde edin.
Yukarıdaki işlevleri kullanarak, içinde bulunulan ayın 12'sinden 14'üne kadar olan dönem için sevk hizmetine başvuruların alınmasına ilişkin bir tahmin yapın.
Orijinal ve alınan veri serileri için bir diyagram oluşturun.
Sorun çözümü
TREND ve BÜYÜME işlevlerinden farklı olarak, yukarıda listelenen işlevlerin (EĞİM, KESME NOKTASI, DİZGİ, LGRFPRIB) hiçbirinin regresyon olmadığını unutmayın. Bu işlevler yalnızca gerekli regresyon parametrelerini belirleyen destekleyici bir rol oynar.
EĞİLİM, KESME NOKTASI, DİZGİ, LGRFPRIB fonksiyonları kullanılarak oluşturulan doğrusal ve üstel regresyonlar için, TREND ve BÜYÜME fonksiyonlarına karşılık gelen doğrusal ve üstel regresyonların aksine, denklemlerinin görünümü her zaman bilinir.
1 . Denklemi kullanarak doğrusal bir regresyon oluşturalım:
y = mx+b
regresyon eğimi m, SLOPE işlevi tarafından belirlenir ve serbest terim b, KESMENOKTASI işlevi tarafından belirlenir.
Bunu yapmak için aşağıdaki eylemleri gerçekleştiriyoruz:
orijinal tabloyu A4:B14 hücre aralığına girin;
m parametresinin değeri C19 hücresinde belirlenecektir. Kategoriden seç İstatistiksel fonksiyon Eğim; bilinen_değerler_y alanına B4:B14 hücre aralığını ve bilinen_değerler_x alanına A4:A14 hücre aralığını girin.
Formül C19 hücresine girilecektir: =EĞİM(B4:B14,A4:A14);
Benzer bir teknik kullanılarak D19 hücresindeki b parametresinin değeri belirlenir. İçeriği şu şekilde görünecektir: =SEGMENT(B4:B14,A4:A14). Böylece, doğrusal bir regresyon oluşturmak için gereken m ve b parametrelerinin değerleri sırasıyla C19, D19 hücrelerinde saklanacaktır;
2 Daha sonra, doğrusal regresyon formülünü C4 hücresine şu biçimde girin: =$C*A4+$D. Bu formülde C19 ve D19 hücreleri mutlak referanslarla yazılmıştır (olası kopyalama sırasında hücre adresi değişmemelidir). Mutlak referans işareti $, klavyeden veya imleci hücre adresinin üzerine getirdikten sonra F4 tuşunu kullanarak yazılabilir.
y = mx+b
Doldurma tutamacını kullanarak bu formülü C4:C17 hücre aralığına kopyalayın. Gerekli veri serisini elde ediyoruz (Şekil 12). Uygulama sayısının tam sayı olması nedeniyle Hücre Formatı penceresinin Sayı sekmesinde ondalık basamak sayısını içeren sayı biçimini 0 olarak ayarlamanız gerekmektedir.
. Şimdi denklem tarafından verilen doğrusal bir regresyon oluşturalım:
DOT işlevini kullanarak.
Bunu yapmak için:
DOT işlevini C20:D20 hücre aralığına dizi formülü olarak girin: =(LINEST(B4:B14,A4:A14)). Sonuç olarak, C20 hücresinde m parametresinin değerini ve D20 hücresinde b parametresinin değerini elde ederiz;
3 formülü D4 hücresine girin: =$C*A4+$D;
LGRFPRIBL işlevi kullanılarak benzer şekilde gerçekleştirilir:
C21:D21 hücre aralığında LGRFPRIBL fonksiyonunu bir dizi formülü olarak giriyoruz: =( LGRFPRIBL (B4:B14,A4:A14)). Bu durumda m parametresinin değeri C21 hücresinde, b parametresinin değeri D21 hücresinde belirlenecek;
formül E4 hücresine girilir: =$D*$C^A4;
doldurma işaretçisi kullanılarak bu formül, üstel regresyona yönelik veri serilerinin yerleştirileceği E4:E17 hücre aralığına kopyalanır (bkz. Şekil 12).

Şek. Şekil 13'te gerekli hücre aralıklarıyla kullandığımız fonksiyonları ve formülleri görebileceğiniz bir tablo gösterilmektedir.
Büyüklük R 2 isminde belirleme katsayısı.
Bir regresyon bağımlılığı oluşturma görevi, R katsayısının maksimum değeri aldığı model (1)'in m katsayılarının vektörünü bulmaktır.
R'nin önemini değerlendirmek için aşağıdaki formül kullanılarak hesaplanan Fisher F testi kullanılır:

Nerede N- numune büyüklüğü (deney sayısı);
k, model katsayılarının sayısıdır.
Eğer F veri için bazı kritik değerleri aşarsa N Ve k ve kabul edilen güven olasılığı, bu durumda R'nin değeri anlamlı kabul edilir. Tablolar kritik değerler F matematiksel istatistiklerle ilgili referans kitaplarında verilmiştir.
Böylece, R'nin önemi yalnızca değeriyle değil, aynı zamanda deney sayısı ile modelin katsayıları (parametreleri) sayısı arasındaki oranla da belirlenir. Aslında, basit bir doğrusal model için n=2 için korelasyon oranı 1'e eşittir (tek bir düz çizgi her zaman bir düzlemdeki 2 noktadan çizilebilir). Ancak eğer deneysel veriler rastgele değişkenler, bu R değerine büyük bir dikkatle güvenilmelidir. Genellikle anlamlı R ve güvenilir regresyon elde etmek için deney sayısının model katsayılarının sayısını (n>k) önemli ölçüde aşmasını sağlamaya çalışırlar.
Doğrusal bir yapı oluşturmak için regresyon modeli gerekli:
1) deneysel verileri içeren n satır ve m sütundan oluşan bir liste hazırlayın (çıkış değerini içeren sütun) e listede ilk veya son olmalıdır); Örneğin bir önceki görevin verilerini alalım, “Dönem No.” diye bir sütun ekleyelim, dönem sayılarını 1'den 12'ye kadar numaralandıralım. (bunlar değerler olacaktır) X)
2) Veri/Veri Analizi/Regresyon menüsüne gidin

"Araçlar" menüsünde "Veri Analizi" öğesi eksikse, aynı menüdeki "Eklentiler" öğesine gidip "Analiz paketi" onay kutusunu işaretlemelisiniz.
3) "Regresyon" iletişim kutusunda şunu ayarlayın:
· giriş aralığı Y;
· giriş aralığı X;
· çıktı aralığı - hesaplama sonuçlarının yerleştirileceği aralığın sol üst hücresi (bunların yeni bir çalışma sayfasına yerleştirilmesi önerilir);

4) "Tamam"a tıklayın ve sonuçları analiz edin.
Sıradan En Küçük Kareler (OLS) yöntemi - matematiksel yöntem, çözmek için kullanılır çeşitli görevler, bazı fonksiyonların istenen değişkenlerden sapmalarının karelerinin toplamının en aza indirilmesine dayanır. Aşırı belirlenmiş denklem sistemlerini (denklem sayısı bilinmeyenlerin sayısını aştığında) “çözmek”, sıradan (aşırı belirlenmemiş) denklemler durumunda bir çözüm bulmak için kullanılabilir. doğrusal olmayan sistemler belirli bir fonksiyonun nokta değerlerine yaklaşmak için denklemler. OLS, örnek verilerden regresyon modellerinin bilinmeyen parametrelerini tahmin etmek için kullanılan temel regresyon analizi yöntemlerinden biridir.
Ansiklopedik YouTube
1 / 5
✪ En küçük kareler yöntemi. Ders
✪ En küçük kareler yöntemi, ders 1/2. Doğrusal fonksiyon
✪ Ekonometri. Ders 5. En Küçük Kareler Yöntemi
✪ Mitin I.V. - Fiziksel sonuçların işlenmesi. deney - En küçük kareler yöntemi (Ders 4)
✪ Ekonometri: En küçük kareler yönteminin özü #2
Altyazılar
Hikaye
İle XIX'in başı V. bilim adamlarının sahip olmadığı belirli kurallar bilinmeyenlerin sayısının denklem sayısından az olduğu bir denklem sistemini çözmek; O zamana kadar denklemlerin türüne ve hesap makinelerinin zekasına bağlı olarak özel teknikler kullanıldı ve bu nedenle aynı gözlem verilerine dayanan farklı hesap makineleri ortaya çıktı. çeşitli sonuçlar. Yöntemin ilk uygulamasından Gauss (1795) sorumluydu ve Legendre (1805) bunu bağımsız olarak keşfedip yayınladı. modern isim(Fr. En İyi Yöntemler). Laplace yöntemi olasılık teorisiyle ilişkilendirdi ve Amerikalı matematikçi Adrain (1808) onun olasılık teorisi uygulamalarını değerlendirdi. Yöntem, Encke, Bessel, Hansen ve diğerlerinin daha ileri araştırmalarıyla yaygınlaştırıldı ve geliştirildi.
En küçük kareler yönteminin özü
İzin vermek x (\displaystyle x)- kit n (\displaystyle n) bilinmeyen değişkenler (parametreler), f ben (x) (\displaystyle f_(i)(x)), , m > n (\displaystyle m>n)- bu değişkenler kümesinden bir dizi işlev. Görev bu değerleri seçmektir x (\displaystyle x) böylece bu fonksiyonların değerleri belirli değerlere mümkün olduğunca yakın olur. y ben (\displaystyle y_(i)). Esasen hakkında konuşuyoruz Aşırı belirlenmiş bir denklem sisteminin “çözümü” hakkında f ben (x) = y ben (\displaystyle f_(i)(x)=y_(i)), i = 1 , … , m (\displaystyle i=1,\ldots ,m) soldaki belirtilen maksimum yakınlık anlamında ve doğru parçalar sistemler. En küçük kareler yönteminin özü, sol ve sağ tarafların sapmalarının karelerinin toplamını bir “yakınlık ölçüsü” olarak seçmektir. | f ben (x) − y ben |
(\displaystyle |f_(i)(x)-y_(i)|).. Dolayısıyla MNC'nin özü şu şekilde ifade edilebilir: ∑ ben e ben 2 = ∑ ben (y ben − f ben (x)) 2 → min x (\displaystyle \sum _(i)e_(i)^(2)=\sum _(i)(y_(i)-f_( i)(x))^(2)\rightarrow \min _(x)) Denklem sisteminin bir çözümü varsa, minimum kareler toplamı şu şekilde olacaktır: sıfıra eşit Denklem sisteminin kesin çözümleri analitik olarak veya örneğin çeşitli yöntemler kullanılarak bulunabilir. sayısal yöntemler optimizasyon. Eğer sistem aşırı belirlenmişse, yani genel anlamda bağımsız denklemlerin sayısı x (\displaystyle x) daha fazla miktar İstenilen değişkenler varsa, bu durumda sistemin kesin bir çözümü olmaz ve en küçük kareler yöntemi bazı "optimum" vektörleri bulmamıza olanak tanır. vektörlerin maksimum yakınlığı anlamında y (\displaystyle y) Ve f (x) (\displaystyle f(x)) veya sapma vektörünün maksimum yakınlığı
e (\displaystyle e)
sıfıra (yakınlık Öklid uzaklığı anlamında anlaşılmaktadır). Örnek - doğrusal denklem sistemi
Özellikle sistemi "çözmek" için en küçük kareler yöntemi kullanılabilir,Nerede doğrusal denklemler A x = b (\displaystyle Ax=b) bir (\displaystyle A) dikdörtgen matris boyut
m × n , m > n (\displaystyle m\times n,m>n) (yani A matrisinin satır sayısı aranan değişken sayısından daha fazladır). Böyle bir denklem sistemi x (\displaystyle x) genel durum çözümü yok. Dolayısıyla bu sistem ancak böyle bir vektörün seçilmesi anlamında “çözülebilir” vektörlerin maksimum yakınlığı anlamında vektörler arasındaki "mesafeyi" en aza indirmek için A x (\displaystyle Ax) b (\displaystyle b). Bunu yapmak için sistem denklemlerinin sol ve sağ tarafları arasındaki farkların karelerinin toplamını en aza indirme kriterini uygulayabilirsiniz; (A x − b) T (A x − b) → min (\displaystyle (Ax-b)^(T)(Ax-b)\rightarrow \min ). Bu minimizasyon problemini çözmenin çözüme yol açtığını göstermek kolaydır
sonraki sistem.denklemler
A T A x = A T b ⇒ x = (A T A) − 1 A T b (\displaystyle A^(T)Ax=A^(T)b\Rightarrow x=(A^(T)A)^(-1)A^ (T)b) n (\displaystyle n) Regresyon analizinde OLS (veri yaklaşımı) İstenilen değişkenler varsa, bu durumda sistemin kesin bir çözümü olmaz ve en küçük kareler yöntemi bazı "optimum" vektörleri bulmamıza olanak tanır. Olsun x (\displaystyle x) bazı değişkenlerin değerleri İstenilen değişkenler varsa, bu durumda sistemin kesin bir çözümü olmaz ve en küçük kareler yöntemi bazı "optimum" vektörleri bulmamıza olanak tanır. vektörlerin maksimum yakınlığı anlamında x (\displaystyle x)(bu gözlemlerin, deneylerin vb. sonuçları olabilir) ve ilgili değişkenler vektörler arasındaki "mesafeyi" en aza indirmek için. Buradaki zorluk, arasındaki ilişkinin sağlanmasıdır. en iyi değerler parametreler vektörler arasındaki "mesafeyi" en aza indirmek için değerlerin maksimuma yakınlaştırılması f (x , b) (\displaystyle f(x,b)) gerçek değerlere İstenilen değişkenler varsa, bu durumda sistemin kesin bir çözümü olmaz ve en küçük kareler yöntemi bazı "optimum" vektörleri bulmamıza olanak tanır.. Aslında bu, aşırı belirlenmiş bir denklem sisteminin "çözülmesi" durumuna gelir. vektörler arasındaki "mesafeyi" en aza indirmek için:
F (x t , b) = y t , t = 1 , … , n (\displaystyle f(x_(t),b)=y_(t),t=1,\ldots ,n).
Regresyon analizinde ve özellikle ekonometride, olasılıksal modeller değişkenler arasındaki bağımlılıklar
Y t = f (x t , b) + ε t (\displaystyle y_(t)=f(x_(t),b)+\varepsilon _(t)),
Nerede ε t (\displaystyle \varepsilon _(t))- sözde rastgele hatalar modeller.
Buna göre gözlenen değerlerin sapmaları İstenilen değişkenler varsa, bu durumda sistemin kesin bir çözümü olmaz ve en küçük kareler yöntemi bazı "optimum" vektörleri bulmamıza olanak tanır. modelden f (x , b) (\displaystyle f(x,b)) modelin kendisinde zaten varsayılmıştır. En küçük kareler yönteminin (sıradan, klasik) özü bu tür parametreleri bulmaktır. vektörler arasındaki "mesafeyi" en aza indirmek için, burada sapmaların karelerinin toplamı (hatalar; regresyon modelleri için bunlara genellikle regresyon artıkları denir) e t (\displaystyle e_(t)) minimum olacaktır:
b ^ O L S = arg min b R S S (b) (\displaystyle (\hat (b))_(OLS)=\arg \min _(b)RSS(b)),Nerede R S S (\displaystyle RSS)- İngilizce Artık Kareler Toplamı şu şekilde tanımlanır:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 (\displaystyle RSS(b)=e^(T)e=\sum _ (t=1)^(n)e_(t)^(2)=\toplam _(t=1)^(n)(y_(t)-f(x_(t),b))^(2) ).Genel durumda bu problem sayısal optimizasyon (minimizasyon) yöntemleriyle çözülebilir. Bu durumda onlar hakkında konuşuyorlar doğrusal olmayan en küçük kareler(NLS veya NLLS - İngilizce Doğrusal Olmayan En Küçük Kareler). Birçok durumda alabilirsiniz analitik çözüm. Minimizasyon problemini çözmek için şunu bulmak gerekir: sabit noktalar işlevler R S S (b) (\displaystyle RSS(b)) bilinmeyen parametrelere göre ayırt edilmesi vektörler arasındaki "mesafeyi" en aza indirmek için, türevleri sıfıra eşitlemek ve elde edilen denklem sistemini çözmek:
∑ t = 1 n (y t - f (x t , b)) ∂ f (x t , b) ∂ b = 0 (\displaystyle \sum _(t=1)^(n)(y_(t)-f(x_) (t),b))(\frac (\kısmi f(x_(t),b))(\kısmi b))=0).Doğrusal regresyon durumunda OLS
Regresyon bağımlılığının doğrusal olmasına izin verin:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t (\displaystyle y_(t)=\sum _(j=1)^(k)b_(j)x_(tj)+\varepsilon =x_( t)^(T)b+\varepsilon _(t)).İzin vermek sen açıklanan değişkenin gözlemlerinin sütun vektörüdür ve X (\displaystyle X)- Bu (n × k) (\displaystyle ((n\time k)))-faktör gözlemlerinin matrisi (matrisin satırları, faktör değerlerinin vektörleridir) bu gözlem, sütunlara göre - değerlerin vektörü bu faktör tüm gözlemlerde). Doğrusal modelin matris gösterimi şu şekildedir:
y = X b + ε (\displaystyle y=Xb+\varepsilon ).Daha sonra açıklanan değişkenin tahmin vektörü ile regresyon artıklarının vektörü eşit olacaktır.
y ^ = X b , e = y − y ^ = y − X b (\displaystyle (\hat (y))=Xb,\quad e=y-(\hat (y))=y-Xb).Buna göre regresyon artıklarının karelerinin toplamı şuna eşit olacaktır:
R S S = e T e = (y − X b) T (y − X b) (\displaystyle RSS=e^(T)e=(y-Xb)^(T)(y-Xb)).Bu fonksiyonun parametre vektörüne göre türevini almak vektörler arasındaki "mesafeyi" en aza indirmek için ve türevleri sıfıra eşitleyerek bir denklem sistemi elde ederiz ( matris formu):
(X T X) b = X T y (\displaystyle (X^(T)X)b=X^(T)y).Şifresi çözülmüş matris formunda bu denklem sistemi şuna benzer:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 ∑ x t 3 x t 2 ∑ x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y t ∑ x t 2 y t ∑ x t 3 y t ⋮ ∑ x t k y t) , (\displaystyle (\begin(pmatrix)\toplam x_(t1)^(2)&\toplam x_(t1)x_(t2)&\toplam x_(t1)x_(t3)&\ldots &\toplam x_(t1)x_(tk)\\\toplam x_(t2)x_(t1)&\toplam x_(t2)^(2)&\toplam x_(t2)x_(t3)&\ldots &\ toplam x_(t2)x_(tk)\\\toplam x_(t3)x_(t1)&\toplam x_(t3)x_(t2)&\toplam x_(t3)^(2)&\ldots &\sum x_ (t3)x_(tk)\\\vdots &\vdots &\vdots &\ddots &\vdots \\\toplam x_(tk)x_(t1)&\toplam x_(tk)x_(t2)&\toplam x_ (tk)x_(t3)&\ldots &\toplam x_(tk)^(2)\\\end(pmatrix))(\begin(pmatrix)b_(1)\\b_(2)\\b_(3 )\\\vdots \\b_(k)\\\end(pmatrix))=(\begin(pmatrix)\sum x_(t1)y_(t)\\\sum x_(t2)y_(t)\\ \sum x_(t3)y_(t)\\\vdots \\\sum x_(tk)y_(t)\\\end(pmatrix))),) herkes için tüm meblağların alındığı yer kabul edilebilir değerler t (\displaystyle t).
Modele bir sabit dahil edilmişse (her zamanki gibi), o zaman x t 1 = 1 (\displaystyle x_(t1)=1) herkesin önünde t (\displaystyle t) yani solda üst köşe denklem sisteminin matrisi gözlem sayısıdır n (\displaystyle n) ve ilk satırın ve ilk sütunun geri kalan öğelerinde - yalnızca değişken değerlerinin toplamları: ∑ x t j (\displaystyle \toplam x_(tj)) ve sistemin sağ tarafındaki ilk eleman ∑ y t (\displaystyle \toplam y_(t)).
Bu denklem sisteminin çözümü şunu verir: genel formül Doğrusal model için OLS tahminleri:
b ^ Ö L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y (\displaystyle (\hat (b))_(OLS)=(X^(T) )X)^(-1)X^(T)y=\left((\frac (1)(n))X^(T)X\right)^(-1)(\frac (1)(n ))X^(T)y=V_(x)^(-1)C_(xy)).Analitik amaçlar için, bu formülün son temsilinin faydalı olduğu ortaya çıkıyor (denklem sisteminde n'ye bölünürken toplamlar yerine aritmetik ortalamalar görünür). Bir regresyon modelinde veriler merkezli, o zaman bu gösterimde ilk matris, faktörlerin örnek bir kovaryans matrisi anlamına gelir ve ikincisi, faktörlerin bağımlı değişkenle kovaryanslarının bir vektörüdür. Ayrıca veriler aynı zamanda normalleştirilmiş MSE'ye (yani sonuçta standartlaştırılmış), bu durumda ilk matris bir örnek anlamına gelir korelasyon matrisi faktörler, ikinci vektör ise faktörlerin bağımlı değişkenle örnek korelasyonlarının vektörüdür.
Modeller için OLS tahminlerinin önemli bir özelliği sabit ile- oluşturulan regresyonun çizgisi örnek verilerin ağırlık merkezinden geçer, yani eşitlik sağlanır:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j (\displaystyle (\bar (y))=(\hat (b_(1)))+\sum _(j=2)^(k) (\hat (b))_(j)(\bar (x))_(j)).Özellikle, son çare olarak, tek regresör bir sabit olduğunda, OLS tahmincisinin şunu elde ederiz: tek parametre(sabitin kendisi) açıklanan değişkenin ortalama değerine eşittir. Yani, bilinen aritmetik ortalama iyi özellikler kanunlardan büyük sayılar, aynı zamanda bir en küçük kareler tahminidir - bundan minimum karesel sapmaların toplamı kriterini karşılar.
En basit özel durumlar
Eşleştirilmiş doğrusal regresyon durumunda y t = a + b x t + ε t (\displaystyle y_(t)=a+bx_(t)+\varepsilon _(t)) değerlendirildiğinde doğrusal bağımlılık bir değişken diğerinden, hesaplama formülleri basitleştirilmiştir (onsuz yapabilirsiniz) matris cebiri). Denklem sistemi şu şekildedir:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) (\displaystyle (\begin(pmatrix)1&(\bar (x))\\(\bar (x))&(\bar (x^(2)))\\\end(pmatrix)(\begin(pmatrix)a\\b\\\end(pmatrix))=(\begin(pmatrix)(\bar (y))\\ (\overline (xy))\\\end(pmatrix))).Buradan katsayı tahminlerini bulmak kolaydır:
( b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . (\displaystyle (\begin(cases) (\hat (b))=(\frac (\mathop (\textrm (Cov)) (x,y))(\mathop (\textrm (Var)) (x)))=(\frac ((\overline) (xy))-(\bar (x))(\bar (y))))((\overline (x^(2))))-(\overline (x))^(2))),\\( \hat (a))=(\bar (y))-b(\bar (x))).\end(cases)))Genel durumda sabitli modellerin tercih edilmesine rağmen, bazı durumlarda teorik değerlendirmelerden sabitin olduğu bilinmektedir. a (\displaystyle a) sıfıra eşit olmalıdır. Örneğin fizikte gerilim ve akım arasındaki ilişki şöyledir: U = I ⋅ R (\displaystyle U=I\cdot R); Gerilim ve akımı ölçerken direnci tahmin etmek gerekir. Bu durumda modelden bahsediyoruz. y = b x (\displaystyle y=bx). Bu durumda denklem sistemi yerine elimizdeki tek denklem
(∑ x t 2) b = ∑ x t y t (\displaystyle \sol(\toplam x_(t)^(2)\sağ)b=\toplam x_(t)y_(t)).
Bu nedenle, tek katsayıyı tahmin etmeye yönelik formül şu şekildedir:
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ (\displaystyle (\hat (b))=(\frac (\sum _(t=1)^(n)x_(t) )y_(t))(\toplam _(t=1)^(n)x_(t)^(2)))=(\frac (\overline (xy))(\overline (x^(2)) ))).
Bir polinom modelinin durumu
Veriler bir değişkenin polinom regresyon fonksiyonuna uyuyorsa f (x) = b 0 + ∑ ben = 1 k b ben x ben (\displaystyle f(x)=b_(0)+\sum \limits _(i=1)^(k)b_(i)x^(i)) o zaman dereceleri algılamak x ben (\displaystyle x^(i)) her biri için bağımsız faktörler olarak ben (\displaystyle i) Doğrusal bir modelin parametrelerini tahmin etmeye yönelik genel formüle dayalı olarak model parametrelerini tahmin etmek mümkündür. Bunu yapmak için genel formülde böyle bir yorumla dikkate alınması yeterlidir. x t ben x t j = x t ben x t j = x t ben + j (\displaystyle x_(ti)x_(tj)=x_(t)^(i)x_(t)^(j)=x_(t)^(i+j)) vektörlerin maksimum yakınlığı anlamında x t j y t = x t j y t (\displaystyle x_(tj)y_(t)=x_(t)^(j)y_(t)). Buradan, matris denklemleri V bu durumdaşu şekli alacaktır:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 b 1 ⋮ b k ] = [ ∑ n y t ∑ n t y t ⋮ ∑ n x t k y t ] .
(\displaystyle (\begin(pmatrix)n&\toplam \limits _(n)x_(t)&\ldots &\sum \limits _(n)x_(t)^(k)\\\toplam \limits _( n)x_(t)&\sum \limits _(n)x_(t)^(2)&\ldots &\sum \limits _(n)x_(t)^(k+1)\\\vdots & \vdots &\ddots &\vdots \\\sum \limits _(n)x_(t)^(k)&\sum \limits _(n)x_(t)^(k+1)&\ldots &\ toplam \limits _(n)x_(t)^(2k)\end(pmatrix))(\begin(bmatrix)b_(0)\\b_(1)\\\vdots \\b_(k)\end( bmatrix))=(\begin(bmatrix)\sum \limits _(n)y_(t)\\\sum \limits _(n)x_(t)y_(t)\\\vdots \\\sum \limits _(n)x_(t)^(k)y_(t)\end(bmatrix))).)
OLS tahmincilerinin istatistiksel özellikleri Her şeyden önce, doğrusal modeller için OLS tahminlerinin şu şekilde olduğunu not ediyoruz: doğrusal tahminler yukarıdaki formülden aşağıdaki gibi. Tarafsız OLS tahminleri için aşağıdakilerin gerçekleştirilmesi gerekli ve yeterlidir: en önemli koşul Regresyon analizi: faktörlere bağlı olarak, rastgele hatanın matematiksel beklentisi sıfıra eşit olmalıdır. Bu durum
- özellikle eğer tatmin olursa matematiksel beklenti rastgele hatalar
- sıfıra eşittir ve
faktörler ve rastgele hatalar bağımsız rastgele değişkenlerdir. İkinci koşul - faktörlerin dışsallığı koşulu - temeldir. Bu özellik karşılanmazsa, hemen hemen tüm tahminlerin son derece yetersiz olacağını varsayabiliriz: tutarlı bile olmayacaklardır (yani, çok büyük hacimli veri elde edilmesine izin vermiyor niteliksel değerlendirmeler bu durumda). Klasik durumda, dışsallık koşulunun otomatik olarak karşılandığı anlamına gelen rastgele hatanın aksine, faktörlerin determinizmi hakkında daha güçlü bir varsayım yapılır. Genel durumda tahminlerin tutarlılığı için matrisin yakınsaması ile birlikte dışsallık koşulunun sağlanması yeterlidir. Vx (\displaystyle V_(x))
Örnek boyutu sonsuza arttıkça bazı tekil olmayan matrislere.
Tutarlılık ve tarafsızlığın yanı sıra (sıradan) en küçük kareler tahminlerinin de etkili olabilmesi için (doğrusal tarafsız tahminler sınıfının en iyisi), rastgele hatanın ek özelliklerinin karşılanması gerekir: Bu varsayımlar rastgele hata vektörünün kovaryans matrisi için formüle edilebilir..
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Bu koşulları sağlayan doğrusal modele denir.. Klasik doğrusal regresyon için OLS tahminleri tarafsızdır, tutarlıdır ve tüm doğrusal tarafsız tahminler sınıfındaki en etkili tahminlerdir (İngiliz literatüründe bazen kısaltma kullanılır) MAVİ (En İyi Doğrusal Tarafsız Tahminci) - en iyi doğrusal tarafsız tahmin; V Rus edebiyatı Gauss-Markov teoremine daha sık başvurulur). Gösterilmesi kolay olduğu gibi, katsayı tahminleri vektörünün kovaryans matrisi şuna eşit olacaktır:
V (b ^ Ö L S) = σ 2 (X T X) − 1 (\displaystyle V((\hat (b))_(OLS))=\sigma ^(2)(X^(T)X)^(-1 )).
Verimlilik, bu kovaryans matrisinin "minimum" olduğu anlamına gelir (katsayıların herhangi bir doğrusal kombinasyonu ve özellikle katsayıların kendileri minimum varyansa sahiptir), yani doğrusal tarafsız tahminciler sınıfında OLS tahmincileri en iyisidir. Bu matrisin köşegen elemanları katsayı tahminlerinin varyanslarıdır - önemli parametreler Alınan değerlendirmelerin kalitesi. Ancak rastgele hata varyansı bilinmediğinden kovaryans matrisini hesaplamak mümkün değildir. Rastgele hataların varyansının tarafsız ve tutarlı (klasik doğrusal model için) tahmininin miktar olduğu kanıtlanabilir:
S 2 = R S S / (n − k) (\displaystyle s^(2)=RSS/(n-k)).
Bu değeri kovaryans matrisi formülünde yerine koyarak kovaryans matrisinin bir tahminini elde ederiz. Ortaya çıkan tahminler aynı zamanda tarafsız ve tutarlıdır. Hata varyansının tahmininin (ve dolayısıyla katsayıların varyansının) ve model parametrelerinin tahminlerinin bağımsız rastgele değişkenler olması da önemlidir; bu, model katsayıları hakkındaki hipotezlerin test edilmesi için test istatistiklerinin elde edilmesini mümkün kılar.
Klasik varsayımların karşılanmaması durumunda OLS parametre tahminlerinin en verimli olmadığı ve W (\displaystyle W) bazı simetrik pozitif tanımlı ağırlık matrisidir. Geleneksel en küçük kareler, ağırlık matrisinin birim matrisle orantılı olduğu bu yaklaşımın özel bir durumudur. Bilindiği gibi simetrik matrisler (veya operatörler) için bir genişleme vardır. W = P T P (\displaystyle W=P^(T)P). Bu nedenle, belirtilen fonksiyonel aşağıdaki gibi temsil edilebilir e T P T P e = (P e) T P e = e ∗ T e ∗ (\displaystyle e^(T)P^(T)Pe=(Pe)^(T)Pe=e_(*)^(T)e_( *)) yani bu fonksiyonel bazı dönüştürülmüş “kalanların” karelerinin toplamı olarak temsil edilebilir. Böylece, en küçük kareler yöntemlerinin bir sınıfını - LS yöntemlerini (En Küçük Kareler) - ayırt edebiliriz.
Genelleştirilmiş bir doğrusal regresyon modeli için (rastgele hataların kovaryans matrisine hiçbir kısıtlama getirilmeyen), en etkili olanın (doğrusal tarafsız tahminler sınıfında) sözde tahminler olduğu kanıtlanmıştır (Aitken teoremi). genelleştirilmiş En Küçük Kareler (GLS - Genelleştirilmiş En Küçük Kareler)- Rastgele hataların ters kovaryans matrisine eşit ağırlık matrisine sahip LS yöntemi: W = V ε − 1 (\displaystyle W=V_(\varepsilon )^(-1)).
Doğrusal bir modelin parametrelerinin GLS tahminlerine yönelik formülün şu şekilde olduğu gösterilebilir:
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y (\displaystyle (\hat (b))_(GLS)=(X^(T)V^(-1)X)^(-1) X^(T)V^(-1)y).
Bu tahminlerin kovaryans matrisi buna göre şuna eşit olacaktır:
V (b ^ G L S) = (X T V − 1 X) − 1 (\displaystyle V((\hat (b))_(GLS))=(X^(T)V^(-1)X)^(- 1)).
Aslında OLS'nin özü, orijinal verilerin belirli (doğrusal) bir dönüşümünde (P) ve sıradan OLS'nin dönüştürülmüş verilere uygulanmasında yatmaktadır. Bu dönüşümün amacı, dönüştürülen veriler için rastgele hataların zaten klasik varsayımları sağlamasıdır.
Ağırlıklı OLS
Çapraz ağırlık matrisi (ve dolayısıyla rastgele hataların kovaryans matrisi) durumunda, ağırlıklı En Küçük Kareler (WLS) olarak adlandırılan matrise sahibiz. Bu durumda, model artıklarının ağırlıklı kareler toplamı en aza indirilir, yani her gözlem, bu gözlemdeki rastgele hatanın varyansıyla ters orantılı bir "ağırlık" alır: e T W e = ∑ t = 1 n e t 2 σ t 2 (\displaystyle e^(T)We=\sum _(t=1)^(n)(\frac (e_(t)^(2))(\ sigma_(t)^(2)))). Aslında veriler, gözlemlerin ağırlıklandırılmasıyla (beklenen değerle orantılı bir miktara bölünerek) dönüştürülür. standart sapma rastgele hatalar) ve ağırlıklı verilere olağan OLS uygulanır.
ISBN 978-5-7749-0473-0 .
Özellikler arasındaki stokastik ilişkileri incelemenin yöntemlerinden biri regresyon analizidir.
Regresyon analizi, bulmak için kullanılan bir regresyon denkleminin çıktısıdır. ortalama değer başka (veya diğer) değişkenlerin (faktör nitelikleri) değeri biliniyorsa, rastgele bir değişken (sonuç niteliği). Aşağıdaki adımları içerir:
- bağlantı biçiminin seçimi (analitik regresyon denkleminin türü);
- denklem parametrelerinin tahmini;
- analitik regresyon denkleminin kalitesinin değerlendirilmesi.
Doğrusal ikili ilişki durumunda regresyon denklemi şu formu alacaktır: y i =a+b·x i +u i . Seçenekler verilen denklem a ve b verilerden tahmin edilir istatistiksel gözlem x ve y. Böyle bir değerlendirmenin sonucu aşağıdaki denklemdir: burada a ve b parametrelerinin tahminleri, regresyon denkleminden (hesaplanan değer) elde edilen sonuçtaki özelliğin (değişken) değeridir.
Parametreleri tahmin etmek için en sık kullanılanlar en küçük kareler yöntemi (LSM).
En küçük kareler yöntemi, regresyon denkleminin parametrelerinin en iyi (tutarlı, verimli ve tarafsız) tahminlerini sağlar. Ancak yalnızca rastgele terim (u) ve bağımsız değişken (x) ile ilgili belirli varsayımlar karşılanırsa (bkz. OLS varsayımları).
En küçük kareler yöntemini kullanarak bir doğrusal çift denklemin parametrelerini tahmin etme problemişu şekildedir: sapmaların karelerinin toplamı olan parametre tahminlerinin elde edilmesi gerçek değerler hesaplanan değerlerden etkili öznitelik - y i - minimumdur.
Resmi olarak OLS kriterişu şekilde yazılabilir:  .
.
En küçük kareler yöntemlerinin sınıflandırılması
- En küçük kareler yöntemi.
- Yöntem maksimum olasılık(normal bir klasik doğrusal regresyon modeli için, regresyon artıklarının normalliği varsayılır).
- Genelleştirilmiş en küçük kareler OLS yöntemi, hataların otokorelasyonu ve değişen varyans durumunda kullanılır.
- Ağırlıklandırılmış en küçük kareler yöntemi ( özel durum Heteroskedastik artıklara sahip OLS).
Konuyu açıklayalım klasik yöntem grafiksel olarak en küçük kareler. Bunu yapmak için, gözlemsel verilere (xi , y i , i=1;n) dayalı olarak bir dağılım grafiği oluşturacağız. dikdörtgen sistem koordinatlar (böyle bir nokta grafiğine korelasyon alanı denir). Noktalara en yakın olan düz bir çizgiyi bulmaya çalışalım korelasyon alanı. En küçük kareler yöntemine göre çizgi, korelasyon alanı noktaları ile bu çizgi arasındaki dikey mesafelerin karelerinin toplamı minimum olacak şekilde seçilir. 
Bu problemin matematiksel gösterimi:  .
.
y i ve x i =1...n değerleri tarafımızdan bilinmektedir; bunlar gözlemsel verilerdir. S fonksiyonunda sabitleri temsil ederler. Bu fonksiyondaki değişkenler - , parametrelerinin gerekli tahminleridir. İki değişkenli bir fonksiyonun minimumunu bulmak için, bu fonksiyonun her bir parametre için kısmi türevlerini hesaplamak ve bunları sıfıra eşitlemek gerekir; 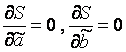 .
.
Sonuç olarak, 2 normal doğrusal denklemden oluşan bir sistem elde ederiz: 
Bu sistemi çözerek gerekli parametre tahminlerini buluyoruz: 
Regresyon denkleminin parametrelerinin hesaplanmasının doğruluğu, miktarlar karşılaştırılarak kontrol edilebilir (hesaplamaların yuvarlanmasından dolayı bazı tutarsızlıklar olabilir).
Parametre tahminlerini hesaplamak için Tablo 1'i oluşturabilirsiniz.
Regresyon katsayısı b'nin işareti ilişkinin yönünü gösterir (b>0 ise ilişki doğrudandır, b ise ilişkidir)<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Resmi olarak, a parametresinin değeri, x'in sıfıra eşit olduğu y'nin ortalama değeridir. Nitelik faktörü sıfır değere sahip değilse ve olamıyorsa, a parametresinin yukarıdaki yorumu anlamlı değildir.
Özellikler arasındaki ilişkinin yakınlığının değerlendirilmesi
doğrusal çift korelasyon katsayısı - r x,y kullanılarak gerçekleştirilir. Aşağıdaki formül kullanılarak hesaplanabilir:  . Ek olarak doğrusal çift korelasyon katsayısı, regresyon katsayısı b aracılığıyla belirlenebilir:
. Ek olarak doğrusal çift korelasyon katsayısı, regresyon katsayısı b aracılığıyla belirlenebilir:  .
.
Doğrusal çift korelasyon katsayısının kabul edilebilir değerleri aralığı –1 ile +1 arasındadır. Korelasyon katsayısının işareti ilişkinin yönünü gösterir. Eğer r x, y >0 ise bağlantı doğrudandır; eğer rx, y<0, то связь обратная.
Bu katsayı büyüklük olarak birliğe yakınsa, özellikler arasındaki ilişki oldukça yakın doğrusal bir ilişki olarak yorumlanabilir. Eğer modülü bir ê r x y ê =1'e eşitse, o zaman özellikler arasındaki ilişki fonksiyonel doğrusaldır. Eğer x ve y özellikleri doğrusal olarak bağımsızsa, o zaman r x,y 0'a yakındır.
r x,y'yi hesaplamak için Tablo 1'i de kullanabilirsiniz.
Tablo 1
| N gözlem | x ben | sen ben | x ben ∙y ben | ||
| 1 | x 1 | y 1 | x 1 y 1 | ||
| 2 | x 2 | y 2 | x 2 y 2 | ||
| ... | |||||
| N | xn | e-n | x n y n | ||
| Sütun Toplamı | ∑x | ∑y | ∑x y | ||
| Ortalama değer |
|
|
 ,
,
burada d2, regresyon denklemiyle açıklanan y'nin varyansıdır;
e 2 - y'nin artık (regresyon denklemiyle açıklanmayan) varyansı;
s 2 y - y'nin toplam (toplam) varyansı.
Belirleme katsayısı, toplam değişkenlik (dağılım) y içindeki regresyonla (ve dolayısıyla x faktörüyle) açıklanan sonuçta ortaya çıkan y özelliğinin varyasyonunun (dağılımının) oranını karakterize eder. R 2 yx belirleme katsayısı 0'dan 1'e kadar değerler alır. Buna göre 1-R 2 yx değeri, modelde dikkate alınmayan diğer faktörlerin etkisinin ve spesifikasyon hatalarının neden olduğu varyans y oranını karakterize eder.
Eşleştirilmiş doğrusal regresyonla R 2 yx =r 2 yx.
En küçük kareler yöntemi
En küçük kareler yöntemi ( OLS, OLS, Sıradan En Küçük Kareler) - Örnek verileri kullanarak regresyon modellerinin bilinmeyen parametrelerini tahmin etmeye yönelik temel regresyon analizi yöntemlerinden biri. Yöntem, regresyon artıklarının karelerinin toplamının en aza indirilmesine dayanmaktadır.
Çözümün gerekli değişkenlerin bazı fonksiyonlarının karelerinin toplamını en aza indirmeye yönelik bazı kriterleri karşılaması veya sağlaması durumunda, en küçük kareler yönteminin kendisinin herhangi bir alandaki bir sorunu çözmek için bir yöntem olarak adlandırılabileceği belirtilmelidir. Bu nedenle, en küçük kareler yöntemi, sayısı bu büyüklüklerin sayısını aşan denklemleri veya kısıtlamaları karşılayan bir miktarlar kümesi bulurken, belirli bir fonksiyonun diğer (daha basit) fonksiyonlar tarafından yaklaşık olarak temsil edilmesi (yaklaştırılması) için de kullanılabilir. , vesaire.
MNC'nin özü
(Açıklanan) değişken arasındaki olasılıksal (regresyon) ilişkinin bazı (parametrik) modeli verilse sen ve birçok faktör (açıklayıcı değişkenler) X
bilinmeyen model parametrelerinin vektörü nerede
- rastgele model hatası.Bu değişkenlerin değerlerine ilişkin örnek gözlemler de olsun. Gözlem numarası () olsun. O halde inci gözlemdeki değişkenlerin değerleridir. Daha sonra b parametrelerinin verilen değerleri için, açıklanan y değişkeninin teorik (model) değerlerini hesaplamak mümkündür:
Artıkların boyutu b parametrelerinin değerlerine bağlıdır.
En küçük kareler yönteminin (sıradan, klasik) özü, artıkların karelerinin toplamının (İng. Kalan Kareler Toplamı) minimum olacaktır:
Genel durumda bu problem sayısal optimizasyon (minimizasyon) yöntemleriyle çözülebilir. Bu durumda onlar hakkında konuşuyorlar doğrusal olmayan en küçük kareler(NLS veya NLLS - İngilizce) Doğrusal Olmayan En Küçük Kareler). Çoğu durumda analitik bir çözüm elde etmek mümkündür. Minimizasyon problemini çözmek için, fonksiyonun bilinmeyen parametreler b'ye göre türevini alarak, türevleri sıfıra eşitleyerek ve elde edilen denklem sistemini çözerek fonksiyonun durağan noktalarını bulmak gerekir:
Modelin rastgele hataları normal olarak dağıtılıyorsa, aynı varyansa sahipse ve ilişkisizse, OLS parametre tahminleri maksimum olabilirlik tahminleriyle (MLM) aynıdır.
Doğrusal bir model durumunda OLS
Regresyon bağımlılığının doğrusal olmasına izin verin:
İzin vermek sen açıklanan değişkenin gözlemlerinin bir sütun vektörüdür ve faktör gözlemlerinin bir matrisidir (matrisin satırları belirli bir gözlemdeki faktör değerlerinin vektörleridir, sütunlar belirli bir faktörün değerlerinin vektörüdür) tüm gözlemlerde). Doğrusal modelin matris gösterimi:
Daha sonra açıklanan değişkenin tahmin vektörü ile regresyon artıklarının vektörü eşit olacaktır.
Buna göre regresyon artıklarının karelerinin toplamı şuna eşit olacaktır:
Bu fonksiyonun parametre vektörüne göre türevini alarak ve türevleri sıfıra eşitleyerek bir denklem sistemi elde ederiz (matris formunda):
.Bu denklem sisteminin çözümü, doğrusal bir model için en küçük kareler tahminlerinin genel formülünü verir:
Analitik amaçlar açısından bu formülün ikinci gösterimi faydalıdır. Bir regresyon modelinde veriler merkezli, o zaman bu gösterimde ilk matris, faktörlerin örnek bir kovaryans matrisi anlamına gelir ve ikincisi, faktörlerin bağımlı değişkenle kovaryanslarının bir vektörüdür. Ayrıca veriler aynı zamanda normalleştirilmiş MSE'ye (yani sonuçta standartlaştırılmış), o zaman ilk matris, faktörlerin örnek korelasyon matrisi anlamına gelir, ikinci vektör, faktörlerin bağımlı değişkenle örnek korelasyonlarının bir vektörüdür.
Modeller için OLS tahminlerinin önemli bir özelliği sabit ile- oluşturulan regresyonun çizgisi örnek verilerin ağırlık merkezinden geçer, yani eşitlik sağlanır:
Özellikle, tek regresörün bir sabit olduğu uç durumda, tek parametrenin (sabitin kendisi) OLS tahmininin, açıklanan değişkenin ortalama değerine eşit olduğunu buluruz. Yani, büyük sayılar yasalarından iyi özellikleriyle bilinen aritmetik ortalama, aynı zamanda en küçük kareler tahminidir - ondan sapmaların minimum kare toplamı kriterini karşılar.
Örnek: en basit (çift yönlü) regresyon
Eşleştirilmiş doğrusal regresyon durumunda hesaplama formülleri basitleştirilmiştir (matris cebiri olmadan yapabilirsiniz):
OLS tahmincilerinin özellikleri
Öncelikle yukarıdaki formülden de anlaşılacağı gibi doğrusal modeller için OLS tahminlerinin doğrusal tahminler olduğunu not ediyoruz. Tarafsız OLS tahminleri için, regresyon analizinin en önemli koşulunu yerine getirmek gerekli ve yeterlidir: faktörlere bağlı olarak rastgele bir hatanın matematiksel beklentisi sıfıra eşit olmalıdır. Bu koşul, özellikle şu durumlarda karşılanır:
- rastgele hataların matematiksel beklentisi sıfırdır ve
- faktörler ve rastgele hatalar bağımsız rastgele değişkenlerdir.
İkinci koşul - faktörlerin dışsallığı koşulu - temeldir. Bu özellik karşılanmazsa, hemen hemen tüm tahminlerin son derece yetersiz olacağını varsayabiliriz: tutarlı bile olmayacaklar (yani, çok büyük miktarda veri bile bu durumda yüksek kaliteli tahminler elde etmemize izin vermiyor) ). Klasik durumda, dışsallık koşulunun otomatik olarak karşılandığı anlamına gelen rastgele hatanın aksine, faktörlerin determinizmi hakkında daha güçlü bir varsayım yapılır. Genel durumda, tahminlerin tutarlılığı için, örneklem büyüklüğü sonsuza arttıkça matrisin tekil olmayan bir matrise yakınsaması ile birlikte dışsallık koşulunun sağlanması yeterlidir.
Örnek boyutu sonsuza arttıkça bazı tekil olmayan matrislere.
Bu varsayımlar rastgele hata vektörünün kovaryans matrisi için formüle edilebilir.
V (ε) = σ 2 I (\displaystyle V(\varepsilon)=\sigma ^(2)I) Bu koşulları sağlayan doğrusal modele denir.. Klasik doğrusal regresyon için OLS tahminleri tarafsızdır, tutarlıdır ve tüm doğrusal tarafsız tahminler sınıfındaki en etkili tahminlerdir (İngiliz literatüründe bazen kısaltma kullanılır) MAVİ (En İyi Doğrusal Temelsiz Tahminci) - en iyi doğrusal tarafsız tahmin; Rus edebiyatında Gauss-Markov teoremine daha sık başvurulur). Gösterilmesi kolay olduğu gibi, katsayı tahminleri vektörünün kovaryans matrisi şuna eşit olacaktır:
Genelleştirilmiş OLS
En küçük kareler yöntemi geniş genellemeye izin verir. Artıkların karelerinin toplamını en aza indirmek yerine, artıklar vektörünün bazı pozitif belirli ikinci dereceden biçimleri (burada bazı simetrik pozitif belirli ağırlık matrisleri) en aza indirilebilir. Geleneksel en küçük kareler, ağırlık matrisinin birim matrisle orantılı olduğu bu yaklaşımın özel bir durumudur. Simetrik matrisler (veya operatörler) teorisinden bilindiği gibi, bu tür matrisler için bir ayrıştırma vardır. Sonuç olarak, belirtilen fonksiyonel şu şekilde temsil edilebilir, yani bu fonksiyonel bazı dönüştürülmüş "kalanların" karelerinin toplamı olarak temsil edilebilir. Böylece, en küçük kareler yöntemlerinin bir sınıfını - LS yöntemlerini (En Küçük Kareler) - ayırt edebiliriz.
Genelleştirilmiş bir doğrusal regresyon modeli için (rastgele hataların kovaryans matrisine hiçbir kısıtlama getirilmeyen), en etkili olanın (doğrusal tarafsız tahminler sınıfında) sözde tahminler olduğu kanıtlanmıştır (Aitken teoremi). genelleştirilmiş En Küçük Kareler (GLS - Genelleştirilmiş En Küçük Kareler)- Rasgele hataların ters kovaryans matrisine eşit ağırlık matrisine sahip LS yöntemi: .
Doğrusal bir modelin parametrelerinin GLS tahminlerine yönelik formülün şu şekilde olduğu gösterilebilir:
Bu tahminlerin kovaryans matrisi buna göre şuna eşit olacaktır:
Aslında OLS'nin özü, orijinal verilerin belirli (doğrusal) bir dönüşümünde (P) ve sıradan OLS'nin dönüştürülmüş verilere uygulanmasında yatmaktadır. Bu dönüşümün amacı, dönüştürülen veriler için rastgele hataların zaten klasik varsayımları sağlamasıdır.
Ağırlıklı OLS
Çapraz ağırlık matrisi (ve dolayısıyla rastgele hataların kovaryans matrisi) durumunda, ağırlıklı En Küçük Kareler (WLS) olarak adlandırılan matrise sahibiz. Bu durumda, model artıklarının ağırlıklı kareler toplamı en aza indirilir, yani her gözlem, bu gözlemdeki rastgele hatanın varyansıyla ters orantılı bir "ağırlık" alır: . Aslında veriler, gözlemlerin ağırlıklandırılmasıyla (rastgele hataların tahmin edilen standart sapması ile orantılı bir miktara bölünerek) dönüştürülür ve ağırlıklandırılmış verilere sıradan OLS uygulanır.
Uygulamada MNC kullanımına ilişkin bazı özel durumlar
Doğrusal bağımlılığa yaklaşım
Belirli bir skaler miktarın belirli bir skaler miktara bağımlılığının incelenmesi sonucunda durumu ele alalım (Bu, örneğin voltajın akım gücüne bağımlılığı olabilir: sabit bir değer nerede, direnç iletken), bu miktarların ölçümleri yapıldı, bunun sonucunda değerler ve bunlara karşılık gelen değerler ortaya çıktı. Ölçüm verileri bir tabloya kaydedilmelidir.
Masa. Ölçüm sonuçları.
| Ölçüm numarası | ||
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 |
Soru şudur: Bağımlılığı en iyi şekilde tanımlamak için hangi katsayı değeri seçilebilir? En küçük kareler yöntemine göre bu değer, değerlerin değerlerden sapmalarının karelerinin toplamı olacak şekilde olmalıdır.
minimum düzeydeydi
Sapmaların karelerinin toplamının bir ekstremumu vardır - bir minimum, bu da bu formülü kullanmamıza izin verir. Bu formülden katsayının değerini bulalım. Bunu yapmak için sol tarafını şu şekilde dönüştürüyoruz:
Son formül, problemde gerekli olan katsayı değerini bulmamızı sağlar.
Hikaye
19. yüzyılın başlarına kadar. bilim adamlarının, bilinmeyenlerin sayısının denklem sayısından az olduğu bir denklem sistemini çözmek için belirli kuralları yoktu; O zamana kadar denklemlerin türüne ve hesap makinelerinin zekasına bağlı özel teknikler kullanılıyordu ve bu nedenle aynı gözlem verilerine dayanan farklı hesap makineleri farklı sonuçlara varıyordu. Bu yöntemi ilk kullanan Gauss (1795) oldu ve Legendre (1805) bunu bağımsız olarak keşfedip modern adı (Fransızca) altında yayınladı. En İyi Yöntemler ). Laplace yöntemi olasılık teorisiyle ilişkilendirdi ve Amerikalı matematikçi Adrain (1808) bunun olasılık teorisi uygulamalarını değerlendirdi. Yöntem, Encke, Bessel, Hansen ve diğerlerinin daha ileri araştırmalarıyla yaygınlaştırıldı ve geliştirildi.
OLS'nin alternatif kullanımları
En küçük kareler yöntemi fikri, regresyon analiziyle doğrudan ilgili olmayan diğer durumlarda da kullanılabilir. Gerçek şu ki, karelerin toplamı vektörler için en yaygın yakınlık ölçülerinden biridir (sonlu boyutlu uzaylarda Öklid metriği).
Bir uygulama, denklem sayısının değişken sayısından daha fazla olduğu doğrusal denklem sistemlerinin “çözümüdür”
matrisin kare değil dikdörtgen olduğu yer.
Böyle bir denklem sisteminin genel durumda hiçbir çözümü yoktur (eğer sıralama aslında değişken sayısından büyükse). Bu nedenle, bu sistem ancak vektorler arasındaki "mesafeyi" en aza indirecek böyle bir vektörün seçilmesi anlamında "çözülebilir". Bunu yapmak için sistem denklemlerinin sol ve sağ tarafları arasındaki farkların karelerinin toplamının en aza indirilmesi kriterini uygulayabilirsiniz. Bu minimizasyon problemini çözmenin aşağıdaki denklem sisteminin çözümüne yol açtığını göstermek kolaydır.
Dengelemeden sonra aşağıdaki formda bir fonksiyon elde ederiz: g (x) = x + 1 3 + 1 .
Karşılık gelen parametreleri hesaplayarak y = a x + b doğrusal ilişkisini kullanarak bu verilere yaklaşabiliriz. Bunu yapmak için en küçük kareler yöntemini uygulamamız gerekecek. Ayrıca hangi çizginin deneysel verileri en iyi şekilde hizalayacağını kontrol etmek için bir çizim yapmanız gerekecektir.
Yandex.RTB R-A-339285-1
OLS (en küçük kareler yöntemi) tam olarak nedir?
Yapmamız gereken asıl şey, iki değişkenli F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 fonksiyonunun değerinin şu şekilde olacağı doğrusal bağımlılık katsayılarını bulmaktır: en küçük. Başka bir deyişle, a ve b'nin belirli değerleri için, sunulan verilerin ortaya çıkan düz çizgiden karesel sapmalarının toplamı minimum bir değere sahip olacaktır. En küçük kareler yönteminin anlamı budur. Örneği çözmek için yapmamız gereken tek şey, iki değişkenli fonksiyonun ekstremumunu bulmak.
Katsayıların hesaplanmasına yönelik formüller nasıl türetilir?
Katsayıların hesaplanmasına yönelik formüller türetmek için iki değişkenli bir denklem sistemi oluşturup çözmeniz gerekir. Bunu yapmak için F (a, b) = ∑ i = 1 n (y i - (a x i + b)) 2 ifadesinin a ve b'ye göre kısmi türevlerini hesaplıyoruz ve bunları 0'a eşitliyoruz.
δ F (a , b) δ a = 0 δ F (a , b) δ b = 0 ⇔ - 2 ∑ ben = 1 n (y ben - (a x ben + b)) x ben = 0 - 2 ∑ ben = 1 n ( y ben - (a x ben + b)) = 0 ⇔ a ∑ ben = 1 n x ben 2 + b ∑ ben = 1 n x ben = ∑ ben = 1 n x ben y ben a ∑ ben = 1 n x ben + ∑ ben = 1 n b = ∑ ben = 1 n y ben ⇔ a ∑ ben = 1 n x ben 2 + b ∑ ben = 1 n x ben = ∑ ben = 1 n x ben y ben a ∑ ben = 1 n x ben + n b = ∑ ben = 1 n y ben
Bir denklem sistemini çözmek için ikame veya Cramer yöntemi gibi herhangi bir yöntemi kullanabilirsiniz. Sonuç olarak elimizde en küçük kareler yöntemini kullanarak katsayıları hesaplamak için kullanılabilecek formüllerimiz olmalıdır.
n ∑ ben = 1 n x ben y ben - ∑ ben = 1 n x ben ∑ ben = 1 n y ben n ∑ ben = 1 n - ∑ ben = 1 n x ben 2 b = ∑ ben = 1 n y ben - a ∑ ben = 1 n x ben n
Fonksiyonun bulunduğu değişkenlerin değerlerini hesapladık.
F (a , b) = ∑ i = 1 n (y i - (a x i + b)) 2 minimum değeri alacaktır. Üçüncü paragrafta bunun neden tam olarak böyle olduğunu kanıtlayacağız.
Bu, en küçük kareler yönteminin pratikteki uygulamasıdır. A parametresini bulmak için kullanılan formülü, ∑ ben = 1 n x ben, ∑ ben = 1 n y ben, ∑ ben = 1 n x ben y ben, ∑ ben = 1 n x ben 2'nin yanı sıra parametreyi içerir.
n – deneysel veri miktarını belirtir. Her tutarı ayrı ayrı hesaplamanızı öneririz. B katsayısının değeri a'dan hemen sonra hesaplanır.
Orijinal örneğe geri dönelim.
Örnek 1
Burada n'nin beşe eşit olduğunu görüyoruz. Katsayı formüllerinde yer alan gerekli miktarların hesaplanmasını daha kolay hale getirmek için tabloyu dolduralım.
| ben = 1 | ben=2 | ben=3 | ben=4 | ben=5 | ∑ ben = 1 5 | |
| x ben | 0 | 1 | 2 | 4 | 5 | 12 |
| sen ben | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x ben y ben | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x ben 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Çözüm
Dördüncü satır, her bir birey için ikinci satırdaki değerlerin üçüncü satırdaki değerlerle çarpılmasıyla elde edilen verileri içerir. Beşinci satır, ikinci satırın karesi olan verileri içerir. Son sütun, bireysel satırların değerlerinin toplamını gösterir.
İhtiyacımız olan a ve b katsayılarını hesaplamak için en küçük kareler yöntemini kullanalım. Bunu yapmak için son sütundaki gerekli değerleri değiştirin ve tutarları hesaplayın:
n ∑ ben = 1 n x ben y ben - ∑ ben = 1 n x ben ∑ ben = 1 n y ben n ∑ ben = 1 n - ∑ ben = 1 n x ben 2 b = ∑ ben = 1 n y ben - a ∑ ben = 1 n x ben n ⇒ a = 5 33, 8 - 12 12, 9 5 46 - 12 2 b = 12, 9 - a 12 5 ⇒ a ≈ 0, 165 b ≈ 2, 184
Gerekli yaklaşık düz çizginin y = 0, 165 x + 2, 184 gibi görüneceği ortaya çıktı. Şimdi hangi doğrunun verilere daha iyi yaklaşacağını belirlememiz gerekiyor - g (x) = x + 1 · 3 + 1 veya 0, 165 x + 2, 184. En küçük kareler yöntemini kullanarak tahmin yapalım.
Hatayı hesaplamak için, σ 1 = ∑ i = 1 n (y ben - (a x ben + b i)) 2 ve σ 2 = ∑ i = 1 n (y i) düz çizgilerinden elde edilen verilerin sapmalarının karelerinin toplamını bulmamız gerekir. - g (x i)) 2, minimum değer daha uygun bir çizgiye karşılık gelecektir.
σ 1 = ∑ ben = 1 n (y ben - (a x ben + b ben)) 2 = = ∑ ben = 1 5 (y ben - (0, 165 x ben + 2, 184)) 2 ≈ 0, 019 σ 2 = ∑ ben = 1 n (y ben - g (x ben)) 2 = = ∑ ben = 1 5 (y ben - (x ben + 1 3 + 1)) 2 ≈ 0,096
Cevap:σ 1'den beri< σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0,165 x + 2,184.
En küçük kareler yöntemi grafiksel gösterimde açıkça gösterilmiştir. Kırmızı çizgi g (x) = x + 1 3 + 1 düz çizgisini, mavi çizgi ise y = 0, 165 x + 2, 184'ü gösterir. Orijinal veriler pembe noktalarla gösterilir.
Tam olarak neden bu tür yaklaşımlara ihtiyaç duyulduğunu açıklayalım.
Veri yumuşatma gerektiren görevlerde ve ayrıca verilerin enterpolasyon veya tahmin edilmesi gereken görevlerde kullanılabilirler. Örneğin, yukarıda tartışılan problemde, gözlemlenen y niceliğinin değeri x = 3 veya x = 6'da bulunabilir. Bu tür örneklere ayrı bir makale ayırdık.
OLS yönteminin kanıtı
Fonksiyonun a ve b hesaplanırken minimum değer alabilmesi için, belirli bir noktada fonksiyonun diferansiyelinin ikinci dereceden formunun matrisinin F (a, b) = ∑ i = olması gerekir. 1 n (y i - (a x i + b)) 2 pozitif tanımlıdır. Size nasıl görünmesi gerektiğini gösterelim.
Örnek 2
Aşağıdaki formda ikinci dereceden bir diferansiyelimiz var:
d 2 F (a ; b) = δ 2 F (a ; b) δ a 2 d 2 a + 2 δ 2 F (a ; b) δ a δ b d a d b + δ 2 F (a ; b) δ b 2 d 2b
Çözüm
δ 2 F (a ; b) δ a 2 = δ δ F (a ; b) δ a δ a = = δ - 2 ∑ ben = 1 n (y ben - (a x ben + b)) x ben δ a = 2 ∑ ben = 1 n (x ben) 2 δ 2 F (a; b) δ a δ b = δ δ F (a; b) δ a δ b = = δ - 2 ∑ ben = 1 n (y ben - (a x ben + b) ) x ben δ b = 2 ∑ ben = 1 n x ben δ 2 F (a ; b) δ b 2 = δ δ F (a ; b) δ b δ b = δ - 2 ∑ ben = 1 n (y ben - (a x ben + b)) δ b = 2 ∑ ben = 1 n (1) = 2 n
Başka bir deyişle, bunu şu şekilde yazabiliriz: d 2 F (a ; b) = 2 ∑ ben = 1 n (x ben) 2 d 2 a + 2 2 ∑ x ben ben = 1 n d a d b + (2 n) d 2 b.
İkinci dereceden formda bir matris elde ettik M = 2 ∑ ben = 1 n (x ben) 2 2 ∑ ben = 1 n x ben 2 ∑ ben = 1 n x ben 2 n .
Bu durumda, bireysel elemanların değerleri a ve b'ye bağlı olarak değişmeyecektir. Bu matris pozitif tanımlı mıdır? Bu soruyu cevaplamak için açısal küçüklerin pozitif olup olmadığını kontrol edelim.
Hesaplıyoruz köşe minör birinci dereceden: 2 ∑ ben = 1 n (x ben) 2 > 0 . X i noktaları çakışmadığı için eşitsizlik kesindir. Daha sonraki hesaplamalarda bunu aklımızda tutacağız.
İkinci dereceden açısal minörü hesaplıyoruz:
d e t (M) = 2 ∑ ben = 1 n (x ben) 2 2 ∑ ben = 1 n x ben 2 ∑ ben = 1 n x ben 2 n = 4 n ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2
Bundan sonra, matematiksel tümevarım kullanarak n ∑ i = 1 n (x i) 2 - ∑ i = 1 n x ben 2 > 0 eşitsizliğini kanıtlamaya geçiyoruz.
- Olacak mı diye kontrol edelim bu eşitsizlik keyfi n için geçerlidir. 2'yi alıp hesaplayalım:
2 ∑ ben = 1 2 (x ben) 2 - ∑ ben = 1 2 x ben 2 = 2 x 1 2 + x 2 2 - x 1 + x 2 2 = = x 1 2 - 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
Doğru bir eşitlik elde ettik (eğer x 1 ve x 2 değerleri çakışmıyorsa).
- Bu eşitsizliğin n için doğru olacağını varsayalım; n ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2 > 0 – doğru.
- Şimdi n + 1'in geçerliliğini kanıtlayacağız, yani. (n + 1) ∑ ben = 1 n + 1 (x ben) 2 - ∑ ben = 1 n + 1 x ben 2 > 0, eğer n ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2 > 0 .
Hesaplıyoruz:
(n + 1) ∑ ben = 1 n + 1 (x ben) 2 - ∑ ben = 1 n + 1 x ben 2 = = (n + 1) ∑ ben = 1 n (x ben) 2 + x n + 1 2 - ∑ ben = 1 n x ben + x n + 1 2 = = n ∑ ben = 1 n (x ben) 2 + n x n + 1 2 + ∑ ben = 1 n (x ben) 2 + x n + 1 2 - - ∑ ben = 1 n x ben 2 + 2 x n + 1 ∑ ben = 1 n x ben + x n + 1 2 = = ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2 + n x n + 1 2 - x n + 1 ∑ ben = 1 n x ben + ∑ ben = 1 n (x ben) 2 = = ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2 + x n + 1 2 - 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 - 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 - 2 x n + 1 x 1 + x n 2 = = n ∑ ben = 1 n (x ben) 2 - ∑ ben = 1 n x ben 2 + + (x n + 1 - x 1) 2 + (x n + 1 - x 2) 2 + . . . + (xn - 1 - xn) 2 > 0
İçerisindeki ifade diş telleri, 0'dan büyük olacaktır (2. adımda varsaydığımıza göre) ve geri kalan terimlerin tümü sayıların kareleri olduğundan 0'dan büyük olacaktır. Eşitsizliği kanıtladık.
Cevap: bulunan a ve b eşleşecek en düşük değer F (a , b) = ∑ i = 1 n (y ben - (a x ben + b)) 2 fonksiyonları, yani bunlar en küçük kareler yönteminin (LSM) istenen parametreleridir.
Metinde bir hata fark ederseniz, lütfen onu vurgulayın ve Ctrl+Enter tuşlarına basın.







